драйвер способен использовать новую возможность
Начиная с версии 6 5 Gemini ODBC- драйвер способен использовать новую возможность InterBase версии 6.5 - асинхронную отмену выполняющихся на сервере запросов.
Автоматические транзакции
Для разрешения провайдеру самостоятельно управлять транзакциями нужно указать в строке инициализации параметр "auto_commit=true":
Call сn.Open(
"data source=localhost:d:\database\employee.gdb;auto_commit=true",
"gamer", "vermut")
В этом случае все создаваемые объекты сессий для данного источника данных будут способны самостоятельно запускаться и завершать транзакции без явного участия пользователя. Для выборочного разрешения такого режима можно воспользоваться свойством сессии "Session AutoCommit". Если это свойство равно true, то сессия может обслуживать запросы к базе данных без необходимости явного запуска и подтверждения.
По умолчанию автоматические транзакции используют уровень изоляции SNAPSHOT. Если требуется установить другой уровень изоляции, то нужно либо установить параметр инициализации источника данных "auto_commit_level", либо изменить свойство сессии "Autocommit Isolation Levels" в одно из следующих значений:
0 х 1000 - READ COMMITED;
0 x 10000 - REPEAT ABLE READ. Это режим по умолчанию;
0 x 100000 - SERIALIZABLE.
О принципе функционирования автоматических транзакций следует сказать следующее. Автоматическая транзакция не управляется через интерфейс сессии. За её завершение и откат отвечает команда или набор строк внутри этой сессии. Если команда не возвращает набор строк (rowset), то транзакция фиксируется сразу. Если внутри автоматической транзакции появляется набор строк, то транзакция завершается при освобождении этого набора То есть внутри одной сессии. у которой свойство "Session AutoCommit" равно true, может существовать несколько активных транзакций. Естественно, что в этом случае пользователь также может явно управлять запуском и завершением транзакции, принадлежащей сессии. В случае явного запуска транзакции, для дальнейших запросов и операций в рамках этой сессии будет использоваться контекст именно этой транзакции.
Несмотря на то, что ffiProvider старается выполнить как можно больше операций в рамках одной автоматической транзакции, все равно производительность приложения, не осуществляющего самостоятельного контроля над транзакциями, не может сравниться с приложениями, явно управляющими транзакциями.
Библиотека классов C++ для работы с OLE DB
Созданная как дополнительный слой ("обертка") над СОМ-объектами, эта библиотека классов обеспечивает более тесную интеграцию с OLE DB-провайдерами. В ней нет всего списка возможностей, который предлагает ADODB, но предоставляемый сервис делает ее более приспособленной для построения независимых и эффективных компонентов, работающих с базами данных через OLE DB.
К основным достоинствам данной библиотеки классов относится:
автоматическое создание и разрушение объектов;
изоляция классов для работы с базами данных друг от друга, что обеспечивает исключительную модульность и гибкость приложений на основе данной библиотеки;
возможность подключения объекта C++ к уже существующему OLE DB компоненту;
удобная работа с наборами полей и параметров, значительно более гибкая по сравнению с компонентами ADODB и VCL;
возможность выбора способа обработки ошибок - через исключения или через код возврата.
Поскольку данная библиотека доступа создавалась специально для использования в больших проектах, её классы значительно уменьшают сложность взаимодействия с OLE DB-провайдером В случае необходимости использовать ADODB (например, для совместной работы модулей проекта, написанных на C++ и на VBScript, в рамках одной транзакции) в библиотеке реализованы механизмы "шлюзования".
Разумеется, существуют еще несколько других библиотек, упрощающих работу с OLE DB-провайдерами. Однако в нижеследующих примерах будут использоваться только компоненты ADODB и библиотека классов C++ для работы с OLE DB. Поэтому, прежде чем приступить к работе над описанными примерами, убедитесь в наличии всех необходимых программных продуктов. Помните, что вы можете скачать все примеры и нужные для их работы программы на сайте поддержки данной книги www.InterBase-world com.
Чтение метаданных
Помимо управления транзакциями, сессия предоставляет еще одну полезную возможность - получение метаданных для базы данных (о метаданных см. главу "Структура базы данных InterBase" (ч. 4)). Поскольку в некоторых системах, например в Microsoft Distributed Query, операция получения метаданных выполняется очень часто, то IBProvider хранит информацию о них в оперативной памяти (т. е. кеширует). Кэширование метаданных можно настраивать для обеспечения оптимального быстродействия. Определить режим кеширования можно через свойство инициализации источника данных "schema_cache" и свойство сессии - "Session Schema Cache". Этим свойствам можно присваивать следующие значения:
Кэширование запрещено. Данные будут всегда перечитываться.
Глобальное кеширование на уровне Data Source. Это режим по умолчанию.
Кеширование на уровне Session.
Если при запросе метаданных сессия содержит явно запущенную транзакцию, то провайдер не будет использовать дополнительную внутреннюю транзакцию для получения данных, а воспользуется уже существующей. Если явно запущенной транзакции нет, то IBProvider автоматически запустит внутреннюю транзакцию с уровнем изоляции, указанной в свойстве сессии "Autocommit Isolation Levels". Для запрещения автоматического запуска провайдером внутренних транзакций для извлечения метаданные необходимо определить в строке инициализации источника данных "inner_trans=false" или установить свойство сессии "Session InnerTrans=false".
Получение и вывод списка таблиц базы данных:
ADODB
Dim cn As New ADODB.Connection
Call cn.Open("file name=d:\database\employee.ibp")
Dim rs As ADODB.Recordset
Set rs = cn.OpenSchema(adSchemaTables)
Cells.Clear
Dim col As Long, row As Long
row = 1
'печать названия колоник
For col = 0 To rs.Fields.Count - 1
Cells(row, col + 1) = rs(col).Name
Next col
'печать содержимого
While Not rs.EOF
row = row + 1
For col = 0 To rs.Fields.Count - 1
Cellsfrow, col + 1) = rs(col).Value
Next col
rs.MoveNext
Wend
Здесь следует обратить внимание на одну особенность. Спецификация OLE DB для некоторых полей таблиц метаданных определяет типы, несовместимые с VARIANT, например UI8. Поэтому при попытке получения значения из этих полей через ADODB может возникнуть ошибка;
C++
try
{
t_db_data_source сn;
_THROW_OLEDB_FAILED(cn,attach("file
name=d:\\database\\employee.ibp"));
t_db_session session;
_THROW_OLEDB_FAILED(session,create(сn));
//библиотека напрямую не поддерживает
//работу с интерфейсом получения
//наборов информационной схемы,
//поэтому напишем необходимый код "в лоб".
IDBSchemaRowsetPtr spSR(session.session_obj());
if(!spSR)
t_ole_error::throw_error(
"query interface [IDBSchemaRowset]",spSR.m_hr);
IUnknownPtr spUnk;
HRESULT hr=spSR->GetRowset(NULL,DBSCHEMA_TABLES,0,NULL,
IID_IUnknown,0,NULL,&spUnk.ref_ptr());
if(FAILED(hr))
t_ole_error::throw_disp_error(hr,"get tables list");
//подключаем полученный набор к курсору
t_db_cursor cursor;
_THROW_OLEDB_FAILED(cursor,attach(spUnk))
//получаем описание полей результирующего
//множества (набора данных)
t_db_row row;
_THROW_OLEDB_FAILED(cursor,describe(row))
//печатаем содержимое набора
while(cursor.fetch(row)==S_OK)
{
for(t_db_row::size_type i=0;i!=row.count;++i)
cout<<row.columns(i).name<<":"<<row[i].as_string<<endl ;
cout<<endl;
}//while
//проверяем причину выхода из цикла
_THROW_OLEDB_FAILED(cursor,m_last_result)
}
catch(const exception& exc){
cout<<"error:"<<exc.what()<<endl;
}
Communication Diagnostics
Прежде чем приниматься писать приложение базы данных на Java, необходимо проверить, а доступна ли нужная база данных. Для проверки возможности соединения с базами данных InterBase через InterClient служит Java-апплет Communication Diagnostics, входящий в состав поставки InterClient. Чтобы его запустить, можно либо открыть файл CommDiag.html, после чего в отдельном окне запустится этот апплет (естественно, ваш браузер должен поддерживать JAVA-апплеты), либо запустить его в командной строке следующим образом: Java InterBase.interclient.utils.CommDiag
При этом появится окно диалога для проверки соединения с базой данных.
Если у вас в настройках Windows стоят региональные установки (Панель управления\Язык и стандарты, закладка Общие\Язык(Местоположение)) для России - "Русский", то скорее всего вместо нормальных русских букв вы увидите непонятные символы, свидетельствующие о неправильной кодировке файлов ресурсов для русского языка.
Бороться с некорректным представлением сообщений InterClient на русском языке можно двумя способами: либо установить в качестве значения для "Язык(Местоположение)" язык "Английский" и получить таким образом окно диагностики на английском языке, либо скачать исправленную версию JDBC-драйвера InterBase interclient.jar с корректной поддержкой русского языка. Его можно скачать с сайта http://people.comita.spb.ru/users/sergeya/Java/interclient.jar или с сайта поддержки этой книги www.InterBase-world.com.
Здесь приводится английский вариант окна диагностики, которое изображено на рисунке 3.5:
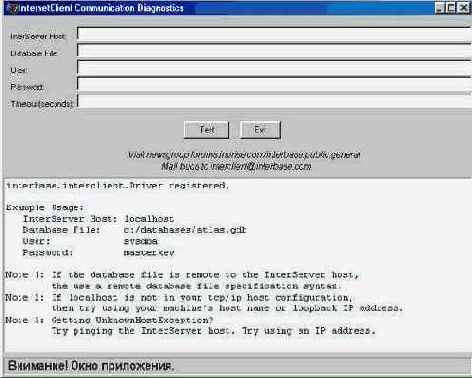
Рис 3.5. Окно диагностики соединения через InterClient
Как видно из рисунка, для того, чтобы проверить соединение с базой данных через InterClient, необходимо заполнить поля "InterServer Host", "Database File", а также "User" и "Password". Если вы работаете по локальной сети (или вообще на собственной локальной машине), то поле "Timeout" можно не задавать.
Допустим, у нас есть база данных test.gdb под управлением InterBase на компьютере-сервере server_nt, к которой мы хотим подключиться через InterClient. Если обычная строка соединения к базе выглядит так:
server_nt:С:\Database\test.gdb
то необходимо ввести в поле "InterServerHost" значение "server_nt", а в поле Database File - "C:/Database/test.gdb". Обратите внимание, что в качестве разделителя каталогов используется прямая косая черта. Вообще говоря, InterClient позволяет использовать для разделения каталогов в строке соединения и привычную Windows-пользователям обратную косую черту, однако лучше использовать прямую, чтобы не было необходимости квотировать обратную косую черту в программе на Java.
Нажимаем кнопку Test и видим результаты подсоединения к базе данных. Помните, что программа-транслятор InterServer обязательно должна функционировать на том же компьютере, где работает InterBase. Поэтому "InterServer Host" совпадает с именем сервера, на котором работает InterBase. Допускается, но не рекомендуется указывать в поле "InterServer Host" IP-адрес компьютера- сервера.
Итак, если соединение прошло успешно, то увидите успешное подтверждение соединения в окне диагностики. Пример сведений, выдаваемых в окне диагностики для базы данных на локальном компьютере со строкой соединения localhost:C:\Database\test.gdb, приведен ниже:
InterClient Release: 2.0.1 Test Build,
Client/Server Edition
InterClient compatible JRE versions: 1.3
InterClient compatible IB versions: 5, 6
InterClient driver name:
InterBase.interclient.Driver
InterClient JDBC protocol: jdbc:InterBase:
InterClient JDBC protocol version: 20001
InterClient expiration date: no expiration date
Testing database URL
jdbc:InterBase://localhost/C:/Database/test.gdb.
Connection established to
jdbc:InterBase://localhost/C:/Database/test.gdb
Database product name: InterBase
Database product version: WI-T6.2.773 Firebird 1.0
Database ODS version: 10.0
Database Page Size: 8,192 bytes
Database Page Allocation: 134 pages
Database Size: 1,072 Kbytes
Database SQL Dialect: 3
Middleware JDBC/Net server name: InterServer
Middleware JDBC/Net server version: 2.0.1 Test Build
Middleware JDBC/Net server protocol version: 20001
Middleware JDBC/Net server expiration date: no expiration date
Middleware JDBC/Net server port: 3060
Test connection closed.
***** N0 installation problems detected! *****
Помимо разнообразных сведений, в окне диагностики выводится строка JDBC- соединения, которая была использована для проверки связи с базой данных:
jdbc:InterBase://localhost/C:/Database/test.gdb
Это очень удобный способ формировать синтаксически правильные строки JDBC-соединения. Давайте сохраним эту строку для будущего использования в нашей программе.
Инсталляция ADODB-компонентов
Компоненты ADO входят в состав свободно распространяемого дистрибутива Microsoft Data Access Components и доступны для скачивания на сайте компании Microsoft - www microsoft com/data. Для написания примеров использовались ADODB-компоненты из дистрибутива версии 2.6.
Инсталляция IBProvider
Перед установкой OLE DB-провайдера убедитесь, что на вашей машине инсталлирована клиентская часть InterBase Для этого на компьютере как минимум, должна находиться GDS32.DLL. Обычно она находится в системном каталоге Windows (System - для 95/98/МЕ, System32 - для NT4/Win2000) Подробнее обустановке клиентской части InterBase см. главу "Установка InterBase - взгляд изнутри" (ч. 4)
В минимальный набор дистрибутива IBProvider входят два модуля: _IBProvider.dll и cw3250mt.dll. Скопируйте оба файла в системный каталог Windows и выполните команду regsvr32 _B3Provider.dll для регистрации провайдера в системе.
Если вы обладаете готовым дистрибутивом IBProvider, то программа инсталляции выполнит все необходимые операции самостоятельно.
Обратите внимание, что при инсталляции провайдера в Windows NT4/Windows 2000 у вас должны быть права на запись в реестр Поэтому операцию регистрации лучше всего выполнять, обладая правами администратора.
После установки провайдера перезагрузка ОС не требуется
Использование библиотеки классов
Библиотека классов поставляется в виде исходных текстов. Поэтому для ее использования нужно выполнять следующие требования:
Явно добавить в проект файлы из каталога Lib:
ole_lib\oledb\oledb_client_lib.cpp Основные классы для работы с OLE DB
ole_lib\oledb\oledb_client_base.cpp
ole_lib\oledb\oledb_common.cpp
ole_lib\oledb\oledb_variant.cpp
ole_lib\oledb\oledb_ado_lib.cpp Утилиты стыковки с ADODB
ole_lib\ole_base.cpp
ole_lib\ole_auto.cpp
Win32Lib\win321ib.cpp
structure\util_classes.cpp
util_func.cpp
Начало каждого срр-файла, включенного в проект, должно выглядеть следующим образом:
ttinclude <_pch_.h> #pragma hdrstop
Добавить в параметры проекта (опция Conditional defines) макрос INCLUDE_OLEDB_HEADER.
При использовании в проекте VCL компонент, нужно добавить в параметры проекта макрос _USE_VCL_. В этом случае файл <vcl.h> будет добавлен в проектный csm-файл (файл прекомпилированного заголовка) косвенно из <_pch_ h>.
Основной каталог include, используемый компилятором C++ Builder, должен содержать заголовочные файлы OLE DB SDK. BCB5 и Free Borland C++ Compiler уже содержат все необходимое. В ВСВЗ нужно добавить эти файлы самостоятельно, используя OLE DB SDK версии не выше 2.1.
Представленная в составе дистрибутива IBProvider библиотека классов является основой для проектов, её использующих. Поэтому предполагается, чго заголовочный файл <_pch_.h> прямо или косвенно включен в каждый срр-файл проекта. Возможность параллельного использования с другими библиотеками осуществляется за счет определения пространств имен. Поддержка библиотеки VCL добавлена изначально. Для поддержки других библиотек потребуется модифицировать <_pch_.h>.
Перенос на другие компиляторы C++ полностью зависит от степени их совместимости с последним стандартом C++ и от сложности перехода на другую реализацию STL.
Использование IBProvider в клиентских приложениях
Низкоуровневые прикладные интерфейсы для работы с СУБД (API) обычно не используются в клиентских приложениях из-за большого объема кода, необходимого для подготовки и выполнения SQL-запросов. Это относится и к OLE DB-интерфейсам. Поэтому примеры, демонстрирующие взаимодействие с различными OLE DB-провайдерами непосредственно через их СОМ-интерфейсы, носят исключительно демонстрационный характер и имеют мало общего с реальным программированием приложений баз данных Для решения повседневных задач обычно используют надстройки в виде других СОМ-объектов или библиотек классов, которые существенно упрощают работу с OLE DB. Работать с IBProvider можно двумя основными способами - через стандартные ADODB компоненты и с помощью собственной библиотеки классов для поддержки IBProvider. написанной для компилятора Borland C++ Builder.
Использование нескольких сессий в ADODB
Несмотря на то что модель объектов ADODB не предоставляет прямой возможности одновременного использования нескольких сессий с одним источником данных, это ограничение можно обойти. Решение основывается на применение внутреннего интерфейса ADOConnectionConstruction компоненты ADODB.Connection.
void clone_adodb_connection(IDispatch* pCurrentConnection,
IDispatchPtr& spNewConnection)//throw
{
//объявляем типы смарт-указателей для интерфейсов
//конструирования ADODB-подключения
DECLARE_IPTR_TYPE(ADOConnectionConstruction);
DECLARE_IPTR_TYPE(ADOConnectionConstructionl5);
//1 получаем источник данных, привязанный к pCurrentConnection
ADOConnectionConstructionPtr
spConstruct(pCurrentConnection);
ADOConnectionConstruetionl5Ptr
spConstructlS(pCurrentConnection);
if(!spConstruct && !spConstruct15)
t_ole_error::throw_error("Объект - не ADODB.Connection",
E_INVALIDARG);
IUnknownPtr spDataSource;
//берем указатель на OLE DB-источник данных
if((bool)spConstruct15)
spConstruct15->get_DSO(&spDataSource.ref_ptr());
if(!spDataSource && (bool)spConstruct)
spConstruct->get_DSO(&spDataSource.ref_ptr());
if(!spDataSource)
t_ole_error::throw_error(
"ADODB.Connection не инициализирован",E_FAIL);
//2 создаем новую сессию для spDataSource ------------------
IUnknownPtr spNewSession;
IDBCreateSessionPtr spDBCreateSession(spDataSource);
assert((bool) spDBCreateSession);
if(FAILED(spDBCreateSession->CreateSession
(NULL,IID_IUnknown,kspNewSession.ref_ptr())))
{
t_ole_error::throw_error(
"Ошибка создания новой сессии",E_FAIL);
}
assert((bool)spNewSession);
//3 создаем новый экземпляр ADODB.Connection ----------------
IUnknownPtr spUnkNewConnection;
HRESULT hr=SafeCreateInstance("ADODB.Connection",
NULL,CLSCTX_INPROC,IID_IUnknown,
(void**)&spUnkNewConnection.ref_ptr());
if(FAILED(hr))
t_ole_error::throw_error(
"Ошибка создания \"ADODB.Connection\"",hr);
spConstruet = spUnkNewConnection;
spConstruct15=spUnkNewConnection;
if(!spConstructlS && !spConstruct)
throw t_ole_error(
"Ошибка подключения к \"ADODB.Connection\"",E_FAIL);
spDataSource->AddRef(); // ADO не вызывает для них AddRef spNewSession->AddRef();
//при конструировании ADODB.Connection
//пытается установить свои свойства,
//в результате чего, если IBProvider уже подключен
//к базе данных, может произойти ошибка
//тем не менее подключение уже сконструировано
//и вполне работоспособно.
if((bool)spConstructlS) //IID_Connect-on15
{
spConstruct15->WrapDSOandSession(spDataSource,spNewSession);
hr = spUnkNewConnection ->
Querylnterface(IID_ConnectionlS,spNewConnection);
}
else //IID_Connection
{
spConstruct->WrapDSOandSession(spDataSource,spNewSession);
hr = spUnkNewConnection ->
Querylnterface(IID_Connection,spNewConnection);
}
if (FAILED(hr))
t_ole_error::throw_error(
"Ошибка получения IDispatch из ADODB.Connection",hr);
assert((bool)spNewConnection);
//всё — spNewConnection подключен к тому же
//источнику данных, но обладает
//собственной сессией.
}//cione_adodb_connection
Использование пула подключений к базе данных
Для многопользовательских серверных приложений, обрабатывающих клиентские запросы с помощью запросов к отдельной базе данных, повторное употребление ресурсов SQL-сервера является одним из основных способов увеличения производительности. Поэтому пул подключений, кеширующий инициализированные источники данных, является важной составляющей такого рода программного обеспечения. Кроме того, важно понимать, что механизм пула подключений не реализуется самим OLE DB-провайдером. От последнего требуется только корректно обрабатывать уведомления о помещении в пул и обеспечивать многопоточный доступ к компонентам. IBProvider реализует оба требования, поэтому клиенту предлагается только провести корректную инициализацию источника данных.
Для включения пула подключений при работе через ADODB нужно указать в строке подключения параметры
"OLE DB Services=-l;free_threading=true"
Параметр "OLE DB Services=-l" указывает ADODB на необходимость использования пула подключений. Параметр "free_threading=true" устанавливает внутренний флаг, объявляющий поддержку многопоточного доступа.
Для демонстрации работы пула ниже приведен простой пример, выполняющий в цикле инициализацию и закрытие источника данных. Для запрещения пула подключений присвойте "OLE DB Services" нулевое значение. Замеры производительности проводятся очень грубо - в секундах, но этого оказалось достаточно, чтобы увидеть преимущества пула подключений. По истечении 60 с с момента добавления в пул неиспользуемые источники данных освобождаются и производиться отключение от сервера базы данных.
Для того чтобы подробно изучить процесс функционирования пула подключений, следует воспользоваться информацией на сайте компании Microsoft или посмотреть в документацию по OLE DB SDK (см. "Resource Pooling").
ADODB:
Dim en As New ADODB.Connection
Dim cnt As Long
Dim start As Date, total As Date
total = Time
For cnt = 1 To 10
start = Time
cn.Provider = "LCPI.IBProvider.1"
cn.Properties("OLE DB Services") = -1
cn.Properties("free_threading") = True
cn.Open "data source=localhost:d:\database\employee.gdb;", _
"gamer", "vermut"
Dim cmd As New ADODB.Command
cmd.ActiveConnection = cn
cmd.CommandText = "select count(*) from job"
cn.BeginTrans
cmd.Execute
cn.CommitTrans
cn.Close
Debug.Print ">" & CStr(CDate(Time - start))
' можно сделать задержку чуть больше 60 с,
'чтобы понаблюдать за освобождением
'инициализированного источника данных и
'потерю подключения к базе данных
'Application.Wait Time + CDate("О:1:05")
'Debug.Print "disconnect"
'Application.Wait Time + CDate("0:0:15")
Next cnt
Debug.Print "total:" & CStr(CDate(Time - total))
'освобождение последнего объекта, использующего
'пул подключений, приводит к уничтожению всех
' инициализированных источников данных
Set cn = Nothing
Использование скриптов в клиентских приложениях базы данных InterBase
Время от времени у любого программиста появляется желание вынести часть логики своих приложений на уровень, который можно было бы изменять без перекомпиляции приложения. А для определенного класса задач это требование изначально является первоочередным. Как правило, когда речь заходит о добавлении такой возможности, сразу вспоминают серверы приложений. Однако существуют задачи, для которых то же самое эффективнее реализовывать на уровне отдельного клиента.
Использование такого рода "программ" разгружает основной код приложения от алгоритмов, сильно подверженных переменчивым желаниям пользователей. Например:
Проверка достоверности данных при сохранении.
Контроль прав на чтение и изменение данных.
Правила движения документов.
Настраиваемый пользовательский интерфейс.
Печать выходных форм.
Встроенные отчеты.
При этом не существует больших проблем с выполнением сценариев, поскольку реализовано и доступно достаточно много компонентов для быстрого решения этой задачи. В том числе и бесплатный ActiveX-компонент ScriptControl от Microsoft.
Основные трудности при реализации такого подхода приходятся на осуществление тесной интеграции основного кода приложения и кода сценария. В числе важных вопросов находится и обеспечение доступа сценария к базе данных.
Самым тривиальным решением было бы создание внутри сценария собственного подключения к база данных. Но, как уже было замечено ранее, это медленно и неэффективно. Другим решением является передача готового подключения из основного кода приложения. И вот здесь применение ADODB- и OLEDB- компонентов доступа дает максимальный эффект.
Компоненты ADODB изначально приспособлены для использования в ActiveX-сценариях. Впрочем, для передачи в сценарий соединения с базой данных ADODB.Connection с выделенной сессией могут потребоваться некоторые усилия. Решение этой задачи было приведено в разделе описания сессии.
Компоненты OLEDB нельзя непосредственно использовать в сценариях. Но их можно "обернуть" в ADODB-компоненты и таким образом использовать в коде сценария. Подробности можно посмотреть в примерах, входящих в дистрибутив IBProvider.
Естественно, что для сложных задач проблема связи сценариев с базами данных не является основной. Тем не менее стоимость программного решения может резко возрасти, если приложение будет базироваться на компонентах доступа, которые нельзя ни напрямую, ни через какой-либо адаптер использовать в сценариях.
Источник данных
Создание компонента Data Source является отправной точкой для работы с базой данных через IBProvider. Существует несколько сценариев создания и инициализации компонента доступа. Они отличаются объемом работы, выполняемой в клиентском приложении, библиотекой доступа к OLE DB и самим IBProvider.
Вариант 1. Клиент самостоятельно осуществляет все этапы:
ADODB
Dim en As New ADODB.Connection
cn.Provider = "LCPI.IBProvider.1"
cn.Properties("data source") =
"localhost:d:\database\employee.gdb"
en.Properties("user id") = "gamer"
en.Properties("password") = "vermut"
cn.Open
C++
t_db_data_source cn;
_THROW_OLEDB_FAILED(cn,create("LCPI.IBProvider.1"))
t_db_ob]_props cn_props(/*refresh=*/false);
_THROW_OLEDB_FAILED(cn_props,attach_data_source(en.m_obj, DBPROPSET_DBINITALL))
_THROW_OLEDB_FAILED(cn_props,set("data source" "iocalhost:d:\\database\\employee. gdo")) ;
_THROW_OLEDB_FAILED(cn_props,set("user id","gamer"));
_THROW_OLEDB_FAILED(cn_props,set("password","vermut"));
_THROW_OLEDB_FAILED(en,attach(""));
Вариант 2. Создание и инициализацию выполняет клиентская библиотека:
ADODB
Dim en As New ADODB.Connection
Call en.Open("provider=LCPI.IBProvider.1; data
source=Iocalhost:d:\database\employee.gdb", "gamer", "vermut")
C++
t_db_data_source cn;
_THROW_OLEDB_FAILED(en,attach("provider=LCPI.IBProvider.1;"
"data source=localhost:d:\\database\\employee.gdb;"
"user id=gamer;password=vermut"));
Вариант 3. Провайдер создает клиентская библиотека, инициализацию выполняет сам провайдер:
ADODB
Dim en As New ADODB.Connection
Call en.Open("file name=d:\database\employee.ibp")
C++
t_do_data_source cn;
_THROW_OLEDB_FAILED(cn,
attach!"file name=d:\\database\\employee.ibp"));
//или явно указываем провайдер и файл с параметрами
_THROW_OLEDB_FAILED(en,
attach("provider=LCPI.IBProvider.1;"
"file name=d:\\database\\employee.ibp"));
где "employee.ibp" - обычный текстовый файл, в котором хранится строка подключения вида
data souгсе=Iocalhost:d:\\database\\employee.gdb;
user id=gamer;
password=vermut
Пока OLE DB-провайдер не подключен к базе данных, параметры инициализации будут единственно доступным набором свойств. В IBProvider определены стандартные свойства инициализации и собственные, предназначенные для специанализированной настройки дальнейшей работы с базой данных. (За подробностями обращайтесь к документации по IBProvider.)
После успешного подключения к базе данных становятся доступными свойства информационного набора, с помощью которых компонент источника данных предоставляет сведения о сервере базы данных. Часть этих свойств стандартизовано спецификацией OLE DB. Остальные свойства предоставляют информацию, специфичную для IBProvider, содержащую расширенные сведения о сервере и базе данных.
Пример получения значений информационных свойств:
ADODB
'подключение к базе данных
....
'стандартные свойства
Debug.Print en.Properties("provider version")
Debug.Print en.Properties("provider friendly name")
'специфические свойства
Debug.Print en.Properties("IB Base Level")
Debug.Print en.Properties("IB GDS32 Version")
Debug.Print en Properties("IB Version")
C++
//Подключение к базе данных
//...
t_db_obj_props cn_props(false);
_THROW_OLEDB_FAILED(cn_props,
attach_data_source(cn.m_obi, DBPROPSET_DATASOURCEINFOALL));
..печать всех информационных свойств
for(UINT i = 0; i! =cn_props .GetltemsInContainer () ;+ + i)
{
cout<<cn_props[i].name()<<":"<<print(cn_props[i].value())<<endl
;
}
Компонент Data Source имеет еще несколько возможностей: например, сохранение параметров подключения к базе данных в файле и перечисление до- пус!имы\ символов для названий объектов базы данных. Однако в основном он используется для создания объектов сессий.
Команда
Команда используется для выполнения SQL-запросов к базе данных Важно не путать команду, которая является СОМ-объектом, с текстом команды, который представляет собой строку. Обычно команды используют для описания данных, например для создания таблицы и предоставления привилегий, и манипуляции данными, например для обновления и удаления строк Особый случай манитчя- ции данными - создание набора строк (примером служит оператор SQL SELECT).
Спецификация OLE DB определяет гибкий набор интерфейсов для выполнения и обработки результатов SQL-запросов. Определяется так последовательность шагов:
Создание команды.
Установка текста запроса.
Подготовка запроса.
Подготовка параметров запроса.
Установка свойств результирующего множества (набора данных).
Выполнение запроса.
Компоненты ADODB
В настоящее время этот набор компонентов стал промышленным стандартом взаимодействия с OLE DB-провайдерами. ADODB (www.microsoft.com/data) - это весьма удобный высокоуровневый интерфейс, реализующий классическую иерархию объектов для работы с базами данных в виде СОМ-объектов, поддерживающих технолог ию OLE Automation.
Реализация OLE DB-интерфейсов большинства провайдеров не является взаимозаменяемой и больше ориентирована на использование из программ, написанных на C++, что приводит к проблемам совместимости и переносимости приложений между различными OLE DB-провайдерами. Поэтому ADODB-компонеты, сглаживающие различия между разными OLE DB-провайдерами и доступные для использования практически везде - начиная от VisualBasic и заканчивая тем же C++, - лучше подходят для использования в качестве универсальной платформонезависимой основы для приложений баз данных.
Но у ADODB-компонентов имеется ряд недостатков, которые являются обратной стороной достоинств:
Ограничения на типы данных, накладываемые структурой VARIANT.
Некоторое снижение производительности за счет того, что создание объектов ADODB производится через инфраструктуру СОМ.
Отсутствие встроенной поддержки использования нескольких независимых транзакций в рамках одного подключения, чем InterBase выгодно отличается от других SQL-серверов базы данных.
Появляется дополнительный уровень взаимодействия с OLE DB.
Для того, чтобы избежать недостатков ADODB-компонентов, была разработана специализированная библиотека классов C++, которая реализует доступ к OLE DB провайдерам (в том числе и к IBProvider) с максимально возможной эффективностью. Эта библиотека поставляется в составе дистрибутива IBProvider.
Набор строк
Наборы строк - это центральные объекты, которые позволяют всем компонентам доступа к данным OLE DB представлять свои данные в табличной форме. Фактически набор строк - это совокупность строк, состоящих из полей данных. Компоненты доступа к базовым таблицам предоставляют свои данные в форме набор строк. Процессоры запросов (команда) представляют в форме набора строк результаты SQL-запросов. Это позволяет создавать слои объектов, поставляющих и потребляющих данные посредством одного и того же объекта.
СУБД InterBase поддерживает только однонаправленное движение курсора по набору строк, возвращаемому SQL-запросами. Под курсором здесь и далее будет подразумеваться текущая позиция в наборе строк. Этого вполне достаточно для очень широкого круга задач. Положительной стороной однонаправленного обхода наборов строк в InterBase является возможность загрузки приложением большого объема данных без хранения в памяти уже обработанной информации. IBProvider по умолчанию обеспечивает именно такой способ "навигации" по множеству строк.
Хотя понятие курсора и присутствует в OLE DB, его основное назначение заключается в получении идентификаторов строк (HROW), а не самих данных полей строки. С помощью этих идентификаторов клиент может получать интересующие его данные в конкретной строке результирующего набора данных. То есть получив идентификатор строки, пользователь может выполнять многократное чтение полей одной и той же строки. Например, при первом чтении определяется размер данных BLOB-поля, а при втором осуществляется загрузка его содержимого.
Клиент обязан освободить идентификатор строки, когда последний ему уже не нужен. Но может это и не сделать, имитируя с помощью массива идентификаторов строк произвольный доступ к результирующему множеству SQL- запроса. При использовании ADODB этого можно добиться с помощью свойства ADODB.Recordset.CacheSize. В этом случае провайдер начнет осуществлять кеширование данных заблокированных рядов.
Помимо последовательного обхода всех строк множества, IBProvider поддерживает пропуск рядов и возможность возвращения курсора на начало множества за счет повторного выполнения запроса.
Пример создания набора строк, способа пропуска строк и возвращения курсора на начало набора:
ADODB
cmd.CommandText = "select * from job where job_code=:job_code"
cmd(";job_code") = "Eng"
Set rs = cmd.Execute
'последовательный обход всех строк множества
While Not rs.EOF
rs.MoveNext
Wend
rs.MoveFirst 'Restart
rs.Move 1 'пропускаем первый ряд
'...
rs.MoveFirst 'Restart
rs.Kove 2 'пропускаем первые два ряда
'...
Произвольный доступ к результирующему множеству SQL-запросов IBProvider имитирует за счет кеширования выбранных данных на стороне клиента. Для работы в этом режиме провайдер использует более совершенный компонент управления множеством, реализующий возможности обратной выборки и произвольного перемещения по набору данных, а также возможность "приблизительного" позиционирования. И кроме того, в режиме произвольного доступа набор строк предоставляет закладки строк, с помощью которых клиент может быстро возвращаться к некоторой строке. В некотором смысле закладки строк эквивалентны идентификатору строки (HROW), но гораздо более эффективны и не требуют никаких ресурсов для хранения. Кроме того, при работе через ADODB значение закладки текущей строки можно получить и сохранить для дальнейшего использования (см. ADODB.Recordset.Bookmark), а идентификатор строки - нет.
Ниже приведен пример создания набора строк, поддерживающего произвольный доступ, "программируя" его характеристики напрямую через свойства команды.
Пример позиционирования курсора набора рядов в случайном порядке.
ADODB
Dim cmd As New ADODB.Command
Dim rs As ADODB.Recordset
cmd.ActiveConnection = cn
cmd.CommandText = "select * from job where job_code=:job_code"
cmd("job_code") = "Eng"
'включаем поддержку закладок
cmd.Properties("Use Bookmarks") = True
Set rs = cmd.Execute
Dim i As Long
For i = 0 To rs.RecordCount
'нумерация с единицы
rs.AbsolutePosition = CLng(Rnd * rs.RecordCount) + 1
'...
Next i
В общем, клиент независимо от режима доступа может заставить провайдер хранить данные выбранных строк. В первом случае это будет осуществлено за счет явного участия пользователя и провайдера, во втором случае - провайдер будет осуществлять это самостоятельно.
Поэтому набор строк OLE DB-провайдера для InterBase всегда использует собственный механизм контроля над объемом расходуемой памяти для хранения результирующего множества. Он заключается в удержании в указанном объеме памяти только наиболее часто используемых строк и вытеснении остальных строк во временный файл. При этом создание файла откладывается до последнего момента. Такой способ хранения данных выгодно отличает IBProvider от других компонентов доступа, которые основываются на поддержке со стороны ОС и использовании ее файла подкачки.
По умолчанию IBProvider удерживает в памяти 32 строки, независимо от их размера. Часто этого может оказаться недостаточно. Поэтому спецификация OLE DB определяет стандартное свойство набора строк "Memory Usage", которое позволяет отрегулировать верхнюю границу используемой памяти.
|
0 |
IBProvider удерживает в памяти 32 ряда. По умолчанию. |
|
1...99 |
Использовать процент от доступной памяти ОС (как физической гак и файла подкачки) |
|
100... |
Использование указанного размера памяти в килобайтах. |
Единственным ограничением, которое присутствует в текущей версии IBProvider (1.6.2), является невозможность редактирования выбранного множества строк, т. е. работы с так называемыми "живыми" запросами, которые часто используются в приложениях, создаваемых с помощью средств разработки компании Borland.
Настройка используемого диалекта InterBase SQL
Gemini ODBC драйвер потдерживает настройкх чиалекта SQL ктиентского приложения. В зависимости oт диалекта драйвер определяет возможности сервера и сообщает их приложению через соответствующие функции ODBC API Например, в диалекте 3 InteiBase поддерживает quoted identifier, и поэтому, при работе с базой данных через приложение SQL Explorer, тексты SQL запросов будут формироваться с идентификаторами в кавычках
Gemini ODBC-драйвер поддерживает все типы данных в каждом из диалектов, включая NUMERIC/DECIMAL, DATE, TIME и TIMESTAMP.
Настройка параметров транзакций
Опции настройки DSN предусматривают задание параметров транзакций использование команд COMMIT/ROLLBACK или COMMIT RETAINING/ROLLBACK RETAINING при завершении транзакции, установку режима "только чтение", установка режима ожидания (WAIT/NO_WAIT) и запрещение выборки старых версий при уровне изоляции READ COMMITTED.
Немного истории
Одним из распространенных заблуждений разработчиков баз данных является мысль, что СУБД InterBase ориентирована исключительно на работу с продуктами компании Borland. И этому способствовало то, что до последнего времени все качественные библиотеки доступа к этому серверу баз данных существовали только для создания приложений на Delphi, C++ Builder или Kylix. Для остальных систем программирования приходилось использовать InterBase API или ODBC. И хотя первое позволяет создавать высокопроизводительные приложения, а второе обладает значительными претензиями на универсальность, оба подхода не в полной мере удовлетворяют требованиям современных программных систем, базирующихся на компонентных технологиях. Поэтому потребность в использовании компонентов доступа к InterBase, универсальных с точки зрения языка программирования, была. И вопрос их реализации заключался только в одном: что именно должны предоставлять эти компоненты и кто решится начать их разработку.
Ответ на первый вопрос дают принципы современной организации масштабируемой архитектуры программного обеспечения, подразумевающие использование компонентов и их группировку в раздельно компилируемые модули. Поэтому компоненты доступа должны обеспечить прозрачную интеграцию компонентов в пределах как одного модуля, так и нескольких. И технология Component Object Model (COM) позволяет без проблем применять эти принципы на практике. Но полноценное использование этой технологии для создания крупных проектов с использованием InterBase осложнялось отсутствием готовой стандартизованной реализации СОМ-объектов доступа к этой СУБД. В результате разработчики программного обеспечения под InterBase вынуждены либо продолжав создавать монолитные приложения, либо самостоятельно решать проблемы совместного использования ресурсов СУБД малосвязанными между собой модулями программы. В первом случае осознанное ограничение возможностей программы экономит время. Во втором, опуская дополнительные трудозатраты на создание компонентов доступа, можно попасть в ловушку, которая в лучшем случае не позволяет сменить сервер базы данных, в худшем приводит к краху всего проекта. Как правило, разработчики это осознают, когда поздно что-либо менять.
Тем не менее попытки создания СОМ-объектов для доступа к InterBase были Наиболее успешной попыткой можно считать библиотеку Visual Database Tools от компании Borland (VDBT). Это VCL-подобные компоненты для Visual Basic, работающие с InterBase через Borland Database Engine. Но библиотека VDBT была готовой реализацией СОМ-объектов доступа к InterBase, а не открытой спецификацией. Поэтому расширению и усовершенствованию не подлежала.
Спецификацию под названием OLE Database (OLE DB), предназначенную для создания компонентов доступа к базам данных, выпустила компания Microsoft, которая курирует и саму СОМ-технологию. Но Open Source InterBase 6 не имел собственного OLE DB-провайдера, поэтому ничего не оставалось, как начать самостоятельную разработку OLE DB for InterBase, известную ныне как IBProvider.
Обзор возможностей IBProvider
Возможность работы со всей линейкой СУБД InterBase, начиная с версии 4 х и заканчивая клонами InieiBase 6 - Firebird и Yattil Минимальным условием работы IBProvider является наличие на компьютере клиента динамической библиотеки GDS32.dll от InterBase 4 (см. главу "Состав модулей InterBase" (ч. 4)). IBProvider самостоятельно определяет уровень возможностей сервера (так называемый base level) и клиентской части (т е. возможности GDS32.dll). а также диалект базы данных и автоматически подстраивается под эти параметры.
Поддержка всех типов данных InterBase. Есть поддержка BLOB-полей (бинарных и текстовых), массивов и типов DECIMAL/NUMERIC (см. главу " Типы данных" (ч. 1)).
Поддержка storage-объектов для работы с BLOB-полями. Эти объекты могут возвращаться клиенту и приниматься в качестве входящих параметров.
Практически весь спектр OLE DB-типов. Помимо типов, непосредственно поддерживаемых InterBase, IBProvider способен принимать и возвращать беззнаковые целые числа, булевы значения, строки UNICODE и т. д.
Встроенная поддержка конвертирования данных из одного типа в другой, преобразования массивов, бинарного и текстового представления BLOB-полей. Для преобразования типа данных NUMERIC используется библиотека для работы с большими целыми числами, что обеспечивает естественную поддержку 64-битовых целых.
Поддержка многопоточной работы. Компоненты провайдера самостоятельно обеспечивают синхронизацию доступа к своим ресурсам, поэтому клиент может не беспокоиться о проблемах параллельной работы с одним подключением к базе данных из нескольких потоков одного приложения.
Отказоустойчивость. Для компонентов, работающих в составе серверных приложений, исключительно важна надежность. При разработке провайдера повсеместно используются мощные возможности языка Си++ для автоматического освобождения ресурсов и обработки исключительных ситуаций.
Оптимизация работы с результирующим множеством SQL-запросов. В зависимости от требований клиента используется механизм либо однонаправленного доступа к выборке, либо произвольного. Для поддержки обработки большого количества данных автоматически применяются временные файлы, причем для доступа к ним используется 64-битовая адресация
Тридцатидвухбитовый кеш выбранных строк результирующего множества. Применение динамической системы приоритетов позволяет удерживать в заданном объеме памяти только наиболее часто используемые строки, а хеш- таблица обеспечивает эффективную навигацию по содержимому кеша. Таким образом, LBProvider способен с одинаковой производительностью обрабатывать как небольшие по размеру результирующие множества, так и очень большие, даже превышающие объем доступной оперативной памяти.
Оптимизация работы с оперативной памятью. Во-первых, IBProvider использует две собственные "кучи" (heap) для динамического выделения памяти. Это снижает нагрузку на системную кучу. Во-вторых, IBProvider интенсивно запускает совместно используемые объекты, хранящие информацию только для чтения. Во время работы IBProvider создает глобальный пул (pool) объектов, что приводит к экономии памяти и позволяет уменьшить время создания и инициализации объектов и, таким образом, улучшить общую производительность приложения баз данных.
Полная поддержка синтаксиса SQL. Также поддерживаются команды для создания/удаления базы данных и явного управления транзакциями.
Работа с базой данных в режиме автоматического запуск и подтверждения транзакций (autocommit). По умолчанию этот режим выключен, так как он не является оптимальным для работы с InterBase, но при необходимости его можно включить.
Полная поддержка параметризованных запросов. Можно использовать именованные и неименованные параметры, самостоятельно или автоматически формировать описания параметров и передавать их значения в обоих направлениях (in-out-параметры).
Поддержка вызова хранимых процедур (сокращенно - ХП; подробнее о них см главу "Хранимые процедуры" (ч. 1)). Провайдер распознает запросы вида "ехес proc_name", "execute proc_name", "execute procedure proc_name" и возвращает результат работы хранимой процедуры через выходные (out) параметры.
Возможность получения метаданных из базы данных InterBase. Это списки таблиц, колонок, хранимых процедур, индексов, ограничений и т. д. (всего 26 видов метаданных). Помимо CASE-средств и систем построения отчетов, эта информация использ>ется в Microsoft Distributed Query для выполнения гетерогенных запросов к нескольким базам данных под управлением различных (!) SQL-серверов (например, MS SQL) посредством OLE DB-провайдеров.
Тщательное следование парадигмам объектно-ориентированного проектирования, а также двухлетнее тестирование в реальных системах СУБД гарантируют высокий уровень надежности и стабильности IBProvider, который идеально подходит для использования в составе программного обеспечения с круглосуточным режимом работы.
В настоящий момент, оставив позади большой объем работ по созданию OLE DB для InterBase, можно пересмотреть роль и назначение этого драйвера. Вытеснив оригинальную клиентскую часть GDS32.DLL на второй план, IBProvider предоставляет мощный объектно-ориентированный низкоуровневый клиентский API для работы с InterBase. Встраиваясь в приложения баз данных, OLE DB-провайдер способен взять на себя всю работу по организации взаимодействия с сервером базы данных. Предоставление ресурсов для работы с базой данных в виде СОМ-объектов снимает традиционные ограничения, накладываемые на клиентские приложения баз данных. Приложение можно дробить на модули, которые можно создавать с помощью разных систем программирования. Используя сценарии, написанные на VBScript/JScript, в программы можно добавлять логику, которую невозможно реализовать на уровне базы данных. OLE DB является общепризнанным промышленным стандартом доступа к данным, что позволяет легко разворачивать и управлять приложениями, разработанными с использованием IBProvider.
Таким образом, разработка крупных масштабируемых клиентских приложений для InterBase с помощью средств разработки компании Microsoft, а также любых других систем, поддерживающих OLE DB, становится более реальной и доступной, чем можно было себе представить ранее.
Операционная система
Все перечисленные компоненты для написания примеров были установлены на одном компьютере, работающем под управлением Windows NT4 Service Pack 5, Internet Explorer 5.
Особенности реализации поддержки массивов
OLEDB-спецификация для представления типа данных "массив" использует структуру SAFEARRAY. Эта же структура употребления для управления массивами в Visual Basic.
Элементы массивов не могут содержать NULL. Это ограничение связано с тем, что InterBase не поддерживает тип VARIANT.
Все типы строк, хранящиеся в массивах, обрабатываются сервером как Си- строки, т. е. заканчивающиеся нулем. IBProvider исходит именно из такого способа хранения и не использует собственных символов типа \п для определения конца строки.
Провайдер предоставляет полную поддержку для преобразования массивов из одного типа в другой. И пользуется ею по умолчанию, поскольку VB не понимает структуру SAFEARRAY, содержащую данные, несовместимые с VARIANT. Вообще говоря, наверное, можно было бы всегда возвращать массивы, содержащие VARIANT, но удалось обойтись без этой крайности. Отключить конвертирование массивов можно с помощью свойства инициализации источника данных (строка подключения) или набора строк "array_vt_type", установив его значение в false.
Как и BLOB-поля, провайдер не хранит и не кеширует данные массива. Информация каждый раз загружается с сервера.
Если при чтении массивов от пользователя не требуется никакой помощи, то для записи массивов провайдеру может потребоваться дополнительная информация. Дело в том, что запись массива, как и BLOB-поля, производиться отдельным обращением к InterBase API. Для этой операции требуется иметь описание, содержащее имя таблицы и имя колонки, в которую производится запись, тип элемента и сведения о размерности. Провайдер способен самостоятельно определить эту информацию только при работе с сервером InterBase 6.x и выше. Для работы с InterBase 4.x и InterBase 5.x IBProvider вводит нестандартное расширение, позволяющее определять в тексте запроса параметры вида "параметр.таблица.колонка". Этот синтаксис может быть использован как для именованных, так и для неименованных параметров:
update job set language_req=?.job.language_req
update job set language_req=:param.job.language_req
Переданные таким образом названия таблицы и колонки используются только для внутренних целей и недоступны вне провайдера. Если IBProvider смог самостоятельно получить эту информацию или значение параметра не является массивом, то пользовательская помощь игнорируется. В противном случае клиент отвечает за корректность переданных дополнительных сведений о параметре. Дополнительно заметим, что во 2-й и 3-й части такого составного имени параметра можно использовать квотированные названия объектов базы данных.
Клиент не имеет возможности определить интересующее его подмножество массива. Провайдер всегда возвращает массив целиком. Это ограничение OLEDB, а не InterBase.
При записи массива можно передавать подмножество. Но нужно учитывать, что массив всегда пересоздается. Поэтому в случае выполнения "UPDATE...", можно потерять предыдущую информацию из неуказанных элементов.
Пример чтения массивов.:
ADODB
Dim en As New ADODB.Connection
cn.Open "file name=d:\database\employee.ibp"
Dim cmd As New ADODB.Command, rs As ADODB.Recordset
cmd.ActiveConnection = cn
cmd. CornmandText = "select * from proj_dept_budget"
Set rs = cmd.Execute
Dim qhc As Variant ' QUART_HEAD_CNT
Dim i As Long
While Not rs.EOF
If IsNull(rs("quart_head_cnt")) Then
Debug.Print "NULL"
Else
qhc = rs("quart_head_cnt")
For i = LBound(qhc, 1) To UBound(qhc, 1)
Debug.Print "qhc[" & CStr(i) & "]=" & CStr(qhc(i))
Next i
End If
rs.MoveNext
Debug.Print "-------------------"
Wend
Пример записи массивов (InterBase 5.6):
ADODB
Dim en As New ADODB.Connection
cn.Open "file name=d:\database\employee.ibp"
Debug.Print en.Properties("IB Version")
cn.BeginTrans
Dim cmd As New ADODB.Command, rs As ADODB.Recordset
cmd.ActiveConnection = cn
cmd CommandText = "select * from proj_dept__budget"
Set rs = cmd.Execute
Dim upd_cmd As New ADODB.Command
upd_cmd.ActiveConnection = cn
upd_cmd.CommandText = _
"update proj_dept_budget " & _
"set quart_head_cnt=:a pro]_aept_budget.quart_head_cnt " & _
"where year=:year and proj_id=:proj_id and dept_no=:dept_no"
upd_cmd.Parameters.Refresh
Dim qhc As Variant ' QUAD_HEAD_CNT
Dim i As Long, RowAffected As Long
While Not rs.EOF
If Not IsNull(rs("quart_head_cnt")) Then
qhc = rs("quart_head_cnt")
For i = LBound(qhc, 1) To UBound(qhc, 1)
qhc(i) = 10 * qhc(i)
Next i
upd_cmd("a") = qhc
upd_cmd("year") = rs("year")
upd_cmd ("proj_id" ) = rs ("proj_id")
upd_cmd("dept_no") = rs("dept_no")
upd_cmd.Execute RowAffected ' транзакционные изменения
Debug.Print ">" & CStr(RowAffected)
End If
rs.MoveNext
Debug.Print -------------------
Wend
en.CommitTrans
Поддержка кодировки UNICODE
Microsoft ODBC 3.5 определяет два типа драйверов - ANSI и UNICODE. Gemini ODBC-драйвер является по этой классификации драйвером UNICODE. Это дает возможность приложениям, использующим версию UNICODE интерфейса ODBC, обрабатывать данные различных национальных наборов символов Для хранения таких данных InterBase предоставляет кодировку (character set) UNICODE_FSS, но вы также можете использовать другие кодировки при хранении данных, в любом случае текстовые строки будут переданы в приложение правильно
Подготовка команды
Если пользователю нужна информация о наборе рядов, который она создаст, то команду нужно подготовить:
C++
t_db_row row;
_THROW_OLEDB_FAILED (cmd, prepare("select * from iob",&row))
Поскольку с точки зрения взаимодействия с InterBase подготовка представляет собой передачу текста SQL-запроса серверу базы данных, то этот этап будет выполнен всегда - либо явным указанием пользователя, либо самой командой. При этом повторный вызов операции подготовки для одного и того же текста запроса игнорируется. Реализация команды провайдера для InterBase не осуществляет переподготовку запроса при повторном выполнении команды, поэтому явная подготовка с целью оптимизации многократного использования команды не имеет смысла
ADODB способно самостоятельно определять необходимость явной подготовки команды, поэтому об этом можно не заботиться Библиотека классов всегда проводит явную подготовку команды, выполняя ее сразу же после установки текста запроса.
Подготовка параметров SQL-запроса
Многократно выполняемые SQL-запросы, как правило, содержат параметры, представляющие собой переменные в тексте SQL-запроса. IBProvider поддерживает два вида параметров: именованные и неименованные. Перед выполнением параметризованного SQL-запроса команда должна обладать описаниями параметров. Описание параметра — это его тип, имя, направление передачи значения (in-out). Пользователь может самостоятельно сформировать описания параметров или поручить формирование параметров команде.
Явное определение параметров SQL-запроса, несмотря на свою громоздкость при работе через ADODB. обеспечивает более эффективную работу с приложениями, поскольку исключается лишнее обращение к серверу для получения их описаний.
Пример явного определения параметров SQL-запроса:
ADODB
cmd.CommandText="select * from job where job_code=?"
cmd.Parameters.Append cmd.CreateParameter(,adBSTR,adParamlnput)
cmd(0)="Eng"
C++
t_db_row row;
t_db_row param(1);
_THROW_OLEDB_FAILED(cmd2,
prepare("select * from job where job_code=?",&row))
//тип параметра определяется его значением
param[0]="Eng";
param.count=1;
_THROW_OLEDB_FAILED(cmd2,execute(¶m));
//Тип параметра задается отдельно от значения,
//в этом случае провайдер выполнит преобразование значения
//в указанный тип.
set_param(param,0,adBSTR,"Eng");
param.count=1;
_THROW_OLEDB_FAILED(cmd2,execute(¶m));
Автоматическое определение описаний параметров SQL-запроса позволяет клиентскому приложению перепоручить отслеживание типов параметров InterBase и конвертору типов IB Provider.
Пример явного указания команде сгенерировать описания типов:
ADODB
cmd.CommandText = "select * from job where job_code=?"
cmd.Parameters.Refresh
cmd(0) = "Eng"
Явное указание обновления списка параметров (cmd.Parameters.Refresh) обычно можно опустить. Однако иногда это необходимо. Например, для выполнения такого цикла:
ADODB
Dim cmd As New ADODB.Command
Dim is As ADODB.Recordset
cmd.ActiveConnection = сn
cmd.CommandText = "select * from job where job_code=?"
Dirr i AS_ Long For i = 0 To 10
cmd.Parameters.Refresh
cmd(0) = "Eng"
Set rs = cmd,Execute
'...
'rs.Close
Next i
Вся хитрость заключается в том, что ADODB при выполнении второй итерации будет создавать новую OLE DB-команду, поскольку предыдущая занята обслуживанием результирующего множества SQL-запроса, созданного на первом шаге. Без строки cmd.Parameters.Refresh внутренний список описания параметров новой команды не будет сформирован, хотя коллекция ADODB.Command.Parameters будет содержать элементы. В результате при вызове метода cmd.execute в команду передаются значения параметров, описание которых у нее отсутствует. Принудительное обновление решает эту проблему. Понятно, что создание новой команды снижает производительность описанного выше алгоритма. Поэтому для того, чтобы ADODB могло повторно воспользоваться OLE DB-командой, нужно закрывать результирующее множество (rs.Close).
Повторный вызов cmd.Parameters.Refresh для одного и того же запроса не приводит к повторному обращению к серверу, поэтому расходы на такое дублирование ничтожны.
Автоматическая генерация описания параметров:
C++
_THROW_OLEDB_FAILED(cmd2,describe_params(param));
param[0]="Eng";
_THROW_OLEDB_FAILED(cmd2,execute(¶m) ) ;
Существует единственное исключение, когда IBProvider обязательно выполнит дополнительный запрос на сервер для получения описания параметров SQL- запроса. Это касается слуиая, когда в параметре передается массив. Для такого типа параметров необходима дополнительная информация об имени таблицы и поля, в которые будут производить запись данных, а также информация о размерности массива. Подробности см. далее в разделе "Работа с массивами".
В вышеприведенных примерах были использованы неименованные параметры, обозначаемые в тексте запроса символом вопросительного знака. Именно такое обозначение параметров поддерживает и сам InterBase. Однако иногда удобно использовать именованные параметры в SQL-запросах:
Именованный параметр можно многократно указывать в разных частях одного запроса.
Порядок описания параметров может не соответствовать порядку использования параметров в тексте запроса. Это недопустимо для неименованных параметров.
В ADODB за удобство именованных параметров приходиться "платить" использованием режима автоматической генерации описания параметров (ADODB.Command.Parameters.Refresh). Причина заключается в том, что имя параметра, указываемое в ADODB.Command.CreateParameter, не передается команде. При использовании классов C++ такого ограничения нет - описание параметров можно формировать обоими способами. Еще одним ограничением, ADODB является невозможность использования именованных параметров для BLOB-полей -только неименованные параметры '?'.
Как уже было сказано выше, команда запрещает одновременное использование в тексте запроса именованных и неименованных параметров.
Сам InterBase поддерживает неименованные параметры. Поэтому команда вынуждена заменять в тексте запроса именованные параметры на неименованные параметры. Окончательный текст запроса, используемый для передачи на сервер, доступен через свойство команды "Prepare Stmt"
Пример многократного выполнения параметризованного запроса, содержащего именованный параметр:
ADODB
Dim cmd As New ADODB.Command
Dim rs As ADODB.Recordset
cmd.ActiveConnection = en
cmd.CommandText = "select * from job where job_code=:job_code"
Dim i As Long
For i = 0 To 10
cmd.Parameters.Refresh
cmd("job_code") = "Eng"
Debug.Print cmd.Properties("prepare stmt")
Set rs = cmd.Execute
'...
rs.Close
Next i
Запрос без параметров
Предположим, у нас есть таблица следующей структуры:
CREATE TABLE BOOKS (
B_ID INTEGER NOT NULL,
B_INDEX CHAR(16) NOT NULL,
B_NAME VARCHAR(80) NOT NULL,
B_AUTHOR VARCHAR(SO) NOT NULL,
B_ADDED TIMESTAMP DEFAULT 'now' NOT NULL,
B_THEME VARCHAR(60) NOT NULL);
Для того чтобы отобразить результат запроса "select b_id. b_index, b_name. b_authoi, b_added, b_theme from books" в виде следующей таблицы (см. Рис. 3.1):

Рис 3.1. Результат выполнения SQL-запроса, представленный в браузере в виде HTML- таблицы
понадобится следующий скрипт: (examplel.с)
#include <ibase.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
// Эта структура предназначена для хранения переменных типа SQL_VARYING
#define SQL_VARCHAR(len) struct {short vary_length; char
vary_string[(len)+1];}
int main (void){
/ / Константы, необходимые для работы с базой данных - инициализируйте их в
// соответствии с реальным путем к базе, пользователем и паролем
char *dbname = "localhost:/var/db/demo.gdb";
char *uname = "sysdba";
char *upass = "masterkey";
char *query = "select b_id, b_index, b_name, b_author, b_added,
b_theme from books";
/ / Переменные для работы с базой данных
isc_db_handle db_handle = NULL;
isc_tr_handle transaction_handle = NULL;
isc_stmt_handle statement_handle=NULL;
char dpb_buffer[256], *dpb, *p;
short dpb_length;
ISC_STATUS status_vector[20] ;
XSQLDA *isqlda, *osqlda;
long fetch_code;
short
o_ind[20]={0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0, 0,0);
/ / Остальные переменные
int i = 0;
long b_id;
char b_index[17];
SQL_VARC HAR(100) b_name;
SQL_VARCHAR(100) b_author;
SQL_VARCHAR(100) b_theme;
ISC_TIMESTAMP b_added;
struct tm added_time;
char decodedTime[100];
Здесь наше приложение начинает вывод стандартного HTML-документа:
printf("Content-type:
text/plain\n\n<html><body><center><b>Example Nr l</b><br>SELECT
without input parameters</centerxbr>") ;
а затем подключается к базе данных - здесь два этапа
// создаем так называемый database parameter buffer, необходимый
/ / для подключения к базе данных
dpb=dpb_buffer;
*dpb++ = isc_dpb_versionl;
*dpb++ = isc_dpb_user_name;
*dpb++ = strlen(uname);
for(p = uname; *p; ) *dpb++ = *p++;
*dpb++ = isc_dpb_password;
*dpb++ = strlen(upass);
for (p=upass; *p;) *dpb++ = *p++;
dpb_length = dpb dpb_buffer;
// Подключаемся к базе
isc_attach_database(
status_vector,
strlen(dbname),
dbname,
&db_handle,
dpb_length,
dpb_buffer) ;
Далее идет стандартная для большинства API-функций проверка и анализ результата:
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector) ;
return(1);
}
Если подключение к базе данных произошло удачно, начинается транзакция:
if (db_handle){
isc_start_transaction(
status_vector,
&transaction_handle,
1,
&db_handle,
0,
NULL);
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector);
return(1);
}
}
Далее инициализируются структуры, которые будут заполняться результатами запроса:
osqlda = (XSQLDA *)malloc(XSQLDA_LENGTH(6));
osqlda -> version = SQLDA_VERSION1;
osqlda -> sqln = 6;
osqlda->sqlvar[0].sqldata = (char *)&b_id;
osqlda->sqlvar[0].sqltype = SQL_LONG;
osqlaa->sqlvar[0].sqlind = &o_ind[0];
osqlda->sqlvar[1].sqldata = (char *)&b_index;
osqlda->sqlvar[1].sqltype = SQL_TEXT;
osqlda->sqlvar[1].sqlind = &o_ind[l];
osqlaa->sqlvar[2].sqldata = (char *)&b_name;
osqlda->sqlvar[2].sqltype = SQL_VARYING;
osqlda->sqlvar[2J .sqlind = ko_ind[2];
osqlda->sqlvar[3].sqldata = (char *)&b_author;
osqlda->sqlvar[3].sqltype = SQL_VARYING;
osqlda->sqlvar[3].sqlind = &o_ind[3];
osqlda->sqlvar[4].sqldata = (char *)&b_added;
osqlda->sqlvar[4].sqltype = SQL_TIMESTAMP;
osqlda->sqlvar[4].sqlind = &o_ind[4];
osqlda->sqlvar[5].sqldata = (char *)&b_theme;
osqlda->sqlvar[5].sqltype = SQL_VARYING;
osqlda->sqlvar[5].sqlind = &o_ind[5];
А вот здесь, собственно, и начинается подготовка к исполнению запроса сервером:
isc_dsql_allocate_statement(
status_vector,
&db_handle,
&statement_handle);
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector);
return(1);
}
isc_dsql_prepare(
status_vector,
&transaction_handle,
&scatement_handle,
0,
query,
SQL_DIALECT_V6,
osqlda);
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector);
return(1);
}
isc_dsql_execute2(
status_vector,
&transaction_handle,
&statement_handle,
1,
NULL,
NULL);
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector) ;
return(1);
}
Здесь начинается таблица HTML-документа. Ситуация, когда в базе данных может не оказаться данных, подробно анализируется во втором примере.
printf("<center><table bgcolor=black cellpadding=l
cellspacing=l><tr align=center bgcolor=#999999> <td>Book
ID</tr> <td>CODE</tr> <td>TITLE</tr> <td>AUTHOR</tr>
<td>ADDED</tr> <td>THEME</tr> </tr>");
После исполнения запроса сервер готов к передаче данных. "Доставкой" данных !лнимаегся функция isc_dsql_tetch()'
while((fetch_code = isc_dsql_fetch(
status_vector,
&statement_handle,
1,
osqlda))= = 0) {
Для строковых переменных требуется корректно установить длину, так как размер возвращаемых данных не всегда соответствуем максимально возможному, и если этого не сделать, то вместе с реальными данными можно получить' "мусор" из памяти или остатки предыдущих строк:
b_index[osqlda->sqlvar[1].sgllen]= ' \0 ' ;
b_name.vary_string[b_name.vary_length] = '\0' ;
b_author.vary_string[b_author.vary_length]='\0';
b_theme.vary_string[b_theme.vary_length]='\0';
Структуру типа TIMESTAMP, как и структуры DATE/TIME, перед выводом в документ можно преобразовать в строковый тип в нужном формате. Для этого сначала она декодируется в структуру tm, а затем в строку:
isc_decode_timestamp(&b_added,&added_time);
strftime(decodedTime,sizeof(decodedTime),"%d-%b-%Y
%H:%M",&added_t ime);
printf("<tr bgcolor=white><td>%i</td> <td>%s</td> <td>%s</td>
<td>%s</td> <td>%s</td> <td>%s</td> </tr>",
b_id,
b_index,
b_name vary_strxng,
b_author.vary_string,
decodedTime,
b_theme.vary_string);
}
После вывода всех данных необходимо завершить документ:
printf ("</table></center></body></html>") ;
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector);
return(1);
}
free(osqlda);
isc_dsql_free_statement(
status_vector,
&statement_handle,
DSQL_drop);
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector);
recurn(l);
}
Затем завершить транзакцию и отключиться от базы данных:
if (transaction_handle){isc_commit_transaction(status_vector,
&transaction_handle);}
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector);
return(1),
}
if (db_handle) isc_detach_database(status_vector, &db_handle);
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector) ;
return(1);
}
return(0);
}// end of main
Обратите внимание на маленькую разницу в работе с переменными SQLJVARYING и SQL_TEXT (это соответственно VARCHAR и CHAR языка SQL). Разница в том, что если в базе данных хранится меньше символов, чем максимально возможно для столбца (например, объявлено CHAR(16), а хранится строка "12345"), то сервер добавит N пробелов в конец строки, где N является' разницей между максимально возможным количеством символов и реально хра-1 нящимся в поле таблицы. Тип SQL_VARYING свободен от этого недостача,< однако при получении данных нужно учитывать, что только определенное зна-1 чение символов является реально полученными; остальное количество - это| случайные данные из памяти компьютера, на котором исполняется скрипт. Для | удобства работы с этим типом обычно определяют структуру, где член структу- \ ры SQL_VARCHAR vary_length указывает размер полученной строки,^ a vary_string собственно содержит строку.
Если запрос гарантированно возвращает одно значение (например, одиночный SELECT или вызов хранимой процедуры), то использовать функцию; isc_dsql_fetch() нет необходимости, вместо этого в параметр функции! isc_dsql_execute2() можно подставить значение osqlda переменной Работа с ти-1 пами SQL DATE и TIME абсолютно не отличается от работы с переменнымиii типа TIMESTAMP - всего лишь используются другие функции для преобразо-" вания: isc_decode_sql_date() и isc_decode_sql_time(). j
Запрос с параметрами
Теперь рассмотрим пример исполнения запроса с параметрами - вызов xpaнимой процедуры, которая просто вставит данные из формы в эту же таблицу.| Принципиально этот пример практически ничем не отличается от вышеприведенного, за исключением того что в нем появляются две дополнительные части - одна разбирает переменные HTML-формы, другая (если переменные переданы) исполняет процедуру.
Вот текст этой ХП.
create procedure InsertData (b_index char(16),
b_name varchar(80),
b_author varchar(80),
b_theme varchar(60))
returns (result_code integer)
as
begin
insert into books (
B_ID,B_INDEX,B_NAME, B_AUTHOR,B_ADDED,BJTHEME)
values(0,.b_index, :b_name, :b_author, 'now', :b_theme);
result_code = 0;
when any
do begin
result_code=-l;
end
end
Текст ХП достаточно банальный, вместо него в действительности можно было бы воспользоваться командой INSERT, однако подразумевается, что в реальной процедуре производятся некоторые манипуляции с входными данными (например, код книги может генерироваться не генератором, а по определенному алгоритму) и в качестве результата либо происходит вставка данных, либо процедура возвращает код ошибки.
Текст скрипта второго примера выглядит так :
#include <ibase.h>
#include <stdio.h>
#include <stdlib.h>
#include <scring.h>
#include <time.h>
#include "cgic.h"
#define SQL_VARCHAR(len) struct {short vary_length; char
vary_string[(len)+1];}
Вот здесь некоторое отличие: используемая для разбора переменных www- библиотека заменяет стандартную функцию main:
int cgiMain (void){ '
char *dbname = "localhost:/var/db/demo.gdb";
char *uname = "sysdba";
char "upass = "masterkey";
char *qaery = "select b_id, b_index, b_name, b_author, b_added,
b_theme from books";
На месте неизвестных входящих параметров - знаки вопроса:
char *SPCall = "execute procedure insertdata (?,?,?,?)";
isc_db_handle db_handle = NULL;
isc_tr_handle transaction_handle = NULL;
isc_stmt_handle statement_handle=NULL;
char dpb_buffer[256], *dpb, *p;
short dpb_length;
ISC_STATUS status_vector[20];
XSQLDA *isqlda, *osqlda;
Long fetch_code;
Short
o_ind[20]={0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0);
int i = 0;
int hDisplayed=0;
int formVarErr;
int ExecSP=l;
long res_code;
long b_id;
char b_index[17];
SQL_VARCHAR(100) b_name;
SQL_VARCHAR(100) b_author;
SQL_VARCHAR (100) b_theme;
ISC_TIMESTAMP b_added;
struct tm added_time;
char decodedTime[100];
char form_b_index[17],
form_b_name[81],
form_b_author[81],
form_b_theme[61];
В этой части происходит анализ переменных, полученных скриптом, и в зависимости от метода вызова принимается решение, исполнять ли ХП или нет.
printf("Content-type:
text/plain\n\n<htmlxbody><center><b>Example Nr 2</b><hr
width=\%></centerxbr> Part 1: Executable SP
demo with both types of parameters.<br>");
if(strcmp(cgiRequestMethod,"POST")==0){
formVarErr =
cgiFormStringNoNewlines("b_index",form_b_index,17);
if (formVarErr!=cgiFormSuccess){
printf("<br><b>Error: Book index missed or too long</b>");
ExecSP=0,
}
formVarErr = cgiFormStringNoNewlines("b_name",form_b_name,81);
if {formVarErr!=cgiFormSuccess){
printf ("<brxb>Error: Book name missed or too long</b>");
ExecSP=0;
}
formVarErr =
cgiFormStringNoNewlines("b_author",form_b_author,81);
if (formVarErr!=cgiFormSuccess){
printf ("<br><b>Error: Book author missed or too long</b>");
ExecSP=0;
}
formVarErr =
cgiFormStringNoNewlines("b_theme",form_b_theme,61);
if (formVarErr!=cgiFormSuccess){
printf("<br><b>Error: Book theme missed or too long</b>");
ExecSP=0;
}
}
else{
ExecSP=0;
printf ("<brxi>Procedure execution skipped</i> - REQUEST_METHOD
must be POST");
}
Заметьте: если специфика приложения требует того, чтобы определенные www-переменные обязательно присутствовали и удовлетворяли определенным условиям (например, учетные данные пользователя могут быть защищены контрольной суммой), то именно в этом месте приложение производит решение о целесообразности продолжения работы. 1
После разбора переменных идет непосредственно работа с базой данных:
dpb=dpb_buffеr;
*dpb++ = isc_dpb_versionl;
*dpb++ = isc_dpb_user_name;
*dpb++ = strlen(uname);
for(p = uname; *p;)
*dpb++ = *p++;
*dpb++ = isc_dpb_password;
*dpb++ = strlen(upass);
for (p=upass; *p;)
*dpb++ = *p++;
dpb_length = dpb- dpb_buffer;
isc_attach_database(
status_vector,
strlen(dbname),
dbname,
&db_handle,
dpb_length,
dpb_buffer);
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector);
return(1};
}
if (db_handle){
isc_start_transaction(
status_vector,
&transaction_handle,
1,
&db_handle,
0,
NULL);
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector);
return(l);
}
}
Если были получены данные и они корректны, происходит вызов хранимой процедуры:
if(ExecSP){
printf("<br><i>Attempt to call SP with the following
parameters:
' %s' , '%s' , ' %s' , '%s'</i>.....",form_b_index,form_b_name,form_b_a
uthor,form_b_theme);
Как можно видеть, принципиально инициализация структур для входящих параметров не сильно отличается от инициализации исходящих параметров из первого примера:
isqlda = (XSQLDA *)malloc(XSQLDA_LENGTH(4));
isqlda->version = SQLDA_VERSION1;
isqlda->sqln = 4;
isqlda->sqld = 4;
isqlda->sqlvar[0] .sqldata = (char *)&form_b_index;
isqlda->sqlvar[0].sqltype = SQL_TEXT;
isqlda->sqlvar[0].sqllen = strlen(form_b_index);
isqlda->sqlvar [1] . sqldata = (char * ) &f orm_b_name,
isqlda->sqlvar[1].sqltype = SQL_TEXT;
isqlda->sqlvar[1].sqllen = strlen(form_b_name);
isqlda->sqlvar[2].sqldata = (char *)&form_b_author;
isqlda->sqlvar[2].sqltype = SQL_TEXT;
isqlda->sqlvar[2].sqllen = strlen(form_b_author);
isqlda->sqlvar[3].sqldata = (char *)&form_b_theme;
isqlda->sqlvar[3].sqltype = SQL_TEXT;
isqlda->sqlvar[3].sqllen = strlen(form_b_theme);
osqlda = (XSQLDA *)malloc(XSQLDA_LENGTH(1));
osqlda -> version = SQLDA_VERSION1;
osqlda -> sqln = 1; osqlda -> sqld = 1;
osqlda->sqlvar[0].sqldata = (char *)&res_code;
osqlda->sqlvar[0].sqltype = SQL_LONG;
osqlda->sqlvar[0].sqllen = sizeof(long);
osqlda->sqlvar[0].sqlind = &o_ind[0];
Вызов ХП происходит сразу, без предварительной подготовки (подробнее об этом будет рассказано несколько ниже):
isc_dsql_exec_immed2(
status_vector,
&db_handle,
&transaction_handle,
0,
SPCall,
SQL_DIALECT_V6,
isqlda,
osqlda};
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector) ;
return(1);
}
if(res_code==0){
printf(" <t»successfly</b>.");
}
else{
printf(" <b>failed with result_code=%i</b>.",res_code);
}
free(isqlda);
free(osqlda);
}
Далее идет выборка данных из таблицы базы данных - это несколько модифицированная часть из первого примера, которая анализирует, были ли получены данные или таблица оказалось густой и отображать нечего.
printf ("<brxbr> Part 2: Select without input
parameters<br>");
osqlda = (XSQLDA *)malloc(XSQLDA_LENGTH(6));
osqlda -> version = SQLDA_VERSION1;
osqlda -> sqln = 6;
osqlda->sqlvar[0].sqldata = (char *)&b_id;
osqlda->sqlvar[0].sqltype = SQL_LONG;
osqlda->sqlvar[0].sqlind = &o_ind[0];
osqlda->sqlvar[1].sqldata = (char *)&b_index;
osqlda->sqlvar[1].sqltype = SQL_TEXT;
osqlda->sqlvar[1].sqlind = &o_ind[l];
osqlda->sqlvar[2].sqldata = (char *)&b_name;
osqlda->sqlvar[2].sqltype = SQLJVARYING;
osqlda->sqlvar[2].sqlind = &o_ind[2];
osqlda->sqlvar[3].sqldata = (char *)&b_author;
osqlda->sqlvar[3].sqltype = SQL_VARYING;
osqlda->sqlvar[3].sqlind = &o_ind[3];
osqlda->sqlvar[4].sqldata = (char *)&b_added;
osqlda->sqlvar[4].sqltype = SQL_TIMESTAMP;
osqlda->sqlvar[4].sqlind = &o_ind[4];
osqlda->sqlvar[5].sqldata = (char *)&b_theme;
osqlda->sqlvar[5].sqltype = SQL_VARYING;
osqlda->sqlvar[5].sqlind = &o_ind[5];
isc_dsql_allocate_statement(
status_vector,
&db_handle,
&statement_handle);
if (stacus_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector);
return{1);
}
isc_dsql_prepare(
status_vector,
&transaction_handle,
&statement_handle,
0,
query,
SQL_DIAL,ECT_Y6,
osqlda);
if (status_vector [ 0] == 1 && status_vector[1]) {
isc_print_status(status_vector) ;
return(1);
}
Заметьте, что если бы запрос гарантированно возвращал одну запись, то надобность в вызове функции isc_dsql_fetch()oтпaлa бы, а на месте последних двух пустых значений в вызове нижеследующей функции были бы соответственно isqlda и osqlda:
isc_dsql__execute2 (
status_vector,
&transaction_handle,
&statement_handle,
1,
NULL,
NULL);
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status (status_vector);
return(1);
}
while((fetch_code = isc_dsql_fetch(
status_vector,
&staternent .handle,
1,
osqlda))==0)
{
Вот здесь и производится проверка на существование хотя бы одной записи в таблице:
if (!hDisplayed){
hDisplayed=l;
printf ("<brxbr><center><table bgcolor=black
cellpadding=l cellspacing=l><tr align=center bgcolor=#999999>
<td>Book ID</tr> <td>CODE</tr> <td>TITLE</tr> <td>AUTHOR</tr>
<td>ADDED</tr> <cd>THEME</tr> </tr>");
}
Далее идет уже знакомая по предыдущему примеру обработка текстовых переменных:
b_index[osqlda->sqlvar[1].sqllen]='\0';
b_name.vary_string[b_name.vary_length]='\0';
b_author.vary_string[b_author.vary_length]='\0';
b_theme.vary_string[b_theme.vary_length]='\0';
и преобразование TIMESTAMP в удобочитаемое выражение:
isc_decode_timestamp(&b_added,&added_time);
strftime(decodedTime,sizeof(decodedTime),"%d-%b-%Y
%H: %M", &added_t ime) ;
printf("<tr bgcolor=white><td>%i</td> <td>%s</td> <td>%s</td>
<td>%s</td> <td>%s</td> <td>%s</td> </tr>",
b_id,
b_index,
b_name.vary_string,
b_author.vary_string,
decodedTime,
b_theme.vary_string);
}
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector);
return(1);
}
free(osqlda);
isc_dsql_free_statement(
status_vector,
&statement_handle,
DSQL_drop);
if (scacus_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector) ;
return(1);
}
Завершаем транзакцию и отключаемся от базы данных:
if (transaction_handle){
isc_commit_transaction(status_vector, &transaction_handle); }
if (status_vector[0] == 1 && status_vector[1]){
isc_pnnt_status (status_vector) ;
return(1);
}
if (db_handle) isc_detach_database(status_vector, &db_handle);
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector);
return(1);
}
Завершаем документ HTML-формой для ввода данных:
if(hDisplayed){
printf("</table></center><br>");
}
else{
printf ("<br><brxbr><center><b>Table is
empty</b></center><brxbr><br>") ;
}
printf ( "<centerxtable width=%><tr
><td><form name ='demo ' method=POST
action= ' example2 ' xtable>") ;
printf("<tr><td align=left>Book index</td><td>
<input type=text name='b_index' size=16 maxlength=16></td></tr>") ;
printf("<tr><td align=left>Book name</td><td>
<input type=text name= ' b_name ' size=16 maxlength=80x/tdx/tr>");
printf ("<tr><td align=lef t>Book author</td><td>
<input type=text name='b_author' size=16 maxlength=80></td></tr>");
printf("<tr><td align=left>Book theme</td><td>
<input type=text name='b_theme' size=16 maxlength=60></td></tr>");
printf ("<trxtd colspan=2 >
<input type= ' submit' value='Add data'></td></tr>"};
printf ("</table></form></td></tr></table></center></body></html>");
return(0);
}// end of main
Вот что мы получим при первом запуске приложения при пустой таблице данных (см. рис 3.2):

Рис 3.2. Результат вставки записи
После вставки какой-нибудь записи в таблицу при помощи формы справа снизу результат будет следующим (см. рис 3.3).
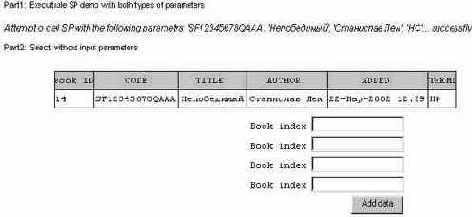
Рис 3.3. Результаты выполнения CCI-приложения
В этом приложении читается несколько переменных www-окружения, которые проверяются на ненулевую длину и передаются в качестве входящего параметра запроса. Переменные www-окружения читаются при помощи функций библиотеки CGIC (ее можно загрузить с сайта http://www.boutell.com/cgic), однако вы можете воспользоваться любой удобной вам библиотекой. В качестве результата анализируется переменная res_code, и в зависимости от ее значения сообщается результат вызова процедуры. Неизвестные входные параметры, участвующие в запросе, передаются следующим образом: на местах неизвестных параметров ставится знак вопроса (?), а в соответствующей этому параметру переменной XSQLDA определяется тип и данные для передаваемой переменной, причем допускается смешивать родственные типы (int-smallint, char-varchar и т д ) При внимательном изучении примера видно, что запрос, выбирающий данные из таблицы, вызывается несколько отличным методом, нежели запрос вызывающий ХП. Первый запрос, состоит из следующих этапов:
Резервирование ресурсов, требуемых для запроса библиотекой доступа к InterBase, - вызов функции isc_dsql_allocate_statement().
Подготовка запроса к исполнению сервером - именно на этом этапе выдаются сообщения об ошибках в синтаксисе - вызов функции isc_dsql_prepare().
Исполнение запроса сервером - вызов функции isc_dsql_execute2() (или isc_dsql_execute(), отличие этих функций в том, что вызов isc_dsql_execute() непременно требует вызова функции isc_dsql_fetch(), если существуют исходящие параметры). На этом этапе могут быть выданы сообщения о несоответствии типов и/или количества элементов XSQLDA.
Доставка данных приложению - вызов isc_dsql_fetch(). В отличие от большинства остальных API-функций эта функция возвращает целое число, содержащее код ошибки, - пока это значение равно нулю, данные есть и их можно прочитать. Когда выбраны все данные, это значение становится отличным от нуля.
Освобождение ресурсов, занятых на этапе 1, - вызов isc_dsql_free_statement(). Инициализация структур XSQLDA обычно происходит до п. 2.
Второй запрос исполняется сразу, минуя все вышеперечисленные пункты, кроме п. 3. В данном случае используется функция isc_dsql_exec_immed2(). Отличие данных методов заключается в том, что в случае первого запроса можно воспользоваться пп. 3 и 4 внутри цикла - это дает преимущество в скорости, при исполнении одного и того же запроса, но с разными значениями параметров, так как синтаксис уже проверен и запрос сразу исполняется. Метод, реализованный в исполнении второго запроса, обычно применяется при однократном вызове хранимых процедур или при исполнении команд, которые разрешается исполнять только в этих функциях (например, CREATE DATABASE разрешается использовать только в вызове функции isc_dsql_execute_immediate()).
Так как в случае "немедленного" исполнения запроса не происходит его предварительного анализа, то необходимо инициализировать переменную sqld структуры XSQLDA, которая используется для получения результата (в данном случае это делает строка osqlda -> sqld =1). Если не проинициализировать эту переменную, то в качестве результата вызова функции isc_dsql_exec_immed2 будет получена ошибка Message length error... По той же причине, необходимо явно указывать размер памяти, который будет занимать переменная, хранящая результат, - в данном случае это sizeof(long). Если этого не сделать, то последствия будут непредсказуемы, - в лучшем случае вы не получите ничего на выходе.
При разработке CGI-приложений, работающих с InterBase, следует придерживаться следующих правил:
Все переменные www-окружения должны быть проанализированы до подключения к базе данных - может случиться, что нужных данных нет или они не удовлетворяют каким-либо требованиям и работа с базой данных заведомо теряет смысл. В этом случае следует проинформировать пользователя о неверно введенных данных.
Старайтесь вывод данных, не зависящих от работы с самой базой данных, производить вне подключения, тем самым сохраняя ресурсы сервера.
Запускайте, если это возможно, сервер от имени пользователя с ограниченными правами.
Создайте клиента базы данных (см. главу "Безопасность в InterBase: пользователи, роли и права" (ч. 4)), которого будут использовать все www-приложения для доступа к базе данных, и назначьте ему минимально необходимые права.
Маленький совет напоследок (применимый для InterBase с архитектурой SuperServer): если прописать вызов сервера в inittab с параметром respawn, то система сама перезапустит сервер в случае его падения надежнее, чем это сделает guardian Таким образом, получится некий аналог птицы Феникс - сервер базы данных возродится сразу же после фатальной ошибки (допущенной, например, при разработке приложений на API).
приложения на Java
Давайте рассмотрим простой пример приложения на Java, который будет устанавливать связь с базой данных, производить выборку данных из таблицы и распечатывать ее на экране.
Хотя в данном примере показывается работа с InterBase, можно заметить, что он похож на примеры работы с другими серверами СУБД. Это связано с тем, что Java, а точнее, JDBC предоставляет универсальный способ общения своих приложений и любых СУБД, для которых есть JDBC-драйвера. InterBase не является исключением, и любой Java-разработчик сможет легко разобраться в использовании JDBC-драйвера InterBase, если он ранее уже работал с JDBC.
Итак, вот пример программы, которая находится в файле SampleInterBase2JAVA.Java:
import Java.sql.*;
public class SampleInterBase2JAVA {
public static void main(String[] args){
// срока соединения с базой данных InterBase String url =
"jdbc:InterBase://localhost/C:/Database/test.gdb"; try {
// загружаем драйвер для InterBase
Class.forName("InterBase.interclient.Driver");
} catch(Java.lang.ClassNotFoundException e) {
// в случае, если драйвер не найден,
// выдаем сообщение об ошибке
System.err.printlnfe.getMessage()) ;
}
Connection conn = null; // соединение с базой данных
try {
// создаем соединение с базой данных (объект conn)
// указанной в строке соединения url
// используем пользователя/пароль:
SYSDBA/masterkey
conn = DriverManager.getConnection(url,"SYSDBA", "masterkey");
} catch(Java.sql.SQLException sqle){
// в случае проблем с подключением
// выдаем соответствующее сообщение об ошибке
System.err.println(sqle.getMessage()) ;
}
//после создания соединения
// создаем объект выражение stint
Statement stmt = null;
try{
stmt = conn.createStatement();
}catch(Java.sql.SQLException EsqlConn){
System.err.printlntEsqlConn.getMessage());
}
// текст SQL-запроса
String sSQL = "Select ID, NAME FROM TableExample";
ResultSet rs = null;
try{
// выполняем запрос и помещаем результат
//в объект ResultSet rs
rs = stmt.executeQuery(sSQL);
}catch( Java, sql. SQL/Exception EsqlConn) {
System.err.printIn(EsqlConn.getMessage());
}
// распечатываем результат на экране
try{
while (rs.next()) {
int id = rs.getlntC'ID");
String s = rs.getStringt"NAME");
System.out.println(id + " " + s) ;
}
}catch(Java.sql.SQLException EsqlFetch){
System.err.println(EsqlFetch.getMessage());
}
}
}
Теперь можно попытаться откомпилировать и запустить эту тестовую программу следующим образом:
Java.exe SampleInterBase2JAVA
Если все установлено правильно и существует такая база, то вы получите два столбца с результатами. Однако есть одна особенность, которую необходимо знать для работы из Java с базами данными, содержащими кириллицу.
Если вы следовали рекомендациям, приведенным в главе "Русификация InterBase" (ч. 1), то ваша тестовая база, в которой предполагается хранить русские символы, создана с использованием набора символа (charser) WIN1251.
Если попытаться получить из базы данных строки, содержащие русские символы описанным в приведенном выше примере способом, то в результате выборки будут находиться символы с некорректной кодировкой, которые прочитать будет невозможно. Чтобы заставить JDBC-драйвер InterBase использовать правильный набор символов для работы с кириллицей, необходимо указать его в параметрах соединения. Для этого следует создать объект Properties и поместить в него параметры соединения. За набор символов, который будет использоваться для соединения с базой данных, отвечает параметр charset. Вот пример соединения:
// задаем параметры соединения строку соединения,
// имя пользователя, пароль и набор символов
String url = "jdbc:InterBase://localhost/C:/Database/test.gdb";
String uName = "SYSDBA";
String pass = "masterkey";
String charSet="cp!251";
// создаем структуру для хранения параметров соединения
Properties prop = new Properties();
prop.put("user", uName);
prop.put("password", pass);
prop.put{"charset", charSet);
// получаем соединение с базой данных InterBase
// с указанием используемого набора символов
Connection db = DriverManager.getConnection(url, prop);
Таким образом разрешается проблема в приложениях Java с работой с кириллическими символами в базах данных InterBase.
ы использования ADODB
Для создания примеров работы с IBProvider через ADODB был применен Visual Basic for Application (VBA) из Microsoft Excel 97. Для использования ADODB-компонентов нужно их добавить в список библиотек, употребляемых Visual Basic Для этого:
Откройте редактор кода Visual Basic (Alt+Fl 1).
Выберите пункт меню Сервис\Ссылки.
Найдите в списке строку Microsoft ActiveX Data Objects 2.6 Library и поставьте рядом с ней галочку.
Закройте окно, нажав кнопку "ОК".
ы использования библиотеки классов
Для написания и тестирования примеров использовался Borland C++ Builder 3-й версии (с установленным пакетом исправлений, который доступен для скачивания на сайте компании Borland). Библиотека классов самостоятельно конфигурируется под использование компилятора и STL из ВСВ5, поэтому примеры переносятся на Borland C++ Builder 5-й версии без проблем.
В примерах, включенных в текст этого раздела, опускаются этап инициализации СОМ и обработка исключений. Все это, естественно, присутствует в оригинале примеров, доступных для скачивания с сайта поддержки этой книги www.lnterBase-world.com.
Также для изучения технологии использования библиотеки классов для работы с OLE DB из C++ рекомендуется посмотреть примеры из дистрибутива IBProvider.
Примеры работы с транзакциями
Ниже приведены примеры, демонстрирующие способы запуска и завершения транзакций, поддерживаемые OLE DB-провайдером.
ADODB:
явное управление транзакцией:
Dim en As New ADODB.Connection
сn.Provider = "LCPI.IBProvider.1"
Call en.Open(
"data source=localhost:d:\database\employee.gdb",
"gamer","vermut")
'стандартный способ
сn IsolationLevel = adXactRepeatableRead
сn.BeginTrans
'...
'можно указать использование commit retaining
'cn.Attributes = adXactAbortRetaining + adXactCommitRetaining
cn.CoimutTrans
'управление транзакцией через SQL (можно использовать специфику
InterBase)
Dim cmd As New ADODB.Command
cmd.ActiveConnection = en
cmd.CommandText = "set transaction"
cmd.Execute
'...
cmd CommandText = "rollback"
cmd Execute
автоматический запуск транзакций - разрешение и запрещение:
Dim en As New ADODB.Connection
en Provider = "LCPI.IBProvider.1"
'auco_commit=true включение автоматических транзакций
'для всех сессий
Call cn.Open(
"data source=localhost:d:\database\employee.gdb;auto_commit=true",
"gamer", "vermut")
Dim cmd As New ADODB.Command
Dim rs As ADODB Recordset
cmd ActiveConnection = cn
cmd.CommandText = "select * from rdb$database"
Sec rs = cmd.Execute 'транзакция запускается неявно
'...
'и Судет завершена при закрытии результирующего множества
rs Close
'альтернативой auto_commit=true является установка
'(после успешного подключения к база данных)
'свойства сессии Session AutoCommit=true.
'В ADODB это одно и то же,
'поскольку на одно подключение - одна сессия
'через это же свойство можно "выключить" глобальное
'разрешение на автоматический
'запуск транзакции, что дальше и демонстрируется
cn Properties("Session AutoCommit") = False
cmd.CommandText = "select * from rdb$database"
Set rs = cmd Execute
'выдаст олибку "Automatic transaction is disabled"
При программировании на C++ принципы взаимодействия с сессией точно такие же. Но в C++ сессия будет отдельным объектом.
В нижеследующем примере на C++ демонстрируется трюк, который часто используется для моделирования принудительного завершения транзакций. Дело в том, что InterBase реализует многоверсионную архитектуру данных (подробнее о многоверсионности данных см. главу "Транзакции Параметры транзакций" (ч 1)) Одной из особенностей такой архитектуры является то, что любые транзакции желательно завершать подтверждением (commit), а не откатом (lollback).
Однако, как правило, транзакцию, в рамках которой выполняется операция чтения данных, не подтверждают, а откатывают. Особенно в случае достаточно длинного участка кода, который генерирует исключения в случае непредвиденных ошибок загрузки информации Поэтому и нужно принудительно завершать транзакции так. как это показано в нижеследующем примере.
try
{
t_db_data_source cn;
_THROto_OLEDB_FAILED(en,attacn("provider=LCPI.IBProvxCter.1,"
"data source=localhost:d:\\database\\employee.gdb;"
"user id=gamer;"
"password=vermut"));
t_db_session session;
// метод create перегружен для разных типов аргумента, поэтому
// можно передавать
// как C++ объект (t_db_data_source), так и IUnknown источника
// данных
_THROW_OLEDB_FAILED(session,create(en)) ,
// запуск транзакции
_THROW_OLEDB_FAILED(session,start_transaction() ) ;
// создаем объект для принудительного завершения транзакции
t_auto_mem_fun_l<HRESULT,bool,t_db_session>
_auto_commit_(session, /*commit_retaining=*/false, &t_db_session::commit);
//... теперь, что бы ни произошло, транзакция
// будет "закоммичена"
throw runtime_error("This is my test error");
}
catcn(const exception& exc)
{
cout<< "error:"<<exc.what()<<endl;
}
По умолчанию библиотека не генерирует исключений, поэтому даже если сбой произошел из-за проблем с самой базой данных, то принудительное завершение транзакции, выполняемое в деструкторе _auto_commit_, не возбудит исключения.
Прокручиваемые курсоры
Gemini ODBC-драйвер поддерживает наравне с однонаправленными (FORWARD-ONLY) курсорами также статические (STATIC) необновляемые курсоры
Работа с BLOB-полями
IBProvider предоставляет поддержку двум типам BLOB-полей: содержащих текст (SUB_TYPE TEXT) и бинарные данные. При этом доступ к BLOB может быть организован как к данным в памяти, так и к объекту-хранилищу. В любом случае провайдер не хранит сами данные BLOB-поля, а каждый раз загружает их по требованию клиента.
ADODB. Чтение BLOB:
Dim cn As New ADODB.Connection
cn.Open "file name=d:\database\employee.ibp"
cn.BeginTrans
Dim cmd As New ADODB.Command
Dim rs As ADODB.Recordset
cmd.ActiveConnection = cn
'JOB_REQUIREMENT - текстовое BLOB-поле
cmd.CommandTexc = "select nob_requirement from job"
Set rs = cmd.Execute
'доступ к BLOB как к данным в памяти
While Not rs.EOF
'печатаем размер BLOB-поля. обращение к ActualSize
'не производит загрузки самих данных
Debug.Print "size:" & CStr(rs(0).ActualSize)
If IsNull(rs(0)) Then
Debug.Print "NULL"
Else
Debug.Print rs(0)
End If
rs.MoveNext
Wend
Debug.Print "******************"
rs.MoveFirst
'чтение порциями по 40 байт
Dim seg As Variant, str As String
Const seg_size = 40
While Not rs.EOF
'пропускаем пустые BLOB-поля
If (Not IsNulKrs(0))) Then
str = ""
Do
seg = rs(0).GetChunk(seg_size)
'когда данных нет - GetChunk возвращает NULL
If IsNull(seg) Then Exit Do
str = str + seg
Debug.Print "get chunk: " & Len(seg) & " bytes"
Loop While True
Debug.Print ">" & CStr(rs(0).ActualSize) & " - " & Len(str)
Debug.Print ">" & str
End If
rs.MoveNext
Wend
cn.CommitTrans
ADODB. Запись BLOB-поля:
Dim cn As New ADODB.Connection
cn.Open "file name=d:\database\employee.ibp"
cn.BeginTrans
Dim cmd As New ADODB.Command
Dim rs As ADODB.Recordset
cmd.ActiveConnection = cn
'JOB_REQUIREMENT - текстовое BLOB-поле
cmd.CommandText = "select * from job"
Set rs = cmd.Execute
Dim upd_cmd As New ADODB.Command
upd_cmd.ActiveConnection = cn
upd_cmd.CommandText = _
"update job set job_requirement=? " & _
"where job_code=? and job_grade=? and " & _
"job_country=?"
upd_cmd.Parameters.Refresh
Dim RowAffected As Long
While Not rs.EOF
If (Not IsNull(rs("job_requirement"))) Then
upd_cmd(0) = UCase(rs("job_requirement"))
upd_cmd(l) = rs("job_code")
upd_cmd(2) = rs("job_grade")
upd_cmd(3) = rs("job_country")
upd_cmd.Execute RowAffected
Debug.Print "affect:" & CStr(RowAffected)
End If
rs.MoveNext
Wend
'отменяем все изменения в базе данных
cn.RollbackTrans
Работа с BLOB-полями через TBProvider на C++ также прозрачна. Хотя можно написать более интересные алгоритмы, например подстановка объекта-хранилища, полученного из результирующего множества, в качестве параметра в команду, привязанную к другой базе данных. Подробности см. в примерах из дистрибутива IBProvider и спецификации OLEDB - "BLOB's and OLE Objects".
Работа с хранимыми процедурами
Хранимые процедуры делятся на две категории - селективные (процедуры- выборки) и исполняемые.
Принцип работы с селективной хранимой процедурой, возвращающей ре- з>льтат своей работы в виде набора строк, очень похож на выполнение обычного SQL-запроса "SELECT..." содержащего параметры.
Вызов селективной процедуры "SUB_TOT_BUDGET"
ADODB
'вспомогательная функция конвертирования VARIANT в строку
'с поддержкой NULL
Function my_cstr(s As Variant) As String
If (IsNull(s)) Then
my_cstr = "NULL"
Else
my_cstr = CStr(s)
End If
End Function
Sub sproc_select()
Dim cn As New ADODB.Connection
cn.Open "file name=d:\database\employee.ibp"
cn.BeginTrans
Dim cmd As New ADODB.Command
cmd.ActiveConnection = cn
cmd.CommandText = "select * from SUB_TOT_BUDGET(?)"
cmd(0) = 100
Dim rs As ADODB.Recordset
Set rs = cmd.Execute
Dim col As Long
While Not rs.EOF
Debug.Print "----------------"
For col = 0 To rs.Fields.Count - 1
Debug.Print CStr(col) & ":" & rs.Fields(col).Name & " - " &
my_cstr(rs(col})
Next col
rs.MoveNext
Wend
cn.CommitTrans
End Sub
Вызов исполняемой ХП отличается от использования селективной ХП в том плане, что применяют SQL-запрос EXECUTE PROCEDURE... и получают результат работы через out-параметры. IBProvider различает только вызов исполняемой ХП, анализируя сигнатуру SQL-запроса. Наряду с SQL-выражением EXECUTE PROCEDURE..., непосредственно поддерживаемого InterBase, в тексте команды можно указывать EXECUTE ... и ЕХЕС ... IBProvider распознает в этих командах попытку вызова исполняемой ХП и автоматически приводит текст SQL-запроса к совместимому с InterBase. Для получения результата работы исполняемой ХП нужно либо самостоятельно описать out-параметры, либо попросить команду сформировать эти описания самостоятельно (ADODB Command Paiameters.Refresh). Основными правилами здесь являются:
В тексте запроса out-параметры не упоминаются
Описание out-параметров после in-параметров.
Не обязательно определять все out-параметры. При работе через ADODB. это могут быть первые out-параметры из всего списка (пропуски не допускаются). При прямой работе с OLE DB-командой можно указывать имена интересующих выходящих параметров ХП, тем самым получать out-параметры в любой комбинации.
Тестовая база данных employee.gdb не содержит готовых примеров исполняемых ХП, поэтому для следующего примера будет определена своя собственная простейшая хранимая процедура.
Определение исполнимой хранимой процедуры:
SQL
create procedure sp_calculate_values(x integer,у integer)
returns(valuel integer,value2 varchar(64))
as
begin
valuel=x+y;
value2=x-y;
end
Вызов и обработка результатов исполнимой хранимой процедуры SP_CALCULATE_VALUES:
ADODB
Sub sproc_exec()
Dim en As New ADODB.Connection
cn.Open "file name=d:\database\employee.ibp"
cn.BeginTrans
Dim cmd As New ADODB.Command
cmd.ActiveConnection = cn
'автоматическое определение параметров
cmd.CommandText = "exec sp_calculate_values(:xl,:x2)"
cmd('x1") =200
cmd("x2") = 100
cmd.Execute
Debug.Print "outl=" & CStr(cmd("valuel"))
Debug.Print "out2=" & CStr(cmd("value2"))
' явное определение параметров
cmd.CommandText = "execute sp_calculate_values(?,?)"
cmd.Parameters.Append cmd.CreateParameter(, adlnteger,
adParamlnput, , 200)
cmd.Parameters.Append cmd.CreateParameter(, adlnteger,
adParamlnput, , 300)
cmd.Parameters.Append cmd.CreateParameter("vl", adlnteger,
adParamOutput)
cmd.Parameters.Append cmd.CreateParameter("v2", adBSTR,
adParamOutput)
cmd.Execute
Debug.Print "vl=" & CStr(cmd("vl"))
Debug.Print "v2=" & CStr(cmd("v2"))
сn.CommitTrans
End Sub
При явном определении параметров можно попробовать испытать мрован к'р на "прочность", задав некорректный порядок перечисления параметров. Например, сначала out-параметры, потом in-параметры.
Работа с InterBase с использованием ODBC
Интерфейсы ODBC основаны на международном стандарте ISO/EC 9075-3:1995 Information technology -- Database languages -- SQL -- Part 3: Call-Level Interface (SQL/CLI). Стандартизация интерфейсов доступа к данным позволяет разрабатывать "горизонтальные" приложения, не зависящие на уровне исходного кода от используемой базы данных.
Термин "ODBC" является сокращением английских слов "Open DataBase Connectivity" и обозначает набор интерфейсов прикладного уровня (API - Application Programming Interface), предоставляющих возможность обращения! к базам данных из приложений. Кроме интерфейсов, ODBC фирмы Microsoft? предоставляет инфраструктуру компонентов доступа к данным.
В этой главе описано использования драйвера Gemini InterBase ODBC для подключения приложений к базам данных InterBase с точки зрения пользователя, а также особенности данного драйвера. Если вы программируете с использованием интерфейса ODBC, вам следует ознакомиться документацию The ODBC Programmer's Reference, входящую в состав Microsoft Developer Network Library (MSDN).
Gemini InterBase ODBC driver соответствует версии 3.51 спецификации Microsoft ODBC, поддерживаются все функции уровней Level 0 (Core), Level 1 и большинство функций Level 2. Высокая степень соответствия стандарту позволяет использовать большинство приложений, поддерживающих интерфейс ODBC, среди которых:
пакет Microsoft Office;
генератор отчетов Seagate Crystal Reports;
приложения, написанные с использованием технологии ADO, в том числе приложения ASP для Microsoft US;
Microsoft SQL Server (использование баз данных InterBase как связанного сервера).
Драйвер существует в двух вариантах - настольном (desktop) и серверном (site). Первый вариант предназначен для офисных приложений, генераторов отчетов и других приложений, используемых на клиенте. Второй вариант рассчитан на использование в составе серверов приложений или Web-серверов.
Работа с массивами
Встроенная поддержка массивов является одним из основных пунктов списка достоинств InterBase как SQL сервера баз данных. И одновременно массивы возглавляют список его невостребованных возможностей. В практике сильная потребность в использовании массивов возникала только один раз. Эта работа была связана с анализом накапливаемой информации, касающейся функционирования торговой организации. Тогда основным препятствием оказалось отсутствие готового решения для работы с массивами InterBase из VBA (MS Office).
Поэтому в IBProvider была реализована поддержка массивов с предоставлением высокоуровневого представления этого несомненно полезного типа данных InterBase.
Распределенные транзакции
Еще одним способом инициирования транзакции является подключение сессии к координатору распределенных транзакций. В общих чертах, координатор представляет собой сессию, транслирующую вызовы собственных интерфейсов управления транзакциией в идентичные групповые вызовы интерфейсов списка дочерних сессий. Как правило, от пользователя не требуется никакого участия для подключения к координатору. За это отвечает окружение, у которого пользовательский код запрашивает подключение к базе данных.
На практике распределенные транзакции обычно используются в СОМ+ (MTS) и Microsoft Distributed Query. В первом случае существует следующая особенность. Когда компоненты просят у своего окружения предоставить им подключение к базе данных, то на каждый такой запрос создается отдельная пара источник данных - сессия. Связано это с описанным выше принципом работы пула подключений. Если компонентов, обрабатывающих пользовательский запрос, очень много и они работают с одной и той же базой данных с идентичными параметрами подключения, то имеет смысл один раз получить подключение и потом предоставлять его компонентам. Иначе в распределенной транзакции будет использовано множество сессий, каждая из которых соответствует процессу или потоку на сервере базы данных, что может привести к резкому снижению производительности сервера СУБД.
Распределенные запросы
Помимо определения самой спецификации OLE DB, Microsoft активно применяет ее в своих разработках, связанных с управлением данными. И одной из самых потрясающих разработок этой категории является Microsoft Distributed Query - программный компонент, входящий в состав MS SQL, позволяющий делать SQL-запросы к нескольким источникам данных с использованием OLE DB-провайдеров. И хотя возможность обращения в одном запросе сразу к нескольким источникам данных так же доступна и в BDE, процессор распределенных SQL-запросов, реализованный Microsoft, несомненно, представляет собой более мощный и более совершенный механизм для этих целей. Далее будут перечислены основные моменты и принципы использования IBProvider в распределенных запросах с применением MS SQL 7.
MS Distributed Query потребовал полной стабильности в описании метаданных. Для этого пришлось реализовать в IBProvider полную поддержку всех типов InterBase и обеспечить совпадение описания метаданных в наборах информационной схемы с описанием колонок результирующих множеств.
Из-за скрупулезной сверки данных результирующих множеств с описанием их метаданных не допускается усечение хвостовых пробелов полей типа CHAR. По умолчанию усечение производится. Чтобы запретить эту операцию, в строке подключения к базе данных нужно указать свойство инициализации источника данных "truncate_char=false".
Процессор распределенных запросов не поддерживает массивы, поэтому не стоит их выбирать в результирующее множество.
Несовпадение диапазона дат MS SQL и InterBase приводит к тому, что нельзя выбирать даты до 1 января 1753 года.
При работе с 3-м диалектом подключения нужно соблюдать регистр символов имени объекта базы данных, независимо от того, квотировано оно или нет Дело в том, что процессор запросов начинает повсеместно использовать двойные кавычки для имен объектов базы данных независимо от того, хотите вы этого или нет. Для подключения 1-го диалекта квотированные имена не используются, поэтому большие и маленькие символы в названии объектов базы данных не различаются.
Регистрация базы данных к процессору распределенных запросов MS SQL 7:
Скопируйте и зарегистрируйте IBProvider на компьютер с сервером баз данных MS SQL 7, процессор запросов которого будет использоваться для выполнения распределенных запросов.
Откройте "SQL Server Enterprise Manager" (консоль управления MS SQL серверами) и подключитесь к интересующему вас серверу.
Перейдите на "SecurityVLinked Servers" дерева элементов конфигурирования сервера. В контекстном меню этого элемента выберите пункт "New Linked Server..."
В открывшемся диалоге нужно указать параметры подключения к базе данных InterBase через IBProvider. Для этого:
В поле "Linked Server" укажите имя, которое будет использоваться в SQL- запросах для идентификации нашей базы данных. Например, "ГВ_ЕМР".
В выпадающем списке "Provider Name" выберите "LCPI OLE DB Provider for InterBase".
Нажмите кнопку Options и установите галочку напротив пункта "Allow InProcess". Закройте это окно, нажав кнопку ОК.
В поле "Data Source" нужно указать путь к базе данных. Например, main:e:\database\employee.gdb.
В поле "Provider string" указываются остальные параметры подключения:
"use id=gamer, password=vermut; free_threading=true; truncate_char=false".
Закройте диалог ввода параметров подключения.
Если все параметры были введены правильно, то, перейдя в дереве на элемент "SecurityYLinked Servers\IB_EMP\Tables", можно посмотреть на список таблиц базы данных "employers.gdb". Если при указании параметров подключения была допущена ошибка, связанный сервер нужно удалить (выбрав в его контекстном меню "Удалить") и повторить операцию регистрации с самого начала.
После того как источник данных был подключен в качестве связанного сервера к MS SQL, можно начать эксперименты с SQL-запросами. Для этого нужно открыть SQL Server Query Analyzer. Это можно сделать из меню "Tools" консоли управления MS SQL-серверами или через меню группы программ для работы с MS SQL, которое доступно через кнопку "Пуск" панели задач Windows.
В поле ввода SQL- запросов Query Analyzer можно вводить как одиночный текст запроса, так и группу запросов, используя точку с запятой в качестве разделителя. При наборе запросов нужно использовать синтаксис MS SQL, а не InterBase, поскольку последний переходит в ранг обычного носителя данных взаимодействие с которым осуществляется через OLE DB-интерфейсы и очень простые SQL-запросы.
Как уже было описано ранее, любая операция с данными базы InterBase, требует наличия активной транзакции. Поэтому самым первым SQL-запросом будет команда запуска транзакции:
MS SQL
BEGIN TRANSACTION;
После этого можно вводить SQL-запросы на выборку данных из источника данных IВ_ЕМР:
MS SQL
SELECT EMP.* FROM IB_EMP...EMPLOYEE EMP WHERE
EMP.JOB_CODE='Eng';
где IВ_ЕМР...EMPLOYEE представляет собой составное имя объекта, которое полностью идентифицирует его расположение в пространстве имен сервера баз данных MS SQL.
Теперь можно зарегистрировать любую другую базу данных InterBase, выполнив действия по аналогии с вышеописанными. В том числе никто не запрещает зарегистрировать несколько раз одну и ту же базу данных под разными псевдонимами, например ПЗ_ЕМР и Ю_ЕМР_1. Конечно, в качестве связанного сервера может использоваться любой другой OLE DB-поставщик данных, который поддерживает необходимую для процессора запросов функциональность.
Пример нахождения записей описания служащих источника данных Ш_ЕМР_1, отсутствующих в базе данных Ш_ЕМР:
MS SQL
SELECT EMP1.*
FROM IB_EMP_1...EMPLOYEE EMP1
WHERE NOT EXISTS(SELECT * FROM IB_EMP... EMPLOYEE EMP
WHERE EMP1.FIRST_NAME=EMP.FIRST_NAME AND
EMP1.LAST_NAME=EMP.LAST_NAME)
Если IB_ЕМР и IB_ЕМР_1 являются псевдонимами одной и той же базы, то результирующее множество этого SQL-запроса должно быть пустым.
При первом обращении к связанному источнику данных его сессия подключается к координатору распределенной транзакции, активизированному командой "BEGIN TRANSACTION" и для дальнейшей работы будет использоваться транзакция, принадлежащая сессии. В предыдущем примере для выполнения запроса к координатору транзакций будет подключено две сессии, каждая из которых содержит активную транзакцию. Поэтому, теоретически, если между запусками этих двух транзакций таблица EMPLOYEER будет изменена, результирующее множество может оказаться непустым. На практике, конечно, с одной базой через два различных псевдонима обычно не работают.
Поскольку в настоящий момент IB Provider (версия 1.6.2) не реализует OLE DB-интерфейсы модификации результирующих множеств, использование процессора запросов для выполнения запросов "INSERT ...", "UPDATE ...", "DELETE..." невозможно.
Разработка приложений баз данных
Немного истории
Обзор возможностей ГВProvider
Использование IB Provider в клиентских приложениях
Компоненты ADODB
Библиотека классов C++ для работы с OLE DB
Инсталляция IB Provider
Инсталляция ADODB-компонентов
Примеры использования ADODB
Использование библиотеки классов
Примеры использования библиотеки классов
Тестовая база данных
Операционная система
Состав компонентов IB Provider
Источник данных
Сессия
Уровни изоляции транзакции
Управление транзакциями
Автоматические транзакции
Управление транзакциями через SQL
Примеры работы с транзакциями
Распределенные транзакции
Использование нескольких сессий в ADODB
Чтение метаданных
Команда
Создание команды
Установка текста команды
Подготовка команды
Подготовка параметров SQL-запроса
Установка свойств результирующего множества
Выполнение команды
Набор строк
Практическое использование IBProvider
Работа с BLOB-полями
Работа с массивами
Особенности реализации поддержки массивов
Работа с хранимыми процедурами
Создание СОМ-объектов для работы с базой данных
Использование скриптов в клиентских приложениях базы данных InterBase
Использование пула подключений к базе данных
Распределенные запросы
Заключение
Создание CGI-приложений под ОС Linux с использованием InterBase API
Пример 1. Запрос без параметров
Пример 2. Запрос с параметрами
Заключение
Работа с InterBase с использованием ODBC
Возможности драйвера Gemini ODBC
Поддержка кодировки UNICODE
Вызов хранимых процедур InterBase с использованием стандартного синтаксиса ODBC
Прокручиваемые курсоры
Асинхронная отмена вызовов для InterBase 6.5
Настройка используемого диалекта InterBase SQL
Настройка параметров транзакций
Установка драйвера и настройка источников данных
Вероятные проблемы и способы их решения
Заключение
Создание клиентов на Java. InterClient и JDBC
Установка InterClient
Communication Diagnostics
Пример приложения на Java
Заключение
Сессия
Основная функция сессии - установить рамки транзакции с заданными параметрами (подробнее о транзакциях см. главу "Транзакции. Параметры транзакций" (ч 1))
Хотя в ADODB понятие сессии совмещено с понятием источника данных, в OLE DB это два различных объекта. Надо полагать, что основная причина такой иерархии объектов ADODB заключается в архитектуре пула подключений, используемого в серверных приложениях Microsoft. Гораздо проще и эффективнее осуществлять балансировку загрузки на уровне отдельных подключений к базе данных, чем на уровне сессий. Как правило, в SQL-серверах через два раздельных подключения можно осуществлять параллельные запросы к базе данных, а через разные сессии одного подключения такая работа будет осуществляться последовательно. Тем не менее InterBase может одновременно обслуживать несколько транзакций в рамках одного подключения и в данном случае выгодно отличается от большинства других SQL-серверов. Поэтому IBProvider поддерживает возможность создания нескольких объектов сессий, принадлежащих одному источнику данных.
Состав компонентов IBProvider
Давайте рассмотрим составные части IBProvider. Компоненты, входящие в состав OLE DB-провайдера, делятся на 4 основные группы:
Источник Оанны\ (Data Source). Компоненты этой группы отвечают за инициализацию и управление подключением к базе данных. Здесь же предоставляется интерфейс для создания сессии.
Сессия (Session). Компонент управления транзакцией. У одного источника данных может быть несколько сессий. Кроме управления транзакциями, сессия обеспечивает создание команд, открытие таблиц и получение информации о метаданных базы данных.
Команда (Command). Компонент для подготовки и выполнения SQL-запросов к базе данных Команда выполняется в рамках конкретной сессии, однако в случае работы в режиме автоматического запуска и подтверждения транзакций (autocommit) выполняется в рамках собственной транзакции. Внутри одной сессии может существовать множество команд.
Набор строк (Ronset). Компонент, реализующий интерфейсы навигации по результатам SQL-запроса (результирующему множеству) и доступа к его содержимому.
Для описания взаимодействующих сторон, будет использоваться следующая терминология:
Клиент - это любой фрагмент системного или прикладного кода, использующий интерфейс OLE DB. Сюда могут входить и сами компоненты доступа. Так же, для обозначения этой стороны взаимодействия, будут использоваться термины пользователь и потребитель.
Компонентов доступа - это любой программный компонент, предоставляющий интерфейс OLE DB. Параллельно будут использоваться OLE DB- поставщик, OLE DB-провайдер, провайдер и IBProvider.
Настройка и определение функциональности компонентов осуществляется через их свойства. Свойства - это атрибуты объекта. Например, свойства набора строк определяют верхний предел объема оперативной памяти для хранения данных, поддержку закладок и потоковую модель. Клиенты устанавливают значения свойств, чтобы потребовать от соответствующего объекта некоторого заданного поведения, и читают свойства, чтобы определить возможности объекта Каждое свойство характеризуется значением, типом, описанием, атрибутом чтения/записи
Свойство идентифицируется GUID (глобальный уникальный идентификатор, представляющий собой структуру длиной 128 бит) и целым числом, представляющим идентификатор свойства. Набор свойств - это совокупность свойств с одним и тем же GUID.
Создание CGI-приложений под ОС Linux с использованием InterBase API
Подавляющее количество CGI-приложений ориентировано на чтение данных и отображение полученных результатов в виде HTML. В общем виде вся работа приложения может быть описана следующей схемой:
Чтение переменных, специфичных для WWW (разбор переменных html-форм и т. д.).
Подключение к базе данных.
Некоторое количество выборок и вставок (возможно, с исполнением хранимых процедур).
Отключение от базы данных.
Отправка данных клиенту.
Следует отметить, что часто пп. 4 и 5 меняются местами, например, при отображении данных в виде HTML-таблиц, построении отчетов и в прочих ситуациях, когда данных, полученных из базы данных, может быть много и хранение их в оперативной памяти вплоть до разрыва соединения нецелесообразно.
Также необходимо помнить, что, как правило, "тяжелые" запросы, которые могут выполняться несколько минут, в CGI-приложениях не используются; в случае употребления таких запросов браузер клиента считает, что произошел сбой соединения и сообщает об истечении времени ожидания.
Еще одной особенностью CGI-приложений является то, что практически всегда известно количество, наименование и тип входных и выходных параметров. Также обычно не возникает необходимости в обработке исключительных ситуаций, таких, как разрыв соединения во время работы с базой данных, так как пользователь, увидев в своем браузере пустой или некорректный результат, обычно ее обновляет, что дает возможность вновь выполнить запрос.
CGI-приложение является по сути прослойкой между Интернетом и базой данных, поэтому особое внимание следует уделять корректной работе с памятью и данными, которые приложение будет получать из Интернента. Самый лучший вариант - считать, что изначально будут посылаться некорректные данные, поэтому придется разработать эффективную защиту от "замусоривания".
При работе на уровне API дополнительный разбор текстовых переменных не производится - они попадают в базу данных в том виде, в каком хранятся в памяти скрипта. Таким образом, можно, например, хранить текст в различных кодировках в полях таблиц с CHARACTER SET NONE. Также не возникает проблем с одинарными или двойными кавычками.
Весь процесс создания CGI- приложения можно условно разделить на две части: сначала в общем виде создается шаблон HTML-документа, который должен получиться в результате работы, а затем необходимо реализовать собственно CGI-скрипт.
На начальном этапе написания приложения достаточно заменить переменные, которые в рабочей версии будут выбираться из присылаемых браузером запросов, на константы. Обычно всю отладочную информацию также выводят в результирующий HTML-документ - это позволяет легко отлаживать приложение. После того как основной алгоритм программы заработает, можно вместо констант обрабатывать непосредственно переменные из HTTP-запросов.
Специфика CGI-приложений предполагает, что в качестве SQL-сервера хорошо проявит себя архитектура SuperServer, которая обеспечивает хорошую производительность на множестве маленьких запросов при относительно небольшом объеме занимаемой памяти.
CGI-приложения можно писать на любом языке программирования - от С до Perl, где есть соответствующие библиотеки для работы с WWW.
Давайте рассмотрим написание CGI-приложения под ОС Linux с использованием языка C/C++, который производит откомпилированный код и избавляет от необходимости распространять приложения в исходных кодах, как в случае Perl или РНР. Все примеры в данной главе написаны на C/C++, однако легко могут быть переписаны под FPC/PERL/PHP.
В комплект поставки InterBase и его клонов входит заголовочный файл ibase.h с описанием функций InterBase API, констант, макросов и т. д., доступных разработчику клиентских приложений InterBase на C/C++. Написание приложений с использованием чистого API может показаться непривычно громоздким из-за высокой детализации кода приложения. Зная работу с базой данных на уровне InterBase API, можно довольно легко написать свою обертку вокруг API- функций или воспользоваться уже существующими (например, IBProvider из предыдущей главы).
Прежде чем перейти к рассмотрению реальных примеров, необходимо ввести следующие понятия:
Параметры запроса - это переменные, которые передаются серверу (входящие) или возвращаются в качестве результата (исходящие). В примерах эти переменные носят соответственно названия isqlda и osqlda.
Большинство IB API- функций возвращают так называемый STATUS_VECTOR - массив целых чисел (long). Анализируя этот массив, можно узнать, произошел ли вызов функции успешно, и если нет-то по какой причине.
В качестве параметров используется особая структура, XSQLDA - extended SQL Descriptor Area. Она позволяет \знать (или передать) всю необходимую информацию о каждом конкретном параметре, а также сами данные в структуре SQLVAR - SQL Variable. В силу изложенного выше при написании CGI- приложений интерес представляют лишь несколько полей из этих структур:
Структура XSQLDA, описывающая параметры запросов
Поле |
Тип (для языка С) |
Описание |
version |
short |
Версия XSQLDA-структуры; должна быть установлена в соответствии с версией используемой клиентской библиотеки. Для текущих версий InterBase это значение соответствует SQDA_VERSION1 |
sqln |
short |
Количество элементов массива sqlvar (иными словами, количество передаваемых и/или получаемых переменных). Это поле должно быть обязательно заполнено для входящих и исходящих параметров до передачи данных запроса серверу |
sqld |
short |
Указывает количество входящих или исходящих параметров. Обычно это поле для исходящих параметров инициализируется библиотекой InterBase. 0 в этом поле означает, что запрос не является выборкой (non-SELECT query) |
Поле |
Тип (для языка С) |
Описание |
|
sqldata |
char* |
Указатель на данные, которые необходимо передать серверу |
|
sqltype |
short |
Информация о типе передаваемых данных. Для полей, допускающих SQL-значение NULL- используется тип, на единицу больший, чем базовый. Например, для типа SQL INTEGER используется значение SQL_LONG, если NULL не допускается, и тип SQLJ.ONG+1, если в значении поля допускается NULL |
|
sqllen |
short |
Размер памяти, занимаемой переменной, на которую указывает sqldata |
|
sqlind |
short * |
Это поле - индикатор того, является ли значение передаваемой переменной NULL (в этом случае это поле должно быть равно единице) или нет (в этом случае значение этого поля 0). Заполнение этого поля является обязательным, если переменная может принимать значение NULL. Таким образом, если вы хотите передать значение NULL серверу и в sqltype указан не базовый тип (например, SQLJ.ONG+1), то инициализировать это поле обязательно; если же указан, например тип SQL_LONG, то это поле можно не инициализировать - сервер проигнорирует его значение. При чтении данных из результата это поле указывает, является ли полученное значение NULL или отличается от него. Анализировать необходимо именно это поле - результат сравнения переменной sqldata с пустым значением может быть абсолютно непредсказуемым |
Подробнее все поля этих структур описаны в [7] и представляют интерес > только при написании действительно сложных приложений или библиотек.
Теперь, когда даны необходимые определения, можно непосредственно по* I знакомиться с методами DSQL-программирования. Их всего 4: I
Нет переменных ни на входе ни на выходе. В этом случае обе структуры * SQLDA (isqlda, osqlda) должны быть инициализированы NULL (или любым пустым указателем в используемом вами языке - например, nil в Паскале) в вызове функций isc_dsql_execute, isc_dsql_execute2 и т. д. Обычно это запросы, которые удаляют записи с жестко заданными свойствами.
Есть переменные как на входе, так и на выходе; в этом случае нужно инициализировать соответствующие структуры.
Нет переменных на выходе, но есть на входе; в этом случае osqlda = NULL, a isqlda требуется инициализировать.
Нет переменных на входе, но есть на выходе; в этом случае isqlda = NULL, a osqlda требуется инициализировать.
Теперь примеры. Для простоты будем работать только с одной таблицей, структура которой описана ниже.
Создание клиентов на Java. InterClient и JDBC
Технология Java является одной из самых бурно развивающихся в мире. Поэтому поддержка Java является необходимым условием существования любого сервера баз данных. Разумеется, и InterBase, и все его клоны поддерживают возможность работы с приложениями на Java.
Для того чтобы работать с базами данных InterBase в Java-приложениях, необходимо задействовать технологию JDBC (часто расшифровывается как Java DataBase Connectivity). Для подключения JDBC к InterBase можно использовать несколько способов.
Во-первых, можно применять мост JDBC-ODBC, который может использоваться в комбинации с многочисленными ODBC-драйверами для InterBase и его клонов - например, Gemini. Но сейчас разработчики на Java стараются не использовать мост ODBC-JDBC, так как это существенно увеличивает зависимость приложения от платформы. Для того чтобы разрабатывать независимые от платформы приложения, существует "сетевой" JDBC-драйвер для InterBase, так называемый InterClient.
InterClient относится к 3-му типу JDBC-драйверов согласно классификации компании Sun. InterClient состоит из двух частей - собственно драйвера, написанного на "чистом" Java, и промежуточного сервера (называемого InterServer), который транслирует вызовы JDBC-команд в команды InterBase. Данный способ является наиболее безопасным и гибким для работы в Интернете. Именно InterClient мы будем использовать в качестве основы для примера, в котором продемонстрируем разработку клиента InterBase на Java.
Все приведенные ниже примеры приводятся в предположении, что на рабочем компьютере, где будет установлен InterClient, предварительно установлен пакет JDK1.3 или JDK1.4. Работа InterClient 2.x с более ранними версиями JDK может вызвать некоторые проблемы и иногда необходимость использовать более раннюю версию InterClient 1.6.
Создание команды
Как уже было отмечено ранее, объект команды создается объектом сессии.
С помощью отдельной сессии можно создать много команд
По умолчанию команда пользуется транзакцией породившей ее сессии Если же сессия не содержит активной транзакции и разрешен режим автоматического подтверждения/отката, то команда будет выполняться в своей собственной автоматической транзакции, не зависящей от сессии.
Примеры создания команд.
ADODB
Dim сn As New ADODB.Connection
сn.Open "file name=d:\database\employee.ibp"
Dim cmd As New ADODB.Command cmd.ActiveConnection = сn
C++
t_db_data_source сn;
_THROW_OLEDB_FAILED(cn, attach(
"file name=d:\\database\\employee.ibp"));
t_db_session session;
_THROW_OLEDB_FAILED(session,create(en));
t_db_command cmdl,cmd2;
//Создаем команду традиционным способом,
//используя объект C++ сессии
_THROW_OLEDB_FAILED(cmdl,create(session));
//Команду также можно создать, обладая
//только указателем на lUnknown OLE DB-сессии.
//Это более подходящий способ для СОМ-объектов
IUnknownPtr spSession(session session_obj());
_THTOW_OLEDB_FAILED(cmd2,create(spSession));
Создание СОМ-объектов для работы с базой данных
Самым эффективным применением технологии OLEDB является создание и использование специализированных компонентов для работы с базой данных. Этот подход изначально начал применяться для серверов приложений (application servers). Однако ничто не мешает реализовывать re же самые принципы при создании обычного приложения базы данных. В этом случае, помимо обычных преимуществ компонентной технологии, исчезают типичные проблемы, связанные с передачей и разделением ресурсов сервера баз данных между несколькими модулями клиентского приложения. Для малосвязанных модулей достаточно разделять одно подключение, в случае использования сервисных компонентов может потребоваться совместная работа в контексте одной транзакции. Поскольку эти ресурсы представлены в виде СОМ-объектов, то для корректной работы требуется только правильно управлять их счетчиком ссылок. Однако для опытного программиста, использующего СОМ-технологии в реальной работе, это не проблема.
Исходя из накопленного опыта создания таких компонентов и их использования из программ, написанных на C++, VBA и VBScript, можно порекомендовать следующую структуру СОМ-объектов:
Дуальный (dual) интерфейс автоматизации, через который выполняется основное взаимодействие с объектом. Этот же интерфейс предоставляет свойство Connection для того, чтобы устанавливать и получать подключение, используя ADODB-компоненты. Как уже было сказано ранее, ADODB.Connection одновременно является и источником данных и сессией.
Обычный интерфейс (наследующий ILJnknown) для инициализации компонента посредством указателя на ITJnknown сессии.
Внутренняя работа с базой данных осуществляется через низкоуровневые интерфейсы OLEDB посредством классов C++. Таким образом, компонент изолируется от ADODB и обеспечивает более производительное функционирование собственных алгоритмов.
Принцип наиболее эффективной работы также не очень сложный - компонент должен свести к минимуму число создающихся и подготавливающихся команд. Так же имеет смысл загрузить в память содержимое таблиц, небольших по размеру и хранящих фиксированные данные. В основном под эту категорию попадают таблицы справочников. Тогда можно исключить из запросов все возможные обращения для выборки этой информации, что в конечном итоге, уменьшает нагрузку на сервер базы данных.
В качестве поддержки совместного использования ADODB и OLEDB в одном проекте инструментальная библиотека представляет две утилиты:
construct_adodb_connection - создание ADODB подключения на базе существующего источника данных и сессии;
get_adodb_session - получение OLEDB-сессии, обслуживаемой ADODB-подключением.
Несмотря на открывающиеся в связи с использованием IBProvider перспективы, связанные с дроблением ваших приложений для InterBase на модули, главное не переусердствовать. Не стоит делать компоненты, предназначенные для коллекций, с собственным механизмом чтения и записи. Помните, что любой использующий команды объект делает как минимум 4-5 обращений к серверу:
Создание
Подготовка.
Выполнение.
Выборка результата.
Разрушение
Поэтому для групповых операций больше всего приемлем классический подход, когда реализуется групповая загрузка и запись, отделенная от самих данных.
Еще одной хорошей идеей является создание в приложении обычных классов с реализацией той логики, которая скорее всего не потребуется вне границ вашего приложения. Согласитесь, что написание класса и СОМ-компонента требует несравнимых усилий. Кроме того, не забывайте, что создание СОМ-объектов производиться через СОМ-инфраструктуру, поэтому накладные расходы распространяются и на время выполнения приложения. Поэтому обычные классы все равно остаются основным "тактическим средством" больших приложений, разработанных в объектно-ориентированном стиле
Ниже приводиться пример СОМ-объекта, который подключается к сессии и используется для того, чтобы получить значение генератора (см. главу "Таблицы Первичные ключи и генераторы" (ч. 1)). Здесь мы ограничимся лишь IDL-описанием двух интерфейсов и реализацией их методов. Помимо этого, используются возможности инструментальной библиотеки из дистрибутива IBProvider I.6.2. В реальном случае этот код, конечно же, лучше оформить в виде обычного класса. Тогда можно исключить одновременную поддержку ADODB и OLEDB. Кроме того, в данном примере не оптимизирована работа метода GenID для случая повторного использования подготовленной команды, для случая многократного вызова метода с идентичными аргументами.
IDL-описание интерфейсов:
////////////////////////////////////////////////////////////
//interface IDBSessionObject
// уcтановка/получение рабочей OLEDB-сессии объекта
[
object,
uuid(98E5AB40-333E-llD6-AC8F-OOAOC907DB93),
pointer_default(unique)
]
interface IDBSessionObject:IUnknown
{
HRESULT SetDBSession([in] lUnknown* pSession);
HRESULT GetDBSession([out]lUnknown** ppSession);
};//interface IDBSessionObject
/////////////////////////////////////////////
//interface IDBGenID
// интерфейс получения значения генератора
[
object,
uuid(98E5AB41-333E-llD6-AC8F-OOAOC907DB93),
dual,
oleautomation,
pointer_default(unique),
nonextensible
]
interface IDBGenID:IDispatch
{
[propput]
HRESULT Connection([in]IDispatch* pConnection);
[propget]
HRESULT Connection([out,retval]IDispatch** ppConnection);
HRESULT Convert([in]BSTR GenName,
[in]LONG Count,
[out,retval]LONG* pResult);
};//interface IDBGenID
Реализация методов установки сессии:
//m_spADODBConnection - член класса,
// содержащий указатель на ADODB-подключение
//m_spSession - член класса,
// содержащий указатель на используемую OLEDB-сессию
//m_Cmd - команда (t_db_command) получения значения генератора
//IDBSessionObject interface ------------------------------
HRESULT _stdcall TDBGenID::SetDBSession(lUnknown* pSession)
{
::SetErrorlnfo(0,NULL);
HRESULT hr=S_OK;
_OLE_TRY_
{
//освобождаем ADODB connection
m_spADODBConnection.Release();
m_spSession=pSession;
//инициализируем объекты взаимодействия с базой данных
m_Cmd destroy();
}
_OLE_DIS P_CATCHES_
return hr;
}//SetDBSession
HRESULT _stdcall TDBGenID::GetDBSession(lUnknown** ppSession)
{
::SetErrorlnfo(0,NULL);
return m_spSession.CopyTo(ppSession);
}//GetDBSession
//IOC2_ObjectLoader interface -----------
HRESULT _stdcall TDBGenID::put_Connection
(IDispatch* pConnection)
{
::SetErrorInf0(0,NULL);
HRESULT hr=NOERROR;
_OLE_TRY_
{
IDispatchPtr spConnection(pConnection) ; //блокируем в памяти
//освобождаем текущие подключения
SetDBSession(NULL);
if(pConnection) {
IUnknownPtr spDBSession;
get_adodb_session(pConnection,spDBSession); //throw
if(SUCCEEDED(hr=SetDBSession(spDBSession)))
m_spADODBConnection=pConnection;
}//pConnection!=NULL
}
_OLE_DISP_CATCHES_
return hr;
}//put_Connection
HRESULT _stdcall TDBGenID::get_Connection
(IDispatch** ppConnection)
{
::SetErrorlnfо(0,NULL);
if(ppConnection==NULL)
return E_POINTER;
*ppConnection=NULL;
HRESULT hr=S_OK;
_OLE_TRY_
{
if(!m_spADODBConnection && (bool)m_spSession)
{
IGetDataSourcePtr spGetDataSource(m_spSession);
if(i spGetDataSource)
t_ole_error::throw_error
("query IGetDataSource interface",spGetDataSource.m_hr);
IUnknownPtr spDataSource;
if(FAILED(hr=get_data_source(spGetDataSource,spDataSource)))
t_ole_error::throw_error("Получение источника данных",hr);
IDBPropertiesPtr spDBProperties(spDataSource);
if(!spDBProperties)
t_ole_error::throw_error
("query IDBProperties interface",spDBProperties.m_hr);
construct_adodb_connection(spDBProperties,m_spSession,
m_spADODBConnection);//throw
}//if - создание ADODB-объекта
hr=m_spADODBConnection.CopyTo(ppConnection);
}
_OLE_DISP_CATCHES_
return hr;
}//get_Connection
Реализация метода получения значения генератора:
HRESULT _stdcall TDBGenID::GenID(BSTR GenName,LONG Count,
LONG* pResult)
{
::SetErrorlnfо(0,NULL);
if(pResult==NULL)
return E_POINTER;
HRESULT hr=S_OK;
_OLE_TRY_
{
if(!m_spSession)
throw runtime_error("Объект неинициализирован");
if(!m_Cmd.is_created())
_THROW_OLEDB_FAILED(m_Cmd,create(m_spSession));
structure::str_formatter stmt
("select gen_id(%l,%2) from rdb$database");
t_db_row row(1);
_THROW_OLEDB_FAILED (m_Cmd, prepare ( stmt«GenName«Count, &row) )
_THROW_OLEDB_FAILED(m_Cmd,execute(NULL));
if(m_Cmd.fetch(row)==S_OK)
*pResult=row[0].as_integer;
else
{
//проверим причину сбоя получения данных
_THROW_OLEDB_FAILED(m_Cmd,m_last_result)
throw runtime_error("Получено пустое множество");
}
}
_OLE_DIS P_CATCHES_
return hr;
}//GenID
Тестовая база данных
Для тестирования использовался Firebird 1.0 и база данных employee.gdb, входящая в дистрибутив этого сервера баз данных. На этом сервере был создан пользователь "gamer" с паролем "vermin"
Для сокращения объема кода, проводящего подключение к базе данных, использовался текстовый файл employee.ibp, содержащий следующую информацию:
data source=c266:d:\database\employee.gdb;
user=gamer;
password=vermut;
auto_cornmit = true ;
ctype=win!251;
Управление транзакциями
Поскольку корректное использование транзакций является важным условием разработки эффективных приложений баз данных, то IBProvider по умолчанию требует явного участия пользователя в процессе управления транзакциями.
Причинами отказа от автоматического запуска и завершения транзакции являются относительно высокие затраты ресурсов на эту операцию и желание контролировать все действия с базой данных.
Надо сказать, что последнее обстоятельство является наиболее важным, поскольку при разработке большой программной системы, состоящей и множества независимых модулей, явный контроль операций с базой данных позволяет избегать многих ошибок.
В то же время иногда автоматический запуски завершение транзакции могут оказаться очень удобными для решения небольших и несложных задач.
Помимо автоматических транзакций для работы с данными в IBProvider определена еще одна категория внутренних транзакций (inner transaction), используемых для чтения метаданных базы данных По умолчанию внутренних транзакций разрешены, поскольку CASE-дизайнеры и системы построения отчетов для получения метаданных явно не управляют транзакциями.
Управление транзакциями через SQL
Помимо управления транзакцией через OLE DB-интерфейсы сессии, IBProvider осуществляет специальную поддержку SQL-запросов вида: "SET TRANSACTION...", "COMMIT" и "ROLLBACK". В этом случае будет использоваться транзакция, принадлежащая сессии. Управление транзакциями через SQL-запросы позволяет указывать специфические параметры контекста транзакции, которые не стандартизированы в OLE DB и которые возможно использовать благодаря особенностям InterBase API.
Уровни изоляции транзакции
В IBProvider реализована поддержка трех уровней изоляции транзакций: READ COMMITTED, REPEATABLE READ (SNAPSHOT), SERIALIZABLE (SNAPSHOT TABLE STABILITY). При работе через ADODB след>ет обратить внимание на значение свойства ADODB.Connection.IsolationLevel. Библиотека классов C++ по умолчанию использует режим REPEATABLE READ. Подробнее об у ровнях изоляции транзакций вы можете узнать в главе "Транзакции. Параметры транзакций" (ч. 1).
Установка драйвера и настройка источников данных
Дистрибутив драйвера состоит из одного исполнимого файла с именем ibgem_21_desk.exe (для настольной редакции драйвера версии 2.1). Чтобы установить драйвер, необходимо запустить этот файл.
Существует два способа создания соединений в ODBC - с использованием DSN (Data Source Name - имя источника данных) и без DSN (так называемые DSN-less-соединения.
В первом случае все параметры соединения (такие, как имя базы данных, сервер и сетевой протокол) конфигурируются пользователем и хранятся в отдельном ключе системного реестра для каждого DSN. При соединении приложение указывает имя DSN, а также, возможно, имя пользователя и пароль для аутентификации. Источники данных бывают системные (System DSN), пользовательские (User DSN), а также файловые (File DSN). Системные источники данных доступны всем приложениям, работающим на данном компьютере, независимо от учетной записи, под которой они запущены. Пользовательские источники данных определены для каждой учетной записи. И наконец, файловые DSN хранятся в файлах, их может использовать любое приложение, в том числе выполняемое на других компьютерах при наличии доступа к соответствующему файлу DSN.
Примерный вид диалога настройки DSN приведен на рисунке 3 4.
Рис 3.4. Диалог настройки источника данных
В случае использования DSN-less-соединения приложение должно передать все параметры соединения вместе с именем драйвера в строке соединения.
Ниже перечислены все опции настройки источника данных параллельно для настройки DSN и при задании в строке соединения. Параметр Options содержит битовую маску, каждый бит которой соответствует установке некоторого флага в диалоге DSN.
Табл 3.1. Параметры настройки источника данных
|
Поле диалога настройки DSN |
Параметр строки соединения |
Значение по умолчанию |
Описание | ||||
|
--- |
Driver |
--- |
Имя ODBC-драйвера. Используется только для DSN-less-соединений. Если имя драйвера содержит пробелы, необходимо заключить его в фигурные скобки. Для Gemini ODBC-драйвера нужно задавать так: DRIVER={Gemini InterBase ODBC Driver 2 0); | ||||
|
Data Source Name |
DSN |
--- |
Имя источника данных Используется для соединений с применением DSN | ||||
|
Protocol |
Protocol |
1 |
Протокол, используемый для соединения. Задается числовым кодом, возможные значения которого таковы: 1 - Local; 2 -TCP; 3 - NetBEUI (Named Pipes); 4-SPX | ||||
|
Server |
Server |
" " |
Имя серверного компьютера для удаленных протоколов. Пустое имя соответствует локальному серверу | ||||
|
Database File |
Database |
--- |
Имя файла базы данных. Обязательный параметр | ||||
|
Default User Name |
UID |
" " |
Имя пользователя | ||||
|
Password |
PWD |
" " |
Пароль пользователя. Не рекомендуется задавать пароль в настройках DSN, поскольку он хранится в реестре в открытом виде | ||||
|
Role |
Role |
" " |
Имя роли SQL, используемое при подключении к базе данных | ||||
|
Character Set |
Charset |
" " |
Название кодировки пользовательского подключения | ||||
|
InterBase Version |
Version |
6 |
Номер версии сервера, в котором была создана база данных | ||||
|
Dialect |
Dialect |
3 |
InterBase SQL-диалект | ||||
|
Soft Commits | 256 (0x100) |
Использовать COMMIT RETAINING. Соответствует биту 8 (маска 256) поля Options. Внимание! Установленному биту соответствует "жесткий" COMMIT | |||||
|
Close Cursors on Commit |
Закрывать курсоры при завершении транзакции. Соответствует биту 0 (маска 1 ) поля Options | ||||||
|
Case- insensitive identifiers |
Отключает поддержку идентификаторов, зависящих от регистра в диалекте 3 Соответствует биту 2 (маска 4) поля Options | ||||||
|
Report Owners as Schemes |
Options |
Выдавать имя владельца объектов при описании структуры базы данных. Для большинства приложений приводит к проблемам. Соответствует биту 1 (маска 2) поля Options | |||||
|
No Record Versions |
Запрещает чтение старых версий записей в уровне изоляции READ COMMITTED Соответствует бит 4 (маска 16) поля Options | ||||||
|
No Wait On Locks |
Запрещает ожидание транзакции в случае конфликтов обновлений. Соответствует биту 5 (маска 32) поля Options | ||||||
|
Read Only |
Readonly |
0 |
Устанавливает режим обращения "только чтение" к базе данных |
Рассмотрим несколько примеров задания строки соединения из приложения В качестве приложения возьмем скрипт на языке VB Script. Для запуска теста вам необходимо выполнить скрипт с помощью команды cscript имя-файла.vbs.
DSN-less соединение
В этом примере все параметры соединения устанавливаются программно
dim conn
set conn = CreateObject("ADODB.Connection")
conn . open "Dnver= {Gemini InterBase ODBC Driver
2.0);Protocol=2;Server=localhost;Database=z:\borland\InterBase\
examples\employee.gdb;Dialect=3;UID=sysdba;PWD=masterkey"
Соединение с использованием DSN
В этом примере вам необходимо создать источник данных с именем Employee. В программе передаются только имя пользователя и пароль.
dim conn
set conn = CreateOb3ect("ADODB.Connection")
conn.open "DSN=Employee;UID=sysdba;PWD=masterkey"
Установка InterClient
В настоящий момент самой последней является версия InterClient 2.01. Надо отметить, что InterClient является бесплатным и его можно свободно скачать с сайта http://firebird.sourceforge.net/ или с с.айта поддержки данной книги www.InterBase-world.com. Существуют версии InterClient как для Windows 95/98/ Me/NT 4/2000, так и для Linux. Мы рассмотрим установку и работу под Windows, хотя и установка под Linux ненамного сложнее и вся установка сводится к распаковке tar-архива и запуску инсталляционных скриптов.
В скачанном архиве InterClient для Windows находится программа- установщик, которая производит все необходимые действия по установке нужных файлов и модификации реестра.
InterClient состоит из двух основных частей - драйвера для JDBC, находящегося в файле interclient.jar, и транслятора вызовов JDBC в вызовы InterBase - программы InterServer. Для того чтобы можно было из программ на Java обращаться к серверу InterBase, функционирующему на каком-либо компьютере, необходимо, чтобы на этом же компьютере был запущен InterServer.
В ОС Windows 95/98/Me InterServer может функционировать только в режиме приложения, а в NT/2000 - и в режиме сервиса. В составе установочного пакета InterClient поставляется программа для конфигурирования InterServer, с помощью которой можно настроить параметры запуска InterServer и управлять его состоянием.
Далее, после того как отработала программа-установщик InterClient, нам необходимо сделать следующее.
Во-первых, проверить, записалась ли в файл services строка
interserver 3060/tcp # InterBase InterServer
Этот файл находится в каталоге c:\windows\services в ОС Windows 95/98/Me и в каталоге c:\winnt\system32\drivers\etc\services в NT/2000. Данная запись необходима для того, чтобы к InterServer можно было обратиться по сети.
Во-вторых, необходимо запустить программу для конфигурирования InterServer - isconfig.exe и убедиться, что InterServer функционирует так, как вам требуется.
И в-третьих, необходимо добавить путь к файлу interclient.jar в JAVA CLASSPATH. Например, если установка InterClient была произведена в каталог C:\Program Files\Firebird\InterClient, то в JAVA CLASSPATH необходимо добавить C:\Program Files\Firebird\InterClient\interclient.jar.
На этом установка InterClient завершена и мы можем приступить к разработке приложения на Java. Однако сначала рассмотрим некоторые типичные проблемы и способы их разрешения, которые могут возникнуть в процессе работы.
Установка свойств результирующего множества
Перед выполнением команды, создающей набор рядов, можно задать различные свойства этого набора. Например, поддерживаемые интерфейсы, возможности позиционирования и верхняя граница объема оперативной памяти, используемой для хранения данных. Эти свойства задаются на уровне объекта команды и будут скопированы в набор свойств объекта результирующего множества.
Пример настройки свойств набора результирующего множества команды:
ADODB
'разрешить поддержку закладок для
'произвольного позиционирования в наборе
cmd.Properties("Use bookmarks") = True
'Использовать 1 MB памяти для кеширования рядов
cmd.Properties("Memory Usage") = 1024
C++
t_db_obj_props cmd_props(false);
_THROW_OLEDB_FAILED(cmd_props,
attach_command(cmd2.command_obj()));
_THROW_OLEDB_FAILED(cmd_props,set("Use Bookmarks",true));
_THROW_OLEDB_FAILED(cmd_props,set("Memory Usage",1024));
Установка текста команды
Если команда только что создана, она еще не содержит текста. Поэтому текст SQL-запроса нужно установить
Пример установки текста запроса:
ADODB
cmd.Command.Text = "select x
from job"
При этом IBPrivider сбрасывает флаг подготовленности команды и очищает список параметров Как это ни странно, здесь могут происходить ошибки:
Команда обнаружит смешанное использование параметров - именованных " param" и неименованных, обозначаемых вопросительным знаком ('"?")
Сбой преобразования SQL-запросов из ODBC-диалекта в вид, пригодный для передачи на сервер
Все действия, связанные с установкой текста команды, осуществляются локально, т. е. обращение к серверу базы данных не производится.
Вероятные проблемы и способы их решения
Сообщение "Client library cannot be loaded" при попытке установить соединение. - На компьютере не установлен клиент InterBase/Firebird. Проверьте наличие библиотеки GDS32.DLL в системном каталоге Windows
Ошибка "Optional feature not supported". - В строке соединения и настройке DSN имя сервера указано дважды, например, в поле Server и в поле Database. При этом на сервер приходит строка соединения следующего вида: Localhost:localhost./path_to_database/db.gdb. Проверьте настройки DSN и строку коннекта
Ошибка "Una\ tillable database" при соединении из службы N1, например US или MS OLAP Sendees. - Возможная причина - источник данных настроен на использование локального протокола. Локальный протокол InterBase/Firebird не поддерживает соединения из служб Windows NT/2000. Используйте протокол TCP или Named Pipes с пустым именем сервера.
При установке на "чистую" Windows NT 4.0 имя DSN в ODBC Data Source отображается неправильно. - На компьютере не установлен ODBC Driver Manager версии 3.5 или выше. Установите обновление MDAC, которое можно загрузить с Web-сайта Microsoft.
При записи пустой строки в связанную таблицу Microsoft Access выдается ошибка "You tried to assign tlie NULL variable to the variable that is not a Vanant data type". - К сожалению, Microsoft Access не допускает хранения пустых строк в связанной таблице. Пустая строка автоматически преобразуются в NULL; если при этом поле таблицы объявлено как NOT NULL, возникает данная ошибка.
Невозможно обновить связанную таблицу в Microsoft Access, содержащую вычисляемые поля. - Клиентская библиотека InterBase не содержит средств для определения того, какие из полей результата выборки являются обновляемыми. При обновлении любого поля таблицы Microsoft Access выполняет команду обновления всех полей, включая вычисляемые, что приводит к ошибочной ситуации.
Выполнение команды
Вызов операции execute является последним этапом выполнения SQL-запроса к базе данных, в ко юром )частв)е] объект команды Первоначальное и почти полное описание всех этапов выполнения этой операции заняло больше двух листов, забитых сухой технической информацией, дочитывая которую забываешь, с чего все началось. Шутка. Поэтому ограничимся коротким списком задач, выполняемых командой при вызове операции выполнения SQL-запроса.
Проверка параметров. Количество разнообразных ошибок, вылавливаемых на этом этапе, превышает полтора десятка.
Получение транзакции, в рамках которой будет выполняться SQL-запрос. Это может быть собственная активная транзакция родительской сессии или отдельная автоматически завершаемая транзакция (если таковые разрешены).
Создание нового дескриптора низкоуровневого запроса, если текущий, принадлежащий команде, обслуживает набор строк, сформированных предыдущим вызовом операции execute. Такая ситуация может произойти при многократных вызовах execute для одного и того же SQL-запроса.
Подготовка команды, если эта операция еще не была выполнена.
Вызов InterBase API для выполнения запроса.
Возвращение результата (если таковые создаются) через OUT-параметры или объект набора строк (rowset)
При выполнении SQL-запросов модификации данных (INSERT, UPDATE, DELETE) можно узнать число строк, затронутых запросом:
ADODB
cmd.CommandText =
"insert into project (proj_id,proj_name,proj_desc) " & _
"values(?,?,?)"
cmd(0) = 1001
cmd(l) = "test 1001"
cmd(2) = "test 1001"
Dim RowAffected As Long 'кол-ве вставленных строк
cmd.Execute RowAffected
Debug.Print "insert " & CStr(RowAffected) & " rows"
Вызов хранимых процедур InterBase с использованием стандартного синтаксиса ODBC
Как известно, InterBase использует два типа хранимых процедур" так называемые selectable-процедуры и executeable-процедуры; при этом процедуры разного типа отличаются способом вызова в SQL. В отличие от других ODBC- драйверов, Gemini ODBC отслеживает тип процедуры и всегда формирует корректный SQL-вызов без дополнительных пользовательских настроек.
Несмотря на устрашающий размер примеров,
Несмотря на устрашающий размер примеров, в работе с базами данных InterBase и его клонов на уровне API нет ничего слишком сложного, скорее там много монотонной работы по кодированию. Однако приложения с использованием InterBase API являются при правильном написании наиболее производительными.
Поэтому изучайте примеры в этой книге- и создавайте on-line-игры, www-магазины и порталы!
Если вы применяете приложения, рассчитанные на использование источников данных ODBC, такие, как настольные офисные системы, языки программирования или даже серверы баз данных, использование ODBC, вероятно, будет самым простым и надежным способом интегрировать их с базами данных InterBase/Firebird. Для разработчиков ODBC предоставляет возможность проектировать приложения, способные однообразно работать с InterBase/Firebird наравне с другими серверами СУБД в качестве источника данных и при необходимости легко переносить приложения между разными типами серверов
В этой главе описан драйвер Gemini ODBC, его настройка и использование для доступа к базам данных InterBase. Свежую информацию о драйвере, сообщения о выпуске новых версий вы всегда сможете найти на Web-сайте поддержки данной книги www.InterBase-world.com, а также на сайте Gemini www.ibdatabase.com.
В этой главе описан JDBC-драйвер для InterBase и его клонов - InterClient и приведен небольшой пример приложения на Java, подключающегося к базе данных InterBase и выполняющего простейший запрос. Основная идея этой главы в том, чтобы показать, насколько легко связать InterBase и Java.
