Механизмы и алгоритмы обслуживания запросов
Одним из предназначений сервера имен является обработка запросов. Существуют два способа обработки запросов сервером:
 | Нерекурсивный способ. Для ответа сервер использует только локальную информацию. Ответное сообщение содержит либо требуемую информацию, либо ошибку, либо ссылку на соседний сервер. Данный способ должен поддерживаться всеми серверами имен. |
| Рекурсивный способ. В этом состоянии сервер имен работает также в роли программы разрешения (resolve) и в ответном сообщении может возвратить либо ошибку, либо требуемую информацию, но никогда — ссылку на другой сервер имен. Данный способ не обязан поддерживаться серверами имен. Для работы этим способом необходимо специальное программное обеспечение как на хосте сервера имен, так и на машине клиента. Этот способ используется в следующих случаях: |
Обработчик ответов не может обрабатывать ответы, содержащие ссылки на другие серверы.
Запрос должен быть обработан только определенными серверами.
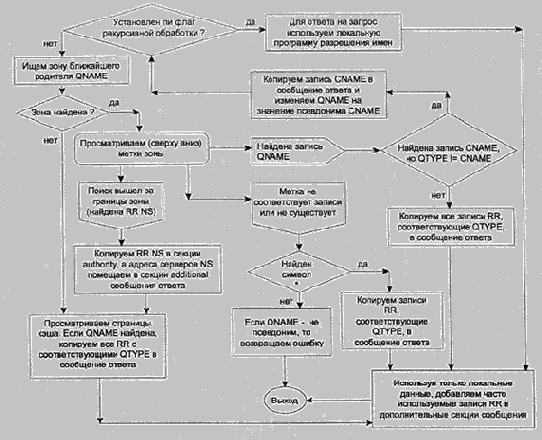
Алгоритм обработки запросов, используемый сервером имен, зависит от операционной системы хоста и структуры данных, используемой для хранения записей RR. Далее приведен алгоритм, предполагающий, что записи RR организованы в виде структуры дерева, по одному ("дереву") на каждую зону (алгоритм 1).
Установить или снять флаг использования рекурсии (зависит от настроек сервера). Если флаг рекурсивной обработки установлен, переходим на шаг 5, иначе — на шаг 2.
Ищем зону ближайшего родителя QNAME. Если нашли, то переходим на шаг 3, иначе — на шаг 4.
Просматриваем (сверху вниз) метки зоны. Просмотр останавливается, если происходит одно из следующих событий:
• Найдена запись QNAME. Если поиск остановился на записи CNAME (псевдонима), но QTYPE не совпадает с CNAME (нам не нужен псевдоним), тогда копируем запись CNAME в сообщение ответа, изменяем QNAME на значение псевдонима CNAME и возвращаемся на шаг 1. Иначе, копируем все записи RR, соответствующие QTYPE в сообщение ответа и переходим на шаг 6.
• Поиск вышел за пределы зоны — мы получаем ссылку. Это случается, когда мы наталкиваемся на запись NS RR, обозначающую срез или конец данной зоны. Копируем запись NS RR в секции полномочий (authority) сообщения ответа, помещаем в дополнительные (additional) секции сообщения адреса соответствующих серверов имен (используя "приклеенные" записи) и переходим на шаг 4.
/p>
Алгоритм 1. Обработка запросов сервером имен
5. Для ответа на запрос используем локальную программу разрешения имен (или ее копию). Помещаем в сообщении ответа все результаты поиска, включая промежуточные записи CNAME.
6. Используя только локальные данные, добавляем некоторые часто используемые записи RR (например, адреса соответствующих доменов) в дополнительные секции сообщения. Выход.
Особенности использования доменных имен
При анализе доменных имен компьютеров следует учитывать следующие особенности их использования:
Доменные имена сообщают только о том, кто отвечает за его выделение и ничего не говорят о том, кто отвечает за компьютер, соответствующий данному IP - адресу.
Компоненты доменного имени не обязательно скажут о том, к какой сети относится компьютер. Доменные имена и сети часто перекрываются, но между ними не всегда есть связь; два компьютера в одном домене могут находиться в разных сетях. Например, системы uxc.cso.uiuc.edu и ux1.cso.uiuc.edu могут работать в разных сетях.
Компьютер может иметь несколько имен. Особенно это относится к компьютерам, которые предоставляют услуги, так как сервисная программа может быть в будущем перенесена на другой компьютер. Так, рабочая станция, имеющая к примеру имя nyx.cs.edu, может одновременно являться компьютером, на котором каждый из числа сотрудников этого учреждения может получить файлы общего пользования, обращаясь к нему по имени ftp.cs.edu ( ftp - название программы перемещения файлов). В случае снятия этой услуги с данного компьютера имя ftp.cs.edu перейдет на другой компьютер вместе с сервисной программой. Имена, которые символически указывают на сервисную программу, являются псевдонимами, заменяющими уникальное “каноническое имя” компьютера.
Понятие зоны, деление DNS-пространства на зоны
Зона представляет собой полную спецификацию какой-либо части пространства имен домена. К данной зоне, как правило, имеют доступ несколько серверов имен. В соответствии с соглашением, каждая зона должна быть доступна, по меньшей мере, с двух серверов. Один сервер имен, как правило, поддерживает работу одной или более зон.
База данных домена может быть разбита на зоны двумя способами: по классам и "срезам" пространства имен.
| Деление по классам. Для какого-либо класса строится и инсталлируется отдельная база данных. Поскольку пространство имен одно и то же для всех классов, структуры данных для отдельных классов можно рассматривать как параллельные "деревья" пространства имен. Ясно, что данные узлов этих "деревьев" будут зависеть от класса, которому они принадлежат. Причиной построения нового класса, как правило, является необходимость в новом формате данных, или требуется построить независимое (от уже существующего) пространство имен. |
| Деление по "срезам". Внутри отдельного класса, "срез" в пространстве имен можно сделать между любыми двумя соседними узлами. После построения такого "среза" каждая группа пространства имен будет представлять собой отдельную зону. Такой "срез" в пространстве имен может проходить в разных классах по различным местам пространства имен, части новых зон могут принадлежать различным серверам имен и т. д. |
Эти правила деления подразумевают, что каждая зона имеет по крайней мере один узел и имя домена, пространством имен которого она владеет. Кроме того, в соответствии со структурой "дерева", каждая зона имеет своего "родителя" — зону, расположенную в системе иерархии ближе к корню "дерева". Имя зоны — родителя часто используется для определения имени данной зоны.
Безусловно, деление пространства имен таким образом, что каждый домен располагался бы в отдельной зоне или так, чтобы все узлы домена располагались бы в отдельной зоне, было удобно с точки зрения единого администрирования.
Однако вместо этого база данных чаще всего разделена по организационному принципу, т. е. каждая организация, работающая с определенной частью "дерева", желает контролировать и изменять свою часть самостоятельно.
Информация, хранящаяся в определенной зоне, состоит из четырех основных частей:
Данные о правах узлов внутри зоны.
Данные, определяющие узел родителя зоны.
Данные о подзонах данной зоны.
Данные о правах доступа к серверам имен подзон данной зоны.
Вся эта информация хранится в виде RR-записей, т. е. данная зона может быть полностью описана в терминах RR. Зоны могут очень просто перемещаться между серверами имен, например, через механизм перемещения соответствующих RR, посредством обмена RR-сообщениями или передачей по FTP текстовых файлов главного архива.
Информация, находящаяся под управлением данной зоны, состоит из всех RR, прикрепленных ко всем узлам от вершины узла данной зоны к узлам-потомкам зоны.
Для управления зоной особенно важными являются записи RR, описывающие вершину зоны. Эти записи могут быть двух типов: записи серверов имен — по одному в RR и одна запись RR SOA, описывающая параметры работы зоны. Записи NS обозначают срезы данной зоны. Поскольку серверы имен всегда ассоциированы с границами зоны, записи NS RR могут располагаться только в узлах, которые являются родительскими каких-либо зон. Среди записей, образующих зону, записи NS RR могут располагаться как в вершине зоны, так и в ее конце, но никак не посередине.
Примечание
Структура зон содержит всю необходимую информацию для установления соединения с серверами имен своих подзон. Однако для обращения к серверам имен подзон, необходимо знать IP-адреса этих серверов. В частности, если имя сервера имен само хранится в подзоне, мы можем столкнуться с ситуацией, когда запись NS RR говорит, что, для того чтобы получить адрес сервера, нам необходимо обратиться к серверу, адрес которого мы хотим выяснить. Для разрешения подобных недоразумений зона содержит так называемые "приклеенные" записи, которые не являются частью зоны и содержат адреса серверов подзоны.
построения и инсталляции DNS
Рассмотрим пример построения зоны DNS.
На рис.16 уполномоченный сервер каждого домена показан рядом со своим доменом в круглых скобках. Корневые серверы: С.ISI.EDU, SRI-NIC.ARPA и A.ISI.EDU. Домен MIL обслуживают серверы SRI-NIC.ARPA и A.ISI.EDU. Домен EDU обслуживают SRI-NIC.ARPA и C.ISI.EDU.
Примечание
Серверы могут обслуживать как непрерывные, так и разделенные (разрывные) зоны. На данной схеме сервер C.ISI.EDU работает в непрерывной зоне с корневым и EDU доменами. Сервер A.ISI.EDU работает с непрерывной зоной в корневом и MIL доменах, но также обслуживает и разрывную зону ISI.EDU.
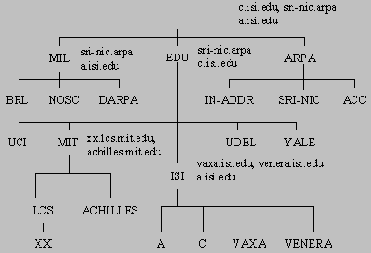
Рис. 16. Пример построения зоны с отдельным администрированием корневой зоны и зон MIL, EDU и ISI.EDU
Рассмотрим сервер имен С.ISI.EDU, который обслуживает в классе IN корневой домен, домены MIL и EDU. Данные его зон имеют следующий вид:
IN SOA SRI-NIC.ARPA. HOSTMASTER.SRI-NIC.ARPA. (
870611 ;serial
1800 ;refresh
300 ;retry
604800 ;expiry
86400) ; minimum TTL
NS A.ISI.EDU.
NS C.ISI.EDU.
NS SRI-NIC.ARPA.
MIL. 86400 NS SRI-NIC.ARPA.
86400 NS A.ISI.EDU.
EDU. 86400 NS SRI-NIC.ARPA.
86400 NS C.ISI.EDU.
SRI-NIC.ARPA. A 26.0.0.73
A 10.0.0.51
MX 0 SRI-NIC.ARPA.
HINFO DEC-2060 TOPS20
ACC.ARPA. А 26.6.0.65
HINFO PDP-11/70 UNIX
MX 10 ACC.ARPA.
USC-ISIC.ARPA. CNAME C.ISI.EDU.
73.0.0.26.IN-ADDR.ARPA. PTR SRI-NIC.ARPA.
65.0.6.26.IN-ADDR.ARPA. PTR ACC.ARPA.
51.0.0.10.IN-ADDR.ARPA. PTR SRI-NIC.ARPA.
52.0.0.10.IN-ADDR.ARPA. PTR C.ISI.EDU.
103.0.3.26.IN-ADDR.ARPA. PTR A.ISI.EDU.
A.ISI.EDU. 86400 A 26.3.0.103
C.ISI.EDU. 86400 A 10.0.0.52
Здесь приведено содержание текстового файла главного архива. Все записи, за исключением записи SOA RR, укладываются в одну строчку. Класс всех записей зоны должен быть один и тот же, поэтому только первая запись зоны SOA RR содержит информацию класса. Далее расположены записи RR NS уполномоченных серверов доменов MIL и EDU, с записями так называемых "приклеенных" адресов (эти записи не являются частью зоны).
К корневому домену присоединены четыре записи RR: SOA, определяющая корневую зону, и три NS RR, которые содержат параметры серверов имен корневой зоны. Данные записи SOA RR описывают управляющие параметры зоны. Данные зоны инсталлированы на хосте SRI-NIC.ARPA, и главную часть зоны составляет домен HOSTMASTER@SRI-NIC.ARPA.
Когда сервер имен загружает информацию о зоне, он устанавливает минимальное значение TTL-записей зоны в значение поля MINIMUM (здесь оно равно 86400 секунд или 1 день), это означает, что все управляющие данные зоны не могут иметь значение TTL ниже данного.
Записи NS RR доменов MIL и EDU устанавливают границу между корневой зоной и зонами MIL и EDU.
Примечание
В данном примере нижние (дочерние) зоны обслуживаются серверами имен, которые также обслуживают и корневую зону.
Далее, в качестве еще одного примера, приведена часть файла главного архива зоны EDU:
EDU. IN SOA SRI-NIC.ARPA. HOSTMASTER.SRI-NIC.ARPA. (
870729 ;(serial)
1800 ;(refresh) 30 minutes
300 ;(retry) 5 minutes
604800 ;(expire)
86400 ;(minimum) of a day
)
NS SRI-NIC.ARPA.
NS C.ISI.EDU.
UCI 172800 NS ICS.UCI
172800 NS ROME.UCI
ICS.UCI 172800 A 192.5.19.1
ROME.UCI 172800 A 192.5.19.31
. . .
UDEL.EDU. 172800 NS LOUIE.UDEL.EDU.
172800 NS UMN-REI-UC.ARPA.
LOUIE.UDEL.EDU. 172800 A 10.0.0.96
172800 A 192.5.39.3
. . .
MIT.EDU. 43200 NS XX.LCS.MIT.EDU.
43200 NS ACHILLES.MIT.EDU.
XX.LCS.MIT.EDU. 43200 A 10.0.0.44
ACHILLES.MIT.EDU. 43200 A 18.72.0.8
ы построения запросов и ответов серверов имен
Запрос QNAME=SRI-NIC.ARPA, QTYPE=A выглядит следующим образом:
|
|
Рис.17. Формат DNS-сообщения запроса и значения полей сообщения
Ответ от сервера имен C.ISI.EDU имеет вид:
|
|
Рис.18. Формат DNS-сообщения запроса и значения полей сообщения ответа
Заголовок (header) сообщения ответа выглядит так же, как и заголовок запроса, за исключением того, что установлен бит RESPONSE (ответ) и бит ЛА (ответ пришел от уполномоченного сервера). Поле Question сообщения ответа выглядит так же, как и поле Question запроса. Поле данных сообщения ответа содержит запрашиваемые адреса.
Если тот же самый запрос пришел бы от другого сервера, который не является уполномоченным сервером домена SRI-NIC.ARPA, ответ выглядел бы гак. как показано на рис. 19.
|
/p> |
Рис.19. Формат DNS- сообщения ответа от неуполномоченного сервера DNS и значения полей сообщения ответа
Заголовок этого сообщения не содержит бита АА и TTL принимает другое значение. Можно предположить, что эти данные получены не из зоны, а из кэша, и время нахождения данных в кэше составляет разницу между значением TTL, установленным в зоне и полученным (8640— 1777). Порядок записей в сообщении ответа RR не имеет значения.
Рассмотрим запрос QNAME=SR1-NIC.ARPA, QTYPE=*. Этот запрос аналогичен предыдущему, только тип возвращаемых данных может принимать различные значения. Тогда от хоста C.ISI.EDU мы получим следующий ответ (рис. 20):
|
|
Рис.20. Формат DNS-сообщения ответа на запрос всех ресурсов, ассоциированных с определённым именем и значением полей сообщения ответа
Если тот же самый запрос будет направлен на сервер имен, который не уполномочен для работы с SRI-NIC.ARPA, ответы будут следующими (рис.21 и 22):
|
|
Рис.21. Формат DNS-сообщения ответа от неуполномоченного сервера имен на запрос всех ресурсов, ассоциированных с определенным именем, и значения полей сообщения ответа
|
|
Рис.22. Формат DNS-сообщения ответа от другого неуполномоченного сервера имен на запрос всех ресурсов, ассоциированных с определенным именем, и значения полей сообщения ответа
Оба ответа не содержат бита АА. Кроме того, эти два сообщения содержат различные значения TTL, а это значит, что оба отвечающих сервера поместили эти данные в кэш в различное время и первый кэшировал ответы с типом QTYPE=A, а второй — с типом HINFO.
Рассмотрим запрос QNAME=SRI-NIC.ARPA, QTYPE=MX. Такой запрос может быть сделан при поиске серверов — маршрутизаторов почты. Ответ сервера C.ISI.EDU будет такой, как показано на рис. 3.23.
Ответ содержит секции MX RR. Кроме того, дополнительные секции пакета содержат информацию об адресах почтовых серверов.
Составим запрос QNAME==SIR-NIC.ARPA, QTYPE=A, в котором пользователь ввел неверное имя домена. Ответ от C.ISI.EDU будет таким, какой показан на рис. 3.24.
Сообщение указывает, что такое имя не существует (выставлен флаг ошибки — RCODE). Запись начала зоны SOA, содержащаяся в поле Authority указывает, что имя домена, указанное в запросе, не существует в данной зоне SOA как минимум 86400 секунд — это срок обновления информации зоны.
|
|
Рис. 23. Формат DNS-сообщения ответа на запрос поиска серверов — маршрутизаторов почты (тип — MX) и значения полей сообщения ответа
|
|
Рис. 24. Формат DNS-сообщения ответа на запрос адреса несуществующего ресурса и значения полей сообщения ответа
Отправим запрос QNAME=BRL.MIL, QTYPE=A на сервер C.ISI.EDU. Ответное сообщение будет иметь вид, показанный на рис. 25.
|
|
Рис. 25. формат DNS-сообщения ответа на запрос адреса ресурса неуполномоченного сервера имен и значения полей сообщения ответа
Поле ответа данного сообщения не содержит информации. Отвечающж сервер С.ISI.EDU не уполномочен для работы с доменом MIL, и он возвра щает информацию об уполномоченных для работы с доменом MIL серверах имен - A.ISI.EDU и SRI-NIC.ARPA.
Примеры работы программы разрешения имен
Следующие примеры иллюстрируют работу программы разрешения имен на компьютере клиента. Предполагаем, что программа разрешения начинает работу без кэша (как бывает после перезагрузки компьютера), хосты системы расположены по адресам 26.х.х.х, и структура SBELT содержит следующую информацию:
match count = -1
SRI-NIC.ARPA. 26.0.0.73 10.0.0.51
A.ISI.EDU. 26.3.0.103
Эта информация определяет серверы, к которым можно обращаться за информацией. Параметр match count = -1 обозначает "удаление" этих серверов (этот параметр играет роль на последующих стадиях алгоритма разрешения).
Предположим, что первый запрос пришел от программы локального почтового клиента, который хочет отправить почту по адресу PVM@ISI.EDU. Почтовый клиент запрашивает записи типа MX домена ISI.EDU.
Программа разрешения просматривает кэш и ищет записи MX RR для ISI.EDU. Но поскольку кэш пуст, она организует опрос серверов имен, и ищет записи NS доменов ISI.EDU, EDU и корневого. Предположим, что и этот опрос ничего не дал. Тогда программа обращается за информацией к структуре SBELT — она копирует ее в структуру SLIST.
Теперь программа разрешения должна выбрать один из трех адресов серверов имен. Поскольку сеть локального хоста 26.х.х.х, выбор делается между 26.0.0.73 и 26.3.0.103 (как правило, берется первый, по порядку следования, адрес). Затем по выбранному адресу отправляется запрос (рис.26):
|
|
Рис. 26. формат DNS-сообщения запроса серверов MX и значения полей сообщения запроса
Если ответ не приходит через определенный промежуток времени, запрос отправляется на другой адрес (при этом запрос может быть отправлен и по ранее использованному адресу).
Предположим, что от SRI-NIC. ARPA получен ответ (рис. 27):
|
/p> |
Рис. 27. Формат DNS- сообщения ответа на запрос серверов MX от неуполномоченного сервера и значения полей сообщения ответа
Программа разрешения кэширует ответ и на его основе строит новый SLIST, который будет выглядеть следующим образом:
match count = 3
A.ISI.EDU. 26.3.0.103
VAXA.ISI.EDU. 10.2.0.27 128.9.0.33
VENERA.ISI.EDU. 10.1.0.52 128.9.0.32
Теперь программа разрешения делает запрос по искомому типу MX. Ответ будет выглядеть примерно так, как показано на рис.28.
После получения ответа, программа разрешения добавляет эту информацию в кэш и возвращает MX RR клиенту.
|
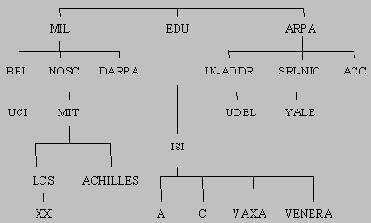
Программы разрешения именПрограммы разрешения имен (resolve) представляют собой интерфейс для работы пользовательских программ с серверами имен домена. В простейшем случае, программа разрешения получает запрос от пользовательской программы (например, почтового агента, TELNET или FTP) в виде системного вызова или вызова из подпрограммы. Требуемая информация возвращается в формате, понятном пользовательской программе и совместимом с форматом данных локального хоста. Программы разрешения расположены на той же самой машине, что и программы, запрашивающие этот сервис. Но для работы программ разрешения необходимо обращаться к серверам имен на других хостах, и время ответа этих программ может варьироваться от миллисекунд до нескольких секунд. Поэтому одной из важных особенностей программ разрешения является возможность устранения сетевых задержек ответов, используя механизм кэширования предыдущих результатов запросов. Этот механизм позволяет разделять доступ и совместно использовать кэш данной программы разрешения имен различными процессами, пользователями и хостами сети. Пространство имен домена и записи базы данныхСпецификация Структура пространства имен домена представляет из себя "дерево". Каждый узел сети (или лист этого "дерева") обозначает ресурс системы, который реально может и не существовать. Узел имеет метку, длина которой может достигать 63 байт. Метка с нулевой длиной используется для обозначения корня дерева, т. е. данного домена. Пример древовидного пространства имен домена приведен на рис.5.
Рис.5. Пример древовидного пространства имен домена Полное имя домена представляет собой путь от данного узла к корню "дерева", составленный из меток доменов старших уровней, т. е. доменов, расположенных ближе к корню "дерева" в системе иерархии доменов. Имя домена представляет собой строку из ASCII-символов верхнего или нижнего регистра первой половины таблицы символов (до 128). Полное имя состоит из меток доменов (данного домена и всех родительских), отделенных друг от друга символом ".". Данный домен может представлять собой субдомен от "родительских" доменов. Например, A.B.C.D — субдомен домена B.C.D, субдомен доменов C.D, D и корневого домена. К данному домену можно обращаться через полное (абсолютное) имя, например, "silly.tamu.edu", или через имя внутри домена — родителя, например, "silly", когда мы находимся внутри домена "tamu.edu". Длина полного имени домена, т. е. сумма длин всех меток пути ограничена 255 байтами. Древовидная структура имен доменов подразумевает распараллеливание областей управления частями этой структуры между организациями. Потенциально, каждый узел "дерева" может являться родителем неограниченного числа новых субдоменов. Однако на практике это ограничивается администраторами серверов имен. Техническая спецификация DNS не указывает, каким образом строить то или иное пространство имен для данной системы доменов — это предоставляется сетевым администраторам системы. Она описывает только наиболее общие принципы построения, которые могут использоваться для работы с DNS программными приложениями, т. к. разные части дерева могут иметь различную семантику и использоваться приложениями для различных целей. В примере, приведенном на рис.5, корневой домен содержит три субдомена: MIL, EDU и ARPA. Домен LCS.MIT.EDU содержит один субдомен XX.LCS.MIT.EDU. Все "листья" "дерева" также являются доменами. Серверы именСерверы имен управляют информацией, которую составляет база данных имен и адресов домена. База данных разделена на секции, называемые зонами, которые распределяются для обслуживания между различными серверами имен. Основной задачей серверов имен является обработка запросов на основе информации локальных зон, расположенных на данном хосте, или переадресация запроса на серверы, располагающие требуемой информацией. Структура работы сервера имен во многом зависит от сетевой среды работы, операционной системы хоста и от структуры данных, которыми сервер управляет. Основной единицей базы данных пространства имен является зона. Система доменов и распределенная база данных DNS
Для обращения к хостам в сети Internet используются 32-разрядные IP-адреса, однозначно идентифицирующие любой сетевой компьютер. Однако для пользователей применение IP-адресов при обращении к хостам не очень удобно. Поэтому в Internet принято присваивать имена всем компьютерам. Использование имен дает пользователю возможность лучше ориентироваться в кибер-пространстве Internet — куда проще запомнить, например, имя www.foyota.com, чем четырехзвенную цепочку IP-адреса. Применение в Internet понятных для пользователей имен и породило проблему их преобразования в IP-адреса. Такое преобразование необходимо, так как на сетевом уровне адресация пакетов осуществляется не по именам, а по IP-адресам, следовательно, для непосредственной адресации сообщений в Internet имена не годятся. Поэтому была создана новая система преобразования имен, позволяющая пользователю, в случае отсутствия у него информации о соответствии имен и IP-адресов, получить необходимые сведения. Эта система получила название системы имен доменов — DNS (Domain Name System). DNS (Domain Name System) - это распределенная база данных, поддерживающая иерархическую систему имен для идентификации узлов в сети Internet. Служба DNS предназначена для автоматического поиска IP-адреса по известному символьному имени узла. Спецификация DNS определяется стандартами RFC 1034 и 1035. DNS требует статической конфигурации своих таблиц, отображающих имена компьютеров в IP-адрес. Для реализации системы DNS был создан специальный сетевой протокол DNS. Кроме того, в сети создавались специальные выделенные информационно-поисковые серверы — DNS-серверы. Протокол DNS является служебным протоколом прикладного уровня. Этот протокол несимметричен - в нем определены DNS-серверы и DNS-клиенты. DNS-серверы хранят часть распределенной базы данных о соответствии символьных имен и IP-адресов. Эта база данных распределена по административным доменам сети Internet. Клиенты сервера DNS знают IP-адрес сервера DNS своего административного домена и по протоколу IP передают запрос, в котором сообщают известное символьное имя и просят вернуть соответствующий ему IP-адрес. Если данные о запрошенном соответствии хранятся в базе данного DNS-сервера, то он сразу посылает ответ клиенту, если же нет - то он посылает запрос DNS-серверу другого домена, который может сам обработать запрос, либо передать его другому DNS-серверу. Все DNS-серверы соединены иерархически, в соответствии с иерархией доменов сети Internet. Клиент опрашивает эти серверы имен, пока не найдет нужные отображения. Этот процесс ускоряется из-за того, что серверы имен постоянно кэшируют информацию, предоставляемую по запросам. Клиентские компьютеры могут использовать в своей работе IP-адреса нескольких DNS-серверов, для повышения надежности своей работы. База данных DNS имеет структуру дерева, называемого доменным пространством имен, в котором каждый домен (узел дерева) имеет имя и может содержать поддомены. Имя домена идентифицирует его положение в этой базе данных по отношению к родительскому домену, причем точки в имени отделяют части, соответствующие узлам домена. Корень базы данных DNS управляется центром Internet Network Information Center. Домены верхнего уровня назначаются для каждой страны, а также на организационной основе. Имена этих доменов должны следовать международному стандарту ISO 3166. Для обозначения стран используются трехбуквенные и двухбуквенные аббревиатуры, а для различных типов организаций используются следующие аббревиатуры: com - коммерческие организации (например, microsoft.com); edu - образовательные (например, mit.edu); gov - правительственные организации (например, nsf.gov); org - некоммерческие организации (например, fidonet.org); net - организации, поддерживающие сети (например, nsf.net). В целях предоставления зарубежным странам, чьи сети входят в INTERNET, возможности контроля за именами находящихся в них систем создан набор 2-х буквенных доменов, которые соответствуют доменам высшего уровня для этих стран. Например: au для Австралии ca для Канады cn для Китая fi для Финляндии fr для Франции se для Швеции и т.д. Общее число кодов стран - 300; компьютерные сети существуют приблизительно в 150 из них. Следует отметить, что США имеют свой собственный код страны, хотя он широко не иcпользуется. В США большинство систем пользуются “организационными” доменами (типа edu ), а не “географическими”( типа va.us - штат Вирджиния). Каждый домен DNS администрируется отдельной организацией, которая обычно разбивает свой домен на поддомены и передает функции администрирования этих поддоменов другим организациям. Каждый домен имеет уникальное имя, а каждый из поддоменов имеет уникальное имя внутри своего домена. В имени может быть любое число доменов, но более пяти встречается редко. Каждый последующий домен в имени (если смотреть слева направо) больше предыдущего. Имя домена может содержать до 63 символов. Каждый хост в сети Internet однозначно определяется своим полным доменным именем (fully qualified domain name, FQDN), которое включает имена всех доменов по направлению от хоста к корню. Состав и основные элементы DNSDNS имеет три основные компоненты:
/p> Работа системы DNS в целом может представляться по-разному:
Примечание В целях увеличения производительности, сервер имен и программы разрешения имен на одной машине могут частично выполнять функции друг друга и разделять доступ к базе данных. Основным предназначением системы имен домена является обеспечение работы механизма именования ресурсов. Этот механизм должен работать с различными хостами, сетями, семействами протоколов и типами организаций. Описанная выше функциональная структура DNS позволяет изолировать проблемы отдельных модулей системы, и, тем самым, создает универсальную модульную архитектуру, пригодную для работы в гетерогенных средах. Хост может участвовать в работе системы доменов различными способами, в зависимости от типа программного обеспечения и требуемой информации, Пользователь взаимодействует с пространством имен через программы разрешения. Запросы пользователя представляют собой вызовы функций программы разрешения (или системных функций, если программа разрешения составляет часть операционной системы) с соответствующими параметрами. Программа разрешения отвечает на запросы пользователей на основании имеющейся у нее в кэше информации или переадресовывает запросы на Другие серверы имен. Программа разрешения может отправить несколько запросов на несколько серверов имен одновременно. Простейший и наиболее распространенный способ работы с серверами имен показан на рис. 1. 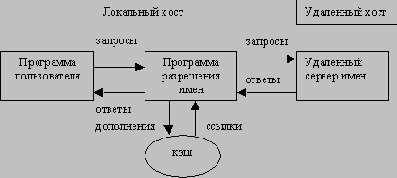 Рис. 1. Простейший способ работы с серверами имен Сервер имен может работать как отдельная программа (процесс) на выделенной машине, которая специально для этого предназначена. Представленный на рис.2 сервер имен обрабатывает запросы на основании информации из файлов главного архива локальной системы. 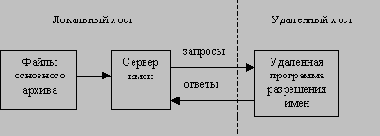 Рис.2. Схема работы сервера имен с локальной базой имен Система DNS требует, чтобы доступ к информации определенной зоны мог быть осуществлен с нескольких серверов имен. Серверы, имеющие доступ к данной зоне, должны синхронизировать информацию, используя механизм перемещения зон DNS. На схеме, приведенной на рис.3, сервер имен периодически устанавливает виртуальное соединение с другим сервером и синхронизирует информацию общих зон. Протокол синхронизации почти такой же, что используется при запросах пользователей. 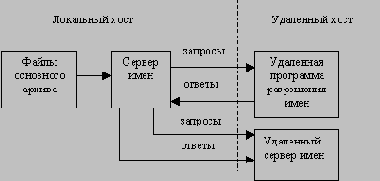 Рис.3. Схема взаимодействия двух серверов имен Показанная на схеме (рис.4) разделяемая база данных хранит данные пространства имен, которые состоят из записей, поступающих с операциями обновления и кэшированных данных запросов. 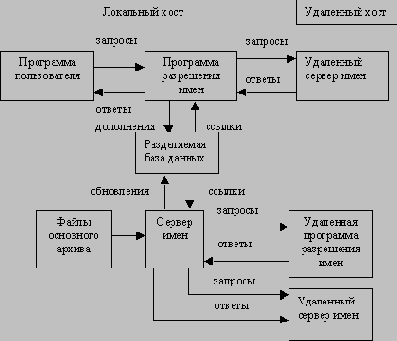 Рис.4. Схема полной функциональности DNS Текстовое представление данныхЗаписи RR хранятся в базе данных DNS и передаются в пакетах DNS-протокола в двоичном виде. Однако, как известно, RRs модифицируются администратором в файлах главного архива в текстовом формате. Текстовый формат представления состояния базы данных значительно упрощает процедуры вставки, модификации или удаления записей. Текстовый файл содержит последовательность записей, которые располагаются в строчки, заканчивающиеся символом перевода строки — <CRLF>. Для размещения информации на нескольких строках используются скобки. Ниже перечислены некоторые из этих символов, имеющих специальное значение:
Примечание
В записях ресурсов доменное имя, не заканчивающееся точкой, считается относительным. При обработке оно прибавляется к текущему домену. Поэтому, когда задается полное имя, его необходимо заканчивать точкой. Общая структура файла выглядит следующим образом: <domain-name><RR> [; <coniment>] <blank><RR> [ ;<comrnent>] <blank>[;<comment>] $INCLUDE <file-name> [<domain-name>] ;[<cominent>]
/p>
[<class>] [<TTL>] <type> <RDATA>
NS A.ISI.EDU. NS VAXA MX 20 VAXA A A 26.3.0.103 VAXA A 10.2.0.27 А 128.9.0.33 /p> $INCLUDE <SUBSYS>ISI-MAILBOXES.TXT где файл <SUBSYS>ISI-MAILBOXES.TXT может содержать, например, следующее: МОЕ MX A.ISI.EDU. LARRY MX A.ISI.EDU. STOOGES MX МОЕ |

XX.LCS.MIT.EDU. 17777 IN A 10.0.0.44
Записи базы данных
Имя домена идентифицирует ресурс системы. Эта ассоциация хранится в базе данных DNS виде отдельной записи — resource records (RRs), компоненты которой представлены на рис. 6.
| 0 | 15 |
|
NAME |
TYPE |
CLASS |
TTL |
RDLENGTH |
RDATA |
Рис.6. Компоненты записи RR
NAME (255 байт). Имя, которое идентифицирует ресурс. Имя ресурса содержит имя домена (или хоста пользователя), в котором расположен этот ресурс, т. е. "владельца" информации. Например, RR, которая содержит IP-адрес хоста, содержит и имя домена, в котором расположен этот адрес. (Серверы имен хранят информацию о ресурсе в древовидной структуре параллельно со структурой пространства имен в базе данных.)
TYPE (2 байта). Тип ресурса. Тип обозначает группу принадлежности ресурса, например, адрес хоста или идентификатор почтового роутера.
CLASS (2 байта). Поле класса ресурса. Поле класса идентифицирует формат данных ресурса. Например, принадлежит ресурс IP-адреса хоста к ARPA Internet (класс "IN") или к Computer Science Network format (класс "CSNET"). Необходимо отметить, что для разных типов ресурса класс ресурса может означать разное. Например, класс IN использует только 32-битные IP-адреса, а класс CSNET использует как 32-битные IP-адреса, так и адреса Х25 и номера телефонов. То есть поле класса используется как указатель того, как использовать информацию, хранящуюся в данном ресурсе.
TTL (32 бита). Параметр, используемый для управления RR. TTL задает временной интервал продолжительности нахождения данной записи в кэше системы (в секундах). При просмотре этой записи в кэше данный интервал уменьшается, и если он становится меньше или равным нулю — данная запись в кэше системы уничтожается. Если данное поле пустое, то в качестве TTL берется значение поля Minimum, задаваемое в записи SOA.
LENGTH (32 бита). Длина поля данных. Это поле позволяет серверу имен или программе разрешения имен домена определить границы данных, даже если они не в состоянии интерпретировать содержимое поля данных.
DATA. Данные ресурса. Максимальная длина поля — 65535 байт. Формат представления данных определяется полями типа и класса.
Поле типа может принимать одно из следующих значений (в таблицу включены наиболее распространенные типы записей):
| Тип | Величина | Описание |
| A | 1 | Адрес хоста или ресурса (вид адреса определяется полем класса) |
| NS | 2 | Сервер имен домена определяет имя хоста, который управляет пространством имен и адресов домена и, тем самым устанавливает нижнюю границу зоны, открытой записью SOA (точнее, определяет первую запись вне данной зоны) |
| MX | 15 | Идентификатор почтового роутера (определяет хост, который служит в данном домене в качестве обработчика всей поступающей почты) |
| CNAME | 5 | Псевдоним ресурса |
| SOA | 6 | Имя домена, определяющего начало зоны пространства имен данного домена (владельца записи). Кроме тех случаев, когда сервер имен передает полномочия самому себе, SOA определяет верхнюю границу области полномочий ( в текстовом файле - верхнюю границу зоны). Кроме того, поле данных может содержать дополнительную информацию о зоне, используемую сервером имен (временные интервалы обновления, и т.д.). Записи SOA никогда не кэшируются и создаются при инсталляции сервера имен. |
| PTR | 12 | Указатель другой части пространства имен домена |
| WKS | 11 | Описание сервисов хоста (содержит спецификацию работающих на данном компьютере сервисов) |
| HINFO | 13 | Идентификатор процессора (CPU) и операционной системы (OS) хоста. |
Класс означает принадлежность записи к определенной системе, тогда как тип определяет функциональность записи в этой системе.
Например, сеть Internet определена значением поля класса = 1, и обозначением "IN" — Internet, а сеть CHAOS значением класса = 3, и обозначением "СН".
Для типа "А" класса "IN" поле данных будет содержать 32-битный IP-адрес, а для того же типа класса "СН" (система CHAOS) — имя домене CHAOS, следующее за 16-битным адресом CHAOS.
Как уже было сказано, формат поля данных во многом зависит от типа записи. Ниже представлены форматы полей данных ресурса для класса "IN' некоторых типов RR.
| Тип "CNAME". Запись с ресурсом типа CNAME (рис.7) применяется для указания псевдонима хоста, тип — строка. |
| 0 | 15 |
CNAME |
| Тип "HINFO". Запись с ресурсом типа HINFO (рис.8) служит для хранения информации о хосте, например, об аппаратной платформе и операционной системе компьютера. CPU тип — строка, OS тип — строка. |
| 0 | 15 |
CPU |
| OS |
| Тип "MX". Для отдельных хостов или всего домена запись с ресурсом типа MX (рис.9) позволяет определить почтовый шлюз — компьютер, куда будет направляться электронная почта, предназначенная для этих хостов. Поле данных состоит из 16-битного значения приоритетности почтового роутера, задает приоритет доставки. При этом ноль означает самый высокий приоритет, и строки — имени хоста, работающего как почтовый роутер. |
| 0 | 15 |
/p>
PREFERENCE |
| EXCHANGE |
Рис. 9. Запись с ресурсом типа MX
| Тип "NS". Запись с ресурсом типа NS (рис.10) обозначает имя хоста, являющегося первичным сервером имен для домена. Поле данных содержит имя хоста |
| 0 | 15 |
NSDNAME |
| Тип "SOA": параметры зоны. Запись с ресурсом типа SOA (рис.11) обозначает начало зоны управления сервера имен. Зона управления действует до следующей записи SOA. Пакет данных содержит: MNAME — имя родительского домена данной зоны; RNAME — имя домена, обозначающее почтовый ящик администратора зоны; SERIAL — 32-битный идентификатор зоны; REFRESH — 32-битное значение интервала времени (в секундах), через который содержание зоны должно обновляться; RETRY — 32-битный интервал (в секундах) повторения запросов обновления содержания зоны в случае неудачи операции обновления; EXPIRE — 32-битный интервал (в секундах) продолжительности полномочий домена в зоне; MINIMUM — 32-битное значение (в секундах) минимального значения TTL, которое устанавливается в сообщениях ответа в данной зоне на запросы, если у запрашиваемой записи параметр TTL не установлен в большее значение. |
| 0 | 15 |
MNAME |
| RNAME |
| SERIAL |
| REFRESH |
| RETRY |
| EXPIRE |
| MINIMUM |
| Тип "WKS". Запись с ресурсом типа WKS (рис.12) используется для описания широко известных сервисов, поддерживаемых определенным протоколом, хостом, расположенным по определенному адресу (поле ADDRESS — 32 бита). Поле PROTOCOL (8 бит) специфицирует тип протокола, а битовое поле (<BIT MAP> — переменной длины) определяет порт сервиса, работающий по данному протоколу: каждый бит поля, равный 1, определяет активный порт (если бит, соответствующий номеру порта отсутствует, считается, что он равен 0). Например, если PROTOCOL=6 (TCP), а 26-ой бит поля установлен в 1, это означает, что данный хост слушает 25-й (SMTP) порт протокола TCP. Запись WKS создается на каждый протокол, с которым работает хост. |
/p>
| 0 | 8 | 15 |
| ADDRESS | |
| PROTOCOL | BIT MAP |
| BIT MAP |
Запросы. Стандартные и инверсные запросы
Запросы представляют собой сообщения, которые отправляются серверу имен и на которые он должен ответить. Запросы передаются через дейтаграммы UDP (порт 53) или соединения TCP (порт 53). Выбор протокола осуществляется в зависимости от требований операции к скорости и достоверности передаваемых данных.
Например, протокол UDP используется для построения стандартных запросов Internet, но не используется для операций перемещения зоны, поскольку в первом случае важна скорость выполнения операции, а во втором — надежность соединения для передачи данных. Кроме того, UDP позволяет установить более гибкий контроль интервалов повторной передачи потерянных пакетов. TCP используется, например, когда сервер одновременно работает с несколькими соединениями, или клиентская часть требует для передачи данных установки достоверного соединения. Ответ на запрос либо содержит требуемую информацию, либо переадресует запрос на другой сервер имен, либо сообщает о возникновении ошибки обработки или передачи запроса.
Запросы передаются в виде сообщений определенного формата. Сообщение состоит из заголовка, который содержит определенные управляющие поля, такие как поле кода операции (opcode), типа запроса, статуса запроса и др., и четырех секций для параметров записей RR, содержание которых зависит от кода операции запроса (рис.13).
|
Header |
Query |
Answer |
Authority |
Additional |
Рис.13.Структура сообщения DNS-протокола
Заголовок (Header). Содержит управляющие поля.
Запрос (Query). Содержит имя и другие параметры запроса.
Ответ (Answer). Содержит RR ответа на запрос.
Права (Authority). Содержит RR, описывающие другие полномочные для работы с данной RR серверы имен.
Дополнительные секции (Additional). Содержат дополнительную информацию. На рис.14 показана структура заголовка сообщения DNS-протокола.
| 0 | 8 | 15 |
/p>
| ID | |||||||
| QR | OPCODE | AA | TC | RD | RA | Z | RCODE |
| QDCOUNT | |||||||
| ANCOUNT | |||||||
| NSCOUNT | |||||||
| ARCOUNT |
ID (16 бит). Идентификатор цикла запрос-ответ. ID запроса копируется в поле сообщения ответа, которое, в свою очередь, может быть запросом следующей итерации первоначального запроса.
QR (1 бит). Флаг запроса или ответа (0 / 1). OPCODE (4 бита). Тип запроса (простои / инверсный / запрос статуса). АА (1 бит). Флаг уполномоченного ответа. RCODE (4 бита). Код статуса ответа. QDCOUNT (16 бит). Количество записей в секции запроса. ANCOUNT (16 бит). Количество записей в секции ответа. NSCOUNT (16 бит). Количество записей в секции уполномоченных серверов NS. ARCOUNT (16 бит). Количество записей в дополнительной секции.
Стандартный запрос (секция Query) содержит имя домена, информацию на который мы хотим получить (QNAME), тип запроса (QTYPE), класс запроса (QCLASS). Структура секции Query сообщения DNS-протокола представлен на рис. 15. Поля QTYPE и QCLASS по 16 бит каждое, содержат коды типа и класса записи RR, информацию о которой мы хотим получить.
| 0 | 15 |
| QNAME |
| QTYPE |
| QCLASS |
Используя параметры имени домена (хоста), типа и класса, сервер имен ищет в таблице базы данных соответствующие записи.
Например, хост — отправитель почты может сделать запрос о наличии в домене ISI.EDU почтовых роутеров, например, для отправки почты в этот домен. Параметры запроса будут следующими: QNAME=ISI.EDU, QTYPE=MX, QCLASS=IN. В ответ хост получит пакет, содержащий в секции ответа (Answer) структуру записи RR (описание структуры см. выше), например, со следующей информацией:
ISI.EDU. MX 10 MARS.ISI.EDU.
MX 10 POMPA.ISI.EDU.
/p>
дополнительная секция ответа (Additional) может содержать, например, IP-адреса почтовых роутеров:
MARS.ISI.EDU. А 10.2.0.27
А 128.9.0.33
POMPA.ISI.EDU. A 10.1.0.52
А 128.9.0.32
Механизм инверсных запросов используется, например, для соотнесения IP-адресов и имен хостов Internet. Для соотнесения IP-адресов и имен хостов в Internet используется специальный домен IN-ADDR.ARPA. Записи в домене IN-ADDR.ARPA состоят из суффикса IN-ADDR.ARPA и четырех предшествующих ему меток. Каждая метка представляет собой байт Internet-адреса. Расположены метки в порядке, обратном расположению байт Internet-адреса. Например, если Internet-адрес домена 10.2.0.52, то в домене IN-ADDR.ARPA ему будет соответствовать запись 52.0.2.10.IN-ADDR.ARPA. Такое обратное представление адреса позволяет определять управляющие зоны и шлюзы для классов сетей.
Например, если домен IN-ADDR.ARPA содержит информацию о ISI-шлюзе между сетью 10 и 26, и имеет адреса 10.2.0.22 и 26.0.0.103, то база данных будет содержать следующие записи:
10.IN-ADDR.ARPA. PTR GW.ISI.EDU.
26.IN-ADDR.ARPA. PTR GW.ISI.EDU.
22.0.2.10.IN-ADDR.ARPA. PTR GW.ISI.EDU.
103.0.0.26.IN-ADDR.ARPA. PTR GW.ISI.EDU.
При использовании сервиса инверсных запросов следует иметь ввиду, что, поскольку домен IN-ADDR.ARPA и обычный домен данного хоста или шлюза расположены в различных зонах, возможно, что данные в этих доменах будут не согласованы, кроме того, шлюзы, как правило, имеют в разных доменах различные имена.
Предназначение механизма обратных запросов и домена IN-ADDR.ARPA состоит в том, чтобы по IP-адресу хоста можно было быстро определить домен и управляющие элементы домена, где расположен этот хост.
Все серверы имен должны понимать и распознавать как стандартные, так и инверсные запросы. Ясно, что инверсные запросы не могут гарантировать полноту и уникальность возвращаемой информации даже внутри определенного домена. Эти запросы, как правило, используются при инсталляции и тестировании различных компонент сервера имен.
Электронная почта
Служба электронной почты предназначена для обеспечения возможности обмена персональными сообщениями между пользователями ИВС. Данная служба состоит из объектов клиентов службы (клиентских программ доступа) и серверов электронной почты. Серверы электронной почты, взаимодействуя друг с другом, образуют сеть электронной почты. Данная сеть по принципам построения напоминает ранее существовавшие сети с коммутацией сообщений. Каждый пользователь сети закреплен за своим сервером и имеет в нем электронный “почтовый ящик” под определенным именем. Для отправки сообщения достаточно передать его в определенном формате на свой почтовый сервер с указанием адреса получателя. Почтовый сервер, проанализировав адрес получателя, отправит сообщение через сеть почтовых серверов серверу, содержащему почтовый ящик получателя, куда это сообщение и будет положено. Для получения своих сообщений достаточно обратиться к своему почтовому серверу и считать из почтового ящика все свои сообщения.
Существует несколько типов служб электронной почты, базирующихся на различных протоколах обмена: X.400, UUCP, SMTP.
Однако наибольшее распространение получила сетевая служба, используемая в сети Internet, базирующаяся на протоколе SMTP. <
АТМ и модель OSI
Базовая модель OSI не учитывает концепции оверлейных сетей, где один сетевой уровень накладывается на другой, хотя позже понятие таких сетей было введено в модель OSI в качестве дополнения.
Оверлейная модель АТМ представляет собой надстройку и расширение инфраструктуры общепринятых на сегодняшний день протоколов сетевого уровня. Поэтому такая модель обеспечивает сбалансированность установленных в системе приложений и облегчает их последующую переносимость.
АТМ становится сетевым протоколом благодаря исключительной сложности своих систем адресации и маршрутизации, причем вне зависимости от того факта, что в АТМ действуют другие протоколы сетевого уровня.
Библиографическая справка
Frame Relay первоначально замышлялся как протокол для использования в интерфейсах ISDN, и исходные предложения, представленные в CCITT в 1984 г., преследовали эту цель. Была также предпринята работа над Frame Relay в аккредитованном ANSI комитете по стандартам T1S1 в США.
Крупное событие в истории Frame Relay произошло в 1990 г., когда Cisco Systems, StrataCom, Northern Telecom и Digital Equipment Corporation образовали консорциум, чтобы сосредоточить усилия на разработке технологии Frame Relay и ускорить появление изделий Frame Relay, обеспечивающих взаимодействие сетей. Консорциум разработал спецификацию, отвечающую требованиям базового протокола Frame Relay, рассмотренного в T1S1 и CCITT; однако он расширил ее, включив характеристики, обеспечивающие дополнительные возможности для комплексных окружений межсетевого об'единения. Эти дополнения к Frame Relay называют обобщенно local management interface (LMI) (интерфейс управления локальной сетью).
Дополнения LMI
Помимо базовых функций передачи данных протокола Frame Relay, спецификация консорциума Frame Relay включает дополнения LMI, которые делают задачу поддержания крупных межсетей более легкой. Некоторые из дополнений LMI называют "общими"; считается, что они могут быть реализованы всеми, кто взял на вооружение эту спецификацию. Другие функции LMI называют "факультативными". Ниже приводится следующая краткая сводка о дополнениях LMI:
Сообщения о состоянии виртуальных цепей
(общее дополнение).
Обеспечивает связь и синхронизацию между сетью и устройством пользователя, периодически сообщая о существовании новых PVC и ликвидации уже существующих PVC, и в большинстве случаев обеспечивая информацию о целостности PVC. Сообщения о состоянии виртуальных цепей предотвращают отправку информации в"черные дыры", т.е. через PVC, которые больше не существуют.
Многопунктовая адресация (факультативное).
Позволяет отправителю передавать один блок данных, но доставлять его через сеть нескольким получателям. Таким образом, многопунктовая адресация обеспечивает эффективную транспортировку сообщений протокола маршрутизации и процедур резолюции адреса, которые обычно должны быть отосланы одновременно во многие пункты назначения.
Глобальная адресация (факультативное).
Наделяет идентификаторы связи глобальным, а не локальным значением, позволяя их использование для идентификации определенного интерфейса с сетью Frame Relay. Глобальная адресация делает сеть Frame Relay похожей на LAN в терминах адресации; следовательно, протоколы резолюции адреса действуют в Frame Relay точно также, как они работают в LAN.
Простое управление потоком данных
(факультативное).
Обеспечивает механизм управления потоком XON/XOFF, который применим ко всему интерфейсу Frame Relay. Он предназначен для тех устройств, высшие уровни которых не могут использовать биты уведомления о перегрузке и которые нуждаются в определенном уровне управления потоком данных.
Формат сообщений LMI
В предыдущем разделе описан базовый формат протокола Frame Relay для переноса блоков данных пользователя. Разработанная консорциумом спецификация Frame Relay также включает процедуры LMI. Сообщения LMI отправляются в блоках данных, которые характеризуются DLCI, специфичным для LMI (определенным в спецификации консорциума как DLCI=1023). Формат сообщений LMI представлен на Рис. 14-3.
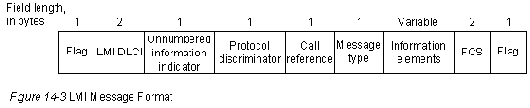
В сообщениях LMI заголовок базового протокола такой же, как в обычных блоках данных. Фактическое сообщение LMI начинается с четырех мандатных байтов, за которыми следует переменное число информационных элементов (IE). Формат и кодирование сообщений LMI базируются на стандарте ANSI T1S1.
Первый из мандатных байтов (unnumbered information indicator-индикатор непронумерованной информации) имеет тот же самый формат, что и индикатор блока непронумерованной информации LAPB (UI) с битом P/F, установленным на нуль. Следующий байт называют "дискриминатор протокола" (protocol discriminator); он установлен на величину, которая указывает на "LMI". Третий мандатный байт (call reference-ссылка на обращение) всегда заполнен нулями.
Последний мандатный байт является полем "типа сообщения" (message type). Определены два типа сообщений. Сообщения "запрос о состоянии" (status enquiry) позволяют устройствам пользователя делать запросы о состоянии сети. Сообщения "состояние" (status) являются ответом на сообщения-запросы о состоянии. Сообщения "продолжайте работать" (keepalives) (посылаемые через линию связи для подтверждения того, что обе стороны должны продолжать считать связь действующей) и сообщения о состоянии PVC являются примерами таких сообщений; это общие свойства LMI, которые должны быть частью любой реализации, соответствующей спецификации консорциума.
Сообщения о состоянии и запросы о состоянии совместно обеспечивают проверку целостности логического и физического каналов. Эта информация является критичной для окружений маршрутизации, т.к.
алгоритмы маршрутизации принимают решения, которые базируются на целостности канала.
За полем типа сообщений следуют несколько IЕ. Каждое IЕ состоит из одно-байтового идентификатора IЕ, поля длины IЕ и одного или более байтов, содержащих фактическую информацию.
Глобальная адресация
В дополнение к общим характеристикам LMI существуют несколько факультативных дополнений LMI, которые чрезвычайно полезны в окружении межсетевого об'единения. Первым важным факультативным дополнением LMI является глобольная адресация. Как уже отмечалось раньше, базовая (недополненная) спецификация Frame Relay обеспечивает только значения поля DLCI, которые идентифицируют цепи PVC с локальным значением. В этом случае отсутствуют адреса, которые идентифицируют сетевые интерфейсы или узлы, подсоединенные к этим интерфейсам. Т.к. эти адреса не существуют, они не могут быть обнаружены с помощью традиционной техники обнаружения и резолюции адреса. Это означает, что при нормальной адресации Frame Relay должны быть составлены статистические карты, чтобы сообщать маршрутизаторам, какие DLCI использовать для обнаружения отдаленного устройства и связанного с ним межсетевого адреса.
Дополнение в виде глобальной адресации позволяет использовать идентификаторы узлов. При использовании этого дополнения значения, вставленные в поле DLCI блока данных, являются глобально значимыми адресами индивидуальных устройств конечного пользователя (например, маршрутизаторов). Реализация данного принципа представлена на Рис.14-4.
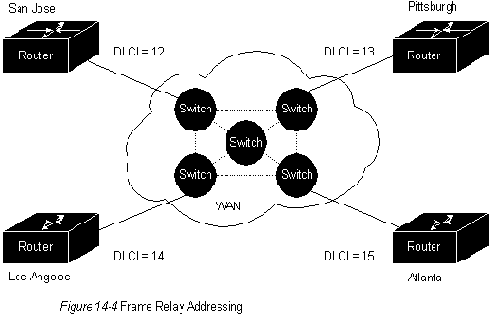
Необходимо отметить, что каждый интерфейс, изображенный на Рис.14-4, имеет свой собственный идентификатор. Предположим, что Питтсбург должен отправить блок данных в Сан Хосе. Идентификатором Сан Хосе является число 12, поэтому Питттсбург помещает величину "12" в поле DLCI и отправляет блок данных в сеть Frame Relay. В точке выхода из сети содержимое поля DLSI изменяется сетью на 13, чтобы отразить узел источника блока данных. Т.К. интерфейс каждого маршрутизатора имеет индивидуальную величину, как у идентификатора его узла, отдельные устройства могут быть различимы.
Это обеспечивает адаптируемую маршрутизацию в сложных окружениях.
Глобальная адресация обеспечивает значительные преимущества в крупных комплексных об'единенных сетях, т.к. в этом случае маршрутизаторы воспринимают сеть Frame Relay на ее периферии как обычную LAN. Нет никакой необходимости изменять протоколы высших уровней для того, чтобы использовать все преимущества, обеспечиваемые их возможностями.
Групповая адресация (multicusting)
Другой ценной факультативной характеристикой LMI является многопунктовая адресация. Группы многопунктовой адресации обозначаются последовательностью из четырех зарезервированных значений DLCI (от 1019 до 1022). Блоки данных, отправляемые каким-либо устройством, использующим один из этих зарезервированных DLCI, тиражирутся сетью и отправляются во все выходные точки группы с данным обозначением. Дополнение о многопунктовой адресации определяет также сообщения LMI, которые уведомляют устройства пользователя о дополнении, ликвидации и наличиии групп с многопунктовой адресацией.
В сетях, использующих преимущества динамической маршрутизации, маршрутная информация должна обмениваться между большим числом маршрутизаторов. Маршрутные сообщения могут быть эффективно отправлены путем использования блоков данных с DLCI многопунктовой адресации. Это обеспечивает отправку сообщений в конкретные группы маршрутизаторов.
Форматы блока данных
Формат блока данных изображен на Рис. 14-1. Флаги ( flags ) ограничивают начало и конец блока данных. За открывающими флагами следуют два байта адресной ( address ) информации. 10 битов из этих двух байтов составляют идентификацию (ID) фактической цепи (называемую сокращенно DLCI от "data link connection identifier").
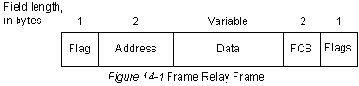
Центром заголовка Frame Relay является 10-битовое значение DLCI. Оно идентифицирует ту логическую связь, которая мультиплексируется в физический канал. В базовом режиме адресации (т.е. не расширенном дополнениями LMI), DLCI имеет логическое значение; это означает, что конечные усторойства на двух противоположных концах связи могут использовать различные DLCI для обращения к одной и той же связи. На рис. 14-2 представлен пример использования DLCI при адресации в соответствии с нерасширенным Frame Relay.
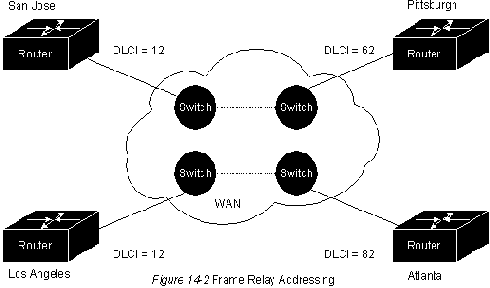
Рис. 14-2 предполагает наличие двух цепей PVC: одна между Aтлантой и Лос-Анджелесом, и вторая между Сан Хосе и Питтсбургом. Лос Анджелес может обращаться к своей PVC с Атлантой, используя DLCI=12, в то время как Атланта обращается к этой же самой PVC, используя DLCI=82. Аналогично, Сан Хосе может обращаться к своей PVC с Питтсбургом, используя DLCI=62. Сеть использует внутренние патентованные механизмы поддержания двух логически значимых идентификаторов PVC различными.
В конце каждого байта DLCI находится бит расширенного адреса (ЕА). Если этот бит единица, то текущий байт является последним байтом DLCI. В настоящее время все реализации используют двубайтовый DLCI, но присутствие битов ЕА означает, что может быть достигнуто соглашение об использовании в будущем более длинных DLCI.
Бит C/R, следующий за самым значащим байтом DLCI, в настоящее время не используется.
И наконец, три бита в двубайтовом DLCI являются полями, связанными с управлением перегрузкой. Бит "Уведомления о явно выраженной перегрузке в прямом направлении" (FECN) устанавливается сетью Frame Relay в блоке данных для того, чтобы сообщить DTE, принимающему этот блок данных, что на тракте от источника до места назначения имела место перегрузка.
Бит "Уведомления о явно выраженной прегрузке в обратном направлении" (BECN) устанавливается сетью Frame Relay в блоках данных, перемещающихся в направлении, противоположном тому, в котором перемещаются блоки данных, встретившие перегруженный тракт. Суть этих битов заключается в том, что показания FECN или BECN могут быть продвинуты в какой-нибудь протокол высшего уровня, который может предпринять соответствующие действия по управлению потоком. (Биты FECN полезны для протоколов высших уровней, которые используют управление потоком, контролируемым пользователем, в то время как биты BECN являются значащими для тех протоколов, которые зависят от управления потоком, контролируемым источником ("emitter-controlled").
Бит "приемлемости отбрасывания" (DE) устанавливается DTE, чтобы сообщить сети Frame Relay о том, что какой-нибудь блок данных имеет более низшее значение, чем другие блоки данных и должен быть отвергнут раньше других блоков данных в том случае, если сеть начинает испытывать недостаток в ресурсах. Т.е. он представляет собой очень простой механизм приоритетов. Этот бит обычно устанавливается только в том случае, когда сеть перегружена.
Инкапсуляция пакетов
Существует методика, в соответствии с которой транспортировка разнообразных пакетов сетевого и канального уровней осуществляется через соединение АТМ (AAL 5), и методика мультиплексирования пакетов разных типов с использованием одного соединения. В этих случаях одно и то же соединение используется многократно для всех пересылок данных между двумя узлами, что экономит соединительные ресурсы. Соединение устанавливается один раз, и дальнейшие задержки с установлением соединений отсутствуют.
Если же сетевой уровень требует гарантий QoS, то для каждого отдельно взятого потока данных необходимо свое собственное соединение. Многократное использование одного соединения возможно только при наличии средства, с помощью которого узел, получивший пакет по соединению АТМ, сможет распознать тип полученного пакета, а также приложение или объект более высокого уровня, которым необходимо передать этот пакет. Для этого пакет снабжается префиксом в виде поля мультиплексирования. Возможны два варианта (см. RFC 1483):
Инкапсуляция LLC/SNAP. При таком способе через одно соединение передаются протоколы разных типов, причем тип инкапсулированного пакета идентифицируется стандартным заголовком LLC/SNAP. Но все соединения, использующие этот тип инкапсуляции, прерываются в оконечной системе на подуровне логического контроля соединений (LLC), поскольку именно здесь происходит мультиплексирование пакетов.
Мультиплексирование VC. При таком способе через соединение АТМ передается протокол только одного типа, изначально определенный при установлении соединения. В результате с пакетом не требуется передавать поля мультиплексирования и типа пакета, хотя передаваемый пакет может быть снабжен префиксом в виде пустого поля.
Мультиплексирование VC может применяться там, где необходимо обеспечить непосредственную связь АТМ между приложениями, в обход протоколов низкого уровня. Но такая непосредственная связь делает невозможным взаимодействие с другими узлами, находящимися вне сети АТМ.
Архитектура протоколов “IP над АТМ” использует инкапсуляцию LLC/SNAP. Кроме того, МСЭ-T одобрил ее в качестве инкапсуляции, принятой по умолчанию для мультипротокольной передачи через сеть АТМ. Рабочая группа “IP над АТМ” определила стандартный размер максимального блока обмена для АТМ, установив его равным 9180 байт.
IP над ATM
Передача протокольных блоков данных любого протокола сетевого уровня через сеть АТМ, работающую в оверлейном режиме, имеет два основных аспекта: инкапсуляцию пакетов (packet encapsulation) и определение адресов (address resolution).
Определение адресов
Чтобы протокол IP мог использоваться в сетях АТМ, необходим механизм преобразования IP-адресов в соответствующие адреса АТМ. Таблица преобразования адресов может быть сконфигурирована вручную, но это не масштабируемое решение. Рабочая группа “IP над АТМ” установила протокол преобразования адресов, обеспечивающий автоматическую поддержку преобразования адресов IP в формат RFC 1577. Такой протокол, получивший название “классического IP над АТМ”, вводит понятие логической подсети IP (Logical IP Subnet, LIS). Подобно “нормальной” подсети IP, LIS состоит из ряда IP-узлов (хостов или маршрутизаторов), связанных в одну подсеть IP.
Для преобразования адресов своих узлов, LIS поддерживает один АТМARP-сервер, в то время как все узлы (клиенты) этой LIS конфигурируются уникальными адресами данного сервера АТМARP. Задействованный узел LIS сначала устанавливает соединение с ее АТМARP - сервером, используя при этом свой конфигурированный адрес. АТМARP-сервер обнаруживает соединение с новым LIS-клиентом, передает подключенному клиенту обратный запрос ARP (Inverse ARP request), запрашивает IP- и АТМ- адреса данного узла и сохраняет их в своей АТМARP-таблице.
Впоследствии любой узел LIS, желающий определить IP-адрес назначения, пошлет на сервер АТМARP-запрос и получит от него ATMARP-ответ, если соответствующее адресное отображение будет найдено. Если - нет, то от сервера поступит отклик АТМ_NAK, указывающий на отсутствие зарегистрированного адресного соответствия. В целях повышения надежности АТМARP-сервер со временем удаляет свою адресную таблицу, как устаревшую. При этом его клиенты должны периодически обновлять свои строки в таблице, в ответ на поступающие от сервера обратные запросы ARP. Клиент LIS, который получил адрес АТМ, соответствующий определенному адресу IP, может установить соединение по такому адресу.
Основы технологии
Frame Relay обеспечивает возможность передачи данных с коммутацией пакетов через интерфейс между устройствами пользователя (например, маршрутизаторами, мостами, главными вычислительными машинами) и оборудованием сети (например, переключающими узлами). Устройства пользователя часто называют терминальным оборудованием (DTE), в то время как сетевое оборудование, которое обеспечивает согласование с DTE, часто называют устройством завершения работы информационной цепи (DCE). Сеть, обеспечивающая интерфейс Frame Relay, может быть либо общедоступная сеть передачи данных и использованием несущей, либо сеть с оборудованием, находящимся в частном владении, которая обслуживает отдельное предприятие.
В роли сетевого интерфейса, Frame Relay является таким же типом протокола, что и Х.25. Однако Frame Relay значительно отличается от Х.25 по своим функциональным возможностям и по формату. В частности, Frame Relay является протоколом для линии с большим потоком информации, обеспечивая более высокую производительность и эффективность.
В роли интерфейса между оборудованием пользователя и сети, Frame Relay обеспечивает средства для мультиплексирования большого числа логических информационных диалогов (называемых виртуальными цепями) через один физический канал передачи, которое выполняется с помощью статистики. Это отличает его от систем, использующих только технику временного мультиплексирования (TDM) для поддержания множества информационных потоков. Статистическое мультиплексирование Frame Relay обеспечивает более гибкое и эффективное использование доступной полосы пропускания. Оно может использоваться без применения техники TDM или как дополнительное средство для каналов, уже снабженных системами TDM.
Другой важной характеристикой Frame Relay является то, что она использует новейшие достижения технологии передачи глобальных сетей. Более ранние протоколы WAN, такие как Х.25, были разработаны в то время, когда преобладали аналоговые системы передачи данных и медные носители. Эти каналы передачи данных значительно менее надежны, чем доступные сегодня каналы с волоконно-оптическим носителем и цифровой передачей данных.
В таких каналах передачи данных протоколы канального уровня могут предшествовать требующим значительных временных затрат алгоритмам исправления ошибок, оставляя это для выполнения на более высоких уровнях протокола. Следовательно, возможны большие производительность и эффективность без ущерба для целостности информации. Именно эта цель преследовалась при разработке Frame Relay. Он включает в себя алгоритм проверки при помощи циклического избыточного кода (CRC) для обнаружения испорченных битов (из-за чего данные могут быть отвергнуты), но в нем отсутствуют какие-либо механизмы для корректирования испорченных данных средствами протокола (например, путем повторной их передачи на данном уровне протокола).
Другим различием между Frame Relay и Х.25 является отсутствие явно выраженного управления потоком для каждой виртуальной цепи. В настоящее время, когда большинство протоколов высших уровней эффективно выполняют свои собственные алгоритмы управления потоком, необходимость в этой функциональной возможности на канальном уровне уменьшилась. Таким образом, Frame Relay не включает явно выраженных процедур управления потоком, которые являются избыточными для этих процедур в высших уровнях. Вместо этого предусмотрены очень простые механизмы уведомления о перегрузках, позволяющие сети информировать какое-либо устройство пользователя о том, что ресурсы сети находятся близко к состоянию перегрузки. Такое уведомление может предупредить протоколы высших уровней о том, что может понадобиться управление потоком.
Стандарты Current Frame Relay адресованы перманентным виртуальным цепям (PVC), определение конфигурации которых и управление осуществляется административным путем в сети Frame Relay. Был также предложен и другой тип виртуальных цепей - коммутируемые виртуальные цепи (SVC). Протокол ISDN предложен в качестве средства сообщения между DTE и DCE для динамичной организации, завершения и управления цепями SVC. Как T1S1, так и CCITT ведут работу по включению SVС в стандарты Frame Relay.
Основы технологии АТМ
 | Особенности технологии АТМ |
| Работа сети АТМ |
| Сигнализация и адресация АТМ |
| АТМ и модель OSI |
| Перспективы использования АТМ |
Одной из наиболее перспективных, быстро развивающихся технологий в области связи в настоящее время является метод высокоскоростной передачи данных с использованием непрерывно следующих друг за другом ячеек фиксированной длины, называемый ATM (Asynchronous Transfer Mode - асинхронный режим передачи). Технология АТМ развивается по пути использования международных стандартов и позволяет передавать по магистральной линии связи с высокой скоростью большие объемы данных различного типа (речь в реальном масштабе времени, видеоизображения, цифровые данные и т.д.). При этом обеспечивается возможность масштабирования сети связи, наращивания ее возможностей по мере возрастания потребностей пользователей в объемах передаваемых данных и в перечне услуг. Рассмотрим подробнее особенности этой технологии передачи информации, ее преимущества и недостатки.
Особенности технологии АТМ
Технология ATM является наиболее перспективным решением задачи переноса разнородной информации в широкополосных цифровых сетях с интеграцией служб. Это - специфический, подобный пакетному, метод переноса информации, использующий принцип асинхронного временного мультиплексирования.
Метод АТМ является ориентированным на соединения: любой передаче информации предшествует организация виртуального соединения (коммутируемого или постоянного) между отправителем и получателем данных, что впоследствии упрощает процедуры маршрутизации. Данные перед их передачей по каналам связи делятся на участки длиной 48 байт. К ним добавляется заголовок (5 байт). Образуются ячейки, которые передаются с использованием виртуальных каналов, т.е. имеющих идентификатор логических каналов, организуемых между двумя устройствами для установления связи. В одном физическом канале связи, как правило, передаются совместно ячейки, принадлежащие множеству различных виртуальных каналов. Ячейки, поступающие от различных комплектов оконечного оборудования данных, объединяются в канале связи, образуя групповой сигнал, и коммутируются в узлах сети.
По сравнению с коммутацией пакетов, где пакеты могут иметь различные размеры с различными расстояниями между ними, ячейки АТМ имеют строго фиксированную длину, кратную байту, и следуют друг за другом без перерывов. Это облегчает процедуры обработки сигнала, что позволяет повысить скорость передачи информации и предоставляет возможности широкополосной связи. В отличие от коммутации каналов с временным уплотнением ячейки предоставляются пользователям только на время передачи информации. При отсутствии необходимости передачи информации пользователь не занимает ресурсы сети связи, что повышает эффективность их использования. Отсюда происходит название метода: термин “асинхронный” означает, что ячейки, принадлежащие одному соединению, поступают в канал связи нерегулярно, и временные интервалы предоставляются источнику сообщений в соответствии с его реальными потребностями.
Небольшая длина ячейки позволяет легко перемежать ячейки, используемые для различных приложений, таких как передача данных, речи и видеоизображений. Высокая скорость дает возможность передавать информацию в реальном масштабе времени.
Контрольные функции, такие как распознавание типа сообщения, подтверждение факта получения сообщения принимающим терминалом, выявление ошибок при передаче информации, управление повторной передачей и т.д. с целью упрощения процедур обработки ячеек промежуточными узлами связи переданы протоколам верхних уровней.
Общая композиция протоколов включает физический уровень, уровень АТМ, уровень адаптации (AAL - ATM Adaptation Layer), который зависит от вида предоставляемой услуги, и верхние уровни.
Физический уровень соответствует традиционному первому уровню эталонной модели взаимодействия открытых систем и регламентирует физическую среду переноса информации. Кроме того он обеспечивает функции идентификации границ ячеек, обнаружения и исправления ошибок в заголовках.
Уровень АТМ служит для мультиплексирования/ демультиплексирования ячеек, генерации заголовков ячеек, выделения информационного поля и прозрачный его перенос. Никакая обработка информационного поля (например, контроль на наличие ошибок) уровнем АТМ не выполняется. Граница между уровнем АТМ и уровнем адаптации соответствует границе между функциями, относящимися к заголовку, и функциями, относящимися к информационному полю.
Уровень AAL поддерживает функции протоколов верхних уровней, обеспечивает адаптацию с ними функций передачи уровня АТМ, а также соединения между АТМ и не-АТМ интерфейсами. Примерами функций данного уровня являются обнаружение информационных блоков, поступающих с верхнего уровня, их сегментация на передающем конце и преобразование исходного цифрового сигнала в ячейки АТМ, восстановление исходной информации из ячеек АТМ на приемном конце, направление информационных блоков к верхнему уровню, компенсация переменной величины задержки в сети АТМ для звуковых сигналов, обработка частично заполненных ячеек, действия при потере ячеек и т.д.
Любая специфическая информация уровня адаптации (например, длина поля данных, отметки времени, порядковый номер), которая должна быть передана между взаимодействующими уровнями адаптации, содержится в информационном поле ячейки АТМ.
Телекоммуникационная сеть, использующая технологию АТМ, состоит из набора коммутаторов, связанных между собой. Коммутаторы АТМ поддерживают два вида интерфейсов: интерфейс “пользователь - сеть” (UNI - user-network interface) и интерфейс “сеть - узел сети” (NNI - network-network interface). UNI соединяет оконечные системы АТМ (рабочие станции, маршрутизаторы и др.) с коммутатором АТМ, тогда как NNI может быть определен как интерфейс, соединяющий два коммутатора АТМ.
На рисунке показан форматячейки АТМ в соответствии со стандартом UNI.
| VCIL | Control | HCS | AL |
ДАННЫЕ |
| Заголовок 5 байт | Поле данных 48 байт | |||
| VCIL - идентификатор постоянного виртуального канала (3 байта). Control - поле управления (1 байт). HCS - поле контрольной суммы (1 байт). AL - поле адаптационного уровня АТМ (4 байта). |
||||
Три двоичных символа четвертого октета используются для идентификации типа сообщения, передаваемого в информационном поле ячейки (данные пользователя или служебная информация управления, контроля и обеспечения).
Данное поле “ тип полезной нагрузки” также может использоваться для информирования о перегрузке в сети.
В пятом октете заголовка содержится проверочная последовательность заголовка. Ячейка уничтожается, если в ее заголовке обнаруживается ошибка. Кроме того с помощью этого поля выполняется синхронизация ячеек АТМ. При отсутствии синхронизма по принятым четырем байтам вычисляется проверочный байт. Процедура повторяется до тех пор пока найденный таким образом проверочный байт не совпадет с принятым пятым байтом, после чего наличие синхронизации проверяется каждые 53 байта. Для поддержания синхронизации ячейки передаются постоянно, даже если нет информации для передачи. В этом случае посылаются пустые ячейки.
Формат ячейки, определенный для интерфейса NNI, немного отличается от рассмотренного. NNI-ячейки в отличие от ячеек UNI не содержат поля управления общим потоком, и четыре первых бита каждой ячейки используются расширенным полем идентификатора виртуального пути (12 бит). Поскольку поле управления общим потоком используется редко, но существует (его использование не определено, например, в решениях по UNI консорциума Форум АТМ), на практике функционального различия между ячейками UNI и NNI нет, кроме разве того, что ячейка последнего может поддерживать большее пространство идентификаторов ВП.
Перспективы использования АТМ
Технология АТМ обладает важными преимуществами перед существующими методами передачи данных в локальных и глобальных сетях, которые должны обусловить ее широкое распространение во всем мире /15/. Одно из важнейших достоинств АТМ - обеспечение высокой скорости передачи информации (широкой полосы пропускания). Появление надежных аппаратно-программных средств сети Ethernet для скорости 1 Гбит/с еще ожидается в перспективе, в то время как АТМ уже сейчас обеспечивает скорость 622 Мбит/с.
АТМ устраняет различия между локальными и глобальными сетями, превращая их в единую интегрированную сеть. Сочетая в себе масштабируемость и эффективность аппаратной передачи информации, присущие телефонным сетям, метод АТМ обеспечивает более дешевое наращивание мощности сети. Это - техническое решение, способное удовлетворить грядущие потребности, поэтому многие пользователи выбирают АТМ часто больше ради ее будущей, нежели сегодняшней значимости.
Стандарты АТМ унифицируют процедуры доступа, коммутации и передачи информации различного типа (данных, речи, видеоизображений и т.д.) в одной сети связи с возможностью работы в реальном масштабе времени. В отличие от ранних технологий локальных и глобальных сетей, ячейки АТМ могут передаваться по широкому спектру носителей от медного провода и волоконно-оптического кабеля до спутниковых линий связи, при любых скоростях передачи, достигающих сегодняшнего предела 622 Мбит/с. Технология АТМ обеспечивает возможность одновременного обслуживания потребителей, предъявляющих различные требования к пропускной способности телекоммуникационной системы.
Однако, несмотря на достоинства АТМ, его повсеместное внедрение задерживается по ряду причин. Для локальных сетей, связывающих персональные компьютеры, распространение технологии АТМ тормозится наличием более дешевых технологий (например, Ethernet). Все еще недостаточна потребность в высоких скоростях передачи, и большинство организаций не стремится использовать расширенную полосу пропускания АТМ, пока передача видеоизображений, графики и информации других видов, требующая высокой пропускной способности линий связи, еще не играет для них важной роли. Одним из основных препятствий для роста АТМ на всех уровнях, а главное, на уровне персональных компьютеров - это отсутствие адекватных стандартов. Многие из них не соответствуют друг другу, не совместимы со своими предшественниками и являются предметом споров различных организаций, предпринимающих усилия по стандартизации. К настоящему времени полный комплект единых готовых стандартов отсутствует. К числу сдерживающих факторов также следует отнести нехватку АТМ-продуктов на рынке программного обеспечения и недостаток опыта работы пользователей.
Указанные достоинства АТМ и причины, задерживающие его повсеместное внедрение, определяют перспективы его дальнейшего использования в развитых зарубежных государствах как коммерческими, так и военными организациями. С течением времени растут потребности пользователей в объемах передаваемых данных, что делает технологию АТМ все более привлекательной. Кроме того, цены на коммутаторы АТМ сокращаются каждый год приблизительно на 50% (начиная с 1991 г.), по мере того как производители наращивают объемы их выпуска. По прогнозам компании по исследованию рынка Forrester Research (Кембридж, шт. Массачусетс), адаптер АТМ для персонального компьютера к концу тысячелетия будет стоить менее 200 долларов.
Для борьбы за единство стандартов и развитие технологии АТМ в 1991 г. был образован консорциум Форум АТМ. К маю 1996 г. им были разработаны 62 спецификации, в том числе интерфейс пользователь-сеть, определяющий, каким образом устройства подключаются к сетям АТМ с различными скоростями, эмуляция локальной сети (LANE - Local Area Network Emulation), эмуляция каналов, базовые сигналы между переключателями, основные принципы тестирования и т.д. Еще 34 спецификации находятся в стадии разработки. В соответствии с соглашением Anchorage Accord, утвержденным на встрече Форум ATM в апреле 1996 г., новые версии спецификаций должны теперь быть совместимы со своими предшественниками, что должно повысить востребованность АТМ.
Как полагают эксперты, технология АТМ будет прокладывать свой путь в инфраструктуры корпораций постепенно, в течение нескольких лет. Пользователи могут строить сеть АТМ поэтапно, эксплуатируя ее параллельно с уже существующими у них системами. Конечно, в первую очередь технология АТМ окажет влияние на глобальные сети, на магистральные линии связи, соединяющие несколько локальных вычислительных сетей. Однако, невзирая на слухи о противоположном, пользователи также готовы к использованию АТМ и в локальных сетях. Недавний опрос, проведенный компанией Sege Research, в котором приняли участие 175 пользователей, касался вопроса о том, какие технологии они намерены использовать в своих сетях в 1999 году. АТМ обогнал по популярности Ethernet. Более 40% пользователей хотели бы установить Ethernet на 100 Мбит/с, а около 45% планируют использовать АТМ на 155 Мбит/с. Совершенно неожиданно оказалось, что 28 % опрошенных намерены использовать АТМ на 622 Мбит/с.
<
Протокол Bridge
Название протокола условное. Протокол предназначен для передачи МАС-кадров между мостами ЛВС, в случае если мосты разнесены и связаны по WAN интерфейсу. Типовая структура протокольного блока (кадра) протокола показана на рисунке.

В ряде случаев структура в деталях может отличаться (в зависимости от фирмы изготовителя оборудования), но в любом случае передаются следующие параметры:
| МАС адрес карты Ethernet получателя |
| МАС адрес карты Ethernet отправителя |
| Тип следующего протокола |
Значения поля "тип следующего протокола" определены в рекомендации RFC1700. Данное поле с теми же значениями используется также в протоколах SNAP и Router* (название условное). Назначение полей приведено здесь.
Протокол Frame Relay
|
Библиографическая справка | |||||
| Основы технологии | |||||
| Дополнения LMI | |||||
| Форматы блока данных | |||||
| Формат сообщений LMI
| |||||
|
Реализация сети |

Протокол HDLC
Протокол может использоваться в каналах доступа к хостам и маршрутизаторам. Обеспечивает гарантированную доставку кадров.
HDLC, LAPB являются бит-ориентированными протоколами канального уровня. Для синхронизации канала используется комбинация типа "флаг" (код 01111110) . Началом передаваемого блока данных (кадра) является первый байт после флага, отличный от него. После передачи последнего информационного байта сразу передаются флаги. Для обеспечения прозрачности кода передаваемой информации используется процедура "битстаффингования". Принудительное добавление “0” после следующих подряд пяти “1”.
Формат блока данных HDLC такой же, как у SDLC; поля HDLC обеспечивают те же функциональные возможности, что и соответствующие поля SDLC. Кроме того, также, как и SDLC, HDLC обеспечивает синхронный режим работы с полным дублированием.
HDLC имеет несколько незначительных отличий от SDLC. Во-первых, HDLC имеет вариант для 32-х битовых контрольных сумм. Во-вторых, в отличие от SDLC, HDLC не обеспечивает конфигурации "loop" и "hub go-ahead". Главным различием между HDLC и SDLC является то, что SDLC обеспечивает только один режим передачи, в то время как HDLC обеспечивает три. HDLC обеспечивает следующие три режима передачи:
Режим нормальной ответной реакции (NRM)
SDLC также использует этот режим. В этом режиме вторичные узлы не могут иметь связи с первичным узлом до тех пор, пока первичный узел не даст разрешения.
Режим асинхронной ответной реакции (ARM)
Этот режим передачи позволяет вторичным узлам инициировать связь с первичным узлом без получения разрешения.
Асинхронный сбалансированный режим (ABM)
В режиме АВМ появляется "комбинированный" узел, который, в зависимости от ситуации, может действовать как первичный или как вторичный узел. Все связи режима АВМ имеют место между множеством комбинированных узлов. В окружениях АВМ любая комбинированная станция может инициировать передачу данных без получения разрешения от каких-либо других станций.
Каждый протокольный блок в общем случае состоит из адреса принимающей станции, поля управления, информационной части и контрольной суммы. В поле управления могут размещаться идентификатор кадра, номера переданного и принятого кадров, признак запроса и др. В протоколе HDLC используются 23 типа протокольных блоков (см. табл.).
Для организации связи станции обмениваются кадрами, определяющими режим передачи данных. В качестве команд установления соединения используются кадры SABM, SABME, SNRM, SNRME, SARM, SARME. Для подтверждения соединения используется кадр UA. Для разъединения используются кадры DISC, DM, RD. Для передачи данных используется кадр I. Каждый кадр I нумеруется. Для управления потоком кадров используются RR, RNR, RES, SRES. Каждый переданный кадр I должен быть подтвержден кадром RR или I. В случае неготовности станции формируется кадр RNR. Для запроса повторной передачи используется кадр REJ либо SREJ. <
Протокол Router
Название условное. Предназначен для связи разнесенных маршрутизаторов через WAN интерфейсы. Обеспечивает поддержку мультипротокольных сетей за счет передачи идентификатора типа следующего протокола.
Значения поля "тип следующего протокола" определены в рекомендации RFC1700. Данное поле с теми же значениями используется также в протоколах SNAP и Router* (название условное). Назначение полей приведено здесь.
Структура информационного кадра протокола приведена на рисунке. Возможны небольшие отличия в зависимости от типа используемого оборудования.
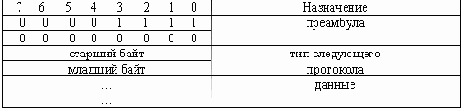 <
<
Протокол SLIP
Протокол SLIP (Serial Line IP) обеспечивает инкапсуляцию IP-пакетов в кадры, пригодные для передачи по последовательному каналу связи. В этом случае IP-дейтаграмма должна завершаться символом 0хС0 (“конец”). Во многих реализациях дейтаграмма и начинается с этого символа, что позволяет принимающей стороне эффективно отбросить все принятое до передачи кадра. Если какой-либо байт дейтаграммы равен символу “конец”, то вместо него передается двухбайтовая последовательность 0хDB, 0xDC. Октет 0хDB выполняет в SLIP функцию ESQ-символа. Если же байт дейтаграммы равен 0хDB, то вместо него передается последовательность 0xDB, 0xDD. Недостатками SLIP считаются отсутствие возможности обнаружения и коррекции ошибок, возможностей обозначать пакеты различными типами, сжимать данные и др. Полное описание протокола можно найти в рекомендации RFC1065. <
Работа сети АТМ
Сеть АТМ - это набор коммутаторов и оконечных систем (хостов, маршрутизаторов и т.д.) АТМ, связанных между собой межточечными каналами связи (point-to-point links), либо интерфейсами UNI или NNI. Первый тип интерфейса (UNI) используется при соединении оконечных систем АТМ, второй (NNI) - при соединении коммутаторов АТМ.
Задачи коммутатора АТМ по сути очень просты: при известном значении ИВК или ИВП получить некоторую ячейку по каналу связи, найти соответствующее соединение в местной таблице преобразования, чтобы тем самым определить выходной порт (или порты), а также новые ВК и ВП для такого соединения на данном канале связи, после чего данная ячейка вместе с соответствующими идентификаторами передается на выходной канал связи.
Каждой передаче данных предшествует настройка местных таблиц преобразования, осуществляемая извне. По способу настройки таких таблиц различают два основных типа АТМ-соединения:
Постоянное виртуальное соединение (Permanent Virtual Connection, PVC). Соединение PVC устанавливается посредством какого-либо внешнего механизма, как правило, посредством административного управления сетью. При этом ряд коммутаторов между источником и приемником АТМ программируется определенным значением ИВК и ИВП.
Коммутируемое виртуальное соединение (Switched Virtual Connection, SVC). Соединение SVC устанавливается автоматически, посредством сигнального протокола. Соединение SVC не требует ручного вмешательства, необходимого для настройки PVC, и, поэтому, оно получило более широкое распространение. Протоколы высокого уровня, действующие в сетях АТМ, как правило, используют SVC.
Существуют, в зависимости от типа соединения (SVC или PVC), два основных варианта соединения АТМ:
Межточечное соединение (point-to-point), при котором две оконечные АТМ-системы соединяются между собой. Такое соединение может быть однонаправленным или двунаправленным.
Точечно-многоточечное соединение (point-to-multipoint), при котором одна передающая оконечная АТМ-система (так называемый “корневой узел”) соединяется с несколькими принимающими оконечными системами (их называют “концевыми узлами”).
Тиражирование ячеек в сети осуществляется посредством коммутаторов АТМ, в которых соединение расходится на несколько ветвей. Такое соединение является однонаправленным и позволяет передавать информацию из корня на концевые узлы, в то время как концевые узлы, в рамках того же соединения, не могут передавать информацию корню или друг другу.
Необходимо отметить, что среди перечисленных вариантов АТМ-соединений отсутствуют возможности широковещательной (broadcasting) или групповой (многоадресной) передачи (multicasting), характерные для многих ЛВС среднего уровня с общей средой передачи данных, таких как Ethernet и Token Ring. В сетях АТМ аналогом групповой (многоадресной) передачи могло бы стать “многоточечно-многоточечное” соединение. Однако такое решение не реализуемо из-за того, что в наиболее распространенном 5 варианте уровня AAL (AAL5), который применяется для передачи данных в сетях АТМ, не предусмотрено никаких средств для чередования ячеек из разных пакетов в одном соединении. Это значит, что все пакеты AAL5, посланные по определенному соединению и в определенном направлении, будут приняты последовательно, без чередования ячеек из различных пакетов, поскольку в противном случае приемник не сможет восстановить полученные пакеты.
Для решения задачи групповой (многоадресной) передачи в АТМ возможны три способа:
Групповая (многоадресная) передача по виртуальному пути. При таком механизме, все узлы группы многоадресной передачи соединяются между собой по многоточечно-многоточечному виртуальному пути, причем каждому узлу назначается свое собственное, уникальное значение ИВК, в рамках данного ВП. Таким образом, пакеты могут быть распознаны по уникальному значению ИВК источника.
Сервер групповой (многоадресной) передачи. При таком механизме все узлы, передающие данные в группу многоадресной передачи, устанавливают межточечную связь с внешним устройством, которое называется сервером групповой (многоадресной) передачи. Посредством точечно-многоточечной связи такой сервер, с свою очередь, присоединен ко всем узлам, принимающим пакеты групповой (многоадресной) передачи.Сервер получает пакеты по межточечным соединениям, а затем передает их через точечно-многоточечное соединение, но только после того, как убедится, что пакеты организованы в последовательности (то есть следующий пакет пересылается только по окончании пересылки предыдущего). Таким образом, предотвращается смешивание ячеек.
Оверлейные точечно-многоточечные соединения. При таком механизме, каждый узел группы многоадресной передачи устанавливает точечно-многоточечное соединение со всеми узлами группы и, в свою очередь, становится концевым узлом в равнозначных соединениях всех остальных узлов. Следовательно, все узлы могут как передавать сигналы на все остальные узлы, так и принимать их со всех остальных узлов.
Действующие в сетях АТМ высокоуровневые протоколы реализуют групповую (многоадресную) передачу двумя последними способами.
Реализация сети
Frame Relay может быть использована в качестве интерфейса к услугам либо общедоступной сети со своей несущей, либо сети с оборудованием, находящимся в частном владении. Обычным способом реализации частной сети является дополнение традиционных мультиплексоров Т1 интерфейсами Frame Relay для информационных устройств, а также интерфейсами (не являющимися специализированными интерфейсами Frame Relay) для других прикладных задач, таких как передача голоса и проведение видео-телеконференций. На Рис. 14-5 "Гибридная сеть Frame Relay" представлена такая конфигурация сети.
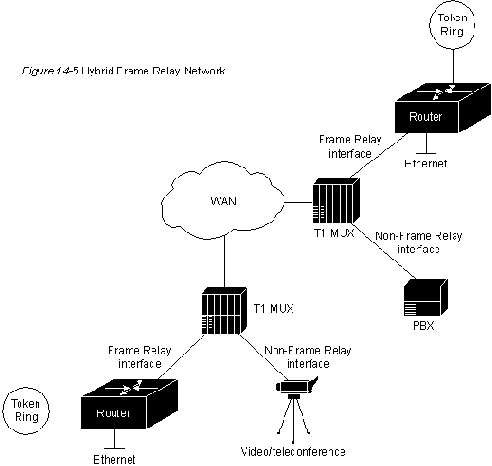
Обслуживание общедоступной сетью Frame Relay разворачивается путем размещения коммутирующего оборудования Frame Relay в центральных офисах (CO) телекоммуникационной линии. В этом случае пользователи могут реализовать экономические выгоды от тарифов начислений за пользование услугами, чувствительных к трафику, и освобождены от работы по администрированию, поддержанию и обслуживанию оборудования сети.
Для любого типа сети линии, подключающие устройства пользователя к оборудованию сети, могут работать на скорости, выбранной из широкого диапазона скоростей передачи информации. Типичными являются скорости в диапазоне от 56 Kb/сек до 2 Mb/сек, хотя технология Frame Relay может обеспечивать также и более низкие и более высокие скорости. Ожидается, что в скором времени будут доступны реализации, способные оперировать каналами связи с пропускной способностью свыше 45 Mb/сек (DS3).
Как в общедоступной, так и в частной сети факт обеспечения устройств пользователя интерфейсами Frame Relay не является обязательным условием того, что между сетевыми устройствами используется протокол Frame Relay. В настоящее время не существует стандартов на оборудование межсоединений внутри сети Frame Relay. Таким образом, могут быть использованы традиционные технологии коммутации цепей, коммутации пакетов, или гибридные методы, комбинирующие эти технологии. <
Сигнализация и адресация АТМ
На различных участках АТМ действуют разные сигнальные протоколы: оконечная система и АТМ обмениваются сигналами АТМ UNI через интерфейс UNI; сигналы АТМ NNI действуют в интерфейсе NNI. Сигнальные запросы АТМ UNI передаются по соединению, установленному по умолчанию: ИВП=0, ИВК=5.
В обмене сигналами по сети АТМ применяется “однопроходный” метод установления связи, действующий во всех распространенных сетях связи (например, в телефонных сетях). Это значит, что запрос на установление связи, поданный определенной оконечной системой-источником, распространяется по сети и устанавливает по пути необходимые соединения до тех пор, пока не достигнет своего пункта назначения: оконечной системы-приемника. Маршрутизация запроса на соединение (а, значит, и любого последующего потока данных) осуществляется под управлением протоколов маршрутизации АТМ. Исходя из адреса назначения, сетевого трафика и параметров QoS (качество обслуживания), затребованных оконечной системой-источником, оконечная система-приемник может по своему выбору принять или отвергнуть запрос на соединение. Маршрутизация вызова производится исключительно на основе параметров, установленных в исходном сообщении-запросе, что ограничивает согласование параметров соединения между источником и приемником, которое также может повлиять на маршрутизацию соединения.
В общих чертах, желающая установить соединение оконечная система-источник формирует и через свой UNI передает в сеть сообщение “Установка”, которое содержит адрес оконечной станции-приемника, желательные параметры сетевого трафика и QoS, разнообразные дополнительные информационные элементы, определяющие привязку к необходимым высокоуровневым протоколам и т.д. Это сообщение “Установка” передается на первый коммутатор (коммутатор ввода), к которому присоединена оконечная система-источник.
Коммутатор вывода отправляет сообщение “Установка” на оконечную систему через ее UNI. Эта система может, по своему выбору, либо принять, либо отвергнуть полученный запрос на соединение.
В первом случае она возвращает запросившей оконечной системе-источнику, по тому же самому пути, сообщение “Соединение”. Оконечная система-источник получает сообщение “Соединение” и подтверждает его получение, после чего каждый узел может начинать передачу данных по установленному соединению. Если оконечная система-приемник отвергает запрос на соединение, она возвращает сообщение “Сброс”, сбрасывая по дороге все установленные параметры соединения (например, все назначенные идентификаторы соединения). Сообщение “Сброс” используется также оконечными системами или сетью для сброса установленного соединения после того, как все данные будут переданы.
Очевидно, что любой сигнальный протокол требует определенной адресной схемы, посредством которой такой протокол идентифицирует источники и приемники, участвующие в соединении. Сектор стандартизации электросвязи (МСЭ-Т) долгое время рекомендовал для применения в общедоступных сетях АТМ систему адресации Е.164, где адреса похожи на телефонные номера. Адреса, соответствующие Рекомендации Е.164, являются общественным (весьма дорогим) ресурсом и, как правило, не могут быть использованы в частных сетях. Поэтому Форум АТМ расширил систему адресации АТМ, распространив схему частных сетей АТМ для спецификации UNI 3.0/3.1. Форум рассмотрел две принципиально разные модели адресации.
Эти модели различаются точкой зрения взаимодействия уровня протокола АТМ с другими существующими уровнями и протоколами, в частности, с существующими протоколами сетевого уровня IP, IPX и т.д. У каждого такого протокола есть своя схема адресации и свои протоколы маршрутизации. Суть одной из моделей состоит в том, чтобы точно такие же схемы адресации использовать в сетях АТМ. Тогда оконечные точки АТМ могут быть заданы готовыми адресами сетевого уровня (например, адресами IP), и эти адреса будут передаваться сигнальными запросами.
Для маршрутизации сигнальных запросов в сетях АТМ подходят также существующие протоколы маршрутизации сетевого уровня (такие как IGRP и OSPF), поскольку эти запросы, в которых применяются существующие адреса сетевого уровня, практически ничем не отличаются от сигнальных пакетов, не ориентированных на установление логических соединений.
Такая модель приравнивает уровень АТМ к существующим сетевым уровням, и, поэтому, ее называют одноранговой (peer) моделью.
Другая, альтернативная модель обособляет уровень АТМ от всех других существующих протоколов и устанавливает для него абсолютно новую систему адресации. Подразумевается, что все существующие протоколы должны работать в сети АТМ. Поэтому данную модель называют подсетевой (subnetwork) или оверлейной (overlay) моделью. Фактически, такой режим работы аналогичен тому, при котором протоколы, подобные IP, накладываются на другие протоколы (например Х.25) или работают в линиях с вызовом по номеру. Оверлейная модель требует определить как новую систему адресации, так и связанный с ней протокол маршрутизации. Каждая система АТМ получает здесь свой собственный адрес в дополнение к адресам других протоколов, которые она поддерживает. Адресное пространство АТМ логически отделяется от адресного пространства любого другого протокола, действующего на уровне АТМ, и, как правило, никак с ним не связано. Поэтому всем протоколам, действующим в подсети АТМ, требуется определенный протокол отображения адресов более высокого уровня (например, адресов IP) на соответствующие адреса АТМ.
Именно по оверлейной модели Форум АТМ реализовал передачу сигналов АТМ в спецификации UNI 3.0/3.1. Одна из причин такого решения состоит в том, что одноранговая модель, упрощая адресацию оконечной системы АТМ, в то же время значительно усложняет коммутаторы АТМ, которые в сущности должны выполнять функции мультипротокольных маршрутизаторов и поддерживать адресные таблицы всех текущих протоколов, а также всех установленных для них протоколов маршрутизации.
Еще одним важным обстоятельством является то, что оверлейная модель отделяет АТМ от других высокоуровневых протоколов, обеспечивая тем самым возможность их независимой реализации.
Получив в свое распоряжение оверлейную модель, Форум АТМ разработал для частных сетей особый адресный формат, основанный на синтаксисе адреса точки доступа к сетевому обслуживанию (NSAP) в среде Взаимодействия открытых систем (OSI).
Все адреса АТМ формата NSAP состоят из трех компонентов: идентификатора полномочий и формата (Authority and Format Identifier, AFI), который задает тип и формат, идентификатора исходного домена (Initial Domain Identifier, IDI), задающего распределение адресов и административные полномочия, и части, определяемой доменом (Domain Specific Part, DSP), которая содержит фактическую информацию о маршрутизации.
В частных сетях АТМ существует три формата адресации, отличающиеся друг от друга типом AFI и IDI:
формат Е.164: в этом случае IDI содержит номер, сформированный в соответствии с Рекомендацией МСЭ-Т Е.164;
формат DCC: в этом случае IDI содержит числовой код страны (Data Country Code, DCC), идентифицирующий определенную страну согласно международному стандарту ISO 3166. Такой адрес каждая организация - член ISO устанавливает для своей страны;
формат ICD: в этом случае IDI представляет собой указатель международного кода (International Code Designator, ICD). Такие указатели присваиваются согласно стандарту ISO 6523 соответствующим регистрационным органом (Британским институтом стандартов). Кодами ICD идентифицируются определенные международные организации.
Организациям и частным провайдерам сетевого сервиса Форум АТМ рекомендует создавать собственные системы нумерации на базе форматов DCC и ICD.
Уровень физического взаимодействия
Данный уровень объединяет протоколы канального и физического уровня ЭМВОС и обеспечивает передачу данных сетевого уровня взаимодействия по физической среде передачи данных, объединяющей группу объектов (от 2 и более) сетевого уровня. Если в группу входит более двух объектов, то одной из задач уровня является выбор конкретного объекта в группе по адресу физического уровня. В качестве физической среды передачи информации используются реальная и виртуальная физические среды, образуемые с помощью телекоммуникационной сети более низкого уровня (например, сеть X.25, Frame Relay, ATM и др.). Уровень физического взаимодействия образуется посредством устройств доступа к физической среде (сетевые адаптеры и устройства канального сопряжения), средств формирования физической среды (кабели, сетевые концентраторы, коммутаторы, мосты, модемы и др). Протоколы физического уровня взаимодействия определяются используемыми технологиями построения сетей, наибольшее распространение среди которых получили TokenRing, Ethernet (различных типов), 100 VG AnyLan, ATM, Frame Relay. Для образования каналов связи используются кабельные линии различных типов, радиосети (RadioLan), каналы связи поставщиков телекоммуникационных услуг. В таблице приведены основные типы уровней физического взаимодействия, используемые в различных средах передачи данных.

Как видно из таблицы, в качестве физической среды взаимодействия сетевых объектов могут использоваться как отдельные каналы связи, так и сами ИВС, сети Frame Relay и АТМ.
Это объясняется тем, что с одной стороны современные сетевые архитектуры обеспечивают возможность создания частных сетей на основе сетей общего пользования. Например, в настоящее время сеть “Sprint” на основе сетевой архитектуры ISO (X.25) используется ее абонентами как физическая среда доступа к сети Internet.
С другой стороны сети АТМ и Frame Relay, выступая в качестве физической среды передачи данных, используют внешние выделенные цифровые каналы для организации своей работы.
Назначение канала определяет и типы используемых в них протоколов обмена. Рассмотрим наиболее часто используемые типы протоколов:
| PPP |
| SLIP (Serial Line IP) |
| Bridge* |
| IEEE802.3-MAC |
| IEEE802.2-LLC |
| SNAP |
| HDLC |
| ATM |
| Frame Relay |
Последовательность символов, закодированных методом Base
Последовательность символов, закодированных методом Base 64, разделяется на группы по 4 символа. Затем каждому символу в соответствии с таблицей кодировки Base64 ставится в соответствие десятичное значение порядкового номера. Каждое десятичное значение представляется в шестибитовом виде, и далее формируется последовательность длиной 24 бита (6*4). Полученная последовательность разбивается на три группы по 8 бит, при приведении которых к символьному виду получаются 3 символа ASCII. Пример реализации алгоритма показан на рисунке 1.
Шесть бит первого символа Base64 являются старшими шестью битами первого байта данных. Их необходимо переместить с позиций 1-6 на позиции 3-8. Для этого выполняется операция сдвига влево на две позиции. Затем выделяются биты с позиций 5-6 из второго символа и комбинируются выделенные 6 старших и 2 младших бита. В результате получается 1-й байт данных.
Для получения 2-го байта данных, выполняются те же операции, только вместо сдвига влево на два и сдвига вправо на четыре бита выполняется сдвиг влево на четыре и вправо на два бита.
Для получения 3-го байта данных берутся 5-6 биты 3-го символа Base64, которые соответствуют первым двум старшим битам данных, и 4-й символ. Результатом сложения является третий байт. <
Язык гипертекстовых ссылок - HTML
HTML - гипертекстовый язык меток, разработан для подготовки гипертекстовых документов в системе WWW современной информационной супермагистрали.
HTML - представляет собой совокупность достаточно простых команд, которые вставляются в исходный текстовый документ (файл в коде ASCII) и позволяют управлять представлением этого документа на экране дисплея. Таким образом текст, подготовленный в любом текстовом редакторе и сохраненный в формате ASCII, становится WWW-страницей (HTML-документом) после добавления в него ряда команд языка HTML.
Базовые элементы языка HTML:
 | форматирование текста; |
| создание списков; |
| связь с другими страницами; |
| вставка изображений; |
| форматирование информации в таблицы; |
| связь с другими услугами Internet (FTP, UseNet), электронной почтой. |
Команды HTML задаются с помощью специальных элементов - тэгов (tag). Tэги позволяют управлять представлением информации на экране при отображении HTML-документов специальными программами просмотра (WWW-браузерами).
Тэг задается в виде строки символов, заключенных между символами < и >. Информация между этими ограничивающимися символами задает содержание команды HTML. Существует два типа команд: команды, задаваемые с помощью одного тэга, и команды, требующие применения пары тэгов. Для команд с парными тэгами применяется правило записи закрывающих тэгов. Если некоторый тэг используется в качестве открывающего, то закрывающий тэг имеет почти такой же вид, но с одним исключением: отличительным признаком закрывающего тэга является символ наклонной черты (slash) перед именем элемента. Например:
<b> Этот текст выделен полужирным начертанием < /b>.
Структура HTML документа
| <HTML> | - | начало страницы |
| <HEAD> | I | служебная информация |
| --------- | } | (например - заголовок документа) |
| </HEAD> | I | |
| <BODY> | I | информация самого |
| --------- | } | документа (" тело" документа) |
| </BODY> | I | |
| </HTML> | - | конец страницы |
Команды HTML
1. Управление расположением текста на экране
| Новый абзац | <P> |
| Горизонтальная линия | <HR> |
| Конец строки | <BR> |
| Заголовки (наибольший) | <H1> |
| Заголовки (наименьший) | <H6> |
| Жирный | <B> Текст будет жирным </B> |
| Курсив | <I> </I> |
| Подчеркивание | <U> </U> |
| Моноширинный | <TT> </TT> |
| Форматированный | <PRE> </PRE> |
| Базовое изображение | <IMG SRC = "имя файла"> |
| Изображение, выровненное по верху текста | <IMG SRC = "имя файла" ALIGN=TOP> |
| Изображение, выровненное по середине текста | <IMG SRC = "имя файла" ALIGN=MIDDLE> |
| Изображение, выровненное по низу текста | <IMG SRC = "имя файла" ALIGN=BOTTOM> |
| Изображение с альтернативным текстом | <IMG SRC = "имя файла" ALT="Альт. Текст"> |
| Отступ текста от левого края | <UL> , <OL> |
| Нумерованные списки | <UL> <LI> Первый элемент списка <LI> Второй элемент списка и т.д. </UL> |
| Маркированный список | <OL><LI> Первый маркер <LI> Второй маркер и так далее </OL> |
| Список определений | <DL><DT> Первый термин <DT> Первое определение <DT> Второй термин <DT> Второе определение и т.д. |
| какой-либо другой документ HTML; |
| любой файл, не являющийся документом HTML (изображение или любой двоичный файл, простой текст и т.д.); |
| некоторая точка в текущем документе HTML. |
/p>
5. Построение гипертекстовых связей
| Внешняя связь | <A HREF="URL>Название ссылки </A> |
| Якорь | <A HREF="Имя якоря" > Название ссылки </A> |
| Внутренняя связь | <A HREF="#Имя якоря"> Название ссылки </A> |
| Электронная почта | <A HREF="maito:Ваш адрес"> Название ссылки </A> |
| FTP (каталог) | <A HREF="ftp://хост/каталог/"> Название ссылки </A> |
| FTP (файл) | <A HREF="ftp://хост/каталог/имя"> Название ссылки </A> |
| Gopher | <A HREF="gopher/хост"> Название ссылки </A> |
| Usenet | <A HREF="news:имя_группы_новостей"> Название ссылки</A> |
| Telnet | <A HREF="telnet://хост"> Название ссылки </A> |
| Заголовок документа ( помещается вся описательная информация и название документа) | <HEAD> </HEAD> |
| Название документа | <TITLE> </TITLE> |
| Тело документа | <BODY> </BODY> |
Процедура предназначена для преобразования двоичных
Процедура предназначена для преобразования двоичных файлов перед передачей их через службы, поддерживающие только 7-битовую ASCII-кодировку (SMTP, NNTP и др.). Сущность преобразования сводится к замене серий двоичных знаков на серии ASCII- символов. Каждая последовательность из трех байт (24 бит) сообщения преобразуется в четыре шестибитовых значения (рис.1). Затем каждому шестибитовому значению ставится в соответствие символ ASCII согласно числу, представленному шестью битами. Количество символов ASCII ограничено 64. Пример соответствия кодов Base64 и ASCII приведен ниже. Если количество символов (байтов) не кратно трем, то используется дополнительный символ “=”.
| Слово: | C | O | P | E |
| Шестнадцатиричное: | 0x43 | 0x4F | 0x50 | 0x45 |
| Двоичное: | 01000011 | 01001111 | 01010000 | 01000101 |
| 6-битовое: | 010000 | 110100 | 111101 | 010000 | 010001 | 010000 |
| Десятичное: | 16 | 52 | 61 | 16 | 17 | 16 |
| Base64: | Q | 0 | 9 | Q | R | Q |
Процедура кодирования сообщений UUcode
Назначение процедуры - такое же, как и у процедуры Base64. Процедура до недавнего времени широко использовалась в сети Internet. В настоящее она постепенно вытесняется более гибкой процедурой Base64.
Входные данные программы UUEncode начинаются со слова “begin” и заканчиваются словом “end”. В строке “begin” также указывается трехзначный номер и имя файла. Трехзначное число указывает права доступа и нотации Unix; обычно для исполняемых программ это число 755 или 700, а для других типов файлов - 644 или 600. Остальные строки содержат непосредственно закодированные данные (рис. 1).
Каждая строка закодированных данных начинается с символа, указывающего на число байт в декодированной строке. Чтобы получить символ ASCII нужно добавить 32 к числу байта в декодированной строке. Последняя строка начинается с символа (‘) , заменяющего пробел (ASCII 32) и указывающего на то, что эта строка не содержит ни одного байта данных. Такая строка помещается в конце каждого файла. Обычно длинный, закодированный программой UUEncode файл имеет в начале большинства строк символ М, это означает, что полная строка кодирует ровно 45 байт данных.

Рис 1.
Процедура декодирования UUEncode аналогична процедуре декодирования Base 64, описанной выше. Отличие состоит в том, что вместо таблицы преобразования символов каждые 6 бит суммируются с числом 32, получая, таким образом, значение символа в интервале от пробела (для нуля) до символа подчеркивания (ASCII). <
Спецификация MIME
Стандарт MIME (Multipurpose Internet Mail Extension), или в нотации Internet RFC-1341, предназначен для описания тела почтового сообщения Internet. Предшественником MIME является стандарт почтового сообщения ARPA (RFC822). Стандарт RFC822 был разработан для обмена текстовыми сообщениями. С момента опубликования стандарта возможности аппаратных средств и телекоммуникаций ушли далеко вперед и стало ясно, что многие типы информации, которые широко используются в сети невозможно передать по почте без специальных ухищрений. Так в тело сообщения нельзя включить графику, аудио, видео и другие типы информации. RFC822 не дает возможностей для передачи даже текстовой информации, которую нельзя реализовать в семибитовой кодировке ASCII. Естественно, что при использовании RFC822 не может быть и речи о передаче размеченного текста для отображения его различными стилями. Ограничения RFC822 становятся еще более очевидными, когда речь заходит об обмене сообщениями в разных почтовых системах. Например, для приема/передачи сообщений из/в X.400, который позволяет иметь двоичные данные в теле сообщения, ограничения старого стандарта могут стать фатальными, так как не спасает старый испытанный способ кодировки информации процедурой uuencode, так как эти данные могут быть по-различному проинтерпретированы в X.400 и программе рассылки почты в Internet (mail-agent).
В некотором смысле стандарт MIME ортогонален стандарту RFC822. Если последний подробно описывает в заголовке почтового сообщения текстовое тело письма и механизм его рассылки, то MIME, главным образом, сориентирован на описание в заголовке письма структуры тела почтового сообщения и возможности составления письма из информационных единиц различных типов.
В стандарте зарезервировано несколько способов представления разнородной информации. Для этой цели используются специальные поля заголовка почтового сообщения:
| поле версии MIME, которое используется для идентификации сообщения, подготовленного в новом стандарте; |
| поле описания типа информации в теле сообщения, которое позволяет обеспечить правильную интерпретации данных; |
| поле типа кодировки информации в теле сообщения, указывающее на тип процедуры декодирования; |
| два дополнительных поля, зарезервированных для более детального описания тела сообщения. |
/p>
Стандарт MIME разработан как расширяемая спецификация, в которой подразумевается, что число типов данных будет расти по мере развития форм представления данных. При этом следует учитывать, что анархия типов (безграничное их увеличение) тоже не допустима. Каждый новый тип в обязательном порядке должен быть зарегистрирован в IANA (Internet Assigned Numbers Authority). Остановимся подробнее на форме и назначении полей, определяемых стандартом.
Поле версии MIME (MIME-Version)
Поле версии указывается в заголовке почтового сообщения и позволяет определить программе рассылки почты, что сообщение подготовлено в стандарте MIME. Формат поля выглядит как:
MIME-Version: 1.0
Поле версии указывается в общем заголовке почтового сообщения и относится ко всему сообщению целиком. Здесь уместно отметить, что в отличие от стандарта RFC822, стандарт MIME позволяет перемешивать поля заголовка сообщения с телом сообщения. Поэтому все поля делятся на два класса: общие поля заголовка, которые записываются в начале почтового сообщения и частные поля заголовка, которые относятся только к отдельным частям составного сообщения и записываются перед ними.
Поле типа содержания тела почтового сообщения (Content-Type)
Поле типа используется для описания типа данных, которые содержатся в теле почтового сообщения. Это поле сообщает программе чтения почты какого сорта преобразования необходимы для того, чтобы сообщение правильно проинтерпретировать. Эта же информация используется и программой рассылки при кодировании/декодировании почты. Стандарт MIME определяет семь типов данных, которые можно передавать в теле письма: текст (text); смешанный тип (multipart); почтовое сообщение (message); графический образ (image); аудио информация (audio); фильм или видео (video); приложение (application). Общая форма записи поля выглядит в записи Бекуса-Наура как:
Content-Type:= type "/" subtype *[";" parameter] type := "application" / "audio" / "image" / "message" / "multipart" / "text" / "video" / x-token x-token := <Два символа "X-", за которыми без пробела следует последовательность любых символов> subtype := token parameter:= attribute "=" value attribute:= token value := token / quoted-string token := 1*<любой символ кроме пробела и управляющего символа, или tspecials> tspecials:= "(" /")" / "<" / ">" / "@" ; Обязательно / "," / ";" / ":" / "\" / <"> ; должны быть, / "/" / "[" / "]" / "?" / "." ; заключены в / "=" ; кавычки.
Остановимся подробнее на каждом из типов, разрешенных стандартом MIME.
Text. Этот тип указывает на то, что в теле сообщения содержится текст. Основным подтипом типа "text" является "plain", что обозначает так называемый планарный текст. Понятие планарного текста появилось в связи с тем, что существует еще размеченный текст, т.е. текст со встроенными в него символами управления отображением, и гипертекст, т.е. текст, который можно просматривать не последовательно, а произвольно, следуя гипертекстовым ссылкам. Для обозначения размеченного текста используют подтип "richtext", а для обозначения гипертекста подтип "html". Вообще говоря, "html" - это специальный вид размеченного текста, который используется для представления гипертекстовой информации в системе World Wide Web, которая получила в последнее время широкое распространение в Internet. Понятие размеченного текста требует более подробного обсуждения, так как его передача и интерпретация являются одной из причин появления стандарта MIME.
"Richtext" определяет текст со встроенными в него специальными управляющими последовательностями, которые в соответствии со стандартом языка разметки документов SGML называются тагами. Таги представляют из себя последовательность символов типа "<строка-символов>". "Строка-символов" определяет управляющее действие. Таги делятся на таги начала элемента текста ("<......>") и таги конца элемента текста ("</......>"). В качестве примера такой разметки можно привести следующий фрагмент текста:
<bold>Now</bold> is the time for <italic>all</italic> good men <smaller>(and <lt>women>)</smaller> to <ignoreme></ignoreme> come to the aid of their <nl>
В этом фрагменте <bold> означает выделение "жирным" шрифтом, <italic> - курсив, <smaller> - мелкий шрифт, <lt> - знак "<", игнорирование обозначено как <ignoreme>, новая строка как <nl>.
Специальный тип разметки задается подтипом "html". Это так называемый гипертекст. Разметка гипертекста строится по тому же принципу как и в тексте типа "richtext".
Однако применяются таги, позволяющие описать гипертекстовые ссылки. К таким тагам относятся "<A HREF="......">.....</A>", <IMG ....>, <A NAME="...."></A>. Таг "<A HREF="......"> .......</A> определяет следующий фрагмент текста, который будет просматриваться. При этом текст между тагом начала и тагом конца будет выделен в программе просмотра цветом или другим способом и используется как контекстная гипертекстовая ссылка. Таг <IMG .....> задет встроенный в текст документа графический образ. В некотором смысле этот таг аналогичен "multipart", который разрешает комбинировать сообщение из нескольких фрагментов разного типа. Таг <A NAME...> определяет "якорь", т.е. место внутри документа, на которое можно сослаться как на метку. В качестве примера такой разметки текста можно привести следующий фрагмент:
Это пример разметки документа в формате HTML. <H1>Это заголовок документа</H1> <P> - Это параграф. <A HREF="test.html#mark1"> Это пример гипертекстовой ссылки.</A> <IMG SRC="test.gif" ALIGN=Bottom> Это встроенный image. <A NAME="mark1"></A> Это "якорь" внутри текста документа.
"Multipart". Этот тип содержания тела почтового сообщения определяет смешанный документ. Смешанный документ может состоять из фрагментов данных разного типа. Данный тип имеет ряд подтипов.
Подтип "mixed" - задает сообщение, состоящее из нескольких фрагментов, которые разделены между собой границей, задаваемой в качестве параметра подтипа. Приведем простой пример:
From: Nathaniel Borenstein <nsb@bellcore.com> To: Ned Freed <ned@innosoft.com> Subject: Sample message MIME-Version: 1.0 Content-type: multipart/mixed; boundary="simple boundary"
This is the preamble. It is to be ignored, though it is a handy place for mail composers to include an explanatory note to non-MIME compliant readers. --simple boundary
This is implicitly typed plain ASCII text. It does NOT end with a linebreak. --simple boundary
Content-type: text/plain; charset=us-ascii
This is explicitly typed plain ASCII text. It DOES end with a linebreak. --simple boundary--
This is the epilogue. It is also to be ignored.
В данном примере поле "Content-Type" определяет подтип "mixed" и границу между фрагментами, как строку "--simple boundary--". В начале каждого фрагмента может быть задана своя строка с полем "Content-Type". Как видно из примера, существует два фрагмента, которые не отображаются: преамбула и эпилог, в которые можно поместить комментарии.
Другим подтипом может быть подтип "alternative". Данный подтип позволяет организовать вариабельный просмотр почтового сообщения в зависимости от типа программы просмотра. Приведем пример:
From: Nathaniel Borenstein <nsb@bellcore.com> To: Ned Freed <ned@innosoft.com> Subject: Formatted text mail MIME-Version: 1.0 Content-Type: multipart/alternative; boundary=boundary42 --boundary42
1 фрагмент
Content-Type: text/plain; charset=us-ascii
...plain text version of message goes here.... --boundary42
2 фрагмент
Content-Type: text/richtext
.... richtext version of same message goes here ... --boundary42
3 фрагмент
Content-Type: text/x-whatever
.... fanciest formatted version of same message goes here ... --boundary42--
В этом примере для работы с планарным текстом при использовании алфавитно-цифровых программ просмотра предназначен первый фрагмент текста. Для просмотра размеченного текста используется второй фрагмент, для специальной программы просмотра может быть подготовлен специальный вариант (фрагмент 3).
Подтип "digest" предназначен для многоцелевого почтового сообщения, когда различным частям хотят приписать более детальную информацию, чем просто тип:
From: Moderator-Address MIME-Version: 1. 0 Subject: Internet Digest, volume 42 Content-Type: multipart/digest; boundary="---- next message ----"
------ next message ----
From: someone-else Subject: my opinion
...body goes here ...
------ next message ----
From: someone-else-again Subject: my different opinion
... another body goes here...
------ next message ------
Приведенный пример показывает как можно воспользоваться подтипом "digest" для рассылки почты разным пользователям и по-разному поводу, используя поля "From:" и "Subject"
в качестве частных заголовков.
Подтип "parallel" предназначен для составления такого почтового сообщения, части которого должны отображаться одновременно, что предполагает запуск сразу нескольких программ просмотра. Синтаксис такого сообщения аналогичен рассмотренным выше.
Тип "message". Данный тип предназначен для работы с обычными почтовыми сообщениями, которые однако не могут быть переданы по почте по разного рода причинам. Эти причины объясняются подтипами данного типа.
Подтип "partial" предназначен для передачи одного большого сообщения по частям для последующей автоматической сборки у получателя. Приведем пример передачи аудио сообщения разбитого на части:
X-Weird-Header-1: Foo From: Bill@host.com To: joe@otherhost.com Subject: Audio mail Message-ID: id1@host.com MIME-Version: 1.0 Content-type: message/partial; id="ABC@host.com"; number=1; total=2
X-Weird-Header-1: Bar X-Weird-Header-2: Hello Message-ID: anotherid@foo.com Content-type: audio/basic Content-transfer-encoding: base64
... first half of encoded audio data goes here... and the second half might look something like this:
From: Bill@host.com To: joe@otherhost.com Subject: Audio mail MIME-Version: 1.0 Message-ID: id2@host.com Content-type: message/partial; id="ABC@host.com"; number=2; total=2
... second half of encoded audio data goes here...
Атрибуты подтипа определяют идентификатор сообщения (id), номер порции (number) и общее число порций (total).
Следует обратить внимание на то, что каждая часть имеет свое поле "Content-Type". Это означает, что все сообщение может состоять из частей разных типов.
Другим подтипом является "External-Body",
который позволяет ссылаться на внешние, относительно сообщения, информационные источники. Этот подтип похож на гипертекстовую ссылку из типа "text". Приведем конкретный пример:
From: Whomever Subject: whatever MIME-Version: 1.0 Message-ID: id1@host.com Content-Type: multipart/alternative; boundary=42 --42 Content-Type: message/external-body; name="BodyFormats.ps"; site="thumper.bellcore.com"; access-type=ANON-FTP; directory="pub"; mode="image"; expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)" Content-type: application/postscript --42 Content-Type: message/external-body; name="/u/nsb/writing/rfcs/RFC-XXXX.ps"; site="thumper.bellcore.com"; access-type=AFS expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)" Content-type: application/postscript --42 Content-Type: message/external-body; access-type=mail-server server="listserv@bogus.bitnet"; expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)" Content-type: application/postscript get rfc-xxxx doc --42--
В данном примере приведено использование "External-Body" и "multipart/alternative". Все сообщение разбито на несколько фрагментов. В каждом из фрагментов находится ссылка на внешний файл. Реально тела почтового сообщения нет (границы программами просмотра не отображаются). Однако если программа просмотра способна работать с внешними протоколами, то можно ссылки разрешить автоматически, запуская соответствующий сервис.
Стандартным подтипом типа "message" является "rfc822". Данный подтип определяет сообщения стандарта RFC822.
Типы описания нетекстовой информации. Таких типов имеется четыре:
| "image" для описания графических образов. Наиболее часто используются файлы форматов GIF и JPEG. |
| "audio" для описания аудио информации. Для воспроизведения сообщения данного типа требуется специальное оборудование. |
| "video" для передачи фильмов. Наиболее популярным является формат MPEG. |
| "application" для передачи данных любого другого формата, обычно используется для передачи двоичных данных для последующего промежуточного преобразования. Так если на машине стоит видео-карта с 512Kb памяти, а графика подготовлена в 256 цветах, то сначала ее следует преобразовать и здесь может помочь тип "application". Основной подтип данного типа - "octet-stream", но существуют "ODA" и "Postscript". |
/p>
Назначение данных типов ясно из названия - обозначение данных для последующей обработки как данных в форматах, определяемых подтипом.
Поле типа кодирования почтового сообщения (Content-Transfer-Encoding). Многие данные передаются по почте в их исходном виде. Это могут быть 7bit символы, 8bit символы, 64base символы и т.п. Однако при работе в разнородных почтовых средах необходимо определить механизм их представления в стандартном виде - US-ASCII. Для этого существуют процедуры кодирования такого сорта данных. Наиболее широко применяемая - uuencode. Для того, чтобы при получении данные были бы правильно распакованы и введено в стандарт поле "Сontent-Transfer-Encoding". Синтаксис этого поля следующий:
Content-Transfer-Encoding:= "BASE64" / "QUOTED-PRINTABLE" / "8BIT" / "7BIT" / "BINARY" / x-token
Каждая из альтернатив применяется в своем подходящем случае. Альтернативы "8bit", "7bit", "BINARY" реально никакого преобразования не требуют, так как почта передается байтами и SMTP не делает различия между ними. Однако они введены для строгости описания типов. "BASE64" обычно используется в связке с типом "text/ISO-8859-1", "x-token" позволяет пользователю описать свою процедуру преобразования.
Дополнительные необязательные поля.
Как уже говорилось ранее, стандарт определяет еще два дополнительных поля: "Content-ID" и
"Content-Description". Первое поле определяет уникальный идентификатор содержания, а второе служит для комментария содержания. Ни то, ни другое программами просмотра обычно не отображаются.
В заключении обсуждения стандарта MIME комплексный пример без комментариев:
MIME-Version: 1.0 From: Nathaniel Borenstein <nsb@bellcore.com> Subject: A multipart example Content-Type: multipart/mixed; boundary=unique-boundary-1
This is the preamble area of a multipart message. Mail readers that understand multipart format should ignore this preamble. If you are reading this text, you might want to consider changing to a mail reader that understands how to properly display multipart messages. --unique-boundary-1
...Some text appears here... [Note that the preceding blank line means no header fields were given and this is text, with charset US ASCII. It could have been done with explicit typing as in the next part.]
--unique-boundary-1 Content-type: text/plain; charset=US-ASCII
This could have been part of the previous part, but illustrates explicit versus implicit typing of body parts.
--unique-boundary-1 Content-Type: multipart/parallel; boundary=unique-boundary-2
--unique-boundary-2 Content-Type: audio/basic Content-Transfer-Encoding: base64
... base64-encoded 8000 Hz single-channel u-law-format audio data goes here....
--unique-boundary-2
Content-Type: image/gif Content-Transfer-Encoding: Base64
... base64-encoded image data goes here....
--unique-boundary-2--
--unique-boundary-1 Content-type: text/richtext
This is <bold><italic>richtext.</italic></bold> <nl><nl>Isn't it <bigger><bigger>cool?</bigger></bigger>
--unique-boundary-1 Content-Type: message/rfc822
From: (name in US-ASCII) Subject: (subject in US-ASCII) Content-Type: Text/plain; charset=ISO-8859-1 Content-Transfer-Encoding: Quoted-printable
... Additional text in ISO-8859-1 goes here ...
--unique-boundary-1--
Подводя итоги обсуждения, еще раз следует отметить, что стандарт MIME позволяет расширить область применения электронной почты, обеспечить доступ к другим информационным ресурсам сети в стандартных форматах. <
table border="0" cellpadding="0" cellspacing="0" width="100%">
Протокол FTP (File Transfer Protocol)
FTP (File Transfer Protocol или "Протокол Передачи Файлов") - один из старейших протоколов в Internet и входит в его стандарты. Обмен данными в FTP проходит по TCP-каналу. Построен обмен по технологии "клиент-сервер". На рисунке изображена модель протокола.
Модель протокола
В FTP соединение инициируется интерпретатором протокола пользователя. Управление обменом осуществляется по каналу управления в стандарте протокола TELNET. Команды FTP генерируются интерпретатором протокола пользователя и передаются на сервер. Ответы сервера отправляются пользователю также по каналу управления. В общем случае пользователь имеет возможность установить контакт с интерпретатором протокола сервера и отличными от интерпретатора пользователя средствами.
Команды FTP определяют параметры канала передачи данных и самого процесса передачи. Они также определяют и характер работы с удаленной и локальной файловыми системами.
Сессия управления инициализирует канал передачи данных. При организации канала передачи данных последовательность действий другая, отличная от организации канала управления. В этом случае сервер инициирует обмен данными в соответствии с параметрами, согласованными в сессии управления.
Канал данных устанавливается для того же host'а, что и канал управления, через который ведется настройка канала данных. Канал данных может быть использован как для приема, так и для передачи данных.
Возможна ситуация, когда данные могут передаваться на третью машину. В этом случае пользователь организует канал управления с двумя серверами и организует прямой канал данных между ними. Команды управления идут через пользователя, а данные напрямую между серверами.
Канал управления должен быть открыт при передаче данных между машинами. В случае его закрытия передача данных прекращается.
Соединение с двумя разными серверами и передача данных между ними <
H323_RUS