Сети с многокаскадными соединениями
4.1.10 Сети с многокаскадными соединениями
Семенов Ю.А. (ГНЦ ИТЭФ)
Среди традиционных сетей особое положение занимают сети, базирующиеся на большом числе идентичных ключевых элементов. Это сети с многокаскадными связями (MIN – Multistage Interconnection Network). Идеология таких сетей используется при построении коммутаторов ATM. Из таких сетей наиболее известной является Delta Banyan (Batcher-switch). Эта сеть содержит регулярную структуру N*N переключателей с двух направлений на два. Сеть содержит log2N число каскадов, каждый из которых имеет N/2 переключателей. Для управления маршрутизацией сообщений в этой сети необходимо log2N бит информации. Схема 4-каскадной сети Delta-2 приведена на рис. 4.1.10.1.
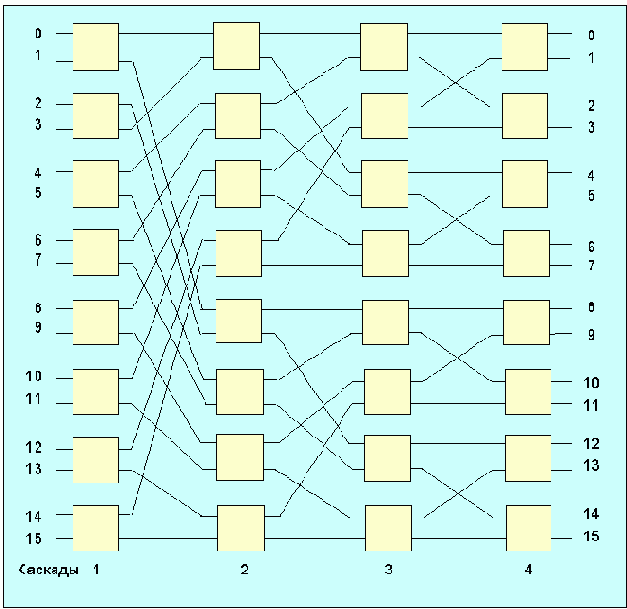
Рис. 4.1.10.1. Блок-схема 4-х каскадной сети Delta-2
Сети управления и сбора данных в реальном масштабе времени (CAN)
4.1.4 Сети управления и сбора данных в реальном масштабе времени (CAN)
Семенов Ю.А. (ГНЦ ИТЭФ)

Стандарт CAN (Controller Area Network - http://www.kvaser.se/can/protocol/index.htm или http://www.omegas.co.uk/can/canworks.htm, а также www.can-cia.de) был разработан в Германии компанией Robert Bosch gmbh для автомобильной промышленности (1970 годы). Сеть CAN ориентирована на последовательные каналы связи, выполненные из скрученных пар проводов (или оптических волокон), стандарт определяет протоколы физического уровня и субуровеней MAC и LLC. Все узлы сети равноправны и подключаются к общему каналу. Уровни сигналов протоколом не нормированы. В CAN использована кодировка типа NRZ (Non Return to Xero). Для распознавания сигнатур начала (SOF) и конца (EOF) кадра используется бит-стафинг. В настоящее время в ЕС разрабатывается новый протокол для сети автомобиля, который бы позволял передачу высококачественного стерео аудио и видео сигналов, обеспечивал работу с мобильными телефонными сетями и Интернет. Предполагается, что пропускная способность протокола составит 45 Мбит/c
Высокая надежность и дешевизна сделала сети CAN привлекательными для промышленности и науки. Сеть предназначена для сбора информации и управления в реальном масштабе времени, но может быть использована и для других целей. Канал can реализует принцип множественного доступа с детектированием столкновений (CSMA/CD - Carrier Sense Multiple Access with Collision Detection, аналогично Ethernet). Сеть может содержать только один сегмент. В соответствии со стандартом ISO 11898 сеть способна работать при обрыве одного из проводов, при закоротке одного из проводов на шину питания или на землю. Скорость работы канала программируется и может достигать 1 Мбит/с. Недиструктивная схема арбитража позволяет сделать доступ к общему каналу существенно более эффективным, чем в случае Ethernet. В настоящее время действуют две версии стандарта с полями арбитража длиной в 11 бит (2.0a) и 29 бит (расширенная версия, 2.0b). Код арбитража одновременно является идентификатором кадра и задается на фазе инициализации сети. При одновременной попытке передачи кадров двумя узлами арбитраж выполняется побитно с использованием схемы проволочного “И”, при этом доминантным состоянием является логический “0”. Выигравший соревнование узел продолжает передачу, а проигравший ждет момента, когда канал освободится. Код-адрес объекта (узла CAN) задается с помощью переключателей на плате CAN при формировании сети.
Когда канал свободен, любой из подключенных узлов, может начать передачу. Кадры могут иметь переменную, но конечную длину. Формат информационного кадра сети CAN, содержащего семь полей, показан на рис. 4.1.4.1.
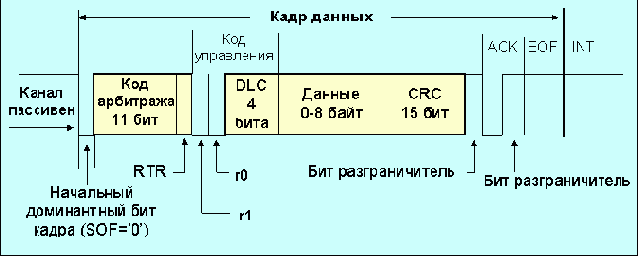
Рис. 4.1.4.1 Стандартный информационный кадр 1 2.0a CAN
Кадр начинается с доминантного бита начала кадра (логический нуль, SOF - start of frame). Далее следует поле арбитража (идентификатор кадра), содержащее 11 бит (эти разряды носят имена id-28, ..., id-18) и завершающееся битом RTR (remote transmission request) удаленного запроса передачи. В информационном кадре RTR=0, для кадра запроса RTR=1. Семь наиболее значимых бит id-28 - id-22 не должны быть никогда все одновременно равными 1. Первым передается бит id28. Доминантные биты r0 и r1 (=0) зарезервированы для будущего использования (в некоторых спецификациях бит r1 называется IDE и относится для стандартных кадров к полю управления). Поле DLC (Data Length Code; биты поля имеют имена dcl3 - dcl0) несет в себе код длины поля данных в байтах. Поле данных, размещенное вслед за ним, может иметь переменную длину или вообще отсутствовать. CRC - циклическая контрольная сумма. В качестве образующего полинома при вычислении CRC используется x15 + x14 + x10 + x8 + x7 + x4 + x3 + 1. Формально, следующий за контрольной суммой бит-разграничитель (=1) принадлежит полю CRC. Поле отклика (ack) содержит два бита, первый из которых первоначально имеет уровень 1, а узлы получатели меняют его значение на доминантное (логический 0). Бит используется для сообщения о корректности контрольной суммы. Второй бит поля всегда имеет уровень логической 1. Завершающее поле EOF (end of frame) содержит семь единичных бит. За этим полем следует поле-заполнитель (INT) из трех единичных бит, после него может следовать очередной кадр. Формат расширенного информационного кадра сети can показан на рис. 4.1.4.2.
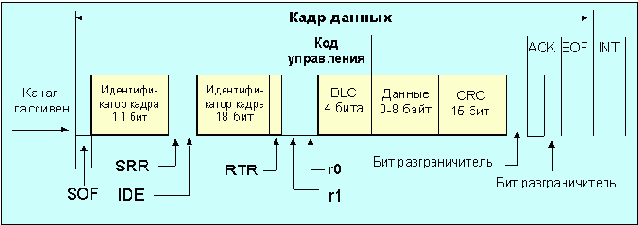
Рис. 4.1.4.2. Расширенный информационный кадр 2.0b CAN
Однобитовое субполе SRR (substitute remote request) включено в поле арбитража (идентификатора кадра) и всегда содержит код 1, что гарантирует преимущество стандартного информационного кадра (2.0a) случае его соревнования с расширенным кадром (2.0b) (при равных 11 битах идентификатора). Субполе IDE (identifier extension) служит для идентификации расширенного формата и для этого типа кадра всегда имеет уровень логической 1. Вслед за IDE следует 18-битовое поле (биты имеют имена id-17, ..., id-0; первым передается бит id-28) расширения идентификатора кадра. Контроллеры 2.0b полностью совместимы с кадрами 2.0a и могут посылать и принимать пакеты обоих типов. Идентификаторы в пределах одной сети должны быть уникальными. Следует иметь в виду, что 18-битное поле расширения идентификатора можно при определенных условиях использовать и для передачи информации. Идентификатор не является адресом места назначения, а определяет назначение передаваемых данных (адресация по содержанию). По этой причине пакет может быть принят отдельным узлом, группой узлов, всеми узлами сети или не воспринят вообще. Предельное число различных идентификаторов для версии 2.0a составляет 2032, а для 2.0b превышает 500 миллионов.
Послав кадр- запрос другому узлу, отправитель может затребовать присылку определенной информации. Удаленный узел должен откликнуться информационным кадром с тем же идентификатором, что и запрос.
Если несколько узлов начнут передачу одновременно, право передать кадр будет предоставлено узлу с более высоким приоритетом, который задается идентификатором кадра. Механизм арбитража гарантирует, что ни информация, ни время не будут потеряны. Если одновременно начнется передача запроса и информационного кадра с равными идентификаторами, предпочтение будет дано информационному пакету. В процессе арбитража каждый передатчик сравнивает уровень передаваемого сигнала с реальным уровнем на шине. Если эти уровни идентичны, он может продолжить передачу, в противном случае передача прерывается и шина остается в распоряжении более приоритетного кадра.
Протокол can имеет развитую систему диагностики ошибок. В результате вероятность не выявленной ошибки составляет менее 4.7ґ 10-11. При выявлении ошибки кадр отбрасывается и его передача повторяется.
Число узлов, подключенных к каналу, протоколом не лимитируется. Практически такое ограничение налагается задержкой или предельной нагрузкой канала.
Любой модуль can может быть переведен в пассивный режим (“состояние сна”), при котором внутренняя активность прекращается, а драйверы отключаются от канала. Выход из этого режима возможен либо по внутренним причинам, либо вследствие сетевой активности. После “пробуждения” модуль ждет, пока стабилизируется его внутренний тактовый генератор, после чего производится синхронизация его работы с тактами канала (11 тактов). Благодаря синхронизации отдельные узлы не могут начать передачу асинхронно (со сдвигом на часть такта). Протокол предусматривает использование четырех типов кадров:
Информационный.
Удаленный запрос (требование присылки информационного кадра с тем же идентификатором, что и запрос).
Сообщение об ошибке.
Уведомление о перегрузке канала (требует дополнительной задержки до и после передач информационных кадров и удаленных запросов).
Информационные кадры и удаленные запросы могут использовать как стандартные, так и расширенные форматы кадров (2.0a и 2.0b).
Кадр удаленного запроса
может иметь стандартный и расширенный форматы. В обоих случаях он содержит 6 полей: SOF, поле арбитража, поле управления, CRC, поля ACK и EOF. Для этого типа кадров бит RTR=1, а поле данных отсутствует вне зависимости от того, какой код содержится в субполе длины.
Кадр сообщения об ошибке
имеет только два поля - суперпозиция флагов ошибки и разграничитель ошибки. Флаги ошибки бывают активными и пассивными. Активный флаг состоит из шести нулевых бит, а пассивный - из шести единиц. Суперпозиция флагов может содержать от 6 до 12 бит. Разграничитель ошибки состоит из восьми единичных бит.
Кадр перегрузки
включает в себя два поля - перпозиция флагов перегрузки и разграничитель перегрузки (8 бит =1). В поле флаг ерегрузки записывается 6 бит, равных нулю (как и в поле флаг активной ошибки). Кадры ошибки или перегрузки не требуют межкадровых разделителей. Существует ряд условий перегрузки, каждое из которых вызывает посылку такого кадра:
внутренние обстоятельства приемника, которые требуют задержки передачи следующего кадра данных или запроса.
Детектирование доминантного бита в начале поля int.
Обнаружение узлом доминантного восьмого бита в поле разграничителя ошибки или разграничителя перегрузки.
Время пребывания канала в пассивном состоянии не нормировано. Появление доминантного бита на шине, пребывающей в пассивном состоянии, воспринимается как начало очередного кадра. Предусматривается возможность установления масок в узле на отдельные двоичные разряды идентификатора, что позволяет игнорировать их значения. Маскирование делает возможным мультикастинг-адресацию.
Поля SOF, идентификатор, управляющее поле, данные и CRC кодируются таким образом, что при появлении пяти идентичных бит подряд, в поток вставляется бит противоположного уровня. Так 0000000 преобразуется в 00000100, а 1111110 в 11111010. Это правило не распространяется на CRC-разделители, поля ACK и EOF, а также на кадры сообщения об ошибке или переполнении. Существует 5 разновидностей ошибок (таблица 3.3.4.1).
Таблица 4.1.4.1 Разновидности ошибок.
Тип ошибки
Описание
bit error Передающий узел обнаружил, что состояние шины не соответствует тому, что он туда передает stuff error Нарушено правило кодирования (вставка бита противоположного значения после 5 идентичных бит, см. абзац выше). CRC error Приемник обнаружил ошибку в контрольной сумме. form error Обнаружено нарушение формата кадра acknowledgment error Выявлен неверный уровень первого бита поля ack. Любой узел CAN должен регистрировать и по запросу сообщать число ошибок при передаче и приеме.
Номинальное время, выделенное для передачи одного бита, включает в себя четыре временные области: sync_seg, prop_seg, phase_seg1, phase_seg2 (рис.3.4.4.3).
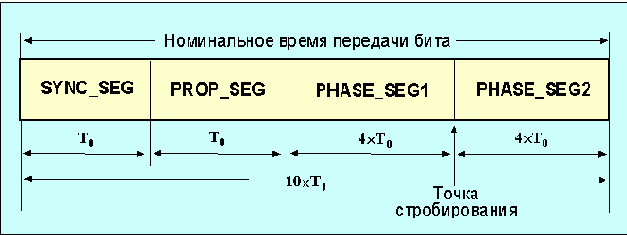
Рис. 4.1.4.3 Временные зоны периода передачи одного бита
Первая временная область (SYNC_SEG) служит для синхронизации работы различных узлов сети. Область PROP_SEG предназначена для компенсации временных задержек в сети и равна сумме времени распространения сигнала по каналу и задержки во входных компараторах. PHASE_SEG1 и PHASE_SEG2 служат для компенсации фазовых ошибок и могут увеличиваться или уменьшаться после синхронизации. T0 - минимальный квант времени, используемый для формирования временной шкалы в пределах периода передачи одного бита (длительность внутреннего такта может быть значительно короче). Момент стробирования определяет момент времени, когда проверяется состояние канала. Этот момент должен быть синхронным для всех узлов сети. Длительность этих временных областей может задаваться программно. Чем длиннее канал, тем меньшую скорость передачи информации он может обеспечить (см. табл. 3.3.4.2).
Таблица 4.1.4.2 Зависимость пропускной способности канала от его длины
| Длина канала в метрах | Пропускная способность сети в Кбит/с |
| 100 | 500 |
| 200 | 250 |
| 500 | 125 |
| 6000 | 10 |
Символьный набор HTML
10.19 Символьный набор HTML
Семенов Ю.А. (ГНЦ ИТЭФ)
Символьный набор документов HTML, заданный "SGML Declaration for HTML". Этот набор базируется на документе [ISO-8859-1].Кодовое представление
Символ
Описание
� - 
Не используется
	
Символ горизонтальной табуляции


Перевод строки
Возврат каретки
 - 
Не используется
 
Пробел
!
!
Восклицательный знак
"
"
Кавычки
#
Знак числа ()
$
$
Знак доллара
%
%
Знак процента
&
&
Ampersand
'
'
Апостроф
(
(
Левая скобка
)
)
Правая скобка
*
*
Звездочка
+
+
Знак плюс
,
,
запятая
-
-
Дефис
.
.
Точка (полная остановка)
/
/
Косая черта (slash)
0 - 9
0-9
Цифры 0-9
:
:
Двоеточие
;
;
Точка с запятой
<
<
Знак меньше чем
=
=
Знак равенства
>
>
Знак больше чем
?
?
Знак вопроса
@
@
Символ @
A - Z
A-Z
Буквы A-Z
[
[
Левая квадратная скобка
\
\
Обратная косая черта (backslash)
]
]
Правая квадратная скобка
^
^
Знак вставки (^ caret)
_
_
Горизонтальная черта (underscore)
`
Ударение
a - z
a-z
Буквы a-z
{
{
Левая фигурная скобка
|
|
Вертикальная черта
}
}
Правая фигурная скобка
~
~
Тильда (~)
 - Ÿ
Не используется
 
Неразрывный пробел
¡
?
Инвертированный восклицательный знак
¢
?
Знак центов
£
?
Знак фунтов стерлингов
¤
¤
Обобщенный знак валюты
¥
?
Знак иены
¦
¦
Разорванный знак вертикальной черты
§
§
Знак раздела (Section sign)
¨
?
Умляут (горизонтальное двоеточие над буквой)
©
©
Знак авторского права (Copyright)
ª
?
Feminine ordinal
«
«
Левая угловая кавычка (guillemotleft)
¬
¬
Знак отрицания (Not sign)
­
Мягкий дефис (Soft hyphen)
®
®
Зарегистрированная торговая марка
¯
?
Macron accent
°
°
Знак градуса (Degree sign)
±
±
Знак плюс или минус (± )
²
?
Верхний индекс 2 (Superscript two)
³
?
Верхний индекс 3 (Superscript three)
´
?
Знак ударения (Acute accent)
µ
µ
Знак долготы над гласным (горизонтальная черта - Micro sign)
¶
¶
Знак параграфа
·
·
Центральная точка
¸
?
Орфографический знак седиль (Cedilla)
¹
?
Верхний индекс 1 (Superscript one)
º
?
Masculine ordinal
»
»
Правая угловая кавычка (guillemotright)
¼
?
Дробь ј
½
?
Дробь 1/2
¾
?
Дробь ѕ
¿
?
Инвертированный знак вопроса
À
A
Прописное A, grave accent
Á
A
Прописное A, acute accent
Â
A
Прописное A, circumflex accent
Ã
A
Прописное A, tilde
Ä
A
Прописное A, dieresis or umlaut mark
Å
A
Прописное A, ring
Æ
?
Прописное AE dipthong (ligature)
Ç
C
Прописное C, cedilla
È
E
Прописное E, grave accent
É
E
Прописное E, acute accent
Ê
E
Прописное E, circumflex accent
Ë
E
Прописное E, dieresis or umlaut mark
Ì
I
Прописное I, grave accent
Í
I
Прописное I, acute accent
Î
I
Прописное I, circumflex accent
Ï
I
Прописное I, dieresis or umlaut mark
Ð
?
Прописное Eth, исландское
Ñ
N
Прописное N, tilde
Ò
O
Прописное O, grave accent
Ó
O
Прописное O, acute accent
Ô
O
Прописное O, circumflex accent
Õ
O
Прописное O, tilde
Ö
O
Прописное O, dieresis or umlaut mark
×
?
Знак умножения
Ø
O
Прописное O, slash
Ù
U
Прописное U, grave accent
Ú
U
Прописное U, acute accent
Û
U
Прописное U, circumflex accent
Ü
U
Прописное U, dieresis or umlaut mark
Ý
Y
Прописное Y, acute accent
Þ
?
Прописное THORN, Icelandic
ß
?
Строчное sharp s, German (sz ligature)
à
a
Строчное a, grave accent
á
a
Строчное a, acute accent
â
a
Строчное a, circumflex accent
ã
a
Строчное a, tilde
ä
a
Строчное a, dieresis or umlaut mark
å
a
Строчное a, ring
æ
?
Строчный дифтонг ae (ligature)
ç
c
Строчное c, cedilla
è
e
Строчное e, grave accent
é
e
Строчное e, acute accent
ê
e
Строчное e, circumflex accent
ë
e
Строчное e, dieresis or umlaut mark
ì
i
Строчное i, grave accent
í
i
Строчное i, acute accent
î
i
Строчное i, circumflex accent
ï
i
Строчное i, dieresis or umlaut mark
ð
?
Строчное eth, Icelandic
ñ
n
Строчное n, tilde
ò
o
Строчное o, grave accent
ó
o
Строчное o, acute accent
ô
o
Строчное o, circumflex accent
õ
o
Строчное o, tilde
ö
o
Строчное o, dieresis or umlaut mark
÷
?
Строчное ion sign
ø
o
Строчное o, slash
ù
u
Строчное u, grave accent
ú
u
Строчное u, acute accent
û
u
Строчное u, circumflex accent
ü
u
Строчное u, dieresis or umlaut mark
ý
y
Строчное y, acute accent
þ
?
Строчное thorn, исландское
ÿ
y
Строчное y с умляутом (dieresis or umlaut mark)
<!-- Набор символьных объектов. Типичное обращение:
<!ENTITY % HTMLlat1 PUBLIC "-//W3C//ENTITIES Latin 1//EN//HTML">
%HTMLlat1; -->
| Описание | Название символа | Уникод | Название набора |
| <!ENTITY nbsp CDATA " " > | Неразрывный пробел | U+00A0 | ISOnum |
| <!ENTITY iexcl CDATA "¡" > | Инвертированный ! | U+00A1 | ISOnum |
| <!ENTITY cent CDATA "¢" > | Знак цента | U+00A2 | ISOnum |
| <!ENTITY pound CDATA "£" > | Знак фунта | U+00A3 | ISOnum |
| <!ENTITY curren CDATA "¤" > | Знак валюты | U+00A4 | ISOnum |
| <!ENTITY yen CDATA "¥" > | Знак иены | U+00A5 | ISOnum |
| <!ENTITY brvbar CDATA "¦" > | Разорванная вертикальная черта | U+00A6 | ISOnum |
| <!ENTITY sect CDATA "§" > | Знак секции | U+00A7 | ISOnum |
| <!ENTITY uml CDATA "¨" > | Диэреза = двоеточие над гласной | U+00A8 | ISOdia |
| <!ENTITY copy CDATA "©" > | Знак авторского права | U+00A9 | ISOnum |
| <!ENTITY ordf CDATA "ª" > | Указатель женского начала | U+00AA | ISOnum |
| <!ENTITY laquo CDATA "«" > | Левая двойная угловая кавычка | U+00AB | ISOnum |
| <!ENTITY not CDATA “¬” > | Знак отрицания | U+00AC | ISOnum |
| <!ENTITY shy CDATA “­” > | Мягкий дефис | U+00AD | ISOnum |
| <!ENTITY reg CDATA “®”> | Знак зарегистрированной торговой марки | U+00AE | ISOnum |
| <!ENTITY macr CDATA “¯” > | Знак долготы над гласным = черта над | U+00AF | ISOdia |
| <!ENTITY deg CDATA “°” > | Знак градуса | U+00B0 | ISOnum |
| <!ENTITY plusmn CDATA “±” > | Знак плюс-минус | U+00B1 | ISOnum |
| <!ENTITY sup2 CDATA “²” > | 2 в верхнем индексе = знак квадрата | U+00B2 | ISOnum |
| <!ENTITY sup3 CDATA “³” > | 3 в верхнем индексе = знак куба | U+00B3 | ISOnum |
| <!ENTITY acute CDATA “´” > | Резкое ударение | U+00B4 | ISOdia |
| <!ENTITY micro CDATA “µ” > | Знак микро | U+00B5 | ISOnum |
| <!ENTITY a CDATA “¶” > | Знак параграфа | U+00B6 | ISOnum |
| <!ENTITY middot CDATA “·” > | Центральная точка | U+00B7 | ISOnum |
| <!ENTITY cedil CDATA “¸” > | Седиль | U+00B8 | ISOdia |
| <!ENTITY sup1 CDATA “¹” > | 1 в верхнем индексе | U+00B9 | ISOnum |
| <!ENTITY ordm CDATA “º” > | Индикатор мужского начала | U+00BA | ISOnum |
| <!ENTITY raquo CDATA “»” > | Правая двойная угловая кавычка | U+00BB | ISOnum |
| <!ENTITY frac14 CDATA “¼” > | Символ 1/4 | U+00BC | ISOnum |
| <!ENTITY frac12 CDATA “½” > | Символ 1/2 | U+00BD | ISOnum |
| <!ENTITY frac34 CDATA “¾” > | Символ 3/4 | U+00BE | ISOnum |
| <!ENTITY iquest CDATA “¿”” > | Перевернутый знак вопроса | U+00BF | ISOnum |
| <!ENTITY Agrave CDATA “À” > | Латинская прописная буква A с глухим ударением | U+00C0 | ISOlat1 |
| <!ENTITY Aacute CDATA “Á” > | Латинская прописная буква A с ударением | U+00C1 | ISOlat1 |
| <!ENTITY Acirc CDATA “” > | Латинская прописная буква A центральным ударением | U+00C2 | ISOlat1 |
| <!ENTITY Atilde CDATA “Ô > | Латинская прописная буква A с тильдой | U+00C3 | ISOlat1 |
| <!ENTITY Auml CDATA “Ä” > | Латинская прописная буква A с умляутом, (диэрезой) | U+00C4 | ISOlat1 |
| <!ENTITY Aring CDATA “Å” > | Латинская прописная буква A с кружочком сверху | U+00C5 | ISOlat1 |
| <!ENTITY Aelig CDATA “Æ” > | Латинская прописная буква AE | U+00C6 | ISOlat1 |
| <!ENTITY Ccedil CDATA “Ç” > | Латинская прописная буква C с седилью | U+00C7 | ISOlat1 |
| <!ENTITY Egrave CDATA “È” > | Латинская прописная буква E с глухим ударением | U+00C8 | ISOlat1 |
| <!ENTITY Eacute CDATA “É” > | Латинская прописная буква E с ударением | U+00C9 | ISOlat1 |
| <!ENTITY Ecirc CDATA “Ê” | Латинская прописная буква E с циркумфлексом | U+00CA | ISOlat1 |
| <!ENTITY Euml CDATA “Ë” > | Латинская прописная буква E с диэрезой | U+00CB | ISOlat1 |
| <!ENTITY Igrave CDATA “Ì” > | Латинская прописная буква I с глухим ударением | U+00CC | ISOlat1 |
| <!ENTITY Iacute CDATA “Í” > | Латинская прописная буква I с ударением | U+00CD | ISOlat1 |
| <!ENTITY Icirc CDATA “Δ > | Латинская прописная буква I с циркумфлексом сверху | U+00CE | ISOlat1 |
| <!ENTITY Iuml CDATA “Ï” > | Латинская прописная буква I с диэрезой (умляутом) | U+00CF | ISOlat1 |
| <!ENTITY ETH CDATA “Д > | Латинская прописная буква ETH | U+00D0 | ISOlat1 |
| <!ENTITY Ntilde CDATA “Ñ” > | Латинская прописная буква N с тильдой | U+00D1 | ISOlat1 |
| <!ENTITY Ograve CDATA “Ò” > | Латинская прописная буква O с тупым ударением | U+00D2 | ISOlat1 |
| <!ENTITY Oacute CDATA “Ó” > | Латинская прописная буква O с ударением | U+00D3 | ISOlat1 |
| <!ENTITY Ocirc CDATA “Ô” > | Латинская прописная буква O с кружочком сверху | U+00D4 | ISOlat1 |
| <!ENTITY Otilde CDATA “Õ” > | Латинская прописная буква O с тильдой | U+00D5 | ISOlat1 |
| <!ENTITY Ouml CDATA “Ö” > | Латинская прописная буква O с диэрезой (умляутом) | U+00D6 | ISOlat1 |
| <!ENTITY times CDATA “×” > | Знак умножения | U+00D7 | ISOnum |
| <!ENTITY Oslash CDATA “Ø” > | Латинская прописная буква O с косой чертой | U+00D8 | ISOlat1 |
| <!ENTITY Ugrave CDATA “Ù” > | Латинская прописная буква U с глухим ударением | U+00D9 | ISOlat1 |
| <!ENTITY Uacute CDATA “Ú” > | Латинская прописная буква U с ударением | U+00DA | ISOlat1 |
| <!ENTITY Ucirc CDATA “Û” > | Латинская прописная буква U с циркумфлексом сверху | U+00DB | ISOlat1 |
| <!ENTITY Uuml CDATA “Ü” > | Латинская прописная буква U с тремой (умляутом) | U+00DC | ISOlat1 |
| <!ENTITY Yacute CDATA “Ý” > | Латинская прописная буква Y с ударением | U+00DD | ISOlat1 |
| <!ENTITY THORN CDATA “Þ” > | Латинская прописная буква THORN | U+00DE | ISOlat1 |
| <!ENTITY szlig CDATA “ß” > | Латинская строчная буква sharp s = ess-zed | U+00DF | ISOlat1 |
| <!ENTITY agrave CDATA “à” > | Латинская строчная буква a с глухим ударением | U+00E0 | ISOlat1 |
| <!ENTITY aacute CDATA “á” > | Латинская строчная буква a с ударением | U+00E1 | ISOlat1 |
| <!ENTITY acirc CDATA "â"> | Латинская строчная буква a с кружочком сверху | U+00E2 | ISOlat1 |
| <!ENTITY atilde CDATA "ã"> | Латинская строчная буква a с тильдой | U+00E3 | ISOlat1 |
| <!ENTITY auml CDATA "ä"> | Латинская строчная буква a с тремой (умляутом) | U+00E4 | ISOlat1 |
| <!ENTITY aring CDATA "å"> | Латинская строчная буква a с кружочком сверху | U+00E5 | ISOlat1 |
| <!ENTITY aelig CDATA "æ"> | Латинская строчная буква ae = латинская строчная лигатура ae | U+00E6 | ISOlat1 |
| <!ENTITY ccedil CDATA "ç"> | Латинская строчная буква c с седилью | U+00E7 | ISOlat1 |
| <!ENTITY egrave CDATA "è"> | Латинская строчная буква e с глухим ударением | U+00E8 | ISOlat1 |
| <!ENTITY eacute CDATA "é"> | Латинская строчная буква e с ударением | U+00E9 | ISOlat1 |
| <!ENTITY ecirc CDATA "ê"> | Латинская строчная буква e с циркумфлексом сверху | U+00EA | ISOlat1 |
| <!ENTITY euml CDATA "ë"> | Латинская строчная буква e с тремой (умляутом) | U+00EB | ISOlat1 |
| <!ENTITY igrave CDATA "ì"> | Латинская строчная буква i с глухим ударением | U+00EC | ISOlat1 |
| <!ENTITY iacute CDATA "í"> | Латинская строчная буква i с ударением | U+00ED | ISOlat1 |
| <!ENTITY icirc CDATA "î"> | Латинская строчная буква i с циркумфлексом сверху | U+00EE | ISOlat1 |
| <!ENTITY iuml CDATA "ï"> | Латинская строчная буква i с тремой (умляутом) | U+00EF | ISOlat1 |
| <!ENTITY eth CDATA "ð"> | Латинская строчная буква eth | U+00F0 | ISOlat1 |
| <!ENTITY ntilde CDATA "ñ"> | Латинская строчная буква n с тильдой | U+00F1 | ISOlat1 |
| <!ENTITY ograve CDATA "ò"> | Латинская строчная буква o с глухим ударением | U+00F2 | ISOlat1 |
| <!ENTITY oacute CDATA "ó"> | Латинская строчная буква o с ударением | U+00F3 | ISOlat1 |
| <!ENTITY ocirc CDATA "ô"> | Латинская строчная буква o с циркумфлексом сверху | U+00F4 | ISOlat1 |
| <!ENTITY otilde CDATA "õ"> | Латинская строчная буква o с тильдой | U+00F5 | ISOlat1 |
| <!ENTITY ouml CDATA "ö"> | Латинская строчная буква o с тремой (умляутом) | U+00F6 | ISOlat1 |
| <!ENTITY divide CDATA "÷"> | Знак деления | U+00F7 | ISOnum |
| <!ENTITY oslash CDATA "ø"> | Латинская строчная буква o с косой чертой | U+00F8 | ISOlat1 |
| <!ENTITY ugrave CDATA "ù"> | Латинская строчная буква u с глухим ударением | U+00F9 | ISOlat1 |
| <!ENTITY uacute CDATA "ú"> | Латинская строчная буква u с ударением | U+00FA | ISOlat1 |
| <!ENTITY ucirc CDATA "û"> | Латинская строчная буква u с циркумфлексом сверху | U+00FB | ISOlat1 |
| <!ENTITY uuml CDATA "ü"> | Латинская строчная буква u с тремой (умляутом) | U+00FC | ISOlat1 |
| <!ENTITY yacute CDATA "ý"> | Латинская строчная буква y с ударением | U+00FD | ISOlat1 |
| <!ENTITY thorn CDATA "þ"> | Латинская строчная буква thorn | U+00FE | ISOlat1 |
| <!ENTITY yuml CDATA "ÿ"> | Латинская строчная буква y с тремой (умляутом) | U+00FF | ISOlat1 |
/p>
Эталонные символьные объекты для символов, математических символов и греческих букв
Эталонные символьные объекты в этом разделе производят символы, которые могут быть представлены глифами из широко известного шрифта Adobe Symbol, включая греческие буквы, различные скобки, а также секцией математических операторов (+ . - и т.д.).
Чтобы поддержать эти объекты агенты пользователя могут поддерживать целиком ISO10646 или использовать другие средства. Отображение глифов для этих символов может быть реализовано через отображение соответствующих символов ISO10646 или другими способами, такими как установление внутреннего соответствия перечисленных объектов, коды символов и порядковые номера символов в заданном шрифтовом наборе.
Использование греческих символов. Этот символьный набор содержит все буквы, используемые в современном греческом алфавите. Однако, он не включает в себя греческую пунктуацию, символы со знаками ударения или безпробельные акценты (tonos, dialytika), необходимые для их формирования. Здесь нет архаичных букв, уникальных коптских букв или комбинированных букв политонического греческого языка. Определенные здесь объекты предназначены не для представления современного греческого текста, а для применения в технических математических текстах.
Список символов
<!-- Математические, греческие и другие символы HTML -->
<!-- Character entity set. Typical invocation:
<!ENTITY % HTMLsymbol PUBLIC
"-//W3C//ENTITIES Symbols//EN//HTML">
%HTMLsymbol; -->
<!-- Ниже приводится набор соответствующих объектов ISO, если не введены новые имена. Новые имена (напр., не из списка ISO 8879) не противоречат другим существующим именам объектов ISO 8879. Коды символов ISO 10646 даны для каждого символа в шестнадцатеричной нотации. Значения CDATA приведены в десятичном виде ISO 10646 и относятся к символьному набору документа. Имена соответствуют Unicode 2.0. -->
| Греческие символы (ISOgrk3) | ||
| Определение | Название символа | Уникод |
| <!ENTITY Alpha CDATA "Α"> | Греческая прописная альфа (A) | U+0391 |
| <!ENTITY Beta CDATA "Β"> | Греческая прописная бета (B) | U+0392 |
| <!ENTITY Gamma CDATA "Γ"> | Греческая прописная гамма (G) | U+0393 |
| <!ENTITY Delta CDATA "Δ"> | Греческая прописная дельта (D) | U+0394 |
| <!ENTITY Epsilon CDATA "Ε"> | Греческая прописная эпсилон (E) | U+0395 |
| <!ENTITY Zeta CDATA "Ζ"> | Греческая прописная зета (Z) | U+0396 |
| <!ENTITY Eta CDATA "Η"> | Греческая прописная эта (H) | U+0397 |
| <!ENTITY Theta CDATA "Θ"> | Греческая прописная тэта (Q) | U+0398 |
| <!ENTITY Iota CDATA "Ι"> | Греческая прописная иота (I) | U+0399 |
| <!ENTITY Kappa CDATA "Κ"> | Греческая прописная каппа (K) | U+039A |
| <!ENTITY Lambda CDATA "Λ"> | Греческая прописная лямбда (L) | U+039B |
| <!ENTITY Mu CDATA "Μ"> | Греческая прописная мю (M) | U+039C |
| <!ENTITY Nu CDATA "Ν"> | Греческая прописная ню (N) | U+039D |
| <!ENTITY Xi CDATA "Ξ"> | Греческая прописная кси (X) | U+039E |
| <!ENTITY Omicron CDATA "Ο"> | Греческая прописная омикрон (O) | U+039F |
| <!ENTITY Pi CDATA "Π"> | Греческая прописная пи (P) | U+03A0 |
| <!ENTITY Rho CDATA "Ρ"> | Греческая прописная ро (R) | U+03A1 |
| <!ENTITY Sigma CDATA "Σ">*) | Греческая прописная сигма (S) | U+03A3 |
| <!ENTITY Tau CDATA "Τ"> | Греческая прописная тау (T) | U+03A4 |
| <!ENTITY Upsilon CDATA "Υ"> | Греческая прописная ипсилон (U) | U+03A5 |
| <!ENTITY Phi CDATA "Φ"> | Греческая прописная фи (F) | U+03A6 |
| <!ENTITY Chi CDATA "Χ"> | Греческая прописная хи (C) | U+03A7 |
| <!ENTITY Psi CDATA "Ψ"> | Греческая прописная пси (Y) | U+03A8 |
| <!ENTITY Omega CDATA "Ω"> | Греческая прописная омега (W) | U+03A9 |
| <!ENTITY alpha CDATA "α"> | Греческая строчная альфа (a) | U+03B1 |
| <!ENTITY beta CDATA "β"> | Греческая строчная бета (b) | U+03B2 |
| <!ENTITY gamma CDATA "γ"> | Греческая строчная гамма (g) | U+03B3 |
| <!ENTITY delta CDATA "δ"> | Греческая строчная дельта (d) | U+03B4 |
| <!ENTITY epsilon CDATA "ε"> | Греческая строчная эпислон (e) | U+03B5 |
| <!ENTITY zeta CDATA "ζ"> | Греческая строчная зета (z) | U+03B6 |
| <!ENTITY eta CDATA "η"> | Греческая строчная эта (h) | U+03B7 |
| <!ENTITY theta CDATA "θ"> | Греческая строчная тета (q) | U+03B8 |
| <!ENTITY iota CDATA "ι"> | Греческая строчная иота (i) | U+03B9 |
| <!ENTITY kappa CDATA "κ"> | Греческая строчная каппа (k) | U+03BA |
| <!ENTITY lambda CDATA "λ"> | Греческая строчная лямбда (l) | U+03BB |
| <!ENTITY mu CDATA "μ" | Греческая строчная мю (m) | U+03BC |
| <!ENTITY nu CDATA "ν"> | Греческая строчная ню (n) | U+03BD |
| <!ENTITY xi CDATA "ξ"> | Греческая строчная кси (x) | U+03BE |
| <!ENTITY omicron CDATA "ο"> | Греческий строчный омикрон (o) | U+03BF |
| <!ENTITY pi CDATA "π"> | Греческая строчная пи (p) | U+03C0 |
| <!ENTITY rho CDATA "ρ"> | Греческая строчная ро (r) | U+03C1 |
| <!ENTITY sigmaf CDATA "ς"> | Греческая строчная финальная сигма | U+03C2 |
| <!ENTITY sigma CDATA "σ"> | Греческая строчная сигма (s) | U+03C3 |
| <!ENTITY tau CDATA "τ"> | Греческая строчная тау | U+03C4 |
| <!ENTITY upsilon CDATA "υ"> | Греческий строчный ипсилон (u) | U+03C5 |
| <!ENTITY phi CDATA "φ"> | Греческая строчная фи (j) | U+03C6 |
| <!ENTITY chi CDATA "χ"> | Греческая строчная хи (c) | U+03C7 |
| <!ENTITY psi CDATA "ψ"> | Греческая строчная пси (y) | U+03C8 |
| <!ENTITY omega CDATA "ω"> | Греческая строчная омега (w) | U+03C9 |
| <!ENTITY thetasym CDATA "ϑ"> | Греческий тета символ | U+03D1 |
| <!ENTITY upsih CDATA "ϒ"> | Греческий ипсилон с крючком | U+03D2 |
| <!ENTITY piv CDATA "ϖ"> | Греческий символ пи | U+03D6 |
/p> *) Не существует Sigmaf, и нет также символа U+03A2
Общая пунктуация |
|||
| Определение | Название символа | Уникод | Название набора |
| <!ENTITY ensp CDATA " "> | en пробел | U+2002 | ISOpub |
| <!ENTITY emsp CDATA " "> | em пробел | U+2003 | ISOpub |
| <!ENTITY thinsp CDATA " "> | Узкий пробел | U+2009 | ISOpub |
| <!ENTITY zwnj CDATA "‌"> | Разрываемый соединитель нулевой ширины | U+200C | NEW RFC 2070 |
| <!ENTITY zwj CDATA "‍"> | Соединитель нулевой ширины | U+200D | NEW RFC 2070 |
| <!ENTITY lrm CDATA "‎"> | Знак слево-направо | U+200E | NEW RFC 2070 |
| <!ENTITY rlm CDATA "‏"> | Знак справа-налево | U+200F | NEW RFC 2070 |
| <!ENTITY ndash CDATA "–"> | en дефис | U+2013 | ISOpub |
| <!ENTITY mdash CDATA "—"> | em дефис | U+2014 | ISOpub |
| <!ENTITY lsquo CDATA "‘"> | Левая кавычка | U+2018 | ISOnum |
| <!ENTITY rsquo CDATA "’"> | Правая кавычка | U+2019 | ISOnum |
| <!ENTITY sbquo CDATA "‚"> | Single low-9 quotation mark | U+201A | NEW |
| <!ENTITY ldquo CDATA "“"> | Левая двойная кавычка | U+201C | ISOnum |
| <!ENTITY rdquo CDATA "”"> | Правая двойная кавычка | U+201D | ISOnum |
| <!ENTITY bdquo CDATA "„"> | double low-9 quotation mark | U+201E | NEW |
| <!ENTITY dagger CDATA "†" | Кинжал † | U+2020 | ISOpub |
| <!ENTITY Dagger CDATA "‡"> | Двойной кинжал ‡ | U+2021 | ISOpub |
| <!ENTITY bull CDATA "•"> | Маленький черный кружочек (bullet) • **) | U+2022 | ISOpub |
| <!ENTITY hellip CDATA "…"> | Многоточие = трехточечный пунктир … | U+2026 | ISOpub |
| <!ENTITY permil CDATA "‰" | Знак промиль ‰ | U+2030 | ISOtech |
| <!ENTITY prime CDATA "′"> | Прайм = минуты = фут | U+2032 | ISOtech |
| <!ENTITY Prime CDATA "″"> | Дубль прайм = секунды = дюймы | U+2033 | ISOtech |
| <!ENTITY lsaquo CDATA "‹"> | Одиночная, угловая левая кавычка | U+2039 | Предложено ISO |
| <!ENTITY rsaquo CDATA "›"> | Одиночная, угловая правая кавычка | U+203A | Предложено ISO |
| <!ENTITY oline CDATA "‾"> | Верхняя черта | U+203E | NEW |
| <!ENTITY frasl CDATA "⁄"> | Косая черта дроби | U+2044 | NEW |
| <!ENTITY euro CDATA "€"> | Знак евро € | U+20AC | NEW |
/p> **) bullet не тождественен оператору bullet, U+2219
Буквоподобные символы |
|||
| Определение | Название символа | Уникод | Название набора |
| <!ENTITY weierp CDATA "℘"> | Прописная письменная P | U+2118 | ISOamso |
| <!ENTITY image CDATA "ℑ"> | Прописная жирная буква I = мнимая часть | U+2111 | ISOamso |
| <!ENTITY real CDATA "ℜ"> | Прописная жирная буква R = символ действительной части | U+211C | ISOamso |
| <!ENTITY trade CDATA "™"> | Символ торговой марки | U+2122 | ISOnum |
| <!ENTITY alefsym CDATA "ℵ"> | Символ alef ***) | U+2135 | NEW |
Стрелки |
|||
| Определение | Название символа | Уникод | Название набора |
| <!ENTITY larr CDATA "←"> | Стрелка влево | U+2190 | ISOnum |
| <!ENTITY uarr CDATA "↑"> | Стрелка вверх | U+2191 | ISOnum |
| <!ENTITY rarr CDATA "→"> | Стрелка вправо | U+2192 | ISOnum |
| <!ENTITY darr CDATA "↓"> | Стрелка вниз | U+2193 | ISOnum |
| <!ENTITY harr CDATA "↔"> | Двухсторонняя горизонтальная стрелка | U+2194 | ISOamsa |
| <!ENTITY crarr CDATA "↵"> | Стрелка вниз с поворотом налево = возврат каретки | U+21B5 | NEW |
| <!ENTITY lArr CDATA "⇐"> | Двойная стрелка влево +) | U+21D0 | ISOtech |
| <!ENTITY uArr CDATA "⇑"> | Двойная стрелка вверх | U+21D1 | ISOamsa |
| <!ENTITY rArr CDATA "⇒"> | Двойная стрелка вправо ++) | U+21D2 | ISOtech |
| <!ENTITY dArr CDATA "⇓"> | Двойная стрелка вниз | U+21D3 | ISOamsa |
| <!ENTITY hArr CDATA "⇔"> | Двойная двухсторонняя стрелка | U+21D4 | ISOamsa |
++) Уникод не утверждает, что это 'implies' символ, но не имеет другого символа для этих целей, таким образом, ? rArr может использоваться для 'implies' как это рекомендует ISOtech
Математические операторы |
|||
| Определение | Название символа | Уникод | Название набора |
| <!ENTITY forall CDATA "∀"> | Для всех ? | U+2200 | ISOtech |
| <!ENTITY part CDATA "∂"> | Частный дифференциал ? | U+2202 | ISOtech |
| <!ENTITY exist CDATA "∃"> | Существует ? | U+2203 | ISOtech |
| <!ENTITY empty CDATA "∅"> | Пустой набор = диаметр ? | U+2205 | ISOamso |
| <!ENTITY nabla CDATA "∇"> | Набла = обратная разница | U+2207 | ISOtech |
| <!ENTITY isin CDATA "∈"> | Элемент чего-то ? | U+2208 | ISOtech |
| <!ENTITY notin CDATA "∉"> | Не элемент чего-то ? | U+2209 | ISOtech |
| <!ENTITY ni CDATA "∋"> | Содержит, как член ? | U+220B | ISOtech |
| <!ENTITY prod CDATA "∏"> | n-кратное произведение= знак произведения ?#) | U+220F | ISOamsb |
| <!ENTITY sum CDATA "∑"> | n-кратная сумма ?##) | U+2211 | ISOamsb |
| <!ENTITY minus CDATA "−"> | Знак минус ? | U+2212 | ISOtech |
| <!ENTITY lowast CDATA "∗"> | Оператор звездочка ? | U+2217 | ISOtech |
| <!ENTITY radic CDATA "√"> | Квадратный корень = знак радикала v | U+221A | ISOtech |
| <!ENTITY prop CDATA "∝"> | пропорционально ? | U+221D | ISOtech |
| <!ENTITY infin CDATA "∞"> | Бесконечность (Ґ ) | U+221E | ISOtech |
| <!ENTITY ang CDATA "∠"> | Угол (Р ) | U+2220 | ISOamso |
| <!ENTITY and CDATA "∧"> | Логическое И =призма ? | U+2227 | ISOtech |
| <!ENTITY or CDATA "∨"> | Логическое ИЛИ ? | U+2228 | ISOtech |
| <!ENTITY cap CDATA "∩"> | Пересечение ? | U+2229 | ISOtech |
| <!ENTITY cup CDATA "∪"> | Объединение ? | U+222A | ISOtech |
| <!ENTITY int CDATA "∫"> | Интеграл ? | U+222B | ISOtech |
| !ENTITY there4 CDATA "∴"> | Следовательно ? | U+2234 | ISOtech |
| <!ENTITY sim CDATA "∼"> | Оператор тильда = изменяется с = подобно тому ###) | U+223C | ISOtech |
| <!ENTITY cong CDATA "≅"> | Приблизительно равно ? | U+2245 | ISOtech |
| <!ENTITY asymp CDATA "≈"> | Почти равно= асимптотическое приближение к ? | U+2248 | ISOamsr |
| <!ENTITY ne CDATA "≠"> | Не равно (№ ) | U+2260 | ISOtech |
| <!ENTITY equiv CDATA "≡"> | Идентично = тождественно равно (є ) | U+2261 | ISOtech |
| <!ENTITY le CDATA "≤"> | Меньше или равно (Ј ) | U+2264 | ISOtech |
| <!ENTITY ge CDATA "≥"> | Больше или равно ? | U+2265 | ISOtech |
| <!ENTITY sub CDATA "⊂"> | Входит в ? | U+2282 | ISOtech |
| <!ENTITY sup CDATA "⊃"> | Включает в себя L | U+2283 | ISOtech |
| <!ENTITY nsub CDATA "⊄"> | Не является субнабором чего-то ? | U+2284 | ISOamsn |
| <!ENTITY sube CDATA "⊆"> | Входит в или тождественен ? | U+2286 | ISOtech |
| <!ENTITY supe CDATA "⊇"> | Включает в себя или тождественен ? | U+2287 | ISOtech |
| <!ENTITY oplus CDATA "⊕"> | Плюс в кружочке = direct sum (Е ) | U+2295 | ISOamsb |
| <!ENTITY otimes CDATA "⊗"> | Векторное произведение = знак умножения в кружочке (Д ) | U+2297 | ISOamsb |
| <!ENTITY perp CDATA "⊥"> | Ортогонально = перпендикулярно (^ ) | U+22A5 | ISOtech |
| <!ENTITY sdot CDATA "⋅"> | Оператор точка ####) | U+22C5 | ISOamsb |
/p> #) prod не тождественен символу U+03A0 ' греческая прописная буква pi' хотя один и тот же глиф может быть использован для отображения обоих
##) sum не тождественен символу U+03A3 'греческая прописная буква сигма’ хотя один и тот же глиф может быть использован для отображения обоих
###) tilde оператор не тождественен символу U+007E, хотя один и тот же глиф может быть использован для отображения обоих
####) Оператор dot не тождественен символу U+00B7 центральная точка
Различные технические символы |
|||
| Определение | Название символа | Уникод | Название набора |
| <!ENTITY lceil CDATA "⌈"> | left ceiling = apl upstile | U+2308 | ISOamsc |
| <!ENTITY rceil CDATA "⌉"> | right ceiling (` ) | U+2309 | ISOamsc |
| <!ENTITY lfloor CDATA "⌊"> | left floor = apl downstile | U+230A | ISOamsc |
| <!ENTITY rfloor CDATA "⌋"> | right floor | U+230B | ISOamsc |
| <!ENTITY lang CDATA "〈"> | левая угловая скобка | U+2329 | ISOtech |
| <!ENTITY rang CDATA "〉"> | правая угловая скобка= закрывающая скобка | U+232A | ISOtech |
Геометрические формы |
|||
| Определение | Название символа | Уникод | Название набора |
| <!ENTITY loz CDATA "◊"> | ромб (а ) | U+25CA | ISOpub |
Различные символы |
|||
| Определение | Название символа | Уникод | Название набора |
| <!ENTITY spades CDATA "♠"> | черные пики (Є ) | U+2660 | ISOpub |
| <!ENTITY clubs CDATA "♣"> | черные крести=лист кислицы (§ ) | U+2663 | ISOpub |
| <!ENTITY hearts CDATA "♥"> | черные черви (© ) | U+2665 | ISOpub |
| <!ENTITY diams CDATA "♦"> | черные бубни (Ё ) | U+2666 | ISOpub |
Эталонные символьные объекты для символов разметки текста и интернационализации
Эталонные символьные объекты в этой секции предназначены для символов разметки текста (markup) (они те же, что и в HTML 2.0 и 3.2), для обозначения пробелов и дефисов. Остальные символы в этой секции используются для интернационализации.
Добавлены некоторые символы из CP-1252, которые не встречаются в наборах HTMLlat1 или HTMLsymbol. Все они из диапазона 128 - 159 символьного набора cp-1252. Эти объекты позволяют обозначать символы независимо от платформы.
Для поддержки этих объектов агенты пользователя могут поддерживать полный набор ISO10646 или использовать другие средства. Отображение глифов этих символов может быть реализовано, если возможно отображение символов ISO10646 или другими средствами.
Список символов
<!-- Набор символьных объектов:
<!ENTITY % HTMLspecial PUBLIC "-//W3C//ENTITIES Special//EN//HTML">
%HTMLspecial; -->
<!-- Используется набор объектов ISO, если не введены новые имена. Новые имена (напр., не из списка ISO 8879) не будут конфликтовать с любыми существующими именами объектов ISO 8879. Коды символов ISO 10646 приводятся для всех символов в шестнадцатеричном виде. Значения CDATA представляют собой десятичные коды ISO 10646. Имена соответствуют именам Unicode 2.0. -->
Специальные символы HTML. Контроли C0 и базовый латинский |
|||
| Определение | Название символа | Уникод | Название набора |
| <!ENTITY quot CDATA """> | Кавычка = APL quote | U+0022 | ISOnum |
| <!ENTITY amp CDATA "&"> | Знак & | U+0026 | ISOnum |
| <!ENTITY lt CDATA "<"> | Знак меньше чем | U+003C | ISOnum |
| <!ENTITY gt CDATA ">"> | Знак больше чем | U+003E | ISOnum |
Латинские буквы, расширение А |
|||
| Определение | Название символа | Уникод | Название набора |
| <!ENTITY OElig CDATA "Œ"> | Латинская прописная лигатура OE | U+0152 | ISOlat2 |
| <!ENTITY oelig CDATA "œ"> | Латинская строчная лигатура oe | U+0153 | ISOlat2 |
| <!ENTITY Scaron CDATA "Š"> | Латинская прописная буква S с короной | U+0160 | ISOlat2 |
| <!ENTITY scaron CDATA "š"> | Латинская строчная буква s с короной | U+0161 | ISOlat2 |
| <!ENTITY Yuml CDATA "Ÿ"> | Латинская прописная буква Y с тремой (умляутом) | U+0178 | ISOlat2 |
Латинские буквы, расширение B |
|||
| Определение | Название символа | Уникод | Название стандарта |
| <!ENTITY fnof CDATA "ƒ" --> | Латинская строчная буква f с крючком = флорин | U+0192 | ISOtech |
Модификаторы букв |
|||
| Определение | Название символа | Уникод | Название стандарта |
| <!ENTITY circ CDATA "ˆ"> | Модификатор буквы – облегченное ударение | U+02C6 | ISOpub |
| <!ENTITY tilde CDATA "˜"> | Малая тильда | U+02DC | ISOdia |
Синхронные каналы SDH/SONET
4.3.6 Синхронные каналы SDH/SONET
Семенов Ю.А. (ГНЦ ИТЭФ)

Мультиплексирование потоков информации при формировании мощных региональных и межрегиональных каналов имеет два решения. Одно базируется на синхронном мультиплексировании и носит название синхронная цифровая иерархия (SDH, cм. Н.Н.Слепов, Синхронные цифровые сети SDH. ЭКО-ТРЕНДЗ, Москва, 1998), другое использует простой асинхронный пакетный обмен и носит название асинхронный режим передачи (ATM, см. предыдущую главу).
Стандарт SDH (synchronous digital hierarchy) разработан в Европе, (предназначен для замены иерархии асинхронных линий E-1/E-3) используется в настоящее время многими сетями и представляет собой модификацию американского стандарта на передачу данных по оптическим каналам связи SONET (synchronous optical network). Несмотря на свое название SONET не ограничивается исключительно оптическими каналами. Спецификация определяет требования для оптического одно- и мультимодового волокна, а также для 75-омного коаксиального кабеля CATV 75. Пропускная способность SONET начинается с 51,84 Мбит/с STS-1 (synchronous transport signal-1). Более высокие скорости передачи информации в sonet кратны этому значению. Стандартизованы следующие скорости передачи, которые кратны скорости 64 Кбит/с.
Соответствие каналов SONET и SDH приведено ниже[W. Simpson RFC-1619 “PPP over SONET/SDH”] (и тот и другой могут использоваться для организации связей по схеме PPP):
|
sonet |
sdh |
||
| STS-3c | STM-1 | ||
| STS-12c | STM-4 | ||
| STS-48c | STM-16 |
sonet (стандарт ANSI, предназначенный для замены NADH - north american digital hierarchy) использует улучшенную PDH - (plesiochronous digital hierarchy - plesios - близкий (греч.)) схему мультиплексирования каналов. В плезиохронной (почти синхронной) иерархии используется мультиплексирование с чередованием бит, а не байт. Мультиплексор формирует из N входных потоков один выходной (сети, где разные часы сфазированы с разными стандартами, но все они привязаны к одной базовой частоте называются плезиохронными). Так как скорости разных каналов могут не совпадать и нет структур, которые могли бы определить позиции битов для каждого из каналов, используется побитовая синхронизация. Здесь мультиплексор сам выравнивает скорости входных потоков путем введения (или изъятия) соответствующего числа бит. Информация о введенных и изъятых битах передается по служебным каналам. Помимо синхронизации на уровне мультиплексора происходит и формирование кадров и мультикадров. Так для канала Т2 (6312кбит/с) длина кадра равна 789 бит при частоте кадров 8 кГц. Мультикадр содержит 12 кадров. Помимо европейской и американской иерархии каналов существует также японская. Каждая из этих иерархий имеет несколько уровней. Сравнение этих иерархий представлено в таблице 4.3.6.1.
Таблица 4.3.6.1. Сравнение европейской и американской иерархии каналов
Скорости передачи для иерархий
Американская
1544 Кбит/c
Европейская
2048 Кбит/c
Японская
1544 Кбит/c
0
64 (DS0)
64
64
1
1544 (DS1)
2048 (Е1)
1544 (DS1)
2
6312 (DS2)
8448 (Е2)
6312 (DS2)
3
44736 (DS3)
34368 (Е3)
32064 (DSJ3)
4
274176 (Не входит в рекомендации МСЭ-Т)
139264 (Е4)
97728 (DSJ4)
Но добавление выравнивающих бит в PDH делает затруднительным идентификацию и вывод потоков 64 Кбит/с или 2 Мбит/с, замешанных в потоке 140 Мбит/с, без полного демультиплексирования и удаления выравнивающих бит. Если для цифровой телефонии PDH достаточно эффективна, то для передачи данных она оказалась недостаточно гибкой. Именно это обстоятельство определило преимущество систем SONET/SDH. Эти виды иерархических систем позволяют оперировать потоками без необходимости сборки/разборки. Структура кадров позволяет выполнять не только маршрутизацию, но и осуществлять управление сетями любой топологии. Здесь использован чисто синхронный принцип передачи и побайтовое, а не побитовое чередование при мультиплексировании. Первичной скоростью SONET выбрана 50688 Мбит/с (ОС1). Число уровней иерархии значительно расширено (до 48). Кратность уровней иерархии равна номеру уровня.
CCITT выработал следующие рекомендации на эту тему: G.707, G.708 и G.709. CCITT разработал рекомендации для высокоскоростных каналов H:
| H0 | 384 Кбит/с=4*64 Кбит/с. 3*h0=1,544 Мбит/с | |
| H1 | H11 | 1536 Кбит/с |
| H12 | 1920 Кбит/с | |
| h4 | ~135 Мбит/с | |
| H21 | ~34 Мбит/с | |
| H22 | ~55 Мбит/с. |
В SONET предусмотрено четыре варианта соединений: точка-точка, линейная цепочка (add-drop), простое кольцо и сцепленное кольцо (interlocking ring). Линейные варианты используются для ответвлений от основного кольца сети. Наиболее распространенная топология - самовосстанавливающееся кольцо (см. также FDDI). Такое кольцо состоит из ряда узлов, которые связаны между собой двухсторонними линиями связи, образующими кольцо и обеспечивающими передачу сообщений по и против часовой стрелки. Способность сетей SONET к самовосстановлению определяется не только топологией, но и средствами управления и контроля состояния. При повреждении трафик перенаправляется в обход, локально это приводит к возрастанию информационного потока, по этой причине для самовосстановления сеть должна иметь резерв пропускной способности (как минимум двойной). Но, проектируя сеть, нужно избегать схем, при которых основной и резервный маршрут проходят через одну и ту же точку, так как они могут быть, если не повезет, повреждены одновременно. Резервные пути могут использоваться для низкоприоритетных обменов, которые могут быть заблокированы при самовосстановлении.
Сети SONET (и SDH) имеют 4 архитектурных уровня:
Фотонный (photonic) - нижний уровень иерархии. Этот уровень определяет стандарты на форму и преобразование оптических сигналов, на электронно-оптические связи.
Секционный (section) - предназначен для управление передачей STS-кадров (sonet) между терминалами и повторителями. В его функции входит контроль ошибок.
Линейный (line) - служит для синхронизации и мультиплексирования, осуществляет связь между отдельными узлами сети и терминальным оборудованием, например линейными мультиплексорами, выполняет некоторые функции управления сетью.
Маршрутный (path) - описывает реальные сетевые услуги (T-1 или T-3), предоставляемые пользователю на участке от одного терминального оборудования до другого.
Существующие PDH-сети мультиплексируют каналы, используя каскадную схему, показанную на рис. 4.3.6.1.
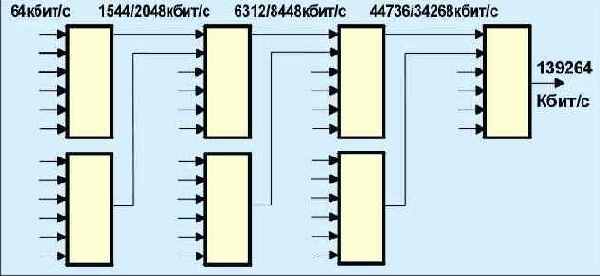
Рис. 4.3.6.1. pdh-мультиплесирование
SDH-иерархия распространяется до 2500 Мбит/с и может быть расширена вплоть до 13 Гбит/с (ограничение оптического кабеля). SDH предоставляет существенно улучшенную схему мультиплексирования каналов для быстродействующих интерфейсов с полосой 150 Мбит/с и выше:
обеспечивается единый стандарт для мультиплексирования и межсетевого соединения;
прямой доступ к низкоскоростным каналам без необходимости полного демультиплексирования сигнала;
простая схема управления сетью;
возможность использования новых протоколов, по мере их появления (напр. atm)
При передаче по сети SDH информация вкладывается в специальные структуры, называемые виртуальными контейнерами (VC). Эти контейнеры состоят из двух частей:
Собственно контейнер (C), где лежит передаваемая информация;
Заголовок (path overhead - POH), который содержит вспомогательную информацию о канале, управляющую информацию, связанную с маршрутом передачи.
Описано несколько типов виртуальных контейнеров для использования в различных каналах.
Таблица 4.3.6.2. Виды виртуальных контейнеров
Виртуальный контейнер |
Поддерживаемые услуги |
| VC-11 | 1.544 Мбит/с североамериканские каналы |
| VC-12 | 2.048 Мбит/с европейские каналы |
| VC-2 | 6.312 Мбит/с каналы (используются редко). VC-2 могут также объединяться для достижения больших скоростей |
| VC-3 | 34.368 Мбит/с и 44.736 Мбит/с каналы |
| VC-4 | 139.264 Мбит/с каналы и другие высокоскоростные услуги |
| С-n | Контейнер уровня n (n=1,2,3,4); |
| VC-n | Виртуальный контейнер уровня n (n=1,2,3,4); |
| TU-n | Трибные блоки уровня n (n=1,2,3); |
| TUG-n | Группа трибных блоков n (n=2,3); |
| AU-n | Административные блоки уровня n (n=3,4); |
| AUG | Группа административных блоков (стандарт G.709). |
Виртуальный контейнер VC-3 делится на два виртуальных контейнера VC-31 и VC-32, полезная нагрузка VC-3 образуется из одного контейнера С-3 или с помощью мультиплексирования нескольких групп TUG-2.
Виртуальный контейнер VC-4 с полезной нагрузкой в виде контейнера С-4 или путем мультиплексирования нескольких групп TUG-2 и TUG-3.
Административный блок AU-3 разбивается на подуровни AU-31 и AU-32, поле данных которых формируется из виртуального контейнера VC-31 или VC-32 соответственно.
Административный блок AU-4 не имеет подуровней, его поле данных формируется из виртуального контейнера VC-4 или комбинаций других блоков: 4*VC-31 или 3*VC-32 или 21*TUG-21 или 16*TUG-22.
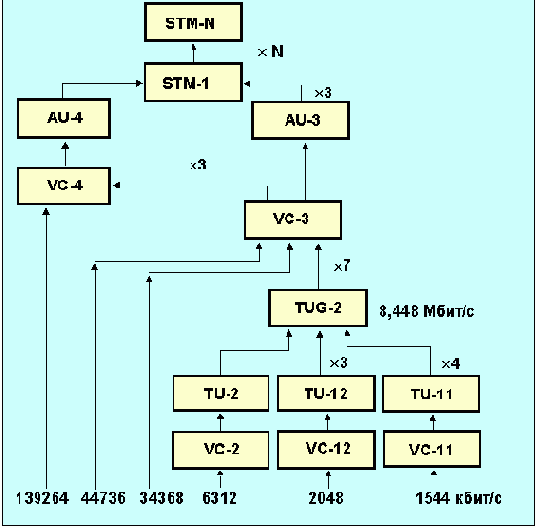
Рис. 4.3.6.2 Иерархия мультиплексирования SDH
На рис. 4.3.6.2 отображена иерархия мультиплексирования потоков информации в SDH. На рисунке не показана возможность вложения контейнера VC-11 в TU-12. SDH-сигнал состоит из STM-1 кадров (synchronous transport module уровень 1; рис. 4.3.6.3). Этот сигнал обеспечивает интерфейс для обмена со скоростью 155.52 Мбит/c, что является базовым блоком, из которого строятся интерфейсы с более высоким быстродействием. Для более высоких скоростей может быть использовано n STM-1 кадров с перекрытием байтов (byte interleave, см. рис. 4.3.6.6). Согласно требованиям CCITT n может принимать значения 1, 4 и 16, предоставляя интерфейс для каналов с полосой 155.52, 622.08 и 2488 Мбит/с. Каждый STM-1 кадр содержит 2430 байтов, передаваемых каждые 125 мксек. Для удобства такой кадр можно отобразить в виде блока, содержащего 9 строк по 270 байт.
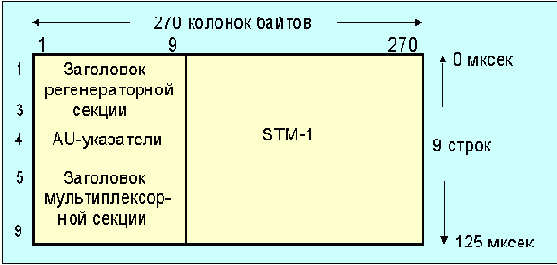
Рис. 4.3.6.3 Структура кадра STM-1
Первые 9 колонок кадра, исключая строку 4, используются в качестве заголовка. Регенераторная часть служит для передачи сигнала между линейным оборудованием и несет в себе флаги разграничения кадров, средства для обнаружения ошибок и управления телекоммуникационным каналом.
Мультиплексорный заголовок используется мультиплексорами, обеспечивая детектирование ошибок и информационный канал с пропускной способностью 576 Кбит/с. AU (administrative units) - предлагает механизм эффективной транспортировки информации STM-1. Административный блок перераспределяет информацию внутри виртуального контейнера. Начало виртуального контейнера индицируется указателем au, в котором содержится номер байта, с которого начинается контейнер. Таким образом, начала STM-1 и VC не обязательно совпадают.
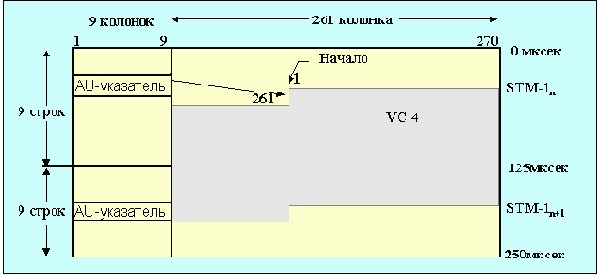
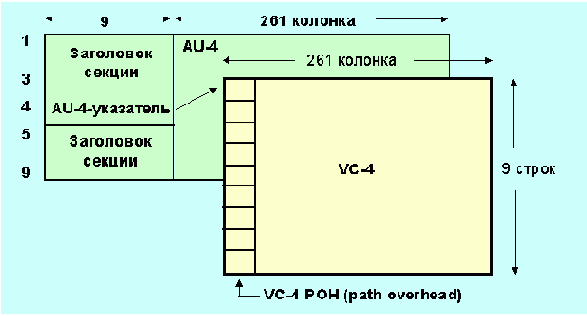
Рис. 4.3.6.5. VC-4, плавающий в AU-4
VC-4 (см. рис. 4.3.6.5) позволяет реализовать каналы с быстродействием 139.264 Кбит/с. Более высокая скорость обмена может быть достигнута путем соединения нескольких VC-4 вместе. Для более низких скоростей (около 50 Мбит/с) предлагается структура AU-3.
Три VC-3 помещаются в один кадр STM-1, каждый со своим au-указателем. Когда три VC-3 мультиплексируются в один STM-1, их байты чередуются, то есть за байтом первого VC-3 следует байт второго vc-3, а затем третьего. Чередование байтов (byte interleaving) используется для минимизации задержек при буферизации. Каждый VC-3 имеет свой AU-указатель, что позволяет им произвольно размещаться в пределах кадра STM-1.
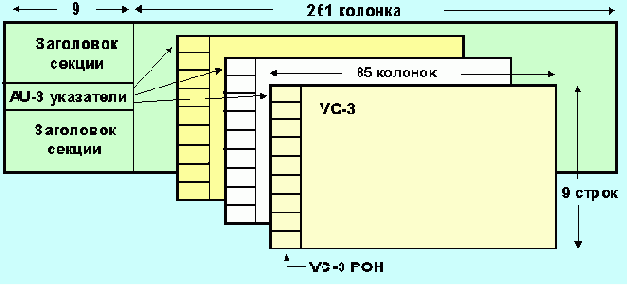
Рис. 4.3.6.6. Три VC-3 в STM-1 кадре
Каждому VC-3 при занесении в STM-1 добавляется 2 колонки заполнителей, которые размещаются между 29 и 30, а также между 57 и 58-ой колонками контейнера VC-3. VC, соответствующие низким скоростям, сначала вкладываются в структуры, называемые TU (tributary units - вложенные блоки), и лишь затем в более крупные - VC-3 или VC-4. TU-указатели позволяют VC низкого уровня размещаться независимо друг от друга и от VC высокого уровня.
VC-4 может нести в себе три VC-3 непосредственно, используя TU-3 структуры, аналогичные AU-3. Однако транспортировка VC-1 и VC-2 внутри vc-3 несколько сложнее. Необходим дополнительный шаг для облегчения процесса мультиплексирования VC-1 и VC-2 в структуры более высокого уровня (см. рис. 4.3.6.7).
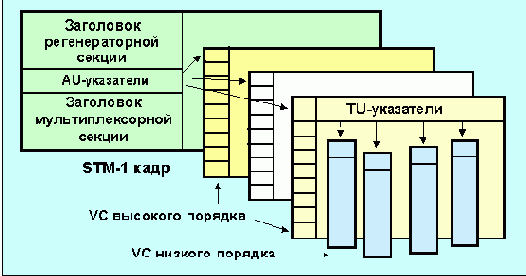
Рис. 4.3.6.7. Транспортировка VC при низких скоростях с использованием TU-структур
Так как VC-1 и VC-2 оформляются как TU, они вкладываются в TUG (Tributary Unit Group). TUG-2 имеет 9 рядов и 12 колонок, куда укладывается 4 VC-11, 3 VC-12 или один VC-2. Каждый TUG-2 может содержать VC только одного типа. Но TUG-2, содержащие различные VC, могут быть перемешаны произвольным образом. Фиксированный размер TUG-2 ликвидирует различия между размерами VC-1 и VC-2, упрощая мультиплексирование виртуальных контейнеров различных типов и их размещение в контейнерах более высокого уровня. Данная схема мультиплексирования требует более простого и дешевого оборудования для осуществления мультиплексирования, чем PDH.
Если в SDH управление осуществляется на скоростях в несколько килобайт, в ATM оно реализуется на скорости канала, что влечет за собой определенные издержки.
Для управления SDH/SONET используется протокол SNMP (см. RFC-1595, “Definitions of Managed Objects for the SONET/SDH Interface Type”) и база данных MIB.
Архитектура сети, базирующейся на SDH, может иметь кольцевую структуру или схему точка-точка.
Система аутентификации удаленных пользователей при подключении через модем RADIUS
4.5.3.1 Система аутентификации удаленных пользователей при подключении через модем RADIUS
Семенов Ю.А. (ГНЦ ИТЭФ)
(RFC-2138. Remote Authentication Dial In User Service, P. Vixie, S. Thomson, Y. Rekhter, J. Bound.)1. Введение
Управление последовательных линий и модемных пулов при большом числе пользователей может потребовать весьма значительных административных усилий. Так как модемные пулы по определению являются каналами во внешний мир, они требуют особых мер безопасности. Это может быть реализовано путем поддержки единой базы данных пользователей, которая используется для аутентификации (проверке имени и пароля). Эта база данных хранит в себе и конфигурационные данные, характеризующие вид услуг, предоставляемых пользователю (например, SLIP, PPP, telnet, rlogin).
Модель клиент/сервер
Сервер сетевого доступа NAS (Network Access Server) работает как клиент системы RADIUS (RFC-2138, 2618-2621). Клиент передает информацию о пользователе специально выделенным серверам RADIUS, и далее действует в соответствии с полученным откликом на эти данные.
Серверы RADIUS принимают запросы от пользователей, осуществляют аутентификацию и выдают конфигурационную информацию, которая необходима клиенту, чтобы предоставить пользователю запрошенный вид услуг.
Сервер RADIUS может выполнять функцию прокси-клиента по отношению к другим серверам RADIUS или прочим аутентификационным серверам.
Сетевая безопасность
Взаимодействие клиента и сервера RADIUS аутентифицируются с использованием общего секретного ключа (пароля), который никогда не пересылается по сети. Кроме того, каждый пароль пользователя пересылается от клиента к серверу в зашифрованном виде, чтобы исключить его перехват.
Гибкие аутентификационные механизмы
Сервер RADIUS может поддерживать несколько методов аутентификации пользователя. При получении имени пользователя и его пароля сервер может воспользоваться PPP PAP или CHAP, UNIX login, и другими аутентификационными механизмами.
Масштабируемый протокол
Все операции подразумевают использование ансамблей атрибут-длина-значение. Новое значение атрибута может быть добавлено без редактирования существующей версии реализации протокола.
1.1. Терминология
В этом документе используются следующие термины:
Услуга
NAS обеспечивает пользователю, подключенному через модем, определенные услуги, такие как PPP или Telnet.
Сессия
Каждый вид услуг, предоставляемый NAS через модемную связь, представляет собой сессию. Начало сессии сопряжено с моментом начала предоставления данной услуги, а конец – со временем завершения этого процесса. Пользователь может иметь несколько сессий одновременно, если сервер поддерживает такой режим.
Молчаливое удаление (silently discard)
| Это означает, что программа выбрасывает пакет без какой-либо обработки. Программная реализация должна предоставлять возможность диагностирования таких случаев и записи их статистики. |
2. Работа
Когда клиент сконфигурирован для использования RADIUS, любой пользователь предоставляет аутентификационные данные клиенту. Это может быть сделано с помощью традиционной процедуры login, когда пользователь вводит свое имя и пароль. В качестве альтернативы может использоваться протокол типаPPP, который имеет специальные пакеты, несущие аутентификационную информацию.
Когда клиент получил такую информацию, он может выбрать для аутентификации протокол RADIUS. Для реализации этого клиент формирует запрос доступа (Access-Request), содержащий такие атрибуты как имя пользователя, его пароль, идентификатор клиента и идентификатор порта, к которому должен получить доступ пользователь. При передаче пароля используется метод, базирующийся на алгоритме MD5 (RSA Message Digest Algorithm [1]).
Запрос Access-Request направляется по сети серверу RADIUS. Если в пределах заданного временного интервала не поступает отклика, запрос повторяется. Клиент может переадресовать запрос альтернативному серверу, если первичный сервер вышел из строя или недоступен.
Когда сервер RADIUS получил запрос, он проверяет корректность клиента-отправителя. Запрос, для которого сервер RADIUS не имеет общего секретного ключа (пароля), молча отбрасывается. Если клиент корректен, сервер RADIUS обращается к базе данных пользователей, чтобы найти пользователя, чье имя соответствует запросу. Пользовательская запись в базе данных содержит список требований, которые должны быть удовлетворены, прежде чем будет позволен доступ. Сюда всегда входит сверка пароля, но можно специфицировать клиента или порт, к которому разрешен доступ пользователя. Сервер RADIUS может посылать запросы к другим серверам, для того чтобы выполнить запрос, в этом случае он выступает в качестве клиента.
Если хотя бы какое- то условие не выполнено, сервер посылает отклик "Access-Reject" (отклонение Access-Reject текст комментария.
Если все условия выполнены, сервер может послать отклик-приглашение (Access-Challenge). Этот отклик может содержать текстовое сообщение, которое отображается клиентом и предлагает пользователю откликнуться на приглашение. Отклик-приглашение может содержать атрибут состояния (State). Если клиент получает Access-Challenge, он может отобразить текст сообщения и затем предложить пользователю ввести текст отклика. Клиент при этом повторно направляет свой Access-Request с новым идентификатором, с атрибутом пароля пользователя, замененным зашифрованным откликом. Этот запрос включает в себя атрибут состояния, содержащийся в приглашении Access-Challenge (если он там был). Сервер может реагировать на этот новый запрос откликами Access-Accept, Access-Reject, или новым Access-Challenge.
Если все условия выполнены, список конфигурационных значений для пользователя укладываются в отклик Access-Accept. Эти значения включают в себя тип услуги (например: SLIP, PPP, Login User) и все параметры, необходимые для обеспечения запрошенного сервиса. Для SLIP и PPP, сюда могут входить такие значения как IP-адрес, маска субсети, MTU, желательный тип компрессии, а также желательные идентификаторы пакетных фильтров. В случае символьного режима это список может включать в себя тип протокола и имя ЭВМ.
2.1. Запрос/Отклик
При аутентификации приглашение/отклик, пользователю дается псевдослучайное число и предлагается его зашифровать и вернуть результат. Авторизованные пользователи снабжаются специальными средствами, такими как смарт-карта или программой, которая облегчает вычисление отклика.
Пакет Access-Challenge обычно содержит сообщение-ответ, включая приглашение (challenge), которое должно быть отображено для пользователя. Обычно оно имеет форму числа и получается от внешнего сервера, который знает, какого типа аутентификатор должен быть применен для данного авторизованного пользователя и, следовательно, может выбрать псевдослучайное число заданной длины.
Пользователь вводит приглашение в свое устройство или программу и вычисляет отклик, который через клиента транспортируется серверу RADIUS посредством второго сообщения Access-Request. Если отклик соответствует ожидаемому значению, сервер присылает сообщение Access-Accept, в противном случае - Access-Reject.
Пример: NAS посылает серверу RADIUS пакет Access-Request с NAS-идентификатором, NAS-портом, именем пользователя, паролем пользователя (который может быть фиксированной строкой, как приглашение "challenge", но Access-Challenge с сообщениями состояния (State) и Reply-Message вместе со строкой "Challenge 12345678, enter your response at the prompt", которую отображает NAS. NAS предлагает ввести отклик и посылает серверу новый запрос NEW Access-Request (с новым идентификатором) с NAS-идентификатором, NAS-портом, именем пользователя, паролем пользователя (отклик, введенный пользователем, шифруется) и с тем же самым атрибутом состояния, который прислан с Access-Challenge. Сервер затем присылает назад Access-Accept или Access-Reject в зависимости от того, корректен ли отклик или следует послать еще один Access-Challenge.
2. Работа с PAP и CHAP
Для PAP, NAS берет идентификатор PAP и пароль и посылает их в пакете Access-Request в полях имя пользователя и пароль пользователя.. NAS может содержать атрибуты Service-Type = Framed-User и Framed-Protocol = PPP в качестве подсказки серверу RADIUS, который предполагает использование услуг PPP.
Для CHAP NAS генерирует псевдослучайное приглашение (желательно 16 октетов) и посылает его пользователю, который возвращает CHAP-отклик вместе с идентификатором и именем пользователя CHAP. NAS посылает затем серверу RADIUS пакет Access-Request с именем CHAP-пользователя в качестве User-Name и с CHAP ID и CHAP-откликом в качестве CHAP-Password (атрибут 3). Случайный вызов может быть включен в атрибут CHAP-Challenge или, если он имеет длину 16 октетов, может быть помещен в поле аутентификатор запроса пакета запроса доступа. NAS может включать в себя атрибуты Service-Type = Framed-User и Framed-Protocol = PPP в качестве подсказки серверу RADIUS, указывая, что предполагается использование канала PPP.
Сервер RADIUS ищет пароль по имени пользователя, шифрует вызов и CHAP-вызов с помощью алгоритма MD5, затем сравнивает результат с CHAP-паролем. Если они совпадают, сервер посылает сообщение Access-Accept, в противном случае - Access-Reject.
Если сервер RADIUS не способен выполнить запрошенную аутентификацию, он должен прислать сообщение Access-Reject. Например, CHAP требует, чтобы пароль пользователя должен быть доступен серверу в открытом текстовом виде, чтобы он мог зашифровать CHAP-вызов и сравнить его с CHAP-откликом. Если пароль не доступен серверу RADIUS в таком виде, он должен послать клиенту сообщение Access-Reject.
2.3. Почему UDP?
Может возникнуть вопрос, почему RADIUS использует протокол UDP вместо TCP. UDP был выбран по чисто техническим причинам. Существует большое число моментов, которые нужно понять. RADIUS является протоколом, ориентированным на операции и имеющим ряд интересных особенностей:
Если запрос к первичному аутентификационному серверу не прошел, он должен быть переадресован вторичному серверу. Чтобы удовлетворить этому, копия запроса должна храниться на уровне выше транспортного, с тем, чтобы позволить альтернативную попытку. Отсюда следует, что необходим таймер ретрансмиссии.
2.
Временные требования данного конкретного протокола значительно отличаются от тех, которые обеспечивает TCP.
3.
Природа данного протокола не требует контроля состояния, что упрощает применение протокола UDP.
Клиенты и серверы приходят и уходят. Системы перезагружаются, а сетевое питание выключается и включается... UDP полностью исключает влияние всех этих событий на работу системы. Любой клиент и сервер может открыть UDP обмен однажды и оставлять его в таком состоянии, игнорируя какие-либо сбои в сетевой среде.
2.4. UDP упрощает реализацию сервера.
В ранних реализациях RADIUS сервер поддерживал один процесс (single threaded). Это означает, что только один запрос принимался, обрабатывался и отправлялся. Это оказалось неприемлемым для сред, где механизм обеспечения безопасности требует определенного времени (1 или более секунд). Очередь запросов в сервере будет значительной и в средах, где сотни людей требуют аутентификации каждую минуту, время обслуживания запроса становится настолько большой, что начинает нервировать пользователей. Очевидным решением проблемы является многопроцессный сервер. Достичь этого проще всего с помощью UDP. Порождаются отдельные процессы для обслуживания каждого запроса, а эти процессы могут напрямую взаимодействовать с клиентом NAS путем отправки UDP-пакета.
Это не панацея. Применение UDP требует организации повторных передач, для чего нужно на сервере запускать соответствующие таймеры. В этом UDP уступает TCP, но это небольшая плата за полученные преимущества.
3. Формат пакета
Один пакет RADIUS вкладывается в одну UDP-дейтограмму [2]. При этом порт назначения равен 1812 (десятичное). При формировании отклика коды портов отправителя и получателя меняются местами. Формат пакета RADIUS показан на рис. .1. Разряды пронумерованы в порядке их передачи.
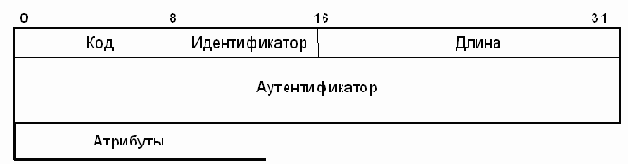
Рис. .1. Формат пакета RADIUS
Поле код содержит один октет и идентифицирует тип пакета RADIUS. Если получен пакет с неверным значением поля код, он молча отбрасывается.
Стандартизованы следующие значения поля код:
Назначение
1
Запрос доступа (Access-Request)
2
Доступ разрешен (Access-Accept)
3
Доступ не разрешен (Access-Reject)
4
Accounting-Request
5
Accounting-Response
11
Access-Challenge
12
Сервер состояния (экспериментальный)
13
Клиент состояния (экспериментальный)
255
Зарезервировано
Коды 4 и 5 будут описаны в документе [RFC-2139]. Коды 12 и 13 зарезервированы для возможного использования.
Поле идентификатор имеет один октет, и служит для установления соответствия между запросом и откликом.
Поле длина имеет два октета. Оно определяет длину пакета, включая поля код, идентификатор, длина, аутентификатор и атрибуты. Октеты за пределом, указанным полем длина,
рассматриваются как заполнитель и игнорируются получателем. Если пакет короче, чем указано в поле длина, он должен быть молча выкинут. Минимальная длина равна 20, а максимальная - 4096.
Поле аутентификатор имеет 16 октетов. Старший октет пересылается первым. Этот параметр служит для аутентификации отклика от сервера RADIUS, и используется в алгоритме сокрытия пароля.
В пакетах Access-Request, значение поля аутентификатор равно 16-октетному случайному числу, называемому аутентификатор запроса. Его значение должно быть непредсказуемым и уникальным на протяжении жизни секретного пароля, совместно используемого клиентом и RADIUS-сервером.
Значение аутентификатора запроса в пакете Access- Request должно быть также непредсказуемым, чтобы исключить возможные атаки.
Хотя протокол RADIUS не может исключить всех возможных атак, в частности с использованием подключения к линии в реальном масштабе времени, но генерация псевдослучайных аутентификаторов все же обеспечивает относительную безопасность.
NAS и сервер RADIUS используют секретный пароль совместно. Этот секретный пароль и аутентификатор запроса пропускаются через хэширование MD5, чтобы получить 16-октетный дайджест, который объединяется посредством операции XOR с паролем, введенным пользователем, результат помещается в атрибут пароля пользователя пакета Access-Request.
Значение поля аутентификатор в пакетах Access-Accept, Access-Reject, и Access-Challenge называется аутентификатором отклика (Response Authenticator). Оно представляет собой однопроходную хэш-функцию MD5, вычисленную для потока октетов, включающих в себя: пакет RADIUS, начинающийся с поля код, и включающий поля идентификатор, длина, аутентификатор запроса из пакета Access-Request, и атрибуты отклика, за которыми следует общий секретный пароль. То есть ResponseAuth = MD5(Код+ID+длина+RequestAuth+атрибуты+секретный_пароль) где знак + означает присоединение.
Секретный пароль, совместно используемый клиентом и сервером RADIUS, должен быть достаточно большим и непредсказуемым, как хороший пароль. Желательно, чтобы секретный пароль имел, по крайней мере, 16 октетов. Сервер RADIUS должен использовать IP-адрес отправителя UDP-пакета, чтобы решить, какой секретный пароль использовать.
Когда используется переадресующий прокси-сервер, он должен быть способен изменять пакет при проходе в том или ином направлении. Когда прокси переадресует запрос, он может добавить атрибут Proxy-State, а при переадресации отклика, он удаляет атрибут Proxy-State. Так как ответы Access-Accept и Access-Reject аутентифицированы по всему своему содержимому, удаление атрибута Proxy-State сделает сигнатуру пакета некорректной. По этой причине прокси должен вычислить ее заново.
Атрибуты
Многие атрибуты могут быть записаны несколько раз, в этом случае порядок следования атрибутов одного и того же типа должен быть сохранен. Порядок атрибутов различных типов может быть изменен.
В данном документе регламентированы атрибуты для пакетов с полем код, равным 1, 2, 3 и 11. Чтобы определить, какие атрибуты допускаются для пакетов с полем код=4 и 5, смотри [9].
4. Типы пакетов
Тип пакета RADIUS определяется полем тип, размещенным в первом октете.
4.1. Запрос доступа
Пакеты Access-Request посылаются серверу RADIUS, и передают информацию, которая используется для определения того, позволен ли данному пользователю доступ к специфицированному NAS, и допустимы ли запрошенные услуги. Программная реализация, желающая аутентифицировать пользователя, должна послать пакет RADIUS с кодом поля тип=1 (Access-Request).
При получении запроса (Access-Request) доступа от корректного клиента, должен быть передан соответствующий ответ. Запрос доступа (Access-Request) должен содержать атрибут имени пользователя. Он должен включать в себя атрибут NAS-IP-адреса или атрибут NAS-идентификатора (или оба эти атрибута, хотя это и не рекомендуется). Он должен содержать атрибут пароля пользователя (User-Password) или атрибут CHAP-пароля. Желательно, чтобы он содержал атрибут NAS-порта или NAS-Port-Type или оба эти атрибута, если только тип запрошенного доступа не содержал номер порта.
Запрос доступа (Access-Request) может содержать дополнительные атрибуты - подсказки серверу, но последний не обязан следовать этим подсказкам. Когда присутствует пароль пользователя (User-Password), он защищается с использованием метода, базирующегося на RSA алгоритме MD5 [1]. Формат пакета Access-Request аналогичен показанному на рис. .1. Только на месте поля аутентификатор размещается поле аутентификатор запроса (Request Authenticator), а в поле код записывается 1.
Поле идентификатор должно измениться при изменении содержимого поля атрибуты, и при получении корректного ответа на предыдущий запрос. При повторных передачах поле идентификатор остается неизменным.
Значение поля аутентификатор запроса ( Request Authenticator) должно изменяться, когда используется новый идентификатор.
Поле атрибуты имеет переменную длину и содержит список атрибутов, которые необходимы для заданного типа сервиса, а также любых дополнительных опционных атрибутов.
4.2. Пакеты Access-Accept
Пакеты Access-Accept посылаются сервером RADIUS, и предоставляют специфическую конфигурационную информацию, необходимую для предоставления пользователю соответствующего сервиса. Если все значения атрибутов, полученных с запросом Access-Request, приемлемы, тогда реализация RADIUS должна послать пакет с полем код=2 (Access-Accept). При получении сообщения Access-Accept, поле идентификатор соответствует обрабатываему запросу (Access-Request). Кроме того, поле аутентификатор отклика должно содержать корректный отклик на полученный запрос Access-Request. Пакеты неверного формата молча отбрасываются. Формат пакета Access-Accept идентичен показанному на рис. .1. Но здесь вместо поля аутентификатор используется поле аутентификатор отклика, имеющее тот же размер. В поле код при этом записывается число 2.
Поле идентификатор является копией одноименного поля в запросе Access-Request, который инициировал сообщение Access-Accept.
Значение поля аутентификатор отклика (Response Authenticator) вычисляется на основе значения Access-Request, как это описано выше. Поле атрибуты имеет переменную длину и содержит список из нуля или более атрибутов.
4.3. Сообщение Access-Reject
Если какое-либо значение полученного атрибута неприемлемо, тогда сервер RADIUS должен послать пакет с полем код= 3 (Access-Reject). Пакет может содержать один или более атрибутов Reply-Message с текстом, который может быть отображен NAS для пользователя. Поле идентификатор для данного пакета копируется из одноименного поля пакета Access-Request, вызвавшего данный отклик.
Значение поля аутентификатор отклика вычисляется на основе содержимого сообщения Access-Request, как это описано выше.
4.4. Сообщение Access-Challenge
Если сервер RADIUS хочет послать пользователю вызов, требующий отклика, то сервер должен реагировать на запрос Access-Request посылкой пакета с полем код=11 (Access-Challenge). Поле атрибуты может содержать один или более атрибутов Reply-Message, и может опционно включать атрибут состояния. Никакие другие атрибуты здесь не применимы.
При получении Access-Challenge, поле идентификатор соответствует содержимому пакета Access-Request. Кроме того, поле аутентификатор отклика должно содержать корректный отклик на обрабатываемый запрос Access-Request. Некорректные пакеты молча отбрасываются. Если NAS не поддерживает обмен вызов/отклик (challenge/response), он должен обрабатывать сообщение Access-Challenge, как если бы это был запрос Access-Reject.
Если сервер NAS поддерживает обмен вызов/отклик, получение корректного сообщения Access-Challenge указывает, что следует послать новый запрос Access-Request. Сервер NAS может отобразить текстовое сообщение для пользователя, если таковое имеется, а затем предложить ему ввести отклик. Затем сервер посылает исходное сообщение Access-Request с новым идентификатором запроса и аутентификатором отклика, с атрибутом пароля пользователя, содержащим зашифрованный отклик пользователя. Кроме того, это сообщение содержит атрибут состояния (State) сообщения Access-Challenge, если таковой имелся.
NAS, который поддерживает PAP может переадресовать сообщение Reply-Message клиенту, подключенному по модемному каналу, и принять PAP-отклик, который он может использовать как отклик, введенный пользователем. Если NAS этого сделать не может, он должен воспринимать Access-Challenge, как если бы он получил сообщение Access-Reject. Формат пакета Access-Challenge совпадает с форматом Access-Accept и Access-Request.
Поле идентификатор является копией одноименного поля пакета Access-Request, который вызвал посылку Access-Challenge.
Значение аутентификатора отклика вычисляется так, как это было описано выше. Поле атрибуты имеет переменную длину, и содержит список из нуля или более атрибутов.
5. Атрибуты
Атрибуты RADIUS несут в себе специфическую аутентификационную и конфигурационную информацию для запросов и откликов. Некоторые атрибуты могут быть включены в список более одного раза. Воздействие такого использования зависит от типа атрибута.
Конец списка атрибутов определяется кодом, содержащимся в поле пакета длина. Формат записи атрибута показан на рис. .2.

Рис. .2. Формат записи атрибута
Поле тип имеет один октет. Возможные значения этого поля перечислены в документе RFC-1700 "Assigned Numbers" [3]. Значения 192-223 зарезервированы для экспериментального использования, значения 224-240 выделены для специальных реализаций, а значения 241-255 зарезервированы на будущее. Ниже в таблице 1. представлена спецификация стандартизованных значений атрибутов. Сервер и клиент RADIUS могут игнорировать атрибуты неизвестного типа.
Таблица .1.
Cпецификация стандартизованных значений атрибутов
Назначение
1
Имя пользователя (User-Name)
2
Пароль пользователя (User-Password)
3
CHAP-пароль
4
NAS-IP-адрес
5
NAS-порт
6
Тип услуги (Service-Type)
7
Framed-Protocol
8
Framed-IP-адрес
9
Framed-IP-Netmask
10
Framed-Routing
11
Filter-Id
12
Framed-MTU
13
Framed-Compression
14
Login-IP-Host
15
Login-Service
16
Login-TCP-Port
17
(unassigned)
18
Сообщение-отклик (Reply-Message)
19
Callback-Number
20
Callback-Id
21
(не определено)
22
Framed-Route
23
Framed-IPX-Network
24
Состояние
25
Класс
26
Vendor-Specific
27
Таймаут сессии (Session-Timeout)
28
Idle-Timeout (таймаут пассивного состояния)
29
Termination-Action (процедура завершения)
30
Called-Station-Id
31
Calling-Station-Id
32
NAS-Идентификатор
33
Proxy-State
34
Login-LAT-Service
35
Login-LAT-Node
36
Login-LAT-Group
37
Framed-AppleTalk-Link
38
Framed-AppleTalk-Network
39
Framed-AppleTalk-Zone
40-59
(зарезервировано для акоунтинга)
60
CHAP-вызов (CHAP-Challenge)
61
NAS-Port-Type
62
Port-Limit
63
Login-LAT-Port
Поле длина является однооктетным, оно определяет длину данного атрибута, включая субполя тип, длина и величина. Если атрибут получен в запросе Access-Request, но с неверной длиной, следует послать сообщение Access-Reject. Если атрибут прислан в пакете Access-Accept, Access-Reject или Access-Challenge и имеет некорректную длину, пакет должен рассматриваться как Access-Reject или молча отбрасываться.
Поле значение содержит ноль или более октетов и содержит специфическую информацию атрибута. Формат и длина поля значение определяется полями тип и длина. Заметим, что строка в RADIUS не требует завершения символом ASCII NUL, так как имеется поле длины. Поле значение может иметь один из четырех форматов.
| строка | 0-253 октетов |
| адрес | 32 битовый код, старший октет передается первым. |
| целое | 32 битовый код, старший октет первый. |
| время | 32 битовый код (старший октет первый) равен числу секунд с момента 00:00:00 GMT, 1-го января, 1970. Стандартные атрибуты не используют этот тип данных, но он представлен здесь, так как может быть применен в атрибутах зависящих от производителя (Vendor-Specific). |
5.1. Имя пользователя
Этот атрибут указывает имя пользователя, который должен быть аутентифицирован. Он используется в пакетах Access-Request. Формат атрибута показан на рис. .3.

Рис. .3. Формат атрибута
Поле тип=1, длина ³
3. Поле строка имеет один или более октетов. NAS может ограничить максимальную длину имени пользователя, но рекомендуется, чтобы программа была способна обрабатывать как минимум 63 октета. Применяется несколько форматов имени пользователя:
| монолитный | Состоит только из буквенно-цифровых символов. Эта простая форма может использоваться для локального управления NAS. |
| простой | Состоит только из печатных символов ASCII. |
| name@fqdn SMTP адрес | Стандартное имя домена (Fully Qualified Domain Name; с или без завершающей точкой) указывает область, где применимо имя. |
| уникальное имя | Имя в формате ASN.1 используется в аутентификационных системах с общедоступным ключом. |
5.2. Пароль пользователя
Этот атрибут указывает на пароль аутентифицируемого пользователя или на вводимые пользователем данные в ответ на Access-Challenge. Этот атрибут используется только в пакетах Access-Request.
При передаче пароль шифруется. Пароль сначала дополняется нулями до границы кратной 16 октетам. Затем согласно алгоритму MD5 вычисляется хэш-функция. Это вычисление производится для потока октетов, состоящего из о бщего секретного пароля, за которым следует аутентификатор запроса (Request Authenticator). Для полученного кода и первых 16 октетов пароля производится операция XOR. Результат кладется в первых 16 октетов поля строка атрибута пароля пользователя.
Если пароль длиннее 16 символов, вычисляется вторая хэш-функция для потока данных, включающего в себя общий секретный пароль и результат предыдущей операции XOR. Полученный результат и вторые 16 октетов пароля объединяются с помощью операции XOR, а полученный код кладется во вторые 16 октетов поля строка атрибута User-Password. Если необходимо, эта операция повторяется. Следует только иметь в виду, что поле строка не может превышать 128 символов.
Данный метод заимствован из книги "Network Security" Кауфмана, Пелмана и Спесинера [4; стр. 109-110]. Более формализовано алгоритм можно описать следующим образом:
Берется общий секретный ключ S и псевдослучайный 128-битный аутентификатор запроса RA. Пароль разбивается на 16-октетные блоки p1, p2, …, pi. последний из них дополняется нулями до размера кратного 16 октетам. Далее реализуется алгоритм MD5. Берутся блоки шифрованного текста c(1), c(2), …, c(i), получаются промежуточные значения b1, b2, … bi:
| b1 = MD5(S + RA) | c(1) = p1 XOR b1 |
| b2 = MD5(S + c(1)) | c(2) = p2 XOR b2 |
| . | . |
| . | . |
| . | . |
| bi = MD5(S + c(I-1)) | c(i) = pi XOR bi |
При получении осуществляется обратный процесс и получается исходная форма пароля. В результате формируется атрибут, где в поле тип записан код 2, в поле длина число в интервале 18-130, а в поле строка - 16-128 октетов зашифрованного пароля.
5.3. Атрибут CHAP-пароль
Этот атрибут характеризует значение отклика, полученного через протокол PPP CHAP (Challenge-Handshake Authentication Protocol) от пользователя в ответ на вызов. Атрибут используется только в пакетах Access-Request. Значение CHAP-вызова хранится в атрибуте CHAP-Challenge (60), если таковой имеется, в противном случае - в поле аутентификатор запроса. Формат атрибута CHAP-Password показан на рис. .4.

Рис. .4. Формат атрибута CHAP-Password
Поле CHAP ID имеет один октет и содержит идентификатор CHAP из CHAP-отклика пользователя. Поле строка имеет 16 октетов и содержит CHAP-отклик пользователя.
5.4. Атрибут NAS-IP-Address
Этот атрибут указывает IP- адрес сервера NAS, который запрашивает аутентификацию пользователя. Атрибут применяется только в пакетах Access-Request. В пакете Access-Request должен присутствовать NAS-IP-адрес или NAS-идентификатор. Формат атрибута NAS-IP-Address представлен на рис. .5.
Рис. .5 Формат атрибута NAS-IP-Address
Поле адрес имеет протяженность 4 октета (IPv4).
5.5. Атрибут NAS-порт
Этот атрибут несет в себе номер порта NAS, который аутентифицируется пользователем. Атрибут применяется только в пакетах Access-Request. Заметим, что здесь термин порт определяет физическое соединение с NAS, а не используется в значении, принятом в протоколах TCP или UDP. NAS-порт или NAS-Port-Type (61) или оба эти атрибута должны присутствовать в пакете Access-Request, если NAS использует несколько портов. Формат атрибута NAS-порт представлен на рис. .6.
Рис. .6. Формат атрибута NAS-порт
Диапазон кодов в поле значение составляет 0 - 65535.
5.6. Атрибут тип услуги (Service-Type)
Этот атрибут указывает на тип услуг, которые заказал или получит пользователь. Атрибут используется в пакетах Access-Request и Access-Accept. NAS не требует реализации всех типов услуг и должен обрабатывать атрибуты неизвестных или неподдерживаемых видов услуг, как запросы Access-Reject. Формат записи атрибута идентичен формату NAS-порт. Только поле тип=6. Коды поля значение перечислены в таблице .2..
Таблица .2.
Коды поля значение
Назначение
1
Login
2
Framed
3
Callback Login
4
Callback Framed
5
Outbound
6
Administrative
7
NAS Prompt
8
Authenticate Only
9
Callback NAS Prompt
Таково назначение кодов атрибута типа услуг при использовании в сообщениях Access-Accept. Когда они применяются в пакетах Access-Request, они должны рассматриваться как подсказки серверу RADIUS и говорят, что NAS имеет причины полагать, что пользователь предпочтет указанные услуги, но сервер не обязан следовать этим подсказкам.
| Login | Пользователь должен быть подключен к ЭВМ. |
| Framed | Для пользователя должен быть запущен пакетный протокол, такой как PPP или SLIP. |
| Callback Login | Пользователь должен быть отсоединен, выполнен обратный дозвон, после чего осуществлено соединение с ЭВМ. |
| Callback Framed | Пользователь должен быть отсоединен, выполнен обратный дозвон, после чего для пользователя запущен пакетный протокол типа PPP или SLIP. |
| Outbound | Пользователю предоставляется доступ к выходным устройствам. |
| Administrative | Пользователю предоставляется доступ к административному интерфейсу NAS, с которого могут выполняться привилегированные команды. |
| NAS Prompt | Пользователю предоставляется возможность вводить непривилегированные команды NAS. |
| Authenticate Only | Запрашивается только аутентификация, ненужно возвращать никакой авторизационной информации Access-Accept (обычно используется прокси-серверами, а не самим NAS). |
| Callback NAS Prompt | Пользователь должен быть отсоединен, выполнен обратный дозвон, после чего ему предоставляется возможность ввода непривилегированных команд NAS. |
/p>
5.7. Атрибут Framed-Protocol
Этот атрибут указывает на необходимость использования пакетного доступа. Атрибут может использоваться пакетами Access-Request и Access-Accept. Формат представления атрибута аналогичен формату атрибута NAS-порт (рис. .6). Поле тип = 7, поле длина = 6. Коды поля значение собраны в таблице .3.
Таблица .3.
Коды поля значение
Назначение
1
PPP
2
SLIP
3
Протокол удаленного доступа AppleTalk (ARAP)
4
Gandalf владелец протокола SingleLink/MultiLink
5
Xylogics владелец IPX/SLIP
5.8. Атрибут Framed-IP-Address
Этот атрибут указывает на адрес, который следует сконфигурировать для пользователя. Атрибут может использоваться пакетами Access-Accept. Он может использоваться в пакетах Access-Request в качестве подсказки NAS, указывающей на то, что сервер предпочитает данный адрес. Сервер не обязан следовать этой подсказке. Формат атрибута идентичен представлению атрибута NAS-IP-адрес (рис. .5).
Поле тип = 8, поле длина = 6.
Поле адрес содержит 4 октета. Значение 0xFFFFFFFF указывает, что NAS следует разрешить пользователю выбрать адрес. Значение 0xFFFFFFFE отмечает, что NAS следует выбрать адрес для пользователя (например, выбрать его из зарезервированного списка, имеющегося в NAS). Другие допустимые значения указывают, что NAS должен использовать этот код в качестве IP-адреса пользователя.
5.9. Атрибут Framed-IP-Netmask
Этот атрибут указывает на сетевую IP-маску, которая должна быть сконфигурирована для пользователя, когда он является маршрутизатором сети. Атрибут может использоваться в пакетах Access-Accept. Он может использоваться в пакете Access-Request в качестве подсказки NAS серверу относительно того, какую сетевую маску он предпочитает. Но сервер не обязан следовать этой подсказке. Формат записи атрибута аналогичен формату атрибута NAS-IP-адрес. Поле тип = 9, поле длина = 6. Поле адрес имеет 4 октета и определяет сетевую IP-маску.
5.10. Атрибут Framed-Routing
Этот атрибут указывает метод маршрутизация для пользователя, когда пользователем является маршрутизатор сети. Атрибут может использоваться в пакетах Access-Accept. Формат записи атрибута аналогичен показанному на рис. .6 (NAS-порт). Поле тип = 10, поле длина = 10. Допустимые коды и их назначения собраны в таблице .4
Таблица .4.
Допустимые коды поля значение и их назначения
Назначение
0
Ничего не делать
1
Посылать маршрутные пакеты
2
Принимать маршрутные пакеты
3
Посылать и принимать
5.11. Атрибут Filter-Id
Этот атрибут указывает на имя списка фильтра для данного пользователя. Нуль или более идентификаторов фильтра может быть переслано в пакете Access-Accept. Идентификация списка фильтра с помощью имени позволяет использовать фильтр с различными NAS вне зависимости от особенностей использования списка фильтра. Формат записи атрибута соответствует рис. .3. поле тип = 11, поле длина ³ 3.
Поле строка здесь имеет один или более октетов и его содержимое зависит от программной реализации. Содержимое должно иметь читабельный формат и не должно влиять на работу протокола. Рекомендуется, чтобы отображаемое сообщение содержало 32-126 ASCII-символов.
5.12. Атрибут Framed-MTU
Этот атрибут указывает значение MTU, которое должно быть проставлено для пользователя, когда это не согласуется каким-либо другим образом (например, PPP). Атрибут используется только в пакетах Access-Accept. Формат атрибута аналогичен показанному на рис. 6. Поле тип = 12, а поле длина = 6. Поле значение имеет 4 октета и может принимать значения в интервале 64-65535.
5.13. Атрибут Framed-Compression
Этот атрибут указывает на протокол сжатия, который следует использовать при передаче данных. Атрибут используется в пакетах Access-Accept. Атрибут используется в пакетах Access-Request в качестве подсказки серверу о том, какой вид компрессии предпочитает использовать NAS, но сервер не обязан следовать этой рекомендации.
Можно использоваться несколько атрибутов данного типа. Окончательное решение о применении того или иного метода компрессии принимает сервер NAS.
Формат атрибута аналогичен показанному на рис. 6. Поле тип = 13, а поле длина = 6. Возможные коды поля значение собраны в таблице .5.
Таблица .5.
Возможные коды поля значение
Назначение
0
Никакого
1
Сжатие заголовка VJ TCP/IP [5]
2
Сжатие заголовка IPX
5.14. Атрибут Login-IP-Host
Этот атрибут указывает на систему, с которой соединяется пользователь при наличии атрибута Login-Service. Атрибут используется в пакетах Access-Accept, а также Access-Request в качестве подсказки серверу, какую из ЭВМ предпочитает NAS, но сервер не обязан следовать этой рекомендации. Формат записи атрибута аналогичен показанному на рис. .5. Поле тип = 14, а поле длина = 6.
Поле адрес имеет 4 октета. Значение 0xFFFFFFFF указывает на то, что NAS должен позволить пользователю выбор адреса. Значение 0 говорит, что NAS должен сам выбрать ЭВМ, с которой будет соединен пользователь. Любые другие значения указывают адрес, с которым сервер NAS должен соединить пользователя.
5.15. Атрибут Login-Service
Этот атрибут указывает на услугу, которая будет использоваться для соединения пользователя с ЭВМ. Атрибут применяются только в пакетах Access-Accept. Формат записи атрибута показан на рис. .6. Поле тип = 15, а поле длина = 6. Возможные коды поля значение собраны в таблице .6.
Таблица .6.
Возможные коды поля значение
Назначение
0
Telnet
1
Rlogin
2
Сброс TCP
3
PortMaster (собственник)
4
LAT
5.16. Атрибут Login-TCP-Port
Этот атрибут указывает порт TCP, с которым следует соединить пользователя при наличии атрибута Login-Service. Атрибут используется только в пакетах Access-Accept. Формат записи атрибута показан на рис. .6. Поле тип = 16, а поле длина = 6. Поле значение имеет четыре октета и может содержать величины в диапазоне 0 - 65535.
5.17. Атрибут типа 17 в настоящее время не определен.
5.18. Атрибут Reply-Message
Этот атрибут содержит текст, который может быть отображен для пользователя. Если используется в пакете Access-Accept, это сообщение об успешном выполнении. При использовании с Access-Reject, это уведомление о неудаче. Это может быть элемент диалога с пользователем перед очередной попыткой послать запрос доступа (Access-Request).
Когда атрибут используется в Access-Challenge, он может содержать приглашение пользователю ввести отклик. Допускается применение нескольких атрибутов Reply-Message, в этом случае они должны отображаться в порядке из записи в пакете. Формат записи атрибута следует схеме, показанной на рис. .3. Поле тип = 18, а поле длина ³ 3.
Поле строка содержит один или более октетов. Его содержимое может зависеть от конкретной программной реализации. Содержимое должно быть читабельным и не должно влиять на работу протокола. Рекомендуется, чтобы текст состоял из печатных ASCII символов с кодами 10, 13 и 32 - 126.
5.19. Атрибут Callback-Number
Этот атрибут представляет собой телефонный номер, используемый для обратного дозвона. Атрибут может использоваться в пакетах Access-Accept, а также в Access-Request в качестве подсказки серверу о том, что желателен обратный дозвон, но сервер не обязан следовать этим рекомендациям. Формат записи атрибута следует схеме, показанной на рис. .3. Поле тип = 19, а поле длина ³ 3.
Поле строка содержит один или более октетов. Действительный формат информации может варьироваться от узла к узлу и отличаться для разных приложений.
5.20. Атрибут Callback-Id
Этот атрибут содержит имя места вызова, которое должно быть интерпретировано сервером NAS. Атрибут может использоваться пакетами Access-Accept. Формат записи атрибута следует схеме, показанной на рис. .3. Поле тип = 20, а поле длина ³ 3.
Поле строка содержит один или более октетов. Действительный формат информации может варьироваться от узла к узлу и отличаться для разных приложений.
5.21. Атрибут типа 21 в настоящее время не определен
5.22. Атрибут Framed-Route
Этот атрибут содержит маршрутную информацию, которая должна быть сконфигурирована сервером NAS для пользователя. Атрибут используется в пакетах Access-Accept и может присутствовать там несколько раз. Формат записи атрибута следует схеме, показанной на рис. .3. Поле тип = 22, а поле длина ³
3.
Поле строка содержит один или более октетов, а его содержимое зависит от приложения. Текст должен быть читабельным и не должен влиять на работу протокола. Рекомендуется, чтобы сообщение содержало ASCII-символы с кодами в диапазоне 32 - 126.
Для IP-маршрутов, атрибут должен содержать префикс места назначения в десятично-точечном представлении (как IP-адрес). Далее опционно может следовать косая черта и число старших бинарных единиц, указывающее на количество разрядов префикса, которые следует использовать. Далее следует пробел, адрес шлюза, еще один пробел и один или более кодов метрики, разделенных пробелами. Например, "192.168.1.0/24 192.168.1.1 1 2 -1 3 400". Длина спецификатора может быть опущена, тогда для префикса класса А подразумевается длина в 8 бит, для класса В - 16 и для класса С - 24 бита. Например, "192.168.1.0 192.168.1.1 1". Если адрес шлюза равен "0.0.0.0", тогда в качестве IP-адреса шлюза следует использовать адрес пользователя.
5.23. Атрибут Framed-IPX-Network
Этот атрибут содержит сетевое число IPX, конфигурируемое для пользователя. Атрибут используется в пакетах Access-Accept. Формат записи атрибута показан на рис. .6. Поле тип = 23, а поле длина = 6.
Поле значение имеет 4 октета. Значение 0xFFFFFFFE указывает, что сервер NAS должен выбрать для пользователя сеть IPX (т.е. выбрать одну или более IPX-сетей из имеющегося списка). Остальные значения должны рассматриваться как IPX-сети, предназначенные для подключения.
5.24. Атрибут State
Этот атрибут предназначен для посылки сервером клиенту в сообщении Access-Challenge и должен быть передан немодифицированным от клиента к серверу в новом отклике Access-Request на исходный вызов, если таковой имеется.
Этот атрибут может быть послан сервером клиенту в сообщении Access-Accept, которое содержит также атрибут Termination-Action со значением RADIUS-Request. Если сервер NAS выполняет процедуру Termination-Action путем посылки сообщения Access-Request по завершении текущей сессии, атрибут должен включать в себя исходный код атрибута State из запроса Access-Request. В любом случае клиент не должен его интерпретировать. В пакете может содержаться только один атрибут State. Использование атрибута зависит от конкретной реализации. Формат записи атрибута следует схеме, показанной на рис. .3. Поле тип = 24, а поле длина ³ 3.
Поле строка имеет один или более октетов. Действительный формат информации может варьироваться от узла к узлу и отличаться для разных приложений.
5.25. Атрибут Class
Этот атрибут предназначен для посылки сервером клиенту в сообщении Access-Accept, он должен быть переслан в неизменном виде клиентом серверу, куда планируется доступ, в пакете Accounting-Request. Клиент не должен интерпретировать этот атрибут. Формат записи атрибута следует схеме, показанной на рис. .3. Поле тип = 25, а поле длина ³ 3. Поле строка содержит один или более октетов. Действительный формат информации может варьироваться от узла к узлу и отличаться для разных приложений.
5.26. Атрибут Vendor-Specific
Этот атрибут служит для того, чтобы позволить производителям обеспечить поддержку их собственных атрибутов, непригодных для общего применения. Атрибут не должен влиять на работу протокола RADIUS.
Серверы, не приспособленные для интерпретации информации, специфической для производителя оборудования или программ, должны игнорировать эти атрибуты (хотя могут и оповещать об этом). Клиенты, которые не получили желательной информации, специфической для изготовителя, должны предпринять попытку работать без этих данных. При этом функциональность может быть сужена (о чем клиент может сообщить пользователю). Формат записи атрибута показан на рис. .7. Поле тип = 26, а поле длина ³ 7.

Рис. .7. Формат записи атрибута Vendor-Specific
Старший октет ID изготовителя равен нулю, а младшие три октета представляют собой код изготовителя, как это определено в RFC-1700 (SMI Network Management Private Enterprise Code [2]). Порядок октетов сетевой.
Поле строка имеет один или более октетов. Действительный формат информации может варьироваться от узла к узлу и отличаться для разных приложений. Строка должна кодироваться в виде последовательности тип производителя / длина / поля значений, специфические для производителя. Пример формата строки показан на рис. .8.

Рис. .8. Пример формата строки
Поле строка предназначено для записи параметров, специфических для данного производителя.
5.27. Атрибут Session-Timeout
Этот атрибут устанавливает максимальное число секунд, в течение которых будет предоставляться услуга пользователю до завершения сессии или очередного вызова. Этот атрибут может быть послан сервером клиенту в сообщениях Access-Accept или Access-Challenge. Формат записи атрибута показан на рис. .6. Поле тип = 27, а поле длина = 6.
Поле значение содержит 4 октета, и несет в себе 32-битовое целое число (максимальное число секунд, в течение которых пользователь будет оставаться соединенным с сервером NAS).
5.28. Атрибут Idle-Timeout
Этот атрибут устанавливает максимальное число секунд (непрерывный временной отрезок), в течение которых пользователь может оставаться пассивным, прежде чем соединение с сервером будет разорвано или будет получен вызов. Этот атрибут передается сервером клиенту в сообщениях Access-Accept или Access-Challenge. Формат записи атрибута показан на рис. .6. Поле тип = 28, а поле длина = 6.
Поле значение содержит 4 октета и несет в себе 32- битовое целое число без знака, соответствующее максимальному времени пассивности клиента в секундах. По истечении этого времени соединение с сервером разрывается.
5.29. Атрибут Termination-Action
Этот атрибут указывает, какие действия должен выполнить сервер NAS, когда процедура будет завершена. Атрибут используется только в пакетах Access-Accept. Формат записи атрибута показан на рис. .6. Поле тип = 29, а поле длина = 6. Поле значение имеет 4 октета. Ниже приведены разрешенные коды поля значения.
| 0 | Значение по умолчанию |
| 1 | RADIUS-Request |
5.30. Атрибут Called-Station-Id
Этот атрибут позволяет NAS посылать в пакетах Access-Request телефонный номер, который вызывает пользователь. При этом используется техника DNIS (Dialed Number Identification) или ей подобная. Заметим, что это может быть не тот телефонный номер, через который пришел вызов. Атрибут используется только в пакетах Access-Request. Формат записи атрибута следует схеме, показанной на рис. .3. Поле тип = 30, поле длина ³ 3.
Поле строка содержит один или более октетов, содержащих телефонный номер, через который пользователь дозвонился до системы. Действительный формат информации может варьироваться от узла к узлу и отличаться для разных приложений.
5.31. Атрибут Calling-Station-Id
Этот атрибут позволяет NAS послать в пакете Access-Request телефонный номер, с которого пришел вызов, используя АОН (ANI - Automatic Number Identification) или другую технику. Атрибут используется только в пакетах Access-Request. Формат записи атрибута следует схеме, показанной на рис. .3. Поле тип = 31, поле длина ³ 3.
Поле строка содержит один или более октетов, где записан номер телефона, с которого позвонил пользователь. Действительный формат информации может варьироваться от узла к узлу и отличаться для разных приложений. Рекомендуется использование печатных ASCII-символов.
5.32. Атрибут NAS-идентификатор
Этот атрибут содержит строку, идентифицирующую запрос Access-Request, посланный сервером NAS. Атрибут используется только в пакетах Access-Request. В пакете Access-Request должен присутствовать атрибут NAS-IP-Address или NAS-Identifier. Формат записи атрибута следует схеме, показанной на рис. .3. Поле тип = 32, а поле длина ³ 3.
Поле строка содержит один или более октетов, и должна быть уникальной для NAS в области действия сервера RADIUS. Например, полное имя домена вполне подходит в качестве NAS-идентификатора. Действительный формат информации может варьироваться от узла к узлу и отличаться для разных приложений.
5.33. Атрибут Proxy-State
Этот атрибут предназначен для посылки прокси-сервером другому серверу при переадресации запроса Access-Request и должен быть возвращен в неизменном виде в сообщениях Access-Accept, Access-Reject или Access-Challenge. Этот атрибут должен быть удален прокси-сервером, до того как отклик будет переадресован серверу NAS. Использование атрибута Proxy-State зависит от реализации. Формат записи атрибута следует схеме, показанной на рис. .3. Поле тип = 33, а поле длина ³ 3.
Поле строка содержит один или более октетов. Действительный формат информации может варьироваться от узла к узлу и отличаться для разных приложений.
5.34. Атрибут Login-LAT-Service
Этот атрибут указывает на систему, с которой должен быть соединен пользователь посредством LAT (Local Area Transport). Он может использоваться в пакетах Access-Accept, но только когда в качестве услуги специфицирован LAT (локальный доступ). Атрибут может использоваться в пакетах Access-Request в качестве подсказки серверу, но сервер не обязан следовать этой рекомендации.
Администраторы используют атрибут сервиса, когда имеют дело с кластерными системами, такими как VAX или Alpha-кластер. В такой среде несколько процессоров совместно используют общие ресурсы (диски, принтеры и т.д.), и администраторы конфигурируют каждый из них для обеспечения к каждому из ресурсов. В этом случае каждая ЭВМ в кластере оповещает о предоставляемых услугах через широковещательные сообщения LAT.
Продвинутые пользователи часто знают, какие сервис-провайдеры (ЭВМ) обладают большим быстродействием и предпочитают использовать имя узла при установлении LAT-соединения. Некоторые администраторы хотели бы, чтобы определенные пользователи работали с определенными машинами, что представляет собой примитивную форму балансировки нагрузки (хотя LAT имеет собственную систему балансировки). Формат записи атрибута следует схеме, показанной на рис. .3. Поле тип = 34, а поле длина ³ 3.
Поле строка имеет один или более октетов и содержит идентификатор LAT-сервиса. Архитектура LAT позволяет этой строке содержать $ (доллар), - (дефис), . (точка), _ (подчеркивание), числа, буквы верхнего и нижнего регистров, а также расширенный символьный набор ISO Latin-1 [6]. Все сравнения в LAT не зависят от регистра символов.
5.35. Атрибут Login-LAT-Node
Этот атрибут указывает на узел, с которым пользователь должен быть соединен автоматически LAT. Атрибут может использоваться в пакетах Access-Accept, но только когда в качестве услуги подключения указан LAT. Он может быть применен в пакете Access-Request в качестве подсказки серверу, но сервер не обязан следовать этим рекомендациям. Формат записи атрибута следует схеме, показанной на рис. .3. Поле тип = 35, а поле длина
³ 3.
Поле строка имеет один или более октетов и содержит идентификатор узла LAT, с которым следует соединиться пользователю. Архитектура LAT позволяет этой строке содержать $ (доллар), - (дефис), . (точку), _ (подчеркивание), числа, буквы нижнего и верхнего регистров, а также расширяющий символьный набор ISO Latin-1. Все сравнения в LAT не зависят от регистра символов.
5.36. Атрибут Login-LAT-Group
Этот атрибут содержит строку, идентифицирующую групповой код LAT, который данный пользователь авторизован использовать. Атрибут может использоваться в пакетах Access-Accept, но только когда специфицирован LAT в качестве Login-Service. Он может быть использован в пакете Access-Request в качестве подсказки серверу, но сервер не обязан следовать этим рекомендациям. LAT поддерживает 256 различных групповых кодов, которые LAT использует как некую форму прав доступа. LAT преобразует эти групповые коды в 256 битовую карту соответствия (bitmap).
Администраторы могут приписать один или более бит группового кода сервис-провайдеру LAT. Он будет воспринимать соединения LAT, которые имеют установленные биты, соответствующие их групповым кодам. Администраторы присваивают битовую маску кодов авторизованных групп каждому пользователю. LAT получает эти маски-карты от операционной системы, и использует их в запросах к сервис-провайдерам. Формат записи атрибута следует схеме, показанной на рис. .3. Поле тип = 36, а поле длина = 34. Поле строка содержит 32-октетную маску-карту. Старший октет передается первым.
5.37. Атрибут Framed-AppleTalk-Link
Этот атрибут содержит сетевой номер AppleTalk, который должен быть использован для последовательного канала пользователя, являющимся маршрутизатором сети AppleTalk. Атрибут применяется только в пакетах Access-Accept. Он никогда не используется, когда пользователь не является маршрутизатором. Формат записи атрибута показан на рис. .6. Поле тип = 37, а поле длина =6.
Поле значение имеет 4 октета. Допустимый диапазон значений 0 - 65535. Специальное значение 0 указывает, что это ненумерованный последовательный канал. Значения 1-65535 обозначают, что последовательной линии между NAS и пользователем присвоен соответствующий сетевой номер AppleTalk.
5.38. Атрибут Framed-AppleTalk-Network
Этот атрибут представляет собой сетевой номер AppleTalk, который сервер NAS должен попытаться присвоить узлу AppleTalk. Атрибут используется только в пакетах Access-Accept. Атрибут никогда не используется, если пользователем является маршрутизатор. Многократное использование атрибута в пакете указывает на то, что NAS может попытаться использовать один из сетевых номеров, приведенных в атрибутах. Формат записи атрибута показан на рис. .6. Поле тип = 38, а поле длина =6.
Поле значение содержит 4 октета. Допустимый диапазон значений 0 - 65535. Специальное значение 0 указывает, что NAS должен назначить сеть для пользователя. Значения в интервале 1 - 65535 (включительно) указывает на сеть AppleTalk, адрес которой должен найти сервер NAS для пользователя.
5.39. Атрибут Framed-AppleTalk-Zone
Этот атрибут указывает на зону AppleTalk по умолчанию, которая должна использоваться для данного пользователя. Атрибут используется только в пакетах Access-Accept. Кратное использование атрибута в одном пакете не допускается. Формат записи атрибута показан на рис. .3. Поле тип = 39, а поле длина ³ 3. Поле строка содержит в себе имя зоны AppleTalk по умолчанию, которая должна использоваться для данного пользователя.
5.40. Атрибут CHAP-Challenge
Этот атрибут содержит сообщение CHAP Challenge, посланное сервером NAS в рамках диалога с пользователем CHAP PPP (Challenge-Handshake Authentication Protocol). Атрибут используется только в пакетах Access-Request. Если значение вызова CHAP содержит 16 октетов, оно может быть помещено в поле аутентификатора запроса, применение данного атрибута тогда уже не нужно. Формат записи атрибута показан на рис. .3. Поле тип = 60, а поле длина ³ 7. Поле строка содержит сообщение CHAP Challenge.
5.41. Атрибут NAS-Port-Type
Этот атрибут определяет тип физического порта NAS, где аутентифицируется пользователь. Атрибут может использоваться вместо или в добавление к атрибуту NAS-Port (5). Атрибут используется только в пакетах Access-Request. Атрибут NAS-Port (5) или NAS-Port-Type или оба должны применяться в пакетах Access-Request, если NAS различает порты. Формат записи атрибута показан на рис. .6. Поле тип = 61, а поле длина =6.
Поле значение имеет 4 октета. "Виртуальный" (в таблице 7) относится к соединению с NAS через некоторый транспортный протокол. Например, если пользователь осуществил удаленный доступ (telnet) в NAS, для того чтобы аутентифицировать себя как внешнего пользователя, запрос Access-Request может включать атрибут NAS-Port-Type = Virtual в качестве подсказки серверу RADIUS, что пользователь не является физическим портом.
Таблица .7.
Код поля значение атрибута NAS-Port-Type
Назначение
0
Async
1
Sync
2
ISDN Sync
3
ISDN Async V.120
4
ISDN Async V.110
5
Виртуальный
5.42. Атрибут Port-Limit
Этот атрибут устанавливает максимальное число портов, предлагаемых сервером NAS пользователю. Этот атрибут может быть послан сервером клиенту в пакете Access-Accept. Он предназначен для использования в среде многоканального PPP [7]. Он может также быть послан сервером NAS серверу в качестве подсказки того, что доступно большое число портов. Формат записи атрибута показан на рис. .6. Поле тип = 62, а поле длина = 6.
Поле значение имеет 4 октета и содержит 32-битовое целое число без знака, которое определяет максимальное число портов, к которым пользователь может быть подключен сервером NAS.
5.43. Атрибут Login-LAT-Port
Этот атрибут указывает порт, с которым должен быть соединен пользователь посредством LAT. Атрибут может использоваться в пакетах Access-Accept, но только когда LAT специфицирован в качестве услуг подключения. Он может использоваться в пакетах Access-Request в качестве подсказки серверу, но сервер может не следовать этой рекомендации. Формат записи атрибута показан на рис. .3. Поле тип = 63, а поле длина ³ 3.
Поле строка имеет один или более октетов и содержит идентификатор порта LAT, который следует использовать. Архитектура LAT позволяет этой строке содержать $ (доллар), - (дефис), . (точку), _ (подчеркивание), цифры, буквы верхнего и нижнего регистра, а также расширенный набор символов ISO Latin-1. Все сравнения в LAT не зависят от регистра символов.
5.44. Таблица атрибутов
В таблице собраны основные характеристики атрибутов, типы пакетов, где они используются, а также возможное число атрибутов в пакете.
Таблица .8.
Основные характеристики атрибутов
| Request | Accept | Reject | Challenge | # | Атрибут |
| 1 | 0 | 0 | 0 | 1 | User-Name |
| 0-1 | 0 | 0 | 0 | 2 | User-Password [*] |
| 0-1 | 0 | 0 | 0 | 3 | CHAP-Password [*] |
| 0-1 | 0 | 0 | 0 | 4 | NAS-IP-Address |
| 01 | 0 | 0 | 5 | NASPort | |
| 0-1 | 0-1 | 0 | 0 | 6 | Service-Type |
| 0-1 | 0-1 | 0 | 0 | 7 | Framed-Protocol |
| 0-1 | 0-1 | 0 | 0 | 8 | Framed-IP-Address |
| 0-1 | 0-1 | 0 | 0 | 9 | Framed-IP-Netmask |
| 0 | 0-1 | 0 | 0 | 10 | Framed-Routing |
| 0 | 0+ | 0 | 0 | 11 | Filter-Id |
| 0 | 0-1 | 0 | 0 | 12 | Framed-MTU |
| 0+ | 0+ | 0 | 0 | 13 | Framed-Compression |
| 0+ | 0+ | 0 | 0 | 14 | Login-IP-Host |
| 0 | 0-1 | 0 | 0 | 15 | Login-Service |
| 0 | 0-1 | 0 | 0 | 16 | Login-TCP-Port |
| 0 | 0+ | 0+ | 0+ | 18 | Reply-Message |
| 0-1 | 0-1 | 0 | 0 | 19 | Callback-Number |
| 0 | 0-1 | 0 | 0 | 20 | Callback-Id |
| 0 | 0+ | 0 | 0 | 22 | Framed-Route |
| 0 | 0-1 | 0 | 0 | 23 | Framed-IPX-Network |
| 0-1 | 0-1 | 0 | 0-1 | 24 | State |
| 0 | 0+ | 0 | 0 | 25 | Class |
| 0+ | 0+ | 0 | 0+ | 26 | Vendor-Specific |
| 0 | 0-1 | 0 | 0-1 | 27 | Session-Timeout |
| 0 | 0-1 | 0 | 0-1 | 28 | Idle-Timeout |
| 0 | 0-1 | 0 | 0 | 29 | Termination-Action |
| 0-1 | 0 | 0 | 0 | 30 | Called-Station-Id |
| 0-1 | 0 | 0 | 0 | 31 | Calling-Station-Id |
| 0-1 | 0 | 0 | 0 | 32 | NAS-Identifier |
| 0+ | 0+ | 0+ | 0+ | 33 | Proxy-State |
| 0-1 | 0-1 | 0 | 0 | 34 | Login-LAT-Service |
| 0-1 | 0-1 | 0 | 0 | 35 | Login-LAT-Node |
| 0-1 | 0-1 | 0 | 0 | 36 | Login-LAT-Group |
| 0 | 0-1 | 0 | 0 | 37 | Framed-AppleTalk-Link |
| 0 | 0+ | 0 | 0 | 38 | Framed-AppleTalk-Network |
| 0 | 0-1 | 0 | 0 | 39 | Framed-AppleTalk-Zone |
| 0-1 | 0 | 0 | 0 | 60 | CHAP-Challenge |
| 0-1 | 0 | 0 | 0 | 61 | NAS-Port-Type |
| 0-1 | 0-1 | 0 | 0 | 62 | Port-Limit |
| 0-1 | 0-1 | 0 | 0 | 63 | Login-LAT-Port |
/p> [*] Запрос Access- Request должен содержать пароль пользователя или CHAP-пароль, но не должен содержать и то и другое.
Ниже в таблице представлены обозначения, использованные в таблице 8.
Этого атрибута не должно быть в пакете.
0+
Атрибут может использоваться в пакете нуль или более раз.
0-1
Атрибут может использоваться в пакете нуль или один раз.
1
Атрибут должен присутствовать в пакете обязательно один раз.
6. Примеры
Предлагается несколько примеров для иллюстрации потока пакетов и использования типовых атрибутов.
6.1. Удаленный доступ пользователя на указанную ЭВМ (Telnet)
Сервер NAS с адресом 192.168.1.16 посылает запрос Access-Request в UDP пакете серверу RADIUS для пользователя с именем NEMO, подключаемого к порту 3.
Code = 1 (Access-Request)
ID = 0
Request Authenticator = {16-октетное случайное число}
Атрибуты:
User-Name = "NEMO"
User-Password = {16-октетный пароль, дополненный в конце нулями и объединенный операцией XOR с MD5(общий секретный пароль|Request Authenticator)}
NAS-IP-Address = 192.168.1.16
NAS-Port = 3
Сервер RADIUS аутентифицирует NEMO и посылает запрос Access-Accept в UDP пакете серверу NAS, требуя от него организации удаленного доступа пользователя NEMO к ЭВМ с заданным адресом.
Code = 2 (Access-Accept)
ID = 0 (то же самое, что и в Access-Request)
Response Authenticator = {16-октетная контрольная сумма MD-5 кода (2),
id (0), приведенного выше Request Authenticator, атрибутов этого отклика и общего секретного пароля }
Атрибуты:
Service-Type = Login-User
Login-Service = Telnet
Login-Host = 192.168.1.3
6.2. Кадровая аутентификация пользователя посредством CHAP
Сервер NAS с адресом 192.168.1.16 посылает запрос Access-Request в UDP-пакете серверу RADIUS для пользователя с именем VANYA для подключения к порту 20 в рамках протокола PPP. Аутентификация осуществляется посредством CHAP. NAS посылает атрибуты Service-Type и Framed-Protocol в качестве рекомендаций серверу RADIUS воспользоваться PPP, хотя NAS необязательно этому последует.
Code = 1 (Access-Request)
ID = 1
Request Authenticator = {16- октетное случайное число, используется также в вызове CHAP (CHAP challenge)}
Атрибуты:
User-Name = " VANYA"
CHAP-Password = {1 октет идентификатора CHAP, за которым следует 16 октетов CHAP-отклика}
NAS-IP-Address = 192.168.1.16
NAS-Port = 20
Service-Type = Framed-User
Framed-Protocol = PPP
Сервер RADIUS аутентифицирует VANYA и посылает запрос Access-Accept в UDP-пакете серверу NAS, сообщая, что он отрывает PPP-сессию и приписывает адрес пользователю из имеющегося у него списка.
Code = 2 (Access-Accept)
ID = 1 (тот же, что и в Access-Request)
Response Authenticator = {16-октетов контрольной суммы MD-5 кода (2), ID (1), Request Authenticator, приведенного выше, атрибутов этого отклика и общего секретного пароля}
Атрибуты:
Service-Type = Framed-User
Framed-Protocol = PPP
Framed-IP-Address = 255.255.255.254
Framed-Routing = None
Framed-Compression = 1 (Компрессия заголовка VJ TCP/IP)
Framed-MTU = 1500
6.3. Пользователь с картой вызова-отклика (Challenge-Response)
Сервер NAS с адресом 192.168.1.16 посылает запрос Access-Request серверу RADIUS для пользователя с именем MANYA, подключаемого к порту 7.
| Code = 1 | (Access-Request) |
Request Authenticator = {16 октетов случайного числа }
Атрибуты:
>User-Name = " MANYA"
User-Password = {16 октетов пароля дополненные в конце нулями,
объединенный функцией XOR с MD5 (общий секретный ключ |Request Authenticator)}
NAS-IP-Address = 192.168.1.16
NAS-Port = 7
Сервер RADIUS решает вызвать MANYA, отсылая назад строку вызова и ожидая отклика. Сервер RADIUS посылает запрос Access-Challenge серверу NAS.
| Code = 11 | (Access-Challenge} |
| ID = 2 | (тот же что и в Access-Request) |
Атрибуты:
Reply-Message = "Challenge 32769430. Enter response at prompt."
State = {Код, который должен быть прислан вместе с откликом пользователя }
Пользователь вводит свой отклик, а NAS посылает новый запрос Access-Request с этим откликом и атрибутом State.
| Code = 1 | (Access-Request) |
| ID = 3 | (Заметьте, что он изменяется) |
Атрибуты:
User-Name = " MANYA"
User-Password = {16 октетов отклика дополненного в конце нулями и объединенного функцией XOR с контрольной суммой MD5 общего секретного пароля и представленного выше аутентификатора запроса (Request Authenticator)}
NAS-IP-Address = 192.168.1.16
NAS-Port = 7
| State = | {Код из пакета Access-Challenge} |
| Code = 3 | (Access-Reject) |
| ID = 3 | (то же что и в Access-Request) |
Атрибуты:
(отсутствуют, хотя сообщение Reply-Message может быть послано)
На практике, с сервером RADIUS связывается база данных, где хранятся имена пользователей и соответствующие им секретные пароли. Конкретный именованный пользователь должен аутентифицироваться только одним способом. Это уменьшает возможности атаки путем согласования использования наименее безопасного метода аутентификации. Если пользователь нуждается в использовании разных аутентификационных методов в различных ситуациях, тогда следует данному пользователю в каждом из этих вариантов выступать под разными именами.
Пароли должны храниться в местах с ограниченным доступом. Эти данные должны быть доступны только процессам, которые с ними работают.
Ссылки
| [1] | Rivest, R., and S. Dusse, "The MD5 Message-Digest Algorithm", RFC 1321, MIT Laboratory for Computer Science, RSA Data Security Inc., April 1992. |
| [2] | Postel, J., "User Datagram Protocol", STD 6, RFC 768, USC/Information Sciences Institute, August 1980. |
| [3] | Reynolds, J., and J. Postel, "Assigned Numbers", STD 2, RFC 1700, USC/Information Sciences Institute, October 1994. |
| [4] | Kaufman, C., Perlman, R., and Speciner, M., "Network Security: Private Communications in a Public World", Prentice Hall, March 1995, ISBN 0-13-061466-1. |
| [5] | Jacobson, V., "Compressing TCP/IP headers for low-speed serial links", RFC 1144, Lawrence Berkeley Laboratory, February 1990. |
| [6] | ISO 8859. International Standard -- Information Processing -- 8-bit Single-Byte Coded Graphic Character Sets -- Part 1: Latin Alphabet No. 1, ISO 8859-1:1987. |
| [7] | Sklower, K., Lloyd, B., McGregor, G., and Carr, D., "The PPP Multilink Protocol (MP)", RFC 1717, University of California Berkeley, Lloyd Internetworking, Newbridge Networks Corporation, November 1994. |
| [8] | Galvin, J., McCloghrie, K., and J. Davin, "SNMP Security Protocols", RFC 1352, Trusted Information Systems, Inc., Hughes LAN Systems, Inc., MIT Laboratory for Computer Science, July 1992. |
| [9] | Rigney, C., "RADIUS Accounting", RFC 2139, January 1997. |
| [10] | B. Aboba, G. Zorn, RADIUS Authentication Client MIB. RFC-2618, June 1999. |
| [11] | G. Zorn, B. Aboba, RADIUS Authentication Server MIB. RFC-2619, June 1999. |
| [12] | B. Aboba, G. Zorn, RADIUS Accounting Client MIB. RFC-2620, June 1999. |
| [13] | G. Zorn, B. Aboba, RADIUS Accounting Server MIB. RFC-2621, June 1999. |
Система Firewall
6.3 Система Firewall
Семенов Ю.А. (ГНЦ ИТЭФ)

Учитывая важность проблемы защиты, разработана специальная система firewall ("огненная стена”). Система firewall заменяет маршрутизатор или внешний порт сети (gateway). Защищенная часть сети размещается за ним. Пакеты, адресованные Firewall, обрабатываются локально, а не просто переадресуются. Пакеты же, которые адресованы объектам, расположенным за Firewall, не доставляются. По этой причине хакер вынужден иметь дело с системой защиты ЭВМ Firewall. Схема взаимодействия Firewall с локальной сетью и внешним Интернет показана на рис. 6.3.1.
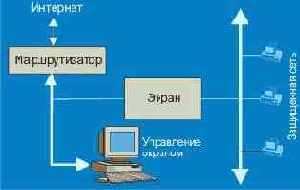
Рис. 6.3.1. Схема Firewall
Такая схема проще и надежнее, так как следует заботиться о защите одной машины, а не многих. Экран, маршрутизатор и ЭВМ управления экраном объединены небольшой, незащищенной локальной сетью. Основные операции по защите осуществляются здесь на IP-уровне. Эту схему можно реализовать и на одной ЭВМ, снабженной двумя интерфейсами. При этом через один интерфейс осуществляется связь с Интернет, а через второй – с защищенной сетью. Такая ЭВМ совмещает функции маршрутизатора-шлюза, экрана и управления экраном. Возможна реализация Firewall, показанная на рис 6.3.2. Здесь функция экрана выполняется маршрутизатором.
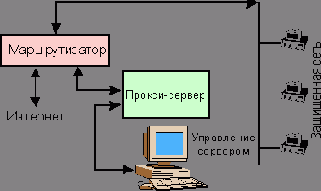
Рис. 6.3.2. Схема Firewall, где функцию экрана выполняет маршрутизатор
В этой схеме доступ из Интернет возможен только к прокси-серверу, ЭВМ из защищенной сети могут получить доступ к Интернет тоже только через прокси-сервер. Ни один пакет посланный из защищенной ЭВМ не может попасть в Интернет и, аналогично, ни один пакет из Интернет не может попасть непосредственно защищенной ЭВМ. Возможны и другие более изощренные схемы, например со вторым “внутренним” Firewall для защиты от внутренних угроз.
Недостатки FireWall происходят от ее преимуществ, осложняя доступ извне, система делает трудным и доступ наружу. По этой причине система FireWall должна выполнять функции DNS (сервера имен) для внешнего мира, не выдавая никакой информации об именах или адресах внутренних объектов, функции почтового сервера, поддерживая систему псевдонимов для своих клиентов. Псевдонимы не раскрываются при посылке почтовых сообщений во внешний мир. Служба FTP в системе может и отсутствовать, но если она есть, доступ возможен только в сервер FireWall и из него. Внутренние ЭВМ не могут установить прямую FTP-связь ни с какой ЭВМ из внешнего мира. Процедуры telnet и rlogin возможны только путем входа в сервер FireWall. Услуги типа NFS, rsh, rcp, finger и т.д. не допускаются. Ни одна из ЭВМ в защищенной сети не может быть обнаружена с помощью PING (ICMP) извне. И даже внутри сети будут возможны только определенные виды трафика между строго определенными машинами. Понятно, что в целях безопасности защищенная сеть не может иметь выходов во внешний мир помимо системы экран, в том числе и через модемы. Экран конфигурируется так, чтобы маршрут по умолчанию указывал на защищенную сеть. Экран не принимает и не обрабатывает пакеты внутренних протоколов маршрутизации (например, RIP). ЭВМ из защищенной сети может адресоваться к экрану, но при попытке направить пакет с адресом из внешней сети будет выдан сигнал ошибки, так как маршрут по умолчанию указывает назад в защищенную сеть. Для пользователей защищенной сети создаются специальные входы для FTP (см. библиографию раздела 6 “Сетевая безопасность в Интернет”), telnet и других услуг. При этом не вводится каких-либо ограничений по транспортировке файлов в защищенную сеть и блокируется передача любых файлов из этой сети, даже в случае, когда инициатором FTP-сессии является клиент защищенной сети. Единственные протоколы, которым всегда позволен доступ к ЭВМ Firewall являются SMTP (электронная почта) и NNTP (служба новостей). Внешние клиенты Интернет не могут получить доступа ни к одной из защищенных ЭВМ ни через один из протоколов. Если нужно обеспечить доступ внешним пользователям к каким-то данным или услугам, для этого можно использовать сервер, подключенный к незащищенной части сети (или воспользоваться услугами ЭВМ управления экраном, что нежелательно, так как снижает безопасность). ЭВМ управления экраном может быть сконфигурирована так, чтобы не воспринимать внешние (приходящие не из защищенной сети) запросы типа FTP, telnet и пр., это дополнительно повысит безопасность. Стандартная система защиты здесь часто дополняется программой wrapper (см. раздел 6 “Сетевая безопасность в Интернет”). Немалую пользу может оказать и хорошая система регистрации всех сетевых запросов. Системы FireWall часто используются и в корпоративных сетях, где отдельные части сети удалены друг от друга. В этом случае в качестве дополнительной меры безопасности применяется шифрование пакетов. Система FireWall требует специального программного обеспечения. Следует иметь в виду, что сложная и дорогостоящая система FireWall не защитит от “внутренних” злоумышленников. Нужно тщательно продумать систему защиты модемных каналов (сама система FireWall на них не распространяется, так как это не внешняя часть сети, а просто удаленный терминал).
Если требуется дополнительная степень защиты, при авторизации пользователей в защищенной части сети могут использоваться аппаратные средства идентификации, а также шифрование имен и паролей.
При выборе той или иной системы Firewall следует учитывать ряд обстоятельств.
Операционная система. Существуют версии Firewall, работающие с UNIX и Windows NT. Некоторые производители модифицируют ОС с целью усиления безопасности. Выбирать следует ту ОС, которую вы знаете лучше.
Рабочие протоколы. Все Firewall могут работать с FTP (порт 21), e-mail (порт 25), HTTP (порт 80), NNTP (порт 119), Telnet (порт 23), Gopher (порт 70), SSL (порт 443) и некоторыми другими известными протоколами. Как правило, они не поддерживают SNMP.
Типы фильтров. Сетевые фильтры, работающие на прикладном уровне прокси-сервера, предоставляют администратору сети возможность контролировать информационные потоки, проходящие через Firewall, но они обладают не слишком высоким быстродействием. Аппаратные решения могут пропускать большие потоки, но они менее гибки. Существует также “схемный” уровень прокси, который рассматривает сетевые пакеты, как черные ящики и определяет, пропускать их или нет. Отбор при этом осуществляется по адресам отправителя, получателя, номерам портов, типам интерфейсов и некоторым полям заголовка пакета.
Система регистрации операций. Практически все системы Firewall имеют встроенную систему регистрации всех операций. Но здесь бывает важно также наличие средств для обработки файлов с такого рода записями.
Администрирование. Некоторые системы Firewall снабжены графическими интерфейсами пользователя. Другие используют текстовые конфигурационные файлы. Большинство из них допускают удаленное управление.
Простота. Хорошая система Firewall должна быть простой. Прокси-сервер (экран) должен иметь понятную структуру и удобную систему проверки. Желательно иметь тексты программ этой части, так как это прибавит ей доверия.
Туннелирование. Некоторые системы Firewall позволяют организовывать туннели через Интернет для связи с удаленными филиалами фирмы или организации (системы Интранет). Естественно, что информация по этим туннелям передается в зашифрованном виде.
Информацию по системам Firewall можно найти по следующим адресам.
URL
Содержание
http://search.netscape.com/eng/mozilla/2.0/relnotes/demo/proxy-live.html Автоматическая конфигурация прокси для Netscape и Microsoft броузеров http://www.software.digital.com Alta Vista Firewall http://www.cyberguardcorp.com/ CyberGuard Firewall http://www.raptor.com/ Eagle Firewall http://www.checkpoint.com/ Firewall-1 http://www.tis.com/ Gauntlet Firewall http://www.on.com/ ON Guard Firewall http://www.sctc.com BorderWare Firewall ftp://ftp.nec.com/pub/socks/ SOCKS прокси ftp://ftp.tis.com/pub/firewalls/toolkit Средства для работы с Firewall majordomo@greatcircle.com Подписной лист по проблематике Firewall. Для подписки в тело сообщения следует поместить subscribe firewall. Там же имеется архив: http://www.greatcircle.com/firewalls
Система поиска файлов Archie
4.5.13 Система поиска файлов Archie
Семенов Ю.А. (ГНЦ ИТЭФ)
ARCHIE - информационная система с наиболее эффективной системой поиска. Система разработана Аланом Эмтейджем, Питером Дойчем и Билом Хееланом из университетского вычислительного центра McGill, Канада. ARCHIE осуществляет поиск по более чем 1000 депозитариям мира допускающим анонимный доступ и содержащим более 2100000 файлов. ARCHIE работает под Windows, MS-DOS, Macintosh, Unix в рамках сети INTERNET. Рекомендуется следовать следующим правилам (в последнее время система стала менее популярна, ее функции взяли на себя поисковые сервера):избегайте проводить поиск в рабочие часы, так как большинство ARCHIE- серверов выполняют и другие локальные функции.
запросы должны быть как можно конкретнее, это ускорит их выполнение.
интерфейс на вашей ЭВМ снизит нагрузку удаленных серверов, поэтому рекомендуется использовать локальные интерфейсы.
используйте ближайший к вам ARCHIE-сервер, это сократит нагрузку телекоммуникационных каналов и повысит надежность поиска.
Базы данных ARCHIE располагаются по адресам:
Имеется возможность доступа к ARCHIE через локальный клиент-сервер, через команду telnet или с помощью электронной почты. В настоящее время доступна версия сервера 3.0. Команды, помеченные ниже (+) работают только с версией 3.0, помеченные же (*), работают только с предшествующими версиями. Для определения версии, с которой вы работаете, выдайте команду version. Локальные серверы работают быстрее и надежнее. В публичном доступе имеются версии для MS-DOS, OS/2, VMS, NeXT, Unix, X-windows и Macintosh. Клиент-серверы доступны через анонимный FTP в каталогах /pub/archie/clients ли /archie/clients, обычно это строчные варианты. Существует и графическая версия (xarchie) для X-windows. Стандартное обращение к ARCHIE имеет форму:
ARCHIE <-options> последовательность символов | образ
где options могут быть:
| o | определяет имя выходного файла для запоминания результата. |
| l | список найденных объектов по одной строке на документ. |
| t | сортирует результат поиска по датам. |
| m# | определяет максимальное число найденных документов (# от 0 до 1000), по умолчанию это число равно 95. |
| H archie-server | специфицирует сервер, куда посылается запрос, в отсутствии этого параметра используется сервер по умолчанию, если такой описан. |
| L | список известных серверов, включая текущий. |
Known archie servers:
archie.ans.net (USA [NY])
archie.rutgers.edu (USA [NJ])
archie.sura.net (USA [MD])
archie.unl.edu (USA [NE])
archie.mcgill.ca (Canada)
archie.funet.fi (Finland/Mainland Europe)
archie.au (Australia)
archie.doc.ic.ac.uk (Great Britain/Ireland)
archie.wide.ad.jp (Japan)
archie.ncu.edu.tw (Taiwan)
* archie.funet. fi is the default Archie server.
* For the most up-to-date list, write to an Archie server and give it the command `servers'.
Следующая группа options определяет разновидность поиска.
| s | объект будет выбран, если имя файла/каталога содержит заданную последовательность символов. Поиск не зависит от того, строчные или заглавные буквы использованы в эталонной последовательности. |
| c | как и выше, но для поиска не безразличны строчные/заглавные буквы. |
| e | последовательность символов должна точно совпадать с образцом, с учетом использования заглавных и строчных символов. Это способ поиска по умолчанию. |
| r | поиск образов, которые включают в себя специальные символы, интерпретируемые до начала поиска. |
Для интерактивного попадания в ARCHIE-сервер используется команда telnet, в ответ на login следует ввести archie. Для того чтобы покинуть ARCHIE-сервер используются команды: exit, quit, bye. Кроме того, существуют следующие команды:
| help ? | Выдает полный список команд |
| help <имя команды> | Выдает описание команды, возврат с помощью клавиши <Enter>. |
| help set variable | Выдает описание присвоения значения системной переменной. |
| list <образ> | Выдает список IP-адресов баз данных и дат их последней коррекции. Параметр, если он присутствует, обеспечивает отбор адресов с учетом соответствия этому параметру. Если нет параметра, то список будет содержать около 1000 адресов. list \.de$ даст адреса в Германии. |
| manpage | Отображение страницы руководства по использованию Archie |
| servers | Выдает список серверов Archie |
| site (*) site-name | Получение списка каталогов и субкаталогов депозитария с именем site-name. Обычно это очень длинный список. |
| whatis <строка> | Осуществляет поиск описания программы для string. |
| prog <строка>|<образ> find(+)<строка>|<образ> | Осуществляет поиск строки <строка> или образа <образ>, представляющий название искомого ресурса. Поиск может выполняться несколькими способами, определяемыми переменной search (команда set), которая также определяет, следует ли интерпретировать параметр как string или pattern. Результат представляет собой список FTP- адресов, размеров найденных объектов и дат последней модификации. Число объектов в списке ограничивается переменной maxhits (команда set). Результат prog может быть отсортирован в соответствии с величиной переменной sortby (команда set). По умолчанию переменные search, maxhits и sortby устанавливаются соответственно на точное соответствие string, 1000 объектов без сортировки результата |
| mail <email> <,email2...> | Отсылает результат поиска по электронной почте по заданному адресу. При команде без параметров результат отсылается по адресу, заданному переменной mailo (команда set). |
| show <переменная> | Отображает значение переменной с данным именем. В отсутствии параметра отображаются все переменные. |
| set <переменная> <значение> | Устанавливает значение одной из переменных ARCHIE. |
/p> Используются следующие переменные:
compress(+) метод_архивации
Задает метод архивации (none или compress), используется до отправки почты командой mail. По умолчанию none.
encode(+) метод_кодирования
Определяет метод кодирования (none или uuencode), используется при отправке по почте. Эта переменная игнорируется, если компрессии нет. По умолчанию none.
mailo email <,email2...>
Определяет e-mail адрес, куда будет послан результат, при выдаче команды без аргумента.
maxhits number
Определяет максимальное число отобранных объектов командой prog (0-1000). По умолчанию эта переменная равна 1000.
search search-value
Определяет вид проводимого поиска: prog string | prog string | pattern. search-values равны:
| sub | Частичное совпадение и независимость от заглавная/сточная. |
| subcase | То же, но не безразлично заглавный/сточный символы. |
| exact | Точное соответствие образцу. |
| regex pattern | Интерпретируется перед началом поиска. |
| sortby sort-value | Описывает то, как сортировать результаты поиска по команде prog. Значения sort-values (параметр сортировки): |
| hostname | Сортировка по FTP-адресам в лексическом порядке |
| time | Сортировка по дате модификации, более поздние сначала. |
| filename | Сортировка по именам файлов или каталогов в лексическом порядке |
| none | Никакой сортировки |
| size | Сортировка документов по размеру |
Сообщает ARCHIE, какой терминал используется.
Доступ через электронную почту
Пользователи могут получить доступ к ARCHIE через электронную почту, послав запрос по адресу archie@archie.ac.il. Команды посылаются в теле сообщения. Командные строки начинаются всегда с первой колонки. Поле subject рассматривается как строка самого сообщения. При этом допустимы следующие команды:
| help | Присылает файл HELP, при этом другие команды сообщения игнорируются. |
| path return-address set mailto(+) return-address | Определяет обратный адрес, отличный от того, что записан в заголовке |
| list pattern <pattern2...> | Выдает список адресов, где есть данные, соответствующие pattern, наиболее свежие по дате |
| site(*) site-name | Выдает список каталогов и субкаталогов по адресу site-name |
| whatis string <string2...> | Ищется в базе данных описание программных продуктов, где содержится string. Прописные или строчные буквы роли не играет |
| prog pattern <pattern2...> find(+) pattern <pattern2> | Поиск всех упоминаний ресурсов с именем pattern. Если несколько pattern помещено в одной строке, результат поиска будет прислан в одном сообщении. Если несколько prog помещено в строке, результат присылается в нескольких сообщениях, по одному на каждый prog. Результат представляет собой список адресов для FTP. Если pattern содержит пробелы, он должен быть заключен в кавычки. Поиск не зависит от того, заглавные или строчные буквы использованы в запросе. |
| compress(*) | Полученный результат будет архивирован и перекодирован с помощью uuencode. В результате будет получен файл с расширением .Z. Сначала по получении сообщения следует обработать с помощью uudecode, а после этого следует выполнить программу uncompress |
| set compress(+) compress-method | Специфицирует метод архивирования (none или compress) перед отправкой по почте. По умолчанию none |
| set encode(+) encode-method | Специфицирует метод кодирования (none или uuencode) перед отправкой по почте. По умолчанию none. |
| quit | Ничего не производит, полезна в случае автоматического добавления подписи в конце сообщения. |
| Description of pattern pattern | Описывает последовательность символов, включая специальные символы. Символ перестает быть специальным, если перед ним стоит "\". |
/p> К числу специальных символов относится:
| . (точка) | Заменяет любые другие символы (wildcard). |
| ^ | Появляется в начале pattern. При этом будет искаться будет последовательность, следующая за "^". Например: "^efgh" узнает "efgh" или "efghij" но не "abcdefgh". |
| $ | Появляется в конце pattern. Так, например: "efghi$" узнает "efghi" или "abcdefghi" но не узнает "efghijkl". |
| alice.fmi.uni-passau.de | 132.231.1.180 | 12:31 | 8 Aug 1993 |
| askhp.ask.uni-karlsruhe.de | 129.13.200.33 | 12:25 | 8 Aug 1993 |
| athene.uni-paderborn.de | 131.234.2.32 | 15:21 | 6 Aug 1993 |
| bseis.eis.cs.tu-bs.de | 134.169.33.1 | 00:18 | 31 Jul 1993 |
| clio.rz.uni-duesseldorf.de | 134.99.128.3 | 12:10 | 8 Aug 1993 |
| cns.wtza-berlin.de | 141.16.244.4 | 16:08 | 31 Jul 1993 |
Если вы пошлете команду whatis compression по почте или посредством Telnet, вы получите следующий результат:
| RFC 468 | Braden, R.T. FTP data compression 1973 March 8; 5p. |
| arc | PC compression program |
| deltac | Image compression using delta modulation |
| spl | Splay tree compression routines |
| squeeze | A file compression program |
| uncrunch | Uncompression program |
| unsqueeze | Uncompression programs (Пример взят из [1]) |
| Host goliat.eik.bme.hu | (152.66.115.2) |
Location: /pub/win3/util
FILE -r--r--r-- 145312 bytes 11:18 22 Dec 1994 amps13.zip
| Host nic.switch.ch | (130.59.1.40) |
Location: /mirror/novell/netwire/novuser/01
FILE -rw-rw-r-- 177681 bytes 02:14 1 Nov 1994 amps15.zip
| Host faui43.informatik.uni.erlangen.de | (131.188.1.43) |
Location:
/mounts/epix/public/pub/pc/windows/cica_mirror/util
FILE -r--r--r-- 145312 bytes 00:00 2 Jun 1994 amps13.zip
| Host ftp.luth.se | (130.240.16.39) |
Location: /pub/msdos/.1/.util
FILE -r--r--r-- 145312 bytes 01:00 1 Jun 1994 amps13.zip
| Host ftp.cyf | kr.edu.pl (149.156.1.8) |
Location: /pub/mirror/ami/chipset_guides
FILE -rw-r--r-- 111858 bytes 00:00 4 Apr 1994 scampsx.z06
FILE -rw-r--r-- 46677 bytes 00:00 4 Apr 1994 scampsx.z07
Это лишь фрагмент выдачи реально она много длиннее. Видно, что один и тот же документ найден в нескольких депозитариях. Если у вас есть вопросы об ARCHIE, пишите Archie Group, Bunyip Information Systems Inc. по адресу info@bunyip.com. В случае обнаружения ошибок, а также с комментариями следует обращаться по адресу archie-admin@bunyip.com. По вопросам, связанным с конкретными серверами можно обратиться по адресу archie-admin@address.of.archie.server, например, archie-admin@archie.ac.il. Список адресов для рассылки информации находится по адресу: archie-people@bunyip.com; для включения в подписной лист можно послать запрос по адресу: archie-people-request@bunyip.com.
Система поиска NETFIND
4.5.8.4 Система поиска NETFIND
Семенов Ю.А. (ГНЦ ИТЭФ)
NETFIND представляет собой прикладную программу для работы со справочниками и каталогами. Получив имя человека и некоторые данные о том, где он работает, NETFIND пытается найти его номер телефона, электронный адрес, используя базу данных доменов seed. NETFIND ищет информацию о людях с помощью Интернет-протоколов SMTP и finger. Netfind работает на ЭВМ SUN OS 4.0 или более новых. Могут быть найдены только лица, имеющие доступ к Интернет. Существует возможность работы с NETFIND через электронную почту. Доступ через telnet возможна по адресам (login: netfind):Место работы искомого человека может быть описано ключевыми словами. NETFIND просматривает свою базу данных seed, чтобы найти домен, отвечающий критериям отбора. Список таких доменов отображается и вам предлагается выбрать из них 1-3. Если обнаружено более 100 доменов, NETFIND выдаст имена некоторых из них и предложит повторить поиск с более жесткими условиями. Можно использовать часть названия организации или домена в качестве эталона в процессе поиска. При использовании более чем одного эталона можно применить знак логической операции AND. По завершении поиска или при прерывании его с помощью ^C NETFIND выдает полученный результат. Предлагаются не только данные о домене или организации, но и даты последних входов искомого человека в систему. Обращение к NETFIND имеет формат:
netfind <опции> фамилия (имя) место работы (ключевые слова)
где допустимы следующие опции:
-h |
Указывает NETFIND обойти фазу поиска домена и немедленно начать поиск индивидуальной ЭВМ в базе seed. Эта функция редко используется обычными пользователями |
-s |
Исключает применение протокола SMTP при поиске. Поиск происходит немного быстрее, но дает не полную информацию, так как не все ЭВМ пользователей поддерживают протокол finger |
-t |
Сообщает сколько случилось таймаутов. -T опция устанавливает время таймаута равным заданному числу секунд, что позволяет увеличить это время в некоторых случаях |
-D |
Устанавливает максимальное число доменов, где будет проводиться поиск. По умолчанию эта величина равна 3 (большее значение устанавливать не рекомендуется). Правильный выбор этого числа заметно ускоряет процесс поиска и снижает нагрузку на сеть. |
-H |
Устанавливает максимальное число ЭВМ, где будет проводиться поиск. По умолчанию это число равно 50. Устанавливать большую величину не рекомендуется |
-m |
Отображает измерительную информацию. Если не указано имя файла, то вывод производится в файл stderr |
-d |
Позволяет устанавливать различные классы отладочного вывода (в stderr), используя соответствующую букву для каждого из них, напр. -dsf. Могут использоваться любые комбинации этих букв |
| c: | Отображает управляющие сообщения (позволяет контролировать, какой точки достигла программа). |
| f: | Отображает сообщения, связанные с finger. |
| h: | Выдает список ЭВМ, найденных в базе данных seed. |
| m: | Отображает сообщения протокола SMTP. |
| n: | Отображает сообщения о неисправности сети. |
| r: | Отображает имена ЭВМ из базы seed, которые были отброшены из-за выбора search scope. |
| s: | Отображает системные сообщения. |
| t: | Отображает сообщения, связанные с thrread. |
| tn nic.uakom.sk | (обращение к серверу в Словакии) | |
| SunOS UNIX (nic) | (произошло соединение) | |
| login: | netfind | (подключаемся к NETFIND-серверу, далее следует текст, выдаваемый сервером) |
Slovakia, Banska Bystrica
Welcome to the Netfind server
questions/problems : Lubos.Elias@uakom.sk
Alternate Netfind servers:
I think that your terminal can display 24 lines. If this is wrong, please enter the "Options" menu and set the correct number of lines. (Если ваш терминал не работает с 24 строками, обратитесь в раздел "Options" и установите верное значение).
| Top level choices: | (Выдано базовое меню) |
| 1. Help (Запрос справочной информации) | |
| 2. Search (Поиск) | |
| 3. Seed database lookup (просмотр базы данных SEED) | |
| 4. Options (Дополнительные возможности) | |
| 5. Quit (exit server) (Уход из сервера) | |
| --> | 1 (Запрошена справочная информация) |
| 1. Netfind search help (Работа с NETFIND) | |
| 2. Usage restrictions (Используемые команды) | |
| 3. Frequently asked questions (Часто задаваемые вопросы) | |
| 4. For more information (Дополнительная информация) | |
| 5. Quit menu (back to top level) (Возврат в предыдущее меню) | |
| --> | 1 (Запрошена информация о работе с NETFIND) |
По имени и приблизительному описанию места работы Netfind пытается найти информацию о данном лице. В качестве имени может быть введена фамилия или имя. Одновременно могут быть выданы ключевые слова: место работы, имя домена, город или страна. Найдя домен, Netfind отображает список доменов и просит вас выбрать от одного до трех из них, где следует провести поиск.
Поиск проходит в два этапа. На первом - Netfind выполняет поиск в каждом из выбранных доменов. На втором этапе проводится более детальное исследование с помощью finger. Имеется возможность прервать поиск с помощью ^C.
По завершении знакомства со справочной информации система возвращается к базовому меню. На этот раз выбираем пункт 2 (Поиск). Система выдает предупреждение:
| NOTE: | Received no responses, and some host or network failures occurred. Maybe try this search again later. (В случае неуспеха можно позднее попытать счастья снова). |
Enter person and keys (blank to exit) --> Burov DESY Germany
(Введено задание на поиск: фамилия, место работы, страна)
Найдено три домена, отвечающие критериям отбора.
Please select at most 3 of the following domains to search:
(предлагается провести поиск по этим трем доменам)
| 0. | desy.de (desy zeus central data acquisition, germany) |
| 1. | dsyibm.desy.de (desy, hamburg, germany) |
| 2. | info.desy.de (desy zeus central data acquisition, germany) |
(введен список доменов, где будет проведен поиск)
( 3) SMTP_Finger_Search: checking domain dsyibm.desy.de
( 3) do_connect:
Finger service not available on host dsyibm.desy.de -> cannot do user lookup.
(Поиск с помощью Finger не доступен на dsyibm.desy.de)
( 1) SMTP_Finger_Search: checking domain info.desy.de
( 2) got nameserver operator.desy.de
( 2) got nameserver sun01a.desy.de
( 2) SMTP_Finger_Search: checking domain desy.de
Mail for Sergei Bourov is forwarded to burov@x4u2.desy.de
Поиск завершился успехом - найден адрес, куда пересылается почта для Бурова, далее на экран выводится следующий текст:
NOTE:
this is a domain mail forwarding arrangement to an outside domain, possibly indicating that "burov" has moved to another department or institution. Hence, mail should be addressed to "burov@x4u2.desy.de" (почта должна посылаться Бурову по адресу).
( 1) SMTP_Finger_Search: checking host x4u2.desy.de
SYSTEM: x4u2.desy.de
| Login name: burov In real life: | Sergei Bourov | |
| (Полное имя: Сергей Буров) | ||
| Office: 1d/39, 2081/2747 | Home phone: none |
/p> Directory: /home/dice/burov Shell: /bin/zsh
Last login at Tue Sep 26 09:04 from UNKNOWN@AXDSYB.desy.de
(последний раз входил в систему во вторник 26-го сентября)
No Plan.
FINGER SUMMARY (результат исследования с помощью Finger):
- Remote user queries (finger) were not supported on host(s) searched in the domain 'dsyibm.desy.de'.
- The most promising email address for "burov" based on the above finger search is burov@x4u2.desy.de.
Continue the search ([n]/y) ? --> n (хотим ли мы продолжить поиск?)
При удаленном доступе к NETFIND имеется служба HELP. В секции каталога DOC обычно имеется также файл "часто задаваемые вопросы" (frequently asked questions - FAQ). Большую пользу может оказать статья "Experience with a Semantically Cognizant Internet White Pages Directory Tool", написанная M.F.Schwartz и P.G.Tsirigotis, Journal of Internetworking Research and Experience, март 1991, стр. 23-50. Существует список адресов подписчиков NETFIND. Для включения вас в этот список необходимо послать запрос по адресу netfind-users-request@cs.colorado.edu, где в тексте сообщения (не в строке subject!) написать: subscribe netfind-users. Исчерпывающую информацию о NETFIND можно найти посредством:
FTP ftp.cs.colorado.edu /pub/cs/distribs/netfind
WWW www.earn.net gnrt/netfind.html alpha.acast.nova.edu netfind.html
Telnet ds.internic.net (Login: netfind).
Системы шифрования
6.4 Системы шифрования
Семенов Ю.А. (ГНЦ ИТЭФ)
Проблема сокрытия содержания послания при его транспортировке волновала людей с древних пор. Известно, что еще Цезарь (100-44 годы до нашей эры) при переписке использовал шифр, получивший его имя. В 1518 году Джоанес Тритемиус написал первую книгу по криптографии, где впервые были описаны многоалфавитные подстановочные шифры. Лишь в 1918 году во время первой мировой войны в Германии была применена шифровальная система ADFGVX. Позднее в 1933-45 годах в Германии была разработана и применена первая шифровальная машина (на этом принципе работает система crypt в UNIX). Мощное развитие криптография получила в период второй мировой войны. С этой шифровальной машиной связан и первый успех в области вскрытия сложных шифров.Чаще всего шифруются тексты документов, но в последнее время шифрованию подвергаются и изображения, голосовые данные и даже тексты программ.
Шифрование предполагает преобразование исходного текста Т с использованием ключа К в зашифрованный текст t. Симметричные криптосистемы для шифрования и дешифрования используется один и тот же ключ К. Появившиеся в последние годы системы с открытым ключом, осуществляют шифрование с помощью общедоступного ключа, для дешифрования в этом случае необходим секретный ключ, который порождается совместно с открытым. Как шифрование, так и дешифрование может реализоваться программно или аппаратно. При этом должны выполняться определенные требования:
Знание использованного алгоритма не должно снижать надежность шифрования.
Длина зашифрованного текста должна быть равна длине исходного открытого текста (это требование относится к числу желательных и выполняется не всегда).
Зашифрованный текст не может быть прочтен без знания ключа.
Каждый ключ из многообразия ключей должен обеспечивать достаточную надежность.
Изменение длины ключа не должно приводить к изменению алгоритма шифрования.
Если известен зашифрованный и открытый текст сообщения, то число операций, необходимых для определения ключа, не должно быть меньше полного числа возможных ключей.
Дешифрование путем перебора всех возможных ключей должно выходить далеко за пределы возможностей современных ЭВМ.
Если при шифровании в текст вводятся дополнительные биты, то алгоритм их внесения должен быть надежно скрыт.
Не должно быть легко устанавливаемой зависимости между последовательно используемыми ключами.
Алгоритм может быть реализован аппаратно.
В симметричных криптосистемах могут использоваться одно- или многоалфавитные подстановки (например, одно-алфавитная подстановка Цезаря), при этом производится замена символов исходного текста на другие с использованием достаточно сложных алгоритмов. Многоалфавитные подстановки несравненно более надежны. К числу простых методов шифрования относится способ перестановок символов исходного текста (этот метод эффективен только лишь при достаточно большой длине исходного текста). Множество перестановок символов для текста из N символов равно N!, что до какой-то степени гарантирует надежность процедуры. Несколько большую надежность предлагает метод гаммирования, когда на исходный текст накладывается псевдослучайная последовательность бит, генерируемая на основе ключа шифрования, например, с использованием операции исключающего ИЛИ. Обратное преобразование (дешифрование) выполняется генерацией точно такой же псевдослучайной последовательности и наложением ее на зашифрованной текст. Гаммирование уязвимо для случая, когда злоумышленнику становится известен фрагмент исходного текста. В этих обстоятельствах он без труда восстановит фрагмент псевдослучайной последовательности, а по нему и всю последовательность. Так если достаточно большое число сообщений начинается со слов "Секретно", а в конце ставится дата сообщения, расшифровка становится вопросом времени и терпения.
Ключ может быть одноразового и многоразового использования. Одноразовый ключ достаточно большой длины (или бесконечный) может обеспечить сколь угодно высокую надежность, но его использование создает неудобства, связанные с его транспортировкой (ключ должен быть как-то доставлен получателю зашифрованного послания). В табличке 6.4.1 приведен пример использования такого вида ключа.
Таблица 6.4.1.
Примером шифрования с использованием секретного ключа является метод Видженера (Vigenere; www.massconfusion.com/crypto/lecture/method6.shtml), относящийся к числу много алфавитных подстановок. Здесь берется небольшое целое число m и алфавит после каждой символьной подстановки сдвигается на m символов. Например, для m=4
1. abcdefghijklmnopqrstuvwxyz
ghijklmnopqrstuvwxyzabcdef
2. opqrstuvwxyzabcdefghijklmn
3. lmnopqrstuvwxyzabcdefghijk
4. fghijklmnopqrstuvwxyzabcde
Ключ = golf (смотри левую вертикальную колонку символов).
Исходный текст разбивается на группы по m символов (в рассмотренном случае по 4). Для каждой группы первый символ заменяется соответствующей буквой первого алфавита, вторая – из второго и т.д. Например, фраза "get me out of here please" будет преобразована следующим образом:
getm eout ofhe repl ease
mser kcfy utsj xsaq kohj.
Наибольшее распространение в последнее время получило блочное шифрование, где последовательность процедур воздействует на блок входного текста. Одним из наиболее известных таких методов стал DES (Data Encryption Standard), который работает с блоками данных по 64 байта (1998 год). Существует четыре режима работы:
| ECB | electronic code book. |
| CBC | cipher block chaining |
| CFB | cipher feedback |
| OFB | output feedback. |
Шифрование и дешифрование базируются на использовании ключей. Математически это можно выразить следующим образом (cм. lglwww.epfl.ch/~jkienzle/digital_money/node11.html; www.ee.mtu.edu/courses/ ee465/groupa/overview.html):
EK(M) = C
DK(c) = M, где K – ключ, M – исходный текст; C – зашифрованный текст.
Эффективность системы шифрования определяется числом кодовых комбинаций или ключей, которое необходимо перебрать, чтобы прочесть зашифрованный текст. Существует две системы ключей шифрования/дешифрования. Для симметричных алгоритмов предполагается, что ключ дешифрования может быть вычислен по известному ключу шифрования. Оба ключа при этом должны быть секретными (например, система DES). Отправитель и получатель должны знать ключи до начала обмена (эти ключи могут и совпадать). Набор таких ключей может быть достаточно большим и в процессе инициализации осуществляется выбор пары ключей, которые будут использованы в данной сессии. В общем случае могут использоваться довольно большие кодовые таблицы, но такая схема неудобна для многоточечного обмена.
Шифры бывают поточными и блочными. В первом случае обработка исходного текста производится побитно или побайтно. Во втором – текст перед обработкой разбивается на блоки.
Асимметричные схемы шифрования/дешифрования предполагают существования независимых ключей для шифрования и дешифрования. Причем один не может быть получен из другого и наоборот. В идеале ключ дешифровки не может быть получен из шифрующего ключа за любое разумное время. В этом случае ключ шифрования может быть сделан общедоступным (например, алгоритм RSA). Партнеры до начала коммуникаций должны послать друг другу ключи шифрования КШО и КШП (ключи шифрования отправителя и получателя). Возможность перехвата таких ключей опасности не представляет. Дешифрование выполняется с помощью ключей КДО и КДП, которые образуют пары с КШО и КШП соответственно и формируются совместно. Ключи КШО и КШП обычно пересылаются на фазе инициализации сессии информационного обмена.
Шифрование может осуществляться по определенным правилам с помощью таблиц шифрования или ключей. При этом могут использоваться самые разные алгоритмы, в том числе, например, перемещение символов текста определенным образом. За свою историю люди придумали достаточно большое число способов шифрования. Новейшие из них базируются на методиках, заимствованных из теории чисел. По этой причине, прежде чем переходить к следующему разделу, введем некоторые определения.
Конгруентность
. a конгруентно b по модулю n (a є nb), если при делении на n a и b, получается идентичный остаток. Так 100 є 1134 (100 и 34 при делении на 11 дают остаток 1) и –6 є 810 (ведь –6 =8(-1)+2). Мы всегда имеем a є nb для некоторого 0 Ј bЈ n-1. Если a єnb и сє d, то справедливы равенства:
a +c є n(b + d) и ac єnbd
Аналогичная процедура для деления не всегда справедлива: 6є 1218 но 3№ 9. Приведенные здесь и далее математические определения и обоснования взяты из: http://lglwww.epfl.ch/~jkienzle/digital/node20.html.
Необходимо также вспомнить о знакомом всем со школьной скамьи понятии наибольшего общего делителя. Для a и b число (a,b) является наибольшим общим делителем, который делит a и b без остатка:
(56,98)=14; (76,190)=38
Теорема 1
. Для любых a,b существуют целые числа x,y, для которых ax+by=(a,b). В данной статье не приводится доказательств представленных утверждений, их следует искать в книгах по дискретной математике.
В этом можно убедиться, решая уравнение 30x+69y=3 путем последовательных упрощающих подстановок (ищется целочисленное решение:
30x+69y=3
[x'=x+2y]
3x'+9y'=3
[y'=y+3x']
3x"+0y'=3
[x"=x'+3y']
Легко видеть, что x"=1, y'=0 является решением окончательного уравнения. Мы можем получить решение исходного уравнения путем обратной подстановки.
x'=x"-3y'=1 y=y'-3x'=-3 x=x'-1y=7
Мы можем решить уравнение вида 30x+69y=15 путем умножения нашего решения: y=-15, x=35. Должно быть ясно, что уравнение не будет иметь целочисленного решения, если 15 заменить на что-то некратное (30,69)=3.
Все другие целочисленные решения 30x+69y= 15 могут быть получены, варьируя первое решение:
y=-15+(30/3)t x=35 –(69/3)t для целого t
Если мы проделаем то же для произвольного равенства ax+by=(a,b), мы возможно получим один из коэффициентов равным нулю, а другой – (a,b). В действительности эта процедура представляет собой алгоритм Евклида для нахождения наибольшего общего делителя.
Важно то, что этот процесс реализуем на ЭВМ даже в случае, когда a и b имеют несколько сотен значащих цифр. Легко показать, что 600-значное число не потребует более чем 4000 уравнений. Теорема 1 справедлива и для простых чисел.
Следствие 1 . |
Если p является простым числом, ar є pas и a № 0, тогда r є s. |
Следствие 2 . |
Если p простое число и a № 0 mod p, тогда для любого b существует y, для которого ay є pb. |
| Следствие 3. | ("Теорема о китайском остатке"). Если (p,q)=1, тогда для любого a,b существует n, для которого n є pa и nє qb. |
a a2 a3 … mod p
, где a и p целые числа.
Оказывается, можно выполнить такие вычисления даже для случая, когда в указанную процедуру вовлечены достаточно большие числа, например:
432678 mod 987.
Фокус заключается в том, что берется число и осуществляется возведение в квадрат.
4322 = 186624; 186624 mod 987 = 81; 4324 mod 987 = 812 mod 987 = 639
4328 -> 6392 mod 987 -> 690 …. 432512 -> 858
так как 678= 512+128+32+4+2, то:
432678->(81)(639)….(858) -> 204
Вычисления с использованием показателя включают в себя ограниченное число умножений. Если числа содержат несколько сотен цифр, необходимы специальные подпрограммы для выполнения таких вычислений. Рассмотрим последовательность степеней 2n mod 11:
2 4 8 5 10 9 7 3 6 1
Здесь числа от 1 до 10 появляются в виде псевдослучайной последовательности.
Теорема 2
Пусть p является простым числом. Существует такое a, что для каждого 1Ј b Ј p-1, существует такое 1Ј x Ј p-1, что axє pb, a не обязательно равно 2.
Степени 2 mod 7 равны 2, 4, 1. Далее числа повторяются, а числа 3, 5, или 6 не могут быть получены никогда. Рассмотрим некоторые следствия этой теоремы.
Следствие 4.
Пусть a соответствует требованиям теоремы 2, тогда ap-1 є p1.
Следствие 5. Для любого b № 0, bp-1 є p1.
Следствие 6. Если x є (p-1)y, тогда bx є pby
Лемма
Пусть b № 0, d наименьшее положительное число, такое что bd єp1.
Тогда для любого с>0 c bc єp1 d
делит c без остатка. В частности для следствия 5, d делит p-1 без остатка.
Согласно теореме 2, если p простое число, существует такое a, при котором равенство ax є pb имеет решение для любого b№ 0. Такое значение a называется примитивным корнем p, а x называется дискретным логарифмом b. Получение b при заданных a и x относительно просто, определение же x по a и b заметно сложнее. Многие современные системы шифрования основываются на факте, что никаких эффективных путей вычисления дискретных логарифмов не найдено. Никакого эффективного метода определения примитивных корней также неизвестно. Однако часто возможно найти примитивные корни в некоторых специальных случаях. Возьмем p=1223. p-1=2*13*47. Согласно лемме, если a не примитивный корень, тогда мы либо имеем a26, a94 или
a611 є 12231. a=2 и a=3 не годятся, но a=5 соответствует всем трем условиям, таким образом, это значение является примитивным корнем. Мы могли бы сказать, что a=4 не может быть признано примитивным корнем без проверки.
Легко показать, что если a примитивный корень, ax примитивный корень в том и только том случае, если (x,p-1)=1. В этом примере это означает, что число примитивных корней равно
1222*(1/2)*(12/13)*(46/47)=552
Таким образом, если мы выберем а произвольно, вероятность того, что это будет примитивный корень равна ~.45. Выбирая а наугад и тестируя, можно сравнительно быстро найти примитивный корень.
Наиболее современные системы шифрования используют асимметричные алгоритмы с открытым и секретным ключами, где нет проблемы безопасной транспортировки ключа. К числу таких систем относится алгоритм rsa (rivest-shamir-adleman - разработчики этой системы – Рональд Ривест, Ади Шамир и Леонард Адлеман, 1977 год), базирующийся на разложение больших чисел на множители.
Другие сходные алгоритмы используют целочисленные логарифмы и вычисление корней уравнений. В отличие от других систем эти позволяют кроме шифрования эффективно идентифицировать отправителя (электронная подпись). К системам с открытым ключом предъявляются следующие требования:
Зашифрованный текст трудно (практически невозможно) расшифровать с использованием открытого ключа.
Восстановление закрытого ключа на основе известного открытого должно быть нереализуемой задачей на современных ЭВМ. При этом должна существовать объективная оценка нижнего предела числа операций, необходимых для решения такой задачи.
К сожалению, эти алгоритмы достаточно медленно работают. По этой причине они могут использоваться для транспортировки секретных ключей при одном из традиционных методов шифрования-дешифрования.
Но следует помнить, что не существует абсолютных мер защиты. На рис.6.4.1. показан способ нарушения конфиденциальности в системах с двухключевой схемой шифрования.
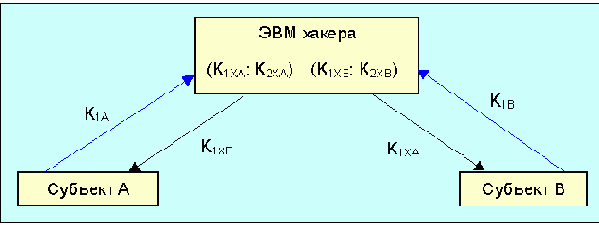
Рис. 6.4.1.
Если хакер умудрится вставить свою ЭВМ в разрыв канала, соединяющего субъектов А и В, у него появляется возможность перехватывать в том числе и шифрованные сообщения. Пусть субъект А сформировал пару ключей К1А и К2А (ключ с индексом 2 является секретным), аналогичную пару ключей сгенерировал субъект В (К1В и К2В). Хакер же тем временем подготовил две пары ключей (К1ХА:К2ХА и К1ХВ:К2ХВ). Когда субъект А пошлет открытый ключ К1А субъекту В, хакер его подменит ключом К1ХА. Аналогичную процедуру он проделает с ключом К1В, посланным от В к А. Теперь сообщение А к В, зашифрованное с помощью ключа К1ХА будет послано В. Хакер его перехватывает, дешифрует с помощью ключа К2ХА, шифрует с помощью ключа К1ХВ и посылает В. Субъект В, получив послание, дешифрует его с помощью "секретного" ключа К2ХВ, полученного от хакера (о чем он, естественно, не подозревает). Аналогичная процедура будет проведена и при посылки сообщения от В к А. В сущности единственным параметром который изменится существенным образом будет время доставки сообщения, так как это время будет включать дешифровку и повторную шифровку сообщения. Но при использовании быстродействующей ЭВМ и при работе с традиционной электронной почтой это может оказаться незаметным. Понятно, что между А и В появится дополнительный шаг (hop). Но и это может быть легко замаскировано под прокси сервер или Firewall.
Решить эту проблему можно путем пересылки открытого ключа своему партнеру по какому-то альтернативному каналу или сверки его по телефону
.
Полезную информацию по системам шифрования можно получить на следующих серверах:
www.cs.hut.fi/crypto/
www.subject.com/crypto/crypto.html
www.rsa.com/
www.netscape.com/newsref/ref/rsa.html
www.microsoft.com/workshop/prog/security/pkcb/crypt.htm
www.semper.org/sirene/people/gerrit/secprod.html
www.fri.com/~rcv/deschall.htm
www.cl.cam.ac.uk/brute/
Служба каталогов NetWare (NDS)
4.2.1.5 Служба каталогов NetWare (NDS)
Семенов Ю.А. (ГНЦ ИТЭФ)

С точки зрения службы каталогов netware (NDS - netware directory services) сеть - это не совокупность ЭВМ, а интегрированная информационная среда. При регистрации в сети клиент получает доступ ко всем ее ресурсам. Для повышения надежности и сокращения времени доступа к сети база данных службы каталогов netware распределена по сети. Отдельные фрагменты базы данных могут располагаться на разных серверах, и могут быть задублированы на нескольких серверах, имеются специальные сетевые средства для синхронизации изменений в этих секциях. Все эти вещи порождают в сети дополнительный трафик, ведь необходимо сравнивать содержимое секций базы данных, их обновление, читать и изменять записи и т.д. Одной из важнейших функций службы каталогов является синхронизация работы ее частей. Синхронизация предполагает определение порядка операций по обслуживанию каталога. В службе каталогов все серверы делятся на:
Главный эталонный временной сервер (устанавливает время для вторичных серверов и клиентов, время устанавливается супервизором, при наличии в сети таких серверов применение первичных и эталонных временных серверов не допускается);
Первичный сервер (синхронизует сетевое время, по крайней мере, с еще одним первичным или эталонным сервером, время устанавливается по выбранному сетевому времени);
Эталонный сервер (задает время для всех остальных серверов и клиентов, синхронизируется от внешнего источника, например, службы времени, первичные серверы должны согласовывать свое время с эталонным сервером);
Вторичный сервер (синхронизируется от главного эталонного, первичного или просто эталонного сервера).
Существует пять функций NCP, которые поддерживают взаимодействие со службой каталогов Netware. Имеются также функции службы каталогов. Коды функций вставляются в пакеты, посылаемые службой каталогов, и служат в качестве субфункций основных NCP-операций. Таблица (4.2.1.5.1) функций и субфункций службы каталогов представлена ниже.
Таблица 4.2.1.5.1 Основные NCP-функции
Вид сервиса
Тип запроса
Код операции
Код субфункции
ping для nds ncp (запрос о NDS) 2222 104 01 Посылка фрагментированного NDS запроса/отклика 2222 104 02 Закрытие NDS-фрагмента 2222 104 03 Возврат контекста bindary 2222 104 04 Мониторирование NDS-связи 2222 104 05 Запрос nds в режиме ping позволяет запросить сервер о поддержке им операции с кодом 104. Если сервер может выполнить эту операцию, он посылает позитивный отклик, который содержит имя дерева каталога и его глубину. При посылке фрагментированного nds запроса присылается фрагментированный отклик. При обновлении секции каталога netware передает последовательность nds-фрагментов, содержащих изменения данной секции. Формат таких пакетов показан на рис. 4.2.1.5.1. В скобках указаны размеры полей в байтах. Поле максимальный размер фрагмента несет в себе максимальное число байт, которое может быть послано в качестве отклика. Код в этом поле соответствует максимуму, поддерживаемому сетевой средой минус 8 (сумма длин поля длины отклика и поля дескриптора фрагмента). Поле флага фрагмента всегда содержит нуль. Поле внутренняя функция хранит в себе код операции для службы каталогов netware. Таблица команд службы каталогов приведена в приложении (10.5) .
В netware имеется развитая собственная система сетевой диагностики, которая позволяет выяснить реальную конфигурацию сети (возможно, что-то не включено или уже сломалось), ее загруженность или частоту ошибок (diagnostic responder). Узлы сети с загруженной программой diagnostic responder должны откликаться на диагностические пакеты, адресованные им или разосланные широковещательно. Наличие отклика говорит о доступности данного сетевого объекта, а его содержимое может нести в себе информацию о конфигурации (наличие IPX/SPX, драйвера локальной сети, программы маршрутизатора или файлового сервера).

Рис. 4.2.1.5.1. Формат пакетов “Фрагментированный NDS-запрос/отклик”
Диагностические запросы содержат код 0x0456 в поле соединителя получателя IPX-заголовка. Формат такого запроса показан на рис. 4.2.1.5.2. Однобайтовое поле счетчика исключаемых узлов задает число станций, которые могут не присылать отклик. Нуль в этом поле предполагает, что все станции должны откликнуться. Допустимый диапазон значений кодов в этом поле 0 - 79. При широковещательной рассылке запроса можно сделать так, чтобы сервер и определенные клиенты на запрос не реагировали. Для этого их адреса помещаются в поля адресов исключаемых узлов. Число таких исключений может достигать 80.

Рис. 4.2.1.5.2. Формат диагностического запроса
Структура пакета-отклика показана на рис. 4.2.1.5.3. В зависимости от числа компонентов конфигурации пакет-отклик может иметь различную длину. Поля базового и вспомогательного номера версии характеризуют вариант программы diagnostic responder (например, 1.1). Поле номер диагностического соединителя SPX указывает на соединитель, которому отсылаются все диагностические отклики. Поле счетчик компонентов содержит число описаний компонентов, содержащихся в пакете. Поле тип компонента описывает один из компонентов (или процессов) узла, посылающего отклик. Описание компонента может быть простым и расширенным. Простое описание содержит один байт идентификатора компонента. Расширенное описание компонента включает в себя информацию о маршрутизаторах, файл-серверах и невыделенных IPX/SPX. Первое поле в этом случае представляет собой идентификатор расширенного описания, который характеризует тип компонента:
Таблица 4.2.1.5.1. Коды типа компонентов
Код компонента |
Тип компонента |
Описание |
| 0 | IPX/SPX | IPX/SPX-процесс или модуль на выделенном файл-сервере, маршрутизаторе или у клиента. |
| 1 | Драйвер маршрутизатора | Процесс драйвера маршрутизации. |
| 2 | Драйвер локальной сети | Процесс драйвера интерфейса локальной сети на файл-сервере или маршрутизаторе. |
| 3 | Оболочка | Модуль-эмулятор или оболочка DOS на рабочей станции (netx.com) |
| 4 | vap | Модуль-эмулятор или оболочка DOS на сервере netware 2.x или внешнем маршрутизаторе для поддержания VAP. |
| 5 | Маршрутизатор | Маршрутизирующий компонент внешнего порта сети (gateway) |
| 6 | Файловый сервер/маршрутизатор | Маршрутизирующий компонент файл-сервера (внутренний маршрутизатор или мост). |
| 7 | Невыделенный IPX/SPX | IPX/SPX-процесс на невыделенном файл-сервере netware 2.x, внешнем порте сети или локальной сети версий 3.x. |
Таблица 4.2.1.5.2 Коды типа сети
Код типа сети |
Компонент |
| 0 | Интерфейс локальной сети |
| 1 | Невыделенный файл-сервер |
| 2 | Перенаправленная удаленная линия |

Рис. 4.2.1.5.3 Формат пакета диагностического отклика
Сервера Novell за счет протоколов RIP и SAP могут заметно загрузить локальную сеть широковещательными сообщениями. По этой причине не следует бездумно множить число таких серверов.
Смарт-карты EMV
4.6.4 Смарт-карты EMV
Семенов Ю.А. (ГНЦ ИТЭФ)
Спецификация карты ICC (Integrated Circuit Card)В основу данной спецификации легли разработки компаний Europay, MasterCard и Visa (EMV) в марте, 1998 года. Следует принимать во внимание, что данная технология будет использоваться не только для финансовых операций. Планируется ее применения для проездных билетов и контроля доступа к ЭВМ. В перспективе можно предположить, что эта техника будет использоваться для идентификации личности, например, вместо паспорта.

Рис. 4.6.4.1. Расположение контактов на лицевой стороне карты
Рис. 4.6.4.2. Положение контактов (все контакты имеют размер 1,7х2,0 мм)
Всего на карте 8 контактов. На рис. 4.6.4.1 обязательные контакты представлены закрашенными прямоугольниками. Контакты C4 и С8 не используются и могут отсутствовать, контакт же С6 используется для программирования на фазе изготовления. Сопротивление для этого контакта по отношению к любым другим контактом должно превышать 10 Мом при напряжении 5 В.
Таблица 4.6.4.1.
| Контакт | Назначение | Контакт | Назначение |
| С1 | VCC – напряжение питания | С5 | GND - земля |
| С2 | RST - сброс | С6 | Не используется |
| С3 | CLK – тактовые импульсы | С7 | Вход/Выход (I/O) |
В таблице 4.6.4.2 представлены параметры входных информационных сигналов
VIH- Высокий уровень входного сигнала
VIL- Низкий уровень входного сигнала
VOH- Высокий уровень выходного сигнала
VOL- Низкий уровень выходного сигнала
tR- Время нарастания сигнала
tF- Время спада сигнала
Таблица 4.6.4.2
| Минимум | Максимум | |
| VIH | 0,7xVcc | Vcc |
| VIL | 0 | 0,8 В |
| tR и tF | - | 1,0 мксек |
Таблица 4.6.4.3
| Условия | Минимум | Максимум | |
| VOH | -20мкА<IOH<0, Vcc= min | 0,7xVcc | Vcc |
| VOL | 0< IOL < 1мА, Vcc = min | 0 | 0,4 В |
| tR и tF | C IN(терминала) =30пФ макс | - | 1,0 мксек |
Таблица 4.6.4.4
| Минимум | Максимум | |
| VIH | Vcc-0,7В | Vcc |
| VIL | 0 | 0,5 В |
| tR и tF | - | 9% тактового периода |
Таблица 4.6.4.5
| Минимум | Максимум | |
| VIH | Vcc-0,7В | Vcc |
| VIL | 0 | 0,6 В |
| tR и tF | - | 1,0 мксек |
Любая транзакция для карты начинается с ее вставления в интерфейсное устройство IFD (Interface Device) и активации контактов карты. Далее следует сброс микросхемы ICC в исходное состояние и установление связи между ICC и IFD. Только после этого начинает реализовываться конкретная транзакция. Любая транзакция завершается дезактивацией контактов и удалением ICC из интерфейсного устройства.
После вставления карты в IFD терминал проверяет, что все сигнальные контакты находятся в состоянии L (низкий логический уровень - VOL). IFD контролирует корректность положения ICC с точностью ±0,5мм. Если карта позиционирована правильно, производится активация контактов в соответствии с порядком, представленном на рис. 4.6.4.3.
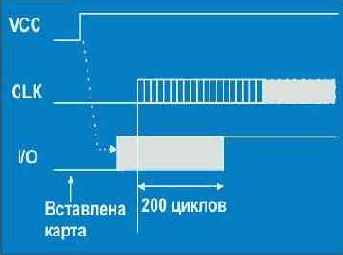
Рис. 4.6.4.3. Последовательность активации контактов ICC
Через некоторое время после подачи на ICC напряжения питания Vcc начинают поступать тактовые импульсы. В исходный момент времени (сразу после вставления карты уровень сигналов на шине I/O является низким (L). Далее уровень этой шины может быть неопределенным (обозначено на рисунке серым прямоугольником), но после прихода 200 тактов этот уровень становится высоким (H). При этом уровень на шине RST остается низким (L). Терминал IFD устанавливает свой драйвер I/O в режим приема не позднее поступления 200-го такта. После этого выполняется процедура сброса (Reset). ICC откликается на команду RESET асинхронно. Время, когда на ICC начинают поступать тактовые импульсы, называется T0. Терминал поддерживает в это время уровень шины RST в низком состоянии.
Рис. 4.6.4.4. Диаграмма реализации “холодного” сброса
После прихода 40000-45000 тактов после Т0 шина RST переходит в состояние H. Этот момент времени называется T1. Начало отклика на Reset со стороны ICC наступает спустя 400-40000 тактов после T1 (время t1). Если за это время отклик со стороны ICC не поступает, терминал в пределах 50 мсек деактивирует контакты микросхемы на карте. Диаграмма холодного сброса ICC показана на рис. 4.6.4.4.
Команда сброса может поступать и в процессе обычной работы – так называемый “теплый” сброс. Временная диаграмма такого сброса показана на рис. 4.6.4.5.
Рис. 4.6.4.5. Временная диаграмма “теплого” сброса
Следует учитывать, что при теплом сбросе напряжение питание Vcc имеет рабочий уровень, шина RST имеет уровень H, состояние шины I/O может быть любым. После перехода шины RST в состояние L (момент времени T0’) на шине I/O не позднее чем через 200 тактов должен установиться уровень H. В момент Т1’ шина RST переходит в состояние H, после чего завершается процедура сброса аналогично “холодному” варианту.
Процедура деактивации контактов ICC показана на рис. 4.6.4.6. В момент начала этой процедуры напряжение питание Vcc имеет рабочий уровень, шина RST имеет уровень H, состояние шины I/O может быть любым. Сигналом к началу процесса является переход шины RST в низкое состояние. Через некоторое время состояние шины I/O должно стать низким, прекращается подача тактовых импульсов, после чего с небольшой задержкой напряжение питания Vcc
становится равным нулю и процедура в пределах 100 мсек завершается. При гальваническом отключении контактов Vcc должно быть не более 0,4 В. По завершении процедуры карта может быть извлечена из интерфейсного устройства.
Рис. 4.6.4.6. Временная диаграмма дезактивации контактов ICC
Исходная длительность такта на шине I/O определяется как:
t = 372/f секунд,
где f частота в Гц. В общем случае t определяется как:
t = F/(Df),
где f частота в Гц, F и D параметры, которые могут варьироваться, но обычно F=372, а D=1. f лежит в пределах (1-5) МГц.
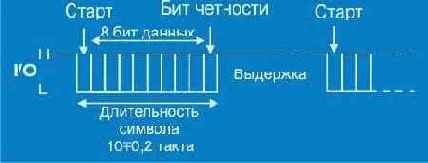
Рис. 4.6.4.7. Диаграмма передачи символов по шине I/O
Перед началом передачи символа шина I/O должна находиться в состоянии H. Для передачи любого символа требуется 10 бит (смотри рисунок 4.6.4.7). Стартовый бит должен иметь уровень L и номер 1. Последний бит представляет собой бит четности (нечет). Стартовый бит детектируется путем стробирования шины I/O. Время стробирования составляет 0,2 t. Время между началами передачи последовательных символов составляет t(10±0,2) плюс время выдержки. Во время выдержки ICC и терминал должны находиться в режиме приема. (H).
Определены два протокола: символьный (Т=0) и блочный (Т=1). ICC поддерживает один из этих протоколов, терминалы поддерживают оба. Тип протокола определяется значением символа TD1. При отсутствии в ATR TD1 рабочим считается протокол Т=0. Физический уровень обмена должен согласовываться с обоими протоколами. Минимальный интервал между лидирующими битами двух последовательных символов, посылаемых ICC, равно 12t. Максимальный интервал между стартовыми битами двух последовательных символов (Work Waiting Time) не должно превышать (960хDxWI) t (параметры D и WI пересылаются с помощью символов TA1 и TC2, соответственно). Если это время будет превышено, терминал не позднее, чем спустя 960t должен начать процесс дезактивации.
В режиме T=0, если ICC или терминал детектировали при передаче/приеме символа ошибку четности, шина I/O переводится в состояние L, чтобы передающая сторона узнала об ошибке.
На транспортном уровне терминала TTL (Terminal Transport Layer) данные всегда передаются через шину I/O так, что старший байт следует первым. Будет ли первым старший бит, определяется символом TS, возвращаемым в ответ на команду сброс ATR. Такой отклик может содержать строку символов.
При отклике на сброс минимальное время между стартовыми битами последовательных символов составляет 9600t. ICC передает все символы отклика в пределах 19200 t. Это время измеряется между стартовым битом первого символа TS и после 12 t от начала последнего символа. Число символов в отклике зависит от транспортного протокола и поддерживаемых управляющих параметров.
ICC может опционно поддерживать более одного транспортного протокола, но одним из таких протоколов должен быть Т=0 или Т1. Символы, присылаемые в рамках ATR, представлены в таблице 4.6.4.6.
Таблица 4.6.4.6.
Базовый ATR для T=0
| Символ | Значение | Примечания |
| TS | 3B или 3F | Указывает на прямую или инверсную схему передачи бит |
| T0 | 6x | Присутствуют TB1 и TC1; х обозначает число исторических байтов |
| TB1 | 00 | VPP не требуется |
| TC1 | 00 - FF | Указывает на необходимость дополнительного времени выдержки. FF имеет специальное назначение. |
Таблица 4.6.4.7
. Базовый ATR для T=1
| Символ | Значение | Примечания |
| TS | 3B или 3F | Указывает на прямую или инверсную схему |
| T0 | Ex | Присутствуют TB1 – TD1; х обозначает число исторических байтов |
| TB1 | 00 | VPP не требуется |
| TC1 | 00 – FF | Указывает на необходимость дополнительного времени выдержки. FF имеет специальное назначение. |
| TD1 | 81 | TA2 – TC2 отсутствуют; TD2 присутствует; должен работать протокол T=1 |
| TD2 | 31 | TA3 и TB2 присутствуют; TC3 и TD3 отсутствуют; должен работать протокол T=1 |
| TA3 | 10 – FE | Возвращает IFSI, что указывает на начальное значение размера информационного поля для ICC и IFSC равное 16-254 байтам |
| TB3 |
Старший полубайт =0-4 Младший полубайт =0-5 |
BWI = 0-4 CWI = 0-5 |
| TCK | Контрольный символ |
/p> Интерфейсы могут поддерживать отклики, не описанные в данной спецификации. Максимальное число символов в отклике, включая TS, не должно превышать 32.
TS служит для синхронизации терминала и для определения логической схемы интерпретации последующих символов. Инверсная логическая схема предполагает, что логической единице на шине I/O соответствует уровень L, а старший бит данных передается первым. Прямая схема предполагает, что логической единице на шине I/O соответствует уровень H, а первым передается младший бит. Первые четыре бита LHHL используются для синхронизации.
ICC может прислать ATR, содержащий TS, который имеет одно из следующих значений:
(H)LHHLLLLLLH – инверсная схема, значение 3F.
(H)LHHLHHHLLH – прямая схема, значение 3B
Последний бит этих кодов Н является битом четности (смотри рис. 4.6.4.7).
T0
– символ формата. Старший полубайт (b5-b8) используется для определения того, присутствуют ли последующие символы TA1-TD1. Если биты b5-b8 установлены в состояние логической единицы, TA1-TD1 присутствуют. Младший полубайт (b1-b4) содержит число опционных исторических байтов (0-15). Смотри таблицу 4.6.4.8.
Таблица 4.6.4.8
| b8 | b7 | b6 | b5 | b4 | b3 | b2 | b1 | |
| Только Т=0 | 0 | 1 | 1 | 0 | X | X | X | X |
| Только Т=1 | 1 | 1 | 1 | 0 | X | X | X | X |
TA1 служит для передачи значений FI и DI, где FI используется для задания значения F (параметр, определяющий тактовую частоту). DI служит для задания значения D, используемого для настройки частоты следования бит. По умолчанию FI=1 и DI=1, что означает F=372, а D=1.
Если ТА1 присутствует в ATR (b5 в T0 равен 1) и TA2 прислан с b5=0, то терминал воспринимает ATR, если TA1=11, и немедленно реализует указанные F и D.
ТВ1
несет в себе значения PI1 и II, где PI1 специфицировано в битах b1-b5 и используется для программирования значения напряжения P, необходимого ICC. PI0=0 означает, что VPP не подключено к ICC. II специфицируется в битах b6 и b7 и служит для определения максимального тока, потребляемого ICC. Этот параметр не используется, если PI1 = 0.
TC1
несет в себе величину N, которая используется для задания дополнительной выдержки (guardtime) между символами. Это время будет добавлено к минимальной выдержке. N может принимать значения 0-255 t.
TD1
указывает, должны ли быть переданы еще интерфейсные байты, и содержит информацию о типе протокола. Старший полубайт используется для индикации наличия символов TA2 – TD2. Биты b5-b8 принимают значение логической единицы, если указанные выше символы присутствуют. Младший полубайт указывает протокол, который будет использован для последующих обменов.
ATR не содержит TD1, если используется только Т=0. Для T=1 TD1=81 указывает на наличие TD2.
Наличие или отсутствие TA2 говорит о работе ICC в специфическом или согласованном режиме, соответственно. Базовый отклик ATR не содержит ТА2.
ТВ2
передает PI2, который используется для определения величины программируемого напряжения Р, необходимого ICC. Если этот символ присутствует, значение, указанное в PI1 (ТВ1), заменяется на новое. По умолчанию ТВ2 отсутствует.
ТС2
специфичен для протокола типа Т=0 и несет в себе значение WI (Waiting time Integer), которое используется для определения максимального интервала между началом передачи любого символа, посланного ICC, и началом предыдущего символа, поступившего от ICC или терминала. Время выдержки вычисляется по формуле 960xDxWI. По умолчанию ТС2 отсутствует, а WI=10. Терминал воспринимает ATR, содержащий ТС2=0А. Он отвергает ATR, несущий в себе ТС2=00 или ТС2>0А.
TD2
указывает, будут ли еще переданы какие-либо интерфейсные байты, а также определяет тип протокола, используемого далее. Старший полубайт используется для указания наличия символов ТА3 – TD3. Биты b5-b8 устанавливаются в единичное состояние при наличии ТА3 – TD3. Младший полубайт указывает тип протокола, применяемый в последующих обменах. При Т=1 он равняется 1. По умолчанию при Т=0 ATR не содержит TD2, в противном случае ATR содержит TD2=31 (T=1).
ТА3
несет в себе информацию о размере поля данных для ICC (IFSI) и специфицирует длину информационного поля INF блоков, которые могут быть получены картой. Этот символ характеризует длину IFSC в байтах и может содержать коды в интервале 0х01-0хFE. Значения 0х00 и 0хFF зарезервированы на будущее. По умолчанию ATR содержит ТА3 со значение в диапазоне 0х10-0хFE, если Т=1, IFSC лежит в интервале 16-254 байта. Если ТА3 содержит недопустимый код, ATR терминалом отвергается.
ТВ3
характеризует значения CWI и BWI, используемые для вычисления CWT и BWT, соответственно. ТВ3 имеет две части. Младший полубайт (b1-b4) используется для определения значения CWI, а старший полубайт (b5-b8) – BWI. По умолчанию ATR несет в себе ТВ3, при этом младший полубайт содержит код 0-5, а старший – 0-4, если Т=1, указывая, что CWI=0-5, а BWI=0-4. Формат ТВ3 показан в таблице 4.6.4.9.
Таблица 4.6.4.9
| b8 | b7 | b6 | b5 | b4 | b3 | b2 | b1 | |
| Только Т=1 | 0 | X | X | X | 0 | Y | Y | Y |
Терминал отвергает ATR, не содержащий ТВ3 или указывающий на значения BWI больше 4 и/или CWI больше 5, или 2CWI<(N+1).
TC3
индицирует тип блока кода детектирования ошибки. Тип кода определяется битом b1 (b2-b8 – не используются). По умолчанию ATR не содержит ТС3. Терминал воспринимает ATR с ТС3=00, и отбрасывает любые-другие ATR, содержащие другие значения ТС3.
ТСК
(контрольный символ) имеет значение, которое позволяет проверить целостность данных, пересылаемых в ATR. Значение TCK таково, что исключающее ИЛИ всех байтов от Т0 до ТСК включительно должно давать код 0. По умолчанию ATR не содержит ТСК, если используется только Т=0, во всех других случаях ТСК должен присутствовать. Терминал воспринимает ATR ICC без TCK, если только Т=0. Во всех остальных случаях терминал отвергнет ATR без, или с некорректным ТСК. Если ТСК некорректно, терминал инициирует последовательность дезактивации не позднее 480 t после начала ТСК.
Если терминал отверг холодный АТR, он не отвергает карту немедленно, а инициирует “теплый” сброс в пределах 4800t. Если терминал отверг теплый ATR, он в пределах 4800 t запускает процедуру дезактивации.
Если во время отклика на холодный или теплый сброс интервал между двумя последовательными символами превысит 9600t, терминал прерывает сессию путем инициализации дезактивации спустя 14400t после стартового бита последнего полученного символа.
Если отклик на холодный или теплый сброс не завершился в пределах 19200t , терминал спустя 24000t (от начала TS) запускает процедуру дезактивации карты.
Если терминал обнаруживает ошибку по четности при передаче символа ATR, он прерывает сессию карты и спустя 4800t инициирует процедуру дезактивации.
4.6.4.1. Команды
Команды всегда инициируются прикладным уровнем терминала TAL (Terminal Application Layer), который посылает инструкции ICC через транспортный уровень TTL (Terminal Transport Layer). Команда содержит последовательность из 5 байт: CLA, INS, P1, P2 и P3.
| Имя байта | Назначение |
| CLA | Класс команды (1 байт). |
| INS | Код инструкции (1 байт). |
| P1 и P2 | Cодержат дополнительные специфические параметры (по 1 байту). |
| Р3 | Указывает либо длину посылаемых в команде данных, либо максимальную длину данных, которые должны быть присланы в отклике от ICC (зависит от кода INS). |
Получив команду, ICC откликается отправкой процедурного или статусных байтов. Процедурный байт указывает TTL, какая операция является следующей. Отклик терминала на процедурный байт представлен в таблице 4.6.4.10.
Таблица 4.6.4.10
. Отклик терминала на процедурный байт
| Значение процедурного байта | Действие терминала |
| Байт равен INS | Все остальные байты данных будут переданы TTL, или TTL будет готов принять все остальные байты от ICC |
| Байт равен дополнению INS | Следующий байт данных будет передан TTL или TTL будет готов принять следующий байт от ICC |
| 60 | TTL введет дополнительное время выдержки (Work Waiting Time) |
| 61 | TTL будет ждать следующий процедурный байт, затем пошлет ICC команду GET RESPONSE с максимальной длиной “xx”, где хх равно значению второго процедурного байта |
| 6C | TTL будет ждать следующий процедурный байт, после чего немедленно повторно пошлет ICC предыдущий командный заголовок, используя длину “xx”, где хх равно значению второго процедурного байта |
/p> Во всех случаях после реализации операции TTL ждет прихода процедурного байта или статусного сообщения.
Командное сообщение, посылаемое от прикладного уровня, и сообщение-отклик ICC называются APDU (Application Protocol Data Unit). Формат APDU показан на рисунке 4.6.4.8.

Рис. 4.6.4.8. Структура командного APDU.
Все поля заголовка имеют по одному байту. Поле данных содержит Lc байт.
| Lc | Число байт в поле данные (0 или 1 байт) |
| Le | Максимальное число байт в поле данных отклика (0 или 1 байт) |
Формат отклика APDU аналогичен показанному на 4.6.4.8.
Поле данных имеет переменную длину и, вообще говоря, может отсутствовать. Однобайтовые поля SW1 и SW2 должны присутствовать обязательно. SW1 характеризует состояние обработки команды, а SW2 – является квалификатором обработки команды.
Кодировка команд для полей CLA и INS представлена в таблице 4.6.4.11.
Таблица 4.6.4.11. Кодирование командного байта
| CLA | INS | Назначение |
| 8х | 1Е | APPLICATION BLOCK (Заблокировать приложение) |
| 8х | 18 | APPLICATION UNBLOCK (Разблокировать приложение) |
| 8х | 16 | CARD BLOCK (Заблокировать карту) |
| 0х | 82 | EXTERNAL AUTHENTICATE (Внешняя аутентификация) |
| 8х | АЕ | GENERATE APPLICATION CRYPTOGRAM (Сформировать прикладную криптограмму) |
| 0х | 84 | GET CHALLENGE (Получить вызов) |
| 8х | СА | GET DATA (Получить данные) |
| 8х | А8 | GET PROCESSING OPTIONS (Получить опции обработки) |
| 0х | 88 | INTERNAL AUTHENTICATE (Внутренняя аутентификация) |
| 8х | 24 | PERSONAL IDENTIFICATION NUMBER (PIN) CHANGE/UNBLOCK – изменение/разблокировка персонального идентификатора |
| 0х | В2 | READ RECORD (Прочесть запись) |
| 0х | А4 | SELECT (Выбор) |
| 0х | 20 | VERIFY (Проверка) |
| 8х | Dx | RFU для платежных систем |
| 8х | Ex | RFU для платежных систем |
| 9х | Xx | RFU производителя для кодирования INS собственника |
| Ех | xx | RFU эмитента для кодирования INS собственника |
Таблица 4.6.4.12. Кодирование статусных байтов SW1, SW2
| SW1 | SW2 | Значение |
| 90 | 00 | Нормальная обработка Процесс завершился успешно |
|
62 63 63 |
83 00 Сх |
Обработка с предупреждением Состояние постоянной памяти не изменилось; выбранный файл некорректен Состояние постоянной памяти изменилось; аутентификация не прошла Состояние постоянной памяти изменилось; счетчик задан “x” (0-15) |
|
69 69 69 6А 6А 6А |
83 84 85 81 82 83 |
Контроль ошибок Команда не разрешена; метод аутентификации блокирован Команда не разрешена; запрошенные данные некорректны Команда не разрешена; условия использования не выполнены Неверные параметры Р1 Р2; функция не поддерживается Неверные параметры Р1 Р2; файл не найден Неверные параметры Р1 Р2; запись не найдена |
Таблица 4.6.4.12А
. Сводные данные по командам/откликам
| Команда | CLA | INS | P1 | P2 | Lc | Данные | Le |
APPLICATION BLOCK |
8C/84 | 1E | 00 | 00 | Число байт данных | Код аутенти-фикации сообщения (MAC) | - |
APPLICATION UNBLOCK |
8C/84 | 18 | 00 | 00 | Число байт данных | Компонент MAC | - |
CARD BLOCK |
8C/84 | 16 | 00 | 00 | Число байт данных | Компонент MAC | - |
EXTERNAL AUTHENTICATE |
00 | 82 | 00 | 00 | 8-16 | Issue Authentication Data | - |
GENERATE APPLICATION CRYPTOGRAM |
80 | AE |
Парам. ссылки |
00 | Перемен. | Данные транзакции | 00 |
GET DATA |
80 | CA |
9F36 9F13 9F17 |
9F36 9F13 9F17 |
- | - | 00 |
GET PROCESSING OPTIONS |
80 | A8 | 00 | 00 | Перемен. | Processing Option Data Object List (PDOL) | 00 |
INTERNAL AUTHENTICATE |
00 | 88 | 00 | 00 | Длина аутент. данных | Аутентиф. данные | 00 |
PIN CHANGE/UNBLOCK |
8C/84 | 24 | 00 | 00, 01 или 02 | Число байт данных | PIN данные | - |
READ RECORD |
00 | B2 | Номер записи |
Парам. ссылки | - | - | 00 |
SELECT |
00 | A4 |
Парам. ссылки |
Опции выбора | 05-10 | Имя файла | 00 |
VERIFY |
00 | 20 | 00 | Квали-фикатор | Перемен | PIN данные транзакции | - |
GET CHALLENGE |
00 | 84 | 00 | 00 | - | - | 00 |
| Заголовок (Prologue) | Данные | Эпилог | ||
| Адрес узла (NAD) | Управляющий протокольный байт (PCB) |
Длина (LEN) |
APDU или управляющая информация (INF) |
EDC (код детектирования ошибки) |
| 1 байт | 1 байт | 1 байт | 0-254 байта | 1 байт |
/p> Рис. 4.6.4.9. Структура блока
Кодирование PCB зависит от его типа, оно представлено в таблицах 4.6.4.13-15.
Таблица
4.6.4.13. Кодирование PCB I-блоков
| b8 | 0 |
| b7 | Номер по порядку |
| b6 | Цепочка (есть еще данные) |
| b5-b1 | Зарезервировано на будущее |
Таблица 4.6.4.14
. Кодирование PCB R-блоков
| b8 | 1 |
| b7 | 0 |
| b6 | 0 |
| b5 | Номер по порядку |
| b4-b1 |
0 – Отсутствие ошибки 1 – EDC и/или ошибка четности 2 – другие ошибки остальные коды зарезервированы |
Таблица 4.6.4.15
. Кодирование PCB S-блоков
| b8 | 1 |
| b7 | 1 |
| b6 |
0 – запрос 1 - отклик |
| b5-b1 |
0 – запрос повторной синхронизации 1 – запрос размера поля данных 2 – запрос абортирования 3 – расширение BWT-запроса 4 – VPP-ошибка остальные коды зарезервированы |
Поле EDC представляет собой объединение всех байт блока, начиная с NAD и кончая последним байтом поля INF (если это поле присутствует), с помощью операции исключающее ИЛИ.
Максимальный размер поля данных ICC (IFSC) блока определяется параметром ТА3, присылаемым ICC в отклике на сброс. IFSI может принимать значения 10-FE, что означает для IFSC диапазон 16-254 байта. Максимальный размер поля данных терминала (IFSD) составляет 254 байта.
Время ожидания блока BWT (Block Waiting Time) в общем случае вычисляется согласно следующей формуле. Реально BWT может лежать в диапазоне (971-15371)t.
Когда отправитель намерен передать объем данных больше, чем это определено параметрами IFSC или IFSD, он должен разбить эту последовательность байтов на несколько I-блоков. Передача этих блоков осуществляется с привлечением механизма цепочек. Для объединения I-блоков в цепочку используется бит b6 в PCB (смотри табл. 4.6.4.13). Если b6=0, то это последний блок в цепочке. Если же b6=1, далее следует как минимум еще один блок. Получение любого I-блок с b6=1 должно быть подтверждено R-блоком. Последний блок цепочки, посланный терминалом, подтверждается I-блоком, если получен безошибочно, или R-блоком, при обнаружении ошибки. В случае ICC получение последнего блока цепочки подтверждается R-блоком при обнаружении ошибки. Если ошибки не было, терминал просто посылает очередной I-блок, если должна обрабатываться очередная команда. Передача цепочки возможна в одно и тоже время только в одном направлении. Когда терминал является получателем, он воспринимает цепочки I-блоков, передаваемых ICC, если длина блоков ? IFSD. Если получателем является ICC, карта воспринимает цепочку I-блоков, посланных терминалом и имеющих длину LEN=IFSC, за исключением последнего блока, длина которого может лежать в диапазоне (1-IFSC). Если длина блока > IFSC, ICC такой блок отвергает, послав R-блок с битами b4-b1 в PCB, равными 2.
4.6.4.2. Элементы данных и файлы
Приложение в ICC содержит набор информационных элементов. Терминал может получить доступ к этим элементам после успешного выбора приложения. Информационным элементам присваиваются имена, они имеют определенное описание содержимого, формат и кодирование. Информационный объект состоит из метки (tag), кода длины и значения. Метка однозначно идентифицирует объект в рамках данного приложения. Поле длина определяет число байт в поле значение. Объекты могут объединяться, образуя составные объекты. Определенное число простых или составных объектов могут образовывать записи. Присвоение меток регламентируется документами ISO/IEC 8825 и ISO/IEC 7816. Записи, содержащие информационные объекты, хранятся в файлах ICC. Структура файла и метод доступа зависят от назначения файла. Организация файлов определяется приложениями платежной системы PSA (Payment System Application). Проход к набору PSA в ICC разрешается с помощью выбора среды платежной системы PSE (Payment System Environment). Когда PSE присутствует, файлы, относящиеся к PSA, доступны для терминала через древовидную структуру каталога. Каждая ветвь этого дерева является файлом определения приложения ADF (Application Definition File) или файлом определения каталога DDF (Directory Definition File). ADF является входной точкой одного или нескольких прикладных первичных файлов AEF (Application Elementary File). ADF со стороны терминала воспринимается как файл, содержащий информационные объекты, которые инкапсулированы в FCI (File Control Information). Информационные файлы состоят из последовательности пронумерованных записей. Каждому файлу присваивается короткий идентификатор SFI (принимает значения 1-10), с помощью которого можно обращаться к файлу. Чтение каталога осуществляется с помощью команды READ RECORD.
Когда PSE присутствует, ICC поддерживает структуру каталога для списка приложений в пределах PSE (определяется эмитентом карты). Каждому приложению присваивается идентификатор AID (Application Identifier; ISO/IEC 7816-5). К любому ADF или DDF в карте обращение производится посредством имени DF (Dedicated File). DF для ADF соответствует AID и для данной карты должно быть уникальным. Формат записи каталога PSE показан на рисунке 4.6.4.11.
|
Метка 70 |
Длина данных (L) |
Метка 61 |
Длина элемента 1 каталога | Элемент каталога 1 (ADF или DDF) |
… … … |
Метка 61 |
Длина элемента N каталога | Элемент каталога N (ADF или DDF) |
/p> Рис. 4.6.4.11. Формат записи каталога PSE
Содержимое полей элемент каталога характеризуется в таблицах 4.6.4.16 и 4.6.4.17.
Таблица 4.6.4.16
. Формат элемента каталога DDF
| Метка (Tag) | Длина | Значение |
| 9D | 5-16 | Имя DDF |
| 73 | переменная | Шаблон каталога |
Таблица 4.6.4.17
. Формат элемента каталога ADF
| Метка (Tag) | Длина | Значение |
| 0х4F | 5-16 | Имя ADF (AID) |
| 0х50 | 1-16 | Метка приложения |
| 0х9F12 | 1-16 | Предпочитаемое имя приложения |
| 0х87 | 1 | Индикатор приоритетности приложения |
| 0х73 | переменная | Шаблон каталога |
4.6.4.3. Соображения безопасности
Статическая аутентификация данных
Статическая аутентификация выполняется терминалом, использующим цифровую подпись, которая базируется на методике общедоступных ключей. Эта техника позволяет подтвердить легитимность некоторых важных данных, записанных в ICC и идентифицируемых с помощью AFL (Application File Locator).
Статическая аутентификация требует существования сертификационного сервера (или центра), который имеет надежную защиту и способен подписывать общедоступные ключи эмитента карты. Каждый терминал должен содержать общедоступный ключ центра сертификации для каждого приложения, распознаваемого терминалом. Взаимодействие клиента, центра сертификации и эмитента карты показано на рисунке 4.6.4.12.
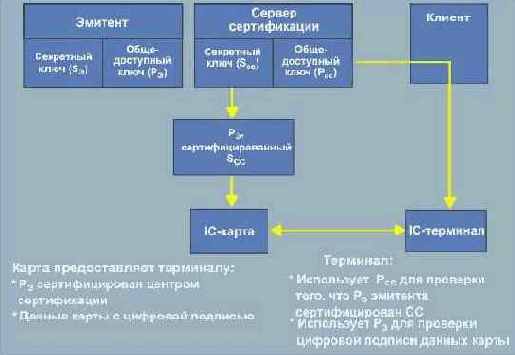
Рис. 4.6.4.12. Диаграмма статической аутентификации данных
Карта ICC, которая поддерживает статическую аутентификацию данных, должна содержать следующие информационные элементы.
Индекс общедоступного ключа сертификационного цента. Это однобайтовый элемент, содержащий двоичное число, которое указывает на общедоступный ключ и связанный с ним алгоритм сертификационного центра приложения. Этот ключ хранится в терминале и должен использоваться с данной картой.
Сертификат общедоступного ключа эмитента карты. Этот элемент имеет переменную длину и предоставляется центром сертификации эмитенту карты.
Подписанные данные приложения. Информационный элемент переменной длины, формируемый эмитентом карты с помощью секретного ключа, который соответствует общедоступному ключу, аутентифицированному в сертификате эмитента.
Остаток (remainder) общедоступного ключа эмитента. Опционный элемент переменной длины ICC.
Показатель степени общедоступного ключа эмитента. Информационный элемент переменной длины, предоставляемый эмитентом карты.
Для поддержки статической аутентификации ICC должна содержать статические прикладные данные, подписанные секретным ключом эмитента. Общедоступный ключ эмитента записывается в ICC вместе с сертификатом общедоступного ключа. Модуль общедоступного ключа сертификационного ключа имеет NCA байт, где NCA ? 248, показатель степени этого ключа равен 2, 3 или 216+1.
Общедоступный ключ эмитента имеет модуль ключа, содержащий NЭ байт, где NЭ < 248 и NЭ < NCC. Если NЭ > (NCC - 36), модуль общедоступного ключа эмитента делится на две части. Одна часть, состоящая из NCC -36 старших байт модуля (левые цифры общедоступного ключа эмитента), и вторая часть с оставшимися NЭ - (NCC - 36) младшими байтами. Показатель степени общедоступного ключа эмитента должен быть равен 2, 3 или 216+1.
Вся необходимая информация, необходимая для статической аутентификации записывается в ICC (смотри таблицу 4.6.4.18 и 4.6.4.19). За исключением RID (Registered Application Provider Identifier), который может быть получен из AID (Application Identifier), эта информация может быть получена посредством команды READ RECORD. Если что-то из этой информации отсутствует, аутентификация терпит неудачу.
Таблица 4.6.4.18
. Данные, сопряженные с общедоступным ключом эмитента, которые должны быть подписаны центром сертификации.
| Имя поля |
Длина (байт) |
Описание |
| Формат сертификата | 1 | Шестнадцатеричное число 0х02 |
| Идентификационный номер эмитента | 4 | Левые 3-8 цифр номера первичного счета PAN (Primary Account Number) |
| Дата истечения действительности сертификата | 2 | MMГГ, после которых данный сертификат не действителен |
| Серийный номер сертификата | 3 | Двоичное число уникальное для сертификата сертификационного центра |
| Индикатор хэш-алгоритма | 1 | Идентифицирует хэш-алгоритм, используемый для получения электронной подписи |
| Индикатор алгоритма общедоступного ключа эмитента | 1 | Идентифицирует алгоритм цифровой подписи, используемый с общедоступным ключом эмитента |
| Длина общедоступного ключа эмитента | 1 | Идентифицирует длину модуля общедоступного ключа эмитента в байтах |
| Длина показателя общедоступного ключа эмитента | 1 | Идентифицирует длину показателя общедоступного ключа эмитента в байтах |
| Общедоступный ключ эмитента или левые цифры этого ключа | NCC - 36 |
Если NЭ ? NCC –36, это поле состоит из общедоступного ключа эмитента дополненного справа NCC – 36 - NЭ байтами, равными BB. Если NЭ > NCC –36, это поле состоит из NCC – 36 старших байт общедоступного ключа эмитента |
| Остаток общедоступного ключа эмитента |
0 или NЭ - NCC + 36 |
Это поле присутствует, только если NЭ > NCC –36, оно состоит из NЭ - NCC + 36 младших байт общедоступного ключа эмитента |
| Показатель общедоступного ключа эмитента | 1 или 3 | Показатель общедоступного ключа эмитента, равный 2, 3 или 216+1. |
/p>
Таблица 4.6.4.19.
Статическая прикладная информация, подписываемая эмитентом
| Имя поля |
Длина (байт) |
Описание |
| Формат подписанных данных | 1 | Шестнадцатеричное число 0х03 |
| Индикатор хэш-алгоритма | 1 | Идентифицирует алгоритм хэширования, используемый для вычисления поля результат хэширования для цифровой подписи |
| Код аутентификации данных | 2 | Код, присвоенный эмитентом |
| Код заполнителя | NЭ - 26 | Код байта заполнителя, равный 0хBB |
| Статические данные, подлежащие аутентификации | Перемен-ная | Статические данные, которые подлежат аутентификации согласно требованиям приложения ICC |
Таблица 4.6.4.20.
Информационные объекты, необходимые для аутентификации статических данных
| Метка (Tag) | Длина | Значение |
| - | 5 | Зарегистрированный идентификатор провайдера приложения (RID) |
| 0х8F | 1 | Индекс общедоступного ключа сертификационного центра |
| 0х90 | NCC | Сертификат общедоступного ключа эмитента |
| 0х92 | NЭ - NCC + 36 | Остаток общедоступного ключа эмитента (если присутствует) |
| 0х9F32 | 1 или 3 | Показатель общедоступного ключа эмитента |
| 0х93 | NЭ | Подписанные статические прикладные данные |
| - | Переменная | Статические данные, которые должны быть аутентифицированы |
Если сертификат общедоступного ключа эмитента имеет длину отличную от модуля общедоступного ключа сертификационного центра, то аутентификация не пройдет.
Для того чтобы получить данные, представленные в таблице 4.6.4.21, используется сертификат общедоступного ключа эмитента и общедоступный ключ центра сертификации. Если хвостовик восстановленных данных сообщения не равен BC, аутентификация не удалась.
Таблица 4.6.4.21
. Формат восстановленных данных сертификата общедоступного ключа эмитента
| Имя поля |
Длина (байт) |
Описание |
| Заголовок восстановленных данных | 1 | Шестнадцатеричное число 0х6A |
| Формат сертификата | 1 | Шестнадцатеричное число 0х02 |
| Идентификационный код эмитента | 4 | Левые 3- 8 цифр РАN, дополняемые справа кодами 0хF |
| Дата истечения действия сертификата | 2 | Дата ММГГ, после которой сертификат становится недействительным |
| Серийный номер сертификата | 1 | Двоичное число уникальное для сертификата, выданного центром сертификации |
| Индикатор хэш-алгоритма | 1 | Идентифицирует хэш-алгоритм, используемый для получения кода поля результата хэширования при вычислении электронной подписи |
| Индикатор алгоритма общедоступного ключа эмитента | 1 | Идентифицирует алгоритм цифровой подписи, который должен быть использован совместно с общедоступным ключом эмитента |
| Длина общедоступного ключа эмитента | 1 | Идентифицирует длину модуля общедоступного ключа эмитента в байтах |
| Длина показателя общедоступного ключа эмитента | 1 | Идентифицирует длину показателя степени общедоступного ключа эмитента в байтах |
| Общедоступный ключ эмитента или левые цифры общедоступного ключа эмитента | NCC - 36 |
Если NЭ ? NCC – 36, это поле состоит из полного общедоступного ключа эмитента, дополненного справа NCC – 36 - NЭ байтами, содержащими код BB. Если NЭ > NCC – 36, это поле состоит из NCC – 36 старших байт общедоступного ключа эмитента |
| Результат хэширования | 20 | Хэш-код общедоступного ключа эмитента и сопряженной с ним информации |
| Хвостовик восстановленных данных | 1 | Шестнадцатеричное число 0хВС |
Проверяется поле формат сертификата и, если его код не равен 0х02, аутентификация отвергается.
Далее объединяются слева направо, начиная со второго и кончая десятым, информационные элементы, представленные в таблице 4.6.4.21 (от поля формат сертификата до общедоступного ключа эмитента или левых цифр этого ключа), к результату добавляется хвостовик общедоступного ключа эмитента (если он имеется) и показатель этого ключа.
Результат данного объединения подвергается хэшированию согласно заданному алгоритму. Полученный результат сравнивается со значением поля результат хэширования (см. табл. 4.6.4.21). Если совпадения нет, аутентификация не состоялась.
Проверяется, что идентификационный номер эмитента соответствует левым цифрам 3-8 PAN. При несоответствии аутентификация отвергается.
Проверяется, не закончился ли срок действия сертификата. Если срок истек, аутентификации не происходит.
Проверяется то, что объединение RID, индекса общедоступного ключа центра сертификации, серийного номера сертификата является корректным, в противном случае аутентификация не проходит.
Если не распознан индикатор алгоритма общедоступного ключа эмитента, аутентификация также не пройдет. Если все предыдущие проверки прошли успешно, то производится объединение левых цифр общедоступного ключа эмитента и его остатка (если таковой имеется) с целью получения модуля общедоступного ключа эмитента, после чего процесс переходит в следующую фазу проверок подписанных статических прикладных данных.
Если подписанные статические прикладные данные имеют длину, отличную от длины модуля общедоступного ключа эмитента, аутентификация не состоится.
Для того чтобы получить данные, представленные в таблице 4.6.4.22, берутся подписанные статические прикладные данные и общедоступный ключ эмитента. Если хвостовик восстановленных данных окажется не равным BC, аутентификация отвергается.
Таблица 4.6.4.22
. Формат восстановленных данных из подписанных статических прикладных данных.
| Имя поля |
Длина (байт) |
Описание |
| Заголовок восстановленных данных | 1 | Шестнадцатеричное число 0х6А |
| Формат подписанных данных | 1 | Шестнадцатеричное число 0х03 |
| Индикатор хэш-алгоритма | 1 | Идентифицирует алгоритм хэширования, используемый для вычисления поля результат хэширования для цифровой подписи |
| Код данных аутентификации | 2 | Код, присвоенный эмитентом |
| Код заполнителя | NЭ - 26 | Код байтов заполнителя, равный 0хBB |
| Результат хэширования | 20 | Хэш статических прикладных данных, которые должны быть аутентифицированы |
| Хвостовик восстановленных данных | 1 | Шестнадцатеричное число 0хВС |
/p> Проверяется заголовок восстановленных данных и, если он не равен 0х6A, аутентификация не проходит.
Проверяется формат подписанных данных и, если его код не равен 0х03, аутентификация не проходит.
Объединяются информационные элементы, начиная со второго по пятый (см. табл. 4.6.4.22), добавляются данные, подлежащие аутентификации, после чего вычисляется хэш. Полученный результат сравнивается со значением поля результата хэширования. При несовпадении аутентификация терпит неудачу. Если все предшествующие проверки прошли успешно, данные считаются аутентифицированными.
4.6.4.4. Динамическая аутентификация данных
Динамическая аутентификация данных выполняется терминалом, с использованием цифровой подписи, базирующейся на технике общедоступного ключа, и имеет целью аутентифицировать ICC и подтвердить легитимность динамической информации, записанной на ICC. Динамическая аутентификация требует наличия центра аутентификации, который подписывает общедоступные ключи эмитента. Каждый терминал должен иметь общедоступные ключи сертификационного центра для каждого приложения, распознаваемого терминалом. Схема аутентификации динамических данных показана на рис. 4.6.4.12.
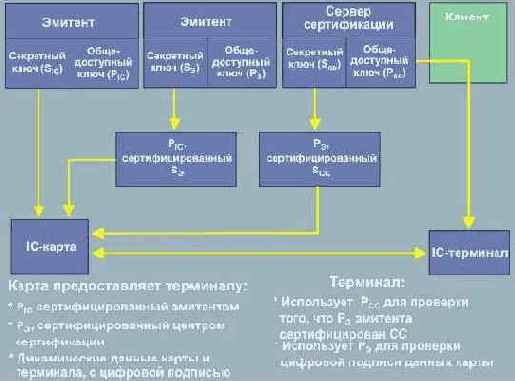
Рис. 4.6.4.12. Схема динамической аутентификации данных
ICC, которая поддерживает аутентификацию динамических данных, должна содержать следующие информационные элементы.
Индекс общедоступного ключа сертификационного центра. Этот элемент состоит из одного байта, который указывает, какой из общедоступных ключей сертификационного центра и алгоритм, доступный терминалу, следует использовать с данной картой ICC.
Сертификат общедоступного ключа эмитента. Этот элемент переменной длины записывается в ICC эмитентом карты. Когда терминал проверяет этот элемент, он аутентифицирует общедоступный ключ и сопутствующие данные ICC.
Остаток общедоступного ключа эмитента.
Показатель общедоступного ключа эмитента.
Остаток общедоступного ключа ICC.
Показатель общедоступного ключа ICC.
Секретный ключ ICC. Элемент переменной длины, используемый для формирования подписанных динамических прикладных данных.
ICC, которые поддерживают аутентификацию динамических прикладных данных, должны сформировать следующий информационный элемент.
Подписанные динамические прикладные данные
. Этот информационный элемент переменной длины формируется ICC с помощью секретного ключа, который соответствует общедоступному ключу, аутентифицированному в сертификате общедоступного ключа ICC.
Чтобы поддерживать аутентификацию динамических данных, каждый терминал должен запоминать большое число общедоступных ключей сертификационного центра, и ставить им в соответствие информацию, которая должна использоваться с этими ключами. Терминал способен найти любой такой ключ, заданный RID и индексом общедоступного ключа сертификационного центра, полученных от ICC.
ICC, поддерживающая аутентификацию динамических данных должна иметь пару ключей, один из которых является секретным, служащим для цифровой подписи, другой – общедоступный для верификации. Общедоступный ключ ICC запоминается ИС картой в сертификате общедоступного ключа, сформированном эмитентом карты. Общедоступный ключ эмитента сертифицирован центром сертификации. Как следствие для верификации подписи ICC терминал должен сначала верифицировать два сертификата, для того чтобы получить и аутентифицировать общедоступный ключ ICC, который далее служит для проверки корректности динамической подписи ICC.
Процедура цифровой подписи использует данные, представленные в таблицах 4.6.4.23 и 4.6.4.24. Модуль общедоступного ключа сертификационного центра содержит NCC байт, где NCC ? 248. Показатель общедоступного ключа сертификационного центра равен 2, 3 или 216+1. Модуль общедоступного ключа эмитента содержит NЭ байт, где NЭ < 248 и NЭ < NCC. Если NЭ > (NCC - 36), модуль общедоступного ключа эмитента делится на две части, одна состоит из NCC – 36 старших байт модуля (левые цифры), а вторая часть содержит остальные NЭ
- (NCC - 36) младших байт модуля (остаток общедоступного ключа эмитента). Показатель общедоступного ключа эмитента равен 2, 3 или 216+1.
Модуль общедоступного ключа ICC содержит NIC байт, где NIC ? 128 и NIC < NЭ. Если NIC > (NЭ - 42), модуль общедоступного ключа ICC делится на две части, одна – состоит из NЭ – 42 старших байт модуля (левые цифры общедоступного ключа ICC) и остальных NIC – (NЭ – 42) младших байт модуля (остаток общедоступного ключа ICC). Показатель общедоступного ключа ICC равен 2, 3 или 216+1.
Для осуществления аутентификации динамических данных терминал сначала извлекает и аутентифицирует общедоступный ключ ICC (аутентификация общедоступного ключа ICC). Вся информация, необходимая для аутентификации общедоступного ключа ICC представлена в таблице 4.6.4.25 и хранится в памяти ICC. За исключением RID, который может быть получен из AID, эта информация извлекается с помощью команды READ RECORD. Если что-то из этой информации отсутствует, аутентификация терпит неудачу.
Таблица 4.6.4.23
. Данные общедоступного ключа эмитента, которые должны быть подписаны сертификационным центром.
| Имя поля |
Длина (байт) |
Описание |
| Формат сертификата | 1 | Шестнадцатеричное число 0х02 |
| Идентификационный номер эмитента | 4 | Левые 3-8 цифр от PAN (дополняемые справа кодами 0хF) |
| Дата истечения времени действия сертификата | 2 | Дата ММГГ, после которой сертификат становится недействительным |
| Серийный номер сертификата | 3 | Двоичное число, уникальное для данного сертификата, присваиваемое центром сертификации |
| Индикатор хэш-алгоритма | 1 | Индицирует алгоритм, используемый для вычисления результирующего хэша цифровой подписи |
| Индикатор алгоритма общедоступного ключа эмитента | 1 | Индицирует алгоритм вычисления цифровой подписи, который должен использоваться совместно с общедоступным ключом эмитента |
| Длина общедоступного ключа эмитента | 1 | Идентифицирует длину модуля общедоступного ключа эмитента в байтах |
| Длина показателя общедоступного ключа эмитента | 1 | Идентифицирует длину показателя общедоступного ключа эмитента в байтах |
| Общедоступный ключ эмитента или левые цифры этого ключа | NCC - 36 |
Если NЭ ? NCC – 36, это поле состоит из полного общедоступного ключа эмитента дополненного справа NCC –36 - NЭ байт с кодом 0хBB. Если NЭ > NCC – 36, это поле состоит из NCC – 36 старших байтов общедоступного ключа эмитента |
| Остаток общедоступного ключа эмитента |
0 или NЭ -NCC + 36 |
Это поле присутствует только если NЭ > NCC – 36 и состоит из NЭ - NCC + 36 младших байт общедоступного ключа эмитента |
| Показатель общедоступного ключа эмитента | 1 или 3 | Показатель общедоступного ключа эмитента равен 2, 3 или 216+1 |
/p>
Таблица 4.6.4.24.
Данные общедоступного ключа ICC, которые должны быть подписаны эмитентом карты
| Имя поля |
Длина (байт) |
Описание |
| Формат сертификата | 1 | Шестнадцатеричное число 0х04 |
| PAN (Primary Application Number) приложения | 10 | PAN дополненный справа кодами 0хF |
| Дата истечения времени действия сертификата | 2 | Дата ММГГ, после которой сертификат становится недействительным |
| Серийный номер сертификата | 3 | Двоичное число, уникальное для данного сертификата, присваиваемое эмитентом |
| Индикатор хэш-алгоритма | 1 | Индицирует алгоритм, используемый для вычисления результирующего хэша цифровой подписи |
| Индикатор алгоритма общедоступного ключа ICC | 1 | Индицирует алгоритм вычисления цифровой подписи, который должен использоваться совместно с общедоступным ключом ICC |
| Длина общедоступного ключа ICC | 1 | Идентифицирует длину модуля общедоступного ключа ICC в байтах |
| Длина показателя общедоступного ключа ICC | 1 | Идентифицирует длину показателя общедоступного ключа ICC в байтах |
| Общедоступный ключ ICC или левые цифры этого ключа | NЭ - 42 |
Если NIC ? NЭ – 42, это поле состоит из полного общедоступного ключа ICC дополненного справа NЭ – 42 - NIC байт с кодом 0хBB. Если NIC > NЭ – 42, это поле состоит из NЭ – 42 старших байтов общедоступного ключа ICC |
| Остаток общедоступного ключа ICC |
0 или NIC - NЭ + 42 |
Это поле присутствует, только если NIC > NЭ – 42 и состоит из NЭ - NCС + 42 младших байт общедоступного ключа ICC |
| Показатель общедоступного ключа ICC | 1 или 3 | Показатель общедоступного ключа ICC равен 2, 3 или 216+1 |
| Данные, подлежащие аутентификации | Переменная | Статические данные, подлежащие аутентификации согласно спецификации ICC для платежных систем |
Таблица 4.6.4.25.
Информационные объекты, необходимые для аутентификации общедоступного ключа
| Метка (Tag) |
Длина (байт) |
Описание |
| - | 5 | Зарегистрированный идентификатор провайдера приложения (RID) |
| 0х8F | 1 | Индекс общедоступного ключа центра сертификации |
| 0х90 | NCC | Сертификат общедоступного ключа эмитента |
| 0х92 | NЭ - NCC + 36 | Остаток общедоступного ключа эмитента (если имеется) |
| 0х9F32 | 1 или 3 | Показатель общедоступного ключа эмитента |
| 0х9F46 | NЭ | Сертификат общедоступного ключа ICC |
| 0х9F48 | NIC - NЭ + 42 | Остаток общедоступного ключа ICC (если он имеется) |
| 0х9F47 | 1 или 3 | Показатель общедоступного ключа ICC |
| - | Переменная | Данные, подлежащие аутентификации |
/p> Терминал считывает индекс общедоступного ключа центра сертификации. Используя этот индекс и RID, терминал может идентифицировать и извлечь из памяти модуль и показатель общедоступного ключа сертификационного центра и сопряженную с ним информацию. Если терминал не сможет найти нужные данные, сертификация не состоится.
Если сертификат общедоступного ключа эмитента имеет длину отличную от длины модуля общедоступного ключа сертификационного центра, аутентификация динамических данных не проходит.
Для того чтобы получить восстановленные данные, представленные в таблице 4.6.4.26, используется сертификат общедоступного ключа эмитента и общедоступный ключ центра сертификации. Если хвостовик восстановленных данных не равен 0хBC, аутентификация динамических данных не проходит.
Проверяется заголовок восстановленных данных и, если он не равен 0х6А, аутентификация отвергается.
Проверяется код формата сертификата и, если он не равен 0х02, аутентификация отвергается.
Объединяются слева направо информационные элементы со второго по десятый (см. табл. 4.6.4.26), добавляется остаток общедоступного ключа эмитента (если он имеется) и показатель этого ключа. Для полученной строки применяется соответствующий алгоритм хэширования. Сравнивается вычисленный хэш и восстановленное значение поля результата хэширования. При несовпадении аутентификация не проходит.
Таблица 4.6.4.26
. Формат восстановленных данных из сертификата общедоступного ключа эмитента.
| Имя поля |
Длина (байт) |
Описание |
| Заголовок восстановленных данных | 1 | Шестнадцатеричное число 0х6А |
| Формат сертификата | 1 | Шестнадцатеричное число 0х02 |
| Идентификационное число эмитента | 4 | Левые 3-8 цифр из PAN, дополненные справа кодами 0хF |
| Дата истечения времени действия сертификата | 2 | Дата ММГГ, после которой сертификат становится недействительным |
| Серийный номер сертификата | 3 | Двоичное число, уникальное для данного сертификата, присваиваемое центром сертификации |
| Индикатор хэш-алгоритма | 1 | Индицирует алгоритм, используемый для вычисления результирующего хэша цифровой подписи |
| Индикатор алгоритма общедоступного ключа эмитента | 1 | Индицирует алгоритм вычисления цифровой подписи, который должен использоваться совместно с общедоступным ключом эмитента |
| Длина общедоступного ключа эмитента | 1 | Идентифицирует длину модуля общедоступного ключа эмитента в байтах |
| Длина показателя общедоступного ключа эмитента | 1 | Идентифицирует длину показателя общедоступного ключа эмитента в байтах |
| Общедоступный ключ эмитента или левые цифры этого ключа | NCC - 36 |
Если NЭ ? NСС – 36, это поле состоит из полного общедоступного ключа эмитента, дополненного справа NСС – 36 - NЭ байтами с кодом 0хBB. Если NЭ > NСС – 36, это поле состоит из NСС – 36 старших байтов общедоступного ключа эмитента |
| Результат хэширования | 20 | Хэш общедоступного ключа эмитента и сопряженных данных |
| Хвостовик восстановленных данных | 1 | Шестнадцатеричное число 0хВС |
/p> Проверяется то, что идентификационный номер эмитента соответствуют 3-8 цифрам PAN. Если соответствия нет, аутентификация отвергается.
Проверяется срок действия сертификата и, если он истек, аутентификация отвергается.
Проверяется то, что объединение RID, индекса общедоступного ключа центра сертификации и серийного номера сертификата корректно.
Если индикатор алгоритма общедоступного ключа эмитента не распознан, аутентификация не проходит. Если все вышеперечисленные проверки прошли успешно, осуществляется объединение левых цифр общедоступного ключа эмитента и остатка этого ключа (если он имеется). Это делается для получения модуля общедоступного ключа эмитента. После данной процедуры система переходит к извлечению общедоступного ключа ICC.
Если сертификат общедоступного ключа ICC имеет длину, отличную от длины модуля общедоступного ключа эмитента, авторизация не проходит.
Для того чтобы получить данные, специфицированные в таблице 4.6.4.27, используется сертификат общедоступного ключа ICC и общедоступный ключ эмитента. Если хвостовик восстановленных данных не равен 0хВС, аутентификация не проходит.
Если при проверке код заголовка восстановленных данных не равен 0х6А, аутентификация не проходит.
Если код формата сертификата не равен 0х04, аутентификация также не проходит.
Таблица 4.6.4.27
. Формат восстановленных данных из сертификата общедоступного ключа ICC.
| Имя поля |
Длина (байт) | Описание |
| Заголовок восстановленных данных | 1 | Шестнадцатеричное число 0х6А |
| Формат сертификата | 1 | Шестнадцатеричное число 0х04 |
| PAN приложения | 10 | PAN, дополненный справа кодами 0хF |
| Дата истечения времени действия сертификата | 2 | Дата ММГГ, после которой сертификат становится недействительным |
| Серийный номер сертификата | 3 | Двоичное число, уникальное для данного сертификата, присваиваемое центром сертификации |
| Индикатор хэш-алгоритма | 1 | Индицирует алгоритм, используемый для вычисления результирующего хэша цифровой подписи |
| Индикатор алгоритма общедоступного ключа ICC | 1 | Индицирует алгоритм вычисления цифровой подписи, который должен использоваться совместно с общедоступным ключом ICC |
| Длина общедоступного ключа ICC | 1 | Идентифицирует длину модуля общедоступного ключа ICC в байтах |
| Длина показателя общедоступного ключа ICC | 1 | Идентифицирует длину показателя общедоступного ключа ICC в байтах |
| Общедоступный ключ ICC или левые цифры общедоступного ключа ICC | NЭ - 42 |
Если NIC ? NЭ – 42, это поле состоит из полного общедоступного ключа ICC, дополненного справа NЭ – 42 - NIC байтами с кодом 0хBB. Если NIC > NЭ – 42, это поле состоит из NЭ – 42 старших байтов общедоступного ключа ICC |
| Результат хэширования | 20 | Хэш общедоступного ключа ICC и сопряженных с ним данных |
| Хвостовик восстановленных данных | 1 | Шестнадцатеричное число 0хВС |
/p> Объединяются слева направо поля из таблицы 4.6.4.27, начиная со второго до десятого, добавляется остаток общедоступного ключа ICC (если имеется), показатель общедоступного ключа ICC и данные, подлежащие аутентификации. Это объединение хэшируется согласно указанному алгоритму. Результат сравнивается со значением поля результат хэширования. При несовпадении аутентификация не проходит.
Восстановленный PAN должен быть равен PAN приложения (ICC). После этого проверяется срок пригодности сертификата. Если все выше перечисленные проверки оказались успешными, система переходит к последующим тестам.
После получения общедоступного ключа ICC терминал выдает команду INTERNAL AUTHENTICATE для объединения информационных элементов DDOL (Dynamic Data Authentication Data Object List). ICC может нести в себе DDOL, но терминал имеет значение DDOL по умолчанию, специфицированное платежной системой на случай отсутствия этих данных в ICC. DDOL должен содержать непредсказуемое число, формируемое терминалом (тэг 0х9F37, четыре двоичных байта).
ICC генерирует цифровую подпись для данных, специфицированных в таблице 4.6.4.28 с использованием секретного ключа (SIC) ICC. Результат называется подписанными динамическими данными приложения.
Таблица 4.6.4.28.
Динамические данные приложения, которые должны быть подписаны
| Имя поля |
Длина (байт) |
Описание |
| Формат подписанных данных | 1 | Шестнадцатеричное число 0х05 |
| Индикатор хэш-алгоритма | 1 | Индицируется алгоритм хэширования, используемый для получения результата |
| Длина динамических данных ICC | 1 | Идентифицирует длину LDD динамических данных ICC в байтах |
| Динамические данные ICC | LDD | Динамические данные, сформированные и/или записанные в ICC |
| Символы заполнителя | NIC - LDD - 25 | (NIC - LDD – 25) байтов заполнителя, содержащего коды 0хBB |
| Динамические данные терминала | Переменная | Объединение информационных элементов, специфицированных DDOL |
Кроме данных, перечисленных в таблице 4.6.4.28, для аутентификации динамических данных необходимы информационные объекты:
Подписанные динамические данные приложения (NIC байтов; тэг 9F4B) и DDOL (тэг 9F49).
Если подписанные динамические данные приложения имеют длину отличную от длины модуля общедоступного ключа ICC, аутентификация не проходит.
Чтобы получить восстановленные данные, описанные в таблице 4.6.4.29 для подписанных динамических данных приложения используется общедоступный ключ ICC. Если хвостовик восстановленных данных не равен 0хBC, аутентификация не проходит.
Таблица 4.6.4.29
. Формат данных, полученных из подписанных динамических данных приложения
| Имя поля |
Длина (байт) |
Описание |
| Заголовок восстановленных данных | 1 | Шестнадцатеричное число 0х6А |
| Формат подписанных данных | 1 | Шестнадцатеричное число 0х05 |
| Индикатор алгоритма хэширования | 1 | Индицируется алгоритм хэширования, используемый для получения результата при вычислении цифровой подписи |
| Длина динамических данных ICC | 1 | Идентифицирует длину динамических данных ICC в байтах |
| Динамические данные ICC | LDD | Динамические данные, сформированные и/или записанные в ICC |
| Символы заполнителя | NIC - LDD - 25 | (NIC - LDD – 25) байтов заполнителя, содержащего коды 0хBB |
| Результат хэширования | 20 | Хэш динамических данных приложения и сопряженной информации |
| Хвостовик восстановленных данных | 1 | Шестнадцатеричное число 0хВС |
Производится объединение слева направо шести информационных элементов из таблицы 4.6.4.29 (начиная с поля формата подписанных данных). Производится хэширование этого объединения, после чего полученный результат сравнивается со значением поля результата хэширования и, если совпадения нет, аутентификация не проходит. Если все предыдущие шаги оказались успешными, аутентификация динамических данных завершается успехом.
4.6.4.5. Безопасный обмен сообщениями
Целью безопасного обмена сообщениями является обеспечение конфиденциальности, целостность данных и аутентификация отправителя. Принято два формата сообщений.
Формат 1
следует спецификации ISO/IEC 7816-4, где поле данных кодируется согласно BER-TLV и правилам ASN.1/ISO 8825. Этот формат задается младшим полубайтом класса команды равным 0xC. Формат предполагает также, что заголовок команды включается в вычисление MAC (Message Authentication Code).
Формат 2
не использует кодирования BER-TLV. В этом случае информационные объекты, содержащиеся в поле данных и их длины должны быть известны отправителю команды и выбранному приложению. Согласно спецификации ISO/IEC 7816-4 этот формат задается младшим полубайтом байта класса, который должен быть равен 0х4.
Поле данных команды в случае формата 1 состоит из следующих TLV (Tag Length Value) информационных объектов, как это показано на рисунке 4.6.4.13.

Рис. 4.6.4.13. Формат 1 поля данных команды для безопасного обмена сообщениями
Данные команды, если имеются, должны быть подписаны. Если поле данных закодировано согласно BER-TLV, оно либо не должно принадлежать контекстному классу (тэг лежит вне диапазона 80-BF), либо иметь четный тэг. Вторым информационным объектом является MAC. Его тэг равен 0х8Е, а его длина лежит в диапазоне 4-8 байт.
В случае формата 2 МАС не кодируется BER-TLV и всегда является последним элементом информационного поля, а его длина лежит в пределах 4-8 байт.
Вычисление s байтов МАС (4?s?8) осуществляется согласно ISO/IEC9797 с использованием 64-битового блочного шифра ALG в режиме CBC.
Процедура формирования МАС начинается с получения ключа сессии из мастерного ключа МАС ICC. Ключ сессии KS для безопасного обмена сообщениями получается из уникальных мастерных ключей MK с привлечением непредсказуемых данных R, так что KS := F(KS)[R]. Единственным требованием к функции F является то, что число возможных ее значений достаточно велико и равномерно распределено.
При использовании формата 1 сообщение состоит из заголовка команды APDU (Application Protocol Data Unite = CLA INS P1 P2) и командной информации (если таковая имеется).
В случае формата 2 сообщение формируется согласно спецификации используемой платежной схемы. Но оно всегда содержит заголовок команды APDU.
Если МАС специфицирован, как имеющий длину менее 8 байтов, он получается из старших (левых) байтов 8-байтного результата его вычисления.
Формат зашифрованных командных данных показан на рисунке 4.6.4.14.
| Тэг | Длина | Значение |
| T | L | Криптограмма (зашифрованные данные) |
Тэг, согласно спецификации ISO/IEC 7816-6 определяется характером исходных (незашифрованных данных). Четный тэг используется, если объект должен быть включен в вычисление МАС; во всех остальных случаях тэг должен быть нечетным.
В случае формата 2 поле данных команды шифруется как целое, исключение составляет MAC, если он присутствует (см. рис. 4.6.4.15)
| Значение 1 | Значение 2 |
| Криптограмма (зашифрованные данные) | МАС (если имеется) |
Процедура шифрования начинается с получения ключа сессии, который вычисляется на основе мастерного ключа шифрования ICC (см. выше). Шифрование производится с использованием 64-битного блочного шифра ALG в режиме СВС (симметричная схема).
Для увеличения безопасности может использоваться PIN (Personal Identification Number). Верификация PIN осуществляется терминалом с использованием асимметричного алгоритма (общедоступный и секретный ключи).
Более полное описание технологии EMV вы можете найти по адресу (английская версия): ftp://saturn.itep.ru/~emvcard.pdf
Не исключено, что конкуренцию EMV-картам в торговле через Интернет составят виртуальные кредитные карты, применение которых упомянуто во введении.
Современные поисковые системы
4.5.14 Современные поисковые системы
Семенов Ю.А. (ГНЦ ИТЭФ)

Развитие Интернет начиналось как средство общения и удаленного доступа (электронная почта, telnet, FTP). Но постепенно эта сеть превратилась в средство массовой информации, отличающееся тем, что операторы сети сами могут быть источниками информации и определяют, в свою очередь то, какую информацию они хотят получить.
Среди первых поисковых систем были archie, gopher и wais. Эти относительно простые системы казались тогда чудом. Использование этих систем показало их недостаточность и определенные врожденные недостатки: ограниченность зоны поиска и отсутствие управления этим процессом. Поиск проводился по ограниченному списку серверов и никогда не было известно, насколько исчерпывающую информацию получил клиент.
Первые WWW-системы работали в режиме меню (Mosaic появилась несколько позже) и обход дерева поиска производился вручную. Структура гиперсвязей могла иметь циклические пути, как, например, на рис. 4.5.14.1. Число входящих и исходящих гиперсвязей для любого узла дерева может быть произвольным.
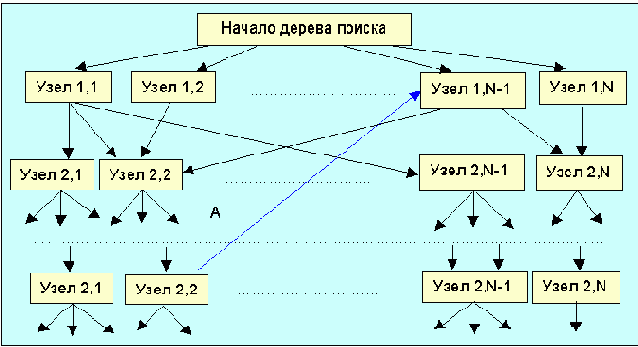
Рис. 4.5.14.1. Пример дерева гиперсвязей
Связь, помеченная буквой А может явиться причиной образования цикла при обходе дерева. Исключить такие связи невозможно, так как они носят принципиально смысловой характер. По этой причине любая автоматизированная программа обхода дерева связей должна учитывать такую возможность и исключать циклы обхода.
Задача непроста даже в случае поиска нужного текста в пределах одного достаточно большого по емкости диска, когда вы заранее не знаете или не помните в каком субкаталоге или в каком файле содержится искомый текст. Для облегчения ручного поиска на серверах FTP в начале каждого субкаталога размещается индексный файл.
Для решения этой задачи в большинстве операционных систем имеются специальные утилиты (например, grep для UNIX). Но даже они требуют достаточно много времени, если, например, дисковое пространство лежит в пределах нескольких гигабайт, а каталог весьма разветвлен. В полнотекстных базах данных для ускорения поиска используется индексация по совокупности слов, составляющих текст. Хотя индексация также является весьма времяемкой процедурой, но производить ее, как правило, приходится только один раз. Проблема здесь заключается в том, что объем индексного файла оказывается сравным (а в некоторых случаях превосходит) с исходным индексируемым файлом. Первоначально каждому документу ставился в соответствие индексный файл, в настоящее время индекс готовится для тематической группы документов или для поисковой системы в целом. Такая схема индексации экономит место в памяти и ускоряет поиск. Для документов очень большого размера может использоваться отдельный индекс, а в поисковой системе иерархический набор индексов. Индексированием называется процесс перевода с естественного языка на информационно-поисковый язык. В частности, под индексированием понимается отнесение документа в зависимости от содержимого к определенной рубрике некоторой классификации. Индексирование можно свести к проблеме распознавания образов. Классификация определяет разбиение пространства предметных областей на непересекающиеся классы. Каждый класс характеризуется набором признаков и специфических для него терминов (ключевых слов), выражающих основные понятия и отношения между ними.
Слова в любом тексте в информационном отношении весьма неравнозначны. И дело не только в том, что текст содержит много вспомогательных элементов предлогов или артиклей (напр., в англоязычных текстах). Часто для сокращения объема индексных регистров и ускорения самого процесса индексации вводятся так называемые стоп-листы. В эти стоп-листы вносятся слова, которые не несут смысловой нагрузки (например, предлоги или некоторые вводные слова). Но при использовании стоп-листов необходима определенная осторожность. Например, занеся в стоп-лист, неопределенный артикль английского языка “а”, можно заблокировать нахождение ссылки на “витамин А”.
Немалое влияние оказывает изменяемость слов из-за склонения или спряжения. Последнее делает необходимым лингвистический разбор текста перед индексацией. Хорошо известно, что смысл слова может меняться в зависимости от контекста, что также усложняет проблему поиска. Практически все современные информационные системы для создания и обновления индексных файлов используют специальные программные средства.
Существующие поисковые системы успешно работают с HTML-документами, с обычными ASCII-текстами и новостями usenet. Трудности возникают для текстов Winword и даже для текстов Postscript. Связано это с тем, что такие тексты содержат большое количество управляющих символов и текстов. Трудно (практически невозможно) осуществлять поиск для текстов, которые представлены в графической форме. К сожалению, к их числу относятся и математические формулы, которые в HTML имеют формат рисунков (это уже недостаток самого языка). Так что можно без преувеличения сказать, что в этой крайне важной области, имеющей немалые успехи, мы находимся лишь в начале пути. Ведь море информации, уже загруженной в Интернет, требует эффективных средств навигации. Ведь оттого, что информации в сети много, мало толку, если мы не можем быстро найти то, что нужно. И в этом, я полагаю, убедились многие читатели, получив на свой запрос список из нескольких тысяч документов. Во многих случаях это эквивалентно списку нулевой длины, так как заказчик в обоих случая не получает того, что хотел.
Встроенная в язык HTML метка <meta> создана для предоставления информации о содержании документа для поисковых роботов, броузеров и других приложений. Структура метки: <meta http-equiv=response content=description name=description URL=url>. Параметр http-equiv=response ставит в соответствие элементу заголовок HTTP ответа. Значение параметра http-equiv интерпретируется приложением, обрабатывающим HTML документ. Значение параметра content определяется значением, содержащимся в http-equiv.
Современная поисковая система содержит в себе несколько подсистем.
web-агенты. Осуществляют поиск серверов, извлекают оттуда документы и передают их системе обработки.
Система обработки. Индексирует полученные документы, используя синтаксический разбор и стоп-листы (где, помимо прочего, содержатся все стандартные операторы и атрибуты HTML).
Система поиска. Воспринимает запрос от системы обслуживания, осуществляет поиск в индексных файлах, формирует список найденных ссылок на документы.
Система обслуживания. Принимает запросы поиска от клиентов, преобразует их, направляет системе поиска, работающей с индексными файлами, возвращает результат поиска клиенту. Система в некоторых случаях может осуществлять поиск в пределах списка найденных ссылок на основе уточняющего запроса клиента (например, recall в системе altavista). Задание системе обслуживания передается WEB-клиентом в виде строки, присоединенной к URL, наример, http://altavista.com/cgi-bin/query?pg=q&what=web&fmt=/&q=plug+%26+play, где в поле поиска было записано plug & play)
Следует иметь в виду, что работа web-агентов и системы поиска напрямую независимы. WEB-агенты (роботы) работают постоянно, вне зависимости от поступающих запросов. Их задача – выявление новых информационных серверов, новых документов или новых версий уже существующих документов. Под документом здесь подразумевается HTML-, текстовый или nntp-документ. WEB-агенты имеют некоторый базовый список зарегистрированных серверов, с которых начинается просмотр. Этот список постоянно расширяется. При просмотре документов очередного сервера выявляются URL и по ним производится дополнительный поиск. Таким образом, WEB-агенты осуществляют обход дерева ссылок. Каждый новый или обновленный документ передается системе обработки. Роботы могут в качестве побочного продукта выявлять разорванные гиперсвязи, способствовать построению зеркальных серверов.
Обычно работа роботов приветствуется, ведь благодаря ним сервер может обрести новых клиентов, ради которых и создавался сервер. Но при определенных обстоятельствах может возникнуть желание ограничить неконтролируемый доступ роботов к серверам узла. Одной из причин может быть постоянное обновление информации каких-то серверов, другой причиной может стать то, что для доставки документов используются скрипты CGI. Динамические вариации документа могут привести к бесконечному разрастанию индекса. Для управления роботами имеются разные возможности. Можно закрыть определенные каталоги или сервера с помощью специальной фильтрации по IP-адресам, можно потребовать идентификации с помощью имени и пароля, можно, наконец, спрятать часть сети за Firewall. Но существует другой, достаточно гибкий способ управления поведением роботов. Этот метод предполагает, что робот следует некоторым неформальным правилам поведения. Большинство из этих правил важны для самого робота (например, обхождение так называемых “черных дыр”, где он может застрять), часть имеет нейтральный характер (игнорирование каталогов, где лежит информация, имеющая исключительно локальный характер, или страниц, которые находятся в состоянии формирования), некоторые запреты призваны ограничить загрузку локального сервера.
Когда воспитанный робот заходит в ЭВМ, он проверяет наличие в корневом каталоге файла robots.txt. Обнаружив его, робот копирует этот файл и следует изложенным в нем рекомендациям. Содержимое файла robots.txt в простейшем случае может выглядеть, например, следующим образом.
# robots.txt for http://store.in.ru
Автор исходного текста может заметно помочь поисковой системе, выбрав умело заголовок и подзаголовок, профессионально пользуясь терминологией и перечислив ключевые слова в подзаголовках. Исследования показали, что автор (а иногда и просто посторонний эксперт) справляется с этой задачей быстрее и лучше, чем вычислительная машина. Но такое пожелание вряд ли станет руководством к действию для всех без исключения авторов. Ведь многие из них, давая своему тексту образный заголовок, рассчитывают (и не без успеха) привлечь к данному тексту внимание читателей. Но машинные системы поиска не воспринимают (во всяком случае, пока) образного языка. Например, в одном лабораторном проекте, разработанном для лексического разбора выражений, состоящих из существительных с определяющим прилагательным, и по своей теме связанных с компьютерной тематикой, система была не способна определить во фразе “иерархическая компьютерная архитектура” то, что прилагательное “иерархическая” относится к слову “архитектура”, а не к “компьютерная” (Vickery & Vickery 1992). То есть система была не способна отличать образное использование слова в выражении от его буквального значения.
В свою очередь специалисты, занятые в области поисковых и информационных систем, способны заметно облегчить работу авторам, снабдив их необходимыми современными тезаурусами, где перечисляются нормативные значения базовых терминов в той или иной научно-технической области, а также устойчивых словосочетаний. Параллельно могут быть решены проблемы синонимов.
В настоящее время, несмотря на впечатляющий прогресс в области вычислительной техники, степень соответствия документа определенным критериям запроса надежнее всего может определить человек. Но темп появления электронных документов в сети достигает ошеломляющего уровня (частично это связано с преобразованием в электронную форму старых документов и книг методом сканирования). Написание рефератов для последующего их использование поисковыми системами достаточно изнурительное занятие, требующее к тому же достаточно высокой профессиональной подготовки. Именно по этой причине уже достаточно давно предпринимаются попытки перепоручить этот процесс ЭВМ. Для этого нужно выработать критерии оценки важности отдельных слов и фраз, составляющих текст. Оценку значимости предложений выработал Г.Лун. Он предложил оценивать предложения текста в соответствии с параметром: Vпр =
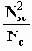
Автоматическая система выявления ключевых слов обычно использует статистический частотный анализ (методика В. Пурто). Пусть f – частота, с которой встречаются различные слова в тексте, а u – относительное значение полезности (важности).
Тогда зависимость f(u) апроксимируется формулой
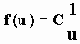 http://www.medialingvo.ru)]. К сожалению, выбор порогов процедура достаточно субъективная. Ключевые слова, выявляемые программно, аранжируются согласно частоте их использования. Замечено, что определенное значение имеет не только частота применения слова в конкретном документе, но и число документов, в которых это слово встречается. В работах Спарка Джонса экспериментально показано, что если N
http://www.medialingvo.ru)]. К сожалению, выбор порогов процедура достаточно субъективная. Ключевые слова, выявляемые программно, аранжируются согласно частоте их использования. Замечено, что определенное значение имеет не только частота применения слова в конкретном документе, но и число документов, в которых это слово встречается. В работах Спарка Джонса экспериментально показано, что если N – число документов и n – число документов, в которых встречается данный индексный термин (ключевое слово), то вычисление его веса по формуле:
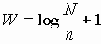
Одним из известных путей облегчения процедуры поиска является группирование документов по определенной достаточно узкой тематике в кластеры. В этом случае запрос с ключевым словом, фигурирующем в заголовке кластера, приведет к тому, что все документы кластера будут включены в список найденных. Кластерный метод наряду с очевидными преимуществами (прежде всего заметное ускорение поиска) имеет столь же явные недостатки. Документы, сгруппированные по одному признаку, могут быть случайно включены в перечень документов, отвечающих запросу, по той причине, что одно из ключевых слов кластера соответствует запросу. В результате в перечне найденных документов вы можете с удивлением обнаружить тексты, не имеющие никакого отношения к интересующей вас теме.
Некоторые поисковые системы предоставляют возможность нахождения документов, где определенные ключевые слова находятся на определенном расстоянии друг от друга (proximity search).
Наиболее эффективным инструментом при поиске можно считать возможность использования в запросе булевых логических операторов AND, OR и NOT. Объединение ключевых слов с помощью логических операторов может сузить или расширить зону поиска.
Проблема соответствия (релевантности) документа определенному запросу совсем не проста.
Индексные файлы, содержащие информацию о WEB-сайтах, занимают около 200 Гигабайт дискового пространства, поиск по содержимому которых производится за время, меньшее одной секунды (на самом деле, реальный поиск производится в более чем в десять раз меньшем объеме). Такой объем содержащейся информации делает Altavista неоценимым помощником в поиске нужных документов и серьезным конкурентом для остальных компаний, содержащих поисковые серверы. Поисковая система Altavista работает на самых мощных компьютерах, произведенных компанией Digital Equipment Corporation – это 16 серверов Alphaserver 8400 5/440, объединенных в сетевой кластер. Каждый из серверов имеет 8 Гбайт оперативной памяти (может иметь до 28 Гбайт), содержит 12 (до 14) процессоров Digital Alfa с тактовой частотой 437 МГц, в качестве жестких дисков используются высокоскоростные и надежные дисковые системы RAID с общим объемом 300 Гбайт. Для обеспечения связи с Интернет используются каналы с суммарной пропускной способностью 100 Мбит/с через шлюз DEC Palo Alto – что является самым мощным корпоративным шлюзом в Интернет.
Пример широко известной поисковой системы alta vista, где задействовано большое число суперЭВМ, показывает, что дальнейшее движение по такому пути вряд ли можно считать разумным, хотя прогресс в вычислительной технике может и опровергнуть это утверждение. Тем не менее, даже в случае фантастических достижений в области создания еще более мощных ЭВМ, можно утверждать, что распределенные поисковые системы могут оказаться эффективнее. Во-первых, местный администратор быстрее может найти общий язык с авторами текстов, которые могут точнее выбрать набор ключевых слов. Во-вторых, распределенная система способна распараллелить обработку одного и того же информационного запроса. Распределенная система памяти и процессоров может, в конце концов, стать более адекватной потокам запросов к информации, содержащейся на том или ином сервере. Способствовать этому может также создание тематических серверов поиска, где концентрируется информация по относительно узкой области знаний. Для таких серверов возможен отбор документов экспертами, они же могут определить списки ключевых слов для многих документов. Здесь возможна автоматическая предварительная процедура фильтрации документов по наличию определенного набора ключевых слов. Способствует этому и существование тематических журналов, где сконцентрированы статьи по определенной тематике.
В случаях, когда поисковая система выдает заказчику большой список документов, отвечающих критериям его запроса, бывает важно, чтобы они были упорядочены согласно их степени соответствия (наличие ключевых слов в заголовке, большая частота использования ключевых слов в тексте документа и т.д.). Но простые критерии здесь не всегда срабатывают, так объемный документ имеет больше шансов попасть в список результата поиска, так как в нем много слов и с большой вероятностью там встречается ключевое слово. По этому критерию Британская энциклопедия должна попасть в результирующий список любого запроса. Для компенсации искажений, вносимых длиной документов, используется нормализация весов индексных терминов.
Нормализация представляет собой способ уменьшения абсолютного значения веса индексных терминов, обнаруженных в документе. Одним из наиболее распространенных методов, решающих данную проблему, является косинусная нормализация. При использовании этого метода нормализации вес каждого индексного термина делится на Евклидову длину вектора оцениваемого документа. Евклидова длина вектора определяется формулой:
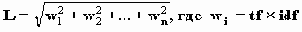 tf – (term frequency), частота, с которой встречается данный индексный термин; IDF (Inverted Document Frequency) – величина, обратная частоте, с которой данный термин встречается во всей совокупности документов. Окончательная формула для вычисления веса термина (w) в документе с учетом косинусного фактора нормализации представляется формулой:
tf – (term frequency), частота, с которой встречается данный индексный термин; IDF (Inverted Document Frequency) – величина, обратная частоте, с которой данный термин встречается во всей совокупности документов. Окончательная формула для вычисления веса термина (w) в документе с учетом косинусного фактора нормализации представляется формулой: 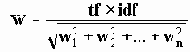
В работах Букштейна, Свенсона и Хартера было показано, что распределение функциональных слов в отличие от специфических слов с хорошей точностью описывается распределением Пуассона. То есть, если ищется распределение функционального слова w в некотором множестве документов, тогда вероятность f(n) того, что слово w будет встречено в тексте n раз представляется функцией:
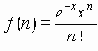
Для представления документов используется векторная модель, где любой документ характеризуется бинарным вектором x = x1,x2,…, xn, где значения xi = 0 или 1, в зависимости от того, присутствует в тексте i-ый индексный термин или нет. Рассматриваются два взаимно исключающих события:
w1 - документ удовлетворяет запросу
w2 - документ удовлетворяет запросу
Для каждого документа необходимо вычислить условные вероятности P(w1|x) и P(w2|x) для определения, какие документы удовлетворяют запросу, а какие нет.
Непосредственно получить значения этих вероятностей нельзя, поэтому необходимо найти другой альтернативный подход для их определения с помощью известных нам величин. По формуле Байеса для дискретного распределения условных вероятностей:
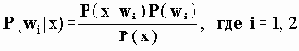
В приведенной формуле P(w1) – первоначальная вероятность соответствия (i = 1) или несоответствия (i = 2) запросу, величина P(x|wi) пропорциональна вероятности соответствия или несоответствия запросу для данного x; в недискретном случае она представляет собой функцию плотности распределения и обозначается как P(x|wi).
Окончательно:
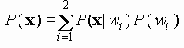
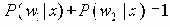 ).
).Для определения релевантности документа используется вполне очевидное правило:
Если
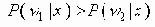 [1].
[1].В противном случае считается, что документ не удовлетворяет запросу. При равенстве значений вероятности решение о релевантности документа принимается произвольно.
Правило [1] основано на том, что при его использовании просто минимизируется средняя вероятность ошибки принятия нерелевантного документа за релевантный и наоборот. То есть, для любого документа x вероятность ошибки
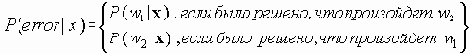
Таким образом, для минимизации средней вероятности ошибки необходимо минимизировать функцию
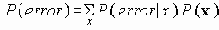
Не углубляясь в теорию вероятностного нахождения релевантных документов, укажем еще одно правило, которое можно использовать вместо [1]:

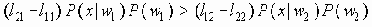 . [2]
. [2]В формуле [2] коэффициенты lij стоимостной функции определяют потери, вносимые при ожидании события wi, когда на самом деле произошло событие wj.
Для практической реализации вероятностного поиска вводится упрощающее предположение относительно P(x|wi). Принимается, что значения xi вектора x являются статистически независимыми. Данное утверждение математически представляется в виде:
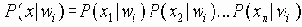
Определим переменные:
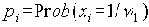
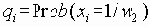 , представляющие собой вероятность того, что в документе присутствует i-ый индексный термин при условии, что документ является релевантным (нерелевантным). Соответствующая вероятность для отсутствия индексных терминов имеет вид
, представляющие собой вероятность того, что в документе присутствует i-ый индексный термин при условии, что документ является релевантным (нерелевантным). Соответствующая вероятность для отсутствия индексных терминов имеет вид 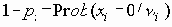
Вероятностные функции, используемые для подстановки в правило [1] имеют вид:
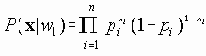
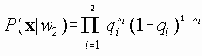
Подставляя значения
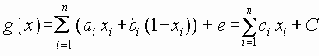
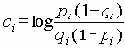
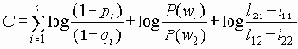 .
.Функция G(x) представляет собой ничто иное, как весовую функцию, в которой коэффициенты Сi представляют собой веса присутствующих в документе индексных терминов. Константа С одинакова для всех документов x, но, конечно, различна для разных запросов и может рассматриваться в качестве порогового значения для поисковой функции. Единственными параметрами, которые могут меняться для данного запроса являются параметры стоимостной функции, вариации которых позволяют получать в ответе большее или меньшее число документов.
Теперь рассмотрим коэффициенты Сi функции G(x) с использованием следующей терминологии:
Таблица 4.5.14.1.
| Релевантные документы | Нерелевантные документы | Общее количество документов | |
 |
 |
 |
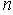 |
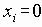 |
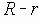 |
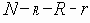 |
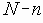 |
| Всего |
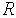 |
 |
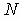 |
R - число релевантных документов
r - число релевантных документов, выданных в ответ на запрос
n - полное число документов, выданных в ответ на запрос
Таблица представляет результаты запроса, направленного системе поиска. Представленная таблица должна существовать для каждого из индексных терминов.
Если мы обладаем всей информацией о релевантных и нерелевантных документах в коллекции документов, то применимы следующие оценки:
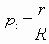
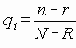 . Тогда функция g(x) может быть переписана в виде
. Тогда функция g(x) может быть переписана в виде 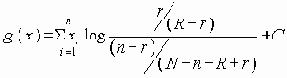
Коэффициент при xi показывает, до какой степени можно провести дискриминацию по i-тому термину в рассматриваемой коллекции документов. В действительности, N может рассматриваться не только как полное количество документов во всей коллекции, но и в некотором ее подмножестве.
Все приведенные формулы были выведены при условии, что индексные термины являются статистически независимыми. В общем случае это, конечно, не так. В теории вероятностного поиска моделируется зависимость между различными индексными формулами, в связи с чем, вид функции G(x) несколько меняется.
Многие системы поиска информации основаны на словарях и тезаурусах для корректировки запросов и представления индексируемых документов, чтобы увеличить шансы найти необходимый документ. На практике, большинство словарей составляется вручную. Словари создаются с помощью одного из двух основных способов:
Связываются слова, описывающие одну и ту же тему.
Связываются слова, описывающие похожие темы.
В первом случае связываются слова, являющиеся взаимозаменяемыми, то есть, в словарях и тезаурусах они принадлежат одному и тому же классу. То есть, можно выбрать по одному слову из каждого класса и совокупность выбранных слов может быть использована для создания контролируемого словаря. Выбирая слова из созданного контролируемого словаря можно проводить индексацию документов или создавать поисковые запросы.
Во втором случае для создания тезауруса используются семантические связи между словами для построения, например, иерархической структуры связей. Создание такого типа словарей является достаточно сложным и трудоемким процессом.
Однако, были предложены способы и для автоматического создания словарей. В то время как созданные вручную словари опираются на семантику (т.е. распознают синонимы, являются более обширными, используют более тонкие взаимосвязи), автоматически созданные тезаурусы, в основном, основаны на синтаксическом и статистическом анализе. Но, так как, использование синтаксиса не приводит к серьезному увеличению эффективности работы систем, то значительно большее внимание уделяется статистическим методам.
Основное допущение, используемое для автоматического создания классов ключевых слов, заключается в следующем. Если ключевые слова a и b могут быть взаимозаменяемы в том смысле, что мы готовы принять документ, содержащий ключевое слово b вместо ключевого слова a и наоборот, то данное обстоятельство имеет место из-за того, что слова a и b имеют одинаковое значение или ссылаются на одинаковые темы.
Основываясь на описанном принципе нетрудно видеть, что создание классификации слов может быть автоматизировано. Можно определить два основных приближения для использования классификации ключевых слов:
Производить замену каждого из ключевых слов, встречающегося в представлении документа или запроса, названием класса, которому оно принадлежит.
Заменять каждое из встреченных ключевых слов всеми словами, входящими в класс, которому принадлежит рассматриваемое ключевое слово.
Для простейшей поисковой стратегии, использующей только что описанные дескрипторы, независимо от того, являются ли они ключевыми словами или названиями классов, созданных на основе группы ключевых слов, “расширенное” представление документов и запросов с помощью любого из вышеописанных способов может существенно повысить число соответствий между документами и запросами и, следовательно, увеличить значение параметра recall. Правда, последнее обстоятельство не является определяющим, так как значение имеет только совокупность параметров (recall, precision), а одно лишь увеличение параметра recall может привести лишь к увеличению объема выдаваемых в ответ на запрос различных документов.
В отчетах об экспериментальных работах по использованию автоматической классификации ключевых слов, проведенных уже упоминавшимся ранее Спарком Джонсом, сообщается, что использование автоматической классификации приводит к увеличению эффективности работы системы по сравнению с системой, использующей неклассифицированные ключевые слова.
Работа Минкера и др. не подтвердила выводы Спарка Джонса и, фактически, показала, что в некоторых случаях использование классификации ключевых слов приводит к существенному ухудшению работы системы в целом. Д. Сальтон в своем отзыве о работе Минкера определил, что целесообразность использования классификации ключевых слов для улучшения эффективности работы поисковых систем еще полностью не определена и является объектом дальнейших экспериментальных исследований. Действительно, при работе в Интернет с поисковыми системами, использующими классификацию ключевых слов, (такими как lycos и excite) заметно существенное увеличение документов, не представляющих ничего общего с запросом, но, тем не менее, имеющих довольно высокий ранг и, следовательно, по мнению поисковой системы, наиболее точно соответствующих заданному запросу.
Для дальнейшего увеличения эффективности системы используется так называемая кластеризация документов.
Существуют две основные области применения методов классификации в системах поиска и локализации информации. Это – кластеризация (классификация) ключевых слов и кластеризация документов.
Под кластеризацией документов понимается создание групп документов, таких, что документы, принадлежащие одной группе, оказываются, в некоторой степени, связанными друг с другом. Другими словами, документы принадлежат одной группе потому, что ожидается, что эти документы будут находиться вместе в результате обработки запроса. Логическая организация документов достигается, в основном, двумя следующими способами.
Первый – путем непосредственной классификации документов и второй – посредством промежуточного вычисления некоторой величины соответствия между различными документами.
Было теоретически доказано, что первый метод является очень сложным для практической реализации, так что любые экспериментальные результаты не могут считаться достаточно надежными. Второй способ классификации заслуживает подробного внимания, и, по сути, является единственным реальным подходом к решению проблемы.
На практике почти невозможно сопоставить каждый из документов каждому из запросов из–за слишком больших затрат машинного времени на проведение таких операций. Было предложено много различных способов для уменьшения количества необходимых для выполнения запроса операций сравнения. Наиболее многообещающим было предложение использовать группы взаимосвязанных документов, используя процедуры автоматического определения соответствия документов. Проводя сравнения запроса всего лишь с одним документом, являющимся представителем группы (заранее определенным) и, таким образом, определяя группу документов, в которой и происходит дальнейший поиск, существенно уменьшается затрачиваемое на обработку запроса машинное время. Однако, Дж. Сальтон полагал, что, хотя использование кластеризации документов и уменьшает время поиска, но неизбежно снижает эффективность поисковой системы. Точка зрения других исследователей несколько отличается от мнения Дж. Сальтона, так, в работе Jardine, N. и Van Rijsbergen, c.j., “The Use of Hierarchic Clustering in Information Retrieval”, Information Storage and Retrieval, 7, 217-240 (1971) делаются выводы о достаточно высоком потенциале методов кластеризации для увеличения эффективности работы поисковых систем.
Для построения систем поиска информации с использованием кластеров необходимо использовать методы для определения степени взаимосвязи между объектами. На основе определенных взаимосвязей можно построить систему кластеров. Взаимосвязь между документами определяется понятиями “степень сходства”, “степень различия” и “степень соответствия”. Значение степени сходства и степени соответствия между документами увеличивается по мере увеличения количества совпадающих параметров. В рассмотрении могут участвовать совершенно разные параметры. Некоторыми исследователями отмечалось, что различие в производительности поисковых систем при использовании различных способов определения степени ассоциации является несущественным, при условии, что функции, используемые для ее определения, являются соответствующим образом нормализованными. Интуитивно, такой вывод можно понять, так как большинство методов определения взаимосвязи между документами используют одни и те же параметры (использующие, в большинстве, статистический анализ текстовых документов). Данное предположение подтверждается в работах И. Лермана, где показано, что многие из способов определения степени соответствия являются монотонными по отношению друг к другу.
В теории поиска информации используется пять основных способов определения степени соответствия. Документы и запросы представляются, в основном, с помощью индексных терминов или ключевых слов, поэтому для облегчения описания моделей обозначим посредством
Самая простая из моделей для определения степени соответствия – это так называемый простой коэффициент соответствия:
В следующей таблице показаны другие подходы к определению степени соответствия, использующие коэффициенты, учитывающие размеры множеств
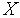
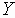 .
.Таблица 4.5.14.2
| Коэффициент | Название |
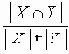 |
Коэффициент Дайса (dice) |
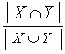 |
Коэффициент Джаккарда (jaccard) |
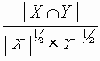 |
Косинусный коэффициент |
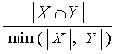 |
Коэффициент перекрытия |
/p> Приведенные коэффициенты, по сути, представляют собой нормализованные варианты простого коэффициента соответствия.
Скажем несколько слов о функциях, определяющих степень различия между документами. Причины использования в системах поиска информации функций, определяющих степень различия между документами, вместо степени соответствия являются чисто техническими. Добавим, что любая функция оценки степени различия между документами d может быть преобразована в функцию, определяющую степень соответствия s следующим образом:
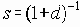
Если P – множество объектов, предназначенных для кластеризации, то функция D определения степени различия документов – это функция, ставящая в соответствие
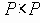
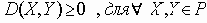
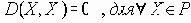
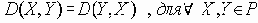
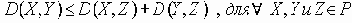
Четвертое свойство неявно отображает тот факт, что функция определения степени различия между документами является, в некоторой степени, функцией, определяющей “расстояние” между двумя объектами и, следовательно, логично предположить, что должна удовлетворять неравенству треугольника. Данное свойство выполняется практически для всех функций определения степени различия.
Пример функции, удовлетворяющей свойствам 1 – 4:
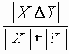
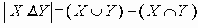 представляет собой разность множеств x и y. Она связана, например, с коэффициентами Дайса соотношением
представляет собой разность множеств x и y. Она связана, например, с коэффициентами Дайса соотношением 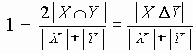
Наконец, представим функцию определения степени различия в альтернативной форме:
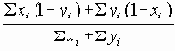
Используя векторное представление документов, для

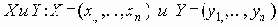 для косинусного коэффициента соответствия
для косинусного коэффициента соответствия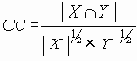
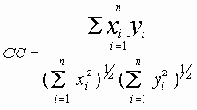 .
.Скажем несколько слов о вероятностном подходе для функций, определяющих степень соответствия. Степень соответствия между объектами определяется по тому, насколько их распределения вероятности отличаются от статистически независимого. Для определения степени соответствия используется ожидаемая взаимная мера информации. Для двух дискретных распределений вероятности

Если xi и xj - независимы, тогда
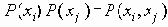
 (и
(и 
Функция
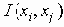
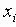 о документе
о документе 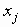
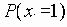
Та степень взаимосвязи, которая существует между индексными терминами i и j вычисляется затем функцией
Были предложены и другие функции, похожие на описанную выше функцию
Как и в случае автоматической классификации документов, использование вероятностных методов при формировании кластеров содержит в себе достаточно высокий потенциал и представляет крайне интересную область для исследований.
Итак, для формирования кластеров необходимо использовать некую функцию соответствия для определения степени связи между парами документов из коллекции.
Постулируем теперь основную идею, на которой, собственно говоря, и построена вся теория кластерного представления коллекции документов. Гипотеза, приведшая к появлению кластерных методов, называется Гипотезой Кластеров и может быть сформулирована следующим образом: “Связанные между собой документы имеют тенденцию быть релевантными одним и тем же запросам”.
Базисом, на котором построены все системы автоматического поиска информации, является то, что документы, релевантные запросу, отличаются от нерелевантных документов. Гипотеза кластеров указывает на целесообразность разделения документов на группы до обработки поисковых запросов. Естественно, она ничего не говорит о том, каким образом должно проводиться это разделение.
Проводился ряд исследований по поводу применения кластерных методов в поисковых системах. Некоторые отчеты приведены в работах Б. Литофски, Д. Крауча, Н. Привеса и Д. Смита, а также М. Фритше.
Кластерные методы, выбираемые для использования в экспериментальных поисковых системах должны удовлетворять некоторым определенным требованиям. Это:
методы, создающие кластеры, не должны существенно их изменять при добавлении новых объектов. То есть, должны быть устойчивы по отношению к объему коллекции.
методы должны быть устойчивы и в том отношении, что небольшие ошибки в описании объектов приводят к небольшим изменениям результата процесса кластеризации.
результат, производимый методами кластеризации, должен быть независимым от начального порядка объектов.
Основной вывод из вышесказанного состоит в том, что любой кластерный метод, не удовлетворяющий приведенным условиям, не может производить сколько-нибудь значащие экспериментальные результаты. Надо сказать что, к сожалению, далеко не все работающие кластерные методы удовлетворяют приведенным требованиям. В основном, это происходит из-за значительных различий между реализованными методами кластеризации от теоретически разработанных ад-хок алгоритмов.
Другим критерием выбора является эффективность процесса создания кластеров с точки зрения производительности и требований к объему необходимого дискового пространства.
Необходимость учета данного критерия находится, естественно, в сильной зависимости от конкретных условий и требований.
Возможно, использование процедур фильтрации базы данных таким образом, что из базы данных будет удаляться информация об индексных терминах, встречающихся в более чем, скажем 80% проиндексированных документов. Таким образом, список стоп-слов будет динамически изменяющимся. Как уже говорилось, использование списка стоп-слов может приводить к 30% уменьшению размеров индексных файлов. Для построения кластеров обычно используется два основных подхода:
кластеризация основывается на вычислении степени соответствия между подвергающимися кластеризации объектами.
кластерные методы применяются не к объектам непосредственно, а к их описаниям.
В первом случае кластеры можно представить с помощью графов, построенных с учетом значений функции соответствия для каждой пары документов.
Рассмотрим некоторое множество объектов, которые должны быть кластеризованы. Для каждой пары объектов из данного множества вычисляется значение функции соответствия, показывающее насколько эти объекты сходны.
Если полученное значение оказывается больше величины заранее определенного порогового значения, то объекты считаются связанными. Вычислив значения функции соответствия для каждой пары объектов, строится граф, по сути, представляющий собой кластер. То есть определение кластера строится в терминах графического представления.
Список литературы
| 1 | Salton, G., “Automatic Text Analysis”, Science, 168, 335-343 (1970) |
| 2 | Luhn, H. P. “The automatic creation of literature abstracts”, IBM Journal of Research and Development, 2, 159-165 (1958) |
| 3 | Gerard Salton, Chris Buckley and Edward A. Fox, “Automatic Query Formulations in Information Retrieval”, Cornell University, http://cs-tr.cs.cornell.edu/ |
| 4 | Tandem Computers Inc. “Three Query Parsers”, http://oss2.tandem.com /search97/doc/srchscr/tpappc1.htm |
| 5 | Object Design Inc., “Persistent Storage Engine PSE-Pro documentation”, http://www.odi.com/ |
| 6 | Roger Whitney, “CS 660: Combinatorial Algorithms. Splay Tree”, San Diego State University. http://saturn.sdsu.edu:8080/~whitney/ |
Список кодов и откликов на почтовые команды и сообщения
10.13 Список кодов и откликов на почтовые команды и сообщения
Семенов Ю.А. (ГНЦ ИТЭФ)
Список видов атак, зарегистрированных Network ICE
6.3.1 Список видов атак, зарегистрированных Network ICE
Семенов Ю.А. (ГНЦ ИТЭФ)
(смотри http://advice.networkice.com/advice/Intrusions/)Число официально зарегистрированных в мире сетевых инцидентов различного рода возрастает экспоненциально, о чем можно судить по рис. 1. (см. http://www.cert.org/stats/). Этот рост совпадает с ростом числа узлов в интернет, так что процент хулиганов и шизефреников величина похоже инвариантная. Атаки можно разделить на несколько классов:
Базирующиеся на дефектах протоколов, например, TCP.
Использующие дефекты операционной системы
Пытающиеся найти и воспользоваться дефектами программ-приложений, включая, например, CGI
Эксплуатирующие человеческие слабости (любопытство, алчность и пр., например, троянские кони)
Список номеров портов для известных троянских коней можно найти в http://www.simovits.com/nyheter9902.html
К первому типу относятся и атаки типа SMURF, ICMP flood и TCP SYN flood. ICMP flood не использует эффектов усиления на локальных широковещательных адресах, а работает c адресами типа 255.255.255.255. Здесь следует заметить, что для аналогичных целей хакеры могут использовать и протоколы TCP или UDP.
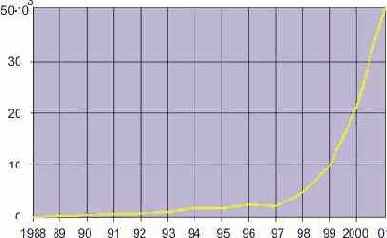
Рис. 1. Распределение числа официально зарегистрированных сетевых инцидентов по годам.
Ниже на рис. 2 показано распределение атак сети ИТЭФ по их разновидностям (Это и последующие два распределения построены студентом МФТИ А.Тарховым).
Рис. 2.
На рис.3 показана зависимость числа атак от времени суток, полученная за 19 дней.
Рис. 3.
На рис.4 показано распределение атак по доменным зонам. Из распределения видно, что этому занятию предаются чаще всего "жители" больших и комерческих сетей. Хотя нельзя исключить, что именно они являются чаще жертвами хакеров.
Рис. 4.
Land attack. Атакер пытается замедлить работу вашей машины, послав пакет с идентичными адресами получателя и отправителя. Для стека протоколов Интернет такая ситуация не нормальна. ЭВМ пытается выйти из бесконечной петли обращений к самой себе. Имеются пэтчи для большинства операционных систем.
| 2000002 | Unknown IP protocol. Традиционными транспортными протоколами являются UDP, TCP и ICMP, которые работают поверх протокола IP. Код протокола определяется полем тип протокола заголовка IP-дейтограммы. Существует большое число протоколов, которые идентифицируются с помощью номеров портов, например, HTTP, использующий в качестве транспорта TCP. Появление незнакомого протокола должно всегда настораживать, так как может нарушить нормальную работу программ. |
| 2000003 | Teardrop attack. Опасное перекрытие IP-фрагментов, сформированное программой teardrop. Ваша операционная система может стать нестабильной или разрушиться. Имеются пэтчи для большинства операционных систем. Адрес отправителя вероятнее всего не является истинным. Это означает, что отправитель использует фальшивый IP-адрес, и прикидывается кем-то еще. К сожалению, не существует простых способов определить, кто в действительности посылает кадры с искаженным адресом отправителя. |
| 2000004 | NewTear attack. Опасное перекрытие IP-фрагментов, сформированное программой newtear. Ваша операционная система может стать нестабильной или разрушиться. Имеются пэтчи для большинства операционных систем. Адрес отправителя вероятнее всего не является истинным. |
| 2000005 | SynDrop attack. Опасное перекрытие IP-фрагментов, сформированное программой syndrop. Ваша операционная система может стать нестабильной или разрушиться. Имеются пэтчи для большинства операционных систем. |
| 2000006 | TearDrop2 attack. Тоже что и, например, SynDrop, но для программы teardrop2 |
| 2000007 | Bonk DoS.. |
| 2000008 | Boink DoS. Тоже что и, например, SynDrop, но для программы boink |
| 2000009 | IP Fragment overlap. Смотри, например 2000005 |
| 2000010 | IP last fragment length changed.. |
| 2000011 | Too much IP fragmentation.. |
| 2000012 | Ping of death. Предпринимается попытка послать пакет, длина которого больше теоретического предела 65536 байтов. Системы до 1997 года были уязвимы для такой атаки. Это делалось, например с помощью ping -l 65550. |
| 2000013 |
| 2000014 | Zero length IP option. Некоторые системы при этом повисают |
| 2000015 | Nestea attack. Опасное перекрытие IP-фрагментов, сформированное программой nestea. Ваша операционная система может стать нестабильной или разрушиться. Имеются пэтчи для большинства операционных систем. Адрес отправителя вероятнее всего не является истинным. Это означает, что отправитель использует фальшивый IP-адрес, и прикидывается кем-то еще. К сожалению, не существует простых способов определить, кто в действительности посылает кадры с искаженным адресом отправителя. |
| 2000016 | Empty fragment. Когда пакеты слишком длины, они могут быть фрагментированы. Система контроля фиксирует фрагмент с нулевой длиной. Например, IP-заголовок имеет 20-байт, а данных вообще нет. Это может указывать, что: Атакер пытается обойти систему контроля вторжения. Некоторое сетевое оборудование (маршрутизаторы/переключатели) работают некорректно, генерируя такие фрагменты. Имеется ошибка в стеке TCP/IP машины, посылающей пакет. Атакер пытается предпринять DoS-атаку против вашей системы. Ядра Linux для версий между 2.1.89 и 2.2.3 были уязвимы для атак DoS с привлечением этой методики. Каждый такой фрагмент вызывает некоторую потерю памяти. Повторно посылая такие фрагменты, можно вызвать кризис из-за отсутствия свободной памяти. Ceotcndetn cкрипт с именем sesquipedalian, который был написан для использования этой ошибки. |
| 2000017 | IP unaligned timestamp. |
| 2000018 | Jolt2. |
| 2000019 | Jolt. |
| 2000020 | IP microfragment. Некоторые программы рушатся при получении временной метки, не выровненной по границе, кратной 32 бит. |
| 2000021 | SSping attack. Попытка атаки с помощью некорректного формата фрагментов. |
| 2000022 | Flushot attack. |
| 2000023 | IP source route end. |
| 2000024 | Oshare attack. |
| 2000025 | IP fragment data changed. |
| 2000101 |
Traceroute.
Кто-то пытается отследить путь от своей машины к вашей. Утилита
traceroute широко используется в Интернет для поиска пути между машинами. Программа traceroute выполняет эту работу и определяет виртуальный путь через Internet. Программа traceroute не является опасной. Не существует способа проникнуть в вашу ЭВМ, используя ее. Однако она помогает хакеру отследить ваши соединения через Интернет. Эта информация может использоваться для компрометации некоторых других участников ваших связей. Например, в прошлом этот вид информации использовался хакерами для того, чтобы отключить свою жертву от Интернет, заставив ближайший маршрутизатор повесить телефонную линию.
| 2000102 | Echo storm. Необычно большое число ping пакетов пришло за ограниченный период времени. Pings Довольно частой атакой домашних пользователей, играющих в сетевые игры или общающихся через сеть, является блокировка их канала с помощью большого числа пакетов Ping. Сейчас ведутся работы, для того чтобы позволить пользователю конфигурировать configuration file, чтобы было можно игнорировать такое вторжение. Смотри статью q000050. |
| 2000103 | Possible Smurf attack initiated.. |
| 2000104 | ICMP unreachable storm.. |
| 2000105 | ICMP subnet mask request. Поступил извне ICMP-запрос маски. В норме этого не должно быть. Атакер исследует структуру сети. |
| 2000106 | Ping sweep. |
| 2000107 | Suspicious Router advertisement. Подозрительное анонсирование новых маршрутов. Атакер возможно пытается перенаправить трафик на себя. Для этого может использоваться, в том числе, и ICMP-протокол. Соответствующие опции должны всегда вызывать подозрение. |
| 2000108 | Corrupt IP options. Опции IP на практике почти не используются. По этой причине в их обработке имеется достаточно много ошибок. Ими часто пытаются воспользоваться хакеры. Появление в пакете IP-опций должно вызывать подозрения. |
| 2000109 | Echo reply without request. Это может быть результатом взаимодействия хакера с засланным троянским конем. Может быть это и результатом дублирования вашего IP-адреса. В любом случае такие пакеты достойны внимания. |
| 2000110 | ICMP flood.. |
| 2000111 | Twinge attack. То же, что и ICMP-flood |
| 2000112 | Loki. Атака, использующая "заднюю дверь" приложения или ОС. Это может быть сделано для сокрытия трафика, например под видом ICMP-эхо или UDP-запросов к DNS и т.д. Воспользуйтесь командой netstat, чтобы выяснить, какие raw SOCKET открыты. |
| 2000201 | UDP port scan.. |
| 2000202 |
UDP port loopback. Пакет UDP путешествует между двумя эхо-портами. Такие пакеты могут делать это бесконечное число раз, используя всю имеющуюся полосу сети и производительность ЦПУ. Имеется несколько стандартных услуг такого рода, которые могут работать в системе. Среди них:
echo (порт 7)
дневная квота (порт 17)
chargen (порт 19)
Атакер может создать проблемы, фальсифицируя адрес отправителя и вынуждая две машины бесконечно обмениваться откликами друг с другом. Таким образом, может быть парализована вся сеть (ведь хакер может послать много таких пакетов). Например, хакер может имитировать посылку пакета от ЭВМ-A (порт chargen) к ЭВМ-B (порт echo). Эхо-служба ЭВМ-B пошлет отклик ЭВМ-A и т.д. 2000203
Snork attack. Регистрируются UDP-дейтограммы с портом назначения 135 (Microsoft Location Service), и отправитель с портом 7 (Echo), 19 (Chargen) или 135. Это попытка замкнуть две службы (если они разрешены/активированы) и заставить их бесконечно обмениваться пакетами друг с другом. Существует пэтч для блокировки таких атак (смотри сайт Microsoft). 2000204
Ascend Attack. Атака маршрутизаторов Ascend путем посылки UDP-пакета в порт 9. 2000205
Possible Fraggle attack initiated.Это не атака вашей ЭВМ. Это скорее попытка перегрузить систему третьей стороны. Это может быть также попытка выявить всех сетевых соседей. Internet поддерживает широковещательную адресацию. Это позволяет послать один "пакет" сотням ЭВМ "субсети". Эта техника позволяет ЭВМ оповестить окружение о своем присутствии. Атакер, используя технику, называемую "spoofing", атакует третью сторону. Атакер притворяется жертвой и посылает эхо-пакеты в субсеть. Каждая включенная ЭВМ откликнется "отправителю". Этот вид атаки был использован югославскими хакерами против сайтов в США и НАТО. Системы Firewall блокируют такие пакеты по умолчанию. Разные пакеты могут быть посланы ЭВМ, чтобы вызвать эхо-отклик. Сюда входят:
| quotd | Присылает отправителю "quote of the day" или "fortune cookie". |
| 2000207 | UDP short header. Заголовок UDP-дейтограммы содержит менее 8 байт (в надежде сломать программу-обработчик) |
| 2000208 | Saihyousen attack. Атака против ConSeal PC Firewall |
| 2000209 | W2K domain controller attack. Атакер посылает error-пакет вашей ЭВМ на UDP порт 464, а ваша система отвечает, возможно получение бесконечного цикла. |
| 2000210 | Echo_Denial_of_Service. Посылается UDP-пакет с номером порта отправителя и получателя равным 7. |
| 2000211 | Chargen_Denial_of_Service. Посылается UDP-пакет с номером порта отправителя и получателя равным 19. |
| 2000301 | TCP port scan. |
| 2000302 | TCP SYN flood. |
| 2000303 | WinNuke attack. |
| 2000304 | TCP sequence out-of-range. |
| 2000305 | TCP FIN scan. Разновидность TCP-сканирования. Однако хакер здесь пытается осуществить так называемое "FIN-сканирование". Он пытается закрыть несуществующее соединение сервера. Это ошибка, но системы иногда выдают разные результаты в зависимости от того, является ли данная услуга доступной. В результате атакер может получить доступ к системе. |
| 2000306 | TCP header fragmentation. |
| 2000307 | TCP short header. |
| 2000308 | TCP XMAS scan. Посылается TCP-сегмент с ISN=0 и битами FIN, URG и PUSH равными 1. |
| 2000309 | TCP null scan. Посылается TCP-сегмент с ISN=0 и битами флагов равными нулю. |
| 2000310 | TCP ACK ping. |
| 2000311 | TCP post connection SYN. |
| 2000312 | TCP FIN or RST seq out-of-range.. |
| 2000313 | TCP OS fingerprint. Посылается необычная комбинация TCP-флагов с тем, чтобы посмотреть реакцию. А по реакции определить вид ОС. |
| 2000314 | NMAP OS fingerprint. |
| 2000315 | Zero length TCP option. |
| 2000316 | TCP small segment size.. |
| 2000317 | TCP SYN with URG flag. |
| 2000318 | TCP Invalid Urgent offset. |
| 2000319 | RFProwl exploit. |
| 2000320 | TCP data changed. |
| 2000321 | Queso Scan. Попытка определения версии ОС или прикладной программы |
| 2000401 | DNS zone transfer. |
| 2000402 |
| 2000403 | DNS name overflow. |
| 2000404 | DNS non-Internet lookup. DNS-запрос послан не DNS- серверу или запрос имеет некорректный формат. |
| 2000405 | DNS malformed. |
| 2000406 | DNS Internet not 4 bytes. |
| 2000407 | DNS HINFO query. |
| 2000408 | DNS spoof successful. |
| 2000409 | DNS IQUERY. |
| 2000410 | DNS I-Query exploit. |
| 2000411 | DNS Chaos lookup. |
| 2000413 | NetBIOS names query. |
| 2000414 | DNS spoof attempt. |
| 2000415 | DNS NXT record overflow. |
| 2000416 | DNS null. DNS-запрос не содержит ни поля запросов, ни поля ответов ни поля дополнительной информации. |
| 2000417 | DNS BIND version request. Сервер BIND DNS содержит в своей базе данных запись CHAOS/TXT с именем "VERSION.BIND". Если кому-то нужна эта запись, присылается версия программы BIND soft. Такой запрос сам по себе не является атакой, но может являться разведывательным рейдом. Однако, если возвращается версия типа "4.9.6-REL" или "8.2.1", это указывает, что у вас установлена версия с хорошо известной дыркой, связанной с переполнением буфера. |
| 2000418 | AntiSniff DNS exploit. Программа AntiSniff может быть использована путем посылки специального DNS-кадра. В случае успеха, атакер может использовать программу, работающую в системе, где работает AntiSniff. AntiSniff представляет собой программу, которая разработана L0pht Heavy Industries в июле 1999. Атакер может использовать L0pht AntiSniff для получения информации о сети, которая может оказаться для него полезной при последующих атаках. Атакер может также использовать L0pht AntiSniff для определения положения компрометированных ЭВМ, переведенных в режим 6 (sniffing), которые могут им позднее использоваться. |
| 2000419 | Excessive DNS requests. |
| 2000420 |
DNS
с транспортным сжатием, что само по себе нормально (популярный алгоритм "gzip"). Подобно всем зонным обменам, это позволяет удаленному атакеру сформировать карту вашей сети. Такой обмен может быть частью атаки, если поступает извне.
2000421
DNS TSIG name overflow.
| 2000422 | DNS name overflow contains %. |
| 2000423 | DNS name overflow very long. |
| 2000501 | SMB malformed. Существует ошибка в старой версии SMB ( система Microsoft для совместного использования файлов и принтеров в сети). Эта ошибка может быть использована при авторизации, путем посылки специально сформированных пакетов. При реализации этого трюка машина крэшится. Данная атака может быть предпринята успешно для систем Windows NT 4.0 SP4 и Windows 95 (все версии). Заметим, что имеются пэтчи для всех систем. Для того чтобы дырка работала, "File and Print Sharing" должно быть разрешено. |
| 2000502 | SMB empty password. |
| 2000503 | SMB I/O using printer share. |
| 2000504 | SMB password overflow. |
| 2000505 | SMB file name overflow. |
| 2000506 | SMB Unicode file name overflow. |
| 2000507 | SMB unencrypted password. |
| 2000508 | RFParalyze exploit. |
| 2000600 | HTTP Attack. |
| 2000601 | HTTP URL overflow. |
| 2000602 | HTTP cgi starting with php. Специально сконструированный URL может позволить нежелательный доступ к CGI на сервере |
| 2000603 |
| 2000604 | HTTP asp with . appended. |
| 2000605 | HTTP cgi with ~ appended. |
| 2000606 | HTTP URL has many slashes. |
| 2000607 | HTTP URL with ::$DATA appended. Предпринята попытка доступа к файлу с завершающей последовательностью ::$DATA. Некоторые серверы в этом случае возвращают исходный файл asp, вместо того, чтобы его (asp) исполнить, таким образом атакер получает критическую информацию о сервере. Исходные тексты программы сервера часто содержат пароли, имена скрытых файлов и т.д. |
| 2000608 | HTTP GET data overflow. |
| 2000609 | Данные HTTP CGI содержат ../../../... Данные, переданные в URL, имеют подозрительный проход, содержащий ../../../..; Этот проход может быть использован для доступа к привилегированным файлам. Атакер пытается добраться по дереву каталогов до нужных ему файлов. Некоторые приложения Web используют проходы, содержащие ../../../.. . Вам следует рассмотреть URL и аргумент GET с целью проверки их корректности. Если проход в аргументе GET, указывает на попытку доступа к привилегированным данным, возможно ваш сервер скомпрометирован. |
| 2000610 | HTTP URL with blank appended. |
| 2000611 | HTTP GET data with repeated char. |
| 2000612 | IIS Double-Byte Code attempt. Специально сформированный URL, который может позволить нежелательный доступ . Выполняется попытка доступа к URL с завершающими %81 - %FE. Некоторые серверы возвращают в этом случае исходный файл, а не выполняют его, таким образом предоставляется атакеру критическая информация о сервере. Исходный текст программы сервера часто содержит скрытые пароли, имена файлов или данные об ошибках в программе. |
| 2000613 | HTTP HOST: repeated many times. |
| 2000614 | HTTP URL contains old DOS filename. |
| 2000615 | HTTP ACCEPT: field overflow. |
| 2000616 | HTTP URL contains /./. |
| 2000617 | HTTP URL contains /.... |
| 2000618 | HTTP GET data contains /.... |
| 2000619 | HTTP URL scan. |
| 2000620 | Whisker URL fingerprint. |
| 2000621 | Web site copying. |
| 2000622 | HTTP Authentication overflow. |
| 2000623 | HTTP POST data contains ../../../... Некоторые Web-серверы используют "скрытое" поле формы, содержащее имя файла, чтобы управлять работой программы сервера. Однако несмотря на то, что поле скрытое, оно может быть переписано. Когда форма поступает серверу, он может пренебречь проверкой корректности значения поля. Таким образом, посылая некорректную форму, хакер может получить доступ к файлам Web-сервера, содержащим критическую информацию. |
| 2000624 | HTTP POST data contains /.... |
| 2000625 | HTTP URL with repeated char. |
| 2000626 | HTTP POST data with repeated char. |
| 2000627 | HTTP URL bad hex code. |
| 2000628 | HTTP URL contains %20. |
| 2000629 | HTTP User-Agent overflow. |
| 2000630 | HTTP asp with \ appended. Произошла попытка доступа к файлу asp с завершающим символом \. В некоторых ситуациях, вместо исполнения программы asp будет возвращен исходный asp-файл. Это раскроет атакеру критическую информацию о сервере. Исходный текст программы сервера часто содержит пароли, скрытые имена файлов или ошибки, которые в такой ситуации относительно легко найти. Хакер может затем использовать эту скрытую (hidden) информацию для вскрытия сервера. |
| 2000631 | URL with repeated .. |
| 2000632 | HTTP JavaServer URL in Caps. |
| 2000633 | HTTP URL with +.htr appended. |
| 2000634 | HTTP path contains *.jhtml or *.jsp. |
| 2000635 | HTTP POST data contains script. |
| 2000636 | HTTP HOST: field overflow. |
| 2000638 | HTTP Cookie overflow. |
| 2000639 | HTTP UTF8 backtrack. |
| 2000640 | HTTP GET data contains script. |
| 2000641 | HTTP login name well known. |
| 2000642 | HTTP DAV PROPFIND overflow. |
| 2000643 | SubSeven CGI. |
| 2000644 | Repeated access to same Web service. |
| 2000645 | HTTP URL with double-encoded ../. |
| 2000646 | HTTP field with binary. |
| 2000647 | HTTP several fields with binary. |
| 2000648 | HTTP CONNECTION: field overflow. |
| 2000700 | POP3 Attack. |
| 2000701 | POP3 USER overflow. |
| 2000702 | POP3 password overflow. |
| 2000703 | POP3 MIME filename overflow. |
| 2000704 | POP3 command overflow. |
| 2000705 | POP3 AUTH overflow. |
| 2000706 | POP3 RETR overflow. |
| 2000707 | POP3 MIME filename repeated chars. |
| 2000708 | POP3 MIME filename repeated blanks. |
| 2000709 | POP3 Date overflow. |
| 2000710 | POP3 APOP name overflow. |
| 2000711 | POP3 false attachment. |
| 2000800 | IMAP4 Attack. |
| 2000801 | IMAP4 user name overflow. |
| 2000802 | IMAP4 password overflow. |
| 2000803 | IMAP4 authentication overflow. |
| 2000804 | IMAP4 command overflow. |
| 2000805 | IMAP4 Parm Overflow. |
| 2000901 | Telnet abuse. |
| 2000902 | Telnet login name overflow. |
2000903
Telnet password overflow. 2000904
Telnet terminal type overflow. 2000905
Telnet NTLM tickle. 2000906
Telnet Bad Environment. 2000907
Telnet Bad IFS. В UNIX, переменная "IFS" специфицирует символ, разделяющий команды. Если значение этой переменной изменено, тогда система детектирования вторжения не будет способна корректно интерпретировать команды. Более того, кто-либо может изменить эту переменную для того, чтобы модифицировать работу некоторых скриптов ядра. В частности плохой IFS станет разграничителем, используемым при разборе любых вводов, таких как имена файлов или DNS-имена. В этом случае, нужно установить IFS соответствующим символу '/' или '.'. Вообще, если вы хотите жить немного спокойнее, лучше заблокировать применение telnet, предложив пользователям перейти на SSH. 2000908
Telnet Environment Format String Attack. В районе августа 2000, выявлено большое число атак типа "format string". Эти атаки связаны с попыткой проникнуть в Telnet-машины путем посылки некорректных переменных окружения (environmental variables with format commands). 2000909
Telnet RESOLV_HOST_CONF. Переменная окружения RESOLV_HOST_CONF посылается с привлечением поля опций Telnet. Это поле не должно никогда изменяться таким способом. Это может означать попытку получения доступа к критическим файлам типа паролей и т.д. 2000910
Telnet bad TERM. Совершена попытка исказить "TERM" Telnet. Клиент Telnet может эмулировать многие виды терминалов текстового типа. Клиент передает эту информацию серверу с помощью переменной "TERM" или команды "term-type". Если обнаружено необычное значение этой переменной, возможно предпринята атака против вашей системы. 2000911
Telnet bad TERMCAP. 2000912
Telnet XDISPLOC. 2000913
Telnet AUTH USER overflow. 2000914
Telnet ENV overflow. 2000915
Telnet login name well known. 2000916
Telnet Backdoor. Атакер пытается воспользоваться известным именем/паролем "задней" двери telnet Trigger. Протокольный анализатор извлекает login name и пароль из входной строки Telnet и сравнивает их со списком известных параметров доступа для задней двери telnet. Некоторые из них приведены ниже:
| Пароль задней двери предоставляемый rootkit для Linux, разработанного в 1994 . | |
| lrkr0x | Пароль задней двери предоставляемый Rootkit I для Linux, разработанного в 1996 |
| satori | Rootkit IV для Linux. |
| rewt | Задняя дверь пользовательского аккоунта, которая предоставляет root-привилегии. |
| h0tb0x | Пароль задней двери для FreeBSD rootkit 1.2 (1/27/97). |
| 2001000 | SMTP Attack. |
| 2001001 | SMTP pipe in mail address. кто-то пытается компрометировать e-mail сервер путем посылки исполняемого кода shell внутри e-mail адреса. Это имеет целью компрометировать e-mail сервер, а также субсистему, обрабатывающую заголовки почтового сообщения. Ниже приводится пример SMTP-сессии с попыткой реализации такой атаки: HELO MAIL FROM: |/usr/ucb/tail|/usr/bin/sh RCPT TO: root DATA From: attacker@example.com To: victim@example.com Return-Receipt-To: |foobar Subject: Sample Exploit |
| 2001002 | SMTP DEBUG command. Кто-то сканирует вашу систему с целью выявления ее уязвимости. В 1988, червь Morris уложил Интернет Internet. Одним из путей распространения червя являлась программа sendmail. Sendmail поддерживала нестандартную команду "DEBUG", которая позволяет любому получить контроль над сервером. Червь Morris автоматизировал этот процесс для распространения через системы sendmail Internet. Сейчас маловероятно, что вы найдете такую старую почтовую систему. Следовательно, такая атака будет означать, что кто-то использует универсальный сканер уязвимости. Иногда система может выйти из синхронизма (сбой в ISN), что вызывает большие потери пакетов. В таких условиях по ошибке может быть запущена команда DEBUG. Например, если вы работаете с версией сервера для системы 486, который обрабатывает большое количество e-mail, такая десинхронизация может произойти. Уязвимой системой является Sendmail/5.5.8. |
| 2001003 | SMTP login name overflow. |
| 2001004 | SMTP EXPN command. |
| 2001005 | SMTP VRFY command. |
| 2001006 | SMTP WIZ command. |
| 2001007 | SMTP Too many recipients. |
| 2001008 | SMTP corrupted MAIL command. |
| 2001009 | SMTP email name overflow. |
| 2001010 | SMTP corrupted RCPT command. |
| 2001011 | SMTP relay attempt. Предпринята попытка использования SMTP в качестве ретранслятора сообщений - это может случиться, когда спамер некорректно использует SMTP-сервер. Это одна из наиболее успешных атак на Internet. Спамер регулярно ищет в Интернет ретранслирующие e-mail сервера. Примерно половина всех e-mail серверов поддерживают ретрансляцию в той или иной форме. |
| 2001012 | SMTP command overflow. |
| 2001013 | SMTP mail to decode alias. Обнаружено сообщение, адресованное пользователю с именем decode. Это может быть попыткой взломать почтовый сервер, или это может быть частью сканирования системы. Это достаточно старый трюк, выявленный в 1990. Системы UNIX позволяют посылать почту клиенту с именем decode, чтобы передать сообщение не клиенту, а программе uudecode. Атакер может попытаться таким образом переписать файлы таким образом, чтобы проникнуть в систему. Эта дырка связана с файлом /etc/aliases, содержащим строку типа: decode: |/usr/bin/uudecode Сейчас, такой тип вторжения может проявиться лишь в случае универсального сканирования с целью выявления уязвимости вашей системы. Например, атакер пытается передать по каналу uuencoded-файл после команды DATA. HELO MAIL FROM: test@example.com RCPT TO: decode DATA begin 644 /usr/bin/.rhosts $*R`K"@`` ` end . QUIT Этот пример пытается атаковать систему путем записи строки "+ +" в файл ".rhosts". Это будет указывать системе, что следует доверять любому, кто вошел в нее через программу типа 'rlogin'. Этот вид атаки существенен только для почтовых серверов, работающих под UNIX. Просмотрите файл "aliases", размещенный в /etc/aliases. Проверьте, нет ли строк типа: decode: |/usr/bin/uudecode uudecode: |/usr/bin/uuencode -d Удалите эти строки. Заметим, что новые системы не допускают такой возможности. |
| 2001014 | SMTP mail to uudecode alias. |
| 2001015 | SMTP too many errors. |
| 2001016 | SMTP MIME file name overflow. |
| 2001017 | SMTP uucp-style recipient. |
| 2001018 | SMTP encapsulated relay. |
| 2001019 | STMP encapsulated Exchange relay. Spam-атака. Выявляется инкапсулируемый почтовый адрес вида . Некоторые версии Microsoft Exchange не способны проверять эти типы адресов, таким образом, они могут использоваться спамерами для посылки неавторизованной почты. |
| 2001020 | SMTP mail to rpmmail alias. |
| 2001021 | SMTP MIME name overflow. |
| 2001022 | SMTP MIME filename repeated chars. |
| 2001023 | SMTP MIME filename repeated blanks. |
| 2001024 | SMTP ETRN overflow. |
| 2001025 | SMTP Date overflow. |
| 2001026 | SMTP Recipient with trailing dot. |
| 2001027 | SMTP FROM: field overflow. |
| 2001028 | SMTP MIME null charset. Обнаружено незнакомое почтовое сообщение, вероятно сконструированное, чтобы разрушить почтовый сервер. В заголовки "Reply-To:" сообщения встраиваются исполняемые Shell и PERL коды. Когда система откликается, эти коду будут исполнены. Например, старые версии list-сервера MAJORDOMO исполняют любой PERL-скрипт, который вставлен в это поле. |
| 2001030 | SMTP ENVID overflow. |
| 2001031 | SMTP false attachment. |
| 2001032 | SMTP Expn Overflow. |
| 2001033 | SMTP Vrfy Overflow. |
| 2001034 | SMTP Listserv Overflow. |
| 2001036 | SMTP Auth Overflow. |
| 2001040 | SMTP Xchg Auth. |
| 2001041 | SMTP Turn. |
| 2001101 | Finger. |
| 2001102 | Finger forwarding. Предпринята попытка использования программы finger для переадресации запроса другой системе. Это часто делается атакерами, чтобы замаскировать свою идентификацию. Finger поддерживает рекурсивные запросы. Запрос типа "rob@foo@bar" просит "bar" сообщить информацию о "rob@foo", заставляя "bar" послать запрос "foo". Эта техника может использоваться для сокрытия истинного источника запроса. Finger является опасным источником информации и по этой причине должен быть заблокирован в /etc/inetd.conf. |
| 2001103 | Finger forwarding overflow. |
| 2001104 | Finger command. |
| 2001105 | Finger list. |
| 2001106 | Finger filename. |
| 2001107 | Finger overflow. |
| 2001108 |
Finger search. Демон "cfinger" позволяет осуществлять поиск любых или всех имен пользователей, при вводе "search.*". Эта возможность поиска предоставляет атакеру легкий способ пронумеровать всех пользователей системы. Широкополосные сканеры (напр. CyberCop Scanner, ISS Scanner) осуществляют сканирование этого типа. Сигнатурой для этого вида атаки является наличие строки "search.*" в качестве имени пользователя.
| 2001109 | Finger Backdoor. Кто-то пытается повторно войти в систему через известную заднюю дверь в finger. Раз система была компрометирована, атакеры могу оставит для себя открытую "потайную" дверь, через которую они смогут войти, когда захотят. Например, одна потайная дверь допускает посылку finger команды "cmd_rootsh", которая открывает shell с привилегиями суперпользователя. Заметим, что если потайная дверь действительно имеется, ваша система уже была скомпрометирована. В настоящее время, все известные потайные двери finger существуют только в системах UNIX. Если вы столкнулись с такой проблемой то, во-первых, просмотрите информацию откликов, которая может быть в наличии. Если вы обнаружили какие-то уведомления об ошибках, то вероятно попытка вторжения не была успешной (но не обольщайтесь). Во-вторых, если вы озабочены возможностью наличия потайной двери в системе, исполните команду finger сами. Чтобы устранить уязвимость данного вида, следует, во-первых, рассмотреть возможность удаления услуги finger вообще. Это опасная услуга, которая предоставляет полезную информацию атакерам. Во-вторых, если вы чувствуете, что система компрометирована, следует заново инсталлировать операционную систему. Поищите потайную дверь в списке пользователей. Трудно представить, что какой-то пользователь в вашей системе имеет имя "cmd_shell". Многие широкодиапазонные сканеры ищут такие потайные двери. |
| 2001110 | Finger Scan. Производится сканирование известных из Finger имен пользователей с целью получения персональной информации. Например, если вы направляете запрос finger "jsmith", вы вероятно ищите данные о "Jane Smith". В безопасных сетях, любое использование finger подозрительно, так как оно может раскрыть важную информацию о пользователе. Однако, существует в системе большое число не пользовательских аккоунтов, таких как "adm", "bin" или "demo". Попытки Finger обратиться к этим аккоунтам указывают, что кто-то использует протокол finger для того, чтобы сканировать сервер с целью получения более существенной информации. В настоящее время, finger работает на UNIX-системах. Чтобы забыть об этих проблемах, заблокируйте finger. Если он работает, атакеры могут получить нужные им данные, а за помощь им вам не платят. |
| 2001111 | Finger Enumeration. Зафиксированы подозрительные команды finger. Finger используется для поиска информации о пользователях. Некоторые системы допускают множественный поиск пользователей. Здесь возможны некорректности. Например, запрос finger о пользователе с именем "e" выдаст список всех пользователей в системе, содержащими "e" в своем имени. Некоторые системы finger допускают также спецификацию множественных имен. Это означает, что finger для "a b c d e f...x y z" перечисляет всех пользователей в системе. В настоящее время, finger работает в основном на системах UNIX. Чтобы забыть об этих проблемах, заблокируйте finger. Если он работает, атакеры могут получить нужные им данные. |
| 2001201 | TFTP file not found. |
| 2001202 | TFTP file name overflow. |
| 2001203 | TFTP Traversal. |
| 2001204 | TFTP Exe Transfer. |
| 2001205 | TFTP Web Transfer. |
| 2001206 | TFTP Echo Bounce. |
| 2001301 | FTP invalid PORT command. Если вы такое обнаружили, это означает, что совершается попытка вторжения в вашу FTP-систему. Немногие ЭВМ допускают такую атаку. Команда "PORT" является частью протокола FTP но обычно незаметна для пользователя, хотя он часто и получает статусные сообщения "PORT command successful". Это уведомляет противоположную сторону о том, кода следует направлять данные. Эта команда форматируется в виде списка из 6 чисел, разделенных запятыми. Например: PORT 192,0,2,63,4,01 Данная команда сообщает противоположной стороне, что данные следует отправлять по адресу 192.0.2.63, порт 1025. Если эта команда искажена, то вероятно атакер пытается компрометировать FTP-сервис. Однако, так как большинство FTP-сервисов противостоит этому типу атаки, шансов у хакера в этом варианте немного. |
| 2001302 | FTP PORT bounce to other system. |
| 2001303 | FTP PORT restricted. |
| 2001304 | FTP CWD ~root command. |
| 2001305 |
FTP SITE EXEC command. Старые версии FTP-серверов поддерживают эту команду, которая разрешает нежелательный доступ к серверу. В версиях wu-ftpd ниже 2.2, имеется возможность исполнения программы (об этом хакер может только мечтать) . Ниже показана сессия, где "robert" имеет легальный аккоунт в системе и пытается реализовать режим строчно-командного доступа к shell.
220 example.com FTP server (Version wu-2.1(1) ready.
Name (example.com:robert): robert
331 Password required for robert.
Password: foobar
230 User robert logged in.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp> quote "site exec cp /bin/sh /tmp/.runme"
200-cp /bin/sh /tmp/runme
ftp> quote "site exec chmod 6755 /tmp/.runme"
200-chmod 6755 /tmp/runme
ftp> quit
221 Goodbye.
Теперь пользователь авторизован и может работать с shell на уровне привилегий root в каталоге /tmp.
| 2001306 | FTP USER name overflow. |
| 2001307 | FTP password overflow. |
| 2001308 | FTP CWD directory overflow. |
| 2001309 | FTP file name overflow. |
| 2001310 | FTP command line overflow. |
| 2001311 | FTP pipe in filename. Совершена попытка исполнить программу на FTP-сервере. Допускающее это ошибка имеется во многих FTP-демонах около 1997, таких что, если перед именем файла присутствует символ PIPE (|), сервер пытается исполнить программу имя которой следует за ним. Так как FTP-сервер обычно работает с привилегией root, может произойти его компрометация. Проверьте, что у вас работает новейшая версия сервера. |
| 2001312 | FTP MKD directory overflow. |
| 2001313 | ProFTPD snprintf exploit. |
| 2001314 | FTP SITE PSWD exploit. |
| 2001315 | FTP compress exec exploit. |
| 2001316 | FTP file exec exploit. |
| 2001317 | FTP command too long. |
| 2001318 | FTP data too long. |
| 2001319 | FTP NLST directory overflow. |
| 2001320 | FTP SITE ZIPCHK metacharacters. |
| 2001321 | FTP SITE ZIPCHK buffer overflow. |
| 2001322 | FTP SITE EXEC exploit. |
| 2001323 |
FTP PrivilegedBounce. Кто-то пытается нарушить безопасность FTP-сервиса, чтобы сканировать другие ЭВМ. Если атака FTP используется при одновременной спецификации привилегированного порта, можете не сомневаться - это сетевая атака. Возможно, что FTP-переадресация на непривилегированный порт является результатом FTP-прокси. По этой причине комбинированная атака рассматривается как отдельная сигнатура. Это позволяет атакеру маскировать свою сетевую идентичность. Возможно также, что атакер, используя эту технику, может обойти некоторые плохо конфигурированные фильтры пакетов или firewalls. Например, если ваш mail-сервер допускает соединения посредством telnet с вашим внутренним FTP-сервером, а с внешними ЭВМ из Internet не допускает, атакер сможет соединиться с вашим telnet-портом на вашем SMTP методом переадресации через ваш FTP-сервер.
К системам допускающим такую атаку относятся SunOS 4.1.x, Solaris 5.x, большинство систем, работающих со старыми FTP-серверами. Чтобы покончить с такого рода угрозой раз и навсегда. Просмотрите, какие ЭВМ и порты вовлечены в этот процесс. Если это ваши ЭВМ, проконтролируйте, как это реализовано. Если же это не ваша ЭВМ, убедитесь, что администратор этой машины, видит, что в соединении участвует ваш FTP-сервер, и если атака осуществлена, ваша машина будет выглядеть, как источник этой атаки. Вы можете провзаимодействовать с этим администратором или по крайней мере записать logs оригинального источника атаки. После этих дипломатических шагов вам следует установить новую версию FTP-сервера, где данная ошибка исправлена, например, wu-ftpd 2.4.2 beta 15 или более новую.
| 2001324 | FTP Site Exec DotDot. Попытка неавторизованного доступа. Некоторые версии wu-ftpd позволяют использовать команду site exec для удаленных машин. Путем предоставления прохода с определенными параметрами, удаленный пользователь может исполнить произвольные команды на FTP-сервере. Эта атака позволяет атакующему выполнять команды на атакуемой машине. Это может привести к получению им доступа root-уровня. Такой дефект имеют системы wu-ftpd 2.4.1 и ранее. Чтобы защитить себя от таких атак, просмотрите команды, которые атакер использовал. Если они представляют угрозу для атакуемой ЭВМ, можете считать машину скомпрометированной. Обновите программное обеспечение FTP-сервера или замените его вообще. |
| 2001325 | FTP Site Exec Format Attack. |
| 2001326 | FTP Site Exec Tar. |
| 2001327 | FTP Site Chown Overflow. |
| 2001328 | FTP AIX Overflow. |
| 2001329 | FTP HELP Overflow. |
| 2001330 | FTP Glob Overflow. |
| 2001331 | FTP Pasv DoS. |
| 2001332 | FTP Mget DotDot. |
| 2001401 | RWHO host name overflow. |
| 2001501 |
Back Orifice scan. Кто-то сканирует вашу систему на предмет троянского коня "Back Orifice". Back Orifice сканы наиболее частые атаки, встречающиеся в Internet. Ваша машина просканирована, но еще не выбрана для атаки. Это означает, что хакер сканирует тысячи ЭВМ в Interent, надеясь найти одну, которая была скомпрометирована посредством Back Orifice. Хакер не обязательно охотится именно на вашу ЭВМ. Большинство взломов происходит путем установки хакером инфицированных программ или документов в Internet в надежде, что какой-то неосторожный клиент скопирует и запустит их у себя. Хакер сканирует затем Internet и ищет эти скомпрометированные ЭВМ. Но даже, если ваша машина была скомпрометирована программой Back Orifice, ваша субсистема firewall может заблокировать доступ к ней.
| 2001502 | Netbus response. |
| 2001503 | Quake backdoor. |
| 2001504 | HP Remote watch. |
| 2001505 | Back Orifice response. |
| 2001506 | Back Orifice ping. |
| 2001507 | PCAnywhere ping. Кто- то пингует систему для того чтобы проверить, работает ли PCAnywhere. Это может быть атака, но может быть и случайный инцидент. PCAnywhere является продуктом Symantec, который позволяет осуществить удаленное управление ЭВМ. Она является очень популярной в Internet для этих легальных целей, позволяя администраторам удаленно контролировать серверы. Хакеры часто сканируют Internet с целью поиска машин, поддерживающих этот продукт. Многие пользователи используют пустые пароли или пароли, которые легко угадать (например слово "password"). Это предоставит легкий доступ хакеру. Если хакер захватил контроль над машиной, он не только могут украсть информацию, но и использовать эту машину для атаки других ЭВМ в Интернет. Случайные сканирования клиентами PCAnywhere обычно видны со стороны соседей. Программа инсталлирует иконку, названную "NETWORK", которая сканирует локальную область. Хотя эти сканы не содержат враждебных намерений, они могут создавать дискомфорт. Чтобы проверить, что на самом деле имеет место, следует рассмотреть IP-адрес атакер. Если IP-адрес относится к локальному сегменту (т.e. подобен вашему IP-адресу), тогда ничего страшного. В противном случае (адрес внешний) - имеет место атака вашей системы. PCanywhere сканирует то, что называется диапазоном "класса C", например, 192.0.2.0 - 192.0.2.255. Если вы не работаете с PCAnywhere, тогда проблем нет. В противном случае, читайте советы по обеспечению безопасности сервера PCAnywhere. |
| 2001508 | ISS Ping Scan. |
| 2001509 | ISS UDP scan. |
| 2001510 | Cybercop FTP scan. |
| 2001511 | WhatsUp scan. |
| 2001512 | Back Orifice 2000 ping. |
| 2001513 | Back Orifice 2000 auth. |
| 2001514 | Back Orifice 2000 command. |
| 2001515 | Back Orifice 2000 response. |
| 2001517 | Scan by sscan program. |
| 2001518 |
phAse Zero trojan horse activity. Возможная попытка вторжения. Программа phAse Zero обладает всеми стандартными особенностями троянского коня, включая возможность выгружать и загружать файлы в ЭВМ с помощью FTP, исполнять программы, стирать и копировать файлы, а также читать и записывать в конфигурационную базу данных (registry). Здесь имеется функция 'Trash Server', которая удалит все файлы из каталога вашей системы Windows. phAse Zero работает под Windows 95, 98 и Windows NT.
| 2001519 | SubSeven trojan horse activity. |
| 2001520 | GateCrasher trojan horse activity. |
| 2001521 | GirlFriend trojan horse activity. |
| 2001522 | EvilFTP trojan horse activity. Неавторизованная попытка вторжения. Троянский конь EvilFTP является одним из многих программ подобного рода, который может использовать атакер для доступа к вашей компьютерной системы без вашего ведома. Когда программа, содержащая троянского коня работает, EvilFTP инсталлирует FTP-сервер на порт12346 с login "yo" паролем "connect." Этот троянский конь при инсталляции в удаленной системе позволяет атакеру выгружать и загружать файлы для системы, где он инсталлирован. |
| 2001523 | NetSphere trojan horse activity. |
| 2001524 | Trinoo Master activity. |
| 2001525 | Trinoo Daemon activity. |
| 2001526 | NMAP ping. Для проверки вашей системы на уязвимость используется программа NMAP. NMAP -очень популярная программа, используемая хакерами для сканирования Internet. Она работает под Unix, и имеет много конфигурационных опций и использует несколько трюков, чтобы избежать детектирования системами, детектирующими вторжение. NMAP не позволяет хакеру вторгнуться в систему, но допускает получение им полезной информации о конфигурации системы и доступных услугах. Программа часто используется как прелюдия более серьезной атаки. |
| 2001527 | NetSphere Client. Активность клиента NetSphere. Это указывает, имеется пользователь в вашей сети, который применил NetSphere для хакерства. Это не должно быть заметно клиентам, если только они сами не работают с NetSpheres. |
| 2001528 | Mstream agent activity. |
| 2001529 | Mstream handler activity. |
| 2001530 | SubSeven password-protected activity. |
| 2001531 | Qaz trojan horse activity. |
| 2001532 | LeakTest trojan horse activity. |
| 2001533 | Hack-a-tack trojan horse activity. |
| 2001534 | Hack-a-tack trojan horse ping. |
| 2001535 | Bionet trojan horse activity. |
| 2001536 | Y3K trojan horse ping. |
| 2001537 | Y3K trojan horse activity. |
| 2001601 | FTP login failed. |
| 2001602 | HTTP login failed. |
| 2001603 |
IMAP4 login failed.
| 2001604 | POP3 login failed. |
| 2001605 | rlogin login failed. |
| 2001606 | SMB login failed. |
| 2001607 | SQL login failed. |
| 2001608 | Telnet login failed. |
| 2001609 | SMTP login failed. |
| 2001610 | PCAnywhere login failed. |
| 2001611 | SOCKS login failed. |
| 2001612 | VNC login failed. |
| 2001701 | rpc.automountd overflow. |
| 2001702 | rpc.statd overflow. |
| 2001703 | rpc.tooltalkd overflow. |
| 2001704 | rpc.admind auth. |
| 2001705 | rpc.portmap dump. |
| 2001706 | rpc.mountd overflow. |
| 2001707 | RPC nfs/lockd attack. |
| 2001708 | rpc.portmap.set. |
| 2001709 | rpc.portmap.unset. |
| 2001710 | rpc.pcnfs backdoor. |
| 2001711 | rpc.statd dotdot file create. |
| 2001712 | rpc.ypupdated command. |
| 2001713 | rpc.nfs uid is zero. |
| 2001714 | rpc.nfs mknod. |
| 2001715 | rpc.nisd long name. |
| 2001716 | rpc.statd with automount. |
| 2001717 | rpc.cmsd overflow. |
| 2001718 | rpc.amd overflow. |
| 2001719 | RPC bad credentials. |
| 2001720 | RPC suspicious credentials. |
| 2001721 | RPC getport probe. |
| 2001722 | rpc.sadmind overflow. |
| 2001723 | rpc.SGI FAM access. |
| 2001724 | RPC CALLIT unknown. |
| 2001725 | RPC CALLIT attack. |
| 2001726 | RPC CALLIT mount. |
| 2001727 | rpc.bootparam whoami mismatch. |
| 2001728 | RPC prog grind. |
| 2001729 | RPC high-port portmap. |
| 2001730 | RPC ypbind directory climb. |
| 2001731 | RPC showmount exports. |
| 2001732 | RPC selection_svc hold file. |
| 2001733 | RPC suspicious lookup. |
| 2001734 | RPC SNMPXDMID overflow. |
| 2001735 | RPC CALLIT ping. |
| 2001736 | RPC yppasswdd overflow. |
| 2001737 | rpc.statd Format Attack. |
| 2001738 | RPC Sadmind Ping. |
| 2001739 | RPC Amd Version. |
| 2001801 | IRC buffer overflow. |
| 2001802 | SubSeven IRC notification. |
| 2001803 | IRC Trinity agent. |
| 2001804 | Y3K IRC notification. |
| 2001901 | IDENT invalid response. Чужой сервер пытается использовать identd клиента. Многие программы осуществляют реверсивные lookups IDENT. Эти программы уязвимы к атакам, когда сервер присылает некорректный отклик. |
| 2001902 | IDENT scan. |
| 2001903 | IDENT suspicious ID. |
| 2001904 | IDENT version. |
| 2001905 | IDENT newline. |
| 2002001 | SNMP Corrupt. |
| 2002002 |
SNMP Crack. Обнаружено большое число строк community (паролей), которые индицируют попытку вскрыть систему контроля паролей. Большое число сообщений SNMP с различными строками community за ограниченный период времени должны рассматриваться как подозрительная активность, и как попытка подобрать корректное значение поля community. SNMP(Simple Network Management Protocol) используется для мониторирования параметров оборудования. Однако, это крайне небезопасный протокол, и ничто не препятствует простому подбору пароля путем простого перебора. Следует конфигурировать систему так, чтобы она была доступна со стороны ограниченного числа машин. Рекомендуется также использовать максимально возможно длинные строки community, что позволит зарегистрировать подбор до того, как он успешно завершится.
| 2002003 | SNMP backdoor. Атакер пытается использовать известную "потайную дверь" сетевого оборудования. Однако, многие приборы имеют пароли для "потайной двери", которые могут использоваться для обхода нормальных проверок, предусмотренных нормальной системой обеспечения безопасности. Скрытые и недокументированные строки community имеются во многих субагентах SNMP, которые могут позволить атакерам поменять важные системные параметры. Удаленные атакеры могут убить любой процесс, модифицировать маршруты, или заблокировать сетевые интерфейсы. Важно то, что атакер может выполнить апосредовано произвольные команды, требующие привилегий суперюзера. |
| 2002004 | SNMP discovery broadcast. Атакер посылает команду SNMP GET по широковещательному адресу. Это может быть попыткой определить, какие системы поддерживают различные возможности SNMP. Это часто дает полную информацию об управляемом приборе, и иногда может предоставить полный контроль над прибором. В то же время, SNMP крайне небезопасный протокол, с легко угадываемым паролем. В результате, он является популярным протоколом для хакеров. |
| 2002005 | SNMP sysName overflow. |
| 2002006 | SNMP WINS deletion. Совершена попытка стереть записи WINS через интерфейс SNMP сервера. Это может быть попытка реализовать Denial-of-Service (DoS) или просканировать систему безопасности. Клиенты Windows контактируют с системой WINS для того, чтобы найти серверы. Многие системы уязвимы для атак при помощи SNMP-команд, посланных серверу для того, чтобы стереть записи. Это не взламывает сервер, но после стирания записи в базе данных, клиенты и серверые смогут более найти друг друга. Однако этот отказ обслуживания (DoS) может предварять другие атаки. Это может быть частью широко диапазонного сканирования с целью поиска слабых точек в сети. Эта атака может быть против систем, где нет работающих SNMP или WINS. |
| 2002007 | SNMP SET sysContact. Совершена попытка удаленно установить поле sysContact через SNMP. Это вероятно сканирование уязвимых мест вашей системы. Группа SNMP "system" используется всеми MIB. Она часто сканируется хакерами при предварительной разведке. Одним из способов сканирования является выполнение команд SET для поля "sysContact" для того, чтобы просмотреть, реагирует ли какая-либо система. Такие SET часто используют для взлома хорошо известные пароли/communities. |
| 2002008 | SNMP lanmanger enumeration. |
| 2002009 | SNMP TFTP retrieval. |
| 2002010 | SNMP hangup. Совершена попытка подвесить пользователя коммутируемой телефонной сети с помощью протокола SNMP. Некоторые типы сетевого оборудования (Ascend, Livingston, Cisco, etc.) могут допускать такое подвешивание пользователей. Это может быть обычным отказом обслуживания (DoS) в chat-комнатах и при играх в реальном времени. Один участник в chat-комнате может не любить другого. Он может взять IP-адрес жертвы, затем осуществлять поиск, пока не найдут прибор доступа, через который подключен клиент телефонной сети. |
| 2002011 | SNMP disable authen-traps. Совершена попытка заблокировать трэпы неудач SNMP-аутентификации, возможно с целью замаскировать активность хакера. Если строка community некорректна, прибор может послать на консоль управления трэп "authentication-failure". Эти строки community не управляют доступом всего SNMP-агента MIB. Вместо этого, они управляют "видами" MIB: различные строки community могут позволять управление различными частями MIB. Предположим сценарий, где атакер желает взломать строку community, отвечающую за секцию MIB поставщика. Это включает множество (возможно миллионы) попыток выяснить правильный пароль. Следовательно, чтобы избежать оповещений об атаке, нападающий должен заблокировать трэпы, которые могут поступить на консоль. |
| 2002012 |
SNMP snmpdx attack. Совершена попытка заменить Sun Solstice Extension Agent, используя SNMP. Это может быть попытка вскрыть систему. Sun Solaris 2.6 поставляется со встроенной SNMP. В этот пакет входит возможность "extension agents": агенты, которые подключены к первичному SNMP-агенту для управления другими частями системы. Следует просмотреть log-book b jndtnbnm на вопросы:
Имеется ли платформа управления, которая может выполнять подобные операции? Является ли строка "community" одной из "печально" известных для Solaris (в особенности "all private")? Параметр "val" содержит имя программы, которая будет исполнена. Выглядит ли это как демон или выглядит ли она как программа, предназначенная для компрометации системы? Типичными вариантами компрометации является создание xterm или скрипта, который изменяет /etc/passwd.
| 2002013 | SNMP 3Com communities. Совершена попытка прочесть строку community/пароля устройства 3Com с помощью SNMP. Это может быть попыткой проникновения в систему. Многие старые версии оборудования 3Com содержат дефекты, которые делают строку community/пароля общедоступной. Атакер, чтобы получить пароли, может прочесть специфические таблицы, используя строку community+"public". После этого атакер получает полный контроль над прибором. Такого рода атаки возможны для хабов 3Com SuperStack II версий ранее 2.12, карт HiPer Arc, с кодами выпуска ранее 4.1.59. |
| 2002014 | SNMP dialup username. |
| 2002015 | SNMP dialup phone number. |
| 2002016 | SNMP scanner. |
| 2002017 | SNMP passwd. |
| 2002018 | SNMP community long. |
| 2002019 | SNMP echo bounce. Обнаружен пакет UDP путешествующий между портами SNMP и ECHO. Техника, которая иногда используется, заключается в том, что пакеты SNMP посылаются службе ECHO промежуточной системы. IP-адрес отправителя фальсифицируется так, чтобы ECHO посылалось службе SNMP атакуемой системы. Атакуемый объект доверяет промежуточной системе и поэтому принимает пакет. |
| 2002020 | SNMP HP Route Metachar. |
| 2002101 | rlogin -froot backdoor. |
| 2002102 | rlogin login name overflow. |
| 2002103 | rlogin password overflow. |
| 2002104 | rlogin TERM overflow. |
| 2002105 | Rlogin login name well known. |
| 2002201 | Melissa virus. |
| 2002202 | Papa virus. |
| 2002203 | PICTURE.EXE virus. |
| 2002204 | W97M.Marker.a virus. |
| 2002205 | ExploreZip worm. |
| 2002206 | Keystrokes monitored. |
| 2002207 | PrettyPark worm. |
| 2002208 |
ILOVEYOU worm.
| 2002209 | Worm extensions. |
| 2002210 | Worm address. |
| 2002301 | Duplicate IP address. |
| 2002401 | NNTP name overflow. |
| 2002402 | NNTP pipe seen. |
| 2002403 | NNTP Message-ID too long. |
| 2002500 | Suspicious URL. |
| 2002501 | bat URL type. |
| 2002502 | cmd URL type. |
| 2002503 | CGI aglimpse. Совершена попытка исполнить программу aglimpse, которая имеет известные уязвимости. Атакер сканирует web-сервер системы и ищет потенциальные уязвимости в секции web-сервера "dynamic content generation" (динамическая генерация содержимого). Эта утилита web-сервера исполняет отдельную программу для генерации web-страниц, когда пользователи осуществляют доступ к сайту. Существует сотни таких программ, которые содержат ошибки в сфере безопасности. В данном примере, хакер просматривает web-сервер и ищет одну из таких программ. Большая часть того, что вы читали в новостях о хакерских "штучках", является описанием слабостей таких программ и повреждений web-сайта. Особенно много информации можно найти о слабостях cgi-bin. Если скрипт виден внешнему миру, вам следует удалить его из данного каталога. Следует также удалить все динамическое содержимое, которое не является абсолютно необходимым для работы web-сайта. Выполните двойную проверку скриптов, которые вы действительно используете, на предмет наличия в них брешей уязвимости. Данная атака является стандартной, использующей метасимвольный CGI на PER. Программа PERL передает "поврежденный" ввод пользователя непосредственно в интерпретатору shell. |
| 2002504 | CGI AnyForm2. Совершена попытка исполнить программу anyform2, которая имеет известную уязвимость. Программа AnyForm cgi-bin содержит уязвимость, которая позволяет удаленному атакеру исполнять программы Web-сервера. Атакер сканирует web-сервер системы и ищет потенциальные уязвимости в секции web-сервера "dynamic content generation" (динамическая генерация содержимого). Эта утилита web-сервера исполняет отдельную программу для генерации web-страниц, когда пользователи осуществляют доступ к сайту. Существует сотни таких программ, которые содержат ошибки в сфере безопасности. В данном примере, хакер просматривает web-сервер и ищет одну из таких программ. |
| 2002505 | CGI bash. Совершена попытка исполнить скрипт bash, который в случае успеха, позволит хакеру получить доступ к серверу. Это программа shell, которая может исполнять произвольные операции на сервере. Если она была случайно помещена в удаленно доступный каталог, и, если вы обнаружили, что какие-то параметры системы стали доступны хакеру, считайте свою систему скомпрометированной. Вы должны немедленно удалить эту программу из данного каталога, проверить систему на наличие троянских коней и проконтролировать, не изменялась ли ее конфигурация. |
| 2002506 | CGI campas. Совершена попытка исполнить campas, которая имеет известную уязвимость. Это известный скрипт, поставляемый с оригинальными web-серверами NCSA. Он оказался весьма популярным среди хакеров (вместе с phf), но в настоящее время его важность незначительна. Эта точка уязвимости позволяет удаленному атакеру исполнять команды на ЭВМ Web-сервера, как если бы он работал на самой машине, где размещен httpd. Эта уязвимость разрешает доступ хакеру к файлам web-сервера. При определенных конфигурациях web-сервера возможно получение хакером административного доступа к ЭВМ. |
| 2002507 | CGI convert.bas. |
| 2002508 | CGI csh. |
| 2002509 | CGI faxsurvey. |
| 2002510 | CGI finger. Произведена попытка исполнить программу finger, который может позволить хакеру неавторизованный доступ к серверу. Атакер сканирует web-сервер системы и ищет потенциальные точки уязвимости в секции "dynamic content generation". Эта утилита web-сервера исполняет отдельную программу для генерации web-страниц, когда пользователь получает доступ к сайту. Существуют сотни таких программ, которые имею окна уязвимости. в данном примере, хакер просматривает web-сервер и ищет одну из таких уязвимых программ. Дополнительную информацию можно найти в cgi-bin exploits. Если этот скрипт виден внешнему миру, его следует удалить из данного каталога. Следует удалить также все динамические данные, которые совершенно необходимы для работы web-сайта. |
| 2002511 | CGI formmail. |
| 2002512 | CGI formmail.pl. |
| 2002513 | CGI glimpse. Попытка исполнения программы glimpse, которая известна своими уязвимостями. Эти уязвимости позволяют атакеру исполнять команды на ЭВМ Web-сервера во время работы процесса пользователя в httpd. В зависимости от конфигурации web-сервер, это может позволить атакеру получит root или административный доступ к ЭВМ. В любом случае, атакер сможет изменить содержимое web-сайта. |
| 2002514 | CGI guestbook.cgi. |
| 2002515 | CGI guestbook.pl. |
| 2002516 | CGI handler. Попытка исполнения CGI-хандлера, который обладает известными слабостями Эта CGI-программа является частью "Outbox Environment" в системах SGI IRIX. Программа может использоваться для выполнения любой команды на web-сервере. Для того, чтобы реализовать это, используйте программу Telnet следующим образом: telnet www.example.com 80 GET /cgi-bin/handler/useless_shit;cat /etc/passwd|?data=Download HTTP/1.0 Используйте символ TAB, чтобы ввести пробел в пределах команды. |
| 2002517 | CGI htmlscript. |
| 2002518 | CGI info2www. |
| 2002519 | CGI machineinfo. |
| 2002520 | CGI nph-test-cgi. |
| 2002521 | CGI perl. Произведена попытка исполнить perl-скрипт, который позволит хакеру неавторизованный доступ к серверу. Это программа shell, которая может выполнить произвольные операции на сервере. Если эта программа случайно помещена в удаленно доступный каталог, и, если выявлена модификация некоторого системного параметра, можете считать свою систему скомпрометированной. Вам следует немедленно удалить программу из ее каталога и поместить в более подходящее место, проверьте вашу систему на наличие троянских коней, а также проконтролируйте конфигурацию на предмет возможных модификаций. |
| 2002522 | CGI perl.exe. Произведена попытка исполнить perl.exe, которая позволит хакеру неавторизованный доступ к серверу. Это программа shell, которая может выполнить произвольные операции на сервере. Если эта программа случайно помещена в удаленно доступный каталог, и, если выявлена модификация некоторого системного параметра, можете считать свою систему скомпрометированной. Вам следует немедленно удалить программу из ее каталога и поместить в более подходящее место, проверьте вашу систему на наличие троянских коней, а также проконтролируйте конфигурацию на предмет возможных модификаций. |
| 2002523 | CGI pfdispaly.cgi. |
| 2002524 | CGI phf. |
| 2002525 | CGI rguest.exe. |
| 2002526 | CGI wguest.exe. |
| 2002527 | CGI rksh. |
| 2002528 | CGI sh. |
| 2002529 | CGI tcsh. |
| 2002530 | CGI test-cgi.tcl. |
| 2002531 | CGI test-cgi. |
| 2002532 | CGI view-source. |
| 2002533 | CGI webdist.cgi. |
| 2002534 | CGI webgais. |
| 2002535 | CGI websendmail. |
| 2002536 | CGI win-c-sample.exe. |
| 2002537 | CGI wwwboard.pl. |
| 2002538 | CGI uploader.exe. |
| 2002539 | CGI mlog.html. |
| 2002540 | CGI mylog.html. |
| 2002541 | CGI snork.bat. |
| 2002542 | CGI newdsn.exe. |
| 2002543 | FrontPage service.pwd. |
| 2002544 | .bash_history URL. |
| 2002545 | .url URL type. |
| 2002546 | .lnk URL type. |
| 2002547 | WebStore admin URL. |
| 2002548 | Shopping cart order URL. |
| 2002549 | Order Form V1.2 data URL. |
| 2002550 | Order Form data URL. |
| 2002551 | EZMall data URL. |
| 2002552 | QuikStore configuration URL. |
| 2002553 | SoftCart password URL. |
| 2002554 | Cold Fusion Sample URL. |
| 2002555 | favicon.ico bad format. |
| 2002556 | Site Server sample URL. |
| 2002557 | IIS sample URL. |
| 2002558 | IIS password change. |
| 2002559 | IIS malformed .HTR request. |
| 2002560 | IIS data service query. |
| 2002561 | .htaccess URL. |
| 2002562 | passwd.txt URL. |
| 2002563 | NT system backup URL. |
| 2002564 | CGI imagemap.exe. |
| 2002565 | adpassword.txt URL. |
| 2002566 | CGI whois suspicious field. |
| 2002567 | Cold Fusion cache URL. |
| 2002568 | IIS malformed HTW request. |
| 2002569 | CGI finger.cgi. |
| 2002570 | WebSpeed admin URL. |
| 2002571 | UBB suspicious posting. |
| 2002572 | SubSeven ICQ pager URL. |
| 2002573 | Oracle batch file URL. |
| 2002574 | sojourn.cgi argument contains %20. |
| 2002575 | Index Server null.htw exploit. |
| 2002576 | FrontPage extension backdoor URL. Прислан "подозрительный" URL. Библиотека dvwssr.dll, встроенная в расширения FrontPage 98 для IIS, включает в себя ключ шифрования "Netscape engineers are weenies!". Этот ключ может быть использован для маскирования имени запрошенного файла, который затем передается в качестве аргумента в dvwssr.dll URL. Любой, кто имеет привилегии доступа к web-серверу ЭВМ мишени может загрузить любую Web-страницу, включая файлы текстов программ ASP. Используя файл dvwsrr.dll можно также переполнить буфер. Успешная атака может позволить исполнение на сервере удаленной программы. |
| 2002577 | FrontPage htimage.exe URL. |
| 2002578 | InfoSearch CGI exploit. |
| 2002579 | Cart32 Clientlist URL. |
| 2002580 | Cart32 ChangeAdminPassword URL. |
| 2002581 | Listserv CGI exploit. |
| 2002582 | Calendar CGI exploit. Подозрительный URL. Конфигурационный параметр содержит мета-символы, которые вероятно означают, что атакер пытается использовать слабости в некоторых версиях CGI-скрипта. В случае успеха, он сможет выполнить произвольную команду на сервере. |
| 2002583 | Rockliffe CGI exploit. |
| 2002584 | RealServer Denial-of-service URL. |
| 2002585 | Java Admin Servlet backdoor URL. Административный модуль Java Web Server допускает компиляцию и исполнение программы Java server с помощью специального URL. Если атакеру удалось загрузить свой собственный Java-код на сервере, он может тогда скомпилировать и исполнить этот код и получить контроль над серверной системой. |
| 2002586 | DOS DoS URL. |
| 2002587 | Auction Weaver CGI exploit. |
| 2002589 | CGI jj exploit. |
| 2002590 | classifieds.cgi. |
| 2002591 | BNBSurvey survey.cgi. |
| 2002592 | YaBB exploit. |
| 2002593 | Webplus CGI exploit. |
| 2002594 | Squid cachemgr.cgi. |
| 2002595 | IIS system32 command. |
| 2002596 | Webevent admin. |
| 2002597 | Unify UploadServlet. |
| 2002598 | Thinking Arts directory traversal. |
| 2002599 | Lotus Domino directory traversal. |
| 2002600 | Commerce.cgi directory traversal. |
| 2002601 | CGI mailnews suspicious field. |
| 2002602 | FrontPage Publishing DoS. |
| 2002603 | way-board cgi file access. |
| 2002604 | roads cgi file access. |
| 2002605 | Hack-a-tack ICQ pager URL. |
| 2002606 | Bionet ICQ pager URL. |
| 2002607 | IIS .printer overflow. |
| 2002608 | ISAPI index extension overflow. |
| 2002609 | Y3K ICQ pager URL. |
| 2002610 | HTTP Pfdisplay Execute. |
| 2002611 | HTTP Pfdisplay Read. |
| 2002701 | SMB passwd file. |
| 2002702 | SMB sam file. |
| 2002703 | SMB winreg file. |
| 2002704 | SMB pwl file type. |
| 2002705 | SMB win.ini file. |
| 2002706 | Startup file access. |
| 2002707 | SMB autoexec.bat file access. |
| 2002710 | SMB RICHED20.DLL access. |
| 2002801 |
MS rpc dump. Атакер пытается сканировать вашу систему для услуг RPC/DCOM. Возможно он ищет слабости в системе доступа. Была попытка загрузки списка всех услуг RCP/DCOM. Это специальная команда, которая может быть послана к "RPC End-Point Mapper" работающему с port 135. Эта атака не направлена непосредственно на вторжение. Она является частью (разведывательного этапа)
reconnaissance атаки. Команда 'epdump' попросит ЭВМ Windows перечислить все работающие сервисы. Хакер, получив эти данные, сможет эффективнее искать слабые места в вашей обороне. Если хакер найдет какие-то их этих услуг, он вероятно попытается воспользоваться ими. Например, существуют пути, посредством которых спамер может направить e-mail через Microsoft Exchange Servers. Путем выполнения 'epdump', спамер может выяснить, работает ли машина в качестве сервера. Если это так, спамер может затем заставить систему переадресовать SPAM своим "клиентам". Зафильтруйте порт 135 в firewall, как для UDP так и TCP.
| 2002802 | MS share dump. |
| 2002803 | MS domain dump. |
| 2002804 | MS name lookup. |
| 2002805 | MS security ID lookup. |
| 2002806 | Malformed LSA request. |
| 2002807 | RFPoison attack. |
| 2002808 | LsaLookup Denial of Service. |
| 2002901 | PPTP malformed. |
| 2002902 | IGMP fragments. |
| 2002903 | SNTP malformed. |
| 2002904 | XDMCP gdm exploit. |
| 2002905 | VNC no authentication. |
| 2002906 | VCF attachment overflow. |
| 2002907 | SNTP overflow. |
| 2002908 | Quake Exploit. |
| 2002911 | RADIUS User Overflow. |
| 2002912 | RADIUS Pass Overflow. |
| 2003001 | HTTP port probe. |
| 2003002 | POP3 port probe. |
| 2003003 | SMTP port probe. |
| 2003004 | FTP port probe. |
| 2003005 | IMAP4 port probe. |
| 2003006 | TELNET port probe. |
| 2003007 | FINGER port probe. |
| 2003008 | RLOGIN port probe. |
| 2003009 | NetBIOS port probe. |
| 2003010 | NNTP port probe. |
| 2003011 | DNS TCP port robe. |
| 2003012 | PCANYWHERE port probe. |
| 2003013 | SQL port probe. |
| 2003014 | MSRPC TCP port probe. |
| 2003015 | XWINDOWS port probe. Возможно хакер просканировал вашу систему, чтобы проверить, доступно ли XWINDOWS. Иногда это делается в ходе подготовки будущей атаки, или иногда это делается с целью выяснения, уязвима ли ваша система. |
| 2003016 | RPC TCP port probe. |
| 2003017 |
SOCKS port probe. Кто-то сканирует вашу систему, чтобы проверить, не работает ли там SOCKS. Это означает, что хакер хочет устроить переадресацию трафика через вашу систему на какой-то другой сетевой объект. Это может быть также chat-сервер, который пытается определить, не пробует ли кто-то использовать вашу систему для переадресации. SOCKS представляет собой систему, которая позволяет нескольким машинам работать через общее Интернет соединение. Многие приложения поддерживают SOCKS. Типичным продуктом является WinGate. WinGate инсталлируется на ЭВМ, которая имеет реальное Интернет соединение. Все другие машины в пределах данной области подключаются к Интернет через эту ЭВМ. Проблема с SOCKS и продуктами типа WinGate заключается в том, что они не делают различия между отправителем и получателем, что облегчает удаленным машинам из Интернет получить доступ к внутренним ЭВМ. Что важно, это может позволить хакеру получить доступ к другим машинам через вашу систему. При этом хакер маскирует свое истинное положение в сети. Атака против жертвы выглядит так, как если бы она была предпринята со стороны вашей машины. Этот вид атаки на первом этапе выглядит как сканирование. При использовании SOCKs систему следует конфигурировать так, чтобы заблокировать посторонний доступ. Хакер рассчитывает на вашу ошибку при конфигурации.
| 2003018 | PPTP port probe. |
| 2003019 | IRC port probe. |
| 2003020 | IDENT port probe. |
| 2003021 | Linux conf port probe. |
| 2003022 | LPR port probe. |
| 2003101 | TCP trojan horse probe. |
| 2003102 | TCP port probe. Кто-то пытался получить доступ к вашей машине, но не смог. Это довольно распространенный вид атаки. Типовой хакер сканирует миллионы ЭВМ, не обольщайтесь вы не являетесь главным объектом интересов хакеров, но и расслабляться пожалуй не следует. |
| 2003103 | Netbus probe. Кто-то попрововал получить доступ к вашей ЭВМ с помощью "NetBus Trojan Horse" и потерпел неудачу. Хакер ищет ЭВМ, скомпрометированную посредством этой программы. Раз вы не скомпрометированы, хакер потерпел неудачу. Программа Trojan рассылается клиентам в надежде, что какой-то легкомысленный человек ее запустит. Задача такой программы похитить пароль, установить вирус, или переформатировать ваш диск. Специальную популярную группу образуют троянские кони, обеспечивающие удаленный доступ к вашей машине. Такие программы хакер пытается прислать по почте, через chat или новости, при этом хакер может не знать, где в Интернет находится ваша ЭВМ (он не знает, кто читает новости, да и по почте он рассылает эту гадость по тысячам адресов). Хакер знает только, кто является вашим провайдером, и вынужден сканировать всех клиентов данного ISP. При таком сканировании хакера устроит ситуация, когда вы получили данного троянского коня от другого атакера. |
| 2003104 | Proxy port probe. Атакер сканирует вашу систему с целью обнаружения прокси-сервера. Затем атакер может воспользоваться вашим прокси-сервером для анонимного просмотра Internet. В настоящее время сканирование TCP-портов 3128,8000 или 8080 рассматривается как обращение к прокси. |
| 2003105 | SubSeven port probe. |
| 2003106 | T0rn port probe. |
| 2003201 | SECURITY/SAM reg hack. Была предпринята попытка доступа к ключу registry под HKLM/SECURITY/SAM. Под этим ключом зарегистрированы имена и пароли пользователей. Хотя пароли зашифрованы, они могут быть проанализированы off-line и выяснены путем грубого перебора. |
| 2003202 | RUN reg hack. Была предпринята попытка записи в ключи registry, которые управляют программой при загрузке системы или когда в систему входит новый пользователь. Такими ключами являются HKLM/SOFTWARE/Microsoft/Windows/CurrentVersion/Run HKLM/SOFTWARE/Microsoft/Windows/CurrentVersion/RunOnce HKLM/SOFTWARE/Microsoft/Windows/CurrentVersion/RunOnceEx HKLM/SOFTWARE/Microsoft/Windows/CurrentVersion/RunServices HKLM/SOFTWARE/Microsoft/Windows/CurrentVersion/RunServicesOnce HKLM/SOFTWARE/Microsoft/Windows/CurrentVersion/RunServicesEx Если имела места попытка записи в один из этих ключей, это может быть попыткой продвинуть Trojan Horse. |
| 2003203 | RDS reg hack. Была предпринята серьезная попытка скомпрометировать систему или легальная сетевая платформа осуществляет удаленное конфигурирование системы. Осуществлена попытка удаленной записи ключей registry HKLM\SOFTWARE\Microsoft\DataFactory\HandlerInfo или HKLM\SOFTWARE\Microsoft\Jet\3.5\Engines\SandboxMode. Эти ключи ограничивают удаленный доступ к определенным базам данных в системе Windows. Атакер может попытаться установить свои значения для этих объектов registry, так что неавторизованный удаленный доступ может быть осуществлен позднее через точку уязвимости RDO exploit. По умолчанию, эти ключи могут быть переписаны кем угодно. Разрешения должны быть изменены так, что только администратор мог их менять. |
| 2003204 | Index Server reg hack. Была предпринята попытка удаленного доступа к записям Index Server's registry. Сделана попытка доступа к ключу registry Remove remote access в HKLM\SYSTEM\CurrentControlSet\Control\SecurePipeServers\Winreg\AllowedPaths |
| 2003205 | NT RASMAN Privilege Escalation attempt. Была предпринята попытка удаленного доступа к троянскому коню RAS manager. Сделана попытка доступа к ключу registry HKLM\SYSTEM\CurrentControlSet\Services\RASMan, который удаленно изменяет программу путем изменения сервера, при следующем запуске ЭВМ, будет исполнена специфицированная программа. |
| 2003206 | LSA Secrets attempt. Была предпринята попытка удаленного доступа к "Local System Authority" через вызов registry. Атакер получает удаленный доступ к информации о секретных пароля хremotely. Эти пароли хранятся в зашифрованном виде в registry. |
| 2003207 | AeDebug reg hack. |
| 2003208 | IMail privilege escalation attempt. |
| 2003209 | SQL Exec Passwd. Была предпринята попытка сканирования записей SQLExecutive registry. Происходит подозрительное чтение записей registry из SQL-сервера. Иногда пароли записываются в registry, что делает систему уязвимой. |
| 2003301 | AOL Instant Messenger overflow. |
| 2003302 | AOL w00w00 attack. |
| 2003401 | SNMP port probe. |
| 2003402 | RPC UDP port probe. |
| 2003403 | NFS port probe. |
| 2003404 | TFTP port probe. |
| 2003405 | MSRPC UDP port probe. |
| 2003406 | UDP ECHO port probe. |
| 2003407 | CHARGEN port probe. |
| 2003408 | QOTD port probe. |
| 2003409 | DNS UDP port probe. |
| 2003410 | MSDNS port probe. |
| 2003411 | NFS-LOCKD port probe. |
| 2003412 | Norton Antivirus port probe. |
| 2003501 | UDP Trojan Horse probe. |
| 2003502 | UDP port probe. |
| 2003601 | FTP passwd file. |
| 2003602 | FTP sam file. |
| 2003604 | FTP pwl file type. |
| 2003605 | FTP win.ini file. |
| 2003606 | FTP Host File. |
| 2003701 | TFTP passwd file. |
| 2003702 | TFTP sam file. |
| 2003704 | TFTP pwl file type. |
| 2003705 | TFTP win.ini file. |
| 2003706 | TFTP Host File. |
| 2003707 | TFTP Alcatel files. |
| 2003801 | HTTP GET passwd file. Была предпринята подозрительная попытка доступа к файлу. Сделана попытка доступа к файлу passwd, который содержит зашифрованные Unix-пароли. Атакер может после этого использовать общедоступные программные средства для вскрытия паролей, содержащихся в этом файле. |
| 2003802 | HTTP GET sam file. |
| 2003804 | HTTP GET pwl file type. |
| 2003806 | HTTP GET AltaVista password. |
| 2003901 | HTTP POST passwd file. |
| 2003902 | HTTP POST sam file. |
| 2003904 | HTTP POST pwl file type. |
| 2003905 | HTTP POST win.ini file. Была предпринята попытка удаленного доступа к системному файлу WIN.INI посредством Web-формы. Эта попытка может быть сопряжена с намерением реконфигурировать систему, чтобы реконфигурированная система при последующем запуске загрузила троянского коня. |
| 2004001 |
SOCKS connect. Кто-то подключился через вашу систему, используя протокол SOCKS. Это может быть хакер, который хочет переадресовать трафик через вашу систему на другие ЭВМ, а также сервер chat, пытающийся определить, не пробует ли кто-то проскочить через вашу систему чтобы работать анонимно на "халяву". SOCKS представляет собой систему, которая позволяет нескольким машинам работать через общее Интернет соединение. Многие приложения поддерживают SOCKS. Типичным продуктом является WinGate. WinGate инсталлируется на ЭВМ, которая имеет реальное Интернет соединение. Все другие машины в пределах данной области подключаются к Интернет через эту ЭВМ. Проблема с SOCKS и продуктами типа WinGate заключается в том, что они не делают различия между отправителем и получателем, что облегчает удаленным машинам из Интернет получить доступ ко внутренним ЭВМ. Что важно, это может позволить хакеру получить доступ к другим машинам через вашу систему. При этом хакер маскирует свое истинное положение в сети. Атака против жертвы выглядит так, как если бы она была предпринята со стороны вашей машины. Этот вид атаки на первом этапе выглядит как сканирование. При использовании SOCKs систему следует конфигурировать так, чтобы заблокировать посторонний доступ. Хакер рассчитывает на вашу ошибку при конфигурации. Ваша внутренняя сеть должна использовать IP-адреса, которые никогда не появляются в Internet. Такими адресами обычно являются "192.168.x.x", "172.16.x.x" или "10.x.x.x".
| 2004002 | SOCKS over SOCKS. Кто- то подключился через вашу систему, используя протокол SOCKS. то может быть хакер, который хочет переадресовать трафик через вашу систему на другие ЭВМ. В этом случае, трафик оказывается инкапсулированным в SOCKS, это означает, что атакер вероятно намерен использовать вашу систему для переадресации к другой системе SOCKS. SOCKS представляет собой систему, которая позволяет нескольким машинам работать через общее Интернет соединение. Многие приложения поддерживают SOCKS. Типичным продуктом является WinGate. WinGate инсталлируется на ЭВМ, которая имеет реальное Интернет соединение. Все другие машины в пределах данной области подключаются к Интернет через эту ЭВМ. Проблема с SOCKS и продуктами типа WinGate заключается в том, что они не делают различия между отправителем и получателем, что облегчает удаленным машинам из Интернет получить доступ ко внутренним ЭВМ. Что важно, это может позволить хакеру получить доступ к другим машинам через вашу систему. При этом хакер маскирует свое истинное положение в сети. Атака против жертвы выглядит так, как если бы она была предпринята со стороны вашей машины. |
| 2004101 | Java contains Brown Orifice attack. |
| 2004201 | HTTP Cross site scripting. |
| 2004301 | DHCP Domain Metachar. |
| 2004302 | BOOTP File Overflow. |
| 2004303 | UPNP NOTIFY overflow. |
| 2004401 | SubSeven email. |
| 2004402 | Bionet email. Программа троянского коня Bionet имеет возможность посылать оповещения через e-mail, когда система, содержащая троянского коня, загружается. Это позволяет хакеру знать, что Bionet работает, и ваша система может быть компрометирована хакером. Судя по всему ваша система скомпрометирована. Вам следует использовать антивирусную программу, чтобы немедленно удалить троянского коня Bionet из вашей системы. |
| 2004403 | Y3K email. |
| 2004501 |
HTTP GET contains xp_cmdshell. В качестве аргумента URL обнаружена строка xp_cmdshell; это обычно указывает, что предпринята попытка исполнить команду shell для атакера исполнять на сервере команды shell.
| 2004502 | HTTP POST contains xp_cmdshell. В данных, передаваемых Web-сайту, обнаружена строка xp_cmdshell. Это обычно указывает, что предпринята попытка выполнить команду shell на SQL-сервере. Если SQL-сервер некорректно сконфигурирован, имеется возможность для атакера выполнять на сервере команды shell. |
| 2004601 | Code Red I. |
| 2004602 | Code Red II. |
| 2004603 | Code Red II+. |
| 2009100 | DNS crack successful. |
| 2009201 | ISS Scan. |
| 2009202 | CyberCop Scan. |
| 2009203 | Nessus Scan. |
| 2009204 | Satan Scan. |
| 2009205 | Saint Scan. |
| 2009206 | Cerebus Scan. |
| 2009207 | Retina Scan. |
| 2010000-2010999 | User-specified filename. |
| 2011000-2011999 | User-specified URL. |
| 2012000-2012999 | User-specified email recipient. |
| 2013000-2013999 | User-specified email pattern. |
| 2014000-2014999 | User-specified MIME-attached filename. |
| 2015000-2015999 | User-specified TCP probe port. |
| 2016000-2016999 | User-specified UDP probe port. |
| 2017000-2017999 | User-specified registry key. |
| 2018000-2018999 | User-specified TCP trojan response. |
| 2019000-2019999 | User-specified IRC channel name. |
| 2020000-2020999 | User-specified Java pattern. |
| 2900001 | Application Terminated. |
| 2900002 | Application Added. |
| 2900003 | Application Communication Blocked. |
| Config | Configuration parameters. |
Справочные данные по математике
10.20 Справочные данные по математике
Семенов Ю.А. (ГНЦ ИТЭФ)
С которой в завихрениях истории
Хохочет бесноватая действительность
Над мудрым разумением теории
И. ГуберманПриводимые в данном разделе определения вляются "шпаргалкой" на случай, когда вы знаете предмет, но что-то забыли. Для первичного изучения математических основ рекомендую обратиться к серьезным монографиям и учебникам.
Условная вероятность.
В теории вероятностей характеристикой связи событий А и B служит условная вероятность P(А|B) события А при условии B, определяемая как P(А|B) = 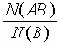
где N(B) – число всех элементарных исходов w, возможных при условии наступления события B, а N(АB) – число тех из них, которые приводят к осуществлению события А.
Если событие B ведет к обязательному осуществлению А: b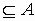 то P(A|B)=1, если же наступление B исключает возможность события А: A*B=0, то P(A|B)=0. Если событие А представляет собой объединение непересекающихся событий A1, A2,…: A =
то P(A|B)=1, если же наступление B исключает возможность события А: A*B=0, то P(A|B)=0. Если событие А представляет собой объединение непересекающихся событий A1, A2,…: A = 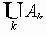
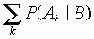 .
.
Если имеется полная система несовместимых событий B =B1, B2,… т.е. такая система непересекающихся событий, одно из которых обязательно осуществляется, то вероятность события A (P(A)) выражается через условные вероятности P(A|B) следующим образом:
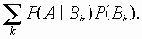
(формула полной вероятности).
Множества.
Множество – это совокупность некоторых элементов. Если элемент х входит в множество А, это записывается как x О A. Соотношения A1 Н A2 или A2 К A1 означает, что A1 содержится во множестве A2 (каждый элемент х множества A1 входит в множество A2; A1 является подмножеством A2).
Суммой или объединением множеств А1 и А2 называется множество, обозначаемое A1 И A2, которое состоит из всех точек х, входящих хотя бы в одно из множеств A1 или A2.
Пересечением или произведением множеств А1 и А2 называется множество, обозначаемое A1З A2, A1*A2 или A1A2, которое состоит из всех точек х, одновременно входящих и в A1 и в A2; пересечение 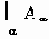
Пустые множества обозначаются 0.
Множества, дополнительные к открытым множествам топологического пространства Х, называются замкнутыми.
Нормированное пространство Х называется гильбертовым, если определена числовая функция двух переменных х1 и х2, обозначаемая (x1,x2) и называемая скалярным произведением, обладающим следующими свойствами:
(x,x)і 0;
(x,x)=0 тогда и только тогда, когда х=0;
(l 1x1+l2
x2, x) = l 1(x1,x) + l 2(x2,x);
(x, l 1x1+l2
x2) = l1(x,x1) + l 2(x,x2)
при любых l1, l2 и x1, x2ОX. Норма ||x|| элемента гильбертова пространства Х определяется как ||x||=

Счетно-гильбертово пространство Х называется ядерным, если для любого р найдется такое q и такой ядерный оператор А в гильбертовом пространстве Х со скалярным произведением (х1,x2)=(х1,х2)q, что (х1,x2)p=(Ax1,x2)q.
Действительное число M является верхней границей или нижней границей множества Sy действительных чисел y, если для всех y О Sy соответственно y Ј M или yі M. Множество действительных или комплексных чисел ограничено (имеет абсолютную границу), если верхнюю границу имеет множество абсолютных величин этих чисел; в противном случае множество не ограничено. Каждое непустое множество Sy действительных чисел y, имеющее верхнюю границу, имеет точную верхнюю границу (наименьшую верхнюю границу) sup y, а каждое непустое множество действительных чисел y, имеющее нижнюю границу, имеет точную нижнюю границу (наибольшую нижнюю границу) inf y. Если множество Sy конечно, то его точная верхняя граница sup y необходимо равна наибольшему значению (максимуму) max y, фактически принимаемому числом y в Sy, а точная нижняя граница inf y равна минимуму min y.
Множество называется открытым, если оно состоит только из внутренних точек. Точка P множества называется внутренней для множества S, если P имеет окрестность, целиком содержащуюся в S.
Компакт. Система множеств G называется центрированной, если пересечение конечного числа любых множеств из G не пусто. Замкнутое множество A Н X называется компактом, если всякая центрированная система G его замкнутых подмножеств F имеет непустое пересечение:
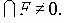 компактным в Х, если его замыкание F=[A] является компактом.
компактным в Х, если его замыкание F=[A] является компактом.Гауссовы случайные процессы
.
Действительная случайная величина x называется гауссовой, если ее характеристическая функция j =j (u) имеет вид
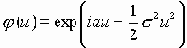
фигурирующие здесь параметры a и s2 имеют простой вероятностный смысл: a=Mx (среднее значение), s2 = Dx (средне-квадратичное отклонение). Соответствующее распределение вероятностей также называется гауссовым, его плотность имеет вид
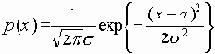
Марковские случайные процессы
.
Случайный процесс x =x(t) на множестве T действительной прямой в фазовом пространстве (E,B) называется марковским, если условные вероятности P(A|U(-Ґ,s) событий AО U(t,Ґ ) относительно s-алгебры U(-Ґ,s) таковы, что при s Јt с вероятностью 1
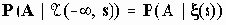
здесь U(u,v) означает s-алгебру порождаемую всевозможными событиями вида { x(t) О B}, t О[u,v]З T, BО B. Если параметр t интерпретировать как время, то описанное марковское свойство случайного процесса x =x (t) состоит в том, что поведение процесса после момента t при фиксированном состоянии x=x (t) не зависит от поведения процесса до момента t. Для любых событий А ОU
(-Ґ,t1) и A2О U(t1, Ґ) и при любом t О T t1 ЈtЈ t2 с вероятностью 1
P(A1A2|x (t)) = P(A1|x (t)) P(A2|x(t)).
Цепи Маркова
. Пусть x (t) - состояние системы в момент времени t, и пусть соблюдается следующая закономерность: если в данный момент времени s система находится в фазовом состоянии i, то в последующий момент времени t система будет находиться в состоянии j с некоторой вероятностью pij(s,t) независимо от поведения системы до указанного момента s. Описывающий поведение системы процесс x (t) называется цепью Маркова. Вероятности pij(s,t) = p{x (t)=j|x (s)=i} (i,j = 1, 2, …) называются переходными вероятностями марковской цепи x (t).
Марковская цепь x (t) называется однородной, если переходные вероятности pij(s,t) зависят лишь от разности t-s: pij(s,t) = pij(s-t) (i,j=1,2,…)
Финальные вероятности
. Пусть состояния однородной марковской цепи x (t) образует один замкнутый положительный непериодический класс. Тогда для любого состояния j существует предел
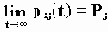
Pj=
где Qj – среднее время возвращения в состояние j в дискретные моменты t = 0, 1, 2, … .
Коэффициент эргодичности
. Пусть x =x (t) – случайный марковский процесс в фазовом пространстве (E,B) с переходной функцией P(s,x,t,B). С вероятностью 1 имеет место равенство
b
(s,t) =
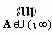
(-?, s))- P(A| =
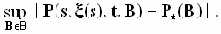
Величина k(s,t) = 1 -
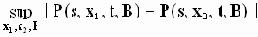
называется коэффициентом эргодичности марковского процесса x =x (t).
Переходная функция.
Функция P(s,x,t,B) переменных s, tО T, s Ј t и xО E, bО b называется переходной функцией марковского случайного процесса x =x (t) на множестве T в фазовом пространстве (E,B), если эта функция при фиксированных s, tО T и xО E представляет собой распределение вероятностей на s
-алгебре b и при фиксированных s, tО T и BО b является измеримой функцией от x О E.
Стационарные случайные процессы
. Стационарный действительный или комплексный случайный процесс x =x (t), рассматриваемый как функция параметра t со значениями в гильбертовом пространстве L2(W) всех действительных или комплексных случайных величин h =h (w), M|h |2<Ґ (со скалярным произведением
(h 1, h2)= M h1
h2),
может быть представлен в виде
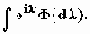
Белый шум.
Простейшим по структуре стационарным процессом с дискретным временем является процесс z =z (t) с некоррелированными значениями:
Mz(t)=0, M|z(t)|2=1,
Mz(t1)
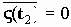
В случае непрерывного времени t аналогом такого процесса является так называемый “белый шум” – обобщенный стационарный процесс z = б u, z с вида
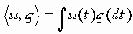
(параметр u=u(t) есть бесконечно дифференцируемая функция), где стохастическая мера z = z (d ) такова, что
Mz (D )=0, M|z (D )|2
=t-s при D =(s,t), Mz (D1) z (D2)=0 для любых непересекающихся D1 и D2.
Стационарный процесс x= x(t), Mx(t)=0, называется линейно-регулярным, если
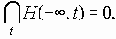
где H(s,t) – замкнутая линейная оболочка в пространстве L2(W) значений x(u), s Ј u Ј t. Стационарный процесс x =x(t) со спектральной мерой F является линейно-регулярным тогда и только тогда, когда F=F( D) абсолютно непрерывна:
F(D) =
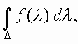
а спектральная плотность f=f(l) удовлетворяет условию
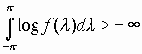
(для дискретного t)
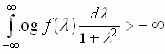
(для непрерывного t)
Стационарный процесс x =x(t) линейно-регулярен тогда и только тогда, когда он получается некоторым физически осуществимым линейным преобразованием из процесса z = z(t) с некоррелированными значениями – в случае дискретного t:
x(t) =
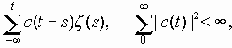
и из процесса z =б u, z с “белого шума” – в случае непрерывного t:
x(t) =
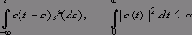
Регулярность. Реальные стационарные процессы часто возникают в результате некоторого случайного стационарного возмущения Z = z (t) типа “белого шума”. Процесс z = z(t) подвергается некоторому линейному преобразованию и превращается в стационарный процесс x =x(t). Спектральная плотность f= f(l) такого процесса в диапазоне -p Ј l Ј p для целочисленного времени и -Ґ <l <Ґ для непрерывного времени t не может обращаться тождественно в нуль ни на каком интервале: в противном случае стационарный процесс x (t) будет сингулярным, что означает возможность его восстановления лишь на полуоси -Ґ ,t0. Процессы, спектр которых практически сосредоточен в полосе частот –W< l <W, не обладают свойствами сингулярных процессов. С энергетической точки зрения эти процессы имеют ограниченный спектр. Составляющие их гармонические колебания вида Ф(dl )eilt с частотами вне интервала (-W,W) имеют весьма малые энергии, но они существенно влияют на линейный прогноз значений x (t+t) на основе x (s) на временной полуоси sЈt.
Линейные устройства, используемые при решении конкретных задач, должны иметь вполне определенную постоянную времени T (определяет длительность переходных процессов). Это означает, что весовая функция h=h(t) рассматриваемого линейного устройства, связанная с соответствующей передаточной функцией Y =Y(p) равенством
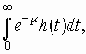
должна удовлетворять требованию h(t)=0 при t>T.
Рассмотрим задачу линейной фильтрации при наличии на входе процесса x =x(t). Тогда x (t)= z (t) +h(t), где h =h(t) – полезный сигнал, а z(t) – независимый от него стационарный случайный процесс (шум). Линейное устройство должно быть выбрано так, чтобы процесс на входе
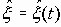
был по возможности близок к входному полезному сигналу h = h(t), так что в стационарном режиме работы
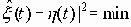
Линейное устройство, отвечающее поставленным требованиям, должно иметь такую передаточную функцию Y=Y(p), чтобы соответствующая спектральная характеристика
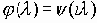
являлась решением интегрального уравнения
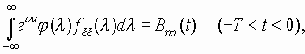
Где
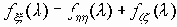
- спектральная плотность входного процесса x (t), а Bh h(t) – корреляционная функция полезного сигнала h (t).
Закон больших чисел
. Пусть x1,…, xn – независимые случайные величины, имеющие одно и то же распределение вероятностей, в частности одни и те же математические ожидания a = M
xk и дисперсии
s2=Dxk, k=1,…,n. Каковы бы ни были e >0 и d >0, при достаточно большом n арифметическое среднее
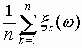
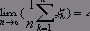 )
) с вероятностью, не меньшей 1-d, будет отличаться от математического ожидания a лишь не более чем на
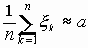
Распределение Эрланга
Рассмотрим систему, которая способна обслуживать m запросов одновременно. Предположим, что имеется m линий и очередной запрос поступает на одну из них, если хотя бы одна из них свободна. В противном случае поступивший запрос будет отвергнут. Поток запросов считается пуассоновским с параметром l0, а время обслуживания запроса (в каждом из каналов) распределено по показательному закону с параметром l, причем запросы обслуживаются независимо друг от друга. Рассмотрим состояния E0, E1,…,Em, где Ek означает, что занято k линий. В частности E0 означает, что система свободна, а Em – система полностью занята. Переход из одного состояния в другое представляет собой марковский процесс, для которого плотности перехода можно описать как:

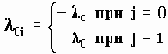
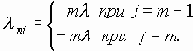

При t ® Ґ переходные вероятности pij(t) экспоненциально стремятся к своим окончательным значениям Pj, j=0,…,m. Окончательные вероятности Pj могут быть найдены из системы:
-l0P0+lP1=0
l0Pk-1 – (l0+kl)Pk + (k+1)lPk+1 =0 (1Ј k<m)
l0pm-1+ml Pm=0
решение которой имеет вид:
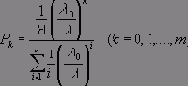
Эти выражения для вероятностей называются формулами (распределением) Эрланга.
SPX-протокол
4.2.1.2 SPX-протокол
Семенов Ю.А. (ГНЦ ИТЭФ)
SPX (Sequence Packet eXchange) и его усовершенствованная модификация SPX II представляют собой транспортные протоколы 7-уровневой модели ISO. Это протокол гарантирует доставку пакета и использует технику скользящего окна (отдаленный аналог протокола TCP). В случае потери или ошибки пакет пересылается повторно, число повторений задается программно. В протоколе SPX не предусмотрена широковещательная или мультикастинг-адресация. В SPX индицируется ситуация, когда партнер неожиданно прерывает соединение, например из-за обрыва связи. Пакеты SPX вкладываются в пакеты IPX. При этом в поле тип пакета IPX записывается код 5. Заголовок пакета SPX всегда содержит 42 байта, включая 30 байт заголовка IPX-пакета, куда он вложен (см. рис. 4.2.1.2.1).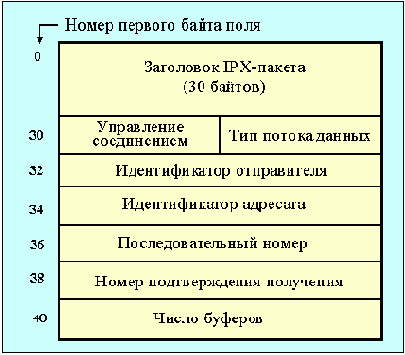
Рис. 4.2.1.2.1. Формат заголовка SPX-пакета
Поле управления соединением определяет, является ли данный пакет системным или прикладным. Это поле содержит однобитовые флаги, используемые spx и spx ii для управления потоком данных в виртуальном канале.
Поле тип потока данных характеризует тип данных, помещенных в пакет. Значения этого поля перечислены ниже:
| 0x00-0x07 | определяется клиентом и может использоваться в приложениях; | ||
| 0x80-0xfb | зарезервированы на будущее; | ||
| 0xfc | spx ii, упорядоченное освобождение запроса; | ||
| 0xfd | spx ii, упорядоченное освобождение подтверждения; | ||
| 0xfe | указывает на окончание связи (end-of-connection). При закрытии канала spx-драйвер посылает клиенту пакет, где в поле тип потока записан данный код; | ||
| 0xff | подтверждение получения сообщения об окончании связи (end-of-connection-acknowledgment). Этим кодом помечается пакет, подтверждающий закрытие канала, в прикладную программу такой пакет не передается |
/p> Поля идентификатора отправителя и получателя содержат коды, определяющие участников информационного обмена, присваиваются SPX-драйвером в момент установления связи. В запросах на соединение это поле содержит код 0xffff. Данное поле служит для обеспечения демультиплексирования пакетов, поступающих на один и тот же соединитель (socket). Поле последовательный номер определяет число пакетов пересланных в одном направлении. Каждый из партнеров обмена имеет свой счетчик, который сбрасывается в ноль после достижения 0xffff, после чего счет может продолжаться. Для приложения это поле, также как и последующие два, неприкосновенно. spx-пакеты подтверждения содержат в этом поле порядковый номер последнего посланного пакета. Поле номер подтверждения характеризует последовательный номер следующего пакета, который spx ожидает получить. Любой пакет с порядковым номером меньше, чем задано в поле номера подтверждения, доставлен благополучно и не требует ретрансмиссии. Поле число буферов служит для указания числа доступных на станции буферов (буфера нумеруются, начиная с 0, один буфер способен принять один пакет) и используется для организации управления потоком данных между приложениями. Код этого поля информирует партнера о наибольшем порядковом номере пакета, который может быть послан. Протокол spx посылает пакеты до тех пор, пока локальный последовательный номер не станет равным числу-указателю на удаленной ЭВМ.
SPX-протокол не посылает следующий пакет до тех пор, пока не получит подтверждение получения предшествующего. Хотя в протоколе SPX предусмотрен алгоритм скользящих окон (как и в TCP), практически он в настоящее время не используется, что вполне оправдано для локальных сетей. Следует заметить, что для достаточно больших LAN, где пакет проходит через несколько переключателей или маршрутизаторов, пренебрежение техникой окон становится непозволительной роскошью. На случай непредвиденных обрывов связи в spx имеется алгоритм “сторожевая собака”. Этот алгоритм реализуется специальной программой, которая активируется лишь в случае, когда в течение определенного времени в канале отсутствует трафик в любом из направлений (машина все сделала, а оператор заснул). В этом случае программа посылает специальные пакеты и, если определенное число попыток “достучаться” до партнера не увенчается успехом, сессия прерывается. Если партнер не присылает отклик за оговоренное время (RTT), производится повторная посылка пакета, при этом RTT увеличивается на 50%. Значение RTT не должно превысить величины max_retry_delay, которая по умолчанию равна 5 секундам. Если связь не восстановилась, отправитель пытается найти другой маршрут до адресата. Если маршрут найден, счетчик попыток сбрасывается в ноль и процедура отправки запускается вновь. Допустимое число попыток может лежать в диапазоне 1-255 (по умолчанию - 10). При отсутствии успеха сессия прерывается.
Значение RTT определяется по времени отклика ближайшего маршрутизатора, которое удваивается, а к полученной величине добавляется некоторая константа. Для каждой из сессий RTT определяется независимо. Многие временные константы задаются администратором сети.
Протокол spx позволяет осуществить от 100 до 2000 соединений одновременно (по умолчанию это число равно 1000). Конфигурационные параметры SPX-протокола (и сети) хранятся в файлах shell.cfg и net.cfg.
В 1992 году была разработана новая версия SPX - SPX II. Главное усовершенствование протокола связано с применением пакетов большего размера. Раньше длинные spx-пакеты фрагментировались и пересылались по частям, учитывая, что очередной пакет может быть послан лишь после получения подтверждения, нетрудно понять крайнюю неэффективность такой схемы. Стандарт spx позволяет обмен пакетами с размером, ограниченным только используемой сетевой средой. Так в Ethernet пакет SPX II может иметь длину 1518 байт. Кроме того, SPX II допускает использование технологии окон, то есть можно послать несколько кадров, не дожидаясь получения подтверждения на каждый из уже посланных. Размер окна устанавливается в соответствии с кодом, содержащимся в поле число-указатель (число буферов/пакетов). При необходимости администратор может задать размер окна раз и навсегда. Формат пакетов SPX II несколько отличается от SPX. В SPX II увеличено число допустимых кодов для поля управления соединением, введено дополнительное поле в заголовок подтверждения (два байта, имя поля “расширенное подтверждение”). Новое поле добавлено после поля число буферов. Алгоритм установление связи в SPX II отличатся от варианта spx тем, что необходимо согласовать размер пересылаемых пакетов.

Рис. 4.2.1.2.2. Формат заголовка SPX-II
Управление сетями Novell осуществляется с помощью стандартного протокола SNMP (Simple Network Management Protocol) и управляющей базы данных MIB.
который разработал такие известные стандарты
2.5.1 Стандарт MPEG-4
Семенов Ю.А. (ГНЦ ИТЭФ)
Живут привольно и просторно
Слова и запах, цвет и звук,
Фактура, линия и форма
И. Губерман
MPEG-4 является стандартом ISO/IEC разработанным MPEG (Moving Picture Experts Group), комитетом, который разработал такие известные стандарты как MPEG-1 и MPEG-2. Эти стандарты сделали возможным интерактивное видео на CD-ROM и цифровое телевидение. MPEG-4 является результатом работы сотен исследователей и разработчиков всего мира. Разработка MPEG-4 (в ISO/IEC нотации имеет название ISO/IEC 14496) завершена в октябре 1998. Международным стандартом он стал в начале 1999. Полностью совместимый расширенный вариант MPEG-4 версия 2 был разработан к концу 1999 и стал международным стандартом в начале 2000. Работы над этим документом продолжаются (см. http://sound.media.mit.edu/mpeg4/SA-FDIS.pdf). MPEG-4 предназначен для решения трех проблем:
Цифровое телевидение;
Интерактивные графические приложения (synthetic content);
Интерактивное мультимедиа World Wide Web.
Стандарт можно купить в ISO, связь через e-mail:sales@iso.ch. Программное обеспечение MPEG-4 может быть получено через сеть по адресу: www.iso.ch/ittf. Эти программы бесплатны, но это не означает, что они не защищены патентами. Смотри также http://mpeg.telecomitalialab.com/standards/mpeg-4/mpeg-4.htm.
1. Особенности стандарта MPEG-4
Стандарт MPEG-4 предоставляет технологии для нужд разработчиков, сервис-провайдеров и конечных пользователей.
Для разработчиков, MPEG-4 позволяет создавать объекты, которые обладают большей адаптивностью и гибкостью, чем это возможно сейчас с использованием разнообразных технологий, таких как цифровое телевидение, анимационная графика WWW и их расширения. Новый стандарт делает возможным лучше управлять содержимым и защищать авторские права.
Для сетевых провайдеров MPEG-4 предлагает прозрачность данных, которые могут интерпретироваться и преобразовываться приемлемые сигнальные сообщения для любой сети посредством стандартных процедур. MPEG-4 предлагает индивидуальные QoS-дескрипторы (Quality of Service) для различных сред MPEG-4. Точное преобразование параметров QoS для каждой из сред в сетевые значения QoS находится за пределами регламентаций MPEG-4 (оставлено на усмотрение сетевых провайдеров). Передача QoS-дескрипторов MPEG-4 по схеме точка-точка оптимизирует транспортировку данных в гетерогенных средах.
Для конечных пользователей, MPEG- 4 предлагает более высокий уровень взаимодействия с содержимым объектов. Стандарт транспортировать мультимедиа данные через новые сети, включая те, которые имеют низкую пропускную способностью, например, мобильные. Описания приложений MPEG-4 можно найти на странице http://www.cselt.it/mpeg.
Стандарт MPEG-4 определяет следующее:
Представляет блоки звуковой, визуальной и аудиовизуальной информации, называемые "медийными объектами". Эти медийные объекты могут быть естественного или искусственного происхождения; это означает, что они могут быть записаны с помощью камеры или микрофона, а могут быть и сформированы посредством ЭВМ;
Описывает композицию этих объектов при создании составных медийных объектов, которые образуют аудиовизуальные сцены;
Мультиплексирование и синхронизацию данных, ассоциированных с медийными объектами, так чтобы они могли быть переданы через сетевые каналы, обеспечивая QoS, приемлемое для природы специфических медийных объектов; и
Взаимодействие с аудиовизуальной сценой, сформированной на принимающей стороне.
1.1. Кодированное представление медийных объектов
Аудиовизуальные сцены MPEG-4 формируются из нескольких медийных объектов, организованных иерархически. На периферии иерархии находятся примитивные медийные объекты, такие как:
статические изображения (например, Фон изображения),
видео-объекты (например, говорящее лицо – без фона)
аудио-объекты (например, голос данного лица);
и т.д.
MPEG-4 стандартизует число таких примитивных медиа-объектов, способных представлять как естественные, так и синтетические типы содержимого, которые могут быть 2- или 3-мерными. Кроме медиа-объектов, упомянутых выше и показанных на рис. 1, MPEG-4 определяет кодовое представление объектов, такое как:
• текст и графика;
• говорящие синтезированные головы и ассоциированный текст, использованный для синтеза речи и анимации головы;
• синтезированный звук
Медиа-объекты в его кодированной форме состоит из описательных элементов, которые позволяют обрабатывать его в аудио-визуальной сцене, а также, если необходимо, ассоциированный с ним поток данных. Важно заметить, что кодированная форма, каждого медиа-объекта может быть представлена независимо от его окружения или фона.
Кодовое представление медиа-объектов максимально эффективно с точки зрения получения необходимой функциональности. Примерами такой функциональности являются разумная обработка ошибок, легкое извлечение и редактирование объектов и представление объектов в масштабируемой форме.
1.2. Состав медийных объектов
На рис. 1 объясняется способ описание аудио-визуальных сцен в MPEG-4, состоящих из отдельных объектов. Рисунок содержит составные медиа-объекты, которые объединяют примитивные медиа-объекты. Примитивные медиа-объекты соответствуют периферии описательного дерева, в то время как составные медиа-объекты представляют собой суб-деревья. В качестве примера: визуальные объекты, соответствующие говорящему человеку, и его голос объединены друг с другом, образуя новый составной медиа-объект.
Такое группирование позволяет разработчикам создавать комплексные сцены, а пользователям манипулировать отдельными или группами таких объектов.
MPEG-4 предлагает стандартизованный путь описания сцен, позволяющий:
помещать медиа-объекты, где угодно в заданной координатной системе;
применять преобразования для изменения геометрического или акустического вида медиа-объекта;
группировать примитивный медиа-объекты для того чтобы образовать составные медиа-объекты;
использовать потоки данных, чтобы видоизменять атрибуты медиа-объектов (например, звук, движущуюся текстуру, принадлежащую объекту; параметры анимации, управляющие синтетическим лицом);
изменять, интерактивно, точку присутствия пользователя на сцене (его точку наблюдения и прослушивания).
Описание сцены строится во многих отношениях также как и в языке моделирования виртуальной реальности VRML (Virtual Reality Modeling language).
Рис. 1. Пример сцены MPEG-4
1.3. Описание и синхронизация потоков данных для медийных объектов
Медиа-объектам может быть нужен поток данных, который преобразуется в один или несколько элементарных потоков. Дескриптор объекта идентифицирует все потоки ассоциированные с медиа-объектом. Это позволяет иерархически обрабатывать кодированные данные, а также ассоциированную медиа-информацию о содержимом (называемом “информация содержимого объекта”).
Каждый поток характеризуется набором дескрипторов для конфигурирования информации, например, чтобы определить необходимые ресурсы записывающего устройства и точность кодированной временной информации. Более тог, дескрипторы могут содержать подсказки относительно QoS, которое необходимо для передачи (например, максимальное число бит/с, BER, приоритет и т.д.)
Синхронизация элементарных потоков осуществляется за счет временных меток блоков данных в пределах элементарных потоков. Уровень синхронизации управляет идентификацией таких блоков данных (модулей доступа) и работой с временными метками. Независимо от типа среды, этот слой позволяет идентифицировать тип модуля доступа (например, видео или аудио кадры, команды описания сцены) в элементарных потоках, восстанавливать временную базу медиа-объекта или описания сцены, и осуществлять их синхронизацию. Синтаксис этого слоя является конфигурируемым самыми разными способами, обеспечивая работу с широким спектром систем.
1.4. Доставка потоков данных
Синхронизованная доставка потока данных отправителя получателю, использующая различные QoS, доступные в сети, специфицирована в терминах слоя синхронизации и доставки, которые содержат двухслойный мультиплексор (см. рис. 2).
Первый слой мультиплексирования управляется согласно спецификации DMIF (Delivery Multimedia Integration Framework). Это мультиплексирование может быть реализовано определенным в MPEG мультиплексором FlexMux, который позволяет группировать элементарные потоки ES (Elementary Streams) с низкой избыточностью. Мультиплексирование на этом уровне может использоваться, например, для группирования ES с подобными требованиями по QoS, чтобы уменьшить число сетевых соединений или значения задержек.
Слой "TransMux" (Transport Multiplexing) на рис. 2 моделирует уровень, который предлагает транспортные услуги, удовлетворяющие требованиям QoS. MPEG-4 специфицирует только интерфейс этого слоя, в то время как остальные требования к пакетам данных будут определяться транспортным протоколом. Любой существующий стек транспортных протоколов, например, (RTP)/UDP/IP, (AAL5)/ATM, или MPEG-2 Transport Stream поверх подходящего канального уровня может стать частным случаем TransMux. Выбор оставлен за конечным пользователем или серис-провайдером, и позволяет использовать MPEG-4 с широким спектром операционного окружения.
Рис. 2. Модель системного слоя MPEG-4
Использование мультиплексора FlexMux является опционным и, как показано на рис. 2, этот слой может быть пустым, если нижележащий TransMux предоставляет все необходимые функции. Слой синхронизации, однако, присутствует всегда. С учетом этого возможно:
идентифицировать модули доступа, транспортные временные метки и эталонную временную информацию, а также регистрировать потерю данных.
опционно выкладывать данные от различных элементарных потоков в потоки FlexMux
передавать управляющую информацию:
индицировать необходимый уровень QoS для каждого элементарного потока и потока FlexMux;
транслировать данные требования QoS в действительные сетевые ресурсы;
ассоциировать элементарные потоки с медиа-объектами
передавать привязку элементарных потоков к FlexMux и TransMux каналам
1.5. Взаимодействие с медийными объектами
Пользователь видит сцену, которая сформирована согласно дизайну разработчика. В зависимости от степени свободы, предоставленной разработчиком, пользователь имеет возможность взаимодействовать со сценой. Пользователю могут быть разрешены следующие операции:
изменить точку наблюдения/слушания на сцене;
перемещать объекты по сцене;
вызывать последовательность событий путем нажатия кнопки мыши на определенных объектах, например, запуская или останавливая поток данных;
выбирать предпочтительный язык, когда такой выбор возможен;
1.6. Менеджмент и идентификация интеллектуальной собственности
Важно иметь возможность идентифицировать интеллектуальную собственность в MPEG-4 медиа-объектах. Полный перечень требований для идентификации интеллектуальной собственности можно найти на базовой странице MPEG в разделе ‘Management and Protection of Intellectual Property’.
MPEG-4 включает в себя идентификацию интеллектуальной собственности путем запоминания уникальных идентификаторов, которые выданы международными системами нумерации (например ISAN, ISRC, и т.д. [ISAN: International Audio-Visual Number, ISRC: International Standard Recording Code]). Эти числа могут использоваться для идентификации текущего владельца прав медиа-объекта. Так как не все содержимое идентифицируется этим числом, MPEG-4 версия 1 предлагает возможность идентификации интеллектуальной собственности с помощью пары ключевых значений (например:”композитор“/”John Smith“). Кроме того, MPEG-4 предлагает стандартизованный интерфейс, который тесно интегрирован с системным слоем для людей, которые хотят использовать системы, контролирующие доступ к интеллектуальной собственности. С этим интерфейсом системы контроля прав собственности могут легко интегрироваться со стандартизованной частью декодера.
2. Основные функции в MPEG-4 версия 1
2.1. DMIF
DMIF поддерживает следующие функции:
Прозрачный интерфейс MPEG-4 DMIF- приложения независящий оттого, является ли партнер удаленным интерактивным или локальной запоминающей средой.
Контроль установления каналов FlexMux
Использование однородных сетей между интерактивными партнерами: IP, ATM, мобильные, PSTN, узкополосные ISDN.
2.2. Системы
Как объяснено выше, MPEG-4 определяет набор алгоритмов улучшенного сжатия для аудио и видео данных. Потоки данных (Elementary Streams, ES), которые являются результатом процесса кодирования, могут быть переданы или запомнены независимо. Они должны быть объединены так, чтобы на принимающей стороне возникла реальная мультимедийная презентация.
Системные части MPEG-4 обращаются к описаниям взаимодействий между аудио и видео компонентами, которые образуют сцену. Эти взаимодействия описаны на двух уровнях.
Двоичный формат для сцен BIFS (Binary Format for Scenes) описывает пространственно-временные отношения объектов на сцене. Зрители могут иметь возможность взаимодействия с объектами, например, перемещая их на сцене или изменяя свое положение точки наблюдения в 3D виртуальной среде. Описание сцены предоставляет широкий набор узлов для композиционных 2-D и 3-D операторов и графических примитивов.
На нижнем уровне, Дескрипторы объектов OD (Object Descriptors) определяют отношения между элементарными потоками, имеющими отношение к конкретному объекту (например, аудио- и видео-потоки участников видеоконференции). OD предоставляют также дополнительную информацию, такую как URL, необходимые для доступа к элементарным потокам, характеристики декодеров, нужных для их обработки, идентификация владельца авторских прав и пр.
Некоторые другие особенности работы системы MPEG-4:
Интерактивно, включая: взаимодействие клиент-сервер; общая модель событий или отслеживание действий пользователя; общая обработка событий и отслеживание взаимодействий объектов на сцене пользователем или с помощью событий, генерируемых на сцене.
Средство объединения большого числа потоков в один общий поток, включая временную информацию (мультиплексор FlexMux).
Средство для запоминания данных MPEG-4 в файле (файловый формат MPEG-4, ‘MP4’)
Интерфейсы для различных терминалов и сетей в виде Java API (MPEG-J)
Независимость транспортного уровня.
Текстовые презентации с международной лингвистической поддержкой, выбор шрифта и стиля, согласование времени и синхронизация.
Инициализация и непрерывное управление буферами приемных терминалов.
Идентификация временной привязки, синхронизация и механизмы восстановления.
Наборы данных, включающие идентификацию прав интеллектуальной собственности по отношению к медиа-объектам.
2.3. Аудио-система
MPEG-4 аудио предлагает широкий перечень приложений, которые покрывают область от понятной речи до высококачественного многоканального аудио, и от естественных до синтетических звуков. В частности, он поддерживает высокоэффективную презентацию аудио объектов, состоящих из:
Речь: Кодирование речи может производиться при скоростях обмена от 2 кбит/с до 24 кбит/с. Низкие скорости передачи, такие как 1.2 кбит/с, также возможны, когда разрешена переменная скорость кодирования. Для коммуникационных приложений возможны малые задержки. Когда используются средства HVXC, скорость и высота тона могут модифицироваться пользователем при воспроизведении. Если используются средства CELP, изменение скорости воспроизведения может быть реализовано с помощью дополнительного средства.
Синтезированная речь: TTS-кодировщики с масштабируемой скоростью в диапазоне от 200 бит/с до 1.2 кбит/с которые позволяют использовать текст или текст с интонационными параметрами (вариация тона, длительность фонемы, и т.д.), в качестве входных данных для генерации синтетической речи. Это включает следующие функции.
Синтез речи с использованием интонации оригинальной речи
Управление синхронизацией губ и фонемной информации.
Трюковые возможности: пауза, возобновление, переход вперед/назад.
Международный язык и поддержка диалектов для текста (т.е. можно сигнализировать в двоичном потоке, какой язык и диалект следует использовать)
Поддержка интернациональных символов для фонем.
Поддержка спецификации возраста, пола, темпа речи говорящего.
Поддержка передачи меток анимационных параметров лица FAP (facial animation parameter).
Общие аудио сигналы. Поддержка общей кодировки аудио потоков от низких скоростей до высококачественных. Рабочий диапазон начинается от 6 кбит/с при полосе ниже 4 кГц и распространяется до широковещательного качества передачи звукового сигнала для моно и многоканальных приложений.
Синтезированный звук: Поддержка синтезированного звука осуществляется декодером структурированного звука (Structured Audio Decoder), который позволяет использовать управление музыкальными инструментами с привлечением специального языка описания.
Синтетический звук с ограниченной сложностью: Реализуется структурируемым аудио декодером, который позволяет работать со стандартными волновыми форматами.
Примерами дополнительной функциональности является возможность управления скоростью обмена и масштабируемость в отношении потоков данных, полосы пропускания, вероятности ошибок, сложности, и т.д. как это определено ниже.
Возможность работы при изменении скорости передачи допускает изменение временного масштаба без изменения шага при выполнении процесса декодирования. Это может быть, например, использовано для реализации функции "быстро вперед" (поиск в базе данных) или для адаптации длины аудио-последовательности до заданного значения, и т.д.
Функция изменения шага позволяет варьировать шаг без изменения временного масштаба в процессе кодирования или декодирования. Это может быть использовано, например, для изменения голоса или для приложений типа караоке. Эта техника используется в методиках параметрического и структурированного кодирования звука.
Изменение скорости передачи допускает анализ потока данных с разбивкой на субпотоки меньшей скорости, которые могут быть декодированы в осмысленный сигнал. Анализ потока данных может осуществляться при передаче или в декодере.
Масштабируемость полосы пропускания является частным случаем масштабируемости скорости передачи данных, когда часть потока данных, представляющая часть частотного спектра может быть отброшена при передаче или декодировании.
Масштабируемость сложности кодировщика позволяет кодировщикам различной сложности генерировать корректные и осмысленные потоки данных.
Масштабируемость сложности декодера позволяет заданную скорость потока данных дешифровать посредством декодеров с различным уровнем сложности. Качество звука, вообще говоря, связано со сложностью используемого кодировщика и декодера.
Аудио эффекты предоставляют возможность обрабатывать декодированные аудио сигналы с полной точностью таймирования с целью достижения эффектов смешения, реверберации, создания объемного звучания, и т.д.
2.4. Видео-система
Стандарт MPEG-4 Видео допускает гибридное кодирование естественных (пиксельных) изображений и видео вместе с синтезированными сценами (генерированными на ЭВМ). Это, например, допускает виртуальное присутствие участников видеоконференций. Видео стандарт содержит в себе средства и алгоритмы, поддерживающие кодирование естественных (пиксельных) статических изображений и видео последовательностей, а также средства поддержки сжатия искусственных 2-D и 3-D графических геометрических параметров.
2.4.1. Поддерживаемые форматы
Следующие форматы и скорости передачи будут поддерживаться MPEG-4 версия 1:
• Скорости передачи: обычно между 5 кбит/с и 10 Mбит/с
• Форматы: progressive а также interlaced видео
• Разрешение: обычно от sub-QCIF вплоть до HDTV
2.4.2. Эффективность сжатия
Эффективное сжатие видео будет поддерживаться для всех скоростей обмена. Сюда входит компактное кодирование текстур с качеством, регулируемым от уровня “приемлемо” (для высоких сжатий данных) вплоть до “практически без потерь”.
Эффективное сжатие текстур для 2-D и 3-D сеток.
Произвольный доступ к видео, обеспечивающий такие функции как пауза, быстрый переход вперед или назад для записанного видео.
2.4.3. Функции, зависящие от содержимого (Content-Based)
Кодирование, учитывающее содержимое изображения и видео, позволяет разделить кодовое преобразование и реконструкцию видео-объектов произвольной формы.
Произвольный доступ к содержимому видео последовательности открывает возможность реализации функций пауза, быстрый переход вперед или назад для записанного видео-объектов.
Расширенное манипулирование видео последовательностями позволяет наложения естественный или синтетический текст, текстуры, изображения и видео. Примером может служить наложение текста на движущийся видео объект, когда текст движется синфазно с объектом.
2.4.4. Масштабируемость текстур изображений и видео
Масштабируемость сложности в кодировщике позволяет кодировщикам различной сложности генерировать корректный и осмысленный поток данных для данной текстуры, изображения или видео.
Масштабируемость сложности в декодере позволяет декодировать потоки текстур, изображений или виде декодерами различного уровня сложности. Достигаемое качество, вообще говоря, зависит от сложности используемого декодера. Это может подразумевать, что простые декодеры обрабатывают лишь часть информационного потока.
Пространственная масштабируемость позволяет декодерам обрабатывать некоторую часть общего потока, сформированного кодировщиком, при реконструкции и отображении текстур, изображений или видео-объектов при пониженном пространственном разрешении. Для текстур и статических изображений будет поддерживаться не более 11 уровней масштабируемости. Для видео последовательностей поддерживается не более трех уровней.
Временная масштабируемость позволяет декодерам обрабатывать некоторую часть общего потока, сформированного кодировщиком, при реконструкции и отображении видео при пониженном временном разрешении. Поддерживается не более трех уровней.
Масштабируемость качества позволяет разбить поток данных на несколько составляющих различной мощности так, чтобы комбинация этих составляющих могла при декодировании давать осмысленный сигнал. Разложение потока данных на составляющие может происходить при передаче или в декодере. Полученное качество, вообще говоря, зависит от числа компонент, используемых при реконструкции.
2.4.5. Кодирование формы и Alpha-представление
Кодирование формы будет поддерживаться, чтобы помочь описанию и композиции изображений и видео, а также видео-объектов произвольной формы. Приложения, которые используют двоичные побитовые карты изображения, служат для презентаций баз данных изображений, интерактивных игр, наблюдения, и анимации. Предлагаются эффективные методы кодирования двоичных форм. Двоичная альфа-маска определяет, принадлежит или нет пиксель объекту. Она может быть включена (‘on’) или выключена (‘off’).
‘Серая шкала’ или ‘alpha’ кодирование формы
Alpha- плоскость определяет прозрачность объекта, которая не обязательно является однородной. Многоуровневые alpha-карты часто используются для затенения различных слоев последовательности изображений. Другими приложениями, которые используют при работе с изображениями ассоциированные двоичные alpha-маски, являются презентации баз данных изображений, интерактивные игры, наблюдения, и анимация. Предлагаются методики, которые позволяют эффективно кодировать двоичные и альфа-плоскости с серой шкалой изображения. Двоичная альфа-маска определяет, принадлежит ли пиксель данному объекту. Маска с серой шкалой предоставляет возможность точно определить прозрачность каждого пикселя.
2.4.6. Надежность в средах, подверженных ошибкам
Устойчивость к ошибкам
будет поддерживаться, чтобы обеспечить доступ к изображениям и видео через широкий спектр систем памяти и передающих сред. Это включает в себя операции алгоритмов сжатия данных в среде, подверженной сбоям при низких скоростях передачи (т.e., меньше чем 64 Кбит/с).
2.4.7. Анимация лица
Часть стандарта, связанная с ‘анимацией лица’, позволяет посылать параметры, которые помогают специфицировать и анимировать синтезированные лица. Эти модели не являются сами частью стандарта MPEG-4, стандартизированы только параметры.
• Определение и кодирование анимационных параметров лица (модельно независимое):
• Позиции характерных деталей и их ориентация для определения сеток при анимации лица.
• Визуальные конфигурации губ, соответствующие фонемам речи.
• Определение и кодирование параметров описания лица (для калибровки модели):
• 3-D позиции характерных признаков (деталей)
• 3-D калибровочные сетки для анимации головы.
• Текстурная карта лица.
• Персональные характеристики.
• Кодирование лицевой текстуры.
2.4.8. Кодирование 2-D сеток с нечетко выраженной структурой
• Предсказание, базирующееся на сетке, и трансфигурация анимационных текстур
• 2-D-формализм с регулярной сеткой и отслеживанием перемещения анимированных объектов
• Предсказание перемещения и отложенная передача текстуры с динамическими сетками.
• Геометрическое сжатие для векторов перемещения:
• 2-D сжатие сетки с неявной структурой и реконструкция в декодере.
3. Главные функции в MPEG-4 версия 2
Версия 2 была зафиксирована в декабре 1999. Существующие средства и профайлы из версии 1 в версии 2 не заменены; новые возможности будут добавлены в MPEG-4 в форме новых профайлов. Системный слой версии 2 обладает обратной совместимостью с версией 1.
3.1. Системы
Версия 2 систем MPEG-4 расширяет версию 1, с тем, чтобы перекрыть такие области, как BIFS-функциональность и поддержка Java (MPEG-J). Версия 2 также специфицирует формат файлов для записи содержимого MPEG-4.
3.2. Видео-системы
3.2.1. Натуральное видео
Видео MPEG-4 версия 2 добавляет новые возможности в следующих областях:
увеличенная гибкость объектно-ориентированного масштабируемого кодирования,
улучшенная эффективность кодирования,
улучшенная стабильность временного разрешения при низкой задержке буферизации,
улучшенная устойчивость к ошибкам,
кодирование нескольких изображений: промежуточные или стереоскопические изображения будут поддерживаться на основе эффективного кодирования нескольких изображений или видео последовательностей. Частным примером может служить кодирование стереоскопического изображения или видео путем сокращения избыточности информации за счет малого различия изображений в стереопаре.
3.2.2. Анимация тела
В версии 2 к анимации лица, существовавшей в версии 1, добавлена анимация тела.
3.2.3. Кодирование 3-D полигональных сеток
Версия 2 MPEG-4 предоставляет набор средств для кодирования многогранных 3-D сеток. Многогранные сетки широко используются для представления 3-D объектов.
3.3. Звук
MPEG-4 Аудио версия 2 является расширением MPEG-4 Аудио версия 1. В новой версии добавлены новые средства и функции, все прежние возможности и функции сохранены. Версия 2 MPEG-4 Аудио предоставляет следующие возможности:
Улучшенная устойчивость к ошибкам
Кодирование аудио, которое сочетает в себе высокое качество и малые задержки
Масштабируемость зерна изображения (масштабируемость разрешения вплоть до 1 кбит/с на канал)
Параметрическое аудио- кодирование для манипулирования звуком при низких скоростях.
Сжатие пауз в разговоре (CELP) для дальнейшего понижения потока данных при кодировании голоса.
Параметрическое кодирование речи, устойчивое к ошибкам.
Пространственная ориентация – возможность реконструировать звуковое окружение, используя метод моделирования.
Обратный канал, который полезен для настройки кодирования или масштабируемого воспроизведения в реальном времени.
Низкая избыточность транспортного механизма MPEG-4 для звука
3.4. DMIF
Основные средства, вводимые DMIF версия 2 предоставляют поддержку (ограниченную) мобильных сетей и мониторирования QoS.
3.4.1. Поддержка мобильных сетей
Спецификация H.245 была расширена (H.245v6), чтобы добавить поддержку систем MPEG-4; спецификация DMIF предоставляет возможность работу с сигналами H.245. Мобильные терминалы могут теперь использоваться системами MPEG-4, такими как BIFS и OD-потоки.
3.4.2. Мониторирование QoS
DMIF V.2 вводит концепцию мониторирования качества обслуживания (QoS). Реализуемого в сети. Интерфейс DMIF-приложения был соответственно расширен. Модель допускает до трех различных режимов мониторирования QoS: непрерывное мониторирование, контроль специфических очередей, и наблюдение за нарушениями QoS
3.4.3. Пользовательские команды с ACK
Модель DMIF позволяет приложениям партнеров обмениваться любыми сообщениями пользователей (поток управляющих сообщений). В DMIF V2 добавлена поддержка сообщений-откликов.
3.4.4. Управление информацией уровня Sync MPEG-4
V.2 улучшает модель DMIF, чтобы позволить приложениям обмениваться прикладными данными со слоем DMIF. Это добавление было введено, чтобы сделать возможным в пределах модели обмен блоками протокольных данных уровня Sync. Это комбинация чисто медийных данных (PDU) и логической информации уровня Sync. Модель подтверждает, что в пределах существующего транспортного стека существуют средства, которые перекрываются с Sync-слоем систем MPEG-4. Это случай RTP и MPEG-2 элементарных потоков пакетов PES (Packetized Elementary Steams), а также MP4-атомов в файловом формате. Во всех таких случаях очевидной реализацией DMIF является преобразование информации уровня Sync, извлеченной из этих структур, а также из SL-PDU, в однородное логическое представление заголовка пакета уровня Sync. Как следствие, введены соответствующие параметры для DAI, с учетом обеспечения их семантической независимости от транспортного стека и приложения.
3.4.5. DAI-синтаксис на языке СИ
DMIF V. 2 вводит информативное дополнение, который предоставляет синтаксис C/C++ для прикладного интерфейса DMIF, как это рекомендуется API-синтаксисом.
4. Расширения MPEG-4 за пределы версии 2
MPEG в настоящее время работает с номером расширения версии 2, в визуальной и системной областях. Никаких работ по расширению MPEG-4 DMIF или Аудио за пределы версии 2 не проводились.
4.1. Визуальная область системы
В визуальной области подготавливается добавление следующих методик:
Масштабируемость пространственного разрешения (Fine Grain) находится на фазе голосования, с предложенными ‘Профайлами поточного видео’ (‘Advanced Simple’ и ‘Fine Grain Scalability’). Масштабируемость пространственного разрешения представляет собой средство, которое допускает небольшие изменения качества путем добавления или удаления слоев дополнительной информации. Это полезно во многих ситуациях, особенно для организации потоков, но также и для динамического (‘статического’) мультиплексирования предварительно закодированных данных в широковещательной среде.
Средства для использования MPEG-4 в студии. Для этих целей были приняты меры для сохранения некоторой формы совместимости с профайлами MPEG-2. В настоящее время, простой студийный профайл находится на фазе голосования (Simple Studio Profile), это профайл с кодированием только I-кадра при высоких скоростях передачи данных (несколько сот Мбит/с), который использует кодирование формы (shape coding). Ожидается добавление профайла ядра студии (Core Studio Profile) (с I и P кадрами).
Изучаются цифровые камеры. Это приложение потребует truly lossless coding, и not just the visually lossless that MPEG-4 has provided so far. A Preliminary Call for Proposals was issued in October 2000.
4.2. Системы
4.2.1. Advanced BIFS
Продвинутый BIFS предоставляет дополнительные узлы, которые могут быть использованы в графе сцены для мониторирования доступности и управляемости среды, такие как посылка команд серверу, продвинутый контроль воспроизведения, и так называемый EXTERNPROTO, узел, который обеспечивает дальнейшую совместимость с VRML, и который позволяет написание макросов, определяющих поведение объектов. Предусмотрено улучшенное сжатие данных BIFS, и в частности оптимальное сжатие для сеток и для массивов данных.
4.2.2. Текстуальный формат
Расширяемый текстовой формат MPEG-4 XMT ( Extensible Textual format) является базовым для представления MPEG-4 описаний сцен, использующих текстовой синтаксис. XMT позволяет авторам текста обмениваться его содержимым друг с другом. Консорциумом Web3D разработаны средства обеспечения совместимости с расширяемым X3D (Extensible 3D), и интеграционным языком синхронизованного мультимедиа SMIL (Synchronized Multimedia Integration Language) от консорциума W3C.
Формат XMT может быть изменен участниками SMIL, VRML, и MPEG-4. Формат может быть разобран и воспроизведен непосредственно участником W3C SMIL, преобразован в Web3D X3D и заново воспроизведен участником VRML, или компилирован в презентацию MPEG-4, такую как mp4, которая может быть затем воспроизведена участником MPEG-4. Ниже описано взаимодействие с XMT. Это описание содержит в себе MPEG-4, большую часть SMIL, масштабируемую векторную графику (Scalable Vector Graphics), X3D, а также текстуальное представление описания MPEG-7 (смотри http://www.cselt.it/mpeg, где имеется документация на стандартe MPEG-7).
XMT содержит два уровня текстуального синтаксиса и семантики: формат XMT-A и формат XMT-U.
XMT-A является версией MPEG-4, базирующейся на XML, содержащей субнабор X3D. В XMT-A содержится также расширение MPEG-4 для X3D, что бы работать с некоторыми специальными средствами MPEG-4. XMT-A предоставляет прямое соответствие между текстовым и двоичным форматами.
XMT-U является абстракцией средств MPEG-4 высокого уровня, базирующейся на W3C SMIL. XMT предоставляет по умолчанию соответствие U и A.
4.2.3. Улучшенная модель синхронизации
Продвинутая модель синхронизации (обычно называемая ‘FlexTime’) поддерживает синхронизацию объектов различного происхождения с возможно разной временной шкалой. Модель FlexTime специфицирует временную привязку, используя гибкую модель с временными ограничениями. В этой модели, медиа-объекты могут быть связаны друг с другом в временном графе с использованием таких ограничений как "CoStart", "CoEnd", или "Meet". И, кроме того, для того чтобы обеспечить определенную гибкость и адаптацию к этим ограничениям, каждый объект может иметь адаптируемую длительность с определенными предпочтениями для растяжения и сжатия, которые могут быть применены.
Модель FlexTime базируется на так называемой метафоре "пружины". Пружина имеет три ограничения: минимальная длина, менее которой она не сжимается, максимальная длина, при которой она может оборваться, и оптимальная длина, при которой она остается ни сжатой, ни растянутой. Следуя модели пружины, временные воспроизводимые медиа-объекты могут рассматриваться как пружины, с набором длительностей воспроизведения, соответствующих этим трем ограничениям пружины. Оптимальная длительность воспроизведения (оптимальная длина пружины) может рассматриваться как предпочтительный выбор автора для длительности воспроизведения медиа-объекта. Участник, где возможно, поддерживает длительность воспроизведения настолько близко к оптимальному значению, насколько позволяет презентация, но может выбрать любую длительность между минимальной и максимальной, как это специфицировал автор. Заметим, что поскольку растяжение или сжатие длительности в непрерывных средах, например, для видео, подразумевает соответствующее замедление или ускорение воспроизведения, для дискретных сред, таких как статическое изображение, сжатие или растяжение сопряжено в основном с модификацией периода рэндеринга.
5. Профайлы в MPEG-4
MPEG-4 предоставляет большой и богатый набор средств для кодирования аудио-визуальных объектов. Для того чтобы позволить эффективную реализацию стандарта, специфицированы субнаборы систем MPEG-4, средств видео и аудио, которые могут использоваться для специфических приложений. Эти субнаборы, называемые ‘профайлами’, ограничивают набор средств, которые может применить декодер. Для каждого из этих профайлов, устанавливается один или более уровней, ограничивающих вычислительную сложность. Подход сходен с MPEG-2, где большинство общеизвестных комбинаций профайл/уровень имеют вид ‘главный_профайл @главный_уровень’. Комбинация профайл@уровень позволяет:
• конфигуратору кодека реализовать только необходимый ему субнабор стандарта,
• проверку того, согласуются ли приборы MPEG-4 со стандартом.
Существуют профайлы для различных типов медиа содержимого (аудио, видео, и графика) и для описания сцен. MPEG не предписывает или рекомендует комбинации этих профайлов, но заботится о том, чтобы обеспечить хорошее согласование между различными областями.
5.1. Визуальные профайлы
Визуальная часть стандарта предоставляет профайлы для кодирования естественного, синтетического и гибридного типов изображений. Существует пять профайлов для естественного видео-материала:
1. Простой визуальный профайл обеспечивает эффективное, устойчивое к ошибкам кодирование прямоугольных видео объектов, подходящих для приложений мобильных сетей, таких как PCS и IMT2000.
2. Простой масштабируемый визуальный профайл добавляет поддержку кодирования временных и пространственных, масштабируемых объектов в простом визуальном профайле. Он полезен для приложений, которые обеспечивают услуги на более чем одном уровне качества, связанных с ограничениями скорости передачи данных или ресурсами декодера, такими как использование Интернет и программное декодирование.
3. Центральный визуальный профайл добавляет поддержку кодировки время-масштабируемых объектов произвольной формы в простой визуальный профайл. Он полезен для приложений, осуществляющих относительно простую интерактивность (приложения Интернет мультимедиа).
4. Главный визуальный профайл добавляет поддержку кодирования черезстрочных, полупрозрачных, и виртуальных объектов в центральном визуальном профайле. Он полезен для интерактивного широковещательного обмена (с качеством для развлечений) и для DVD-приложений.
5. N-битный визуальный профайл добавляет поддержку кодирования видео объектов, имеющих пиксельную глубину в диапазоне от 4 до 12 бит в главный визуальный профайл. Он удобен для использования в приложениях для наблюдения.
Профайлами для синтетических и синтетико-натуральных гибридных визуальных материалов являются:
6. Простой визуальный профайл для анимации лица (Simple Facial Animation) предоставляет простые средства анимации модели лица, удобные для таких приложений как аудио/видео презентации лиц с ухудшенным слухом.
7. Визуальный масштабируемый профайл для текстур (Scalable Texture Visual)
предоставляет пространственное масштабируемое кодирование статических объектов изображений (текстур), полезное для приложений, где нужны уровни масштабируемости, такие как установление соответствия между текстурой и объектами игр, а также работа с цифровыми фотокамерами высокого разрешения.
8. Визуальный профайл базовых анимированных 2-D текстур (Basic Animated 2-D Texture) предоставляет пространственную масштабируемоcть, SNR- масштабируемоcть, и анимацию, базирующуюся на сетках для статических объектов изображений (текстур), а также простую анимацию объектов лица.
9. Гибридный визуальный профайл комбинирует возможность декодировать масштабируемые объекты натурального видео произвольной формы (как в главном визуальном профайле) с возможностью декодировать несколько синтетических и гибридных объектов, включая анимационные статические объекты изображения. Он удобен для различных сложных мультимедиа приложений.
Версия 2 добавляет следующие профайлы для натурального видео:
10. Профайл ARTS (Advanced Real-Time Simple) предоставляет продвинутый метод кодирования прямоугольных видео объектов устойчивый к ошибкам, использующий обратный канал и улучшенную стабильность временного разрешения при минимальной задержке буферизации. Он удобен для кодирования в случае приложений реального времени, таких как видеотелефон, телеконференции и удаленное наблюдение.
11. Центральный масштабируемый профайл добавляет поддержку кодирования объектов произвольной формы с пространственным и временным масштабированием в центральный профайл. Главная особенность этого профайла является SNR, и пространственная и временная масштабируемость для областей и объектов, представляющих интерес. Он полезен для таких приложений как Интернет, мобильные сети и широковещание.
12. Профайл ACE (Advanced Coding Efficiency) улучшает эффективность кодирования для прямоугольных объектов и объектов произвольной формы. Он удобен для таких приложений как мобильный широковещательный прием, и другие приложения, где необходимо высокая эффективность кодирования.
Профайлы версии 2 для искусственного и синтетического/натурального гибридного визуального материала:
13. Продвинутый масштабируемый профайл текстур поддерживает декодирование текстур произвольной формы и статических изображений, включая масштабируемое кодирование формы, мозаичное заполнение и противостояние ошибкам. Он полезен для приложений, требующих быстрого произвольного доступа, а также нескольких уровней масштабируемости и кодирования статических объектов произвольной формы. Примерами таких приложений могут служить просмотр статических изображений в Интернет, а также считывание через Интернет изображений, полученных из цифровых фотоаппаратов с высоким разрешением.
14. Продвинутый центральный профайл комбинирует возможность декодирования видео объектов произвольной формы (как в центральном визуальном профайле) с возможностью декодирования масштабируемых статических объектов произвольной формы (как в продвинутом масштабируемом профайле текстур.) Он удобен для различных мультимедийных приложений, таких как интерактивная передача потоков мультиимедиа через Интернет.
15. Профайл простой анимации лица и тела является супернабором профайла простой анимации лица с добавлением анимации тела.
В последующих версиях будут добавлены следующие профайлы:
16. Продвинутый простой профайл выглядит как простой, здесь он содержит только прямоугольные объекты, но он имеет несколько дополнительных средств, которые делают его более эффективным: B-кадры, компенсация перемещения ? пикселя и компенсация общего перемещения.
17. Масштабируемый профайл тонкой гранулярности допускает большое число масштабных уровней – до 8 – так что качество доставки можно легко адаптировать к условиям передачи и декодирования. Он может использоваться с простым или продвинутым простым в качестве базового уровня.
18. Простой студийный профайл является профайлом с очень высоким качеством для применения в приложениях студийного редактирования. Он работает только с I-кадрами, но он действительно поддерживает произвольные формы и большое число alpha-каналов. Возможная скорость передачи достигает 2 Гбит/c.
19. Центральный студийный профайл добавляет P-кадры к простому студийному варианту (Simple Studio), делая его более эффективным, но требующим более сложной реализации.
5.2. Аудио профайлы
Определены четыре аудио-профайла в MPEG-4 V.1:
Разговорный профайл предоставляет HVXC, который является параметрическим кодером голоса, рассчитанным на очень низкие скорости передачи, CELP узкополосным/широкополосным кодером голоса, или интерфейсом текст-голос.
Профайл синтеза предоставляет собой синтез, использующий SAOL, волновые таблицы и интерфейс текст-голос для генерации звука и речи при очень низких скоростях передачи.
Масштабируемый профайл, супер набор профайла речи, удобен для масштабируемого кодирования речи и музыки для таких сетей, как Интернет и NADIB (Narrow band Audio DIgital Broadcasting). Диапазон скоростей передачи лежит в пределах от 6 кбит/с до 24 кбит/с, при ширине полосы 3.5 и 9 кГц.
Главный профайл является расширенным супер набором всех других профайлов, содержащий средства для синтетического и естественного аудио.
Еще четыре профайла добавлено в MPEG-4 V.2:
Профайл высококачественного аудио содержит кодировщик голоса CELP и простой кодировщик AAC, содержащий систему долгосрочного предсказания. Масштабируемое кодирование может быть выполнено с помощью AAC масштабируемого объектного типа. Опционно, может использоваться синтаксис потока, устойчивый к ошибкам (ER).
Профайл аудио с низкой задержкой (Low Delay Audio) содержит HVXC и CELP кодировщики голоса (опционно использующие синтаксис ER), AAC-кодеры с низкой задержкой и интерфейс текст-голос TTSI.
Профайл натурального аудио содержит все средства кодирования натурального аудио, доступные в MPEG-4.
Профайл межсетевого мобильного аудио (Mobile Audio Internetworking)
содержит AAC масштабируемые объектные типы с малой задержкой, включая TwinVQ и BSAC. Этот профайл предназначен для расширения телекоммуникационных приложений за счет алгоритмов не-MPEG кодирования речи с возможностями высококачественного аудио кодирования.
5.3. Профайлы графики
Профайлы графики определяют, какие графические и текстовые элементы могут использоваться в данной сцене. Эти профайлы определены в системной части стандарта:
Простой 2-D графический профайл предоставляется только для графических элементов средства BIFS, которым необходимо разместить один или более визуальных объектов в сцене.
Полный 2-D графический профайл предоставляет двухмерные графические функции и supports такие возможности как произвольная двухмерная графика и текст, если требуется, в сочетании с визуальными объектами.
3. Полный графический профайл предоставляет продвинутые графические элементы, такие как сетки и экструзии и позволяет формировать содержимое со сложным освещением. Полный графический профайл делает возможными такие приложения, как сложные виртуальные миры, которые выглядят достаточно реально.
3D аудио графический профайл имеет противоречивое на первый взгляд название, в действительности это не так. Этот профайл не предлагает визуального рэндеринга, а предоставляет графические средства для определения акустических свойств сцены (геометрия, акустическое поглощение, диффузия, прозрачность материала). Этот профайл используется для приложений, которые осуществляют пространственное представление аудио сигналов в среде сцены.
5.4. Графические профайлы сцены
Графические профайлы сцены (или профайлы описания сцены), определенные в системной части стандарта, допускают аудио-визуальные сцены только аудио, 2-мерным, 3-мерным или смешанным 2-D/3-D содержимым.
Графический профайл аудио сцены предоставляется для набора графических элементов сцены BIFS для применение исключительно в аудио приложениях. Графический профайл аудио сцены поддерживает приложения типа широковещательного аудио.
Графический профайл простой 2-D сцены предоставляется только для графических элементов BIFS, которым необходимо разместить один или более аудио-визуальных объектов на сцене. Графический профайл простой 2-D сцены допускает презентации аудио-визуального материала, допускающий коррекцию, но без интерактивных возможностей. Графический профайл простой 2-D сцены поддерживает приложения типа широковещательного телевидения.
Графический профайл полной 2- D сцены предоставляется для всех элементов описания 2-D сцены средства BIFS. Он поддерживает такие возможности, как 2-D преобразования и alpha-сглаживание. Графический профайл полной 2-D сцены делает возможными 2-D приложения, которые требуют широкой интерактивности.
Графический профайл полной сцены предоставляет полный набор графических элементов сцены средства BIFS. Графический профайл полной 2-D сцены сделает возможными приложения типа динамического виртуального 3-D мира и игр.
Графический профайл 3D аудио сцены предоставляет средства трехмерного позиционирования звука в отношении с акустическими параметрами сцены или ее атрибутами, характеризующими восприятие. Пользователь может взаимодействовать со сценой путем изменения позиции источника звука, посредством изменения свойств помещения или перемещая место слушателя. Этот профайл предназначен для использования исключительно аудио-приложениями.
5.5. Профайлы MPEG-J
Существуют два профайла MPEG-J: персональный и главный:
1. Персональный – небольшой пакет для персональных приборов.
Персональный профайл обращается к ряду приборов, включая мобильные и портативные аппараты. Примерами таких приборов могут быть видео микрофоны, PDA, персональные игровые устройства. Этот профайл включает в себя следующие пакеты MPEG-J API:
a) Сеть
b) Сцена
c) Ресурс
1.
Главный – включает все MPEG-J API.
Главный
профайл обращается к ряду приборов, включая средства развлечения. Примерами таких приборов могут служить набор динамиков, компьютерные системы мультимедиа и т.д. Он является супер набором персонального профайла. Помимо пакетов персонального профайла, этот профайл содержит следующие пакеты MPEG-J API:
a) Декодер
b) Функции декодера
c) Секционный фильтр и сервисная информация
5.6. Профайл дескриптора объекта
Профайл описания объекта включает в себя следующие средства:
Средство описания объекта (OD)
Средство слоя Sync (SL)
Средство информационного содержимого объекта (OCI)
Средство управления и защиты интеллектуальной собственности (IPMP)
В настоящее время определен только один профайл, который включает все эти средства. В контексте слоев для этого профайла могут быть определены некоторые ограничения, например, допуск только одной временной шкалы.
6. Верификационное тестирование: проверка работы MPEG
MPEG выполняет верификационные тесты для проверки того, предоставляет ли стандарт то, что должно быть. Результаты испытаний можно найти на базовой странице MPEG: http://www.cselt.it/mpeg/quality_tests.htm
6.1. Видео
6.1.1. Тесты эффективности кодирования
6.1.1.1. Низкие и средние скорости передачи бит (версия 1)
При испытаниях для низкой и средней скорости передачи, рассматривались последовательности кадров, которые следуют стандарту MPEG-1. (MPEG-2 будет идентичным для прогрессивных последовательностей за исключением того, что MPEG-1 немного более эффективен, так как имеет несколько меньшую избыточность заголовков). Тест использует типовую тестовую последовательность для разрешений CIF и QCIF, закодированный с идентичными условиями по скорости передачи для MPEG-1 и MPEG-4. Тест был выполнен для низких скоростей от 40 кбит/с до 768 кбит/с.
Тесты эффективности кодирования показывают полное превосходство MPEG-4 перед MPEG-1 как на низкой, так и на средней скорости передачи.
6.1.1.2. Кодирование, базирующееся на содержимом (версия 1)
Верификационные тесты для кодирования, базирующегося на содержимом, сравнивают визуальное качество кодирования object-based и frame-based. Главным соображением было гарантировать, чтобы object-based кодирование можно было поддерживать без ухудшения визуального качества. Содержимое теста было выбрано так, чтобы перекрыть широкий спектр условий моделирования, включая видео сегменты с различными типами движения и сложностью кодирования. Кроме того, условия теста были выбраны так, чтобы перекрыть низкие скорости передачи в диапазоне от 256 кбит/с до 384 кбит/с, и высокие скорости передачи в диапазоне от 512кбит/с до 1.15 Мбит/с. Результаты тестов ясно продемонстрировали, что объектно-ориентированная функциональность, предоставляемая MPEG-4, не имеет избыточности или потерь визуального качества, по сравнению с кодированием frame-based. Не существует статистически значимого различия между вариантами object-based и frame-based.
6.1.1.3. Профайл продвинутой эффективности кодирования ACE (Advanced Coding Efficiency) (версия 2)
Формальные верификационные тесты профайла ACE (Advanced Coding Efficiency) были выполнены с целью проверки, улучшают ли эффективность кодирования три новые средства версии 2, включенные в визуальный ACE профайл MPEG-4 версии 2 (компенсация общего перемещения, компенсация перемещения на четверть пикселя и адаптированное к форме преобразование DCT), по сравнению с версией 1. Тесты исследуют поведение ACE профайла и главного визуального профайла MPEG-4 версия 1 в режимах object-based и frame-based при низкой скорости передачи, frame-based при высокой скорости передачи. Полученные результаты показывают преимущество ACE профайла перед главным профайлом. Ниже приведены некоторые детали сопоставления работы этих профайлов:
Для объектно-ориентированного случая, качество, предоставляемое профайлом ACE при 256 кбит/с равно качеству, обеспечиваемому главным профайлом при скорости 384 кбит/с.
Для кадр-ориентированного случая, качество, предоставляемое профайлом ACE при 128 кбит/с и 256 кбит/с равно качеству, обеспечиваемому главным профайлом при скорости 256 кбит/с и 384 кбит/с соответственно.
Для кадр-ориентированного случая при высоких скоростях передачи, качество, предоставляемое профайлом ACE при 768 кбит/с равно качеству, обеспечиваемому главным профайлом при 1024 кбит/с.
При интерпретации этих результатов, нужно заметить, что главный профайл MPEG-4 более эффективен, чем MPEG-1 и MPEG-2.
6.1.2. Тесты устойчивости к ошибкам
6.1.2.1. Простой профайл (версия 1)
Устойчивость видео к ошибкам в простом профайле MPEG-4 была оценена в ходе тестов, которые симулируют видео MPEG-4, выполненных при скоростях между 32 кбит/с и 384 кбит/с. Испытания произведены при BER < 10-3, и средней длине блока ошибок около 10мс. Тестовая методология базировалась на непрерывной оценке качества в течение 3 минут.
Результаты показывают, что в среднем качество видео, полученное для мобильного канала, является высоким, что воздействие ошибок в видео MPEG-4 остается локальным, и что качество быстро восстанавливается по завершении блока ошибок.
6.1.2.2. Простой продвинутый профайл реального времени ARTS (Advanced Real-Time Simple) (версия 2)
Устойчивость видео к ошибкам в MPEG-4 профайле ARTS была оценена в ходе тестов, аналогичных описанным выше, при скоростях между 32 кбит/с и 128 кбит/с. В этом случае, остаточный уровень ошибок достигал 10-3, а средняя длительность блока ошибок была около 10 мс или 1 мс.
Результаты испытаний показывают превосходство профайла ARTS над простым
профайлом для всех параметров исследования. Профайл ARTS предпочтительнее простого по времени восстановления после прохождения блока ошибок.
6.1.3. Тестирование стабильности временного разрешения
6.1.3.1. Простой продвинутый профайл реального времени ARTS (Advanced Real-Time Simple) (версия 2)
В данном тесте исследовались характеристики видео кодека, использующего технику преобразования с динамическим разрешением, которая адаптирует разрешение видео материала к обстоятельствам в реальном времени. Материал активной сцены кодировался при скоростях 64 кбит/с, 96 кбит/с и 128 кбит/с. Результаты показывают, что при 64 кбит/с, он превосходит простой профайл, работающий при 96 кбит/с, а при 96 кбит/с, визуальное качество эквивалентно полученному для простого профайла при 128 кбит/с.
6.1.4. Проверки масштабируемости
6.1.4.1. Простой масштабируемый профайл (версия 1)
Тест масштабируемости для простого масштабируемого профайла был создан для проверки того, что качество, обеспечиваемое средством временной масштабируемости в простом, масштабируемом профайле, сравненное с качеством, предоставляемым одноуровневым кодированием в простом профайле, и с качеством, обеспечиваемым в простом профайле. В этом тесте используются 5 последовательностей с 4 комбинациями скоростей передачи:
a) 24 кбит/с для базового слоя и 40 кбит/с для улучшенного слоя.
b) 32 кбит/с для обоих слоев.
c) 64 кбит/с для базового слоя и 64 кбит/с для улучшенного слоя.
d) 128 кбит/с для обоих слоев.
Формальные верификационные тесты показали, что при всех условиях, кодирование с временной масштабируемостью в простом масштабируемом профайле демонстрирует то же или несколько худшее качество, чем достижимое при использовании однослойного кодирования в простом профайле. Далее, очевидно, что кодирование с временной масштабируемостью в простом масштабируемом профайле обеспечивает лучшее качество, чем симулкастное (одновременная передача по радио и телевидению или передача несколькими потоками с разной скоростью) кодирование в простом профайле для тех же условий.
6.1.4.2. Центральный профайл (core profile версия 1)
Верификационный тест был создан для оценки характеристик средств временной масштабируемости MPEG-4 видео в центральном профайле (Core Profile).
Тестирование было выполнено с использованием метода "Single Stimulus". Тест создавался с использованием 45 субъектов из двух различных лабораторий. Результаты испытаний показывают, что качество последовательностей, закодированных с привлечением средств временного масштабирования сопоставимы по качеству с вариантом без масштабирования. Очевидно также, что средство временного масштабирования в центральном профайле обеспечивает лучшее качество при равных условиях, чем симулкастное кодирование в центральном профайле.
6.2. Звук
Аудио-технология MPEG-4 состоит из большого числа средств кодирования. Верификационные тесты выполнялись в основном для небольшого набора средств кодирования, которые имеет сходные области использования, чтобы их можно было сравнивать. Так как сжатие является критическим параметром в MPEG, сравнение производилось при сходных скоростях обмена.
Характеристика восприятия
5
Неощутимо
4
Ощутимо, но не раздражающе
3
Слегка раздражающе
2
Раздражающе
1
Весьма плохо
Первоначальной целью тестов является получение субъективного уровня качества средства кодирования, работающего при заданной скорости обмена. Большинство аудио тестов представляют результаты в виде субъективной шкалы оценки качества. Это непрерывная шкала с максимальным значением 5 баллов, как это показано в табличке выше.
Работа различных средств кодирования MPEG-4 представлена в таблице ниже. Для лучшей оценки свойств технологии MPEG-4 в тесты были включены несколько кодировщиков от MPEG-2 и ITU-T и их оценка также включены в таблицу. Результаты из различных тестов не следует сравнивать.
| Средство кодирования | #каналов |
Общая скорость передачи [кбит/c] |
Типовое значение субъективного качества |
| AAC | 5 | 320 | 4.6 |
| 1995 обратно совместимый MPEG-2 слой II | 5 | 640 | 4.6 |
| AAC | 2 | 128 | 4.8 |
| AAC | 2 | 96 | 4.4 |
| MPEG-2 слой II | 2 | 192 | 4.3 |
| MPEG-2 слой III | 2 | 128 | 4.1 |
| AAC | 1 | 24 | 4.2 |
| Масштабируемый: CELP база и улучшение AAC | 1 | 6 base, 18 enh. | 3.7 |
| Масштабируемый: Twin VQ база и улучшение AAC | 1 | 6 base, 18 enh. | 3.6 |
| AAC | 1 | 18 | 3.2 |
| G.723 | 1 | 6.3 | 2.8 |
| Широкополосный CELP | 1 | 18.2 | 2.3 |
| BSAC | 2 | 96 | 4.4 |
| BSAC | 2 | 80 | 3.7 |
| BSAC | 2 | 64 | 3.0 |
| AAC – LD (однопроходная задержка 20 мсек) | 1 | 64 | 4.4 |
| G.722 | 1 | 32 | 4.2 |
| AAC – LD (однопроходная задержка 30 мсек) | 1 | 32 | 3.4 |
| Узкополосный CELP | 1 | 6 | 2.5 |
| Twin VQ | 1 | 6 | 1.8 |
| HILN | 1 | 16 | 2.8 |
| HILN | 1 | 6 | 1.8 |
/p> При кодировании 5-канального материала при 64 кбит/с/канал (320 кбит/с) Продвинутое кодирование аудио AAC ( Advanced Audio Coding) главного профайла было оценено как имеющее "неотличимое качество" (относительно оригинала) согласно определению EBU. При кодировании 2- канального материала при 128 кбит/с как AAC главного профайла так и AAC профайла низкой сложности были оценены как имеющие "неотличимое качество" (относительно оригинала) согласно определению EBU.
Два масштабируемых кодировщика, CELP-база с улучшение AAC, и TwinVQ база с улучшением AAC, работают лучше чем AAC "multicast", работающий при скорости передачи уровня улучшения, но не так хороши как кодировщик AAC, работающий при полной скорости передачи.
Широкополосное кодирующее средство CELP демонстрирует прекрасные характеристики только для голоса.
Побитовое арифметическое кодирование (BSAC) предоставляет весьма малые шаги масштабирования. На верху диапазона масштабирования это кодирование не имеет штрафных балов по отношению к AAC, однако в нижней части диапазона оно уступает односкоростной AAC.
Узкополосный CELP, TwinVQ и индивидуальные гармонические линии и шум (HILN) все могут обеспечить очень высокое сжатие сигнала.
Средства противодействия ошибкам (ER) обеспечивают эквивалентно хорошую устойчивость к ошибкам в широком диапазоне условий канальных ошибок, и делают это с достаточно малой избыточностью по скорости передачи.
7. Промышленный форум MPEG-4
Промышленный форум MPEG-4 является бесприбыльной организацией, имеющей следующую цель: дальнейшее принятие стандарта MPEG-4, путем установления MPEG-4 в качестве принятого и широко используемого стандарта среди разработчиков приложений, сервис провайдеров, создателей материалов и конечных пользователей. Далее следует не исчерпывающая выдержка из устава M4IF о планах работы:
Целью M4IF будет: продвижение MPEG-4, предоставление информации об MPEG-4, предоставление средств MPEG-4 или указание мест, где эти данные можно получить, формирование единого представления об MPEG-4.
Цели реализуются через открытое международное сотрудничество всех заинтересованных участников.
Деятельность M4IF не преследует целей получения финансовой прибыли.
Любая корпорация и частная фирма, государственный орган или интернациональная организация, поддерживающая цели M4IF может являться членом форума.
Члены не обязаны внедрять или использовать специфические технологические стандарты или рекомендации в качестве следствия своего членства в M4IF.
Не существует каких-либо лицензионных требований, налагаемых членством в M4IF, и M4IF не налагает лицензионных ограничений на использование технологии MPEG-4.
Начальный членский взнос равен 2,000 $ в год.
M4IF имеет свою WEB-страницу: http://www.m4if.org
Деятельность M4IF начинается там, где кончается активность MPEG. Сюда входят позиции, с которыми MPEG не может иметь дело, например, из-за правил ISO, таких как патентная чистота.
8. Детальное техническое описание MPEG-4 DMIF и систем
Рис. 3 показывает как потоки, приходящие из сети (или запоминающего устройства), как потоки TransMux, демультиплексируются в потоки FlexMux и передаются соответствующим демультиплексорам FlexMux, которые извлекают элементарные потоки. Элементарные потоки (ES) анализируются и передаются соответствующим декодерам. Декодирование преобразует данные в AV объект и выполняет необходимые операции для реконструкции исходного объекта AV, готового для рэндеринга на соответствующем аппарате. Аудио и визуальные объекты представлены в их кодированной форме, которая описана в разделах 10 и 9 соответственно. Реконструированный объект AV делается доступным для слоя композиции при рэндеринга сцены. Декодированные AVO, вместе с данными описания сцены, используются для композиции сцены, как это описано автором. Пользователь может расширить возможности, допущенные автором, взаимодействовать со сценой, которая отображается.
Рис. 3. Главные компоненты терминала MPEG-4 (принимающая сторона)
8.1. DMIF
DMIF (Delivery Multimedia Integration Framework) является протоколом сессии для управления мультимедийными потоками поверх общих средств доставки данных. В принципе это имеет много общего с FTP. Единственное (существенное) отличие заключается в том, что FTP предоставляет данные, DMIF предоставляет указатели, где получить данные (streamed).
Когда работает FTP, первым действием, которое производит протокол, является установление сессии с удаленным партнером. Далее, выбираются файлы, и FTP посылает запрос об их передаче, партнер FTP пересылает файл через отдельное, сформированное для этой цели соединение.
Аналогично, когда работает DMIF, первым действием, которое он выполняет, является установление сессии с удаленным партнером. Позднее, выбираются потоки и DMIF посылает запрос, передать их, партер DMIF в отклике пришлет указатель на соединение, где будут проходить потоки, и затем также устанавливает соединение.
По сравнению с FTP, DMIF является системой и протоколом. Функциональность, предоставляемая DMIF, определяется интерфейсом, называемым DAI (DMIF-Application Interface), и реализуется через протокольные сообщения. Эти протокольные сообщения для разных сетей могут отличаться.
При конструировании DMIF рассматривается и качество обслуживания (QoS), а DAI позволяет пользователю DMIF специфицировать требования для нужного потока. Проверка выполнения требований оставляется на усмотрение конкретной реализации DMIF. Спецификация DMIF предоставляет советы, как решать такие задачи на новом типе сети, таком, например, как Интернет.
Интерфейс DAI используется для доступа к широковещательному материалу и локальным файлам, это означает, что определен один, универсальный интерфейс для доступа к мультимедийному материалу для большого числа технологий доставки.
Как следствие, уместно заявить, что интегрирующая система DMIF покрывает три главные технологии, интерактивную сетевую технику, широковещательную технологию и работу с дисками; это показано на рис. 4 ниже.
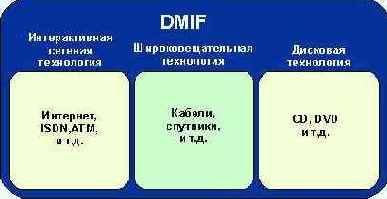
Рис. 4. DMIF осуществляет интеграцию доставки для трех основных технологий
Архитектура DMIF такова, что приложения, которые для коммуникаций базируются на DMIF, не должны быть чувствительны к нижележащему методу коммуникаций. Реализация DMIF заботится о деталях технологии доставки, предоставляя простой интерфейс к приложению.
На рис. 5 представлена указанная выше концепция. Приложение получает доступ к данным через интерфейс приложения DMIF, вне зависимости от того, откуда получены данные: от широковещательного источника, локальной памяти или от удаленного сервера. Во всех сценариях локальное приложение только взаимодействует через универсальный интерфейс (DAI). Различные варианты DMIF будут затем транслировать запросы локального приложения в специфические сообщения, которые должны быть доставлены удаленному приложению, учитывая особенности используемых технологий доставки. Аналогично, данные, поступающие на терминал (из удаленного сервера, широковещательных сетей или локальных файлов) доставляются локальному приложению через DAI.
Специализированные версии DMIF подключаются приложением апосредовано, чтобы управлять различными специфическими технологиями доставки данных, это, однако прозрачно для приложения, которое взаимодействует только с одним "DMIF фильтром". Этот фильтр отвечает за управление конкретным примитивом DAI в нужный момент.
Концептуально, "настоящее" удаленное приложение доступное через сеть, например, через IP или ATM, ничем не отличается от эмулируемого удаленного приложения, получающего материал от широковещательного источника или с диска. В последнем случае, однако, сообщения, которыми обмениваются партнеры, должны быть определены, чтобы обеспечить совместимость (это сигнальные сообщения DMIF). В последнем случае, с другой стороны, интерфейсы между двумя партнерами DMIF и эмулируемым удаленным приложением являются внутренними по отношению реализации и не должны рассматриваться в этой спецификации. Заметим, что для сценариев получения данных широковещательно и из локальной памяти, рисунок показывает цепочку "Локальный DMIF", "Удаленный DMIF (эмулированный)" и "Удаленное приложение (эмулированное)". Эта цепочка представляет концептуальную модель и не должна отражаться в практической реализации (на рисунке она представлена закрашенной областью).
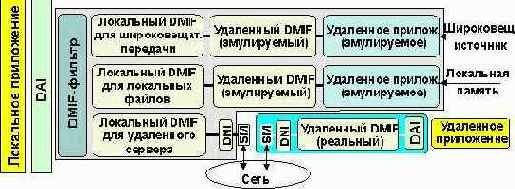
Рис. 5. Архитектура коммуникаций DMIF
При рассмотрении сценариев с широковещанием и локальной памятью предполагается, что эмулируемое удаленное приложение знает, как данные доставлены/запомнены. Это подразумевает знание типа приложения, с которым осуществляется взаимодействие. В случае MPEG-4, это в действительности предполагает знание идентификатора элементарного потока, дескриптора первого объекта, названия услуги. Таким образом, в то время как уровень DMIF концептуально не знает ничего о приложении, которое поддерживает, в частном случае работы DMIF с широковещанием и локальной памятью это утверждение не вполне корректно из-за присутствия эмулированного удаленного приложения (которое, с точки зрения локального приложения является частью слоя DMIF).
При рассмотрении сценария удаленного взаимодействия, слой DMIF ничего не знает о приложении. Введен дополнительный интерфейс DNI (DMIF-Network Interface), который служит для подчеркивания того, какого рода информацией должны обмениваться партнеры DMIF. Дополнительные модули SM (Signaling mapping) служат для установления соответствия между примитивами DNI и сигнальными сообщениями, используемыми в конкретной сети. Заметим, что примитивы DNI специфицированы для информационных целей, и интерфейс DNI в настоящей реализации может отсутствовать.
DMIF допускает одновременное присутствие одного или более интерфейсов DMIF, каждый из которых предназначен для определенной технологии доставки данных. Одно приложение может активировать несколько технологий доставки.
8.1.1. Вычислительная модель DMIF
Когда приложение запрашивает активацию услуги, оно использует сервисный примитив DAI, и формирует соответствующую сессию. Реализация DMIF устанавливает контакт с соответствующим партнером (который концептуально может быть либо удаленным, либо эмулируемым локальным партнером) и формирует вместе с ним сетевую сессию. В случае широковещательного и локального сценариев, способ формирования и управления сессией находится вне зоны ответственности данного документа. В случае интерактивного сценария с удаленным сервером, DMIF использует свой сигнальный механизм для формирования и управления сессией, например, сигнальный механизм ATM. Приложения партнеров используют эту сессию для установления соединения, которое служит для передачи прикладных данных, например, элементарных потоков MPEG-4.
Когда приложению нужен канал, оно использует примитивы канала DAI, DMIF транслирует эти запросы в запросы соединения, которые являются специфическими для конкретных запросов сетевых реализаций. В случае сценариев широковещания и локальной памяти, метод установления соединения и последующего управления находится за пределами регламентаций MPEG-4. В случае сетевого сценария напротив, DMIF использует свой сигнальный механизм для формирования и управления соединением. Это соединение используется приложением для целей доставки данных.
На рис. 6 предоставлена схема активации верхнего уровня и начало обмена данными. Этот процесс включает в себя четыре этапа:
Приложение-инициатор посылает запрос активизации услуги своему локальному слою DMIF – коммуникационное соединение между приложением-инициатором и его локальным партнером DMIF устанавливается в контрольной плоскости (1)
Партнер-инициатор DMIF запускает сетевую сессию с партнером-адресатом DMIF - коммуникационное соединение партнером-инициатором DMIF и партнером-адресатом DMIF устанавливается в контрольной плоскости (2).
Партнер-адресат DMIF идентифицирует приложение-адресат и переадресует запрос активации услуги - коммуникационное соединение между партнером-адресатом DMIF и приложением-адресатом устанавливается в контрольной плоскости (3)
Приложения партнеров создают каналы (запросы передаются через коммуникационные пути 1, 2 и 3). Результирующие каналы в пользовательской плоскости (4) используются приложениями для реального информационного обмена. DMIF вовлечена во все четыре этапа.
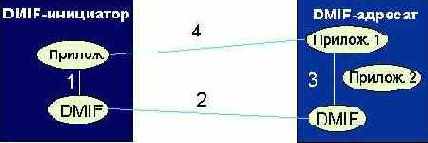
Рис. 6. Вычислительная модель DMIF
Слой DMIF автоматически определяет, предполагается ли предоставление данной услуги удаленным сервером в конкретной сети, например, в IP, или ATM, широковещательной сетью, или устройством локальной памяти: выбор основывается на адресной информации партнера, предоставляемой приложением в качестве части URL, переданной DAI.
8.2. Демультиплексирование, синхронизация и описание потоков данных
Отдельные элементарные потоки должны быть выделены на уровне доставки из входных данных некоторого сетевого соединения или из локального устройства памяти. Каждое сетевое соединение или файл в модели системы MPEG-4 рассматривается как канал TransMux. Демультиплексирование выполняется частично или полностью слоями вне области ответственности MPEG-4. Единственным демультиплексирующим средством, определенным MPEG-4, является FlexMux, которое может опционно использоваться для снижения задержки, получения низкой избыточности мультиплексирования и для экономии сетевых ресурсов.
Для целей интегрирования MPEG-4 в системную среду, интерфейс приложения DMIF является точкой, где можно получить доступ к элементарным потокам, как к потокам sync. DMIF является интерфейсом для реализации функций, недоступных в MPEG. Управляющая часть интерфейса рассмотрена в разделе DMIF.
MPEG-4 определяет модель системного декодера. Это позволяет точно описать операции терминала, не делая ненужных предположений о деталях практической реализации. Это важно для того, чтобы дать свободу разработчикам терминалов MPEG-4 и декодирующих приборов. Это оборудование включает в себя широкий диапазон аппаратов от телевизионных приемников, которые не имеют возможности взаимодействовать с отправителем, до ЭВМ, которые полноценный двунаправленный коммуникационный канал. Некоторые приборы будут получать потоки MPEG-4 через изохронные сети, в то время как другие будут использовать для обмена информацией MPEG-4 асинхронные средства (например, Интернет). Модель системного декодера предоставляет общие принципы, на которых могут базироваться все реализации терминалов MPEG-4.
Спецификация модели буфера и синхронизации является существенной для кодирующих приборов, которые могут не знать заранее, тип терминала и метод получения кодированного потока данных. Спецификация MPEG-4 делает возможным для кодирующего прибора проинформировать декодер о ресурсных требованиях, может оказаться невозможным для приемника реагировать на сообщение передатчика.
8.2.1. Демультиплексирование
Демультиплексирование происходит на уровне доставки, который включает в себя слои TransMux и DMIF. Извлечение входящих информационных потоков из сетевого соединения или из памяти включает в себя два этапа. Во-первых, каналы должны быть найдены и открыты. Это требует наличия некоторого объекта, который осуществляет транспортный контроль и устанавливает соответствие между транспортными каналами и специальными элементарными потоками. Таблица карты таких потоков связывает каждый поток с ChannelAssociationTag (канальной меткой), которая служит указателем для канала, через который идет поток. Определение ChannelAssociationTags для реального транспортного канала, а также управление сессией и каналами осуществляется DMIF-частью стандарта MPEG-4.
Во-вторых, входящие потоки должны быть соответствующим образом демультиплексированы, чтобы восстановить SL-потоки пакетов от нижележащих каналов (входящих в принимающий терминал). В интерактивных приложениях, соответствующий узел мультиплексирования переправляет данные в вышерасположенные каналы (исходящие из принимающего терминала).
Базовый термин ‘TransMux Layer’ используется, чтобы абстрагироваться от нижележащей функциональности – существующей или будущей, которая пригодна для транспортировки потоков данных MPEG-4. Заметим, что этот уровень не определен в контексте MPEG-4. Примерами могут служить транспортный поток MPEG-2, H.223, ATM AAL 2, IP/UDP. Предполагается, что слой TransMux предоставляет защиту и средства мультиплексирования, этот уровень обеспечивает определенный класс QoS. Средства безопасности включают в себя защиту от ошибок и детектирование ошибок, удобное для данной сети или устройств памяти.
В любом конкретном сценарии приложения используется один или более специфических TransMux. Каждый демультиплексор TransMux предоставляет доступ к каналам TransMux. Требования на информационный интерфейс доступа к каналу TransMux те же, что и для всех интерфейсов TransMux. Они включают необходимость надежного детектирования ошибок, доставки, если возможно, ошибочных данных с приемлемой индикацией ошибок и кадрирование поля данных, которое может включать потоки либо SL либо FlexMux. Эти требования реализованы в интерфейсе TransMux (системная часть стандарта MPEG-4). Адаптация потоков SL должна быть специфицирована для каждого стека протоколов.
Средство FlexMux специфицировано MPEG для того, чтобы опционно предоставить гибкий метод, имеющий малую избыточность и задержку для переукладки данных в тех случаях, когда ниже лежащие протоколы не поддерживают это. Средство FlexMux само по себе недостаточно устойчиво по отношению к ошибкам и может либо использоваться в каналах TransMux с высоким QoS, либо для объединения элементарных потоков, которые достаточно устойчивы к ошибкам. FlexMux требует надежного детектирования ошибок. Эти требования реализованы в информационных примитивах прикладного интерфейса DMIF, который определяет доступ к данным в индивидуальных транспортных каналах. Демультиплексор FlexMux выделяет SL-потоки из потоков FlexMux.
8.2.2. Синхронизация и описание элементарных потоков
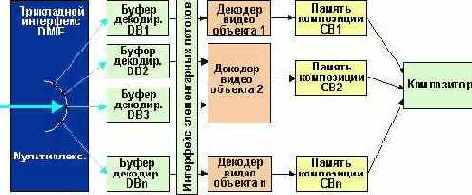
Рис. 7. Архитектура буферов модели системного декодера
Слой sync имеет минимальный набор средств для проверки согласованности, чтобы передать временную информацию. Каждый пакет состоит из блока доступа или фрагмента блока доступа. Эти снабженные временными метками блоки образуют единственную семантическую структуру элементарных потоков, которые видны на этом уровне. Временные метки используются для передачи номинального времени декодирования. Уровень sync требует надежного детектирования ошибок и кадрирования каждого индивидуального пакета нижележащего слоя. Как осуществляется доступ к данным для слоя сжатия, определяется интерфейсом элементарных потоков, описание которого можно найти в системной части стандарта MPEG-4. Слой sync извлекает элементарные потоки из потоков SL.
Чтобы с элементарные потоки могли взаимодействовать с медиа-объектами в пределах сцены, используются дескрипторы объектов. Дескрипторы объектов передают информацию о номере и свойствах элементарных потоков, которые ассоциированы с конкретными медиа-объектами. Сами дескрипторы объектов передаются в одном или более элементарных потоков, так как допускается добавление и удаление потоков (и объектов) в процессе сессии MPEG-4. Для того чтобы обеспечить синхронизацию, такие модификации помечаются временными метками. Потоки дескрипторов объектов могут рассматриваться как описание потоковых ресурсов презентации. Аналогично, описание сцены также передается как элементарный поток, позволяя модифицировать пространственно-временную картину презентации со временем.
8.2.3. Управление буфером
Чтобы предсказать, как декодер будет себя вести, когда он декодирует различные элементарные потоки данных, которые образуют сессию MPEG-4, модель системного декодера (Systems Decoder Mode) позволяет кодировщику специфицировать и мониторировать минимальные буферные ресурсы, необходимые для декодирования сессии. Требуемые буферные ресурсы передаются декодеру в объектных дескрипторах во время установления сессии MPEG-4, так что декодер может решить, может ли он участвовать в этой сессии.
При управлении конечным буферным пространством модель позволяет отправителю, например, передавать данные, не привязанные к реальному времени, досрочно, если имеется достаточно места в буфере со стороны приемника. Запомненные данные будут доступны в любое время, позволяя использовать для информации реального времени при необходимости большие ресурсы канала.
8.2.4. Идентификация времени
Для операции реального времени, модель синхронизации is assumed in which the end-to-end delay from the signal output from an encoder to the signal input to a decoder is constant. Более того, передаваемые потоки данных должны содержать времязадающую информацию в явном или неявном виде. Существует два типа временной информации. Первый тип используется для передачи частоты часов кодировщика, или временной шкалы, декодеру. Второй, состоящий из временных меток, присоединенных к закодированным AV данным, содержит желательное время декодирование для блоков доступа или композиции, а также время истечения применимости композиционных блоков. Эта информация передается в заголовках SL-пакетов сформированных в слое sync. С этой временной информацией, интервалы в пределах картинки и частота стробирования аудио может подстраиваться в декодере, чтобы соответствовать интервалам частоте стробирования на стороне кодировщика.
Различные медиа-объекты могут кодироваться кодировщиками с различными временными шкалами, и даже с небольшим отличием времязадающих частот. Всегда возможно установить соответствие между этими временными шкалами. В этом случае, однако, никакая реализация приемного терминала не может избежать случайного повторения или потери AV-данных, из-за временного наезда (относительное растяжение или сжатие временных шкал).
Хотя допускается работа систем без какой-либо временной информации, определение модели буферизации в этом случае невозможно.
8.3. Улучшенная модель синхронизации (FlexTime)
Модель FlexTime (Advanced Synchronization Model) расширяет традиционную модель хронирования MPEG-4, чтобы разрешить синхронизацию большого числа потоков и объектов, таких как видео, аудио, текст, графика, или даже программы, которые могут иметь разное происхождение.
Традиционная модель синхронизации MPEG- 4 первоначально была сконструирована для широковещательных приложений, где синхронизация между блоками доступа осуществляется через "жесткие" временные метки и эталонные часы. В то время как этот механизм предоставляет точную синхронизацию внутри потока, он терпит неудачу при синхронизации потоков, приходящих из разных источников (и возможно с разными эталонными часами) как это имеет место в случае большинства приложений Интернет и в более сложных широковещательных приложениях.
Модель FlexTime позволяет разработчику материала специфицировать простые временные соотношения для выбранных объектов MPEG-4, таких как "CoStart," "CoEnd," и "Meet." Автор материала может также специфицировать ограничения гибкости для объектов MPEG-4, как если бы объекты были растяжимыми пружинами. Это позволяет синхронизовать большое число объектов согласно специфицированным временным соотношениям.
Наибольшую эффективность внедрение этой техники может дать в случае приложений Интернет, где нужно синхронизовать большое число источников на стороне клиента.
8.3.1. Гибкая длительность
В среде с ненадежной доставкой может так случиться, что доставка определенного элементарного потока или частей потока, может заметно задержаться относительно требуемого времени воспроизведения.
Для того чтобы понизить чувствительность к задержке времени доставки, модель FlexTime основывается на так называемой метафоре "пружины", смотри раздел 4.2.3.
Следуя модели пружины, элементарные потоки, или фрагменты потоков, рассматриваются как пружины, каждый с тремя 3 ограничениями. Оптимальная длина (длительность воспроизведения потока) может рассматриваться как подсказка получателю, когда возможны варианты. Заметим, что при растяжении или сжатии длительности непрерывной среды, такой как видео, подразумевает соответствующее замедление или ускорение воспроизведения, когда элементарный поток состоит из статических картинок. В этом случае растяжение или сжатие предполагает удержание изображения на экране в течение большего или меньшего времени.
8.3.2. Относительное время начала и конца
Два или более элементарных потоков или потоков сегментов могут быть синхронизованы друг относительно друга, путем определения того, что они начинаются ("CoStart") или кончаются ("CoEnd") в одно и то же время или завершение одного совпадает с началом другого ("Meet").
Важно заметить, что существует два класса объектов MPEG-4. Синхронизация и рэндеринг объекта MPEG-4, который использует элементарный поток, такого как видео, не определяется одним потоком, но также соответствующими узлами BIFS и их синхронизацией. В то время как синхронизация и рэндеринг объекта MPEG-4, который не использует поток, такой как текст или прямоугольник, определяется только соответствующими узлами BIFS и их синхронизацией.
Модель FlexTime позволяет автору материала выражать синхронизацию объектов MPEG-4 с потоками или сегментами потоков, путем установления временных соотношений между ними.
Временные соотношения (или относительные временные метки) могут рассматриваться как "функциональные" временные метки, которые используются при воспроизведении. Таким образом, действующее лицо FlexTime может:
Компенсировать различные сетевые задержки с помощью поддержки синхронизованной задержки прибытия потока, прежде чем действующее лицо начнет рэндеринг/воспроизведение ассоциированного с ним узла.
Компенсировать различные сетевые разбросы задержки путем поддержки синхронизованного ожидания прибытия сегмента потока.
Синхронизовать большое число медиа/BIFS-узлов с некоторым медиа потоком неизвестной длины или неуправляемым временем прибытия.
Синхронизовать модификации BIFS (например, модификации полей сцены) при наличии большого числа узлов/потоков, когда некоторые потоки имеют неизвестную длину или неуправляемое время прибытия.
Замедлять или ускорять рэндеринг/воспроизведение частей потоков, чтобы компенсировать ситуации не синхронности, вызванные неизвестной длиной, неуправляемым временем прибытия или его вариацией.
8.3.3. Поддержка FlexTime в MPEG-4
Модель FlexTime поддерживается в MPEG-4 двумя узлами: TemporalTransform и TemporalGroup, и дескриптором: SegmentDescriptor. Узел TemporalTransform специфицирует временные свойства объекта MPEG-4, который нуждается в синхронизации. Узел TemporalGroup специфицирует временные соотношения между объектами, которые представлены узлами TemporalTransform, а SegmentDescriptor идентифицирует доли потока, которые могут быть синхронизованы.
8.3.3.1. Узел TemporalTransform
TemporalTransform
поддерживает синхронизацию узлов в пределах сцены с медиа потоком, или его сегментом, и поддерживает гибкое преобразование ко времени сцены. Этот группирующий узел может гибко поддерживать замедление, ускорение, замораживание или смещение временной шкалы сцены для рэндеринга узлов содержащихся в ней. Его дочернее поле может содержать список узлов типа SF3Dnode, а узел может влиять на замедление, ускорение, замораживание или смещение временной шкалы композитора, когда он осуществляет рэндеринг дочерних узлов, которые преобразованы этим узлом. Кроме того, этот узел имеет поле url, которое может ссылаться на элементарный поток или его сегмент и в этом случае, узел воздействует на временную шкалу потока, указанного в ссылке.
8.3.3.2. Узел TemporalGroup
Узел TemporalGroup
специфицирует временное соотношение между заданным числом TemporalTransforms, чтобы выровнять временные шкалы узлов, в графе сцены. Временная настройка среды с целью удовлетворения ограничений и обеспечения гибкости осуществляется на уровне sync. TemporalGroup может рассматривать временные свойства его дочек и когда все они готовы, а временные ограничения выполнены, может быть дано разрешение на их воспроизведение.
8.3.3. Дескриптор сегмента (SegmentDescriptor)
Массив SegmentDescriptors добавляется в качестве составного элемента в ES_Descriptor. SegmentDescriptor идентифицирует и помечает сегмент потока, так что отдельные сегменты потока могут быть адресуемы с помощью их полей url в узле TemporalTansform.
8.3.4. Модель исполнения
Временное декодирование и настройка часов медиа потоков в соответствии с временными метками является функцией слоя sync. Модель FlexTime требует небольшого изменения модели буферизации MPEG-4 и декодирования. Декодирование может быть задержано у клиента, по отношению к стандартному времени.
Модель буферов для flextime может быть специфицировано следующим образом: "В любое время от момента, соответствующего его DTS, вплоть до границы времени, заданной Flextime, AU немедленно декодируется и удаляется из буфера." Так как точное время удаления из буфера декодирования AU может варьироваться, нельзя быть уверенным, что оно будет удалено раньше наихудшего времени (максимальная задержка для медиа-потока). Используя наихудшее время, а не время, заданное DTS, буфер декодирования может управляться и не так, как предписывается MPEG-4.
8.4. Описание синтаксиса
MPEG-4 определяет язык синтаксического описания чтобы характеризовать точный двоичный синтаксис для двоичных потоков, несущих медиа-объекты и для потоков с информацией описания сцены. Это уход от прошлого подхода MPEG, использовавшего язык псевдо C. Новый язык является расширением C++, и используется для интегрированного описания синтаксического представления объектов и классов медиа-объектов и сцен. Это предоставляет удобный и универсальный способ описания синтаксиса. Программные средства могут использоваться для обработки синтаксического описания и генерации необходимого кода для программ, которые выполняют верификацию.
8.5. Двоичный формат описания сцены BIFS (Binary Format for Scene description)
Кроме обеспечения поддержки кодирования индивидуальных объектов, MPEG-4 предоставляет также возможность создать набор таких объектов в рамках сцены. Необходимая информация композиции образует описание сцены, которая кодируется и передается вместе с медиа-объектами. Начиная с VRML (Virtual reality Modeling Language), MPEG разработал двоичный язык описания сцены, названный BIFS. BIFS расшифровывается как BInary Format for Scenes.
Для того чтобы облегчить авторскую разработку, а также создание средств манипулирования и взаимодействия, описания сцены кодируются независимо от потоков, имеющих отношение в примитивным медиа-объектам. Специальные меры предпринимаются для идентификации параметров, относящихся к описанию сцены. Это делается путем дифференциации параметров, которые используются для улучшения эффективности кодирования объектов (например, векторы перемещения в алгоритмах видео-кодирования), а также те, которые используются в качестве модификаторов объекта (например, положение объекта на сцене). Так как MPEG-4 должен допускать модификацию последнего набора параметров без необходимости декодировать самих примитивных медиа-объектов, эти параметры помещаются в описание сцены, а не в примитивные медиа-объекты. Следующий список предлагает некоторые примеры информации, представленные в описании сцены.
Как объекты группируются
. Сцена MPEG-4 следует иерархической структуре, которая может быть представлена как ориентированный граф без циклов. Каждый узел графа является медиа-объектом, как показано на рис. 8. Три структуры не обязательно являются статическими; атрибуты узла (например, позиционирующие параметры) могут быть изменены, в то время как узлы могут добавляться, замещаться, или удаляться.
Рис. 8. Возможная логическая структура сцены
Как объекты позиционируются в пространстве и времени
. В модели MPEG-4, аудиовизуальные объекты имеют протяженность в пространстве и во времени. Каждый медиа-объект имеет локальную координатную систему. Локальная координатная система объекта является той, в которой объект имеет фиксированное пространственно-временное положение и шкалу. Локальная координатная система служит в качестве указателя для манипулирования медиа-объектом в пространстве и во времени. Медиа-объекты позиционируются на сцене путем спецификации координатного преобразования из локальной координатной системы объекта в глобальную систему.
Выбор значения атрибута. И
ндивидуальные медиа-объекты и узлы описания сцены демонстрируют набор параметров композиционному слою через который может частично контролироваться их поведение. Среди примеров можно назвать понижение звука (pitch), цвет для синтетических объектов, активация или дезактивация информации улучшения для масштабируемого кодирования и т.д.
Другие преобразования медиа-объектов
. Как упомянуто выше, структура описания сцены и семантика узла подвержены сильному влиянию VRML, включая его модель событий. Это предоставляет MPEG-4 очень богатый набор операторов конструирования сцены, включая графические примитивы, которые могут использоваться для построения сложных сцен.
8.5.1. Продвинутый формат BIFS
BIFS версия 2 (продвинутый BIFS) включает в себя следующие новые возможности:
Моделирование продвинутой звуковой среды в интерактивных виртуальных сценах, где в реальном времени вычисляются такие характеристики как рефлексы в комнате, реверберация, допплеровсеие эффекты и перегораживание звука объектами, появляющимися между источником и слушателем. Моделирование направленности источника звука позволяет осуществлять эффективное включение звуковых источников в 3-D сцены.
Анимация тела с использованием на уровне декодера модели тела по умолчанию или загружаемой модели. Анимация тела осуществляется путем посылки анимационных параметров в общем потоке данных.
Применение хроматических ключей, которые служат для формирования формы маски и значения прозрачности для изображения или видео последовательности.
Включение иерархических 3-D сеток в BIFS сцен.
Установление соответствия интерактивных команд и медийных узлов. Команды передаются серверу через обратный канал для соответстующей обработки.
PROTOs и EXTERNPROTOs >
8.6. Взаимодействие с пользователем
MPEG-4 позволяет пользователю взаимодействие с отображаемым материалом. Это взаимодействие может быть разделено на две главные категории: взаимодействие на стороне клиента и взаимодействие на стороне сервера. Взаимодействие на стороне клиента включает в себя манипуляцию материалом, который обрабатывается локально на терминале конечного пользователя. В частности, модификация атрибута узла описания сцены, например, изменения положение объекта, делание его видимым или невидимым, изменение размера шрифта узла синтетического текста и т.д., может быть выполнено путем трансляции событий пользователя. Событием пользователя может быть нажатие клавиши мыши или команда, введенная с клавиатуры.
Другие формы взаимодействия на стороне клиента требуют поддержки со стороны синтаксиса описания сцены и должны быть специфицированы в стандарте. Использование структуры событий VRML предоставляет богатую модель, на основании которой разработчики могут создать вполне интерактивный материал.
Взаимодействие на стороне сервера включает в себя манипуляцию материалом на стороне отправителя в результате действий пользователя. Это, разумеется, требует наличия обратного канала.
8.7. IPR идентификация и защита
MPEG-4 предоставляет механизмы для защиты прав интеллектуальной собственности (IPR). Это достигается путем предоставления кодированных медиа-объектов с опционным набором данных идентификационной интеллектуальной собственности IPI (Intellectual Property Identification), несущим информацию о содержимом, типе содержимого и о владельцах прав на данный материал. Набор данных, если он имеется, является частью дескриптора элементарного потока, который описывает поточную информацию, ассоциированную с медиа-объектом. Номер набора данных, который ассоциируется с каждым медиа-объектом достаточно гибок; другие медиа-объекты могут использовать тот же набор. Предоставление наборов данных позволяет внедрить механизм отслеживания, мониторинга, выставления счетов и защиты от копирования.
Каждое широкодиапазонное приложение MPEG-4 имеет набор требований относящихся к защите информации, с которой оно работает. Эти приложения могут иметь разные требования по безопасности. Для некоторых приложений, пользователи обмениваются информацией, которая не имеет собственной ценности, но которая, тем не менее, должна быть защищена, чтобы защитить права собственности. Для других приложений, где управляемая информация для ее создателя или дистрибьютора имеет большую ценность, требуется управление более высокого уровня и более надежные механизмы защиты. Подразумевается, что дизайн структуры IPMP должен учитывать сложность стандарта MPEG-4 и разнообразие его применений. Эта структура IPMP оставляет детали системы IPMP на усмотрение разработчиков. Необходимые уровень и тип управления и защиты зависят от ценности материала, комплексности, и сложности, связанных с этим материалом бизнес моделей.
Данный подход позволяет конструировать и использовать системы IPMP специфичные для доменов (IPMP-S). В то время как MPEG-4 не стандартизует сами системы IPMP, он стандартизует интерфейс IPMP MPEG-4. Этот интерфейс состоит из IPMP-дескрипторов (IPMP-Ds) и элементарных потоков IPMP (IPMP-ES).
IPMP-Ds и IPMP-ESs предоставляют коммуникационный механизм взаимодействия систем IPMP и терминала MPEG-4. Определенные приложения могут требовать нескольких систем IPMP. Когда объекты MPEG-4 требуют управления и защиты, они имеют IPMP-D, ассоциированные с ними. Эти IPMP-Ds указывают на то, какие системы IPMP следует использовать и предоставляют информацию о том, как защищать получаемый материал. (Смотри рис. 9).
Кроме предоставления владельцам интеллектуальной собственности возможности управления и защиты их прав, MPEG-4 предлагает механизм идентификации этих прав с помощью набора данных IPI (Intellectual Property Identification Data Set). Эта информация может использоваться системами IPMP в качестве входного потока процесса управления и защиты.
Рис. 9. Интерфейсы IPMP в системе MPEG-4
8.8. Информация содержимого объекта
MPEG-4 позволяет подсоединять к объектам информацию об их материале. Пользователи стандарта могут использовать этот поток данных ‘OCI’ (Object Content Information) для передачи текстовой информации совместно с материалом MPEG-4.
8.9. Формат файлов MPEG-4
Формат файла MP4 сконструирован так, чтобы информация MPEG-4 имела легко адаптируемый формат, который облегчает обмены, управление, редактирование и представление медиа-материала. Презентация может быть локальной по отношению к системе осуществляющей этот процесс, или осуществляемой через сеть или другой поточный механизм доставки (TransMux). Формат файлов сконструирован так, чтобы не зависеть от конкретного типа протокола доставки, и в тоже время эффективно поддерживать саму доставку. Конструкция основана формате QuickTime® компании Apple Computer Inc.
Формат файла MP4 сформирован из объектно-ориентированных структур, называемых атомами. Каждый атом идентифицируется тэгом и длиной. Большинство атомов описывают иерархию метаданных, несущих в себе такую информацию как индексные точки, длительности и указатели на медиа данные. Это собрание атомов содержится в атоме, называемом ‘кино атом’. Сами медиа-данные располагаются где-то; они могут быть в файле MP4, содержащемся в одном или более ‘mdat’, в медийных информационных атомах или размещаться вне файла MP4 с доступом через URL.
Мета данные в файле в сочетании с гибкой записью медийных данных в память позволяют формату MP4 поддерживать редактирование, локальное воспроизведение и обмен, и тем самым удовлетворять требованиям интермедиа MPEG4.
8.10. MPEG-J
MPEG-J является программной системой a programmatic system (в противоположность параметрической системе MPEG-4 версия 1), которая специфицирует API для кросс-операций медиа-проигрывателей MPEG-4 с программами на Java. Комбинируя среду MPEG-4 и безопасный исполнительный код, разработчики материала могут реализовать комплексный контроль и механизмы обработки их медиа в рамках аудио-визуальной сессии. Блок-схема плеера MPEG-J в среде системного плеера MPEG-4 показана на рис. 10. Нижняя половинка этого рисунка отображает системный параметрический плеер MPEG-4, называемый также средство презентации (ДП). Субсистема MPEG-J, контролирующая ДП, называется средством приложения (Application Engine), показана в верхней половине рис. 10.
Приложение Java доставляется в качестве отдельного элементарного потока, поступающего на терминал MPEG-4. Оно будет передано MPEG-J, откуда программа MPEG-J будет иметь доступ к различным компонентам и данным плеера MPEG-4. MPEG-J не поддерживает загружаемых декодеров.
По выше указанной причине, группой был определен набор API с различными областями применения. Задачей API является обеспечение доступа к графу сцены: рассмотрение графа, изменение узлов и их полей, и добавление и удаление узлов графа. Менеджер ресурсов API используется для управления исполнением: он обеспечивает централизованное средство управления ресурсами. API терминальных возможностей (Terminal Capability) используется, когда исполнение программы зависит от конфигурации терминала и его возможностей, как статических (которые не меняются во время исполнения) так и динамических. API медийных декодеров (Media Decoders) позволяет контролировать декодеры, которые имеются в терминале. Сетевое API предлагает способ взаимодействия с сетью, являясь прикладным интерфейсом MPEG-4 DMIF.
Рис. 10. Положение интерфейсов в архитектуре MPEG-J
9. Детальное техническое описание визуальной секции MPEG-4
Визуальные объекты могут иметь искусственное или натуральное происхождение.
9.1. Приложения видео-стандарта MPEG-4
MPEG-4 видео предлагает технологию, которая перекрывает широкий диапазон существующих и будущих приложений. Низкие скорости передачи и кодирование устойчивое к ошибкам позволяет осуществлять надежную связь через радио-каналы с ограниченной полосой, что полезно, например, для мобильной видеотелефонии и космической связи. При высоких скоростях обмена, имеются средства, позволяющие передачу и запоминание высококачественного видео на студийном уровне.
Главной областью приложений является интерактивное WEB-видео. Уже продемонстрированы программы, которые осуществляют живое видео MPEG-4. Средства двоичного кодирования и работы с видео-объектами с серой шкалой цветов должны быть интегрированы с текстом и графикой.
MPEG-4 видео было уже использовано для кодирования видеозапись, выполняемую с ручной видео-камеры. Эта форма приложения становится все популярнее из-за простоты переноса на WEB-страницу, и может также применяться и в случае работы со статичными изображениями и текстурами. Рынок игр является еще одной областью работы приложений MPEG-4 видео, статических текстур, интерактивности.
9.2. Натуральные текстуры, изображения и видео
Средства для естественного видео в визуальном стандарте MPEG-4 предоставляют стандартные технологии, позволяющие эффективно запоминать, передавать и манипулировать текстурами, изображениями и видео данными для мультимедийной среды. Эти средства позволяют декодировать и представлять атомные блоки изображений и видео, называемые "видео объектами" (VO). Примером VO может быть говорящий человек (без фона), который может быть также создан из других AVO (аудио-визуальный объект) в процессе формирования сцены. Обычные прямоугольные изображения образуют специальный случай таких объектов.
Для того чтобы достичь этой широкой цели функции различных приложений объединяются. Следовательно, визуальная часть стандарта MPEG-4 предоставляет решения в форме средств и алгоритмов для:
Эффективного сжатия изображений и видео
Эффективного сжатия текстур для их отображения на 2-D и 3-D сетки
Эффективного сжатия для 2-D сеток
Эффективного сжатия потоков, характеризующих изменяющуюся со временем геометрию (анимация сеток)
Эффективного произвольного доступа ко всем типам визуальных объектов
Расширенной манипуляции изображениями и видео последовательностей
Кодирования, зависящего от содержимого изображений и видео
Масштабируемости текстур, изображений и видео
Пространственная, временная и качественная масштабируемость
Обеспечения устойчивости к ошибкам в среде предрасположенной к сбоям
9.3. Синтетические объекты
Синтетические объекты образуют субнабор большого класса компьютерной графики, для начала будут рассмотрены следующие синтетические визуальные объекты:
• Параметрические описания
a) синтетического лица и тела (анимация тела в версии 2)
b) Кодирование статических и динамических сеток Static и Dynamic Mesh Coding with texture mapping
• Кодирование текстуры для приложений, зависимых от вида
9.4. Масштабируемое кодирование видео-объектов
Существует несколько масштабируемых схем кодирования в визуальном MPEG-4: пространственная масштабируемость, временная масштабируемость и объектно-ориентированная пространственная масштабируемость. Пространственная масштабируемость поддерживает изменяющееся качество текстуры (SNR и пространственное разрешение). Объектно-ориентированная пространственная масштабируемость расширяет 'обычные' типы масштабируемости в направлении объектов произвольной формы, так что ее можно использовать в сочетании с другими объектно-ориентированными возможностями. Таким образом, может быть достигнута очень гибкая масштабируемость. Это делает возможным при воспроизведении динамически улучшать SNR, пространственное разрешение, точность воспроизведения формы, и т.д., только для объектов, представляющих интерес, или для определенной области.
9.5. Устойчивость в среде, предрасположенной к ошибкам
Разработанная в MPEG новая методика, названная NEWPRED ('new prediction' – новое предсказание), предоставляет быстрое восстановление после ошибок в приложениях реального времени. Она использует канал от декодера к кодировщику. Кодировщик переключает эталонные кадры, приспосабливаясь к условиям возникновения ошибок в сети. Методика NEWPRED обеспечивает высокую эффективность кодирования. Она была проверена в условиях высоких потоков ошибок:
• Короткие всплески ошибок в беспроводных сетях (BER= 10-3, длительность всплеска 1мс)
• Потери пакетов в Интернет (вероятность потери = 5%)
9.6. Улучшенная стабильность временного разрешения с низкой задержкой буферизации
Еще одной новой методикой является DRC (Dynamic Resolution Conversion), которая стабилизирует задержку буферизации при передаче путем минимизации разброса числа кодовых бит VOP на выходе. Предотвращается отбрасывание больших пакетов, а кодировщик может контролировать временное разрешение даже в высоко активных сценах.
9.7. Кодирование текстур и статические изображения
Следующие три новых средства кодирования текстур и статических изображений предлагается в версии V.2:
Wavelet tiling (деление на зоны) позволяет делить изображение на несколько составных частей, каждая из которых кодируется независимо. Это означает, что большие изображения могут кодироваться/декодироваться в условиях достаточно низких требований к памяти, и что произвольный доступ к декодеру существенно улучшен.
Масштабируемое кодирование формы позволяет кодировать текстуры произвольной формы и статические изображения с привлечением масштабируемости. Используя это средство, декодер может преобразовать изображение произвольной формы с любым желательным разрешением. Это средство позволяет приложению использовать объектно-ориентированную пространственную и качественную масштабируемость одновременно.
Средство противодействия ошибкам добавляет новые возможности восстановления при ошибках. Используя пакетирование и технику сегментных маркеров, оно значительно улучшает устойчивость к ошибкам приложений, таких как передача изображения через мобильные каналы или Интернет.
Упомянутые выше средства используются в двух новых ‘продвинутых масштабируемых текстурах’ и продвинутом центральном профайле (advanced core profile).
9.8. Кодирование нескольких видов и большого числа вспомогательных компонентов
В MPEG-4 видео версии 1 поддерживается до одного альфа-канала на видео канальный слой и определены три типа формы. Все три типа формы, т.е. двоичная форма, постоянная форма и форма с серой шкалой, допускают прозрачность видео объекта. При таком определении MPEG-4 не может эффективно поддерживать такие вещи как многовидовые видео объекты (Multiview Video Objects). В версии 2 введено применение множественных альфа-каналов для передачи вспомогательных компонент.
Базовой идеей является то, что форма с серой шкалой не является единственной для описания прозрачности видео объекта, но может быть определена в более общем виде. Форма с серой шкалой может, например, представлять:
Форму прозрачности
Форму несоразмерности (Disparity shape) для многовидовых видео объектов (горизонтальных и вертикальных)
Форму глубины (Depth shape) (получаемую посредством лазерного дальномера или при анализе различия)
Инфракрасные или другие вторичные текстуры
Все альфа-каналы могут кодироваться с помощью средств кодирования формы, т.е. средства двоичного кодирования формы и средства кодирования формы с серой шкалой, которые используют DCT с компенсаций перемещения, и обычно имеют ту же форму и разрешение, что и текстура видео объекта.
В качестве примера использования множественных вспомогательных компонентов в случае формы несоразмерности для многовидовых видео объектов описаны ниже.
Общим принципом является ограничение числа пикселей, которые следует кодировать при анализе соответствия между конкретными видами объекта, доступными на стороне кодировщика. Все области объекта, которые видны со стороны более чем одной камеры, кодируются только один раз с максимально возможным разрешением. Соотношения несоразмерности могут быть оценены из исходных видов, чтобы реконструировать все области, которые были исключены из кодирования путем использования проекции со скомпенсированной несоразмерностью. Один или два вспомогательных компонентов могут быть выделены, чтобы кодировать карты несоразмерности, указывающие на соответствие между пикселями различных видов.
Мы назначаем области, которые используются для кодирования данных от каждой конкретной камеры как "области интереса" (AOI). Эти AOI могут теперь быть просто определены как видео объекты MPEG-4, и закодированы с их ассоциированными значениями несоразмерности. Из-за возможного отражения объектов в различных видах, а также из-за отклонений цветов или различия экспозиций для разных камер, границы между областями, которые нужно реконструировать на основе разных исходных видов могут оказаться видимыми. Чтобы решить эту проблему, необходимо предварительно обработать пиксели вблизи границ AOI, так чтобы осуществить плавный переход путем интерполяции пикселей из различных смежных видов в пределах переходной области.
Чтобы реконструировать различные точки зрения из текстуры, проекция поверхности с компенсации несоразмерности формируется из текстурных данных в пределах конкретных AOI, с привлечением карты несоразмерностей, полученной из вспомогательной компоненты, декодированной из видео потока MPEG-4. Каждая AOI обрабатывается независимо, а затем проекции изображений ото всех AOI собираются для получения окончательного вида видео объекта с заданной точки зрения. Эта процедура может быть выполнена для системы с двумя камерами с параллельной установкой, но может быть распространена на случай с несколькими камерами со сходящимися оптическими осями.
9.8.1. Анимация лица
‘Лицевой анимационный объект’ может использоваться для представления анимированного лица. Форма, текстура и выражения лица управляются параметрами определения лица FDP (Facial Definition Parameters) и/или параметрами анимации лица FAP (Facial Animation Parameters). Объект лица содержит базовый вид лица с нейтральным выражением. Это лицо может уже отображено. Оно может также получить немедленно анимационные параметры из потока данных, который осуществит анимацию лица: выражения, речь и т.д. Между тем, могут быть посланы параметры определения, которые изменять облик лица от некоторого базового к заданному лицу со своей собственной формой и (опционно) текстурой. Если это желательно, через набор FDP можно загрузить полную модель лица.
Анимация лица в MPEG-4 версии 1 предназначена для высоко эффективного кодирования параметров анимации, которые могут управлять неограниченным числом моделей лица. Сами модели не являются нормативными, хотя существуют средства описания характеристик модели. Кадровое и временное-DCT кодирование большой коллекции FAP может использоваться для точной артикуляции.
Двоичный формат систем для сцены BIFS (Systems Binary Format for Scenes), предоставляет возможности поддержки анимации лица, когда нужны обычные модели и интерпретации FAP:
Параметры определения лица FDP (Face Definition Parameters) в BIFS (модельные данные являются загружаемыми, чтобы конфигурировать базовую модель лица, запомненную в терминале до д екодирования FAP, или инсталлировать специфическую модель лица в начале сессии вместе с информацией о том, как анимировать лицо).
Таблица анимации лица FAT (Face Animation Table) в рамках FDP ( загружаемые таблицы функционального соответствия между приходящими FAP и будущими контрольными точками сетки лица. Это дает кусочно-линейную карту входящих FAP для управления движениями лица. Например: FAP может приказать ‘open_jaw (500)’ (открыть челюсти) и таблица определит, что это означает в терминах перемещения характерных точек;
Интерполяционная методика для лица FIT (Face Interpolation Technique) в BIFS (загружаемое определение карты входящих FAP в общий набор FAP до их использования в характерных точках, которая вычисляется с использованием полиномиальных функций при получении интерполяционного графа лица). Это может использоваться для установления комплексных перекрестных связей FAP или интерполяции FAP, потерянных в потоке, с привлечением FAP, которые доступны для терминала.
Эти специфицированные типы узлов в BIFS эффективно предоставляют для моделей формирования лица встроенную калибровку модели, работающей в терминале или загружаемой стандартной модели, включающей форму, текстуру и цвет.
9.8.2. Анимация тела
Тело является объектом способным генерировать модели виртуального тела и анимации в форме наборов 3-D многоугольных сеток, пригодных для отображения (rendering). Для тела определены два набора параметров: набор параметров определения тела BDP (Body Definition Parameter), и набор параметров анимации тела BAP (Body Animation Parameter). Набор BDP определяет параметры преобразования тела по умолчанию в требующееся тело с нужной поверхностью, размерами, и (опционно) текстурой. Параметры анимации тела (BAP), если интерпретированы корректно, дадут разумно высокий уровень результата выражаемого в терминах позы и анимации для самых разных моделей тела, без необходимости инициализировать или калибровать модель.
Конструкция объекта тело содержит обобщенное виртуальное человеческое тело в позе по умолчанию. Это тело может быть уже отображено. Объект способен немедленно принимать BAP из потока данных, который осуществляет анимацию тела. Если получены BDP, они используются для преобразования обобщенного тела в конкретное, заданное содержимым параметров. Любой компонент может быть равен нулю. Нулевой компонент при отображении тела заменяется соответствующим значением по умолчанию. Поза по умолчанию соответствует стоящей фигуре. Эта поза определена следующим образом: стопы ориентированы в фронтальном направлении, обе руки размещаться вдоль тела с ладонями повернутыми внутрь. Эта поза предполагает также, что все BAP имеют значения по умолчанию.
Не делается никаких предположений и не предполагается никаких ограничений на движения или сочленения. Другими словами модель человеческого тела должна поддерживать различные приложения, от реалистических симуляций человеческих движений до сетевых игр, использующих простые человекоподобные модели.
Стандарт анимации тела был разработан MPEG в сотрудничестве с Рабочей группой анимации гуманоидов (Humanoid Animation Working Group) в рамках консорциума VRML.
9.8.3. Анимируемые 2-D сетки
Сетка 2-D mesh является разложением плоской 2-D области на многоугольные кусочки. Вершины полигональных частей этой мозаики называются узловыми точками сетки. MPEG-4 рассматривает только треугольные сетки, где элементы мозаики имеют треугольную форму. Динамические 2-D сетки ссылаются на сетки 2-D и информацию перемещения всех узловых точек сетки в пределах временного сегмента интереса. Треугольные сетки использовались в течение долгого времени для эффективного моделирования формы 3-D объектов и воспроизведения в машинной графики. Моделирование 2-D сеток может рассматриваться как проекцию треугольных 3-D сеток на плоскость изображения.
Узловые точки динамической сетки отслеживают особенности изображения во времени с помощью соответствующих векторов перемещения. Исходная сетка может быть регулярной, или адаптироваться к характеру изображения, которая называется сеткой, адаптируемой к изображению. Моделирование 2-D сетки, адаптируемая к изображению, соответствует неоднородному стробированию поля перемещения в некотором числе узловых точек вдоль контура и внутри видео объекта. Методы выбора и отслеживания этих узловых точек не является предметом стандартизации.
В 2-D сетке, базирующейся на текстуре, треугольные элементы, в текущем кадре деформируются при перемещении узловых точек. Текстура в каждом мозаичном элементе эталонного кадра деформируется с помощью таблиц параметрического соответствия, определенных как функция векторов перемещения узловых точек. Для треугольных сетей обычно используется аффинное преобразование. Его линейная форма предполагает текстурный мэпинг с низкой вычислительной сложностью. Афинный мэпинг может моделировать преобразование, вращение, изменение масштаба, отражение и вырезание и сохранение прямых линий. Степени свободы, предоставляемые тремя векторами перемещения вершин треугольника, соответствуют шести параметрам афинного преобразования (affine mapping). Это предполагает, что исходное 2-D поле перемещения может быть компактно представлено движением узловых точек, из которого реконструируется афинное поле перемещение. В то же время, структура сетки ограничивает перемещения смежных, мозаичных элементов изображения. Следовательно, сетки хорошо годятся для представления умеренно деформируемых, но пространственно непрерывных полей перемещения.
Моделирование 2- D сетки привлекательно, та как 2-D сетки могут сформированы из одного вида объекта, сохраняя функциональность, обеспечиваемую моделированием с привлечением 3-D сеток. Подводя итог можно сказать, что представления с объектно-ориентированными 2-D сетками могут моделировать форму (многогранная апроксимация контура объекта) и перемещение VOP в неоднородной структуре, которая является расширяемой до моделирования 3-D объектов, когда имеются данные для конструирования таких моделей. В частности, представление видео-объектов с помощью 2-D-сетки допускает следующие функции:
A. Манипуляция видео-объектами
Улучшенная реальность. Объединение виртуальных (сгенерированых ЭВМ) изображений с реальными движущимися объектами (видео) для создания улучшенной видео информации. Изображения, созданные компьютером должны оставаться в идеальном согласии с движущимися реальными изображениями (следовательно необходимо отслеживание).
Преображение/анимация синтетических объектов. Замещение естественных видео объектов в видео клипе другим видео объектом. Замещающий видео объект может быть извлечен из другого естественного видео клипа или может быть получен из объекта статического изображения, используя информацию перемещения объекта, который должен быть замещен.
Пространственно-временная интерполяция. Моделирование движения сетки представляет более надежную временную интерполяцию с компенсацией перемещения.
B. Сжатие видео-объекта
Моделирование 2-D сеток может использоваться для сжатия, если выбирается передача текстурных карт только определенных ключевых кадров и анимация этих текстурных карт для промежуточных кадров. Это называется само преображением выбранных ключевых кадров с использованием информации 2-D сеток.
C. Видео индексирование, базирующееся на содержимом
Представление сетки делает возможным анимационные ключевые мгновенные фотографии для подвижного визуального обзора объектов.
Представление сетки предоставляет точную информацию о траектории объекта, которая может использоваться для получения визуальных объектов с специфическим перемещением.
Сетка дает представление формы объекта, базирующееся на вершинной схеме, которое более эффективно, чем представление через побитовую карту.
9.8.4. 3D-сетки
Возможности кодирования 3-D сеток включают в себя:
Кодирование базовых 3-D многоугольных сеток делает возможным эффективное кодирование 3-D полигональных сеток. Кодовое представление является достаточно общим, чтобы поддерживать как много- так и одно-сеточный вариант.
Инкрементное представление позволяет декодеру реконструировать несколько лиц в сетке, пропорционально числу бит в обрабатываемом потоке данных. Это, кроме того, делает возможным инкрементный рэндеринг.
Быстрое восстановление при ошибках позволяет декодеру частично восстановить сетку, когда субнабор бит потока данных потерян и/или искажен.
Масштабируемость LOD (Level Of Detail – уровень детализации) позволяет декодеру реконструировать упрощенную версию исходной сетки, содержащей уменьшенное число вершин из субнабора потока данных. Такие упрощенные презентации полезны, чтобы уменьшить время рэндеринга объектов, которые удалены от наблюдателя (управление LOD), но также делает возможным применение менее мощного средства для отображения объекта с ухудшенным качеством.
9.8.5. Масштабируемость, зависящая от изображения
Масштабируемость, зависящая от вида, делает возможными текстурные карты, которые используются реалистичных виртуальных средах. Она состоит в учете точки наблюдения в виртуальном 3-D мире для того чтобы передать только видимую информацию. Только часть информации затем пересылается, в зависимости от геометрии объекта и смещения точки зрения. Эта часть вычисляется как на стороне кодировщика, так и на стороне декодера. Такой подход позволяет значительно уменьшить количество передаваемой информации между удаленной базой данных и пользователем. Эта масштабируемость может работать с кодировщиками, базирующимися на DCT.
9.9. Структура средств для представления натурального видео
Алгоритмы кодирования изображение MPEG-4 и видео предоставляют эффективное представление визуальных объектов произвольной формы, а также поддержку функций, базирующихся на содержимом. Они поддерживают большинство функций, уже предлагаемых в MPEG-1 и MPEG-2, включая эффективное сжатие стандартных последовательностей прямоугольных изображений при варьируемых уровнях входных форматов, частотах кадров, глубине пикселей, скоростях передачи и разных уровнях пространственной, временной и качественной масштабируемости.
Базовая качественная классификация по скоростям передачи и функциональности визуального стандарта MPEG-4 для естественных изображений и видео представлена на рис. 11.

Рис. 11. Классификация средств и алгоритмов кодирования звука и изображения MPEG-4
"Ядро VLBV" (VLBV - Very Low Bit-rate Video) предлагает алгоритмы и средства для приложений, работающих при скоростях передачи между 5 и 64 кбит/с, поддерживающие последовательности изображений с низким пространственным разрешение (обычно ниже разрешения CIF) и с низкими частотами кадров (обычно ниже 15 Гц). К приложениям, поддерживающим функциональность ядра VLBV относятся:
Кодирование обычных последовательностей прямоугольных изображений с высокой эффективностью кодирования и высокой устойчивостью к ошибкам, малыми задержками и низкой сложностью для мультимедийных приложений реального времени, и
Операции "произвольный доступ", "быстрая перемотка вперед" и " быстрая перемотка назад" для запоминания VLB мультимедиа ДБ и приложений доступа.
Та же самая функциональность поддерживается при высоких скоростях обмена с высокими параметрами по временному и пространственному разрешению вплоть до ITU-R Rec. 601 и больше – используя идентичные или подобные алгоритмы и средства как в ядре VLBV. Предполагается, что скорости передачи лежат в диапазоне от 64 кбит/с до 10 Мбит/с, а приложения включают широковещательное мультимедиа или интерактивное получение сигналов с качеством, сравнимым с цифровым телевидением.
Функциональности, базирующиеся на содержимом,
поддерживают отдельное кодирование и декодирование содержимого (т.е. физических объектов в сцене, VO). Эта особенность MPEG-4 предоставляет наиболее элементарный механизм интерактивности.
Для гибридного кодирования естественных и искусственных визуальных данных (например, для виртуального присутствия или виртуального окружения) функциональность кодирования, зависящая от содержимого, допускает смешение нескольких VO от различных источников с синтетическими объектами, такими как виртуальный фон.
Расширенные алгоритмы и средства MPEG- 4 для функциональности, зависящей от содержимого, могут рассматриваться как супер набор ядра VLBV и средств для работы при высоких потоках данных.
9.10. Поддержка обычной функциональности и зависящей от содержимого
MPEG-4 видео поддерживает обычные прямоугольные изображения и видео, а также изображения и видео произвольной формы.
Кодирование обычных изображений и видео сходно с обычным кодированием в MPEG-1/2. Оно включает в себя предсказание/компенсацию перемещений за которым следует кодирование текстуры. Для функциональности, зависящей от содержимого, где входная последовательность изображений может иметь произвольную форму и положение, данный подход расширен с помощью кодирования формы и прозрачности. Форма может быть представлена двоичной маской или 8-битовой компонентой, которая позволяет описать прозрачность, если один VO объединен с другими объектами.
9.11. Видео изображение MPEG-4 и схема кодирования
Рис. 12 описывает базовый подход алгоритмов MPEG-4 видео к кодированию входной последовательности изображений прямоугольной и произвольной формы.
Рис. 12. Базовая блок-схема видео-кодировщика MPEG-4
Базовая структура кодирования включает в себя кодирование формы (для VO произвольной формы), компенсацию перемещения и кодирование текстуры с привлечением DCT (используя стандарт 8>x8 DCT или DCT адаптирующийся к форме).
Важным преимуществом кодирования, базирующегося на содержимом, является то, что эффективность сжатия может для некоторых видео последовательностей быть существенно улучшена путем применения соответствующих объектно-ориентированных средств предсказания перемещения для каждого из объектов на сцене. Для улучшения эффективности кодирования и гибкости презентации объектов может использоваться несколько методик предсказания перемещения:
• Стандартная оценка и компенсация перемещения, базирующаяся на блоках 8x8 или 16x16 пикселей.
• Глобальная компенсация перемещения, базирующаяся на передаче статического “образа”. Статическим образом может быть большое статическое изображение, описывающее панораму фона. Для каждого изображения в последовательности, кодируются для реконструкции объекта только 8 глобальных параметров перемещения, описывающих движение камеры. Эти параметры представляют соответствующее афинное преобразование образа, переданного в первом кадре.
9.11.1. Эффективность кодирования в V.2
Стандарт MPEG-4 V.2 улучшает оценку перемещения и компенсации для объектов и текстур прямоугольной и произвольной формы. Введены две методики для оценки и компенсации перемещения:
• Глобальная компенсация перемещения GMC (Global Motion Compensation). Кодирование глобального перемещения для объекта, использующего малое число параметров. GMC основано на глобальной оценке перемещения, деформации изображения, кодировании траектории перемещения и кодировании текстуры для ошибок предсказания.
• Четверть-пиксельная компенсация перемещения улучшает точность схемы компенсации, за счет лишь небольшого синтаксической и вычислительной избыточности. Точное описание перемещения приводит к малым ошибкам предсказания и, следовательно, лучшему визуальному качеству.
В области текстурного кодирования DCT (SA-DCT – адаптивный к форме) улучшает эффективность кодирования объектов произвольной формы. Алгоритм SA-DCT основан на предварительно определенных ортонормальных наборах одномерных базисных функций DCT.
Субъективные оценочные тесты показывают, что комбинация этих методик может дать экономию в необходимой полосе канала до 50% по сравнению с версией 1, в зависимости от типа содержимого и потока данных.
9.12. Кодирование текстур в статических изображениях
Эффективное кодирование визуальных текстур и статических изображений (подлежащих, например, выкладке на анимационные сетки) поддерживается режимом визуальных текстур MPEG-4. Этот режим основан на алгоритме элементарных волн (wavelet) с нулевым деревом, который предоставляет очень высокую эффективность кодирования в широком диапазоне скоростей передачи. Вместе с высокой эффективностью сжатия, он также предлагает пространственную и качественную масштабируемость (вплоть до 11 уровней пространственной масштабируемости и непрерывной масштабируемости качества), а также кодирование объектов произвольной формы. Кодированный поток данных предназначен также для загрузки в терминал иерархии разрешения изображения. Эта технология обеспечивает масштабируемость разрешения в широком диапазоне условий наблюдения более типичном для интерактивных приложений при отображении 2-D и 3-D виртуальных миров.
9.13. Масштабируемое кодирование видео-объектов
MPEG-4 поддерживает кодирование изображений и видео объектов с пространственной и временной масштабируемостью, для обычных прямоугольных и произвольных форм. Под масштабируемостью подразумевается возможность декодировать лишь часть потока данных и реконструировать изображение или их последовательность с:
• уменьшенной сложностью декодера и следовательно ухудшенным качеством
• уменьшенным пространственным разрешением
• уменьшенным временным разрешением
• равным временным и пространственным разрешением, но с ухудшенным качеством.
Эта функциональность желательна для прогрессивного кодирования изображений и видео, передаваемых через неоднородные сети, а также для приложений, где получатель неспособен обеспечить полное разрешение или полное качество изображения или видео. Это может, например, случиться, когда мощность обработки или разрешение отображения ограничены.
Для декодирования статических изображений, стандарт MPEG-4 предоставит 11 уровней гранулярности, а также масштабируемость качества до уровня одного бита. Для видео последовательностей в начале будет поддерживаться 3 уровня гранулярности, но ведутся работы по достижению 9 уровней.
9.14. Устойчивость в среде, предрасположенной к ошибкам
MPEG-4 обеспечивает устойчивость к ошибкам, чтобы позволить доступ к изображениям и видео данным через широкий круг устройств памяти и передающих сред. В частности, благодаря быстрому росту мобильных телекоммуникаций, необычайно важно получить доступ к аудио и видео информации через радио сети. Это подразумевает необходимость успешной работы алгоритмов сжатия аудио и видео данных в среде предрасположенной к ошибкам при низких скоростях передачи (т.е., ниже 64 кбит/с).
Средства противостояния ошибкам, разработанные для MPEG-4 могут быть разделены на три основные группы: ресинхронизация, восстановление данных и подавления влияния ошибок. Следует заметить, что эти категории не являются уникальными для MPEG-4, они широко используются разработчиками средств противодействия ошибкам для видео.
9.14.1. Ресинхронизация
Средства ресинхронизации пытаются восстановить синхронизацию между декодером и потоком данных нарушенную в результате ошибки. Данные между точкой потери синхронизации и моментом ее восстановления выбрасываются.
Метод ресинхронизации принятый MPEG-4, подобен используемому в структурах групп блоков GOB (Group of Blocks) стандартов ITU-T H.261 и H.263. В этих стандартах GOB определена, как один или более рядов макроблоков (MB). В начале нового GOB потока помещается информация, называемая заголовком GOB. Этот информационный заголовок содержит стартовый код GOB, который отличается от начального кода кадра, и позволяет декодеру локализовать данный GOB. Далее, заголовок GOB содержит информацию, которая позволяет рестартовать процесс декодирования (т.е., ресинхронизовать декодер и поток данных, а также сбросить всю информацию предсказаний).
Подход GOB базируется пространственной ресинхронизации. То есть, раз в процессе кодирования достигнута позиция конкретного макроблока, в поток добавляется маркер ресинхронизации. Потенциальная проблема с этим подходом заключается в том, что из-за вариации скорости процесса кодирования положение этих маркеров в потоке четко не определено. Следовательно, определенные части сцены, такие как быстро движущиеся области, будут более уязвимы для ошибок, которые достаточно трудно исключить.
Подход видео пакетов, принятый MPEG-4, базируется на периодически посылаемых в потоке данных маркерах ресинхронизации. Другими словами, длина видео пакетов не связана с числом макроблоков, а определяется числом бит, содержащихся в пакете. Если число бит в текущем видео пакете превышает заданный порог, тогда в начале следующего макроблока формируется новый видео пакет.
Маркер ресинхронизации используется чтобы выделить новый видео пакет. Этот маркер отличим от всех возможных VLC-кодовых слов, а также от стартового кода VOP. Информация заголовка размещается в начале видео пакета. Информация заголовка необходима для повторного запуска процесса декодирования и включает в себя: номер макроблока первого макроблока, содержащегося в этом пакете и параметр квантования, необходимый для декодирования данный макроблок. Номер макроблока осуществляет необходимую пространственную ресинхронизацию, в то время как параметр квантования позволяет заново синхронизовать процесс дифференциального декодирования.
В заголовке видео пакета содержится также код расширения заголовка (HEC). HEC представляет собой один бит, который, если равен 1, указывает на наличие дополнительной информации ресинхронизации. Сюда входит модульная временная шкала, временное приращение VOP, тип предсказания VOP и VOP F-код. Эта дополнительная информация предоставляется в случае, если заголовок VOP поврежден.
Следует заметить, что, когда в рамках MPEG-4 используется средство восстановления при ошибках, некоторые средства эффективного сжатия модифицируются. Например, вся кодированная информация предсказаний заключаться в одном видео пакете так чтобы предотвратить перенос ошибок.
В связи с концепцией ресинхронизацией видео пакетов, в MPEG-4 добавлен еще один метод, называемый синхронизацией с фиксированным интервалом. Этот метод требует, чтобы стартовые коды VOP и маркеры ресинхронизации (т.е., начало видео пакета) появлялись только в легальных фиксированных позициях потока данных. Это помогает избежать проблем, связанных эмуляциями стартовых кодов. То есть, когда в потоке данных встречаются ошибки, имеется возможность того, что они эмулируют стартовый код VOP. В этом случае, при использовании декодера с синхронизацией с фиксированным интервалом, стартовый код VOP ищется только в начале каждого фиксированного интервала.
9.14.2. Восстановление данных
После того как синхронизация восстановлена, средства восстановления данных пытаются спасти данные, которые в общем случае могут быть потеряны. Эти средства являются не просто программами коррекции ошибок, а техникой кодирования данных, которая устойчива к ошибкам. Например, одно конкретное средство, которое было одобрено видео группой (Video Group), является обратимыми кодами переменной длины RVLC (Reversible Variable Length Codes). В этом подходе, кодовые слова переменной длины сконструированы симметрично, так что они могут читаться как в прямом, так и в обратном направлении.
Пример, иллюстрирующий использование RVLC представлен на рис. 13. Вообще, в ситуации, когда блок ошибок повредил часть данных, все данные между двумя точками синхронизации теряются. Однако, как показано на рис. 13, RVLC позволяет восстановить часть этих данных. Следует заметить, что параметры, QP и HEC, показанные на рисунке, представляют поля, зарезервированные в заголовке видео пакета для параметра квантования и кода расширения заголовка, соответственно.

Рис. 13. Пример реверсивного кода переменной длины
9.14.3. Сокрытие ошибок
Сокрытие ошибок
(имеется в виду процедура, когда последствия ошибок не видны) является исключительно важным компонентом любого устойчивого к ошибкам видео кодека. Средства аналогичные данному рассмотрены выше, эффективность стратегии сокрытия ошибок в высшей степени зависит от работы схемы ресинхронизации. По существу, если метод ресинхронизации может эффективно локализовать ошибку, тогда проблема сокрытия ошибок становится легко решаемой. Для приложений с низкой скоростью передачи и малой задержкой текущая схема ресинхронизации позволяет получить достаточно приемлемые результаты при простой стратегии сокрытия, такой как копирование блоков из предыдущего кадра.
Для дальнейшего улучшения техники сокрытия ошибок Видео Группа разработала дополнительный режим противодействия ошибкам, который дополнительно улучшает возможности декодера по локализации ошибок.
Этот подход использует разделение данных, сопряженных с движением и текстурой. Такая техника требует, чтобы был введен второй маркер ресинхронизации между данными движения и текстуры. Если информация текстуры потеряна, тогда для минимизации влияния ошибок используется информация перемещения. То есть, из-за ошибок текстурные данные отбрасываются, в то время данные о движении служат для компенсации перемещения как ранее декодированной VOP.
10. Подробное техническое описание MPEG-4 аудио
MPEG-4 кодирование аудио объектов предлагает средства как для представления естественных звуков (таких как речь и музыка) так и синтетических – базирующихся на структурированных описаниях. Представление для синтетического звука может быть получено из текстовых данных или так называемых инструментальных описаний и параметров кодирования для обеспечения специальных эффектов, таких как реверберация и объемное звучание. Представления обеспечивают сжатие и другую функциональность, такую как масштабируемость и обработку эффектов.
Средства аудио кодирования MPEG-4, охватывающие диапазон от 6кбит/с до 24кбит/с, подвергаются верификационным тестированиям для широковещательных приложений цифрового AM-аудио совместно с консорциумом NADIB (Narrow Band Digital Broadcasting). Было обнаружено, что высокое качество может быть получено для одного и того же частотного диапазона с привлечением цифровых методик и что конфигурации масштабируемого кодировщика могут обеспечить лучшие эксплуатационные характеристики.
10.1. Натуральный звук
MPEG- 4 стандартизирует кодирование естественного звука при скоростях передачи от 2 кбит/с до 64 кбит/с. Когда допускается переменная скорость кодирования, допускается работа и при низких скоростях вплоть до 1.2 кбит/с. Использование стандарта MPEG-2 AAC в рамках набора средств MPEG-4 гарантирует сжатие аудио данных при любых скоростях вплоть до самых высоких. Для того чтобы достичь высокого качества аудио во всем диапазоне скоростей передачи и в то же время обеспечить дополнительную функциональность, техники кодирования голоса и общего аудио интегрированы в одну систему:
• Кодирование голоса при скоростях между 2 и 24 кбит/с поддерживается системой кодирования HVXC (Harmonic Vector eXcitation Coding) для рекомендуемых скоростей 2 - 4 кбит/с, и CELP (Code Excited Linear Predictive) для рабочих скоростей 4 - 24 кбит/с. Кроме того, HVXC может работать при скоростях вплоть до 1.2 кбит/с в режиме с переменной скоростью. При кодировании CELP используются две частоты стробирования, 8 и 16 кГц, чтобы поддержать узкополосную и широкополосную передачу голоса, соответственно. Подвергнуты верификации следующие рабочие режимы: HVXC при 2 и 4 кбит/с, узкополосный CELP при 6, 8.3, и 12 кбит/с, и широкополосный CELP при 18 кбит/с.
• Для обычного аудио кодирования при скоростях порядка и выше 6 кбит/с, применены методики преобразующего кодирования, в частности TwinVQ и AAC. Аудио сигналы в этой области обычно стробируются с частотой 8 кГц.
Чтобы оптимально перекрыть весь диапазон скоростей передачи и разрешить м асштабируемость скоростей, разработана специальная система, отображенная на рис. 14.

Рис. 14. Общая блок-схема MPEG-4 аудио
Масштабируемость полосы пропускания является частным случаем масштабируемости скоростей передачи, по этой причине часть потока, соответствующая части спектра полосы пропускания, может быть отброшена при передаче или декодировании.
Масштабируемость сложности кодировщика позволяет кодирующим устройствам различной сложности формировать корректные информационные потоки. Масштабируемость сложности декодера позволяет данному потоку данных быть декодированному приборами с различной сложностью (и ценой). Качество звука, вообще говоря, связано со сложностью используемого кодировщика и декодера Масштабируемость работает в рамках некоторых средств MPEG-4, но может также быть применена к комбинации методик, например, к CELP, как к базовому уровню, и AAC.
Уровень систем MPEG- 4 позволяет использовать кодеки, следующие, например, стандартам MPEG-2 AAC. Каждый кодировщик MPEG-4 предназначен для работы в автономном режиме (stand-alone) со своим собственным синтаксисом потока данных. Дополнительная функциональность реализуется за счет возможностей кодировщика и посредством дополнительных средств вне его.
10.2. Улучшения MPEG-4 аудио V.2
10.2.1. Устойчивость к ошибкам
Средства устойчивости к ошибкам предоставляют улучшенные рабочие характеристики для транспортных каналов, предрасположенных к ошибкам.
Улучшенную устойчивость к ошибкам для AAC предлагается набором средств сокрытия ошибок. Эти средства уменьшают воспринимаемое искажение декодированного аудио сигнала, которое вызвано повреждением бит информационного потока. Предлагаются следующие средства для улучшения устойчивости к ошибкам для нескольких частей AAC-кадра:
Средство виртуального кодового блокнота (VCB11)
Средство с обращаемыми кодовыми словами переменной длины RVLC (Reversible Variable Length Coding)
Средство изменения порядка кодовых слов Хафмана HCR (Huffman Codeword Reordering)
Возможности улучшения устойчивости к ошибкам для всех средств кодирования обеспечивается с помощью синтаксиса поля данных. Это позволяет применение продвинутых методик кодирования, которые могут быть адаптированы к специальным нуждам различных средств кодирования. Данный синтаксис полей данных обязателен для всех объектов версии 2.
Средство защиты от ошибок (EP tool) работает со всеми аудио объектами MPEG-4 версии 2, предоставляя гибкую возможность конфигурирования для широкого диапазона канальных условий. Главными особенностями средства EP являются следующие:
Обеспечение набора кодов для коррекции/детектирования ошибок с широким диапазоном масштабируемости по рабочим характеристикам и избыточности.
Обеспечение системы защиты от ошибок, которая работает как с кадрами фиксированной, так и переменной длины.
Обеспечение управления конфигурацией защиты от неравных ошибок UEP (Unequal Error Protection) с низкой избыточностью.
Алгоритмы кодирования MPEG-4 аудио версии 2 предоставляет классификацию всех полей потока согласно их чувствительности к ошибкам. На основе этого, поток данных делится на несколько классов, которые могут быть защищены раздельно с помощью инструмента EP, так что более чувствительные к ошибкам части окажутся защищены более тщательно.
10.2.2. Аудио-кодирование с малыми задержками
В то время как универсальный аудио кодировщик MPEG-4 очень эффективен при кодировании аудио сигналов при низких скоростях передачи, он имеет алгоритмическую задержку кодирования/декодирования, достигающую нескольких сот миллисекунд и является, таким образом, неподходящим для приложений, требующих малых задержек кодирования, таких как двунаправленные коммуникации реального времени. Для обычного аудио кодировщика, работающего при частоте стробирования 24 кГц и скорости передачи 24 кбит/с, алгоритмическая задержка кодирования составляет 110 мс плюс до 210 мс дополнительно в случае использования буфера. Чтобы кодировать обычные аудио сигналы enable с алгоритмической задержкой, не превышающей 20 мс, MPEG-4 версии 2 специфицирует кодировщик, который использует модификацию алгоритма MPEG-2/4 AAC (Advanced Audio Coding). По сравнению со схемами кодирования речи, этот кодировщик позволяет сжимать обычные типы аудио сигналов, включая музыку, при достаточно низких задержках. Он работает вплоть до частот стробирования 48 кГц и использует длину кадров 512 или 480 значений стробирования, по сравнению с 1024 или 960 значений, используемых в стандарте MPEG-2/4 AAC. Размер окна, используемого при анализе и синтезе блока фильтров, уменьшен в два раза. Чтобы уменьшить артифакты предэхо в случае переходных сигналов используется переключение размера окна. Для непереходных частей сигнала используется окно синусоидальной формы, в то время как в случае переходных сигналов используется так называемое окно с низким перекрытием. Использование буфера битов минимизируется, чтобы сократить задержку. В крайнем случае, такой буфер вообще не используется.
10.2.3. Масштабируемость гранулярности
Масштабируемость скорости передачи, известная как встроенное кодирование, является крайне желательной функцией. Обычный аудио кодировщик версии 1 поддерживает масштабируемость с большими шагами, где базовый уровень потока данных может комбинироваться с одним или более улучшенных уровней потока данных, чтобы можно было работать с высокими скоростями и, таким образом, получить лучшее качество звука. В типовой конфигурации может использоваться базовый уровень 24 кбит/с и два по 16 кбит/с, позволяя декодирование с полной скоростью 24 кбит/с (моно), 40 кбит/с (стерео), и 56 кбит/с (стерео). Из-за побочной информации передаваемой на каждом уровне, малые уровни-добавки поддерживаются в версии 1 не очень эффективно. Чтобы получить эффективную масштабируемость с малыми шагами для стандартного аудио кодировщика, в версии 2 имеется средство побитового арифметического кодирования BSAC (Bit-Sliced Arithmetic Coding). Это средство используется в комбинации с AAC-кодированием и замещает бесшумное кодирование спектральных данных и масштабных коэффициентов. BSAC предоставляет масштабируемость шагами в 1 кбит/с на аудио канал, т.е. шагами по 2 кбит/с для стерео сигнала. Используется один базовый поток (уровень) данных и много небольших потоков улучшения. Базовый уровень содержит общую информацию вида, специфическую информацию первого уровня и аудио данные первого уровня. Потоки улучшения содержат только специфические данные вида и аудио данные соответствующего слоя. Чтобы получить масштабируемость с небольшими шагами, используется побитовая схема a квантования спектральных данных. Сначала преобразуемые спектральные величины группируются в частотные диапазоны. Каждая из этих групп содержит оцифрованные спектральные величины в их двоичном представлении. Затем биты группы обрабатываются порциями согласно их значимости. Таким образом сначала обрабатываются все наиболее значимые биты (MSB) оцифрованных величин в группе и т.д. Эти группы бит затем кодируются с привлечением арифметической схемы кодирования, чтобы получить энтропийные коды с минимальной избыточностью. Представлены различные модели арифметического кодирования, чтобы перекрыть различные статистические особенности группировок бит.
Верификационные тесты показали, что аспект масштабируемости этого средства ведет себя достаточно хорошо в широком диапазоне скоростей передачи. При высоких скоростях оно столь же хорошо, как главный профайл AAC, работающий на той же скорости, в то время как при нижних скоростях функция масштабируемости требует скромной избыточности по отношению к основному профайлу AAC, работающий на той же скорости.
10.2.4. Параметрическое кодирование звука
Средства параметрического аудио-кодирования сочетают в себе низкую скорость кодирования обычных аудио сигналов с возможностью модификации скорости воспроизведения или шага при декодировании без бока обработки эффектов. В сочетании со средствами кодирования речи и звука версии 1, ожидается улучшенная эффективность кодирования для использования объектов, базирующихся на кодировании, которое допускает выбор и/или переключение между разными техниками кодирования.
Параметрическое аудио-кодирование использует для кодирования общих аудио сигналов технику HILN (Harmonic and Individual Lines plus Noise) при скоростях 4 кбит/с, а выше применяется параметрическое представление аудио сигналов. Основной идеей этой методики является разложение входного сигнала на аудио объекты, которые описываются соответствующими моделями источника и представляются модельными параметрами. В кодировщике HILN используются модели объектов для синусоид, гармонических тонов и шума.
Как известно из кодирования речи, где используются специализированные модели источника, основанные на процессе генерации звуков в человеческом голосовом тракте, продвинутые модели источника могут иметь преимущество в частности для схем кодирования с очень низкими скоростями передачи.
Из-за очень низкой скорости передачи могут быть переданы только параметры для ограниченного числа объектов. Следовательно, модель восприятия устроена так, чтобы отбирать те объекты, которые наиболее важны для качества приема сигнала.
В HILN, параметры частоты и амплитуды оцифровываются согласно с "заметной разницей", известной из психо-акустики. Спектральный конверт шума и гармонический тон описан с использованием моделирования LPC. Корреляция между параметрами одного кадра и между последовательными кадрами анализируется методом предсказания параметров. Оцифрованные параметры подвергаются энтропийному кодированию, после чего эти данные вводятся в общий информационный поток.
Очень интересное свойство этой схемы параметрического кодирования происходит из того факта, что сигнал описан через параметры частоты и амплитуды. Эта презентация сигнала позволяет изменять скорость и высоту звука простой вариацией параметров декодера. Параметрический аудио кодировщик HILN может быть объединен с параметрическим кодировщиком речи MPEG-4 (HVXC), что позволит получить интегрированный параметрический кодировщик, покрывающий широкий диапазон сигналов и скоростей передачи. Этот интегрированный кодировщик поддерживает регулировку скорости и тона. Используя в кодировщике средство классификации речи/музыки, можно автоматически выбрать HVXC для сигналов речи и HILN для музыкальных сигналов. Такое автоматическое переключение HVXC/HILN было успешно продемонстрировано, а средство классификации описано в информативном приложении стандарта версии 2.
10.2.5. Сжатие тишины CELP
Средство “сжатия тишины” уменьшает среднюю скорость передачи благодаря более низкому сжатию пауз (тишины). В кодировщике, детектор активности голоса используется для разделения областей с нормальной голосовой активностью и зон молчания или фонового шума. Во время нормальной голосовой активности используется кодирование CELP как в версии 1. В противном случае передается дескриптор SID (Silence Insertion Descriptor) при малой скорости передачи. Этот дескриптор SID активирует в декодере CNG (Comfort Noise Generator). Амплитуда и форма спектра этого шума специфицируются энергией и параметрами LPC как в обычном кадре CELP. Эти параметры являются опционной частью SID и таким образом могут модифицироваться.
10.2.6. Устойчивое к ошибкам HVXC
Объект HVXC, устойчивый к ошибкам (ER) поддерживается средствами параметрического кодирования голоса (ER HVXC), которые предоставляют режимы с фиксированными скоростями обмена (2.0-4.0 кбит/с) и режим с переменной скоростью передачи (<2.0 кбит/с, <4.0 кбит/с) в раках масштабируемой и не масштабируемой схем. В версии 1 HVXC, режим с переменной скоростью передачи поддерживается максимум 2.0 кбит/с, а режим с переменной скоростью передачи в версии ER HVXC 2 дополнительно поддерживается максимум 4.0 кбит/с. ER HVXC обеспечивает качество передачи голоса международных линий (100-3800 Hz) при частоте стробирования 8кГц. Когда разрешен режим с переменной скоростью передачи, возможна работа при низкой средней скорости передачи. Речь, кодированная в режиме с переменной скоростью передачи при среднем потоке 1.5 кбит/с, и типовом среднем значении 3.0 кбит/с имеет существенно то же качество, что для 2.0 кбит/с при фиксированной скорости и 4.0 кбит/с, соответственно. Функциональность изменения тона и скорости при декодировании поддерживается для всех режимов. Кодировщик речи ER HVXC ориентирован на приложения от мобильной и спутниковой связи, до IP-телефонии, и голосовых баз данных.
10.2.7. Пространственные характеристики среды
Средства пространственной характеристики среды позволяют создавать аудио сцены с более естественными источниками звука и моделированием звукового окружения, чем это возможно в версии 1. Поддерживается как физический подход, так и подход восприятия. Физический подход основан на описании акустических свойств среды (например, геометрии комнаты, свойств конструкционных материалов, положения источников звука) и может быть использован в приложениях подобно 3-D виртуальной реальности. Подход с позиций восприятия позволяет на высоком уровне описать аудио восприятие сцены, основанное на параметрах, подобных тем, что используются блоком эффекта реверберации. Таким образом, аудио и визуальная сцена могут быть сформированы независимо, как это обычно требуется в случае кинофильмов. Хотя пространственной характеристики среды относятся к аудио, они являются частью описания BIFS (BInary Format for Scene) в системах MPEG-4 и называются продвинутым AudioBIFS.
10.2.8. Обратный канал
Обратный канал (back channel) позволяет передать запрос клиента и/или клиентского терминала серверу. Посредством обратного канала может быть реализована интерактивность. В системе MPEG-4 о необходимости обратного канала (back channel) клиентский терминал оповещается с помощью соответствующего дескриптора элементарного потока, характеризующего параметры этого канала. Терминал клиента открывает этот обратный канал, так же как и обычные каналы. Объекты (например, медиа кодировщики или декодеры), которые соединены через обратный канал известны через параметры, полученные через дескриптор элементарного потока и за счет ассоциации дескриптора элементарного потока с дескриптором объекта. В MPEG-4 аудио, обратный канал обеспечивает обратную связь для настройки скорости передачи, масштабируемости и системы защиты от ошибок.
10.2.9. Транспортный поток звука
Транспортный поток MPEG-4 аудио определяет механизм передачи аудио потоков MPEG-4 без использования систем MPEG-4 и предназначен исключительно для аудио приложений. Транспортный механизм использует двухуровневый подход, а именно уровни мультиплексирования и синхронизации. Уровень мультиплексирования (Low-overhead MPEG-4 Audio Transport Multiplex: LATM) управляет мультиплексированием нескольких информационных полей MPEG-4 аудио и аудио конфигурационной информации. Уровень синхронизации специфицирует синтаксис транспортного потока MPEG-4 аудио, который называется LOAS (Low Overhead Audio Stream – аудио поток с низкой избыточностью). Интерфейсный формат для транспортного уровня зависит от ниже лежащего коммуникационного уровня.
10.3. Синтетический звук
MPEG- 4 определяет декодеры для генерирования звука на основе нескольких видов структурированного ввода. Текстовый ввод Text преобразуется в декодере TTS (Text-To-Speech), в то время как прочие звуки, включая музыку, могут синтезироваться стандартным путем. Синтетическая музыка может транспортироваться при крайне низких потоках данных.
Декодеры TTS (Text To Speech) работают при скоростях передачи от 200 бит/с до 1.2 Кбит/с, что позволяет использовать при синтезе речи в качестве входных данных текст или текст с просодическими параметрами (тональная конструкция, длительность фонемы, и т.д.). Такие декодеры поддерживают генерацию параметров, которые могут быть использованы для синхронизации с анимацией лица, при осуществлении перевода с другого языка и для работы с международными символами фонем. Дополнительная разметка используется для передачи в тексте управляющей информации, которая переадресуется другим компонентам для обеспечения синхронизации с текстом. Заметим, что MPEG-4 обеспечивает стандартный интерфейс для работы кодировщика TTS (TTSI = Text To Speech Interface), но не для стандартного TTS-синтезатора.
10.3.1. Синтез с множественным управлением (Score Driven Synthesis).
Средства структурированного аудио декодируют входные данные и формируют выходной звуковой сигнал. Это декодирование управляется специальным языком синтеза, называемым SAOL (Structured Audio Orchestra Language), который является частью стандарта MPEG-4. Этот язык используется для определения "оркестра", созданного из "инструментов" (загруженных в терминал потоком данных), которые формирует и обрабатывает управляющую информацию. Инструмент представляет собой маленькую сеть примитивов обработки сигналов, которые могут эмулировать некоторые специфические звуки, такие, которые могут производить настоящие акустические инструменты. Сеть обработки сигналов может быть реализована аппаратно или программно и включать как генерацию, так и обработку звуков, а также манипуляцию записанными ранее звуками.
MPEG-4 не стандартизует "единственный метод" синтеза, а скорее описывает путь описания методов синтеза. Любой сегодняшний или будущий метод синтеза звука может быть описан в SAOL, включая таблицу длин волн, FM, физическое моделирование и гранулярный синтез, а также непараметрические гибриды этих методов.
Управление синтезом выполняется путем включения "примитивов" (score) или "скриптов" в поток данных. Примитив представляет собой набор последовательных команд, которые включают различные инструменты в определенное время и добавляют их сигнал в общий музыкальный поток или формируют заданные звуковые эффекты. Описание примитива, записанное на языке SASL (Structured Audio Score Language), может использоваться для генерации новых звуков, а также включать дополнительную управляющую информацию для модификации существующих звуков. Это позволяет композитору осуществлять тонкое управление синтезированными звуками. Для процессов синтеза, которые не требуют такого тонкого контроля, для управления оркестром может также использоваться протокол MIDI.
Тщательный контроль в сочетании с описанием специализированных инструментов, позволяет генерировать звуки, начиная с простых аудио эффектов, таких как звуки шагов или закрытия двери, кончая естественными звуками, такими как шум дождя или музыка, исполняемая на определенном инструменте или синтетическая музыка с полным набором разнообразных эффектов.
Для терминалов с меньшей функциональностью, и для приложений, которые не требуют такого сложного синтеза, стандартизован также "формат волновой таблицы” (“wavetable bank format"). Используя этот формат, можно загрузить звуковые образцы для использования при синтезе, а также выполнить простую обработку, такую как фильтрация, реверберация, и ввод эффекта хора. В этом случае вычислительная сложность необходимого процесса декодирования может быть точно определена из наблюдения потока данных, что невозможно при использовании SAOL.
11. Приложение. Словарь и сокращения
| AAC | Advanced Audio Coding – продвинутое кодирование звука |
| AAL | ATM Adaptation Layer – адаптационный уровень ATM |
| Access Unit | Логическая субструктура элементарного потока для облегчения доступа или манипуляции потоком данных |
| ACE | Advanced Coding Efficiency (профайл) – эффективность продвинутого кодирования |
| Amd | Поправка |
| AOI | Area Of Interest – область интереса |
| API | Application Programming Interface – программный интерфейс приложения |
| ARTS | Advanced Real-time Simple – простой, продвинутый профайл реального времени |
| ATM | Asynchronous Transfer Mode – режим асинхронной передачи |
| BAP | Body Animation Parameters – параметры анимации тела |
| BDP | Body Definition Parameters – параметры описания тела |
| BIFS | Binary Format for Scenes – двоичный формат сцены |
| BSAC | Bit-Sliced Arithmetic Coding – побитовое арифметическое кодирование |
| CD | Committee Draft – проект комитета |
| CE | Core Experiment – центральный эксперимент |
| CELP | Code Excited Linear Prediction – линейное предсказание, стимулируемое кодом |
| CIF | Common Intermediate Format – общий промежуточный формат |
| CNG | Comfort Noise Generator – генератор комфортного шума |
| DAI | DMIF-Application Interface – прикладной интерфейс DMIF |
| DCT | Discrete Cosine Transform – дискретное косинусное преобразование |
| DMIF | Delivery Multimedia Integration Framework - |
| DNI | DMIF Network Interface – сетевой интерфейс DMIF |
| DRC | Dynamic Resolution Conversion – преобразование с динамическим разрешением |
| DS | DMIF signaling – сигнальная система DMIF |
| EP | Error Protection – защита от ошибок |
| ER | Error Resilient – противостояние ошибкам |
| ES | Elementary Stream (элементарный поток): последовательность данных, которая исходит из передающего терминала MPEG-4 Terminal и приходит одному получателю, например, медиа- или управляющему объекту в приемном терминале MPEG-4. Он проходит через один канал FlexMux. |
| FAP | Facial Animation Parameters – параметры анимации лица |
| FBA | Facial and Body Animation – анимация лица и тела |
| FDP | Facial Definition Parameters – параметры описания лица |
| FlexMux stream | Последовательность пакетов FlexMux, ассоциированных с одним или более каналов FlexMux, идущих через один канал TransMux |
| FlexMux tool | A Flexible (Content) Multiplex tool – гибкое средство мультиплексирования |
| GMC | Global Motion Compensation – компенсация общего перемещения |
| GSTN | General Switched Telephone Network – общедоступная коммутируемая телефонная сеть |
| HCR | Huffman Codeword Reordering – смена порядка кодовых слов Хафмана |
| HFC | Hybrid Fiber Coax – гибридный волоконный коаксиал |
| HTTP | HyperText Transfer Protocol – протокол передачи гипертекста |
| HVXC | Harmonic Vector Excitation Coding – кодирование с гармоническим возбуждением вектора |
| IP | Internet Protocol – протокол Интернет |
| IPI | Intellectual Property Identification – идентификация интеллектуальной собственности |
| IPMP | Intellectual Property Management и Protection – защита и управление интеллектуальной собственностью |
| IPR | Intellectual Property Rights – Права интеллектуальной собственности |
| IS | International Standard – международный стандарт |
| ISDN | Integrated Service Digital Network – цифровая сеть с интегрированными услугами |
| LAR | Logarithmic Area Ratio – логарифмическое отношение области |
| LATM | Low-overhead MPEG-4 Audio Transport Multiplex: |
| LC | Low Complexity – низкая сложность |
| LOAS | Low Overhead Audio Stream – аудио поток с низкой избыточностью |
| LOD | Level Of Detail – уровень детализации |
| LPC | Linear Predictive Coding – линейно-предсказательное кодирование |
| LTP | Long Term Prediction – долгосрочное предсказание |
| M4IF | MPEG-4 Industry Forum – Промышленный форум MPEG-4 |
| MCU | Multipoint Control Unit – многоточечный блок управления |
| Mdat | media data atoms – атомы медийных данных |
| Mesh | A graphical construct consisting of connected surface elements to describe the geometry/shape of a visual object. - |
| MIDI | Musical Instrument Digital Interface – цифровой интерфейс музыкального инструмента> |
| MPEG | Moving Pictures Experts Group – Экспертная группа по движущимся изображениям |
| MSB | Most Significant Bits - наиболее значимые биты |
| OCI | Object Content Information – информационное содержание объекта |
| OD | Object Descriptor – дескриптор объекта |
| PDA | Personal Digital Assistant – персональный цифровой помощник |
| PDU | Protocol Data Unit – Протокольный блок данных |
| PSNR | Peak Signal to Noise Ratio – отношение пикового значения сигнала к шуму |
| QCIF | Quarter Common Intermediate Format – четвертинный промежуточный формат изображения (видео) |
| QoS | Quality of Service – качество обслуживания |
| Rendering | The process of generating pixels for display – процесс генерации пикселей для отображения |
| RTP | Real Time Transport Protocol – транспортный протокол реального времени |
| RTSP | Real Time Streaming Protocol – поточный протокол реального времени |
| RVLC | Reversible Variable Length Coding – реверсивное кодирование с переменной длиной |
| SA-DCT | shape-adaptive DCT – двойное косинусное преобразование, адаптируемое к форме объекта |
| SID | Silence Insertion Descriptor – дескриптор паузы |
| SL | Sync(hronization) layer – уровень синхронизации |
| SMIL | Synchronized Multimedia Integration Language – интеграционный язык для синхронизованного мультимедиа |
| SNHC | Synthetic- Natural Hybrid Coding – синтетико-натуральное кодирование |
| SNR | Signal to Noise Ratio – отношение сигнал-шум |
| Sprite | Статический спрайт представляет собой возможно большое статическое изображение, описывающие панорамный фон |
| SRM | Session Resource Manager – субъект управления ресурсами сессии |
| SVG | Scalable Vector Graphics – масштабируемая векторная графика |
| T/F coder | Time/Frequency Coder – преобразователь времени в частоту |
| TCP | Transmission Control Protocol – протокол управления передачей данных |
| TransMux | Общая абстракция для любой схемы транспортного мультиплексирования |
| TTS | Text-to-speech – текст в голос |
| UDP | User Datagram Protocol – протокол передачи датограмм пользователя |
| UEP | Unequal Error Protection - |
| UMTS | Universal Mobile Telecommunication System – универсальная мобильная телекоммуникационная система |
| VCB | Virtual CodeBook – виртуальная кодовая книга |
| Viseme | Выражение лица, сопряженное с определенной фонемой |
| VLBV | Very Low Bitrate Video – видео с очень низкой скоростью передачи данных |
| VM | Verification Model – верификационная модель |
| VOP | Video Object Plane – объектная плоскость видео |
| VRML | Virtual Reality Modeling Language – язык моделирования виртуальной реальности |
| W3C | World Wide Web Consortium – консорциум WWW |
| WD | Working Draft – рабочий черновик (проект) |
| WWW | World Wide Web – Всемирная паутина |
| XMT | Extensible MPEG-4 textual format – расширяемый текстуальный формат MPEG-4 |
сделали возможным интерактивное видео
2.5.2 Стандарт MPEG-7
Семенов Ю.А. (ГНЦ ИТЭФ)
Перевод http://mpeg.telecomitalialab.com/standards/mpeg-7/
MPEG-7 является стандартом ISO/IEC, разработанным MPEG (Moving Picture Experts Group), комитетом, который разработал стандарты MPEG-1, MPEG-2 и MPEG-4. Стандарты MpeG-1 и MPEG- 2 сделали возможным интерактивное видео на CD-ROM и цифровое телевидение. Стандарт MPEG-4 предоставляет стандартизованные технологические элементы, позволяющие интеграцию парадигм производства, рассылки и доступа к содержимому в области цифрового телевидения, интерактивной графики и интерактивного мультимедиа.
MPEG-7 формально называется “Мультимедиа-интерфейс для описания содержимого” (Multimedia Content Description Interface), он имеет целью стандартизовать описание мультимедийного материала, поддерживающего некоторый уровень интерпретации смысла информации, которая может быть передана для обработки ЭВМ. Стандарт MPEG-7 не ориентирован на какое-то конкретное приложение, он стандартизует некоторые элементы, которые рассчитаны на поддержку как можно более широкого круга приложений. Дополнительную информацию о MPEG-7 можно найти на базовой странице MPEG:
http://www.cselt.it/mpeg
а WEB-страница MPEG-7 (Industry Focus Group) размещена по адресу http://www.mpeg-7.com. Эти WEB-страницы содержат ссылки на информацию об MPEG, включая описание MPEG-7, многие общедоступные документы, списки "Frequently Asked Questions" и ссылки на WEB-страницы MPEG-7.
1. Введение
Огромное количество аудио-визуальной информации стало доступно в цифровой форме, в виде цифровых архивов, во всемирной паутине, в виде широковещательных потоков, а также в форме частных или профессиональных баз данных. Значение информации часто зависит оттого, насколько ее легко найти, извлечь, отфильтровать и управлять.
Тенденция очевидна. В ближайшие несколько лет, пользователи столкнутся с таким большим числом мультимедийных материалов, предоставляемых разными провайдерами, что эффективный доступ к этому почти бесконечному материалу представляется трудно вообразимым. Несмотря на тот факт, что пользователи имеют увеличивающиеся ресурсы, управление ими становится все более сложной задачей, из-за их объема. Это касается как профессионалов, так и пользователей. Вопрос идентификации и управления материалами не ограничивается приложениями доступа к базам данных, таким как цифровые библиотеки, но распространяются в сферу выбора широковещательных каналов, мультимедийного редактирования и служб мультимедийных каталогов. Протокол MPEG-7 призван решить многие из этих проблем.
MPEG-7 является стандартом ISO/IEC, разработанным MPEG (Moving Picture Experts Group), комитетом, который разработал также стандарты MPEG-1 (1992), MPEG-2 (1995), и MPEG-4 (версия 1 в 1998 и версия 2 в 1999). Стандарты MPEG-1 и MPEG- 2 позволили производить широко распространенные коммерческие продукты, такие как интерактивные CD, DVD, цифровое широковещательное аудио (DAB), цифровое телевидение, и многие другие коммерческие услуги. MPEG-4 является первым реальным мультимедийным стандартом для представления данных, позволяющим интерактивно работать с комбинациями натурального и синтетического материала, закодированного в виде объектов (он моделирует аудио-визуальные данные, как комбинацию таких объектов). MPEG-4 предоставляет стандартизованные технологические элементы, допускающие интеграцию производства, распределения и доступа к мультимедийному материалу. Это относится к интерактивному и мобильному мультимедиа, интерактивной графике и улучшенному цифровому телевидению.
Стандарт MPEG-7, формально назван “Multimedia Content Description Interface”. MPEG-7 предоставит широкий набор стандартизованных средств описания мультимедиа материала. В области действия MPEG-7 находятся как пользователи-люди, так и автоматические системы, выполняющие обработку аудио-визуального материала.
MPEG-7 предлагает полный набор аудиовизуальных средств описания, которые образуют базис для приложений, делая возможным высококачественный доступ к мультимедийному материалу, что предполагает хорошие решения для записи, идентификации материала, обеспечения прав собственности, и быстрой, эргономичной, точной целевой фильтрации, поиска.
Дополнительную информацию о MPEG-7 можно найти на WEB-сайте MPEG-7 http://drogo.cselt.it/mpeg/
и сайте MPEG-7 Industry Focus Group http://www.mpeg-7.com. Эти web-страницы содержат ссылки на ценную информацию о MPEG, включая материалы по MPEG-7, многие общедоступные документы, несколько списков ‘Frequently Asked Questions’ и ссылки на другие WEB-страницы MPEG-7.
1.1. Контекст MPEG-7
Доступно все больше и больше аудиовизуального материала из самых разных источников. Информация может быть представлена в различных медийных формах, таких как статические изображения, графика, 3D модели, звук, голос, видео. Аудиовизуальная информация играет важную роль в обществе, будучи записана на магнитную или фото пленку, или поступая в реальном масштабе времени от аудио или визуальных датчиков в аналоговой или цифровой форме. В то время как аудиовизуальная информация первоначально предназначалась для людей, в настоящее время все чаще такие данные генерируются и передаются и воспринимаются компьютерными системами. Это может быть, например, сопряжено с распознаванием голоса или изображения и медийным преобразованием (голос в текст, картинку в голос, голос в картинку, и т.д.). Другими сценариями являются извлечение информации (быстрый и эффективный поиск для различных типов мультимедийных документов, представляющих интерес для пользователя) и фильтрация потоков описаний аудиовизуального материала (чтобы получить только те элементы мультимедиа данных, которые удовлетворяют предпочтениям пользователя). Например, программа во время телепередачи запускает соответствующим образом программируемый VCR, чтобы записать эту программу, или сенсор изображения выдает предупреждение, когда происходит определенное событие. Автоматическое транскодирование может быть выполнено для строки символов, преобразовав ее в аудиоданные, или можно провести поиск в потоке аудио или видео данных. Во всех этих примерах, аудио-визуальная информация была приемлемым образом закодирована, что позволяет программе ЭВМ предпринять соответствующие действия.
Аудиовизуальные источники будут играть в перспективе все большую роль в нашей жизни, и будет расти необходимость обрабатывать такие данные. Это делает необходимым обработку видов аудиовизуальной информации, имеющей волновую форму, компрессированный формат (такой как MPEG-1 и MPEG-2) или даже объектно-ориентированный (такой как MPEG-4) формат. Необходимы формы презентации, которые позволяют некоторую степень интерпретации смысла информации. Эти формы могут быть переданы в, или доступны для прибора или программы ЭВМ. В примерах приведенных выше датчики изображения могут генерировать визуальные данные не в форме PCM (значения пикселей), а в форме объектов с ассоциированными физическими величинами и временной информацией. Эти объекты могут быть запомнены и обработаны с целью проверки, выполняются ли определенные условия. Видео записывающий прибор может получить описания аудиовизуальной информации, ассоциированной с программой, которая при выполнении заданных условий выдаст команду на запись, например, только новости за исключением спорта или запись фильма с автоматическим вырезанием вставок рекламы (согласитеь, об этом сегодня можно только мечтать).
MPEG- 7 будет стандартом для описания мультимедийных данных, которые поддерживают определенные операционные требования. MPEG не стандартизует приложения. MPEG может, однако использовать приложения для понимания требований и развития технологий. Должно быть ясно, что требования, сформулированные в данном документе, получены из анализа широкого диапазона потенциальных приложений, которые могут использовать описания MPEG-7. MPEG-7 не ориентирован на какое-то конкретное приложение; скорее, элементы, которые стандартизует MPEG-7, будут поддерживать максимально широкий диапазон приложений.
1.2. Цель MPEG-7
В октябре 1996, группа MPEG начала разработку проблем, рассмотренных выше. Новым элементом семейства MPEG стал интерфейс описаний мультмедийного материала, называемый “Multimedia Content Description Interface” (или сокращенно MPEG-7), целью которого явилась стандартизация базовых технологий, позволяющих описание аудио-визуальных данных в рамках мультимедийной среды.
Аудиовизуальный материал MPEG-7 может включать в себя: статические изображения, графику, 3D модели, звук, голос, видео и композитную информацию о том, как эти элементы комбинируются при мультимедийной презентации. В особых случаях этих общих видов данных сюда может включаться выражения лица и частные характеристики личности.
Средства описаний MPEG-7 однако не зависят от способа кодирования и записи материала. Можно сформировать описание MPEG-7 аналогового фильма или картинки, которая напечатана на бумаге, точно также, как и цифрового материала.
MPEG-7, как и другие объекты семейства MPEG, предоставляют стандартное представление аудио-визуальных данных, удовлетворяющих определенным требованиям. Одной из функций стандарта MPEG-7 является обеспечение ссылок на определенные части мультимедийного материала. Например, дескриптор формы, используемый в MPEG-4, может оказаться полезным в контексте MPEG-7, точно также Это может относиться к полям вектора перемещения, используемым в MPEG-1 и MPEG-2.
В своих описаниях MPEG-7 допускает различную гранулярность, предлагая возможность существования различных уровней дискриминации. Хотя описание MPEG-7 не зависит от кодового представления материала, он может использовать преимущества, предоставляемые кодированным материалом MPEG-4. Если материал кодирован с использованием MPEG-4, который предоставляет средства кодирования аудио-визуального материала, в виде объектов, имеющих определенные связи во времени (синхронизация) и в пространстве (на сцене для видео или в комнате для аудио), будет возможно связать описания с элементами (объектами) в пределах сцены, такими как аудио и видео объекты.
Так как описательные характеристики должны иметь смысл в контексте приложения, они будут различными для разных приложений. Это подразумевает, что один и тот же материал может быть описан различным образом в зависимости от конкретного приложения. Возьмем в качестве примера визуальный материал: нижним уровнем абстракции будет описание, например, формы, размера, текстуры, цвета, движения (траектории) и позиции ("где на сцене может размещаться объект"). А для аудио: ключ, тональность, темп, вариации темпа, положение в звуковом пространстве. Высшим уровнем представления будет семантическая информация: "Это сцена с лающей коричневой собакой слева и голубым мячом, падающим справа, с фоновым звуком проезжающих авто". Могут существовать промежуточные уровни абстракции.
Уровень абстракции относится к способу выделения определенных характеристик: многие характеристики нижнего уровня могут быть выделены полностью автоматически, в то время как характеристики высокого уровня требуют большего взаимодействия с человеком.
Кроме описания материала, требуется также включить другие виды информации о мультимедийных данных:
Форма. Примером формы является используемая схема кодирования (например, JPEG, MPEG-2), или общий объем данных. Эта информация помогает определить, может ли материал быть воспринят пользователем.
Условия доступа к материалу. Это включает учет ограничений на использование материала, учитывающих авторские права и права собственности, а также цену.
Классификация. Это включает оценку происхождения материала и его классификацию по предопределенным категориям.
Связь сдругим важным материалом. Информация может помочь пользователю ускорить поиск.
Контекст. В случае записанного документального материала, очень важно знать обстоятельства записи (например, олимпийские игры 1996, финал of 200-метрового забега для мужчин с барьерами)
Во многих случаях будет желательно использовать для описания текстовые данные. Необходимо позаботиться о том, чтобы полезность описаний была независима по возможности от языка. Хорошим примером текстуального описания является указания авторов, названия фильма и пр.
Следовательно, средства MPEG-7 позволят формировать описания (т.e., наборы схем описания и соответствующих дескрипторов по желанию пользователя) материала, который может содержать:
Информацию, описывающую процессы создания и производства материала (директор, заголовок, короткометражный игровой фильм)
Информацию, относящуюся к использованию материала (указатели авторского права, история использования, расписание вещания)
Информация о характеристиках записи материала (формат записи, кодирование)
Структурная информация о пространственных, временных или пространственно-временных компонентах материала (разрезы сцены, сегментация областей, отслеживание перемещения областей)
Информация о характеристиках материала нижнего уровня (цвета, текстуры, тембры звука, описание мелодии)
Концептуальная информация о реальном содержании материала (объекты и события, взаимодействие объектов)
Информация о том, как эффективно просматривать материал (конспекты, вариации, пространственные и частотные субдиапазоны, ...)
Информация о собрании объектов.
Информация о взаимодействии пользователя с материалом (предпочтения пользователя, история использования)
Все эти описания являются, конечно, эффективно закодированными для поиска, отбора и т.д.
Чтобы удовлетворить этому многообразию дополнительных описаний материала, MPEG-7 осуществляет описание материала с нескольких точек зрения. Наборы средств описаний, разработанные с учетом этих точек зрения, представляются в виде отдельных объектов. Однако они взаимосвязаны и могут комбинироваться множеством способов. В зависимости от приложения, некоторые будут присутствовать, а другие отсутствовать, а могут присутствовать лишь частично.
Описание, сформированное с помощью средств MPEG-7, будет ассоциировано с самим материалом, чтобы позволить быстрый и эффективный поиск и фильтрацию материала, представляющего интерес для пользователя.
Данные MPEG-7 могут физически размещаться вместе с ассоциированным AВ-материалом, в том же информационном потоке или в той же системе памяти, но описания могут также размещаться на другом конце света. Когда материал и его описания размещены не совместно, необходим механизм для соединения AВ-материала и его описаний MPEG-7; эти связи должны работать в обоих направлениях.
Тип материала и запрос могут не совпадать; например, визуальный материал может быть запрошен, используя визуальное содержимое, музыка, голос, и т.д. Согласование данных запроса и описания MPEG-7 выполняется поисковыми системами и агентами фильтрации.
MPEG-7 относится ко многим различным приложениям в самых разных средах. Этот стандарт должен обеспечивать гибкую и масштабируемую схему описания аудио-визуальных данных. Следовательно, MPEG-7 не определяет монолитную систему описания материала, а предлагает набор методов и средств для различных подходов описания аудио-визуального материала. MPEG-7 сконструирован так, чтобы учесть все подходы, учитывающие требования основных стандартов, таких как, SMPTE Metadata Dictionary, Dublin Cилиe, EBU P/Meta, и TV Anytime. Эти стандарты ориентированы на специфические приложения и области применения, в то время как MPEG-7 пытается быть как можно более универсальным. MPEG-7 использует также схему XML в качестве языка выбора текстуального представления описания материала. Главными элементами стандарта MPEG-7 являются:
Дескрипторы (D). Представление характеристик, которые определяют синтаксис и семантику представления каждой из характеристик.
Схемы описания DS
(Description Scheme), которые специфицируют структуру и семантику взаимодействия между компонентами. Эти компоненты могут быть дескрипторами
и схемами описания.
Язык описания определений
DDL (Description Definition Language), позволяющий создавать новые схемы описания и, возможно, дескрипторы и обеспечивающий расширение и модификацию существующих схем описания,
Системные средства
служат для поддержки мультиплексирования описаний, синхронизации описаний и материала, механизмов передачи, кодовых представлений (как текстуальных, так и двоичных форматов) для эффективной записи и передачи, управления и защиты интеллектуальной собственности в описаниях MPEG-7.
1.3. Область действия стандарта
MPEG-7 относится к приложениям, которые могут осуществлять запись (или реализовать поточную передачу, например, производить широковещательную пересылку в Интернет), и могут работать как в реальном времени так и off-line. ‘Среда реального времени’ в данном контексте означает, что описание генерируется в процессе приема материала.
На рис. 1 показана блок-схема системы обработки данных MPEG-7. Чтобы полностью использовать возможности описаний MPEG-7, автоматическое извлечение характеристик (или ‘дескрипторов’) может оказаться особенно заметным. Ясно также, что автоматическое извлечение не всегда возможно. Как было указано выше, чем выше уровень абстракции, тем труднее автоматическое извлечение характеристик, и тем полезнее интерактивные средства.

Рис. 1. Область MPEG-7.
Чтобы улучшить понимание терминологии введенной выше (т.e. дескриптор, схема описания и DDL), рассмотрите рис.2 и рис. 3.
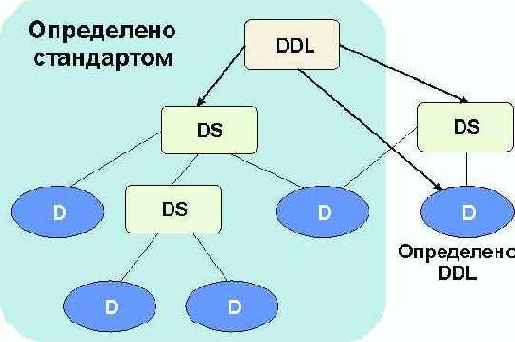
Рис. 2. Взаимодействие различных элементов MPEG-7
На рис. 2 продемонстрирована масштабируемость рассмотренной концепции. Более того, там показано, что DDL предоставляет механизм построения схемы описания, которая в свою очередь образует основу для формирования описания (см. также рис. 3).
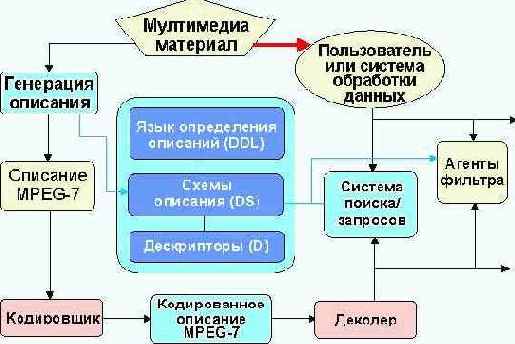
Рис. 3. Абстрактное представление возможных приложений на основе MPEG-7
Овалами обозначены средства, которые выполняют операции, такие как кодирование или декодирование, в то время как прямоугольниками отмечены статические элементы, такие как описания. Пунктирные прямоугольники на рисунке окружают нормативные элементы стандарта MPEG-7.
Главной задачей MPEG-7 будет предоставление новых решений для описания аудио-визуального материала. Таким образом, чисто текстовые документы не являются объектами MPEG-7. Однако аудио-визуальный материал может содержать и сопряженный с ним текст. MPEG-7 будет, следовательно, рассматривать и поддерживать существующие решения, разработанные другими организациями стандартизации для текстовых документов.
Помимо самих дескрипторов на рабочие характеристики системы довольно сильно влияют DB-структуры. Чтобы быстро решить, представляет ли данный материал какой-то интерес, нужно структурировать индексную информацию, например, иерархическим или ассоциативным способом.
1.4. Область применения MPEG-7
Элементы, которые стандартизует MPEG-7, будут поддерживать широкий диапазон приложений (например, мультимедийные цифровые библиотеки, выбор широковещательного медийного материала, мультимедийное редактирование, домашние устройства для развлечений и т.д.). MPEG-7 сделает возможным мультимедийный поиск в WEB столь же простым, как и текстовый. Это станет применимо для огромных архивов, которые станут доступны для широкой публики, это придаст новый стимул для электронной торговли, так как покупатели смогут искать нужный товар по видеообразцам. Информация, используемая для извлечения материала, может также применяться агентами
для отбора и фильтрации широковещательного материала или целевой рекламы. Кроме того, описания MPEG-7 позволят быстрые и эффективные с точки зрения затрат полуавтоматические презентации и редактирование.
Все области применения, базирующиеся на мультимедиа, выиграют от использования MPEG-7. Ниже предлагается список возможных приложений MPEG-7, которые любой из читателей без труда сможет дополнить:
Архитектура, недвижимость и интерьерный дизайн (например, поиск идей)
Выбор широковещательного медийного канала (например, радио, TV)
Услуги в сфере культуры (исторические музеи, картинные галереи и т.д.)
Цифровые библиотеки (например, каталоги изображений, музыкальные словари, биомедицинские каталоги изображений, фильмы, видео и радио архивы)
E-коммерция (например, целевая реклама, каталоги реального времени, каталоги электронных магазинов)
Образование (например, депозитарии мультимедийных курсов, мультимедийный поиск дополнительных материалов)
Домашние развлечения (например, системы управления личной мультимедийной коллекцией, включая манипуляцию содержимым, например, Редактирование домашнего видео, поиск игр, караоке)
Исследовательские услуги (например, распознавание человеческих особенностей, экспертизы)
Журнализм (например, поиск речей определенного политика, используя его имя, его голос или его лицо)
Мультимедийные службы каталогов (например, Желтые страницы, туристская информация, географические информационные системы
Мультимедийное редактирование (например, персональная электронная служба новостей, персональная медийная среда для творческой деятельности)
Удаленное опознавание (например, картография, экология, управление природными ресурсами)
Осуществление покупок (например, поиск одежды, которая вам нравится)
Надзор (например, управление движением, транспортом, неразрушающий контроль в агрессивной среде)
В принципе, любой тип аудио-визуального материала может быть получен с помощью любой разновидности материала в запросе. Это означает, например, что видео материал может быть запрошен с помощью видео, музыки, голоса и т.д. Ниже приведены примеры запросов:
Проиграйте несколько нот на клавиатуре и получите список музыкальных отрывков, сходных с проигранной мелодией, или изображений, соответствующим некоторым образом нотам, например, в эмоциональном плане.
Нарисуйте несколько линий на экране и найдете набор изображений, содержащих похожие графические образы, логотипы, идеограммы,...
Определите объекты, включая цветовые пятна или текстуры и получите образцы, среди которых вы выберете интересующие вас объекты.
Опишите действия и получите список сценариев, содержащих эти действия.
Используя фрагмент голоса Паваротти, получите список его записей, видео клипов, где Паваротти поет, и имеющийся графический материал, имеющий отношение к этому певцу.
1.5. План и метод работы
Метод разработки совместим с тем, что регламентировано в предыдущих стандартах MPEG. Работа над MPEG обычно выполнялась в три этапа: определение, соревнование и сотрудничество. На первой фазе определяется область действия и требования, предъявляемые к стандарту MPEG-7. На следующем этапе участники работают над различными технологиями самостоятельно. Результатом этого этапа является выработка документа CfP (Call for Proposals). В разработке стандарта участвовало около 60 коллективов, было получено 400 предложений.
Выбранные элементы различных предложений на завершающей фазе инкорпорированы в общую модель (eXperimentation Model или XM) стандарта. Целью являлось построение наилучшей модели, которая по существу представляла собой проект стандарта. На завершающей фазе, XM последовательно актуализовалась до тех пор, пока MPEG-7 в октябре 2000 года не достиг уровня CD (Committee Draft). Дальнейшее усовершенствование XM осуществлялось посредством базовых экспериментов (CE - Core Experiments). CE призваны протестировать существующие средства с учетом новых возможностей и предложений. Наконец все части XM (или рабочего проекта), которые соответствуют нормативным элементам MPEG-7, были стандартизованы.
1.6. Части MPEG-7
Стандарт MPEG-7 состоит из следующих частей:
Системы MPEG-7. Средства, которые необходимы при подготовке описаний MPEG-7 для эффективной передачи и записи, и для обеспечения синхронизации между материалом и описаниями. Эти средства имеют также отношение к охране интеллектуальной собственности.
Язык описания определений MPEG-7. Язык для определения новых схем описания и, возможно, новых дескрипторов.
MPEG-7 Audio – дескрипторы
и схемы описания, имеющие отношение исключительно к описанию аудио материала.
MPEG-7 Visual – дескрипторы
и схемы описания, имеющие отношение исключительно к описанию визуального материала
MPEG-7 Multimedia Description Schemes - дескрипторы и схемы описания, имеющие отношение к общим характеристикам описаний мультимедиа.
MPEG-7 Reference Software – программные реализации соответствующих частей стандарта MPEG-7
MPEG-7 Conformance – базовые принципы и процедуры тестирования рабочих характеристик практических реализаций MPEG-7.
1.7. Структура документа
Данный обзорный документ делится на 4 части, не считая введения и приложений. Каждая часть делится на несколько секций, характеризующих различные стороны MPEG-7 [2].
секция 2 описывает основные функции,
секция 3 содержит детальное техническое описание, а
секция 4 содержит список FAQ (Frequently Asked Questions).
2. Главные функции MPEG-7
2.1. Системы MPEG-7
Системы MPEG-7 будут включать в себя средства, которые необходимы для подготовки описаний MPEG-7 для эффективной транспортировки и запоминания, а также позволяют синхронизовать мультимедийный материал и описания и средства, сопряженные с управлением и защитой интеллектуальной собственности. Стандарт определяет архитектуру терминала и нормативных интерфейсов.
2.2. Язык описания определений MPEG-7
Согласно определению в MPEG-7 язык описания определений DDL (Description Definition Language) представляет собой:
“... язык, который позволяет формировать новые схемы описания и, возможно, дескрипторы. Он также позволяет расширение и модификацию существующих схем описания”.
В качестве основы DDL был выбран язык XML. Как следствие, DDL может быть поделен на следующие логические нормативные компоненты:
-Структурная схема языковых компонентов XML;
-Компоненты типа данных схемы;
-Специфические расширения MPEG-7.
2.3. Аудио MPEG-7
Окончательный проект аудио MPEG-7 представляет шесть технологий: система аудио описаний (которая включает в себя дерево шкал и низкоуровневые дескрипторы), средства описания звуковых эффектов, средства описания тембра инструмента, описание голосового материала, сегмент молчания и дескрипторы мелодии, облегчающие обработку запросов.
2.4. Визуальный MPEG-7
Средства визуального описания MPEG-7, включенные в CD/XM состоят из базовых структур и дескрипторов, которые характеризуют следующие визуальные характеристики:
Цвет
Текстура
Форма
Движение
Локализация
Прочие
Каждая категория состоит из элементарных и сложных дескрипторов.
2.5. Основные объекты и схемы описания мультимедиа MPEG-7
Базисом схем описания мультимедиа MDS (Multimedia Description Schemes) является стандартизация набора средств описания (дескрипторы и схемы описания), имеющие дело с общими и мультимедийными объектами.
Общими объектами являются характеристики, которые используются в аудио, видео и текстовых описаниях и, следовательно, характеризуют все медийные типы материала. Такими характеристиками могут быть, например, вектор, время и т.д.
Помимо этого набора общих средств описания стандартизованы более сложные средства описания. Они используются, когда нужно описать более одного вида медийного материала (например, аудио и видео). Эти средства описания могут быть сгруппированы в 5 различных классов согласно их функциональному предназначению:
Описание материала: представление воспринимаемой информации;
Управление материалом: информация о характере медийного материала, формирование и использование АВ материала;
Организация материала: представление анализа и классификации нескольких AВ материалов;
Поиск и доступ: спецификация кратких характеристик и изменений АВ-материала;
Взаимодействие с пользователем: описание предпочтений пользователя и истории использования мультимедийного материала.
2.6. Эталонные программы MPEG-7: модель экспериментов (eXperimentation Model)
Программное обеспечение модели XM (eXperimentation Model) представляет собой систему моделирования для дескрипторов
MPEG-7 (D), схем описания (DS), схем кодирования (CS), языка описания определений (DDL). Кроме нормативных компонентов, системе моделирования необходимы некоторые дополнительные элементы, существенные при исполнении некоторых процедурных программ. Структуры данных и процедурные программы образуют приложения. Приложения XM образуют две разновидности: приложения клиента и сервера.
3. Детальное техническое описание стандарта MPEG-7
3.1. Системы MPEG-7
Системы MPEG-7 в настоящее время определяет архитектуру терминала и нормативных интерфейсов.
3.1.1. Архитектура терминала
Представление информации, специфицированное в стандарте MPEG-7 предоставляет средства описаний кодированного мультимедийного материала. Объект, который использует такое кодовое представление мультимедийного материала, называется "терминалом". Этот терминал может соответствовать отдельно стоящему приложению или быть целой прикладной системой. Архитектура такого терминала изображена на рис. 4, а его работа описана ниже.
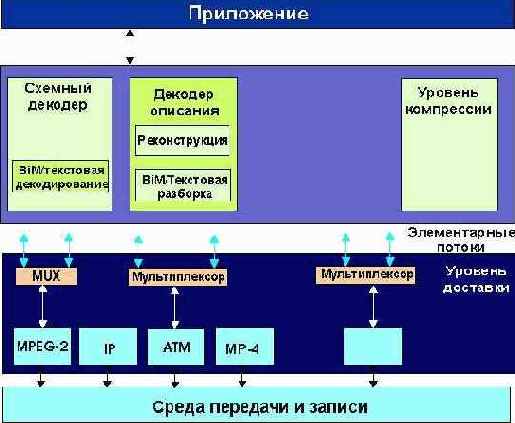
Рис. 4. Архитектура MPEG-7
В нижней части рис. 4 размещена система передачи/записи. Это относится к нижнему уровню инфраструктуры доставки (сетевой уровень и ниже). Эти уровни передают мультиплексированные потоки данных уровню доставки. Транспортная среда MPEG-7 базируется на многих системах доставки данных. Это включает, например, транспортные потоки MPEG-2, IP или MPEG-4 (MP4) файлы или потоки. Уровень доставки реализует механизмы, позволяющие выполнять синхронизацию, формирование кадров и мультиплексирование материала MPEG-7. Материал MPEG-7 может быть доставлен независимо или вместе с данными, которые он описывает. Архитектура MPEG-7 позволяет передавать данные (например, запросы) назад из терминала к отправителю или серверу.
Уровень доставки предоставляет уровню сжатия MPEG-7 элементарные потоки. Элементарные потоки MPEG-7 состоят из последовательности индивидуально доступных порций данных, называемых блоками доступа (Access Units). Блок доступа является наименьшим информационным объектом, к которому может относиться временная информация. Элементарные потоки MPEG-7 содержат данные различной природы:
Схемная информация: эта информация определяет структуру описания MPEG-7;
Информация описаний: эта информация является либо полным описанием мультимедийного материала или фрагментами такого описания.
Уровень доставки приложения может также по запросу доставлять мультимедийный материал. Для этих целей могут использоваться существующие средства доставки.
Данные MPEG-7 могут быть представлены либо в текстовом, либо в двоичном формате, или в виде комбинации этих форматов, в зависимости от типа приложения. MPEG-7 определяет однозначную связь между двоичным и текстовым форматами. Возможно установление двухсторонней однозначной связи между текстовым и двоичным представлениями. Следует заметить, что это не всегда доступно: некоторые приложения могут не захотеть передавать всю информация, содержащуюся в текстовом представлении, а могут предпочесть использовать более эффективную с точки зрения полосы двоичную кодировку с потерями.
Синтаксис текстуального формата определен в части 2 (DDL - Description Definition Language) стандарта. Синтаксис двоичного формата (BiM - двоичный формат для данных MPEG-7) определен в части 1 (системы) стандарта. Схемы определены в частях 3, 4 и 5 (визуальная, аудио и схемы описания мультимедиа) стандарта.
На уровне компрессии, производится разборка потока блоков доступа (текстуальных или двоичных), а описания материала реконструируются. MPEG-7 не перепоручает реконструкцию текстуального представления в качестве промежуточного шага декодирующему процессу. Двоичный поток MPEG-7 может быть разобран с помощью BiM, передан в текстовом формате и затем в этом виде транспортирован для последующей реконструкционной обработки, или двоичный поток может быть разобран BiM и затем передан в подходящем формате для последующей обработки.
Блоки доступа MPEG- 7 далее структурируются как команды, в которые инкапсулированы схемы описания. Команды придают материалу MPEG-7 динамический вид. Они позволяют пересылать описания одним куском или в виде небольших фрагментов. Команды делают возможными базовые операции с материалом MPEG-7, такие как актуализация дескриптора, удаление части описания или добавление новой структуры DDL. На реконструкционном этапе уровня компрессии выполняется актуализация описания и соответствующих схем посредством указанных команд.
3.1.2. Нормативные интерфейсы
3.1.2.1. Описание нормативных интерфейсов
MPEG-7 имеет два нормативных интерфейса, как это показано на рис. 5.
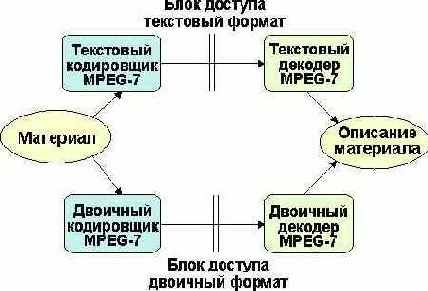
Рис. 5. Нормативные интерфейсы MPEG-7
Материал: это данные, которые должны быть представлены согласно формату, описанному в данной спецификации. Под материалом подразумеваются сами медийные данные, либо их описание.
Двоичный/текстовый кодировщик MPEG-7: программа, осуществляющая преобразование материала к формату, который согласуется с данной спецификацией. Это может включать комплексное преобразование материала с целью извлечения деталей.
Интерфейс текстового формата. Этот интерфейс описывает формат текстуальных блоков доступа. Текстовый декодер MPEG-7 воспринимает поток таких блоков доступа и реконструирует описание материала нормативным способом.
Интерфейс двоичного формата. Этот интерфейс описывает формат двоичных блоков доступа. Двоичный декодер MPEG-7 воспринимает поток таких блоков доступа и реконструирует описание материала нормативным способом.
Двоичный/текстовый декодер MPEG-7.
Программа, осуществляющая преобразование материала к формату, который согласуется с данной спецификацией.
3.1.2.2. Верификация стандарта
В данном разделе описывается, как проверяется то, что двоичное и текстуальное представление являются адекватными одному и тому же материалу. Этот процесс описан на рис. 6.
Рис. 6 - Процесс верификации
Кроме элементов описанных в разделе 3.1.2.1, процесс валидации включает определение канонического представления описания материала. В каноническом пространстве, описания материала могут быть сравнены. Процесс валидации работает следующим образом:
Описание материала преобразуется в текстуальный и двоичный форматы без потерь, генерируя два разных представления одного и того же материала.
Два кодированных описания декодируются соответствующими двоичным и текстовым декодерами.
Из реконструированных описаний материала генерируются два канонических описания.
Два канонических описания должны быть эквивалентны.
Описание канонической презентации XML-документа определено в Canonical XML[3].
3.2. Язык описания определений MPEG-7 (DDL)
Главными средствами, используемыми в описаниях MPEG-7 являются DDL (Description Definition Language), схемы описаний (DS) и дескрипторы (D). Дескрипторы связывают характеристики с набором их значений. Схемы описания являются моделями мультимедийных объектов и всего многообразия элементов, которые они представляют, например, модели данных описания. Они специфицируют типы дескрипторов, которые могут быть использованы в данном описании, и взаимоотношения между этими дескрипторами или между данными схемами описания.
DDL образует центральную часть стандарта MPEG-7. Он обеспечивает надежную описательную основу, с помощью которой пользователь может создать свои собственные схемы описания и дескрипторы. DDL определяет семантические правила выражения и комбинации схем описания и дескрипторов.
DDL не является языком моделирования, таким как UML (Unified Modeling Language), а языком схем для представления результатов моделирования аудио-визуальных данных, например, DS и D.
DDL должен удовлетворять требованиям MPEG-7 DDL. Он должен быть способен выражать пространственные, временные, структурные и концептуальные взаимоотношения между элементами DS и между DS. Он должен предоставить универсальную модель для связей и ссылок между одним или более описаниями и данными, которые им описываются. Кроме того, язык не должен зависеть от платформы и приложения и быть читаемым как машиной, так и человеком. MPEG-7 должен базироваться на синтаксисе XML. Необходима также система разборки DDL (парсинга), которая должна быть способна проверять схемы описания (материал и структуру) и дескрипторы типа данных, как примитивные (целые, текст, дата, время) так и составные (гистограммы, нумерованные типы).
3.2.1. Разработка контекста
Так как схемный язык XML не был специально разработан для аудио-визуального материала, необходимы определенные расширения, для того чтобы удовлетворить всем требованиям MPEG-7 DDL.
3.2.2. Обзор схемы XML
Целью схемы является определение класса XML-документов путем использования конкретных конструкций, чтобы наложить определенные ограничения на их структуру: элементы и их содержимое, атрибуты и их значения, количество элементов и типы данных. Схемы можно рассматривать, как некоторые дополнительные ограничения на DTD.
Главной рекомендацией MPEG-7 AHG было использование схемы, базирующейся на XML. В начале разработки имелось много решений, но ни одно из них не оказалось достаточно стабильным. В исходный момент группа DDL решила разработать свой собственный язык, следуя принципам, используемым группой W3C при подготовке схемы XML. В апреле 2000, рабочая группа W3C XML опубликовала последнюю версию спецификации схемы XML 1.0. Улучшенная стабильность схемного языка XML, его потенциально широкое поле применения, доступность средств и программ разборки, а также его способность удовлетворить большинству требований MPEG-7, привели к тому, что схема XML явилась основой DDL. Однако так как схема XML не была разработана специально для аудио-визуального материала, необходимы некоторые специфические расширения. DDL делится на следующие логические нормативные компоненты:
Схемные структурные компонентыXML;
Схемные компоненты типа данных XML;
Расширениядля XML схемы MPEG-7.
3.2.3. Схема XML: Структуры
Схема XML: Структуры являются частью 2-частной спецификации XML-схемы. Она предоставляет средства для описания структуры и ограничений, налагаемых на материалы документов XML 1.0. Схема XML состоит из набора компонентов структурной схемы, которые могут быть разделены на три группы. Первичными компонентами являются:
Схема - внешний уровень определений и деклараций;
Определения простых типов;
Определения составных типов;
Декларации атрибутов;
Декларации элементов.
Вторичными компонентами являются:
Определения группы атрибутов;
Определения ограничений идентичности;
Определения группы;
Декларации нотации.
Третья группа образована компонентами “helper”, которые входят в другие компоненты и не могут существовать отдельно:
Аннотации;
Фрагменты (Particles);
Произвольные подстановки (Wildcards).
Определения типа задают внутренние компоненты схемы, которые могут использоваться в других компонентах, таких как элементы, атрибуты деклараций или другие определения типа. Схема XML предоставляет два вида компонентов определения типа:
простые типы - являющиеся простыми типами данных (встроенными или вторичными), которые не могут иметь каких-либо дочерних элементов или атрибутов;
составные типы - которые могут нести в себе атрибуты и иметь дочерние элементы, или быть получены из других простых или составных типов.
Новые типы могут быть также определены на основе существующих типов (встроенных или вторичных) путем расширения базового типа. Детали использования этих компонентов можно найти в проекте DDL или в схеме XML: Спецификация структур.
3.2.4. Схема XML: Типы данных
XML Schema:Datatypes является второй частью 2-частной схемной спецификации XML. Она предлагает возможности определения типов данных, которые могут быть использованы для ограничения свойств типов данных элементов и атрибутов в рамках схем XML. Она предлагает более высокую степень проверки типа, чем доступна для XML 1.0 DTD:
набор встроенных примитивных типов данных;
набор встроенных вторичных типов данных;
механизмы, с помощью которых пользователи могут определить свой собственный вторичный тип данных.
Подробные детали встроенных типов данных и механизмы получения вторичных типов можно найти в окончательном проекте DDL или в спецификации XML Schema:Datatypes.
3.2.5. Расширения схемы XML MPEG-7
Следующие характеристики будет нужно добавить к спецификации языка XML для того, чтобы удовлетворить специфическим требованиям MPEG-7:
Массив и матрица типов - как фиксированного, так и параметризованного размеров;
Встроенные примитивные временные типы данных: basicTimePoint и basicDuration.
Программы разборки, специфические для MPEG-7 будут разработаны путем добавления валидации этих дополнительных конструкций к стандартным схемным разборщикам XML.
3.3. Аудио MPEG-7
Аудио MPEG-7 FCD включает в себя пять технологий: структура аудио описания (которая включает в себя масштабируемые последовательности, дескрипторы нижнего уровня и униформные сегменты тишины), средства описания тембра музыкального инструмента, средства распознавания звука, средства описания голосового материала и средства описания мелодии.
3.3.1. Описание системы аудио MPEG-7
Аудио структура содержит средства нижнего уровня, созданные для обеспечения основы для формирования аудио приложений высокого уровня. Предоставляя общую платформу структуры описаний, MPEG-7 Аудио устанавливает базис для совместимости всех приложений, которые могут быть созданы в рамках данной системы.
Существует два способа описания аудио характеристик нижнего уровня. Один предполагает стробирование уровня сигнала на регулярной основе, другой может использовать сегменты (смотри описание MDS) для пометки сходных и отличных областей для заданного звукового отрывка. Обе эти возможности реализованы в двух типах дескрипторов нижнего уровня (один для скалярных величин, таких как мощность или частота, и один для векторов, таких как спектры), которые создают совместимый интерфейс. Любой дескриптор, воспринимающий эти типы может быть проиллюстрирован примерами, описывающими сегмент одной результирующей величиной или последовательностью результатов стробирования, как этого требует приложение.
Величины, полученные в результате стробирования, сами могут подвергаться последующей обработке с привлечением другого унифицированного интерфейса: они могут образовать масштабируемые ряды (Scalable Series). Дерево шкал может также хранить различные сводные значения, такие как минимальное, максимальное значение дескриптора и его дисперсию.
Аудио дескрипторы нижнего уровня имеют особую важность при описании звука. Существует семнадцать временных и пространственных дескрипторов, которые могут использоваться в самых разных приложениях. Они могут быть грубо поделены на следующие группы:
Базовая: мгновенные значения уровня волнового сигнала и мощности.
Базовая спектральная: частотный спектр мощностей, спектральные характеристики, включая среднее значение, спектральная полоса и спектральная однородность.
Параметры сигнала: фундаментальная частота квазипериодических сигналов и гармоничность сигналов.
Временная группа по тембру: временной центроид
Спектральная группа по тембру: специфические спектральные характеристики в линейном пространстве частот, включая спектральный центроид и спектральные свойства, специфические для гармонической частей сигналов, включая спектральное смещение и спектральную ширину.
Представления спектрального базиса: характеристики, используемые первично для распознавания звука.
Каждый из них может использоваться для описания сегмента с результирующим значением, которое применяется для всего сегмента или для последовательности результатов стробирования. Временная группа по тембру (Timbral Temporal) является исключением, так как ее значения приложимы только к сегменту, как целому.
В то время как аудио дескрипторы нижнего уровня вообще могут служить для многих возможных приложений, дескриптор однородности спектра поддерживает аппроксимацию сложных звуковых сигналов. Приложения включают в себя голосовую идентификацию.
Кроме того, очень простым, но полезным средством является дескриптор тишины. Он использует простую семантику "тишины" (то есть отсутствие значимого звука) для аудио сегмента. Такой дескриптор может служить для целей дальнейшей сегментации аудио потока.
3.3.2. Средства описания аудио верхнего уровня (D и DS)
Четыре набора средств описания аудио, которые приблизительно представляют области приложения, интегрированы в FCD: распознавание звука, тембр музыкального инструмента, разговорный материал и мелодическая линия.
3.3.2.1. Средства описания тембра музыкальных инструментов
Дескрипторы тембра служат для описания характеристик восприятия звуков. Тембр в настоящее время определен в литературе как характеристика восприятия, которая заставляет два звука, имеющих одну высоту и громкость, восприниматься по-разному. Целью средства описания тембра является представление этих характеристик восприятия сокращенным набором дескрипторов. Дескрипторы относятся к таким понятиям как “атака”, “яркость” или “богатство” звука.
В рамках четырех возможных классов звуков музыкальных инструментов, два класса хорошо детализированы, и являются центральным объектом экспериментального исследования. В FCD представляются гармонические, когерентные непрерывные звуки и прерывистые, ударные звуки. Дескриптор тембра для непрерывных гармонических звуков объединяет спектральные дескрипторы тембра с временным дескриптором log attack. Дескриптор ударных инструментов комбинирует временные дескрипторы тембра с дескриптором спектрального центроида. Сравнение описаний, использующих один из наборов дескрипторов выполняется с привлечением метрики масштабируемого расстояния.
3.3.2.2. Средства распознавания звука
Схемы дескрипторов и описаний распознавания звука, представляют собой наборы средств для индексирования и категорирования звуков, с немедленным использованием для звуковых эффектов. Добавлена также поддержка автоматической идентификации звука и индексация. Это сделано для систематики звуковых классов и средств для спецификации онтологии устройств распознавания звука. Такие устройства могут использоваться для автоматической индексации сегментов звуковых треков.
Средства распознавания используют в качестве основы спектральные базисные дескрипторы низкого уровня. Эти базисные функции далее сегментируются и преобразуются в последовательность состояний, которые заключают в себя статистическую модель, такую как смешанная модель Маркова или Гаусса. Эта модель может зависеть от своего собственного представления, иметь метку, ассоциированную с семантикой исходного звука, и/или с другими моделями для того, чтобы категоризовать новые входные звуковые сигналы для системы распознавания.
3.3.2.3. Средства описания содержимого сказанного
Средства описания Spoken Content
позволяет детальное описание произнесенных слов в пределах аудио-потока. Учитывая тот факт, что сегодняшнее автоматическое распознавание речи ASR-технологий (Automatic Speech Recognition) имеет свои ограничения, и что всегда можно столкнуться с высказыванием, которого нет в словаре, средства описания Spoken Content жертвует некоторой компактностью ради надежности поиска. Чтобы этого добиться, средства отображают выходной поток и то, что в норме может быть видно в качестве текущего результата автоматического распознавания речи ASR. Средства могут использоваться для двух широких классов сценария поиска: индексирование и выделение аудио потока, а также индексирование мультимедийных объектов аннотированных голосом.
Средства описания Spoken Content поделены на два широких функциональных блока: сетка, которая представляет декодирование, выполненное системой ASR, и заголовок, который содержит информацию об узнанных собеседниках и о самой системе распознавания. Сетка состоит из комбинаций слов голосовых записей для каждого собеседника в аудио потоке. Комбинируя эти сетки, можно облегчить проблему со словами, отсутствующими в словаре, и поиск может быть успешным, даже когда распознавание исходного слова невозможно.
3.3.2.4. Средства описания мелодии
DS мелодического очертания (Melody Contour) является компактным представлением информации о мелодии, которая позволяет эффективно и надежно контролировать мелодическую идентичность, например, в запросах с помощью наигрывания. DS мелодического очертания использует 5-ступенчатый контур (представляющий интервал между смежными нотами), в котором интервалы дискретизированы. DS мелодического очертания (Melody Contour DS) предоставляет также базовую информацию ритмики путем запоминания частот, ближайших к каждой из нот, это может существенно увеличить точность проверки соответствия запросу.
Для приложений, требующих большей описательной точности или реконструкции заданной мелодии, DS мелодии
поддерживает расширенный набор дескрипторов и высокую точность кодирования интервалов. Вместо привязки к одному из пяти уровней в точных измерителях используется существенно больше уровней между нотами (100 и более). Точная информация о ритмике получается путем кодирования логарифмического отношения разностей между началами нот способом аналогичным с используемым для кодирования уровней сигнала.
3.4. Визуальный MPEG-7
Средства визуального описания MPEG-7, включенные в CD/XM состоят из базовых структур и дескрипторов, которые охватывают следующие основные визуальные характеристики:
Цвет
Текстура
Форма
Движение
Локализация
Прочее
Каждая категория состоит из элементарных и составных дескрипторов.
3.4.1. Базовые структуры
Существует пять визуально связанных базовых структур: сеточная выкладка, временные ряды (Time Series), многопрекционность (MultiView), пространственные 2D-координаты и временная интерполяция (TemporalInterpolation).
3.4.1.1. Сеточная выкладка
Сетка делит изображение на равные прямоугольные области, так что каждая область может быть описана отдельно. Каждая область сетки описывается посредством других дескрипторов, таких как цвет или текстура. Более того, дескриптор позволяет ассоциировать субдескрипторы со всей прямоугольной областью, или с произвольным набором прямоугольных областей.
3.4.1.2. Многовидовые 2D-3D
Дескриптор 2D/3D специфицирует структуру, которая комбинирует 2D дескрипторы, представляющие визуальные параметры 3D-объекта, видимые с различных точек. Дескриптор образует полное 3D-представление объекта на основе его проекций. Может использоваться любой визуальный 2D-дескриптор, такой как, например, форма контура, форма области, цвет или текстура. Дескриптор 2D/3D поддерживает интеграцию 2D-дескрипторов, используемых в плоскости изображения для описания характеристик 3D-объектов (реальный мир). Дескриптор позволяет осуществлять сравнение 3D-объектов путем сравнения их проекций.
3.4.1.3. Временные ряды
Этот дескриптор определяет в видео сегменте дескрипторы временных рядов и предоставляет возможность сравнения изображения с видео-кадром и видео-кадров друг с другом. Доступно два типа временных рядов (TimeSeries): RegularTimeSeries и IrregularTimeSeries. В первом, дескрипторы размещаются регулярным образом (с постоянным шагом) в пределах заданного временного интервала. Это допускает простое представление для приложений, которые предполагают ограниченную сложность. Во втором, дескрипторы размещаются нерегулярно (с переменными интервалами) в пределах заданного временного интервала. Это обеспечивает эффективное представление для приложений, которые требуют малой полосы пропускания или малой емкости памяти. Они полезны в частности для построения дескрипторов, которые содержат временные ряды дескрипторов.
3.4.1.4. Пространственные координаты 2D
Это описание определяет 2D пространственную координатную систему, которую следует использовать в других D/DS, где это важно. Оно поддерживает два вида координатных систем: “локальную” и “интегрированную” (рис. 7). В “локальной” координатной системе, все изображения привязаны к одной точке. В “интегрированной” координатной системе, каждое изображение (кадр) может быть привязано к разным областям. Интегрированная координатная система может использоваться для представления координат на мозаичном видео снимке.
a) "Локальные" координаты b) "интегрированные" координаты
Рис. 7. "Локальная" и "интегрированная" координатная система
3.4.1.5. Временная интерполяция
TemporalInterpolation D описывает временную интерполяцию, использующую связанные многогранники. Это может использоваться для аппроксимации многомерных значений переменных, которые меняются со временем, такие как положение объекта в видео. Размер описания временной интерполяции обычно много меньше, чем описание всех величин. На рис. 8 25 реальных величин представлены пятью линейными интерполяционными функциями и двумя квадратичными интерполяционными функциями. Начало временной интерполяции всегда привязывается ко времени 0.
Рис. 8. Реальные данные и функции интерполяции
3.4.2. Описатели цвета
Существует восемь дескрипторов цвета: цветового пространства, доминантных цветов, цветовой дискретизации, GoF/GoP цвета, цветовой структуры, цветового размещения и масштабируемой гистограммы цветов.
3.4.2.1. Цветовое пространство
Понятие цветового пространства используется в других описаниях, базирующихся на цвете. В текущем описании, поддерживаются следующие цветовые пространства:
R,G,B
Y,Cr,Cb
H,S,V
HMMD
Матрица линейного преобразования с учетом R, G, B
Монохромное
3.4.2.2. Оцифровка цвета
Этот дескриптор определяет дискретизацию цветового пространства и поддерживает линейные и нелинейные преобразователи, а также lookup-таблицы. Число уровней квантования конфигурируемо так, чтобы обеспечить большую гибкость для широкого диапазона приложений. В случае нелинейного АЦП, ширина канала преобразования может также конфигурироваться. Для разумных приложений в контексте MPEG-7, этот дескриптор должен комбинироваться с другими, например, чтобы характеризовать значения в цветовой гистограмме.
3.4.2.3. Доминантный цвет(а)
Этот дескриптор цвета является наиболее удобным для представления локальных характеристик (области объекта или изображения), где для предоставления цветовой информации достаточно малого числа цветов. Могут использоваться и полные изображения, например, картинки флагов или цветных торговых марок. Квантование цвета используется для получения малого числа характерных цветов в каждой области/изображении. Соответственно вычисляется процент каждого дискретизируемого цвета в области. Определяется также пространственная когерентность всего дескриптора.
3.4.2.4. Масштабируемый цвет
Дескриптор масштабируемого цвета ( Scalable Color) является гистограммой цветов в цветном пространстве HSV, которая кодируется с помощью преобразования Хара. Ее двоичное представление является масштабируемым с точки зрения числа каналов и числа бит, характеризующих значение точности в широком диапазоне потоков данных. Дескриптор масштабируемого цвета полезен для сравнения изображений и поиска, базирующегося на цветовых характеристиках. Точность отображения возрастает с увеличением числа бит, используемых для описания.
3.4.2.5. Описатель структуры цвета
Дескриптор цветовая структура (Color Structure) является описателем цветовой характеристики, которая объединяет цветовое содержимое (аналогично цветовой гистограмме) и информацию о структуре материала. Его главная задача сравнение изображений главным образом для статических картинок. Метод выборки вводит данные о цветовой структуре в дескриптор, учитывая локально цвета окрестных пикселей, и не анализирует каждый пиксель отдельно. Дескриптор цветовая структура обеспечивает дополнительную функциональность и улучшенный поиск, базирующийся на подобии естественных изображений.
3.4.2.6. Выкладка цвета
Этот дескриптор специфицирует пространственное распределение цветов для быстрого поиска и просмотра. Его целью является не только сравнение изображений и видео клипов, но также поиск, базирующийся на раскладке цветов, такой как сравнение наброска с изображением, которое не поддерживается другими цветовыми дескрипторами. Этот дескриптор может использоваться для всего изображения или для любой его части. Данный дескриптор может также быть применен для областей произвольной формы.
3.4.2.7. Цвет GoF/GoP
Дескриптор цвета группа_кадров/группа_картинок расширяет возможности дескриптора масштабируемого цвета, который определен для статических изображений, чтобы выполнять цветовое описание видео сегментов или собрания статических изображений. Дополнительные два бита позволяют определить, была ли вычислена цветовая гистограмма, прежде чем было осуществлено преобразование Хара: для усреднения, медианы или пересечения. Усредненная гистограмма, которая соответствует усредненному значению счетчика для каждой ячейки всех кадров или изображений, эквивалентна вычислению совокупной цветовой гистограммы всех кадров или изображений с последующей нормализацией. Медианная гистограмма соответствует вычислению медианного значения счетчика для каждой ячейки совокупности кадров или изображений. Более надежно округлять ошибки и присутствие выбросов в распределении яркости изображения по сравнению с усредненной гистограммой. Гистограмма пересечения соответствует вычислению минимального значения счетчика для каждой ячейки совокупности кадров или изображений, чтобы получить цветовые характеристики “наименьшего общего” группы изображений. Заметим, что это отличается от гистограммы пересечения, которая является скалярной мерой. Аналогичные меры сходства/различия, которые используются для сравнения масштабируемых цветовых описаний, могут быть применены для сопоставления цветовых дескрипторов GoF/GoP.
3.4.3. Описатели текстуры
Существует три текстурных дескриптора: Edge Histogram, Homogeneous Texture и Texture Browsing.
3.4.3.1. Описатели однородной текстуры
Однородная текстура представляет собой важный визуальный примитив для поиска и просмотра большой коллекции выглядящих сходно образов. Изображение может рассматриваться как мозаика однородных текстур, так что эти текстурные характеристики, соответствующие областям могут использоваться для индексации визуальных данных. Например, пользователь, просматривающий абстрактную базу данных изображений, может захотеть идентифицировать различные блоки в этой коллекции изображений. Блоки с автомашинами, запаркованными регулярным образом являются хорошим примером однородного текстурного образца, рассматриваемого с большого расстояния, как это происходит при аэросъемке. Аналогично, сельскохозяйственные области и участки растительности являются другим примером однородных текстур, встречающихся при аэро и спутниковых наблюдениях. Примеры запросов, которые могут поддерживаться в этом контексте, могут включать в себя "Поиск всех спутниковых изображений Санта Барбары, которые имеют меньше чем 20% облачного покрытия" или "Найти растительный участок, который выглядит как эта область". Чтобы поддерживать такой поиск изображений, необходимо эффективное представление текстуры. Дескриптор однородной текстуры предоставляет количественное представление, используя 62 числа (по 8 бит каждое), которое удобно для поиска сходства. Получение данных осуществляется следующим образом; изображение сначала обрабатывается посредством набора фильтров Габора, настроенных на определенные ориентации и масштаб (смоделированные с помощью функций Габора). Дескриптор однородной текстуры предоставляет точное количественное описание текстуры, которое может использоваться для поиска. Вычисление этого дескриптора базируется на фильтрации.
3.4.3.2. Просмотр текстуры
Дескриптор просмотра текстуры
(Texture Browsing) полезен для представления однородной текстуры в приложениях, служащих для просмотра, и требует только 12 бит (максимум). Он предоставляет перцептуальную характеристику текстуры, аналогично человеческому описанию в терминах регулярности, шероховатости, ориентированности. Вычисление этого дескриптора осуществляется также как и дескриптора однородной текстуры. Сначала, изображение фильтруется с помощью набора специально настроенных фильтров (смоделированных посредством функций Габора); в отфильтрованном результате идентифицируются два доминантных ориентаций текстуры. Три бита используются для представления каждой из доминантных ориентаций. За этим следует анализ проекций отфильтрованного изображения вдоль доминантных направлений, чтобы определить регулярность (характеризуемую двумя битами) и загрубленность (2 бита x 2). Этот дескриптор совместно с дескриптором однородной текстуры предоставляет масштабируемое решение для представления областей изображения с однородной текстурой.
3.4.3.3. Краевая гистограмма
Дескриптор краевой гистограммы
представляет пространственное распределение пяти типов краев, в частности четырех ориентированных краев и одного неориентированного. Так как края играют важную роль для восприятия изображения, данный дескриптор помогает найти изображения со сходным семантическим значением. Таким образом, он изначально ориентирован на сравнение изображений (по образцам или наброскам), в особенности на естественные изображения с нерегулярными краями. В этом контексте, свойства системы поиска изображения могут быть существенно улучшены, если дескриптор краевой гистограммы комбинируется с другими дескрипторами, такими как дескриптор цветовой гистограммы. Кроме того, наилучшие характеристики системы поиска изображения, учитывая только этот дескриптор, достигаются путем использования полу-глобальных и глобальных гистограмм, получаемых непосредственно из дескриптора краевых гистограмм.
3.4.4. Описатели формы
Существует четыре типа дескрипторов формы: объектная форма, базирующаяся на областях, форма, базирующаяся на контурах, 3D-форма и 2D-3D множественные проекции.
3.4.4.1. Форма, базирующаяся на областях (Region-Based)
Форма объекта может состоять из одной области или набора областей, а также некоторых отверстий в объектах, как это показано на рис 9. Так как дескриптор формы, базирующейся на областях, использует все пиксели, определяющие форму в пределах кадра, он может описывать любую форму, то есть не только простые формы с односвязными областями, как на рис. 9 (a) и (b), но также сложные формы, которые содержат отверстия или несколько не соединенных областей, как показано на рис. 9 (c), (d) и (e), соответственно. Дескриптор формы, базирующейся на областях, может не только эффективно описать столь несхожие формы, но и минимизировать искажения на границах объекта.
На рис. 9 (g), (h) и (i) показаны очень схожие изображения чашки. Различия имеются только в форме ручки. Форма (g) имеет трещину на нижней части ручки, в то время как в (i) ручка не имеет отверстия. Дескриптор формы, базирующейся на областях, рассматривает (g) и (h) подобными, но отличными от (i), так как там ручка не имеет отверстия. Аналогично, на рис. 9(j-l) показана часть видео последовательности, где два диска постепенно разделяются. С точки зрения дескриптора формы, базирующейся на областях, эти картинки схожи.


Рис. 9. Примеры различной формы
Заметим, что черный пиксель в пределах объекта соответствует 1 на изображении, в то время как пиксели белого фона соответствуют 0.
Дескриптор характеризуется малым размером и быстрым временем поиска. Размер данных для представления является фиксированным и равным 17.5 байт.
3.4.4.2. Форма, основанная на контуре
Дескриптор формы, базирующейся на контуре, получает параметры формы объекта или его контур, извлеченный из описания областей. Он использует так называемое Curvature Scale-Space представление, которое воспринимает значимые параметры формы.
Дескриптор формы, базирующейся на контуре объекта, использует Curvature Scale Space представление контура. Это представление имеет несколько важных особенностей, в частности:
Оно извлекает очень хорошие характеристики формы, делая возможным поиск, основанный на сходстве.
Оно отражает свойства восприятия визуальной системы человека и предлагает хорошее обобщение.
Оно устойчиво при плавном движении.
Оно устойчиво при частичном перекрытии формы.
Оно устойчиво по отношению преобразованиям перспективы, которые являются следствием изменения параметров видеокамеры, и представляются общими для изображений и видео.
Оно компактно
Некоторые из выше перечисленных свойств проиллюстрированы на рис. 10, каждый кадр содержит весьма сходные с точки зрения CSS изображения, основанные на результате действительного поиска в базе данных MPEG-7.

Рис. 10.
На рис. 10 (a) продемонстрированы свойства обобщения формы (внешнее сходство различных форм), (b) устойчивость по отношению к плавному движению (бегущий человек), (c) устойчивость к частичному перекрытию (хвосты или ноги лошадей)
3.4.4.3. 3D-форма
Рассматривая непрерывное развитие мультимедийных технологий, виртуальных миров, 3D-материал становится обычным для современных информационных систем. В большинстве случаев, 3D-информация представляется в виде сетки многоугольников. Группа MPEG-4, в рамках подгруппы SNHC, разрабатывала технологии для эффективного кодирования модели 3D-сеток. В стандарте MPEG-7 необходимы средства для интеллектуального доступа к 3D-информации. Главные приложения MPEG-7 имеют целью поиск, получение и просмотр баз 3D-данных.
Предлагаемый дескриптор 3D- формы имеет целью предоставление внутреннего описания формы сеточных 3D-моделей. Он использует некоторые локальные атрибуты 3D-поверхности.
3.4.5. Дескрипторы перемещения
Существует четыре дескриптора перемещения: перемещение камеры, траектория перемещение объекта, параметрическое движение объекта и двигательная активность.
3.4.5.1. Движение камеры
Этот дескриптор характеризует параметры перемещения 3-D камеры. Он базируется на информационных параметрах 3-D-перемещения камеры, которые могут быть автоматически получены.
Дескриптор движения камеры поддерживает следующие стандартные операции с камерой (см. рис. 11): фиксированное положение, панорамное движение (горизонтальное вращение), слежение за движущимся объектом (горизонтальное поперечное перемещение), вертикальное вращение, вертикальное поперечное перемещение, изменение фокусного расстояния, наезд (трансфокация вдоль оптической оси) и вращение вокруг оптической оси.
Рис. 11. Перемещения камеры
Отрывок, для которого все кадры характеризуются определенным типом перемещения камеры, относящееся к одному виду или нескольким, определяет базовые модули для дескриптора перемещения камеры. Каждый составляющий блок описывает начальный момент, длительность, скорость перемещения изображения и увеличение фокусного расстояния (FOE) (или сокращение фокусного расстояния - FOC). Дескриптор представляет объединение этих составляющих блоков, он имеет опцию описания смеси типов перемещения камеры. Смешанный режим воспринимает глобальную информацию о параметрах перемещения камеры, игнорируя детальные временные данные, путем совместного описания нескольких типов движения, даже если эти типы перемещения осуществляются одновременно. С другой стороны, несмешанный режим воспринимает понятие чистых перемещений и их совмещения на протяжении определенного временного интервала. Ситуации, когда одновременно реализуется несколько типов перемещений, описывается, как суперпозиция описаний чистых независимых типов перемещения. В этом режиме описания, временное окно конкретного элементарного сегмента может перекрываться с временным окном другого элементарного сегмента.
3.4.5.2. Траектория движения
Траектория движения объекта является простой характеристикой высокого уровня, определяемая как позиция, во времени и пространстве, одной репрезентативной точки этого объекта.
Этот дескриптор полезен для поиска материала в объектно-ориентированных визуальных базах данных. Он также эффективен в большинстве специальных приложений. В данном контексте с предварительным знанием ряда параметров, траектория позволяет реализовать некоторые дополнительные возможности. При наблюдении, могут выдаваться сигналы тревоги, если траектория воспринимается, как опасная (например, проходит через запретную зону, движение необычно быстро, и т.д.). В спорте могут распознаваться специфические действия (например, обмен ударами у сетки). Кроме того, такое описание позволяет также улучшить обработку данных: для полуавтоматического редактирования медиа данных, траектория может быть растянута, смещена, и т.д., чтобы адаптировать перемещения объекта для любого контекста.
Дескриптор является списком ключевых точек (x,y,z,t) вместе с набором опционных интерполирующих функций, которые описывают путь объекта между ключевыми точками, в терминах ускорения. Скорость неявно известна с помощью спецификации ключевых точек. Ключевые точки специфицируются путем задания моментов времени или их 2-D или 3-D декартовых координат, в зависимости от приложения. Интерполирующие функции определены для каждого компонента x(t), y(t) и z(t) независимо. Некоторые свойства этого представления перечислены ниже:
оно не зависит от пространственно-временного разрешения материала (например, 24 Hz, 30 Hz, 50 Hz, CIF, SIF, SD, HD, и т.д.), то есть если материал существует во многих форматах одновременно, для описания траектории объекта необходим только один набор дескрипторов данного материала.
оно компактно и масштабируемое. Вместо запоминания координаты объекта для каждого кадра, гранулярность дескриптора выбирается на основе ряда ключевых точек, используемых для каждого из временных интервалов.
оно непосредственно допускает широкое разнообразие применений, типа поиска подобия, или категорирование по скорости (быстрые, медленные объекты), поведению (ускоряется, когда приближается к этой области) или по другим характеристикам движения высокого уровня.
3.4.5.3. Параметрическое движение
Модели параметрического движения были использованы в рамках различных схем анализа и обработки изображения, включая сегментацию перемещения, оценки глобального перемещения, и отслеживание объектов. Модели параметрического перемещения использовались уже в MPEG-4, для оценки перемещения и компенсации. В контексте MPEG-7, перемещение является крайне важной характеристикой, связанный с пространственно-временной структурой видео, относящейся к нескольким специфическим MPEG-7 приложениям, таким как запоминание и поиск в видео базах данных, и для целей анализа гиперсвязей. Движение является также критической характеристикой для некоторых специфических приложений, которые уже рассматривались в рамках MPEG-7.
Базовый принцип состоит из описаний движения объектов в видео последовательности, например, в параметрической 2D-модели. В частности, аффинные модели включают в себя трансляции, вращения, масштабирование и их комбинации, планарные модели перспективы делают возможным учет глобальных деформаций, сопряженных с перспективными проекциями, а квадратичные модели позволяют описать более сложные движения.
Параметрическая модель ассоциирована с произвольными фоновыми объектами или объектами переднего плана, определенными как области (группа пикселей) в изображении в пределах заданного интервала времени. Таким способом, движение объекта записывается компактным образом в виде набора из нескольких параметров. Такой подход ведет к очень эффективному описанию нескольких типов перемещения, включая простые преобразования, вращения и изменения масштаба, или более сложные перемещения, такие как комбинации перечисленных выше элементарных перемещений.
Определение подобия характеристик моделей движения является обязательным для эффективного поиска объектов. Оно также необходимо для поддержки запросов нижнего уровня, полезно и в запросах верхнего уровня, таких как "поиск объектов приближающихся к камере ", или для "объектов, описывающих вращательное движение", или "поиск объектов, перемещающихся влево", и т.д.
3.4.5.4. Двигательная активность
Просмотр человеком видео или анимационной последовательности воспринимается как медленная последовательность, быстро протекающий процесс, последовательность действий и т.д. Дескриптор активности
воспринимает интуитивное понятие ‘интенсивность действия’ или ‘темп действий’ в видео сегменте. Примеры высокой ‘активности’ включают такие сцены, как ‘ведение счета голов в футбольном матче’, ‘автомобильные гонки’ и т.д. С другой стороны сцены, типа ‘чтение новостей’, ‘интервью’, ‘снимок’ и т.д. воспринимаются как кадры низкой активности. Видео материал охватывает диапазон от низкой до высокой активности, следовательно нам нужен дескриптор, который позволяет нам точно выражать активность данной видео последовательности/снимка и всесторонне перекрывать упомянутый выше диапазон. Дескриптор активности полезен для приложений, таких как видео наблюдение, быстрый просмотр, динамическое видео резюмирование, информационные запросы и т.д. Например, мы можем замедлить темп презентации кадров, если дескриптор активности указывает на высокую активность, так чтобы облегчить просмотр этой активности. Другим примером приложения является нахождения всех кадров высокой активности в новой видео программе, которая может рассматриваться как просмотр, так и абстракцию.
3.4.6. Локализация
3.4.6.1. Локатор области
Этот дескриптор допускает локализацию областей внутри изображения или кадров путем спецификации их с помощью краткого и масштабируемого отображения боксов или многогранников.
3.4.6.2. Пространственно-временной локатор
Локатор описывает пространственно-временные области в видео последовательности, такой как области движущихся объектов, и обеспечивает функцию локализации. Главным его приложением является гипермедиа, где выделенная точка находится внутри объекта. Другим ведущим приложением является поиск объектов путем проверки, прошел ли объект определенные точки. Это может использоваться для наблюдения. Дескриптор SpatioTemporalLocator
может описывать как связанные, так и несвязанные области.

Рис. 12. Пространственно-временная область
3.4.7. Прочие
3.4.7.1. Распознавание лица
Дескриптор FaceRecognition может использоваться для получения изображения лиц, которые соответствуют запросу. Дескриптор представляет проекцию вектора лица на набор базовых векторов, которые охватывают пространство возможных векторов лица. Набор параметров FaceRecognition получается из нормализованного изображения лица. Это нормализованное изображения лица содержит 56 строк с 46 значениями уровня в каждой строке. Центры двух глаз на каждом изображении лица размещаются на 24-ом ряду и 16-ой и 31-ой колонке для правого и левого глаз соответственно. Это нормализованное изображение затем используется для получения одномерного вектора лица, который состоит из значений яркости пикселей нормализованного изображения лица, которое получается в результате растрового сканирования, начинающегося в верхнем левом углу и завершающегося в нижнем правом углу изображения. Набор параметров FaceRecogniton вычисляется путем проектирования одномерного вектора лица на пространство, определяемое набором базисных векторов.
3.5. Схемы описания мультимедиа MPEG-7
Дескрипторы MPEG-7 сконструированы для описания следующих типов информации: низкоуровневые аудио-визуальные характеристики, такие как цвет, текстура, движение, уровень звука и т.д.; высокоуровневые семантические объекты, события и абстрактные принципы; процессы управления материалом; информация о системе памяти и т.д. Ожидается, что большинство дескрипторов, соответствующих низкоуровневым характеристикам будут извлекаться автоматически, в то время как человеческое вмешательство будет необходимо для формирования высокоуровневых дескрипторов.
MPEG-7 DS преобразуются в дескрипторы путем комбинирования индивидуальных дескрипторов а также других DS в рамках более сложных структур и определения соотношения составляющих дескрипторов и DS. В MPEG-7 DS категорируются в отношении к аудио или видео областям, или по отношению к описанию мультимедиа. Например, характерные DS соответствуют неизменным метаданным, связанным с формированием, производством, использованием и управлением мультимедиа, а также описанием материала. Обычно мультимедийные DS относятся ко всем типам мультимедиа, в частности к аудио, видео и текстовым данным, в то время как специфичные для области дескрипторы, такие как цвет, текстура, форма, мелодия и т.д., относятся исключительно к аудио или видео областям. Как в случае дескрипторов, реализация DS может в некоторых вариантах базироваться на автоматических средствах, но часто требует вмешательства человека.
3.5.1. Средства организации MDS
На рис. 13 представлена схема организации мультимедийных DS MPEG-7 в следующих областях: базовые элементы, описание материала, управление материалом, организация материала, навигация и доступ, взаимодействие с пользователем.
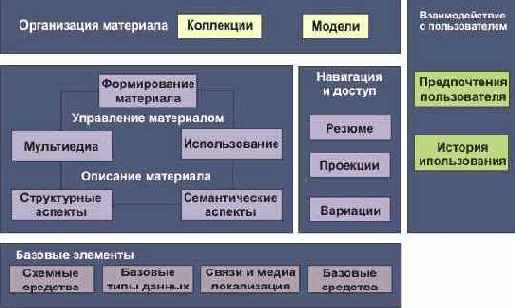
Рис. 13. Обзор мультимедийных DS MPEG-7
3.5.1.1. Базовые элементы
Спецификация мультимедийных DS MPEG-7 определяет определенное число схемных средств, которые облегчают формирование и выкладку описаний MPEG-7. Схемные средства состоят из корневого элемента, элементов верхнего уровня и средств выкладки (Package Tools). Корневые элементы, которые являются начальными элементами описания MPEG-7, позволяют сформировать полные XML-документы и фрагменты описания MPEG-7. Элементы верхнего уровня, которые позволяют корневым элементам в описании MPEG-7 организовать DS для объектно-ориентированных задач описания, таких как описание изображения, видео, аудио или аудио-визуальный материал, собрания (коллекции), пользователи или семантики мира. Созданы пакетные средства для группирования или ассоциации связанных компонентов DS описаний в каталоги или пакеты. Пакеты полезны для организационных и передающих структур и типов описательной информации MPEG-7 для систем поиска и для помощи при просмотре пользователям, незнакомым с особенностями описаний MPEG-7.
Спецификация мультимедийных DS MPEG-7 определяет также некоторое число базовых элементов, которые используются повторно в качестве фундаментальной конструкции при определении MPEG-7 DS. Многие базовые элементы предоставляют специфические типы данных и математические структуры, такие как вектора и матрицы, которые важны для описания аудио-визуального материала. Они включаются также в качестве элементов для связи медиа файлов и локализации сегментов, областей и т.д. Многие базовые элементы предназначены для специальных нужд описания аудио-визуального материала, таких как описание времени, мест, людей, индивидуальностей, групп, организаций, и других текстовых аннотаций. Из-за их важности для описания аудио-визуального материала, давайте очертим подходы MPEG-7 к описанию временной информации и текстовых аннотаций:
Временная информация: DS для описания времени базируется на стандарте ISO 8601, который был воспринят схемным языком XML. Временные DS предоставляют временную информацию в медиа-потоки и для реального мира. MPEG-7 расширяет спецификацию времени ISO 8601 для того, чтобы описать время в терминах стробирования аудио-визуального материала, например, путем подсчета периодов стробирования. Это позволяет поддержать эффективное описание временной информации в больших массивах аудио-визуального материала.
Текстовая аннотация: текстовая аннотация является также важным компонентом многих DS. MPEG-7 предоставляет некоторое число базовых конструкций для текстового аннотирования, включая свободный текст (слова, фразы), структурированный текст (текст плюс назначение слов) и зависимая структурированная аннотация (структурированный текст плюс взаимные связи), для того, чтобы поддерживать широкий диапазон функций текстовых описаний.
3.5.1.2. Управление содержимым
MPEG-7 предоставляет также DS для управления материалом. Эти элементы описывают различные аспекты создания медиа материала, медиа кодирование, запись, форматы файлов и использование материала. Функциональность каждого из этих классов DS представлена ниже [5]:
Создание информации: описывает формирование аудио-визуального материала. Эта информация описывает создание и классификацию аудио-визуального материала и других данных, которые с ним связаны. Информация формирования выдает заголовок (который может быть текстовым или фрагментом аудио-визуального материала), текстовую аннотацию, а также данные о создателях, месте формирования и дате. Классификационная информация описывает, как аудио-визуальный материал классифицируется в таких категориях как жанр, тема, цель, язык и т.д. Она предоставляет также обзор и управляющую информацию, такую как классификация по возрасту, тематический обзор, рекомендации создателей и т.д.. Наконец, информация, сопряженная с материалом, описывает, существует ли другой материал, который связан тематически с данным материалом.
Использование информации: описывает информацию об использовании аудио-визуального материала, такую как права использования, доступность, записи об использовании и финансовая информация. Правовая информация не включается в описание MPEG-7, вместо этого, предлагаются ссылки на владельцев прав и другие данные, относящиеся к защите авторских прав. Правовые
DS предоставляют эти ссылки в форме уникальных идентификаторов, которые управляются извне. Базовая стратегия описаний MPEG-7 заключается в предоставлении доступа к текущей информации о владельце без возможности непосредственного обсуждения возможных условий доступа к самому материалу. DS доступности и DS записей об использовании предоставляют данные, относящиеся, соответственно к доступности и прошлому использованию материала, такому как широковещательная демонстрация, доставка по требованию, продажа CD и т.д. Наконец, финансовые DS предоставляют информацию, связанную со стоимостью производства и доходами, которые могут результатом использования материала. Информация использования
является обычно динамической, меняющейся за время жизни аудио-визуального материала.
Медиа описание: характеризует характер записи, например, сжатие данных, кодирование и формат записи аудио-визуального материала. DS медиа информации идентифицирует источник материала. Образцы аудио-визуального материала называются медиа профайлами, которые являются версиями исходного материала, полученными возможно посредством другого кодирования или записи в другом формате. Каждый медиа профайл описывается индивидуально в терминах параметров кодирования и положения.
3.5.1.3. Описание содержимого
MPEG-7 предоставляет также DS для описания материала. Эти элементы описывают структуру (области, видео кадры и аудио сегменты) и семантику (объекты, события, абстрактные понятия). Функциональность каждого из классов DS представлена ниже:
Структурные аспекты. DS описывает аудио-визуальный материал с точки зрения его структуры. Структурные
DS формируются на основе DS сегментов, которые представляют пространственную, временную или пространственно-временную структуру аудио-визуального материала. Для получения оглавления или индекса для поиска аудио-визуального материала DS сегменты могут быть организованы в иерархические структуры. Сегменты могут быть описаны на основе характеристик восприятия с помощью дескрипторов MPEG-7 для цвета, текстуры, формы, движения, аудио параметров и т.д.
Концептуальные аспекты. DS описывает аудио-визуальный материал с точки зрения семантики реального мира и концептуальных представлений. DS семантики включают в себя такие характеристики как объекты, события, абстрактные концепции и отношения. DS структуры и DS семантики имеют отношение к набору связей, который позволяет описать аудио-визуальный материал на основе его структуры и семантики.
3.5.1.4. Навигация и доступ
MPEG-7 предоставляет также DS для облегчения просмотра и извлечения аудио-визуального материала путем определения резюме, разделов, составных частей и вариантов аудио-визуального материала.
Резюме
предоставляет компактное описание аудио-визуального материала, которое призвано облегчить поиск, просмотр, визуализацию и прослушивание аудио-визуального материала. DS резюме содержат два типа режимов навигации: иерархический и последовательный. В иерархическом режиме, информация организована в виде последовательности уровней, каждый из которых описывает аудио-визуальный материал с разной степенью детализации. Вообще, уровни более близкие к корневому предоставляют более общие резюме, периферийные же уровни повествуют о тонких деталях. Последовательные резюме предоставляют последовательность изображений или видео кадров, возможно синхронизованных со звуком, которые могут служить для просмотра слайдов, или аудио-визуальный набросок.
Разделы и декомпозиции описывают различные составляющие аудио-визуального сигнала в пространстве, времени и частоте. Разделы и декомпозиции могут использоваться для описания различных проекций аудио-визуальных данных, которые важны для доступа с разным разрешением.
Вариации предоставляют информацию о различных вариантах аудио-визуальных программ, таких как резюме и аннотации; масштабируемые, сжатые версии и варианты с низким разрешением; а также версии на различных языках– звук, видео, изображение, текст и т.д. Одной из важных возможностей, обеспечиваемых DS вариации, является выбор наиболее удобной версии аудио-визуальной программы, которая может заменить оригинал, если необходимо, адаптироваться к различным возможностям терминального оборудования, сетевым условиям или предпочтениям пользователя.
3.5.1.5. Организация содержимого
MPEG- 7 предоставляет также DS для организации и моделирования собрания аудио-визуального материала, а также его описания. DS собрания организует коллекцию аудио-визуального материала, сегментов, событий, и/или объектов. Это позволяет описать каждое собрание как целое на основе общих характеристик. В частности, для описания значений атрибутов собрания могут быть специфицированы различные модели и статистики.
3.5.1.6. Интеракция с пользователем
Наконец, последний набор DS MPEG-7 имеет отношение к взаимодействию с пользователем. DS взаимодействия с пользователем описывает предпочтения пользователя и историю использования мультимедийного материала. Это позволяет, например, найти соответствие между предпочтениями пользователя и описаниями аудио-визуального материала, для того чтобы облегчить индивидуальный доступ к аудио-визуальному материалу, презентации и пр.
3.5.2. Управление содержимым
Средства управления описанием материала позволяют охарактеризовать жизненный цикл материала.
Материал, охарактеризованный описаниями MPEG-7, может быть доступным в различных форматах и режимах, с разными схемами кодирования. Например, концерт может быть записан в двух разных режимах: звуковом и аудио-визуальном. Каждый из этих режимов может использовать различное кодирование. Это создает несколько медиа профайлов. Наконец, могут быть получены несколько копий одного и того же материала. Эти принципы режимов и профайлов проиллюстрированы на рис 14.
Рис. 14. Модель материала, профайла и копии
Материал. Реальное событие, такое как концерт может быть представлено различными типами медиа-материала, например, звуковой материал, аудио-визуальный материал. Материал является объектом, который имеет специфическую структуру для отображения реальности.
Медиа информация. Физический формат материала описывается DS медиа информации. Одна копия описания DS будет ассоциирована с одним материалом.
Медиа профайл. Один объект может иметь один или более профайлов, которые соответствуют различным схемам кодирования. Один из профайлов является оригинальным, он называется мастерным профайлом, который соответствует первоначально созданному или записанному материалу. Другие будут получаться перекодированием из мастерного. Если материал закодирован тем же кодирующим средством, но с другими параметрами, формируется другой медиа-профайл.
Медиа копия. Медиа-объект может быть поставлен в соответствие физическому объекту, называемому медиа-копией. Медиа-копия специфицируется идентификатором или локатором.>
CreationInformation. Информация о процессе формирования материала описывается DS CreationInformation. Одна копия описания DS будет ассоциирована с одним материалом.
UsageInformation. Информация об использовании материала описывается DS UsageInformation. Одна копия описания DS будет ассоциирована с одним материалом.
Единственной частью описания, которая зависит от среды записи или формата кодирования является MediaInformation, описанная в этом разделе. Остальная часть описания MPEG-7 не зависит от профайлов или копий и, как следствие, может использоваться, чтобы описать все возможные копии материала.
3.5.2.1. Средства описания среды
Описание среды включает в себя один элемент верхнего уровня, DS MediaInformation. Оно состоит из опционного MediaIdentification D и одного или нескольких MediaProfile D
Идентификация среды (Media Identification) D содержит средства описания, которые являются специфическими по отношению к идентификации аудио-визуального материала вне зависимости от имеющихся различных копий.
Медиа-профайл D содержит различные средства описания, которые позволяют охарактеризовать один профайл аудио-визуального материала. Концепция профайла относится к различным вариациям, которые могут отклоняться от оригинала в зависимости от выбранного кодирования, формата записи и т.д. Профайл, соответствующий оригиналу или мастерной копии аудио-визуального материала, считается мастерным профайлом. Для каждого профайла может быть одна или более медиа-копии мастерного медиа-профайла. MediaProfile D состоит из:
MediaFormat D содержит средства описания, которые являются специфическими для формата кодирования медиа-профайла.
MediaInstance D содержит средства описания, которые идентифицируют и локализуют различные копии медиа-профайлов.
MediaTranscodingHints D содержит средства описания, которые специфицируют рекомендации по транскодированию для описываемого материала. Целью этого D (дескриптора) является улучшение качества и сокращение сложности транскодирующих приложений. Рекомендации по транскодированию могут использоваться в виде схем оценки кодирования с целью снижения вычислительной сложности.
MediaQuality D предоставляет информацию об уровне качества аудио или видео материала. Это может использоваться для представления как субъективной, так и объективной оценки качества.
3.5.2.2. Создание и производство средств описания
Средства описания получения материала предоставляют авторские тексты, описания процесса формирования и/или производства аудио-визуального материала. Эта информация не может быть получена из самого материала. Эти данные связаны с материалом, но не описывают его буквально.
Описание формирования и производства материала содержит в качестве элемента верхнего уровня, DS CreationInformation, который состоит из одного Creation D, нуля или одного Classification D, и нуля или нескольких RelatedMaterial D.
Creation D содержит средства описания, имеющие отношение к формированию материала, включая место, дату, действия, материалы, персонал (технический и творческий) и организации, участвовавшие в процессе.
Classification D содержит средства описания, которые позволяют классифицировать аудио-визуальный материал. Classification D используется для описания классификации аудио-визуального материала. Это позволяет осуществлять поиск и отбор на основе предпочтений пользователя, ориентируясь на классификации пользователя (например, по языку, стилю, жанру и т.д.) и на классификации услуг (например, на цель, патентную защиту, сегментацию рынка, медиа ревью и т.д.).
Related Material D содержит средства описания, имеющие отношение к дополнительной информации о аудио-визуальном материале, имеющемся в других материалах.
3.5.2.3. Средства описания использования содержимого
Средства описания информации об использовании материала предоставляют данные о процессе использования аудио-визуального материала.
Описание данных об использовании обеспечивается посредством DS UsageInformation, который может включать один Rights D, нуль или один Financial D и нуль или несколько Availability D и UsageRecord D.
Важно заметить, что описание DS UsageInformation предполагает добавление новых описаний, каждый раз, когда материал используется (например, DS UsageRecord, доход в Financial D), или когда имеются другие способы доступа к материалу (например, Availability D).
Rights D предоставляет доступ к информации о правах владельцев и правах доступа.
Financial D содержит информацию, относящуюся к издержкам и доходам от полученного аудио- визуального материала. Понятия частичных издержек и доходов позволяют классифицировать различные издержки и доходы, в зависимости от их типа. Итоговые издержки и доходы вычисляются приложением на основе указанных выше составляющих.
Availability D содержит средства описания, относящиеся к доступности использования материала.
DS UsageRecord содержит средства описания, относящиеся к прошлому использованию материала.
3.5.3. Описание содержимого
3.5.3.1. Описание структурных аспектов содержимого
Основным элементом этой части описания является DS сегмента. Она относится к описанию физического и логического аспектов аудио-визуального материала. DS сегмента может использоваться для формирования сегментных деревьев. MPEG-7 специфицирует также DS графа,
который позволяет представлять сложные взаимоотношения между сегментами. Она используется для описания пространственно-временных соотношений, между сегментами, которые не описаны структурами дерева.
Сегмент представляет собой секцию аудио-визуального материала. DS сегмента является абстрактным классом (в смысле объектно-ориентированного программирования). Она имеет девять основных подклассов: DS мультимедийного сегмента, DS аудио-визуальной области, DS аудио-визуального сегмента, DS аудио сегмента, DS статической области, DS статической 3D-области, DS подвижной области, DS видео сегмента и
DS электронной раскраски. Следовательно, она может иметь как пространственные, так и временные свойства. Временной сегмент может быть набором фрагментов аудио-визуальной последоватеьности, представленным DS аудио сегмента, набором кадров видео последовательности, представленным DS
видео сегмента или комбинацией аудио и видео информации, охарактеризованной DS аудио-визуального сегмента. Пространственный сегмент может быть областью изображения или кадром в визуальной последовательности, представленным DS статической области для 2D-областей и DS статической области 3D для 3D-областей. Пространственно временной сегмент может соответствовать подвижной области в видеопоследовательности, представленной DS подвижной области
или более сложной комбинацией визуального и аудио материала, представленного, например, DS аудио-визуальной области. InkSegment DS описывает временной интервал или сегмент электронной раскраски, который соответствует набору чернильных капель, выбрасываемых из сопла. Наконец, наиболее общим сегментом является DS мультимедийного сегмента, который описывает составные сегменты, образующие мультимедийную презентацию. DS сегмента
является абстрактным и не может быть отображен сам по себе: он используется для определения общих свойств его подклассов. Любой сегмент может быть описан с помощью информации формирования, использования медийных данных и текстовой аннотации. Более того, сегмент может быть поделен на субсегменты с помощью DS декомпозиции сегмента.
Сегмент не является обязательно связанным, он может быть составлен из нескольких несвязанных компонентов. Связность здесь относится как к пространственным, так и временным доменам. Временной сегмент (видео сегмент, аудио сегмент или аудио-визуальный сегмент) считается связанными, если он является непрерывной последовательностью видео кадров или аудио фрагментов. Пространственный сегмент (статическая область или статическая 3D-область) считается связанными, если он является группой связанных пикселей. Пространственно-временной сегмент (подвижная область или
аудио-визуальная область) считается связанным в пространстве и времени, если временной сегмент, где он размещен является связанным, и, если каждый кадр, в него входящий, является пространственно связанным (заметим, что это не является классической связностью в 3D-пространстве).
На рис. 16 проиллюстрированы несколько примеров временных или пространственных сегментов и их связности. Рис. 16a и 16b иллюстрируют временные и пространственные сегменты, содержащие один связный компонент. Рис. 16c и 16d иллюстрирует временной и пространственный сегменты, состоящие из трех связанных компонент. Заметим, что в последнем случае, дескрипторы и DS, привязанные к сегменту, являются глобальными по отношению к объединению связанных компонент, образующих сегмент. На этом уровне, невозможно индивидуально описать связанные компоненты сегмента. Если связанные компоненты должны быть описаны индивидуально, тогда сегмент разделяется покомпонентно.
DS Сегмента является рекурсивным, то есть, он может быть поделен на субсегменты, и, таким образом, образовать древовидную структуру. Результирующее сегментное дерево используется для определения медиа-источника, временной и/или пространственной структуры аудио-визуального материала. Например, видео программа может быть временно преобразована в ряд сцен различного уровня, снимков, и микро-сегментов; оглавление может, таким образом, генерироваться на основе этой структуры. Подобные стратегии могут использоваться для пространственных и пространственно-временных сегментов.
Рис. 15. Примеры разложения сегмента на компоненты: a) и b) Декомпозиции сегмента без зазоров и перекрытий; c) и d) Декомпозиции сегмента с зазорами и перекрытиями
Сегмент может также разделен на составные части по медиа-источникам, таким как различным звуковым дорожкам или разным позициям видеокамер. Иерархическая декомпозиция полезна при формировании эффективных стратегий поиска (от глобального до локального). Она также позволяет описанию быть масштабируемым: сегмент может быть описан непосредственно с помощью его набора дескрипторов и DS, а может быть также описан набором дескрипторов и DS, которые относятся к его субсегментам. Заметим, что сегмент может быть разделен на субсегменты различного типа, например, видео сегмент может быть разложен движущиеся области, которые в свою очередь разлагаются на статические области.
Так как это выполняется в пространственно-временном пространстве, декомпозиция должна описываться набором атрибутов, определяющих тип разложения: временное, пространственное или пространственно-временное. Более того, пространственная и временная подсекции могут располагаться с зазором или с перекрытием. Несколько примеров декомпозиций для временных сегментов описано на рис. 15. Рис. 15a и 15b описывают два примера декомпозиции без зазоров или перекрытий. В обоих случаях объединение дочерних объектов соответствует в точности временному продолжению родительского, даже если родитель сам не является связанным (смотри пример на рис. 15b). Рис. 15c демонстрирует пример декомпозиции с зазорами, но без перекрытий. Наконец, рис. 15d иллюстрирует более сложный случай, где родитель состоит из двух связанных компонентов и его декомпозиция создает три дочерних объекта: первый сам состоит из двух связанных компонентов, остальные два состоят из одного связанного компонента. Декомпозиция допускает зазоры и перекрытия. Заметим, что в любом случае декомпозиция означает, что объединение пространственно-временного пространства, определенного дочерними сегментами, включается в пространство, определенное его сегментом-предшественником (дочерние объекты содержатся в предшественниках).
Рис. 16. Примеры сегментов: a) и b) сегменты состоят из одного связного компонента; c) и d) сегменты состоят из трех связанных компонентов
Таблица 1. Примеры характеристик для описания сегмента
Видео
сегмент
Стационарная область
Подвижная область
Видио сегмент
Время
Форма
Цвет
Текстура
Движение
Движение камеры
Мозаика
Характеристики звука
X
.
X
.
X
X
X
.
.
X
X
X
.
.
.
.
X
X
X
.
X
.
.
X
X
.
.
.
.
.
.
X
Как упомянуто выше, любой сегмент может быть описан с помощью данных формирования, информации об использовании, медиа-данных и текстовой аннотации. Однако специфические характеристики, зависящие от типа сегмента, также допускаются. Примеры специфических характеристик представлены в таблице 1. Большинство дескрипторов (D), соответствующих этим характеристикам может быть получено автоматически из исходного материала. Для этой цели в литературе описано большое число различных средств.
Пример описания изображения представлен на рис. 17. Исходные изображения описаны как стационарные области, SR1, которые описаны с помощью данных формирования (заголовок, создатель), информации использования (авторские права), медийной информации (формат файла), а также текстовой аннотации (обобщающей свойства изображения), гистограмм цвета и дескриптора текстуры. Исходная область может быть в дальнейшем разложена на составные области. Для каждого шага декомпозиции, мы указываем, допустимы или нет зазоры и перекрытия. Дерево сегмента состоит из 8 стационарных областей (заметим, что SR8 является одиночным сегментом, составленным из двух связанных сегментов). Для каждой области, на рис. 17 показан тип характеристики, которая реализована. Заметим, что в иерархическом дереве не нужно дублировать информацию формирования, использования и пр., так как предполагается, что дочерние сегменты наследуют эти характеристики.
Рис. 17. Примеры описания изображения с стационарными областями
Описание структуры материала может выходить за рамки иерархического дерева. Хотя, иерархические структуры, такие как деревья, удобны при организации доступа, поиска и масштабируемого описания, они подразумевают ограничения, которые делают их неприемлемыми для некоторых приложений. В таких случаях DS графа сегмента не используется. Структура графа определяется набором узлов, представляющих сегменты, и набора ребер, определяющих отношения между узлами. Чтобы проиллюстрировать использование графов, рассмотрим пример, представленный на рис. 18.
Рис. 18. Пример видео-сегмента и областей для графа, представленного на рис. 19.
Этот пример демонстрирует момент футбольного матча. Определены два видео-сегмента, одна стационарная область и три движущиеся области. Граф, описывающий структуру материала, показан на рис. 19. Видео-сегмент: Обводка & удар включает в себя мяч, вратаря
и игрока. Мяч остается рядом с игроком, движущимся
к вратарю. Игрок появляется справа от вратаря
Видео-сегмент гол включает в себя те же подвижные области плюс стационарную область ворота. В этой части последовательности, игрок
находится слева от вратаря, а мяч движется к воротам. Этот очень простой пример иллюстрирует гибкость данного вида представления. Заметим, что это описание в основном представляется структурным, так как отношения, специфицированные ребрами графа, являются чисто физическими, а узлы, представляющие сегменты, которые являются объектами, определяемыми данными создания, информацией использования и медиа-данными, а также дескрипторами низкого уровня, такими как цвет, форма, движение. В семантически явном виде доступна только информация из текстовой аннотации (где могут быть специфицированы ключевые слова мяч, игрок или вратарь).

Рис. 19. Пример графа сегмента
3.5.3.2. Описание концептуальных аспектов содержимого
Для некоторых приложений, подход, описанный выше, не приемлем, так как он выделяет структурные аспекты материала. Для приложений, где структура практически не используется, но где пользователь в основном интересуется семантикой материала, альтернативным подходом является семантический
DS. В этом подходе, акцент делается не на сегментах, а на событиях, объектах,
концепциях, месте, времени и абстракции.
Документальная сфера относится к контексту для семантического описания, то есть, это "реальность", в которой описание имеет смысл. Это понятие перекрывает область специфических случаев аудио-визуального материала, а также более абстрактных описаний, представляющих область возможных медиа-вариантов.
Как показано на рис. 20, DS SemanticBase
описывает документальные сферы и семантические объекты. Кроме того, несколько специальных DS получается из DS SemanticBase, которые описывают специфические типы семантических объектов, таких как описательные сферы, объекты, объекты агента, события, место и время, например: Семантический
DS описывает документальные сферы (narrative worlds - реальные миры), которые отображаются или сопряжены с аудио-визуальным материалом. Он может использоваться для описания шаблонов аудио-визуального материала. На практике, семантический DS служит для инкапсуляции описания документальной области. DS объекта
описывает воспринимаемый или абстрактный объект. Воспринимаемый объект является сущностью, которая является реальностью, то есть, имеет временное и пространственное протяжение в описываемом мире (например, "Пианино Вани"). Абстрактный объект является результатом абстрагирования воспринимаемого объекта (например, "любое пианино"). Это абстрагирование генерирует шаблон объекта. DS AgentObject расширяет возможности DS объекта. Она описывает человека, организацию, группу людей, или персонализированные объекты (например, "говорящую чашку в анимационном кино"). DS события описывает воспринимаемое или абстрактное событие. Воспринимаемое событие является динамическим отношением, включающим один или более объектов, которые возникают во времени или пространстве описываемого мира (например, "Ваня играет на пианино"). Абстрактное событие является результатом абстрагирования воспринимаемых событий (например, "кто-то играет на пианино"). Эта абстракция позволяет сформировать шаблон события. DS концепции описывает семантическую сущность, которая не может быть описана, как обобщение или абстрагирование специфицированного объекта, события, временного интервала или состояния. Она представляет собой свойство или собрание свойств (например, “гармония” или “готовность”). Эта DS может относиться к среде непосредственно или к другой описываемой семантической сущности. DS SemanticState описывает один или более параметрических атрибута семантической сущности в данное время или в данной точке описываемого мира или в данной позиции среды (например, вес пианино равен 100 кг). Наконец, DS SemanticPlace и SemanticTime
характеризуют соответственно место и время в описываемом мире.
Как и в случае DS сегмента, концепция описания может быть представлена в виде дерева или графа. Структура графа определена набором узлов, представляющих семантические понятия, и набора ребер, специфицирующих отношения между узлами. Ребра описываются DS семантических отношений.
Рис. 20. Средства для описания концептуальных аспектов
Кроме семантического описания индивидуальных привязок в аудио-визуальном материале, семантические DS допускают также описание абстракций. Абстракция относится к процессу получения описания из специфической привязки к аудио-визуальному материалу и обобщению его с помощью нескольких привязок к этому материалу или к набору специальных описаний. Рассматриваются два типа абстракции, называемых медиа-абстракция и стандартная абстракция.
Медиа-абстракция представляет собой описание, которое отделено от конкретных образцов аудио-визуального материала, и может описывать все варианты и образцы аудио-визуального материала, которые достаточно схожи между собой (подобие зависит от приложения и от деталей описания). Типичным примером может служить новость, которая широковещательно передается по разным каналам.
Стандартная абстракция является обобщением медиа-абстракции для описания общего класса семантических сущностей или описаний. Вообще, стандартная абстракция получается путем замещения конкретных объектов, событий или других семантических сущностей классами. Например, если "Ваня играет на пианино" заменяется на "человек играет на пианино", описание становится стандартной абстракцией. Стандартные абстракции могут быть рекурсивными, то есть определять абстракцию абстракций. Обычно стандартная абстракция предназначена для повторного использования или ориентирована на применение в качестве ссылки.
Простой пример описания концептуальных аспектов показан на рис. 21. Описываемый мир включает в себя в данном случае Ваню Иванова играющего на фортепиано со своим учителем. Событие характеризуется семантическим описанием времени: "19:00 24-го апреля 2002", и семантикой места: "Консерватория". Описание включает одно событие: игра и четыре объекта: фортепьяно, Ваня Иванов, его учитель и абстрактное понятие музыканта. Последние три объекта принадлежат к классу агент.
Рис. 21. Пример концептуальных аспектов описания.
3.5.4. Навигация и доступ
MPEG- 7 предоставляет DS, которые облегчают навигацию и доступ к аудио-визуальному материалу путем спецификации резюме, обзоров, разделов и вариаций медиа-данных. DS резюме предоставляет аннотации аудио-визуального материала для того, чтобы обеспечить эффективный просмотр и навигацию в аудио-визуальных данных. Пространственно-частотная проекция дает возможность рассматривать аудио-визуальные данные в пространственно-частотной плоскости. DS вариации специфицируют отношения между различными вариантами аудио-визуального материала, которые позволяют адаптивный выбор различных копий материала при различных условиях доставки и для разных терминалов.
3.5.4.1. Резюме
Аудио-визуальные резюме предоставляют компактные аннотации аудио-визуального материала для облегчения обнаружения, просмотра, навигации, визуализации и озвучивания этого материала. DS резюме
позволяет осуществлять навигацию в рамках аудио-визуального материала иерархическим или последовательным образом. Иерархическая декомпозиция резюме организует материал послойно, так что он на различных уровнях выдает различную детализацию (от грубой до подробной). Последовательные резюме предоставляет последовательности изображений или видео кадров, возможно синхронизованные с аудио и текстом, которые формируют слайд-демонстрации или аудио-визуальные наброски.
HierarchicalSummary
организует резюме нескольких уровней, которые описывают аудио-визуальный материал с разной детализацией. Элементы иерархии специфицируются DS HighlightSummary
и HighlightSegment. Иерархия имеет форму дерева, так как каждый элемент в иерархии кроме корневого имеет прародителя. Элементы иерархии могут опционно иметь дочерние элементы.
HierarchicalSummary сконструирован на основе базового представления временных сегментов AВ-данных, описанных HighlightSegments. Каждый HighlightSegment содержит указатели на AВ-материал, чтобы обеспечить доступ к ассоциированным ключевым видео- и аудио-клипам, к ключевым кадрам и ключевым звуковым составляющим, он может также содержать текстовую аннотацию, относящуюся к ключевым темам. Эти AВ-сегменты группируются в резюме, или рубрики, посредством схемы описания HighlightSummary.
специфицирует резюме, состоящее из последовательности изображений или видео кадров, возможно синхронизованных со звуком или текстом. SequentialSummary может также содержать последовательность аудио-фрагментов. Аудио-визуальный материал, который образует SequentialSummary, может быть записан отдельно от исходного материала, чтобы позволить быструю навигацию и поиск. В качестве альтернативы, последовательные резюме могут связываться непосредственно с исходным аудио-визуальным материалом для того, чтобы ослабить требования к памяти.
Рис. 22. Пример иерархического резюме видео записи футбольного матча, имеющего многоуровневую иерархию. Иерархическое резюме предполагает достоверность (то есть, f0, f1, …) ключевых кадров с точки зрения видео сегмента следующего более низкого уровня.
На рис. 22 показан пример иерархического резюме видео записи футбольного матча. Описание иерархического резюме предоставляет три уровня детализации. Видео запись матча суммирована на одном корневом кадре. На следующем уровне иерархии предлагается три кадра, которые суммируют различные сегменты видеозаписи. Наконец, внизу рисунка показаны кадры нижнего уровня иерархии, отображающие детали, различных сцен сегментов предыдущего уровня.
3.5.4.2. Разделы и декомпозиции
Отображения разделов и декомпозиций описывает различные части аудио-визуального сигнала в пространстве, времени и по частоте. Отображения разделов описывает различные виды аудио-визуального материала, такие как отображения с низким разрешением, пространственных или временных сегментов, или частотных субдиапазонов. Вообще, DS отображения пространства и частоты специфицируют соответствующие разделы в пространственной и частотной плоскостях.
Отображение декомпозиций описывает различные представления аудио-визуального сигнала посредством механизмов графов. Декомпозиции специфицируют узловые элементы информационных структур, базирующихся на графе и соответствующие элементы отношений, которые соответствуют анализу и синтезу внутренних зависимостей отображений.
DS отображений
описывают различные пространственные и частотные отображения аудио- визуальных данных. Определены следующие DS отображения: DS SpaceView описывает пространственное отображение аудио-визуальных данных, например, пространственный сегмент изображения. DS FrequencyView описывает отображение в пределах заданного частотного диапазона, например, частотный субдиапазон звукового сопровождения. DS SpaceFrequencyView специфицирует многомерное отображение аудио-визуальных данных одновременно в пространстве и по частоте, например, частотный субдиапазон пространственного диапазона изображения. DS ResolutionView специфицирует отображение с низким разрешением, такое как набросок изображения. Концептуально, отображение разрешения является частным случаем частотного отображения, которое соответствует низкочастотному субдиапазону данных. DS SpaceResolutionView
специфицирует отображение одновременно в пространстве и по разрешению, например, отображение изображения пространственного сегмента с низким разрешением.
DS декомпозиции проекции описывают различные пространственные и частотные декомпозиции и организацию отображения аудио-визуальных данных. Определены следующие DS декомпозиции проекций: DS ViewSet описывает набор проекций, который может иметь различные свойства полноты и избыточности, например, набор субдиапазонов, полученный при частотной декомпозиции аудио сигнала, образующего ViewSet. DS SpaceTree описывает дерево декомпозиции данных, например, пространственная декомпозиция квадрантов изображения. DS FrequencyTree
описывает частотную декомпозицию данных, например, волновую декомпозицию изображения DS. SpaceFrequencyGraph описывает декомпозицию данных одновременно в пространстве и по частоте. Здесь отображение использует частотный и пространственный графы. Граф видео отображения специфицирует декомпозицию видео данных в пространстве координата-время-частота, например, декомпозиция видео 3-D-субдиапазона. Наконец, MultiResolutionPyramid специфицирует иерархию проекций аудио-визуальных данных, например, пирамиду изображений с разным разрешением.
На рис. 23 приведен пример пространственно-частотного графа декомпозиции изображения. Структура пространственного и частотного графа включает элементы узлов, которые соответствуют различным пространственным и частотным проекциям изображения, состоящего из пространственных проекций (пространственные сегменты), частотных (частотные субдиапазоны), и пространственно-частотных (частотные субдиапазоны пространственных сегментов). Структура пространственного и частотного графа включает также элементы переходов, которые содержат анализ и синтез зависимостей между проекциями. Например, на рис. 23, “S” переходы указывают на пространственную декомпозицию, в то время как “F” переходы отмечают частотную или субдиапазонную декомпозицию.
Рис. 23. Пространственно-частотный граф разлагает изображение или аудио-сигналы в пространстве место-время-частота. Декомпозиция изображений, использующая пространственно-частотный граф, делает возможным эффективный доступ и поиск материала при самом разном разрешении
3.5.4.3. Вариации содержимого
Вариации предоставляют информацию о различных изменениях аудио-визуального материала, такого как резюме, архивированные или версии с малым разрешением, а также версии на различных языках - звук, видео, изображение, текст и т.д.. Одной из главных функций DS вариаций является разрешение серверу, прокси или терминалу выбрать наиболее удобную вариацию аудио-визуального материала, которая может заместить оригинал, если необходимо, адаптировать различные возможности терминального оборудования, сетевых условий или предпочтений пользователя. DS вариаций используется для спецификации различных вариаций аудио-визуальных данных. Вариации могут возникать самыми разными способами, или отражать изменения исходных данных. Значение достоверности вариации определяет ее качество по сравнению с оригиналом. Атрибут типа вариации указывает на характер изменений: резюме, аннотация, язык перевода, уменьшение насыщенности цвета, снижение разрешения, сокращение частоты кадров, архивирование и т.д..
3.5.5. Организация содержимого
MPEG- 7 предоставляет DS для организации и моделирования коллекций аудио-визуального материала, сегментов, событий, и/или объектов, и описания их общих свойств. Коллекции могут быть далее описаны, используя различные модели и статистики для того, чтобы характеризовать атрибуты элементов коллекции.
3.5.5.1. Собрания (Collections)
DS структуры коллекции описывает коллекции аудио-визуального материала или отрывков такого материала, например, временные сегменты видео. DS структуры коллекции
группирует аудио-визуальный материал, сегменты, события, или объекты кластеры коллекций и специфицирует свойства, которые являются общими для всех элементов. DS CollectionStructure описывает также статистику и модели значений атрибутов этих элементов, такие как усредненная гистограмма цвета для коллекции изображений. DS CollectionStructure также описывает отношения между кластерами коллекций.
На рис. 24 показана концептуальная организация коллекций в DS CollectionStructure. В этом примере, каждая коллекция состоит из набора изображений с общими свойствами, например, каждая отображает сходные события в футбольном матче. Внутри каждой коллекции, могут быть специфицированы отношения между изображениями, такие как степень сходства изображений в кластере. В рамках коллекции, DS CollectionStructure специфицирует дополнительные связи, такие как степень сходства коллекций.
Рис. 24. DS структуры коллекции описывает коллекции аудио-визуального материала, включая отношения (то есть, R AB, RBC, RAC) внутри и между кластерами коллекций
3.5.5.2. Модели
DS моделей
предоставляют средства для моделирования атрибутов и характеристик аудио-визуального материала. DS модели вероятности предоставляет собой фундаментальную DS для спецификации различных статистических функций и вероятностных структур. DS модели вероятности могут использоваться для представления образцов аудио-визуальных данных и классов дескрипторов, использующих статистические аппроксимации.
DS аналитической модели описывает коллекции образцов аудио-визуальных данных или кластеров дескрипторов, которые предоставляют модели для конкретных семантических классов. DS аналитической модели специфицирует семантические маркеры, которые индицируют моделируемые классы. DS аналитической модели опционно специфицирует степень доверия, с которой семантический маркер приписан модели. DS классификатора описывает различные типы классификаторов, которые определяют механизм присвоения семантических маркеров аудио-визуальным данным.
3.5.6. Взаимодействие с пользователями
DS UserInteraction
описывает предпочтения пользователей имеющих отношение к использованию AВ-материала, а также историю его использования. Описания АВ-материала в MPEG-7 может быть приведено в соответствие с описаниями предпочтений для того, чтобы выбрать и персонализовать АВ-материал для более эффективного доступа, презентации и использования. DS UserPreference описывает предпочтения для различных типов материала и моделей просмотра, включая зависимость от контекста в терминах времени и места. DS UserPreference описывает также вес относительной важности различных предпочтений, характеристики конфиденциальности предпочтений и будут ли предпочтения изменяться в процессе взаимодействия, агента с пользователем. DS UsageHistory описывает историю действий, предпринятых пользователем мультимедийной системы. Описания истории использования могут пересылаться между клиентами, их агентами, провайдерами материала и оборудованием, и могут быть в свою очередь использованы для определения предпочтений пользователей с учетом характера АВ-материала.
3.6. Эталонные программы: экспериментальная модель
3.6.1. Цели
Программы XM являются основой для эталонных кодов стандарта MPEG-7. Они используют нормативные компоненты MPEG-7:
Дескрипторы (D),
Схемы описания (DS),
Схемы кодирования (Cs),
Язык описания определений DDL (description definition language)
Компоненты систем BiM.
Средства выборки используются исключительно для получения данных из медиа среды прикладного типа. Как будет показано позднее, имеется возможность извлечь проверяемые D или DS из других данных описания. В этом случае, процесс выборки может быть реализован только через один функциональный вызов, то есть, без итеративных циклов с входными данными для каждой временной точки или периода.
3.6.4.4. Класс дескрипторов
Классы дескрипторов несут в себе описательные данные. В программах XM классы для каждого D или DS представляют непосредственно нормативную часть стандарта. Имеются также функции для элементов реализации описаний.
В программах XM имеется два различных способа конструирования классов D или DS. В случае визуальных D, этот класс использует простой подход класса C++. Во всех других случаях этот класс реализуется с помощью общего модуля, который в XM называется GenericDS. Этот класс является интерфейсом между программами C++ XM и реализацией парсера DDL. Здесь используется XML парсер, предоставляющий DOM-API (Data Object Model - Application Programming Interface - прикладной программный интерфейс объектной модели данных). Следовательно, GenericDS является интерфейсом между XM и парсером DOM-API. Управление памятью для описательных данных выполняется посредством библиотеки парсера DOM. Оба подхода могут комбинироваться с помощью функций ImportDDL и ExportDLL
реализованных классов дескриптора C++.
3.6.4.5. Схема кодирования
Схема кодирования включает в себя нормативный кодировщик и декодер для D или DS. В большинстве случаев схема кодирования определена только заданием схемы DDL. Здесь, кодирование представляет собой вывод описания в файл, а декодирование является разборкой (parsing) и загрузкой файла описания в память. Описание запоминается, с использованием класса GenericDS, который является оболочкой для DOM-API. Следовательно, мы можем использовать библиотеку парсера DOM-API для кодирования и декодирования. Эти функции встроены XM с помощью класса GenericDSCS (CS = схема кодирования). Помимо ASCII-представления XML-файла MPEG-7 стандартизует также двоичное представление описаний (BiM).
Другим подходом является использование визуальной группы MPEG-7. Здесь, каждый D имеет также индивидуальное двоичное представление. Это позволяет специфицировать число бит, которое следует использовать для кодирования индивидуальных элементов описания. Примером может служить число бит, используемых для кодирования каждой ячейки гистограммы.
3.6.4.6. Средство поиска
В качестве средств извлечения и поиска используется ненормативное средство стандарта. Оно берет одно описание из базы данных и одно описание запроса, причем запрос может не соответствовать нормативам MPEG-7 D или DS. Средство поиска анализирует описание и обрабатывает нужные входные данные так, как это требуется для специфицированного приложения.
Средства поиска используются во всех клиентских приложениях, которые являются приложениями поиска и доставки (search & retrieval) и приложениями медиа-транскодирования (media transcoding). В случае приложений поиска и доставки, средство поиска сравнивает два входных описания и вычисляет величину их отличия. Для приложения медиа-транскодирования обрабатываются медиа-данные, то есть, медийная информация модифицируется на основе описания и запроса. Так как медиа данные обрабатываются, средство поиска вызывается из приложения транскодирования.
3.6.5. Типы приложений в XM-программах
3.6.5.1. Извлечение из среды
Выборка из медиа приложения относится к типам приложений выборки. Обычно, все D или DS низкого уровня должны иметь класс приложения этого типа. Как показано на рис. 25 это приложение извлекает тестируемые D/DS (DUT) из входных медиа данных. Сначала медиа файл загружается медиа-декодером в мультимедиа-класс, то есть, память. На следующем шагу с помощью средства выборки описание может быть извлечено из мультимедиа-класса. Затем описание проходит через кодировщик и закодированные данные записываются в файл. Этот процесс повторяется для всех мультимедийных файлов медийной базы данных.
Рис. 25. Выборка для приложения медийного типа. Описание извлекается из входных медийных данных
3.6.5.2. Приложение поиска и извлечения
Приложение поиска и получения данных, показанное на рис. 26, относится к типу клиентского приложения. Сначала все описания базы данных, которые могут быть извлечены из медиа приложения, декодируются и загружаются в память. Из медиа данных с помощью средства выборки может быть извлечено и описание запроса. С другой стороны запрос может быть загружен непосредственно из файла. После получения всех входных данных, запрос обрабатывается для всех элементов базы данных, а результирующие расстояния (значения отличия) используются для сортировки данных согласно уровню соответствия запросу. Наконец, сортированный список записывается в качестве медиа базы данных в файл.
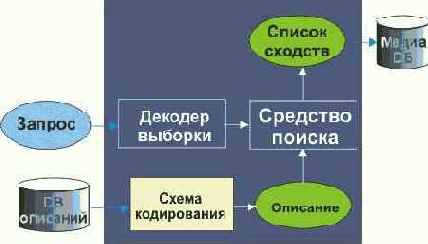
Рис. 26. Поиск и выборка прикладного типа. Сортированная информация из медиа базы данных получается из описаний и запроса
3.6.5.3. Приложение транскодирования среды
Приложение медиа транскодирования также относится к клиентскому типу. Как показано на рис. 27, медиа файлы и их описания загружены. Основываясь на описаниях, медиа данные модифицируются (транскодируются), а новая медиа база данных записывается в файл. Более того, может быть специфицирован запрос, который обрабатывается для описаний до транскодирования.
Рис. 27. Тип приложения медиа транскодирования. Из исходной DB создается транскодированная база данных, соответствующая описаниям и опционно запросу.
3.6.5.4. Приложение описания фильтрации
Приложение фильтрации описаний может относиться к типу выборки или клиента, в зависимости оттого сгенерирован или использован исследуемый дескриптор (DUT). В обоих случаях описания входной базы данных фильтруются на основе регламентаций запроса. Результирующие отфильтрованные описания записываются затем в выходные файлы.
Рис. 28. Приложение фильтрации описаний
3.6.6. Модель ключевого приложения MPEG-7
3.6.6.1. Определение ключевых приложений
Эти приложения называются также ключевыми приложениями, так как они имеют базовый или элементарный тип. Вообще, ключевые приложения необязательно являются приложениями реального мира, так как они используют только репрезентативные и общие задания прикладных сценариев.
Другим важным ограничением программного обеспечения XM является факт, что программы XM являются лишь средствами командной строки, то есть, что приложение, его входы и выходы могут быть специфицированы только, когда работает XM. Ключевые приложения во время работы не поддерживают взаимодействие с пользователем.
3.6.6.2. Модель интерфейса
После идентификации природы ключевых приложений следующим шагом является разработка абстрактной модели такого приложения. Результирующий субнабор входов и выходов показан на рис. 29. Возможными входами являются медиа базы данных, базы данных описаний и запросов. Возможными выходами могут быть медиа базы данных и базы данных описаний. В абстрактной модели семантика выхода медиа базы данных не разделена, то есть, список медиа файлов наилучшего соответствия и транскодированной медиа базы данных не рассматриваются как индивидуальные типы выхода.

Рис. 29. Интерфейсная модель ключевых приложений XM. Эта модель показывает супернабор возможных входов и выходов ключевого приложения XM.
Помимо уже используемых выходов, предполагается, что будет также тип выхода, соответствующий входному запросу. На рис. 29 этот выход имеет название прочий выход. Возможными приложениями для этого могут быть уточняющие запросы, например, для просматривающих приложений. Однако использование этого выхода все еще не ясно и нуждается в дальнейших исследованиях.
Далее мы используем интерфейсную модель ключевых приложений для двух целей, создание новых ключевых приложений и описание отношений ключевых приложений с приложениями реального мира.
3.6.7. Ключевые приложения против приложений реального мира
Как было заявлено выше, ключевыми приложениями в программном обеспечении XM являются приложения элементарного типа. Комбинирование ключевых приложений создает составные приложения. Так как ключевые приложения могут иметь произвольные комбинации входов, модель ключевых приложений является общей для этого диапазона приложений. Следовательно, также возможно, что приложения реального мира могут быть объединены в обрабатывающие сети, состоящие из блоков элементарных ключевых приложений и пользовательских интерфейсов, предоставляющих пользователю механизм взаимодействия и презентации результатов.
Рис. 30. Пример приложения реального мира, извлекающего два разных описания (XM-Appl1, XM-Appl2). Основываясь на первом описании выбран адекватный набор материала (XM-Appl3), который затем транскодирован с использованием второго описания (XM-Appl4). (MDB = медийная база данных, DDB = база данных описаний).
Ссылки
Имеется большое число документов на базовой странице MPEG http://drogo.cselt.it/mpeg/, включая:
Введение в MPEG-7
ТребованияMPEG-7
ПриложенияMPEG-7
КонцепцияMPEG-7
Документы MPEG-7 CD, WD и XM: системы, DDL, видео, аудио и MMDS.
Информацию, имеющую отношение к промышленной сфере, можно найти на Web-сервере MPEG-7 http://www.mpeg-7.com
(Industry Focus Group).
Приложение А. Словарь и сокращения
|
CD |
Committee Draft - проект комитета |
|
CE |
Cилиe Experiment - центральный эксперимент |
|
CS |
Coding Scheme - схема кодирования |
|
D |
Дескриптор |
|
DDL |
Data Description Language - Язык описания данных |
|
DS |
Description Scheme - Схема описания |
|
FCD |
Final Committee Draft - окончательный проект комитета |
|
FDIS |
Final Draft of International Standard - окончательный проект международного стандарта |
|
IS |
International Standard - Международный стандарт |
|
MMDS |
Multimedia Description Schemes - Схемы описания мультимедиа |
|
MPEG |
Moving Pictures Experts Group - Группа экспертов по движущимся изображениям |
|
WD |
Working Draft - рабочий проект |
|
XM |
eXperimentation Model - модель экспериментирования |
Стандартные мультикастинг-адреса Интернет
10.3 Стандартные мультикастинг-адреса Интернет
Семенов Ю.А. (ГНЦ ИТЭФ)
Статический алгоритм Хафмана
2.6.5 Статический алгоритм Хафмана
Семенов Ю.А. (ГНЦ ИТЭФ)
Статический алгоритм Хафмана можно считать классическим (см. также Р. Галлагер. Теория информации и надежная связь. “Советское радио”, Москва, 1974.) Определение статический в данном случае отностится к используемым словарям. Смотри также www.ics.ics.uci.edu/~dan/pubs/DataCompression.html (Debra A. Lelewer и Daniel S. Hirschberg).
Пусть сообщения m(1),…,m(n) имеют вероятности P(m(1)),… P(m(n)) и пусть для определенности они упорядочены так, что P(m(1)) і P(m(2)) і … і P(m(N)). Пусть x1,…, xn – совокупность двоичных кодов и пусть l1, l2,…, lN – длины этих кодов. Задачей алгоритма является установление соответствия между m(i) и xj. Можно показать, что для любого ансамбля сообщений с полным числом более 2 существует двоичный код, в котором два наименее вероятных кода xN и xN-1 имеют одну и ту же длину и отличаются лишь последним символом: xN имеет последний бит 1, а xN-1 – 0. Редуцированный ансамбль будет иметь свои два наименее вероятные сообщения сгруппированными вместе. После этого можно получить новый редуцированный ансамбль и так далее. Процедура может быть продолжена до тех пор, пока в очередном ансамбле не останется только два сообщения. Процедура реализации алгоритма сводится к следующему (см. рис. 2.6.5.1). Сначала группируются два наименее вероятные сообщения, предпоследнему сообщению ставится в соответствие код с младшим битом, равным нулю, а последнему – код с единичным младшим битом (на рисунке m(4) и m(5)). Вероятности этих двух сообщений складываются, после чего ищутся два наименее вероятные сообщения во вновь полученном ансамбле (m(3) и m`(4); p(m`(4)) = p(m(4)) + P(m(5))).
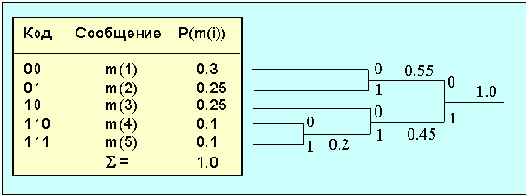
Рис. 2.6.5.1 Пример реализации алгоритма Хафмана
На следующем шаге наименее вероятными сообщениями окажутся m(1) и m(2). Кодовые слова на полученном дереве считываются справа налево. Алгоритм выдает оптимальный код (минимальная избыточность).
При использовании кодирования по схеме Хафмана надо вместе с закодированным текстом передать соответствующий алфавит. При передаче больших фрагментов избыточность, сопряженная с этим не может быть значительной.
Возможно применение стандартных алфавитов (кодовых таблиц) для пересылки английского, русского, французского и т.д. текстов, программных текстов на С++, Паскале и т.д. Кодирование при этом не будет оптимальным, но исключается статистическая обработка пересылаемых фрагментов и отпадает необходимость пересылки кодовых таблиц.
Статистическая теория каналов связи
2.10 Статистическая теория каналов связи
Семенов Ю.А. (ГНЦ ИТЭФ)
Данная статья имеет целью познакомить с терминологией и математическими основами статистической теории передачи данных. Именно на этой математической основе зиждятся приведенные выше теоремы Шеннона и Найквиста. Статья является компиляцией из нескольких источников (Ю.В.Прохоров, Ю.А.Розанов "Теория вероятностей. Основные понятия, предельные теоремы, случайные процессы" Наука, М. 1967; Л.Ф. Куликовский, В.В.Мотов, "Теоретические основы информационных процессов", Высшая школа, 1987; Р. Галлагер "Теория информации и надежная связь" Советское радио, 1974 и др.). Материалы, предлагаемые здесь не могут считаться исчерпывающими и призваны быть поводом для более углубленного изучения по существующим монографиям.
Канал связи предназначен для транспортировки сообщений. Математическая модель канала связи описывается некоторой совокупностью Х1 элементов х1 (X1 = {x11, x12,, …x1j}), называемых сигналами на входе канала, совокупностью Х2 элементов х2 (x2 = {x21, x22,, …x2k}), называемых выходными сигналами, и условными распределениями вероятностей p2=p2(a2
|x1) в пространстве x2 выходных сигналов x2. Если посланный сигнал (сигнал на входе) есть х1, то с вероятностью P2=P2(A2|x1) на выходе канала будет принят сигнал х2 из некоторого множества A2 М Х2 (распределения задают вероятности того или иного искажения посланного сигнала х1). Совокупность всех возможных сообщений обозначим символом x0. Предполагается, что каждое из сообщений x0О X0 может поступать с определенной вероятностью. То есть, в пространстве X0
имеется определенное распределение вероятностей P0=P0(A0 ).
Сообщения х0 не могут быть переданы по каналу связи непосредственно, для их пересылки используются сигналы x1О X1. Кодирование сообщений х0 в сигналы х1 описывается при помощи условного распределения вероятностей P1=P1(A1
|x0). Если поступает сообщение х0, то с вероятностью P1=P1(A1|x0)
будет послан один из сигналов х1, входящих в множество A1 М Х1 (условные распределения P1(A1|x0) учитывают возможные искажения при кодировании сообщений). Аналогичным образом описывается декодирование принимаемых сигналов х2 в сообщения x3. Оно задается условным распределением вероятностей P3=P3(A3|x2) на пространстве Х3 сообщений х3, принимаемых на выходе канала связи.
На вход канала связи поступает случайное сообщение x0 с заданным распределением вероятностей P0=P0(A0). При его поступлении передается сигнал x1, распределение вероятностей которого задается правилом кодирования P1=P1(A1|x0):
P{x2 О A2|x0, x1} = P2(A2|x1)
Принятый сигнал x2 декодируется, в результате чего получается сообщение x3:
P{x3 О A3|x0, x1, x2} = P3(A3| x2)
Последовательность x0 ® x1 ® x 2 ® x3 является марковской. При любых правилах кодирования и декодирования описанного типа имеет место неравенство:
I(x0,x3) Ј I(x1, x2),
где I(x0, x3) – количество информации о
x0 в принятом сообщении
x3, I(x1, x2) – количество информации о x1 в принятом сигнале
x2.
Предположим, что распределение вероятности входного сигнала x1 не может быть произвольным и ограничено определенными требованиями, например, оно должно принадлежать классу W. Величина C = sup I(( x1 , x2) , где верхняя грань берется по всем возможным распределениям P1 О W, называется емкостью канала и характеризует максимальное количество информации, которое может быть передано по данному каналу связи (теорема Шеннона).
Предположим далее, что передача сообщений x0 ® x3 должна удовлетворять определенным требованиям точности, например, совместное распределение вероятностей Px0 x1 передаваемого и принимаемого сообщений x0 и x3 должно принадлежать некоторому классу V. Величина H= inf I( x0
x3),
где нижняя грань берется по всем возможным распределениям Px0 x3 О V,
характеризует минимальное количество информации, которое должно заключать в себе принимаемое сообщение x3 о x0, чтобы было выполнено условие точности передачи. Величина H называется энтропией источника сообщений.
Если возможна передача
x0 ® x1 ® x2 ® x3 с соблюдением требований V и W, то есть существуют соответствующие способы кодирования и декодирования (существуют условные распределения P1, P2 и P3), то H Ј С.
Для выполнения этого неравенства передача является возможной, т.е. возможна передача последовательно поступающих сообщений

Предположим, что совокупность Х0 всех возможных сообщений х0 является дискретной (имеется не более чем счетное число различных сообщений x0, поступающих с соответствующими вероятностями P0(x0), x0 О X0) и условие точности передачи v состоит в том, что принимаемое сообщение x3 должно просто совпадать с переданным сообщением x3 = x0 с вероятностью 1. Тогда
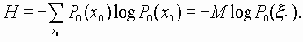
Предположим далее, что имеется лишь конечное число N
различных входных сигналов х1 и нет никаких ограничений на вероятности P{ x1 = x1}, x1 О X1. Кроме того, предположим, что передаваемые сигналы принимаются без искажений, то есть с вероятностью 1 x2= x1. Тогда емкость канала выражается формулой C = log2N, т.е. передаваемое количество информации I(x1, x
2 ) будет максимальным в том случае, когда сигналы x1 О X1 равновероятны.
Если сообщения
поступают независимо друг от друга, то количество информации, которое несет группа сообщений
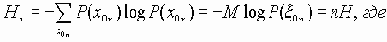
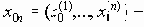
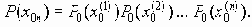
Пусть H<C, положим также d=(1/2)(C-H). Согласно закону больших чисел, примененному к последовательности независимых и одинаково распределенных случайных величин
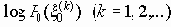
с математическим ожиданием
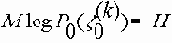
для любого e >0 найдется такое n(e), что при всех n і n(e )
P{-H-d Ј (1/n)logP( x 0n) Ј H+d } і 1-e, где
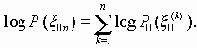
Полученное неравенство говорит о том, что все группы сообщений х0n можно разбить на два класса. К первому классу
и количество которых Mn не больше чем 2n(H+d ):
Mn Ј 2n(H+d )
Ко второму классу
 х0n:
х0n: 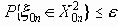
Каждую группу высоковероятных сообщений х0n можно в принципе передать, закодировав ее соответствующей комбинацией сигналов
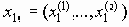
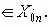
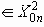 передавать некоторый один и тот же сигнал
передавать некоторый один и тот же сигнал 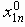
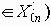 , то с вероятностью, не меньшей чем 1-e, на выходе канала связи будет приниматься последовательность
, то с вероятностью, не меньшей чем 1-e, на выходе канала связи будет приниматься последовательность 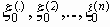
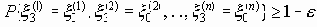
При выполнении неравенства H < C оказывается возможной передача достаточно длинных сообщений
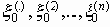
Количество информации I(x0, x3) для абстрактных случайных величин x0 и x3
со значениями в пространствах Х0 и Х3 может быть записано в виде:
I(x0, x
3) = Mi(x0, x3), где
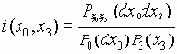
- информационная плотность. Последовательность пар (x0n, x3n) называется информационно устойчивой, если при n ® Ґ
I(x0, x3) ® Ґ и
(по вероятности)
Рассмотренная выше последовательность (x0n, x3n), x3n= x0n
поступающих сообщений x 0n =(
x1n® x 2n, Hn – минимальное количество информации, необходимое для соблюдения требуемой точности передачи x0n
® x 3n, причем
(при n ® Ґ ),
и существуют информационно устойчивые последовательности пар (x0n, x3n) и (x1n, x2n), для которых одновременно
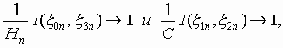
то при весьма широких предположениях для любого наперед заданного e >0 существует такое n(e), что по всем каналам связи с параметром n і n(e) возможна передача с точностью до e.
2.10.2. Канал связи с изменяющимися состояниями
Как было указано выше, канал характеризуется условными распределениями З2, задающими вероятности тех или иных искажений посылаемого сигнала х1. Несколько изменим схему канала связи, считая, что имеется некоторое множество Z возможных состояний z канала связи, причем если канал находится в некотором состоянии z и на входе возникает сигнал x1, то независимо от других предшествующих обстоятельств канал переходит в другое состояние z1. Этот переход подвержен случайностям и описывается условными распределениями P(C|x1, z) (P(C|x1, z) – вероятность того, что новое состояние z1 будет входить в множество C М Z). При этом уже считается, что выходной сигнал х2 однозначно определяется состоянием канала z1, т.е. существует некоторая функция j = j (z) на пространстве z возможных состояний канала такая, что х2= j (z1). Эта более общая схема позволяет учитывать те изменения, которые в принципе могут возникать в канале по мере его работы.
Рассмотрим стационарный режим работы канала связи. Предположим, что последовательно передаваемые сигналы
…., x 1(-1), x 1(0), x 1(1),…, соответствующие состояниям канала …, z (-1), z (0), z (1),…, и определяемые ими сигналы
…, x 2(-1), x 2(0), x 2(1),…, на выходе образуют стационарные и стационарно связанные случайные последовательности. Величина С=supI(x 1,x 2), где I(x 1,x 2), означает скорость передачи информации о стационарной последовательности {x1(n)} последовательностью {x 2(n)} и верхняя грань берется по всем допустимым распределениям вероятностей входной последовательности {x1(n)}, называется пропускной способностью канала связи.
Предположим, что поступающие на вход канала связи сообщения {x 0(n)}, n =…, -1, 0, 1 ,…, образуют случайную последовательность. Будем считать правило кодирования заданным, если при всех k, m и k1,…, km і k определены условные вероятности
P{x 1(k1) О B1,…, x 1
(km)О Bm|x 0(-Ґ ,k)}
Того, что при поступлении последовательности сообщений
x 0(-Ґ ,k) = …, x 0(k-1), x 0(k)
на соответствующих местах будут переданы сигналы x 1(k1),…, x 1(km), входящие в указанные множества B1, …, Bm. Эти вероятности считаются стационарными в том смысле, что они не меняются при одновременной замене индексов k и k1,…,km на k+l и k1+l,…,km+l при любом целом l. Аналогичными вероятностями p{ x 3(k1) О D1,…, x 3(km) О Dm|x 2(-Ґ ,k)}
задается правило декодирования.
Определим величину H
формулой H = inf I( x 0,x 3), где I(x 0, x 3) – скорость передачи информации о стационарной последовательности {x0(n)}
последовательностью {x3(n)}, n = …, -1, 0, 1,…
(эти последовательности предполагаются стационарно связанными), и нижняя грань берется по всем допустимым распределениям вероятностей, удовлетворяющим требованиям точности передачи {x0(n)} ® { x3(n)}.
Неравенство H Ј C является необходимым условием возможности передачи
{x 0(n)} ® {x 1(n)} ® {x 2(n)} ® {x 3(n)}.
Напомним, что каждое сообщение
x0(n) представляет собой некоторый элемент х0 из совокупности Х0. Можно интерпретировать Х0 как некоторый алфавит, состоящий из символов х0. Предположим, что этот алфавит Х0 является конечным и требование точности передачи состоит в безошибочном воспроизведении передаваемых символов:
P{x 3(k) = x 3(k)} =1 для любого целого k.
Предположим также, что имеется лишь конечное число входных сигналов х1 и состояний канала z. Обозначим состояния канала целыми числами 1, 2, …, N, и пусть p(k, x1,j) – соответствующие вероятности перехода из состояния k в состояние j при входном сигнале x1:
p(k,x1,j) = P{z (x+1) = j|z (n)=k, x 1(n+1)=x1}.
Дополнительно предположим, что любые произведения вида
p(k0,x1(1),k1)p(k1,x1(2),k2)… p(kn-1,x1(n),kn)
являются стохастическими матрицами, задающими эргодические цепи Маркова. Это условие будет выполнено, если, например, каждая из переходных матриц {p(k,x1,j)} имеет положительный коэффициент эргодичности. Тогда при выполнении неравенства H<C и соблюдении условия эргодичности стационарной последовательности {x 0(n)} сообщений на входе передача возможна с точностью до любого e >0, т.е. при соответствующих способах кодирования и декодирования принимаемая последовательность сообщений {x 3(n)} будет обладать тем свойством, что p{x3(k) № x 0(k)} < e для любого целого k.
Пусть x 1 = {x (t), t О T1} и x 2= {x (t), t О T2} – два семейства случайных величин, имеющих совместное гауссово распределение вероятностей, и пусть H1 и H2 – замкнутые линейные оболочки величин x (t), t О T1, и x (t), t О T2, в гильбертовом пространстве L2
(W). Обозначим буквами P1 и P2 операторы проектирования на пространства H1 и H2 и положим P(1) = P1P2P1, P(2) = P2P1P2. Количество информации I(x1,x 2) о семействе величин x1, содержащееся в семействе x2, конечно тогда и только тогда, когда один из операторов P(1) или P(2) представляет собой ядерный оператор, т.е. последовательность l 1, l 2,… его собственных значений (все они неотрицательны) удовлетворяет условию
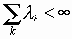
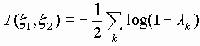
В случае, когда x 1 и x 2 образованы конечным числом гауссовых величин:
x1={x (1),…, x (m)}, x 2 = {x (m+1),…, x (m+n
)}, причем корреляционная матрица B общей совокупности x (1),…, x (m+n) является невырожденной, количество информации I(x 1, x 2) может быть выражено следующей формулой:
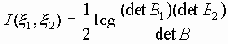
где B1 и B2 – корреляционные матрицы соответствующих совокупностей x 1 и x 2.
Гауссовы распределения обладают следующим экстремальным свойством. Для произвольных распределений вероятностей величин
x 1 = {x (1), …, x (m)}
и x 2 = {x (m+1), …, x (m+n)}
с соответствующими корреляционными матрицами B1, B2 и B количество информации I(x 1, x 2) удовлетворяет неравенству

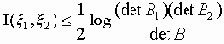
Пусть x = (x 1,…,x n) и h = (h 1,…,hn) – векторные случайные величины в n-мерном евклидовом пространстве X и r(x,y) – некоторая неотрицательная функция, определяющая условие близости величин x и h, которое выражается следующим соотношением:
Mr(x ,h ) Ј e .
Величину H=He, определенную как He = inf I(x, h), обычно называют e–энтропией случайной величины x (нижняя грань берется по всем случайным величинам h, удовлетворяющим указанному условию e–близости случайной величине x).
Пусть r(x,y) = r(|x-y|) и существует производная r’(0), 0< r’(0)<Ґ. Тогда при e ® 0 имеет место асимптотическая формула, в которой логарифмы берутся по основанию e:
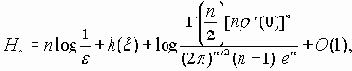
где g() – гамма функция и h(x) – дифференциальная энтропия случайной величины x:
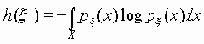
(px(x) – плотность распределения вероятностей, удовлетворяющая весьма широким условиям, которые выполняются, например, если плотность px(x) ограничена и h(x ) > -Ґ ).
Пусть
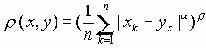
Тогда
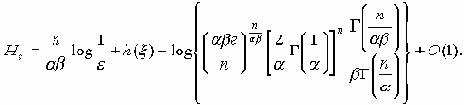
В частности, при a =2, b =1 имеет место асимптотическая формула
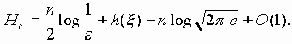
Пусть пара случайных процессов (x 1(t), x 2(t)) образует стационарный в узком смысле процесс, x [u,v] – совокупность значений x (t), u Ј t Ј v, и пусть
 , содержащееся в отрезке
, содержащееся в отрезке 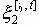 2. Среднее количество указанной информации представляет собой линейно растущую функцию от t:
2. Среднее количество указанной информации представляет собой линейно растущую функцию от t: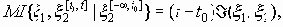
Фигурирующая здесь величина I(x1, x2) называется средней скоростью передачи информации стационарным процессом x2 о стационарном процессе x1 или просто – скоростью передачи информации.
Скорость передачи информации I(x1,x2)
обладает рядом свойств, аналогичных свойствам количества информации. Но она имеет и специфические свойства. Так для всякого сингулярного случайного процесса x 2, т.е. такого процесса, все значения x 2(t) которого являются функциями от совокупности величин
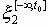 I(x 1, x 2)=0.
I(x 1, x 2)=0.Для всякого регулярного случайного процесса x 2 равенство I(x1,x2)=0 справедливо лишь тогда, когда случайный процесс x 1 не зависит от процесса x2 (это говорит о том, что в некоторых случаях I(x1,x2) № I(x 2,x 1) ).
При дополнительных условиях типа регулярности скорость передачи информации I(x 1,x 2)
совпадает с пределом
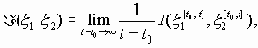
где
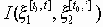
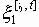 , заключенное в
, заключенное в 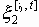
0< c Ј l 2nf(l ) Ј c < Ґ
Пусть стационарный процесс x = x (t) представляет собой последовательность величин, каждая из которых принимает значения из некоторого алфавита x, состоящего из конечного числа символов x1, x2,…,xn. Предположим, что вероятность появления на фиксированном месте определенного символа xi есть pi, а вероятность появиться за ним символу xj не зависит от предшествующих xi значений и есть pij:
P
{x (t) = xi} = pi, P{x(t+1) = xi xi|x(t) = xi, x(t-1),…, } = pij
Другими словами x = x
(t) - стационарная цепь Маркова с переходными вероятностями {pij} и стационарным распределением {pi}. Тогда скорость передачи информации стационарным процессом x(t) будет
I(x,x) = -
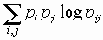
В частности, если x = x(t) – последовательность независимых величин (в случае pij = pj), то
I(x,x) = -
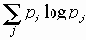
Пусть x1 = x1(t) и x2 = x2(t) – стационарные гауссовы процессы со спектральными плотностями f11(l), f22(l) и взаимной спектральной плотностью f12(l) причем процесс x2 = x2(t) является регулярным. Тогда
I(x1, x2) = -
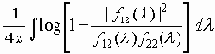
Рассмотрим следующее условие близости гауссовых стационарных процессов x1(t) и x2(t):
M|x1(t) - x2(t)|2 Јd2
Наименьшая скорость передачи информации
H = infI(x1,x2),
совместимая с указанным условием “d-точности”, выражается следующей формулой:
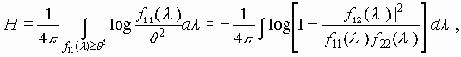
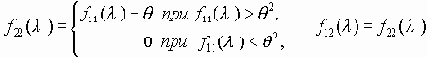
а параметр q2 определяется из равенства
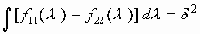
Эта формула показывает, какого типа спектральная плотность f22(l) должна быть у регулярного стационарного процесса x 2(t), который несет минимальную информацию I
(x1,x 2) » H
о процессе x1(t). В случае дискретного времени, когда f11(l ) і q 2 при всех l , -p Ј l Ј p, нижняя грань H скорости передачи достигается для такого процесса x 2
(t) (со спектральной плотностью f22(l), задаваемой приведенной выше формулой), который связан с процессом x 1(t) формулой
x 2(t) = x 1(t) + z(t), где z(t) – стационарный гауссов шум, не зависящий от процесса x 2(t); в общем случае формула f22(l) задает предельный вид соответствующей спектральной плотности регулярного процесса x 2(t).
В случае, когда спектральная плотность f11(l) приближенно выражается формулой
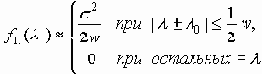
соответствующая минимальная скорость передачи информации H может быть вычислена по приближенной формуле
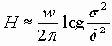
2.10.3. Симметричный канал без памяти
Рассмотрим симметричный канал передачи данных без памяти c конечным числом входных сигналов х1, когда передаваемый сигнал х1 с вероятностью 1-p правильно принимается на выходе канала связи, а с вероятностью p искажается, причем все возможные искажения равновероятны: вероятность того, что на выходе будет сигнал х2, равна
c = supI( x1,x2) достигается в случае, когда на вход поступает последовательность независимых и равномерно распределенных сигналов …, x 1(-1), x 1(0), x 1(1),…; эта пропускная способность выражается формулой
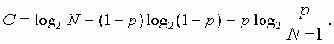
Рассмотрим канал связи, на входе которого сигналы образуют стационарный процесс x 1 = x1(t), M[x 1(t)]2 < Ґ.
Пусть при прохождении сигнала x 1 = x 1(t) он подвергается линейному преобразованию Aj со спектральной характеристикой j (l) и, кроме того, на него накладывается аддитивный стационарный гауссов шум z =z (t), так что на выходе канала имеется случайный процесс x 2(t) вида x 2(t) = aj x 1(t) + z (t).
Предположим также, что ограничения на входной процесс состоит в том, что M[x 1(t)]2 Ј D 2 (постоянная D2 ограничивает среднюю энергию входного сигнала). Пропускная способность такого канала может быть вычислена по формуле
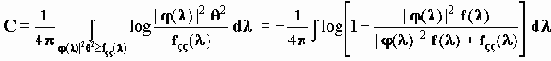
(в последнем выражении интегрирование ведется в пределах -p Ј l Ј p для дискретного времени t и в пределах -Ґ <l <Ґ для непрерывного t), где fz z (l) – спектральная плотность гауссова процесса z (t), функция f(l) имеет вид
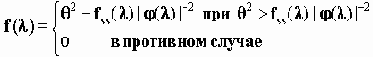
а параметр q2 определяется из равенства
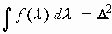
Нужно сказать, что если функция f(l) представляет собой спектральную плотность регулярного стационарного гауссова процесса x 1(t), то этот процесс, рассматриваемый как входной сигнал, обеспечивает максимальную скорость передачи информации: I(x 1,x 2) = C. Однако в наиболее интересных случаях, когда время t меняется непрерывно, функция f(l) обращается в нуль на тех интервалах частот l, где уровень шума сравнительно высок (отличные от нуля значения f(l) сосредоточены в основном на тех интервалах частот l, где уровень шума сравнительно мал), и поэтому не может служить спектральной плотностью регулярного процесса. Более того, если в качестве входного сигнала выбрать процесс x 1(t) с спектральной плотностью f(l), то этот сигнал будет сингулярным и соответствующая скорость передачи информации I(x 1,x2) будет равна нулю, а не максимально возможному значению C, указанному выше.
Тем не менее, приведенные выражения полезны, так как позволяют приблизительно представить вид спектральной плотности f(l) регулярного входного сигнала x 1(t),
обеспечивающей скорость передачи I(x1, x2), близкую к максимальному значению C.
С практической точки зрения наиболее интересен случай, когда канал связи имеет ограниченную полосу w пропускаемых частот, т.е. когда спектральная характеристика выражается формулой
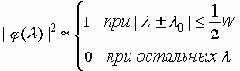
а проходящий через канал шум имеет равномерный спектр:
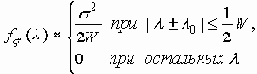
В этом случае пропускная способность может быть вычислена по приближенной формуле
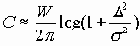
При этом входной сигнал x1(t), обеспечивающий скорость передачи информации I(x1, x2), близкую к максимальной, является гауссовым стационарным процессом со спектральной плотностью f(l) вида
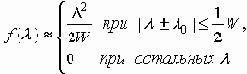
так что параметры D2 и s2 имеют следующий физический смысл: