Администрирование и архитектура InterBase
Установка InterBase - взгляд изнутри
InterBase как встраиваемая СУБД
Установка InterBase на платформе Windows
Установка клиента под Windows
Копирование файлов
Совместное использование gds32.dll, InterBase.msg и mscvrt.dll
Ключи в реестре для клиента InterBase
Регистрация TCP/IP-сервиса при клиентской установке
Установка InterBase-сервера на Windows
Копирование файлов сервера
Совместное использование файлов
Ключи в реестре для сервера InterBase
Регистрация TCP/IP-сервиса
Запуск InterBase-сервера
Расширенная установка InterBase-сервера
Пример установочного скрипта
Резервное копирование базы данных и восстановление из резервной копии
Резервное копирование базы данных InterBase
Инструмент командной строки gbak
Права для выполнения резервного копирования
Резервное копирование многофайловых баз данных
Резервное копирование при работе InterBase в режиме 24x7
Другие инструменты для осуществления резервного копирования
Восстановление из резервной копии
Восстановление с использованием инструмента gbak
Восстановление из резервных копий многофайловых баз данных
Владелец базы данных
Заключение
Миграция
Почему необходима миграция
Сущность процесса миграции
Миграция между различными версиями InterBase
Карта миграции
Прямая миграция
Сохранение информации о пользователях при миграции
Восстановление из резервной копии на системе-приемнике
Особый процесс, или обратная миграция
Совместимость клиентов и серверов различных версий
Перевод базы данных InterBase 6.x на 3-й диалект
Двойные кавычки
Ключевые слова
Типы данных для работы с датой и временем
Большие целые типы
Пошаговые инструкции для перехода на 3-й диалект
Клиенты 3-го диалекта
Заключение
Починка базы данных
Обзор основных причин повреждения базы данных
Отключение питания
Forced writes - палка о двух концах
Повреждения жесткого диска
Ошибки проектирования базы данных
Профилактика повреждений баз данных InterBase
Инструмент командной строки gfix
Восстановление поврежденной базы данных
Спасение данных из поврежденной базы данных
Восстановление "безнадежных" баз данных. InterBase Surgeon
Статистика в InterBase
Статистика базы данных InterBase
Получение статистики
Информация заголовочной страницы (Database header)
Flags
Checksum
Generation
Page size
ODS version
Oldest transaction
Oldest active и Oldest snapshot
Next transaction
Bumped transaction
Sequence number
Next attachment ID
Implementation ID
Shadow count
Page buffers
Next header page
Database dialect
Creation date
Attributes
Shared Cache file
Sweep interval
Информация страниц данных
Статистика страниц индексов
Статистика InterBase-сервера
Статистика по блокировкам
Заключение
Оптимизация работы InterBase
Выбор аппаратного обеспечения для InterBase
Сервер для InterBase
Сетевое оборудование
Рабочие станции
Основные "рычаги" управления производительностью
Кеш базы данных
Forced Writes
Sweep Interval
Размер страницы базы данных
Заключение
Безопасность в InterBase: пользователи, роли и права
Особенности системы защиты данных в InterBase
Разрушаем легенду
Система безопасности InterBase
Пользователи
Роли
Права
.Раздача прав
Организация пользователей в группы с помощью ролей
Аннулирование прав
Как правильно раздавать и аннулировать права
Передача прав
Особенности InterBase 6.5
Общие рекомендации по безопасности
Что такое "архитектура сервера СУБД"?
Состав модулей InterBase
InterBase Super Server для Windows
Кататог BIN в SuperServer
Минимальный состав сервера InterBase SuperServer
InterBase Classic Server под Linux
Каталог BIN в InterBase Classic Server для Linux
Заключение
Classic и SuperServer
Classic
SuperServer
Classic vs SuperServer
Рекомендации по выбору архитектуры: Classic или SuperServer?
Структура базы данных InterBase
Физическая структура базы данных
Зачем изучать физическую структуру базы данных?
Файлы базы данных InterBase
IBSurgeon - проводник по базе данных InterBase
Файлы *.GDB изнутри
Типы страниц и их использование
Понятие об ODS
Мост между физической и логической структурой базы данных
Логическая структура базы данных InterBase
BLR
Иерархия объектов в InterBase
Заключение
Аннулирование прав
Совершенно очевидно, что поскольку права могут быть выданы, то их можно и отобрать. Для этого существует команда REVOKE. В принципе она представляет собой копию GRANT, только с обратным действием. Формат команды REVOKE для различных объектов базы данных похож на GRANT. Например, чтобы отобрать право чтения таблицы table_example у пользователя TESTUSER, достаточно написать;
REVOKE Select ON Table_example FROM testuser;
Точно так же, как и в GRANT, в REVOKE можно перечислять пользователей и права через запят\ю, применять "псевдонимы" ALL для удаления все\ прав (вне зависимости от того, есть они или нет) и PUBLIC для аннулирования прав сразу > всех пользователей. С помощью REVOKE можно также лишить пользователя назначенной ему роли или аннулировать какие-то права у самой роли. Совершенно очевиден также тот факт, что невозможно как-то ограничить или расширить права пользователя SYSDBA. Если бы это было возможно, то в системе защиты InterBase содержалось бы явное противоречие: пользователь SYSDBA мог бы отобрать права на раздачу прав сам у себя, соответственно без права их восстановить! Таким образом, следует помнить, что пользователь SYSDBA всегда обладает всеми возможными правами.
Не будем утомлять читателя демонстрацией примеров употребление всех возможных применений REVOKE.Теперь мы перейдем к значительно более важному вопросу - к идеологии применения прав.
Attributes
Атрибуты базы данных. Могут иметь следующие значения: force write, no_reserve и shutdown. Очевидно, что значения этих атрибутов соответствуют флагам, хранящимся в параметре Flags.
Далее идет информация, озаглавленная Variable header data (переменные данные заголовочной страницы):
BLR
BLR - это специальный язык, используемый в качестве промежуточного звена между SQL-кодом, который пишет программист, и машинным кодом, который "воспринимает" сервер. Никто не пишет непосредственно на BLR - это было бы весьма затруднительно, так как для максимального быстродействия в этом языке используется так называемая обратная польская запись. Вот маленький пример: blr_begin,
bir_assignment,
blr_field, 0, 7, 'D1 , 'А', "I" , 'Е1 , 'I', 'Z', 'М1 ,
blr_variable, 1,0,
blr_assignment,
blr_field, 0, 4, 'R1,'A1,'Т','E',
blr_variable, 0,0, blr_block,
BLR для ваших запросов, процедур, триггеров и других триггеров формируется с помощью специального препроцессора, входящего в состав ядра сервера. Как показано в табл. 4.25. для представлений (VIEW) хранится как их текстовый (исходный) вид. гак и скомпилированный вид, т. е. BLR При обращении к любому объекту имеющему BLR, сервер выполняем бинарный код объекта, а не интерпретирует каждый раз заново исходный текст этих объектов, что позволяет значительно ускорять выполнение сложных запросов.
Большие целые типы
В 3-м диалекте целые числа, имеющие тип NUMERIC или DECIMAL и разрядность больше девяти, хранятся в виде INT64, а менее девяти - в виде DOUBLE PRECISION. В 1-м диалекте и старых версиях все большие целые числа хранятся как DOUBLE PRECISION.
Обратите внимание, что INT64 - это обозначение механизма хранения больших целых чисел, а не какой-то конкретный тип
При переходе с 1-го диалекта на 3-й НИЧЕГО не изменится в хранении больших целых чисел, созданных ДО перехода на 3-й диалект, - они по- прежнему будут иметь тип DOUBLE PRECISION. Чтобы воспользоваться преимуществами хранения данных в INT64 (подробности см. в главе "Типы данных" (ч 1)). можно перенести данные в столбец с типом INT64 Для переноса нужно создать новый столбец нужной разрядности (например, NUMERIC(15,2)), который будет хранить свои значения в виде INT64, и перенести туда значения из старого столбца, затем старый столбец-источник удалить, а новый (со значениями в INT64) переименовать как старый. Переименование легко осуществить, воспользовавшись командой ALTER COLUMN, которая может сменить имя, тип и позицию столбца.
Вот такие препятствия ждут нас на пути к 3-му диалекту. Теперь от обзора перейдем к пошаговому алгоритму перевода базы данных от 1-го диалекта к 3-му. Мы будем рассматривать вариант, названный в [3, глава "Migration Guide"] способом "In-place migration", - когда база данных переводится на 3-й диалект без полного пересоздания базы данных и перекачки всех данных из старой базы данных в новую.
Bumped transaction
Этот параметр более не используется в InterBase. Он является наследием тех версий InterBase, которые использовали так называемый Write-ahead log.
Checksum
Второй строкой идет параметр checksum, т. е. контрольная сумма. Контрольная сумма имеется как на заголовочной странице, так и на любой другой странице базы данных. Однако в современных версиях InterBase (для ODS старше 9.x) она не используется и ее значение всегда равно 12345. Не очень полезный параметр.
Что такое "архитектура сервера СУБД ?
Архитектура - понятие столь широкое и столь часто употребляемое, что, пожалуй, стоит определить, что мы будем понимать под архитектурой в нашем конкретном случае, т. е. по отношению к серверу баз данных InterBase. Попытаемся очертить круг проблем, интуитивно связываемых с понятием архитектуры сервера СУБД. Прежде всего, это способ хранения и обработки информации в базе данных. По этому принципу СУБД можно подразделить на реляционные, сетевые, объектно-ориентированные, иерархические и т. д. InterBase относится к реляционным СУБД, и останавливайся на том, что это такое, мы не будем. Коротко определения этих видов СУБД приведены в глоссарии в конце книги. Если читатель пожелает познакомиться с ними поближе, то лучше всего обратиться к какой-нибудь из множества превосходных книг по этому вопросу, доступных в печатном виде или в Интернете.
Второй важной стороной понятия архитектуры является способ взаимодействия клиентов - потребителей данных с сервером, которые эти данные хранит и обрабатывает. Обычно способ обмена каким-то образом именуется: "архитектура клиент-сервер", "многозвенная архитектура" или "локальные базы данных". Общего, объединяющего названия у этих способов обмена нет. но, несмотря на недостатки подобной классификации, можно сказать, что InterBase представляет собой систему клиент-серверной архитектуры. Под понятием "клиент-серверная архитектура" понимают массу различных вещей. Общим у всех систем, к которым можно применить определение "клиент-серверная", пожалуй, является тот факт, что такая система всегда имеет две четко разделенные части - клиентскую и серверную. В связи с таким делением часто возникает путаница с терминами "сервер" и "клиент". Давайте сразу внесем ясность в этот вопрос. Существуют следующие виды "серверов":
Сервер как компьютер-сервер, т. е. отдельная ЭВМ, обслуживающая запросы, приходящие с других компьютеров
Сервер как экземпляр серверной част СУБД InterBase, выполняющий запросы клиентской части СУБД. Обратите внимание, что серверная и клиентская части СУБД InterBase не обязательно должны находиться на разных компьютерах - они могут выполняться и на одном.
Под понятием "клиент" можно понимать как компьютеры, на которых выполняются какие-то конкретные прикладные программы, так и сами эти программы, которые используют СУБД. Также под клиентом может пониматься клиентская часть InterBase, которая необходима для передачи запросов от прикладных программ серверной части СУБД.
Схематично архитектура клиент-сервер в ее типичной конфигурации изображена на рисунке 4.1.
В этой книге под "сервером" мы будем понимать серверную часть СУБД InterBase, а под "клиентом" - его клиентскую часть. Если эти термины будут использоваться в другом смысле, то это будет указано.
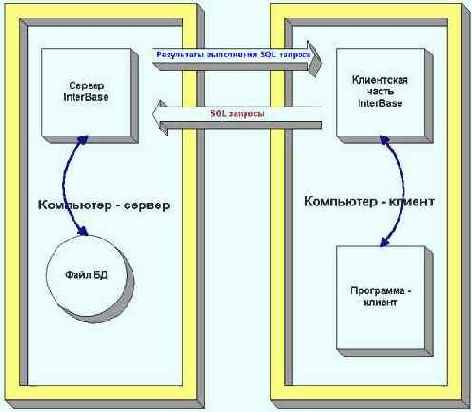
Рис 4.1. Архитектура клиент—сервер InterBase
Под архитектурой также часто понимается состав программного комплекса, т. е. то, из каких модулей состоит сложная сущность, называемая обычно "сервером СУБД", как эти модули взаимодействуют и обеспечивают работу СУБД. InterBase имеет две различные реализации, которые имеют разную архитектуру взаимодействия модулей: Classic и SuperServer. Эти две различные архитектуры будут рассмотрены в главе "Classic и SuperServer" Там мы узнаем, чем отличаются эти архитектуры, и какие недостатки и преимущества они имеют.
И пожалуй, самое простое определение - это архитектура как "начинка" сервера, как ответ на "детский" вопрос, как это все устроено и почему оно работает так, а не иначе. Какова "начинка" СУБД, как организуются данные во все более сложные структуры, начиная от расположения байтов на диске и заканчивая логическими объектами, которые позволяют легко манипулировать данными в базе данных? Ответ на этот вопрос будет рассмотрен в главе "Структура базы данных InterBase". К рассмотрению "начинки" InterBase мы приступим с самого "низа" - с физической структуры данных, посмотрим, как на самом деле лежат байты и биты тех данных, которые пользователи вверяют InterBase. Затем мы перейдем к тому, как элементарные элементы данных организуются в более сложные структуры, которые отвечают логике прикладных задач, обычно решаемых программистами баз данных, т. е. к таблицам, триггерам, хранимым процедурам и другим объектам логической структуры базы данных.
Classic
Рассмотрим подробнее архитектуру Classic-варианта сервера InterBase. В этой модели, как было сказано ранее, для каждого клиентского соединения запускается собственный серверный процесс, который обслуживает данного клиента. Процессом запуска управляет внешний процесс (это inetd или xinetd для Unix-систем).
Серверные процессы изолированы друг от друга. Как и любые другие процессы в ОС, они не могут свободно читать и писать друг у друга в памяти. Тем не менее работать они будут с одной базой данных, в результате чего могут возникнуть конфликты и рассогласования данных в базе данных. Представьте себе, что один серверный процесс пытается изменить страницу в базе данных, которую в данный момент изменяет другой процесс. Очевидно, что возникнет конфликт на почве распределения ресурсов. Чтобы сообщить о том, что определенные ресурсы в базе данных в данный момент используются и разрешить возникающие при "дележке" конфликты, существует специальный процесс - менеджер блокировок (gds_lock_mgr). Необходимость в менеджере блокировок возникает, когда второй клиент подсоединяется к базе. Именно в этот момент менеджер блокировок загружается в память, чтобы "следить за порядком".
Помимо разрешения конфликтов, существует дополнительная необходимость управления сервером в смысле администрирования. К сожалению, в Classic невозможно с клиента получить информацию о количестве клиентских соединений, обслуживаемых в данный момент сервером, так как для каждого клиента существует только один сервер, а информация об остальных серверных процессах, обслуживающих других клиентов, ему недоступна. Также в Classic- вариантах InterBase 6 и его клонов пока не реализовано Services API, которое позволяет управлять сервером через клиентские соединения, а не через специальные программы. Правда, надо отметить, что Yaffil Classic Server имеет реализацию Services API.
У каждого серверного процесса имеется собственный кеш, в котором хранятся используемые страницы базы данных. Например, если мы выделим на обслуживание каждого клиентского соединения 15 Мбайт кеша, то при 20 клиентах нам будет нужно 300 Мбайт ОЗУ только на кеш-память. Если предположить, что клиенты выполняют в основном какие-то однообразные запросы (а так оно и есть в большинстве клиент-серверных систем), то будет очевидным многократное дублирование кешированной информации в каждом серверном процессе. Classic довольно расточителен: даже если клиенты выполняют абсолютно одинаковые запросы, все равно для каждого серверного процесса, обслуживающего одного клиента, будет кешироваться одна и та же информация.
Кроме кеша страниц базы данных, память отводится для кеширования схемы базы (метаданных). Каждый серверный процесс в архитектуре Classic будет иметь свою копию метаданных. На сложной базе (скажем, с сотнями таблиц и процедур) это может вылиться в десятки мегабайтов, причем отрегулировать этот размер нельзя.
Помимо вышеперечисленного, также велик расход ресурсов на запуск множества серверных процессов и функционирование менеджера блокировок. Чтобы преодолеть недостатки подхода "каждому клиенту - по серверу", была разработана архитектура SuperServer, на которую сейчас в компании Borland и направлены все усилия.
Classic и SuperServer
На данный момент существуют два варианта архитектуры InterBase, которые значительно отличаются друг от друга методами работы с клиентами, организацией взаимодействия собственных модулей и даже составом модулей, входящих в определению реализацию архитектуры. Условно эти две различных архитектуры назвали Classic и SuperServer. Чтобы быстро войти в курс дела, коротко рассмотрим главные особенности этих архитектур.
Архитектура Classic кратко характеризуется следующей фразой: "каждому клиенту - собственный сервер". Это означает, что на каждое клиентское соединение на компьютере-сервере запускается серверный процесс, который обслуживает одного клиента. Сколько у нас будет клиентов, установивших соединения, столько экземпляров сервера запустится для их обслуживания (имейте в виду, что одна клиентская программа может открывать сколько угодно соединений с сервером).
Архитектуру SuperServer можно по аналогии охарактеризовать как "на всех клиентов - один сервер". Это означает, что все клиентские соединения обслуживаются одним серверным процессом, где каждым конкретным клиентом занимаются отдельные потоки (threads).
Сразу следует сказать, что компания Borland уже давно, еще до опубликования исходных кодов InterBase 6, заявляла о своей решимости полностью отказаться от архитектуры Classic и перейти исключительно на SuperServer, ввиду ее многочисленных достоинств.
Тем не менее Classic жива и поныне, имеет своих многочисленных приверженцев и не собирается так просто "сдаваться". Причины этой нешуточной схватки двух подходов мы сейчас рассмотрим, и начнем, конечно же, с исторического экскурса.
Ограничим глубину погружения в историю версией InterBase 4.x. Изначально InterBase 4 имел архитектуру Classic - это были версии 4.0 и 4.1. Версия 4.2 стала первым SuperServer в ряду продуктов InterBase. Версия InterBase 5.x уже не имела реализаций архитектуры Classic под платформу Windows - только SupeiSeiver, но для Linux существует версия InterBase 5.6 с архитектурой Classic. В InterBase б сохраняется та же ситуация - под ОС семейства Unix/ Linux существуют InterBase 6 как в варианте SuperServer, так и в варианте Classic, а под Windows - только SuperServer.
Следует заметить, что деление на Classic и SuperServer не означает, что имеются два варианта исходных кодов для каждого вида архитектуры - один для Classic и другой для SuperServer (иначе со временем получились бы два разных сервера). Оба эти варианта архитектуры (и все реализации под разные ОС) производятся из общего набора исходных кодов с помощью директив Ifdef, разделяющих платформенно- и архитектурно-зависимые участки кода друг от друга. С помощью набора этих директив определяют, какой вариант и для какой платформы собирать. Естественно, для разных ОС сборка осуществляется с использованием разных библиотек ввода-вывода, управления памятью и т. д. Таким образом, начиная с версии InterBase 5.x компания Borland перестала разрабатывать вариант сервера под Windows с архитектурой Classic, в результате чего этот вариант архитектуры доступен только поклонникам Unix/Linux-систем, а версии Classic под Windows ни в вариантах реализации от Borland, ни от Firebird не существует.
В конце 2001 года появился еще один альтернативный клон InterBase 6 - СУБД Yaffil, авторами которой являются петербургские программисты Олег Иванов и Алексей Карякин. Этот вариант InterBase как раз и имеет реализацию архитектуры Classic под Windows. Подробнее о Yaffil можно узнать в приложении "Yaffil - российский клон InterBase 6.x".
Стоит ли использовать Yaffil или ставить Firebird/InterBase 6.x на Linux, чтобы ощутить прелести и оценить недостатки архитектуры Classic, - мы сейчас и попытаемся разобраться.
Classic vs SuperServer
Как вы уже могли заметить, картина складывается довольно интересная на каждый недостаток Classic у SuperServer находится достоинство. Classic расточителен - SuperServer экономен, Classic без Services API - у SuperServer он есть.
Однако, как и везде, здесь мы имеем "палку о двух концах", т. е., определенные недостатки Classic переходят в определенных ситуациях в его достоинства, а преимущества SuperServer превращаются в недостатки. Например, рассмотрим случай. когда N нас имеется, скажем, мощный двухпроцессорный компьютер- сервер с большим количеством ОЗУ, например 2 Гбайт.
Если мы установим на такую систему InterBase в варианте SuperServer, то будем наблюдать не ускорение, а замедление по сравнению с однопроцессорным вариантом того же сервера! Более того, с памятью будут твориться сплошные "недоразумения"- экономный SuperServer будет "отказываться" от огромного ОЗУ. пытаясь всячески сэкономить операжвную память. Как же так, мощные процессоры, много памяти, a InterBase SuperServer не очень-то быстро работает?
Вот здесь и проявляются недостатки SuperServer. Проблему с масштабируемостью InterBase архитектуры SuperServer на многопроцессорных компьютерах давно признали в компании Borland. Дело в том, что ядро SuperServer не расчитано на использование нескольких процессоров.
При запуске множества потоков, обрабатывающих запросы клиентов, внутри серверного процесса SuperServer происходит следующее: ОС не может равномерно распределить время между потоками, потому что в InterBase активным может быть только один поток! Остальные добровольно ждут пока этот активный поток с aw "отдаст" им процессор. Что остается ОС? Только выполнять этот единственный поток В InterBase SuperServer встроен некоторый аналог планировщика потоков, реализующий невытесняющую многопоточность с одним активным потоком.
Итак, сервер InterBase SuperServer не может управлять распределением потоков по процессорам. В результате ОС при нарастании нагрузки начинает перебрасывать главный серверный процесс (ibserver.exe) с одного процессора на другой. На это тратятся системные ресурсы и время, что замедляет работу InterBase. С такой ситуацией на многопроцессорных системах борются путем "привязки" (affinity) InterBase варианта SuperServer к одному определенному процессору и игнорирования остальных.
Естественно, что приведенное выше описание является лишь аналогией для иллюстрации проблемы и не может служить точным описанием работы ядра SuperServer Для точного описания механизмов работы следует обратиться непосредственно к анализу исходных кодов InterBase, что выходит за рамки этой книги.
Надо также отметить, что с распределением памяти у SuperServer тоже имеются некоторые проблемы. Если мы рассмотрим, как SuperServer обслуживает множество небольших клиентских запросов, то увидим довольно привлекательную картину: высокую производительность при относительно небольшом использовании оперативной и виртуальной памяти. Многочисленные клиентские запросы совместно (без дублирования) используют кешированную информацию SuperServer. Эта особенность делает вариант InterBase с архитектурой SuperServer особенно привлекательным для Web-приложений, ориентированных именно на такой стиль работы с базами данных
Так как запросы небольшие, то они быстро отрабатывают и освобождают память для следующих за ними запросов.
Иная ситуация складывается, если постановка задачи требует наряду с простыми действиями по регистрации данных и просмотру данных, относящихся ккаком\-то документу или обозримому множеству документов, выполнения запросов аналитического характера, связанных со сканированием больших и сложных выборок и построением на их основе различных агрегатов.
Эти "тяжелые" запросы "проходятся" по большому количеству записей и требуют значительных ресурсов памяти и процессора для их выполнения. Мы пытаемся предусмотреть подобную ситуацию и используем мощное аппаратное обеспечение: высокопроизводительный компьютер-сервер с большим количеством ОЗУ. Однако, SuperServer "не понимает" нашей предусмотрительности и при выполнении "тяжелого" запроса пытается обращаться с ним как с небольшим, т. е. отдает ему доступную кеш-память и ресурсы, вытесняя при этом остальные запросы. Результат печален - пока выполняется запрос-тяжеловес, остальные запросы "топчутся в очереди". В связи с фактически последовательным обслуживанием потоков критическими участками кода ядра InterBase сервер просто не имеет другого выбора.
Остается сказать о достоинствах Classic, проявляющихся в этой ситуации.
Во-первых, масштабируемость архитектуры Classic на несколько процессоров. Из-за того что каждый клиент обслуживается независимым процессом, ОС спокойно "рассаживает" эти процессы по различным процессорам, динамически распределяя нагрузку при помощи системных средств управления приоритетами процессов, стоящих в очередь за использованием ресурсов процессора
В результате действительно можно получить значительный выигрыш от многопроцессорной системы, соответствующий затратам на это оборудование.
Во-вторых, использование памяти и процессора при выполнении "тяжелых" запросов. Если мы запускаем какой-то очень интенсивно работающий с базой запрос, то он выполняется в рамках одного серверного процесса, обслуживающего данного клиента, не останавливая при этом остальные. Приоритет "тяжелого" запроса (фактически процесса) падает по мере увеличения времени использования им ресурсов процессора и он начинает "уступать дорогу" более приоритетным процессам других соединений, выполняющим короткие запросы, т. е. процессор занят на 90%, но на долю "долгожителя" приходится 80-70-60- 50-40 %... Он замедляет остальные, это заметно, но терпимо, и главное - у пользователя не возникает ощущения "подвешенности".
Вот где недостаток "избыточность" перетекает в преимущество "нагрузочная способность"!
Как бы то ни было, архитектура Classic значительно лучше SuperServer справляется с тяжелыми запросами при одновременном обслуживании нескольких клиентов и более корректно реализует вытесняющую многозадачность, что позволяет эффективнее справляться с запросами-"тяжеловесами".
Database dialect
Диалект, используемый в базе данных. Может принимать значения 1 или 3. Диалект 2 могут иметь только клиенты InterBase (см. в этой части главу "Миграция").
Другие инструменты для осуществления резервного копирования
Помимо универсальной утилиты командной строки gbak, множество других инструментов предоставляют удобный графический интерфейс для операций резервного копирования и восстановления из резервной копии. В документации по InterBase 6 приводятся примеры выполнения этих операций с использованием программы IBConsole, которая обычно входит в поставку InterBase и его клонов, однако лучше использовать инструменты из рекомендованного списка (см. приложение "Инструменты администратора и разработчика InterBase").
Помимо однократного осуществления backup часто возникает задача наладить регулярный процесс резервного копирования - например, ежедневный или даже чаще. Как автоматически наладить этот процесс? Для этого можно воспользоваться либо встроенными средствами ОС для организации регулярного копирования, т. е. с помощью штатного планировщика задач в определенное время запускать пакетный файл, содержащий команды для осуществления backup, либо использовать специальную программу-планировщик. Более удобным представляется второй способ - использование специальной программы. Для ОС Windows можно порекомендовать утилиту GBAK Sheduler (www.gbaksheduler.com), которая предоставляет удобный интерфейс для организации регулярного резервного копирования и совершенно бесплатна.
Двойные кавычки
Если в версиях InterBase 4.x и 5.x и диалекте 1 версии 6.x строковые константы позволялось описывать как с помощью как одинарных, так и двойных кавычек, то в 3-м диалекте двойные кавычки применяются только для обозначения идентификаторов, а одинарные - для строковых констант. Чтобы базу можно было перевести из 1-го диалекта в 3-й, необходимо заменить все двойные кавычки, ограничивающие строковые константы, на одинарные. Двойные кавычки могут находиться в триггерах, хранимых процедурах, представлениях, доменах, ограничениях и в значениях столбцов по умолчанию.
Файлы базы данных InterBase
Все данные, которые пользователи "помещают" в базу, используя любой инструмент из множества применяемых для этой цепи "складируются" сервером в некую сущность - баз} данных. Обычно под базой данных понимается и сам сервер СУБД, и пользовательская информация, и даже клиентские программы, которые работают с данными. Мы будем понимать в этой главе под базой данных совершенно конкретную вещь - файлы базы данных.
База данных InterBase представляет собой один или несколько файлов, в которых находится информация обо всем, что связано с этой базой. Исключение составляет информация о пользователях, поскольку пользователи определяются на уровне всего сервера и хранятся отдельно, в системной базе данных ISC4.GDB. Внутри файлов базы данных содержится вся информация о базе: сами данные, индексы, триггеры, хранимые процедуры и т. д.
База данных InterBase для среднего проекта представляет собой один файл, так как ограничение в 32 Гбайта на размер одного файла базы данных позволяет держать все данные в одном файле (версии ниже InterBase 6.5, Firebird 1.0 и Yaffil 1.0 имеют ограничение в 2-4 Гбайт, в зависимости от ОС). 32 гигабайт вполне хватает для хранения информации приложения баз данных среднего размера. Но при необходимости можно разбить базу данных на несколько файлов. Известны базы данных InterBase размером в сотни гигабайт.
Файлы *.GDB изнутри
GOB - зю расширение, которое рекомендуют использовав для файлов баз данных InterBase. Первое, что нужно сказать о строении GDB-файла, - это то, что он представляет собой набор страниц жестко определенного размера. Размер файла базы данных кратен размеру страницы, который неизменен для всех файлов данной базы данных. Разные версии InterBase поддерживают различные размеры страниц, что отражено в таблице 4.21. Размер страницы задается при создании базы данных и не может быть изменен в течение ее жизненного цикла, т. е. изменить размер страницы возможно только при создании базы из резервной копии (restore).
Табл 4.21. Размер страницы, поддерживаемый различными версиями
| Версия InterBase | Размер стр | аницы, байт | |||||||||
| 1024 | 2048 | 4096 | 8192 | 16384 | |||||||
| InterBase 4 0 | * | * | * | * | |||||||
| InterBase 5.x | * | * | * | 4 | |||||||
| InterBase 6 Ox | * | * | * | * | |||||||
| Firebird Ix/Yaffl 1.x /InterBase 6.5 и выше | * | * | * | * | * |
Чтение и запись данных в базе данных осуществляется постранично, и многие важные характеристики базы данных и сервера, такие, например, как размер буфера базы данных (Database cache), зависят от размера страницы и исчисляются в "страницах".
Давайте откроем какую-нибудь базу данных InterBase с помощью IBSurgeon. Для этого достаточно дважды щелкнуть по файлу базы данных. На рисунке 4.2 изображен список страниц, который показывается после того, как IBSurgeon открыл базу данных.
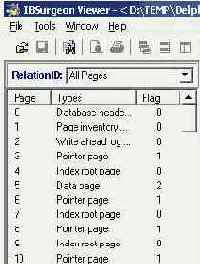
Рис 4.2. Список страниц базы данных
Страницы бывают различных типов, каждый из которых служит определенной цели. Взаимозависимости различных типов страниц условно представлены на рис. 4.3. Он схематично изображает расположение страниц в файле базы данных - слева направо, сверху вниз, если считать от начала файла. Страницы одного типа не идут строго одна за другой - они могут быть перемешаны свободно, располагаясь в файле в том порядке, в котором они создавались сервером при расширении или создании базы данных.
Некоторые типы страниц выглядят "болтающимися без дела", т. е. не имеющими ссылок на другие типы страниц. Однако здесь нет никакого противоречия, просто эти типы страниц связаны и используются на другом структурном уровне, они могут связываться с помощью таблицы RDBSPAGES и других системных таблиц (эта таблица и другие системные объекты будут рассмотрены ниже, в разделе "Логическая структура базы данных"). На рис. 4.3 изображены только явные ссылки между страницами на физическом уровне.
Рассмотрим подробнее, какие бывают типы страниц в базе данных InterBase. В файле ods.h из набора исходных кодов InterBase находится информация обо всех возможных типах страниц. К этому файлу мы будем часто обращаться, чтобы из первоисточника получить данные не только об ODS, но и о многих других основополагающих вещах ядра InterBase.
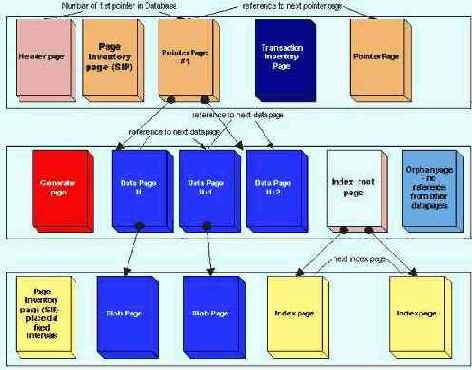
Pис 4.3. Взаимозависимости ме/KCjv разимными типами страниц в базе данных InterBase
Всего задекларировано 11 типов страниц, однако достойны объяснения лишь 9 из них, что ясно видно из табл. 4.22. Типы страниц с идентификаторами 0 и 10 не определены или не используются
Табл 4.22. Типы страниц
|
Определение в ods.h |
Идентификатор страницы |
Английское название страницы |
Русская интерпретации английского названия |
|
pag_undefmed |
0 |
Undefined - If a page has this page type it is probably free |
Неопределенный тип страницы - возможно, страница свободна |
|
pag_header |
1 |
Database header page |
Страница заголовка базы данных |
|
P°g_pages |
2 |
Page inventory page (or Space inventory page - SIP) |
Страница, хранящая информацию о распределении страниц |
|
pag_transactions |
3 |
Transaction inventory page (TIP) |
Страница учета транзакций |
|
pag_pomter |
4 |
Pointer page |
Страница указателей |
|
pag_data |
5 |
Data page |
Страница данных |
|
pag_root |
6 |
Index root page |
Страница вершины индекса |
|
pagjndex |
7 |
Index (B-tree) page |
Страница индексов |
|
pag_blob |
8 |
Blob data page |
Страница для хранения ВЮВ-данных |
|
pagjds |
9 |
Gen-ids |
Страница генераторов |
|
pagjog |
10 |
Write ahead log information |
Не используется |
Flags
Первой строкой в нем идет параметр Flags. Это набор флагов, определяющий важные особенности поведения базы данных. Возможные значения флагов, взятые из файла ods.h, описывающего структуру базы данных (On-disk structure - см. ниже главу "Структура базы данных InterBase"), приведены ниже в табл. 4.13.
Табл 4.13. Флаги файла базы данных
|
Значение флага (десятичное и шестнадцатеричное) |
Расшифровка его значения | ||
|
0x1 1 |
Файл является активным Shadow-файлом | ||
|
0x2 2 |
Режим синхронного чтения-записи включен (forced write on) | ||
|
0x4 4 |
Краткосрочное журналирование | ||
|
0x8 6 |
Долгосрочное журналирование | ||
|
0x10 8 |
Не вычислять контрольные суммы | ||
|
0x20 16 |
Не резервировать место для версий файлов | ||
|
0x40 62 |
Запретить применение совместно используемого кеш-файла | ||
|
0x80 128 |
База данных остановлена | ||
|
0x100 256 |
В базе данных используется SQL диалект 3 | ||
|
0x200 512 |
База данных только для чтения. Если флаг не установлен, то допустимы как чтение, так и запись |
Флаги устанавливаются только с помощью специальных инструментов вроде gfix, изменять флаги с помощью других инструментов опасно - это может привести к порче базы данных.
Надо сказать, что при получении статистики показывается, что значение параметра Flags всегда равно нулю, вне зависимости от установленных флагов. Дело в том, что расшифровка части флагов производится ниже - в параметрах Database Dialect и Attributes.
Forced Writes
Forced Writes - это режим записи данных на диск. Существует два режима - синхронный и асинхронный, которым соответствуют значения Forced Writes ON и OFF. При асинхронном режиме записи данных на диск (т. е. при FW OFF) данные пишутся в файловый кеш ОС, в результате чего ускоряются операции с ке- шированными данными. При синхронном режиме (FW ON) процесс, который изменяет данные, ожидает, пока они пишутся на диск, это позволяет помещать данные на диск гораздо надежнее, чем при асинхронной записи. Правда, стоит отметить, что обращения к диску производятся не после изменения каждой записи (это бы катастрофически снизило производительность), а в следующих случаях:
когда происходит подтверждение транзакции: все страницы, затронутые изменениями в рамках этой транзакции, пишутся на диск;
когда измененная страница становится "непопулярной": т. е. когда к ней перестают часто обращаться и нет смысла держать ее в кеше, она пишется на диск, а ее место в кеше занимает другая страница, к которой чаще обращаются;
когда вытесняется несколько зависящих друг от друга страниц: запись одной из них на диск приводит к записи других;
при исипользовании сервера InterBase с архитектурой Classic страница вытесняется из кеша одного пользователя и пишется на диск, если ее требует другой пользователь.
При включенном режиме асинхронного чтения данные пишутся на диск, когда этого пожелает ОС. При большом объеме ОЗУ база данных может почти целиком быть "втянута" в кеш. Тем не менее отключенный режим Forced Writes - это обоюдоострое оружие. Ускоряя операции чтения и записи данных, асинхронное чтение может привести к значительной потере данных в результате сбоя аппаратного или программного обеспечения. Квитированные данные могут находиться в кеше длительное время (часы и дни), поэтому сбой электропитания может привести к потере данных, являющихся результатом часов и даже дней работы. Поэтому стоит неоднократно подумать, прежде чем приносить надежность в жертву скорости и отключать Forced Writes. И конечно, не стоит включать режим асинхронной записи, если ваш сервер не оснащен источником бесперебойного питания.
Forced writes - палка о двух концах
Чтобы влиять на эту ситуацию, в InterBase 6 предусмотрена настройка режима записи данных на диск. Эта настройка называется foreed writes (FW) и имеет два значения - ON (synchronous) и OFF (asynchronous). Значения forced writes определяют, каким образом InterBase взаимодействует с диском. Если установлено значение forced writes on, то включается режим синхронной записи на диск, когда подтвержденные данные записываются на диск сразу после команды commit, причем сервер ждет завершения записи и лишь потом продолжает работу. В случае режима forced writes off InterBase не торопится записывать данные на диск после команды подтверждения транзакции (commit), а делегирует эту задачу параллельному потоку, в то время как основной поток продолжает обработку данных, не дожидаясь конца записи на диск.
Режим синхронной записи на диск (FW ON) является более безопасным и приводит к минимизации возможной потери данных, однако следствием его применения является некоторая потеря производительности. Режим асинхронной записи (FW OFF) увеличивает производительность, однако значительно возрастает риск потери большого количества данных.
Для получения максимально возможной производительности обычно устанавливают режим FW OFF, в результате чего при сбое питания теряется гораздо большее количество данных, чем при синхронном режиме записи на диск. При установке режима записи следует хорошенько взвесить, насколько увеличение производительности важнее возможности потерять несколько часов работы при неожиданном сбое питания.
Часто сами пользователи грешат неджентльменским отношением к InterBase. В небольших организациях, где экономят на любых мелочах, зачастую на компьютер-сервер, на котором установлен сервер СУБД, также ставят другие серверные (и не только серверные) программы. И в случае их "зависания", недолго думая, нажимают на Reset, что повторяется несколько раз на дню. Хотя InterBase является необычайно устойчивым к таким действиям по сравнению с другими СУБД и позволяет начать работу с базой данных сразу после аварийной перезагрузки, однако такое обращение не проходит бесследно. В результате аварийных перезагрузок накапливаются потерянные страницы, теряются связи между страницами данных. Это может продолжаться довольно долго, однако развязка рано или поздно наступит. Когда "битые страницы" появятся среди страниц учета страниц (PIP) или затронут страницы генераторов или, еще хуже, испортится заголовочная страница базы данных, то база данных может просто больше не открыться и превратиться в большой кусок разрозненных данных, из которого нельзя извлечь ни байта полезной информации.
Мир InterBase
Третья строка - это generation ("поколение" в переводе с английского). Это счетчик, который увеличивается на единицу всякий раз, когда заголовочная страница записывается на диск. Тоже мало полезный параметр.
IBSurgeon - проводник по базе данных InterBase
Так как нам необходимо подробно разобраться в строении файлов баз данных InterBase, то желательно иметь какой-нибудь удобный инструмент, позволяющий работать с файлами базы данных напрямую, а не через ядро сервера InterBase. Самый простой способ - это воспользоваться обычным шестнадцатеричным просмотрщиком и попытаться разобраться в структуре файлов базы данных, рассматривая ее НЕХ-представление Это было бы довольно утомительное занятие.
Но, к счастью, существует инструмент для прямой работы с базами данных InterBase, а также всех его клонов - Firebird и Yaffil. Это IBSurgeon (www.ibsurgeon.com) - инструмент для непосредственной низкоуровневой работы с базами чанных TnterBase/Firebird/Yaffil. который может использоваться для исследования внутренней структуры баз данных InterBase и диагностики поврежденных баз данных с целью их восстановления. (Подробности см. в приложении "Инструменты администратора и разработчика InterBase").
IBSurgeon использует собственный альтернативный механизм доступа к базам данных InterBase/Firebird/Yaffil, что позволяет диагностировать базы данных в любом состоянии, в том числе и те, которые не открываются с помощью ядра сервера InterBase/Firebird/Yaffil.
Мы воспользуемся IBSurgeon для того, чтобы проиллюстрировать внутреннее строение базы данных и придать ему видимые, "реальные" очертания.
Иерархия объектов в InterBase
Чтбы более четко представлять себе, что такое объекты базы данных, мы попробуем построить иерархию объектов базы данных, исходя из принципа "кто кого содержит". Первыми нужно включить в нашу иерархию физические страницы файлов базы данных, как самый низкий уровень организации данных. Затем очевидно, идут таблицы - основополагающие объекты, которые описывают все остальные типы объектов. Таблицы описывают хранимые процедуры, триггеры, вычисляемые поля, проверки, вычисляемые индексы, исключения и т. д. Обратите внимание: только описывают! Таблицы лишь содержат декларации и определения этих объектов, а сами объекты реализуются через BLR. Поэтому мы можем изобразить таблицы в виде некоторой "рамы", поддерживающей все остальные объекты базы данных. В основание рамы мы положим BLR - как прокладку "реализации", затем поместим "слой" триггеров, хранимых процедур, вычисляемых индексов и представлений.
Чтобы успокоив специалисте по внутреннему строению InleiBase, которые могут возразить, что BLR многих объектов (таких, как представления) хранятся в системных таблицах, заметим. что это отношение довольно трудно изобразить на рисунке, и для простоты мы его отпустим. Схема не преследует цель абсолютно точно воссоздать взаимосвязи объектов базы данных, а имеет целью проиллюстрировать их тесную взаимосвязь
Эти типы объектов объединяет то, что они непосредственно связаны с BLR, который их реализует, без промежуточной логики. Отдельно следует расположить исключения - это специальные виды ошибок, определяемые пользователем. Исключения обрабатываются на уровне ядра InterBase и поэтому не имеют BLR Такие виды ограничений, как проверки (CHECK), размещаются "поверх" триггеров, поскольку логика ограничений и проверок на самом деле реализуются триггерами.
То, что у нас получилось в результате попытки выстроить иерархию объектов логической и физической структуры базы данных, изображено на рис. 4.11.
Естественно, данная схема лишь приблизительно отражает логическую структуру и взаимосвязи объектов в базе данных и дает только общее представление о ней. Желающие подробно изучить структуру метаданных базы данных InterBase могут произвести реинжиниринг системных таблиц базы данных и рассмотреть все взаимосвязи между ее объектами, а также обратиться к документации и исходным кодам InterBase. На этой схеме отражены лишь основные объекты базы данных Давайте кратко опишем основные функции, которые эти объекты выполняют в базе данных.
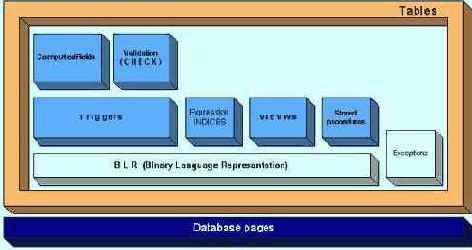
Рис 4.11. Объекты логической структуры базы данных InterBase
Таблицы (tables) - основной объект, содержащий данные, как пользовательские, так и системные. Таблица имеет уникальное имя и содержит в себе набор поименованных полей. Пользователь может помещать данные, извлекать и модифицировав данные в таблицах. Можно сказать, что таблица аналогична обычным "бумажным" таблицам, начерченным вручную.
Триггеры - исполняемые куски кода, которые применяются для реализации дополнительных действий при операциях с данными. Триггеры исполняются до или после операций вставки, модификации и удаления и позволяют осуществить подстановку значений во вновь создаваемые записи и многое другое.
Хранимые процедуры - мощный инструмент реализации бизнес-логики на уровне базы данных. Выполняясь на уровне сервера, хранимые процедуры работают очень быстро и позволяют совершать множество операций над наборами данных. Хранимые процедуры InterBase возвращают стандартные SQL-наборы данных, над которыми можно производить все SQL-операции, включая объединение с другими таблицами.
Представления (VIEW) - это скомпилированные SQL-запросы, выполняющиеся на сервере. Представления позволяют гибко организовывать наборы данных, переносить часть бизнес-логики на сервер.
Проверки (Validation) - ограничения, накладываемые на значения полей в таблице. Например, можно указать, что данное поле будет принимать только положительные значения. Ограничения на значения полей реализуются с помощью триггеров и позволяют эффективно управлять ссылочной целостностью на уровне базы данных. Обычно ограничения применяются для того, чтобы предотвратить помещение неправильных значений в таблицу.
Пользователи (Users) - InterBase позволяет завести для работы с базой данных несколько пользователей и распределять между ними права доступа к различным объектам базы данных. Таким образом, можно гибко управлять разрешениями на те или иные операции с базой данных.
User-Defined Functions (UDF) - функции, определяемые пользователем. Это одна из наиболее мощных возможностей InterBase, позволяющая расширять стандартный SQL-интерфейс своими собственными функциями. Например, функции работы со строками, такие, как UPPER (привести все символы к верхнем} регистру), реализованы в стандартной UDF-библиотеке, поставляющейся в комплекте с InterBase. Свойство создавать собственные UDF дает разработчикам возможность расширять функциональность InterBase практически любыми функциями. Для создания UDF подходит любая среда программирования, которая позволяет производить динамические библиотеки (Visual C++, C++ Builder, Delphi и т. д.).
Implementation ID
Параметр Implementation ID определяет, под какой ОС была создана база данных. Табл. 4.14, взятая из Operation Guide, из комплекта документации InterBase 6.x, дает нам информацию обо всех возможных ОС, поддерживаемых в InterBase. В ней содержатся ОС, под которые хоть когда-то выпускался InterBase Учитывая, что одна из версий InterBase (мы не имеем точной информации о том, какая эта версия) применяется на танках "Abrams", то, вероятно, этот список может быть и неполным. Хотя Implementation ID=3, 6, 9 и 14 наводят на размышление Тем не менее вы, вероятно, согласитесь с тем, что список все равно получается внушительный.
Табл 4.14. ОС, поддерживаемые InterBase (все версии)
|
Значения Implementation ID |
ОС | ||
|
1 |
Apollo | ||
|
2 |
Sun, HP 9000, IMP Delta, NeXT | ||
|
3 |
Reserved | ||
|
4 |
VMS | ||
|
5 |
VAX Ultrix | ||
|
6 |
Reserved | ||
|
7 |
HP 900 | ||
|
8 |
OS/2, Windows NT, Novell NetWare | ||
|
9 |
Reserved | ||
|
10 |
RS 6000 | ||
|
11 |
Data General AviiON | ||
|
12 |
HP M PE/XL | ||
|
13 |
Silicon Graphics Iris | ||
|
14 |
Reserved | ||
|
15 |
DEC 0 SF/1 | ||
|
16 |
Windows 95/98/Me |
Информация страниц данных
Если при запуске gstat укажем ключи -all или -data, то получим информацию обо всех пользовательских таблицах в базе данных. Информация для каждой таблицы выглядит так:
CUSTOMER (33)
Primary pointer page: 129, Index root page: 130
Data pages: 664, data page slots: 749, average fill: 90%
Fill distribution:
0 19% = 4
20 39% = 14
40 59% = 36
60 79% = 55
80 99% = 555
Здесь CUSTOMER -имя таблицы; 33 - идентификатор таблицы (соответствует RDBSRelationID в системной таблице RDBSRelations); Primary pointer page - это номер первой страницы указателей в базе данных для данной таблицы; Index root page - номер первой страницы указателей для индексов этой таблицы; Data pages - число страниц данных, занимаемых данной таблицей; Data page slots - число указателей на страницы данных; average fill - процент использования страниц под хранящиеся данные; Fill distribution - табл. показывающая, какое количество страниц как заполнено. Например, первая строка означает, что 4 страницы заполнены на 0-19 %, а последняя - что 555 страниц, занятых этой таблицей, заполнены на 80-99%.
Надо сказать, что, несмотря на обилие узкотехнических терминов в получаемой статистике (которые рассмотрены ниже в главе "Структура базы данных InterBase"), добываемые данные все же могут быть использованы для оптимизации базы данных даже неспециалистами. Например, если данные на страницах слишком разрежены, то надо задуматься о структуре таблицы. Возможно, требуется разнести поля этой таблицы по нескольким таблицам, чтобы они плотнее размещались на диске, в результате чего можно получить некоторое ускорение операций чтения и записи.
Информация заголовочной страницы (Database header)
Заголовочная страница содержит важную информацию о базе данных в целом. Часть информации является статичной и записывается при создании базы данных, часть - меняется в зависимости от происходящих с базой данных изменений. Запуск утилиты gstat с ключом -all приводит к выводу всей статистической информации базы данных, при этом информация с заголовочной страницы выводится первой. Чтобы прекратить вывод статистики сразу после вывода этой информации, следует при запуске gstat указать только ключ -h. Пример информации с заголовочной страницы приводится ниже:
Database "C:\Database\EVP.GDB"
Database header page information:
Flags 0
Checksum 12345
Generation 1100521
Page size 8192
ODS version 8.2
Oldest transaction 1084640
Oldest active 1100476
Oldest snapshot 1100476
Next transaction 1100478
Bumped transaction 1
Sequence number 0
Next attachment ID 0
Implementation ID 8
Shadow count 0
Page buffers 0
Next header page 0
Database dialect 1
Creation date Dec 19, 2001 21:30:59
Attributes force write
Variable header data:
Shared Cache file:
Sweep interval: 20000
*END*
В первой строке содержится информация о расположении файла базы данных. Далее идет блок информации, озаглавленный Database header page information.
Инструмент командной строки gbak
Наиболее универсальным инструментом, позволяющим осуществить резервное копирование базы данных на любой платформе, является gbak - утилита командной строки, входящая в поставку InterBase. С помощью gbak можно обратиться к любому функционирующему InterBase-серверу и произвести считывание данных и получение на их основе резервной копии, а также восстановить базу данных из резервной копии.
Надо заметить, что в случае использования для работы баз данных, чьи версии не совпадают с версией gbak. действует принцип "обратной совместимости". Это значит, что более "старшие" версии gbak могут работать с серверами и базами данных, созданными и функционирующими под управлением "младших" версий (например, gbak от 5.x может сделать backup базы данных, которая была создана в 4 х). Однако gbak от 4.x не сможет работать с базами данных, которые созданы в 5.x и старше, и также не сумеет распаковать резервные копии от старших версий. Единственным исключением является случай, когда gbak запускается под управлением "младшего" сервера (например, 5.x), а в качестве источника данных указывает старший сервер (например, 6.x), в этом случае произойдет резервное копирование "наоборот" - данные из формата базы данных старшей версии попадут в формат backup младшей версии. Такой прием применяется при переходе от старших версий сервера на младшие - этот процесс называется "обратной миграцией" (подробности см. ниже в главе "Миграция").
Давайте рассмотрим утилиту gbak поподробнее. Для того чтобы создать резервную копию базы данных, необходимо воспользоваться следующим образцом запуска gbak: gbak [-B] [options] <база_данных-источник> <файл резервной копии>
Переключатель -В означает, что необходимо выполнить резервное копирование базы данных, путь к которой указан как <база_ланных-источник>, а результаты резервного копирования упаковать в файл, указанный как <файл резервной копии>. Обратите внимание, что -В взято в квадратные скобки. По общепринятому соглашению квадратные скобки означают, что параметр внутри них необязателен. В нашем случае это значит, что gbak без параметров будет делать именно backup базы данных.
Особый интерес представляют опции, с помощью которых можно управлять процессом резервного копирования. Набор дополнительных ключей (опций), представленный предложением [options], описан в таблице 4.4, взятой из [4].
Табл 4.4. Опции gbak, применяемые при создании резервной копии
|
Опция |
Описание |
|
-b[ackup_dafabase] |
Осуществить резервное копирование базы данных |
|
Опции, влияющие на процесс создания резервной копии |
|
|
-cofnvert] |
Преобразовать внешние файлы во внутренние таблицы |
|
-e[xpand] |
Не производить сжатие резервной копии |
|
-fa[ctor] n |
Использовать блокирующий фактор n для ленточного накопителя |
|
-g[arbage_collect] |
Не собирать "мусор" во время резервного копирования |
|
-ig[nore] |
Игнорировать контрольные суммы |
|
-l[imbo] |
Игнорировать "зависшие" двухфазные транзакции (limbo) |
|
-m[etadata] |
Произвести резервное копирование только метаданных |
|
-rtf |
Создать резервную копию в нетранспортабельном формате |
|
-ol[d_descriptions] |
Производить резервное копирование метаданных в формате "старого стиля", т.е. в режиме совместимости со старыми базами данных |
|
-pas[sword]text |
Пароль пользователя, подключающегося к базе данных для резервного копирования |
|
-role name |
Подсоединиться с использованием роли name |
|
-se[rvice] servicename |
Создать резервную копию на том же компьютере, где находится "база данных-источник". Для этого вызывается Service Manager на компьютере-сервере, причем формат вызова отличается для различных сетевых протоколов: TCP/IP hostname:service_mgr; SPX hostname@service_mgr; Named pipes \\hostname\service_mgr; Local service_mgr |
|
-t[ransportable] |
Создавать транспортабельную (переносимую) резервную копию - этот параметр включен по умолчанию |
|
-u[ser] name |
Имя пользователя, который подключается к базе данных для резервного копирования |
|
-v[erbose] |
Включить показ подробного протокола действий gbak во время backup |
|
-y [file | suppress_output] |
Направлять сообщения в файл (файла с таким именем не должно существовать) или подавить вывод сообщений |
|
-z |
Показать версию gbak и версию ядра InterBase-сервера |
Давайте рассмотрим основные ключи, влияющие на процесс резервного копирования.
Во-первых, это ключи -t и -nt, которые определяют, является ли создаваемая резервная копия транспортабельной, т. е. переносимой с одной платформы на другую. По умолчанию (т. е. если не указывать ничего) создается транспортабельный backup, как при использовании ключа -t.
Во-вторых, это ключ -ig[nore], появление которого заставляет gbak не проверять контрольные суммы страниц базы данных, в результате чего в резервную копию могут попасть поврежденные страницы. Если этого ключа нет, то gbak при обнаружении страницы с запорченной контрольной суммой прекратит резервное копирование и выдаст соответствующую ошибку. Обычно ключ -ignore используют, когда производят починку базы данных (см. ниже главу "Починка базы данных").
В-третьих, переключатель-g[arbage_collect], который отключает сборку "мусора" во время резервного копирования. Как известно, InterBase хранит версии записей, измененных различными транзакциями. Это приводит к тому, что на страницах данных накапливается "мусор" - записи старых версий, которые никому не нужны. "Мусор" старых версий собирается, когда производится чтение самой "свежей", актуальной версии записи (подробнее о версиях и сборке "мусора" см. главу "Транзакции. Параметры транзакций" (ч. 1)). Так как резервное копирование - это чтение всех данных в базе данных, которое считывает каждую запись в каждой таблице, то backup также является инициатором крупномасштабного "субботника" - сборки "мусора" по всей базе данных. Надо сказать, что сборка "мусора" является хоть и полезным, но достаточно ресурсоемким процессом. Отключение сборки "мусора" приводит к значительному ускорению процесса резервного копирования. Это бывает исключительно полезным в случае очень больших (многогигабайтовых) баз данных. Однако в общем случае не рекомендуется отключать сборку "мусора" во время резервного копирования, за исключением случаев, связанных с починкой баз данных (см. главу "Починка базы данных"). Вкратце упомянем случаи использования других переключателей. Если вам необходимо получить резервную копию пустой базы данных, т. е. только ее метаданных, то воспользуйтесь переключателем -m[etadata]. Если вы используете несколько различных баз данных InterBase и применяете механизм двухфазного подтверждения транзакций, то транзакции, совершаемые сразу в двух базах данных, могут "зависнуть", т. е. получить промежуточное состояние - ни подтвержденное, ни отмененное, так называемое "in-limbo''-состояние (подробнее о транзакциях смотрите главу "Транзакции. Параметры транзакций"). Чтобы игнорировать результаты работы limbo-транзакций, т.е. версии записей, созданные этими транзакциями, применяется опция -l[imbo]. Чтобы в файл резервной копии попали данные, которые хранятся во внешних таблицах (external tables), используйте переключатель -convert, который преобразует внешние файлы во внутренние таблицы и сделает их резервную копию.
Инструмент командной строки gfix
Для проверки и восстановления базы данных используется инструмент gfix. Помимо этого, gfix также может выполнять различные действия по управлению базой данных: менять диалект базы данных, устанавливать и снимать режим работы "только чтение".
Инструмент gfix выполняется в режиме командной строки и имеет следующий синтаксис:
gfix [ options] db_name
Options - это набор опций для выполнения gfix, a db_name - имя базы данных, над которой будут производиться операции, определенные набором опций. В таблице 4.11 представлены опции gfix, относящиеся к "починке" базы данных:
Табл 4.11. Опции инструмента gfix для восстановления базы данных
|
Опция |
Описание опции | ||
|
-f[ull] |
Используется в сочетании с -v и означает, что необходимо проверять все фрагменты записей | ||
|
-i[gnore] |
Заставляет gfix игнорировать ошибки контрольных сумм во время проверки или очистки базы данных | ||
|
-m[end] |
Отмечает поврежденные записи как недоступные, в результате чего они удалятся при последующем backup/restore. Опция применяется во время подготовкой поврежденн базы данных к b/r | ||
|
-n[o_update] |
Используется в сочетании с -v для read-only-проверки базы данных, без исправления повреждений | ||
|
-password] |
Позволяет задать пароль при подключении к базе данных | ||
|
-user name |
Позволяет задать имя пользователя при подключении к базе данных | ||
|
-v[alidate] |
Задает проверку базы данных, в ходе которой обнаруживаются ошибки в структуре | ||
|
-m[ode] |
Устанавливает режим записи для базы данных - только для чтения или чтение/запись. Этот параметр может принимать два значения: read_write или read_only | ||
|
-w[rite] {sync | async} |
Включает/выключает режимы синхронной/асинхронной записи (forced writes) в базу данных: sync - включить синхронную запись (FW ON); async - включить асинхронную запись (FW OFF) |
Вот несколько типичных примеров использования gfix:
gfix w sync firstbase.gdb
В этом примере мы устанавливаем для нашей тестовой базы данных firstbase.gdb режим синхронной записи (FW ON).
gfix -v -full firstbase.gdb
В этом примере мы запускаем проверку нашей тестовой базы данных (опция -v), причем указываем, что необходимо проверить также фрагменты записей (-full).
Конечно, назначать различные опции для процесса проверки и восстановления удобнее с помощью какого-нибудь графического инструмента администрирования, но мы будем рассматривать функции восстановления базы данных с точки зрения применения именно инструментов командной строки. Эти инструменты входят в поставку InterBase, и можно быть уверенным, что они буд>т вести себя одинаково во всех ОС, поддерживаемых InterBase. He менее важен тот факт, что они всегда окажутся под рукой. Кроме того, существующие инструменты, позволяющие выполнять администрирование баз данных с клиентского компьклера, используют для этого Services API, которое не поддерживается серверами InterBase с архитектурой Classic. To есть вы сможете использовать сторонние продукты только с серверами архитектуры SuperServer.
InterBase Classic Server под Linux
Корневой каталог InterBase CS содержит несколько подкаталогов и файлов, которые описаны в таблице 4.19. Часть из них имеет то же самое название и назначение, что и в InterBase SS под Windows, поэтому подробно такие файлы описывать не будем.
Табл 4.19. Состав InterBase CS для Linux
|
Каталог или файл |
Краткое описание | ||
|
/bin |
Исполняемые модули InterBase, а также различные утилиты. См. ниже раздел "Каталог BIN для Classic Server" | ||
|
/doc |
Документация по InterBase - обычно содержит последние замечания, список исправленных и неисправленных ошибок и т. д. | ||
|
/examples |
Примеры использования InterBase API на С | ||
|
/help |
В этом каталоге находится база данных help. gdb, которая содержит краткую справку о командах и ключевых словах InterBase SQL | ||
|
/include |
Содержит заголовочные файлы для С, которые могут быть использованы, например, разработчиками на GNU С | ||
|
/intl |
Содержит gdsintl - библиотеку, содержащую информацию о кодировках (аналогично GDSINTL.DLL под Windows) | ||
|
/lib |
Каталог содержит клиентские библиотеки libgs.so и libib_util.so, которые являются аналогами gds32.dll и ib_ util.dll в Windows. Также в этом каталоге находится библиотека libgs.a, которая представляет собой библиотеку для статической сборки клиента | ||
|
/misc |
Каталог содержит Firebird. xinetd - файл конфигурации для менеджера сервисов xinetd, в котором описаны параметры клона InterBase 6.x Firebird | ||
|
/UDF |
Каталог, в котором должны находиться UDF-библиотеки пользователя. По умолчанию содержит только библиотеку ib_udf | ||
|
isc4 gdb |
База данных пользователей InterBase | ||
|
isc_config |
Файл, хранящих настройки конфигурации для InterBase; аналогичен файлу ibconfig в версии InterBase под Windows | ||
|
isc_eventl .teststation |
Файл, который содержит список событий Используется менеджером блокировок | ||
|
iscjockl. teststation |
Файл, который содержит таблицу блокировок. Используется менеджером блокировок | ||
|
InterBase log |
Файл протокола InterBase | ||
|
InterBase msg |
! Файл сообщений InterBase | ||
|
services, isc |
Файл, который содержит информацию о соответствии номера порта имени сервиса, который будет использоваться для InterBase (обычно постановка в соответствие выглядит как gdsdb/tcp 3050). Эту постановку в соответствие необходимо добавить в файл /etc/services (обычно автоматически добавляется установщиком InterBase) |
Рассмотрев икра те состав InterBase Classic Server для Linux, рассмотрим теперь более подробно состав каталога BIN в этой версии. Он отличается в основном программными модулями, специфичными для архитектуры Classic.
InterBase как встраиваемая СУБД
Материал этой главы будет посвящен углубленному рассмотрению процесса установки Intel Base и его клонов на ОС Windows. В этой главе мы попытаемся понять, что значит определение "встроенная" (embedded) СУБД, которое так часто используют по отношению к InterBase.
Почему изложение материала этой главы ориентировано на ОС Windows? Что бы ни говорили поклонники Linux, но наиболее значительный процент серверных инсталляций InterBase осуществляется именно под Windows, а что касается количества клиентских установок, то ОС Windows здесь вообще вне конкуренции. Поэтому мы рассмотрим вопросы встраивания InterBase именно в Windows-приложения
Легковесность и простота администрирования делают InterBase идеальным кандидатом для создания тиражируемых программных систем, которые функционируют по принципу "установил и забыл". СУБД в таком приложении играет "закулисную" роль - в идеале пользователь не должен ничего знать о том, какая СУБД обслуживает его запросы. К встроенной СУБД предъявляются высокие требования по надежности и особые условия администрирования, сводящие к минимуму участие администратора СУБД.
Чтобы разобраться в сущности "встраивания" InterBase в приложения баз данных, необходимо более подробно изучить процессы, протекающие при обычной штатной установке сервера и клиента InterBase Разобравшись в сути процессов установки, легко будет перейти к созданию собственных установщиков Intei Base, которые можно будет встроить в собственные программы
Все процессы установки рассматриваются на примере клона InterBase 6.х - Firebird 1.0.
InterBase Super Server для Windows
Итак, что попадает на компьютер в результате установки сервера InterBase SuperServer под Windows? Чтобы это выяснить, необходимо изучить содержание установочного каталога InterBase. Таблица 4.16 коротко описывает назначение каталогов и файлов, входящих в состав InterBase SS.
Табл 4.16. Каталоги и файлы в установочном каталоге IB SS for Windows
|
Каталог или файл |
Краткое описание | ||
|
Каталоги | |||
|
BIN |
Содержит набор исполняемых файлов, которые реализуют все основные функции InterBase-сервера. Подробнее см. ниже в разделе "Каталог BIN для SuperServer" | ||
|
HELP |
В этом каталоге находится база данных help.gdb, которая содержит краткую справку по командам и ключевым словам InterBase SQL | ||
|
INCLUDE |
Содержит несколько заголовочных файлов на языке С, которые могут быть использованы разработчиками, желающими напрямую использовать InterBase API | ||
|
INTL |
В каталоге находится динамическая библиотека gdsintl dll, которая содержит международные наборы символов и информацию о сопоставлении международных символов (collation). Подробнее о поддержке международных (и русских в том числе) символов см. главу "Русификация InterBase" (ч. 1) | ||
|
LIB |
В этом каталоге находятся файлы *.lib, это библиотеки, которые будут полезны разработчикам баз данных, работающих с InterBase на Borland C++ и MSVC++ | ||
|
UDF |
Важный каталог, который содержит динамические библиотеки, реализующие UDF (User Defined Functions). Библиотеки UDF для InterBase 6.x и всех его клонов должны находиться именно в этом каталоге. Подробнее об UDF см. главу "User Defined Functions" (ч. 1). При установке в UDF записывается библиотека ib_udf.dll, которая содержит множество полезных функций | ||
|
Файлы в корневом каталоге | |||
|
Ibconfig |
Файл настроек InterBase-сервера. Позволяет влиять на производительность и работу сервера. Подробнее о возможных настройках сервера см. главу "Оптимизация работы InterBase" (ч. 4) | ||
|
ibinstall dll |
Динамическая библиотека, реализующая IB Install API | ||
|
lnterBase.log |
Файл протокола (лог), куда InterBase-сервер записывает все предупреждения и ошибки, возникающие в процессе работы. При возникновении любых проблем с работой СУБД InterBase следует обязательно просмотреть этот файл, а лучше всего это делать регулярно. Если проблем с базой данных нет, то лог увеличивается очень медленно и содержит в основном отметки о запуске guardian-процесса и завершении сервера. Если же размер InterBase log растет очень быстро, то это свидетельствует о проблемах (возможно, скрытых) с базой данных или с аппаратным обеспечением | ||
|
InterBase. msg |
Файл содержит каталог сообщений о проблемах и ошибках, которые InterBase возвращает пользователю | ||
|
Isc4 gdb |
Это база данных пользователей данного InterBase-сервера | ||
|
license txt |
Файл содержит лицензионное соглашение Наличие этого файла необходимо для работы сервера | ||
|
ReleaseNotes.pdf |
Краткие замечания по той версии InterBase, которая у вас установлена. Файл в формате Adobe Acrobat Reader. Обычно содержит массу полезной информации об устанавливаемой версии, поэтому рекомендуется обязательно прочитать его | ||
В таблице 4.16 приведен краткий обзор файлов и каталогов, входящих в установку InterBase SuperServer для Windows. Надо заметить, что данные в таблице приведены для случая полной установки сервера. Если же вы отказались во время установки от некоторых предлагаемых опций, то в своем установочном кагалоге вы можете не наблюдать некоторые каталоги и файлы, описываемых в таблице. В связи с этим следует прояснить вопрос, что действительно критически важно для работы сервера, а чем можно пожертвовать. Ниже мы рассмотрим вопрос о минимально необходимом объеме установки сервера и клиента, а пока перейдем к подробному рассмотрению файлов, находящихся в каталоге BIN, содержащем основные исполняемые модули InterBase
Как правильно раздавать и аннулировать права
Предыдущее разделы описывали практические примеры раздачи и аннулирования на объекты базы данных. Однако система безопасности - это всегда иерархическая система, в которой есть более ответственные пользователи, раздающие различные права менее ответственным.
Сейчас настало время прояснить схемы раздачи прав. Прежде всего необходимо ввести понятие владельца объекта (owner). Владелец объекта - это тот, кто создал его. Если пользователь TESTUSER создал какую-то таблицу, то он является владельцем этой таблицы.
Обычно все объекты в период разработки базы данных создаются одним пользователем - SYSDBA. С применением этого же пользователя, как правило, производится вся разработка клиентского приложения. В результате получается, что все объекты всегда доступны. Когда появляется необходимость ввести разграничения по пользователям, необходимо регулировать множество прав, причем не всегда можно заранее сказать, какие права и на какие объекты могут понадобиться для нормальной работы приложения. Из-за этого начинающие разработчики часто считают права на объекты "излишеством" и стараются придумать собственные системы безопасности, не утруждая себя изучением уже существующей. Если вы не хотите попасть в их число, то мы рекомендовали бы вам попытаться разобраться в этой ситуации.
Итак, по умолчанию права на любой объект в InterBase, будь то таблица, представление или хранимая процедура, имеет только его владелец, а также системный администратор SYSDBA. Соответственно раздавать права по умолчанию может только владелец объекта. Любой другой пользователь, не являющийся владельцем объекта, не сможет выдать другому пользователю права на этот объект, если только владелец объекта не передал другому пользователю соответствующие права со специальной опцией WITH GRANT OPTION. Указание этой опции в конце обычного предложения GRANT означает, что пользователь не только получает эти права, но и сможет передавать их другому пользователю Например:
GRANT Select ON Table_example TO testuser WITH GRANT OPTION;
Теперь пользователь testuser может не только выбирать записи из таблицы Table_example, но также передавать право Select (и только его!) другим пользователям.
Если теперь пользователь testuser выдаст права пользователю newuser, затем владелец базы данных отберет право на SELECT у пользователя testuser. то автоматически newuser также потеряет права на Select. To есть все права, выданные пользователем testuser, будут аннулированы.
Для того чтобы не возникало проблем с правами, после этапа активного изменения метаданных лучше всего отказаться от использования SYSDBA как основного пользователя, а создать "специального" пользователя и применять его для разработки клиентского приложения.
Карта миграции
В этом разделе мы рассмотрим, как осуществить процесс миграции с одной версии InterBase на другую. В таблице 4.6 представлены карта возможных переходов с одной версии InterBase на другую.
Под прямой миграцией понимается процесс, включающий backup на системе- исгочнике и восстановление на системе-приемнике.
Прямая миграция - это процесс перехода между версиями, который включает следующие этапы backup (с контрольным restore) - > Установка новой версии IB -> Перенос пользователей -> lestore.
Табл 4.6. Карта миграции
|
НА ВЕРСИЮ |
С ВЕРСИИ | ||||||||
|
InterBase 4.x |
InterBase 5.x |
InterBase 6.x и клоны (диалект база данных 1) |
InterBase 6 х и клоны (диалект база данных 3) | ||||||
|
InterBase 4.x |
Да |
Особый процесс |
Особый процесс |
Нет | |||||
|
InterBase 5.x |
м |
Да |
Особый процесс |
и | |||||
|
InterBase 6.x и клоны (диалект база данных 1) |
и |
и |
Да |
и | |||||
|
InterBase 6.x и клоны (диалект база данных 3) |
Нет |
Нет |
и |
Да | |||||
В случае, если перенос между версиями возможен в виде прямой миграции, в ячейке, соответствующей переходу (пересечению графы и строки) с версии- источника на версию-приемник, ставится "Да". Версия-источник выбирается в заголовке таблицы, версия-приемник - в боковике таблицы. В трех ячейках, соответствующих переходу со старшей версии на младшую, стоит "Особый процесс". Это означает, что процесс миграции возможен с применением особого приема, который мы рассмотрим ниже. Обратите внимание, что переход на версию 6.x с диалектом 3 невозможен с помощью прямой миграции. Для установки диалекта 3 применяется инструмент командной строки gfix (подробнее см. ниже, в разделе "Перевод базы данных InterBase 6.x на 3-й диалект").
Каталог BIN в InterBase Classic Server для Linux
Как будет ясно из главы "Classic и SuperServer", в Classic-архитектуре состав основных исполняемых файлов InterBase меняется - к нему добавляется менеджер блокировок и различные утилиты для управления InterBase. Файлы в каталоге Вт описаны в таблице 4 20.
Табл 4.20. Файлы в каталоге Bin InterBase CS для Linux
|
Файл |
Описание файла | ||
|
changeDBAPassword.sh |
Полезные скрипты на языке shell для некоторых действий: | ||
|
CSchangeRunUser sh |
смены пользователя SYSDBA, смены пользователя, | ||
|
CSrestoreRootRunUser.sh |
с правами которого запускается InterBase | ||
|
gbak |
Утилита резервного копирования и восстановления | ||
|
gdef |
Утилита, позволяющая создавать и изменять метаданные | ||
|
gds_drop |
Утилита, которая останавливает InterBase | ||
|
gds_met_server |
Основной исполняемый файл InterBase в Classic-версии InterBase | ||
|
gds_lock_mgr |
Менеджер блокировок | ||
|
gds_lock_print |
Утилита, применяющаяся для анализа таблицы блокировок | ||
|
gds_pipe |
Утилита, предназначенная для поддержки приложений, использующих POSIX-сигналы | ||
|
gfix |
Утилита модификации и восстановления базы данных | ||
|
gpre |
Препроцессор С для разработчиков на InterBase API | ||
|
gsec |
Утилита управления базой данных пользователей isc4.gdb | ||
|
gsplit |
Утилита для разделения/слияния одного большого файла базы данных в/из нескольких | ||
|
gstat |
Утилита для анализа статистики по базам данных InterBase | ||
|
isc4 gbak |
База данных пользователей InterBase | ||
|
isql |
Interactive SQL - утилита для ввода команд SQL и исполнения SQL-скриптов | ||
|
qli |
Query Language Interpretator - интерпретатор языка GDML |
Каталог BIN в SuperServer
Мы рассмотрим только те файлы, которые относятся непосредственно к самому серверу. Если во время установки вы пожелали поставить ряд инструментов администратора и разработчика, например, таких, как IBConsole, то в каталоге Bin может оказаться больше файлов, которые связаны с этими дополнительными программами.
Табл 4.17. Файлы в каталоге BIN IB SS nog Windows
|
Файл |
Краткое описание файла | ||
|
ibguard.exe |
Это guardian - процесс-хранитель InterBase. Его назначение - вновь запускать InterBase в случае сбоя. Надо отметить, что в Windows 2000 можно обойтись и без "гвардейца", так как ОС самостоятельно может перезапускать InterBase | ||
|
ibserver exe |
Собственно это и есть сам InterBase-сервер. Различные клоны InterBase 6.x: Firebird и Yaffil тоже называют свой основной файл ibserver.exe | ||
|
ib_ufil.dll |
Динамическая библиотека, которая содержит функции, расширяющие возможности InterBase, в частности функции управления памятью, которые необходимы для работы многих UDF | ||
|
gbak.exe |
Утилита командной строки, которая применяется для осуществления резервного копирования и восстановления из резервной копии. Подробнее о gbak см. главу "Резервное копирование и восстановление из резервной копии" (ч 4) | ||
|
gfix.exe |
Утилита командной строки, применяющаяся для модификации и починки базы данных. Подробнее см. главу "Починка базы данных" (ч. 4) | ||
|
gsec exe |
Утилита командной строки, применяющаяся для управления базой данных пользователей InterBase. Она дает возможность добавлять, удалять и изменять пользователей. Подробнее см. главу "Безопасность в InterBase: пользователи, роли и права" (ч. 4) | ||
|
gstat exe |
Утилита командной строки, которая служит для сбора статистики по базе данных | ||
|
iblockpr.exe |
Утилита, которая анализирует таблицу блокировок. Информацию о таблице блокировок вы можете почерпнуть из приложения "Параметры конфигурационного файла InterBase" | ||
|
isql exe |
ISQL - Interactive SQL Интерпретатор SQL, реализованный как утилита командной строки, который может как работать в интерактивном режиме, так и выполнять файлы SQL-скриптов | ||
|
gpre.exe |
Препроцессор С, который будет полезен разработчикам, использующим InterBase API | ||
|
gdef.exe |
Утилита, позволяющая создавать и изменять метаданные | ||
|
gds32.dll |
Динамическая библиотека, которая позволяет клиентам связываться с InterBase-сервером. Собственно эта библиотека и является клиентом InterBase | ||
|
instreg.exe |
Утилита командной строки, которая прописывает или удаляет из реестра Windows необходимые ключи, связанные с InterBase. Обычно эта утилита используется лишь программой-установщиком InterBase во время процесса установки и удаления InterBase | ||
|
instsvc.exe |
Утилита, которая используется для установки InterBase в качестве сервиса NT/2000. Обычно применяется только программой- установщиком InterBase. | ||
|
qli.exe |
QLI - Query Language Intepretator - интерпретатор языка GDML. Используется как для интерактивного выполнения команд GDML, так и для выполнения скриптов |
Кеш базы данных
Кеш базы данных служит для хранения наиболее часто используемых страниц из базы данных. Его размер исчисляется в страницах и может быть установлен тремя разными способами:
Заданием параметра файла конфигурации ibconfig DATABASE CASHE PAGES. При этом устанавливается значение кеша для каждой базы данных, обслуживаемой данным сервером; это означает, что для каждой подключенной базы данных будет распределен кеш указанного в данном параметре размера. Это не слишком гибкий способ, поэтому им обычно не пользуются, если компьютер-сервер обслуживает более одной базы данных. Этот параметр имеет следующие значения по умолчанию: InterBase 6 Classic (Linux) - 75, InterBase 6 SuperServer (Windows) - 2048, a InterBase 5.x - 256. Причем надо отметить, что для Classic устанавливается размер кеша для КАЖДОГО клиентского соединения.
Установкой количества страниц для каждой индивидуальной базы данных с помощью инструмента gfix. Например, выполнение команды gfix -buffers 8192 для какой-либо базы данных приводит к тому, что все соединения к этой базе данных будут использовать кеш размером 8192 страницы. Помните, что версия Classic использует значение размера кеша для каждого клиентского соединения; поэтому не стоит устанавливать размер кеша в Classic более 2048 страниц (даже если у вас несколько гигабайтов ОЗУ). Необходимо отметить, что при создании базы данных задать размер кеша на уровне базы данных невозможно, - он устанавливается позже с помощью gfix.
Установкой параметра функции InterBase API isc_dpb_num_buffers при соединении с базой данных.
Перечисленные способы установки идут в порядке возрастания приоритета, т. е. значения последних вариантов на практике надо использоваться в первую очередь. Тем не менее известный разработчик InterBase Ivan Prenosil вносит поправки в это утверждение, считая, что установка кеша на уровне базы данных имеет наивысший приоритет и не может быть переопределена даже на уровне соединения.
Теперь о конкретных цифрах. Размер кеша может принимать значения от 50 до 65535 страниц. Чтобы посчитать, как много оперативной памяти потребует кеш базы данных, надо умножить размер страницы базы данных на размер кеша. Например, если страница имеет размер 8192 байта, а кеш имеет размер 5000 страниц, то потребуется 40960000 байт ОЗУ (около 40 Мбайт), чтобы вместить этот кеш. Несмотря на то что сейчас ОЗУ стоит достаточно дешево и экономить на нем не стоит, устанавливать размер кеша базы данных более 10000 страниц не следует, это вытекает из тестов, которые показывают уменьшение производительности InterBase при большом размере кеша. Помимо тестов, с результатами которых вы можете познакомиться на сайте www.ibase.ru. Ivan Prenosil указывает на малоизвестный факт: большой размер кеша заметно увеличивает время соединения с базой данной, и чем больше кеш, тем больше времени затрачивается на установку соединения. Правда, в Yaffil эта проблема решена.
Клиенты 3-го диалекта
Переведя базу данных на 3-й диалект, необходимо также перевести на него и клиентские приложения. Обычно в параметрах подключения к базе данных необходимо указывать диалект, с помощью которого будет производиться работа с базой данных. Некоторые библиотеки доступа к InterBase, например ffiProvider, автоматически определяют диалект базы данных и самостоятельно выставляют нужные параметры подключения.
Установив параметры подключения, необходимо привести в соответствие с правилами 3-го диалекта текст SQL-запросов, содержащихся в клиентском приложении. Необходимо изменить все ключевые слова в текстах запросах согласно тем изменениям в базе, которые были произведены во время миграции.
Также необходимо позаботиться о хранении больших целых чисел (хранящихся с использованием механизма INT64), если таковые присутствуют в базе данных и используются в качестве параметров или результатов запросов.
Ключевые слова
Новые ключевые слова могли быть использованы в базе данных, созданной в InterBase 4.x или 5.x, в качестве идентификаторов каких-либо объектов. Для перехода к диалекту 3 необходимо переименовать эти объекты, например YEAR -> YEAR 1 или YEAR->"year" (в 3-м диалекте ключевые слова могут быть идентификаторами, если они заключены в двойные кавычки) При смене диалекта базы данных лучше не использовать кавычки для разрешения конфликтов с ключевыми словами: разработчику надо привыкнуть к такому стилю работы и запомнить, что "Year", "YEAR" и "year" - разные идентификаторы.
Ключи в реестре для клиента InterBase
После установки клиента InterBase необходимо зарегистрировать его в Windows, чтобы дать другим приложениям возможность его использовать. Это делается путем записи определенных значений в реестре Windows. В таблице 4.1 представлены все значения ключей в реестре, которые необходимо установить после установки клиента.
Табл 4.1. Реестровые ключи для установки InterBase
|
Ключ |
Значение | ||
|
HKEY_LOCAL_MACHINE\SOFTWARE\Borland\ InterBaseXCurrent VersionXRoot Directory |
Установочный каталог InterBase. Например: C:\Program FilesXFirebirdX | ||
|
HKEY_LOCAL_MACHINE\SOFTWARE\Borland\ InterBaseXCurrent VersionXVersion |
Версия библиотеки gds32.dll. Например, версия может быть WI-T6.2.679 Firebird 1.0 Final Release |
Если вам нужен установщик для инсталляции InterBase в рамках установки своего программного обеспечения, то можно либо создавать эти ключи самостоятельно, написав для этого специальную программу, либо воспользоваться утилитой instreg.exe из состава InterBase-сервера, которая пропишет эти значения в реестре.
Ключи в реестре для сервера InterBase
При установке сервера, помимо записей о регистрации совместно используемых файлов, необходимо создать ключи в реестре. Например:
[HKEY_LOCAL_MACHINE\SOFTWARE\Borland\InterBase\CurrentVersion]
"Version"="WI-T6.2.679 Firebird Final Release 1.0"
"RootDirectory"="C:\\Program Files\\Firebird\\"
"GuardianOptions"="1"
"ServerDirectory"="C:\\Program Files\\Firebird\\bin"
"DefaultMode"="-r"
Параметры RootDirectory и Version уже знакомы нам - они описаны в установке клиента InterBase и имеют то же самое значение для сервера.
Параметр "DefaultMode"="-r" означает, что InterBase-сервер будет запускаться в режиме сервиса NT/2000/XP. Если нужно запускать InterBase в режиме приложения, то необходимо указать ключ "-а".
Ключ "GuardianOptions"="l" говорит о том, что необходимо запускать процесс-хранитель InterBase - ibguard.exe. Однако в рассматриваемый нами пример минимальной установки "гвардеец" не входит - и поэтому этот параметр может быть либо опущен, либо установлен в 0.
Параметр "ServerDirectory"="C:\\Program Files\\Firebird\\bin" указывает на каталог, из которого запускается ibserver.exe.
Копирование файлов
Как описано ниже в главе "Состав модулей InterBase", минимальный корректный клиент InterBase состоит из трех файлов - gds32.dll, interbase.msg и msvcrt.dll.
Опытные специалисты могут заявить, что абсолютный минимум - это библиотека gds32.dll, которую можно положить в тот же каталог, в котором находится и приложение. Однако для 100 %-ной гарантии правильной установки клиента необходимо все же копировать как минимум 3 файла.
Давайте рассмотрим назначение файлов в этом минималистском варианте установки, которого будет достаточно для работы большинства приложений.
В файле interbase.msg находятся тексты сообщений об ошибках сервера и клиента. Необходимо, чтобы этот файл имел ту же версию, которую имеет и библиотека gds32.dll. Этот файл устанавливается в установочный каталог InterBase.
Файл msvcrt.dll - это одна из самых банальных динамических библиотек, которая почти всегда имеется в системе Windows. InterBase 6.x требует, чтобы версия этой библиотеки была 5.00.7303 или старше. Обычно этот файл устанавливается в системный каталог Windows.
Самым важным файлом является динамическая библиотека gds32.dll, в которой сосредоточена вся основная функциональность, называемая нами "клиентом InterBase". Поэтому установке файла gds32.dll следует уделить особое внимание.
Прежде чем установить gds32.dll на компьютер, необходимо убедиться, что на компьютере нет другой копии этой динамической библиотеки. Для этого необходимо осуществить поиск этого файла в следующих каталогах: системном каталоге Windows (это Windows\System для 9х ОС и Winnt\System32 для NT/2000); в установочных каталогах InterBase 4.x, 5.x и 6.x; в установочном каталоге BDE, а также во всех каталогах, которые включены в переменную среды PATH.
Если будет найдена копия gds32.dll в одном из перечисленных каталогах, то необходимо выяснить ее версию и сравнить с версией gds32.dll, которую вы устанавливаете.
Если устанавливаемая gds32.dll имеет версию новее, чем у существующей библиотеки, то можно произвести замену старой версии на новую. При этом желательно предупредить пользователя о том, что совершается замена. Однако ни в коем случае нельзя заменять новую версию более старой! Это связано с тем, что новые версии библиотеки gds32.dll смогут взаимодействовать со "старыми" версиями сервера InterBase, но не наоборот!
Если решение об установке gds32.dll было принято, то рекомендуется поместить ее в системный каталог Windows.
Копирование файлов сервера
Здесь приведен пример для установки InterBase архитектуры SuperServer, как наиболее распространенный случай. При установке сервера копируются файлы, список которых и место назначения приведены в табл. 4.2.
Табл 4.2. Файлы для установки InterBase-сервера
|
Файл |
Описание файла |
Куда копировать | |||
|
ibserver.exe |
Основной исполняемый файл InterBase |
<lnterBase_root>\Bin | |||
|
ibconfig |
Файл конфигурации InterBase |
< 1 nterBase_root> | |||
|
isc4 gdb |
База данных пользователей InterBase |
<lnterBase_root> | |||
|
license txt |
<lnterBase_root> | ||||
|
ib_license.dat |
<lnterBase_root> | ||||
|
gds32 dll |
Клиентская библиотека |
<lnterBase_root>\Bin/ системный каталог Windows | |||
|
InterBase. msg |
Файл сообщений InterBase |
<lnterBase_root> | |||
|
Msvcrt.dll |
Динамическая библиотека |
Системный каталог Windows |
Вы можете заметить, что последние 3 файла идентичны файлам, копируемым при клиентской установке. Единственное отличие - gds32.dll копируется также в каталог <InterBase_root>\Bin, вместе с основным исполняемым файлом ibscrver.cxe. Это служит дополнительной гарантией того, что ibserver.exe при запуске обнаружит gds32.dll той же самой версии, что и у него самого.
При копировании входящих в состав клиента файлов gds32.dll, InterBase.dll и msvcrt.dll, необходимо соблюдать те же самые условия, что и при клиентской установке.
Далее обязательно необходимо скопировать файлы ibserver.exe, ibconfig и isc4.gdb. Их назначение описано в главе "Состав модулей InterBase" этой части.
Необходимо отметить, что в случае установки поверх уже существующего сервера ни в коем случае нельзя затирать существующую базу данных пользователей Isc4.gdb.
Также весьма важен вопрос о копировании файлов лицензионного соглашения и файлов с лицензиями. Если вы ставите бесплатную версию InterBase 6.x или его клона, то достаточно скопировать в <InterBase_root> файл с лицензионным соглашением InterBase Public License - LICENSE.TXT. Если же вы устанавливаете платную версию InterBase 6.x (например - InterBase 6.5), то также необходимо скопировать в <InterBase_root> файл лицензий ib_license.dat.
Логическая структура базы данных InterBase
Логическая структура - понятие достаточно расплывчатое, поэтому мы попробуем постепенно освоить ключевые идеи, надеясь, что позже они создадут интуитивно понятное ощущение. Первое, что мы рассмотрим из относящегося к логической структуре базы данных, это системные таблицы и их содержимое.
Системные таблицы описывают метаданные, как системные, так и пользовательские. Вообще говоря, термин "метаданные" означает "данные, описывающие множество данных". Приставка "мета-" означает "описывает множество". Например, метаязык - это язык, описывающий множество языков. Метаданные описывают пользовательские данные, т. е. таблицы, триггеры, представления, хранимые процедуры и т. д. - все, что реализует правила хранения и обработки той информации, ради хранения и обработки которой и создается конкретная база данных.
Довольно забавно в первый раз узнать, что все метаданные, - как пользовательские таблицы, триггеры, представления, так и все системные объекты, - хранятся в таких же точно таблицах, из которых можно читать и писать данные с помощью обычных SQL-запросов. Эти таблицы "визуально" отличаются только тем, что их имена начинаются с RDB$. Эти 4 символа зарезервированы для имен системных объектов, ни одна пользовательская таблица, столбец или другой объект не имеют права обладать именами, начинающимися с этих символов. Формально ничто не мешает создать вам таблицу, название которой начинается с зарезервированных символов, однако документация InterBase настойчиво не рекомендует этого делать.
Возникает вопрос: если данные о структуре таблиц базы данных хранятся в точно таких же таблицах, как и пользовательские, то где хранится информация о самих этих таблицах, которые описывают таблицы? Классический пример проблемы "курицы и яйца" - как одно могло появиться раньше другого, если они взаимозависимы? Решение состоит в том, что системные таблицы в их первозданном состоянии "прошиты" в исходных кодах InterBase и автоматически разворачиваются при создании базы данных в определенном порядке.
Дело в том. что логическая структура базы данных состоит не только из таблиц, но и из других объектов. В InterBase существуют следующие объекты:
Table (таблица);
View (представление);
Trigger (триггер);
Computed_field (вычисляемое поле);
Validation (проверка);
Procedure (процедура);
Epression_index (вычисляемый индекс);
Exception (исключение);
User (польюватель),
Field (поле);
Index (индекс);
Usei-Defined Function (UDF) - функция, определяемая пользователем.
Пока, может быть, не совсем очевидно назначение некоторых из этих объектов, но ясно, что их необходимо описывать и хранить в некотором виде, удобном как для пользователя, так и для доступа из ядра InterBase. Лучше всего это сделать, сохранив все эти объекты в системных таблицах. Их добавление и модификация производятся с помощью SQL-запросов. Не правда ли, элегантное решение9
Реализация сервера полностью отделена от конкретной базы данных — все взаимосвязи описываются SQL и его расширениями - языком хранимых процедур и триггеров.
Итак, все объекты сервера хранятся в таблицах. Для каждого вида объектов существует таблица, описывающая все экземпляры, описанные в базе данных. Например, для триггеров есть таблица RDB$Triggers, для процедур - RDBSProcedures, а представления описываются в таблице RDBSRelations.
Рассмотрим подробнее структуру последней таблицы, описывающей все таблицы и представления в базе данных. Структура таблицы RDBSRELATIONS вта из Language Reference for InterBase 6 и приведена в Табл 4 25
Табл 4.25. Системная таблица RDB$Relations
|
Колонка |
Тип данных |
Длина |
Описание |
|
RDB$VIEW_BLR |
BLOB |
80 |
BLR: Для представлений (view), содержит BLR (Binary Language Representation) запроса, который InterBase осуществляет каждый раз, когда идет обращение к представлению |
|
RDB$VIEW SO URGE |
BLOB |
80 |
Текст: Для представлений содержит код SQL-запроса, который реализует это представление |
|
RDB$ DESCRIP TION |
и |
80 |
Пользовательское описание таблицы или представления |
|
RDBSRELATIO NJD |
SMALLINT |
Содержит внутренний идентификатор таблицы/представления |
|
|
RDB$SYSTEM FLAG |
II |
Определяет тип содержимого таблицы: Пользовательские данные - 0; Системная информация > 0 |
|
|
RDB$DBKEY LE NGTH |
N |
Длина db$key |
|
|
RDB$FORMAT |
II |
Зарезервировано для внутреннего использования InterBase Содержит счетчик изменений метаданных для данной таблицы |
|
|
RDB$FIELD_ID |
u |
Число полей в таблице |
|
|
RDB$RELATIO N_NAME |
CHAR |
31 |
Уникальное имя таблицы |
Миграция
Под миграцией базы данных InterBase понимается несколько разных вещей - это и перенос существующей базы данных между различными версиями InterBase (например, с 4.x на 6.x), и смена ОС, под управлением которой функционирует сервер, и смена диалекта базы данных. Мы рассмотрим в этой главе все эти типы миграции и предоставим рекомендации по их безопасному осуществлению. Также будут рассмотрены варианты отката (обратной миграции) с новых версий InterBase на предыдущие.
Минимальный состав сервера InterBase SuperServer
Как видите, довольно большой список файлов. Просмотрев таблицу, можно кратко уяснить назначение каждого файла, однако вопрос "отделения зерен от плевел" остался открытым. Конечно, все перечисленные утилиты важны и являются неотъемлемой частью InterBase. Но какие же файлы содержат основную, базовую функциональность InterBase-сервера?
Вот список файлов, составляющих минимальный сервер InterBase архитектуры SuperServer под Windows, который сможет нормально функционировать (табл. 4.18):
Табл 4.18. Минимальный набор файлов InterBase SS nog Windows
|
Файл |
Расположение |
Описание | |||
|
gds32 dll |
InterBaseXBin |
Клиентская библиотека InterBase | |||
|
ibserver.exe |
InterBaseXBin |
Основной исполняемый файл InterBase (и всех клонов) | |||
|
InterBase, msg |
InterBase |
Файл содержит сообщения сервера и клиента | |||
|
msvcrt.dll |
Windows\System или Winnt\System32 |
Динамическая библиотека Microsoft Visual С. Обычно уже имеется в ОС | |||
|
isc4.gdb |
InterBase |
База данных пользователей InterBase | |||
|
license.txt |
InterBase |
Файл лицензии. Для InterBase 6.x и его Open Source-клонов содержит IPL | |||
|
ib_license.dat |
InterBase |
Только для платных версий InterBase - сертифицированных билдов InterBase 6 х и версии InterBase 6.5 |
Надо отметить, что библиотека msvcrt.dll имеется на всех версиях Windows, кроме Windows 95, да и то в случае, если не установлено никаких пакетов обновления или хотя бы Microsoft Office. Файл сообщений InterBase.msg также не обязателен: если он будет отсутствовать, то некоторые сообщения об ошибках InterBase не будут корректно отображаться, но на работу сервера и клиентских приложений это не повлияет. Обратите внимание, что в случае необходимости поддерживать разнообразные кодировки необходимо включать в установку библиотеку gdsintl.dll! Без нее сервер InterBase работать будет, но без поддержки национальных языков.
Мост между физической и логической структурой базы данных
Мы рассмотрели в общих чертах физическую структуру файлов базы данных. Теперь надо перейти к логической структуре базы данных. Чтобы переход произошел без каких-то "предельных переходов" в понятиях, оставив после себя ощущение непонятности материала и желание перечитать главу с самого начала, давайте построим некий логический "мост" между физическим и логическим уровнями представления информации в базе данных.
Все. что хранится на различных страницах базы данных, необходимо как-то организовать в памяти компьютера, преобразовать данные из файла базы данных в совокупность внутрисерверных объектов и переменных. Эта совокупность называется внутренним образом базы данных (internal database image), по терминологии Анн Харрисон.
Итак, попробуем рассмотреть процесс построения внутреннего образа базы данных.
Сервер читает 1024 байта из начала файла и, если это действительно файл базы данных InterBase, определяет размер страницы этой базы и перечитывает всю заголовочную страницу целиком.
С заголовочной страницы сервер извлекает номер страницы указателей, на которой хранятся ссылки на страницы данных, определяющие таблицу RDB$Pages.
Сервер переходит к этой странице указателей и начинает считывать из указанных там страниц данных информацию. Он заполняет данными первую таблицу RDB$Pages. Эта таблица является чем-то вроде мостика между физическими объектами - страницами файлов базы данных и логическими - таблицами. Структура RDB$Pages, как и других системных таблиц, жестко "прошита" в InterBase.
Получив данные о распределении страниц по отношениям (relations, в сущности, это то же самое, что и обычные таблицы, и для упрощения можно мысленно подменять эти понятия), InterBase начинает формировать структуры данных: сначала системные таблицы, ограничения и индексы, а потом уже пользовательские объекты.
После инициализации системных и пользовательских метаданных (так называют таблицы, ограничения, индексы и все остальные объекты базы данных), InterBase возвращает пользователю, попросившему открыть базу данных, handle этой базы данных (некоторые используют термин "рукоятка" или просто транскрипцию английского слова - "хэндл"). В сущности, handle - это некоторый идентификатор, который указывает InterBase, с какой именно базой данных работать, поскольку одновременно могут работать несколько пользователей, а значит, могут быть открыты несколько баз данных.
После этих операций база данных считается открытой и сервер готов выполнять запросы пользователей к ней.
Теперь, когда проложен некоторый "мост", связывающий физическую и логическую структуру базы данных, можно переходить к особенностям логической структуры.
Next attachment ID
Идентификатор следующего подсоединения к базе данных. Вероятно, всегда равен нулю.
Next header page
Номер следующей заголовочной страницы. Всегда равен нулю. Собственно говоря, любая страница в базе данных имеет ссылку на номер следующей страницы такого же типа (см. ниже главу "Структура базы данных InterBase"), но так как заголовочная страница всегда единственная в каждом файле базы данных, то у нее эта ссылка обнулена.
Next transaction
Идентификатор следующей транзакции, которая будет запущена сервером.
Общие рекомендации по безопасности
Чтобы избежать взлома вашей системы, необходимо соблюдать простые рекомендации, которые значительно осложнят жизнь злоумышленнику, если он вдруг попытается добраться до вашей информации.
Для установки и функционирования сервера InterBase используйте промышленные ОС, в которых предусмотрена система безопасности. Это Windows NT/2UOO/XP, Lmux/Unix/Solans. Избегайте устанавливать сервер с важной информацией на домашние ОС - Windows 95/98/Ме. Конечно, для действительно защищенной системы необходимо наличие квалифицированного системного администратора, который должен контролировать все попытки доступа к компьютеру-серверу.
Используйте средства ОС для ограничения диапазона IP-адресов к компьютеру-серверу. Таким образом можно значительно осложнить атаку через Интернет.
Используйте нестандартный порт для работы с сервером InterBase. По умолчанию применяется порт 3050, но вы сможете изменить это значение на какое-то другое Номер используемого порта настраивается в файле services. В тгом спучае в строке соет.инения с базой чанных надо указать номер порта Например, л1я nopia 4671 строка соединения будет иметь вид srv:4671:Disk\Path\file.gdb. Такую возможность поддерживает все современные кюны InterBase 6 х Firebird 1 0. Yaffil I 0 и InterBase 6 5
Не устанавливайте сервер InteiBase по стандартному пути, предлагаемому установщиком, а также не используйте очевидные пути вроде "C:\IBServer". Это поможет осложнить хищение служебной базы данных ISC4.gdb, если злоумышленник получит удаленный доступ к серверу.
Не разрешайте совместное использование (shared access) по сети тех каталогов, которые содержат файлы баз данных Это не имеет никакого смысла (см раздел "Строка соединения" в главе "Создаем базу данных" (ч. 1)).
При работе на Windows NT/2000/XP используйте файловую систему NTFS. Установите разрешения файловой системы на файлы базы данных только для пользователя "SYSTEM" (или для того пользователя, под чьим именем выполняется серверный процесс InterBase - это можно узнать с помощью апплета "Службы" (Services) в панели управления Windows). Для подключения к базе данных InterBase по рекомендованному протоколу TCP/IP удаленный клиент базы данных должен иметь права только на операцию соединения с сервером. Другими словами, удаленный клиент не работает напрямую с файлами базы данных - с ними paботает только сам серверный процесс InterBase. Однако если удаленный клиент работает с InterBase под Windows по протоколу NetBeui (проще говоря, если в приложении используется строка соединения вида \\srv\Disk\Path\file.gdb) и файл базы данных расположен на диске с файловой системой NTFS, то для работы с базой данных этому клиенту потребуются разрешения NTFS на этот файл. Это замечание имеет смысл только для сетей на базе Windows NT.
Обзор основных причин повреждения базы данных
К сожалению, всегда существует ненулевая вероятность, что любое информационное хранилище будет повреждено и часть информации из него потеряна. Базы данных не исключение из этого правила. В этой главе мы рассмотрим основные причины, которые чаще всего приводят к повреждениям базы данных InterBase, рассмотрим несколько способов восстановления баз данных и извлечения из них информации. Также ознакомимся с рекомендациями и профилактическими действиями, которые позволят свести к минимуму риск потери информации из базы данных.
Прежде всего, раз мы говорим о починке базы данных, необходимо определиться с понятием "поломка базы данных". Обычно базу данных называют поврежденной, если при попытке извлечь или модифицировать содержащуюся в ней информацию возникают ошибки и/или извлекаемая информация оказывается утерянной, неполной или вовсе неправильной. Порой повреждения базы данных скрыты и обнаруживаются только при проверке специальными средствами, но бывают и явные поломки базы данных, когда к базе невозможно подсоединиться, когда отлаженные программы-клиенты выдают странные ошибки (в то время как никаких манипуляций над базой данных не производилось) или когда невозможно восстановить базу данных из резервной копии.
Основными причинами повреждения баз данных являются:
Аварийное завершение работы серверного компьютера, особенно отключение электропитания. Для российской информационной отрасли это настоящий бич, поэтому мы надеемся, что не нужно лишний раз напоминать о необходимости иметь на сервере источник бесперебойного питания.
Дефекты и неисправности серверного компьютера, особенно дисков, дисковых контроллеров, оперативной памяти компьютера и кеш-памяти RAID-контроллеров.
Некорректное соединение с многопользовательской базой данных одного или более пользователей. При соединении по протоколу TCP/IP путь к базе данных должен указываться servername:drive:/path/databasename (для серверов на платформе Unix servernameVpath/databasename), по протоколу NetBEUI \\servername\drive\path\databasename. Даже при соединении с базой с того же компьютера, на котором находится база и работает сервер, следует пользоваться точно такой же строкой, заменяя servername на localhost. Нельзя использовать mapped drive в строке соединения. При нарушении любого из этих правил сервер считает, что он работает с разными базами, и повреждение базы данных гарантировано.
Файловое копирование или другой файловый доступ к базе данных при запущенном сервере. Выполнение команды shutdown или отключение пользователей обычным порядком не является гарантией того, что сервер ничего не делает с базой; если sweep interval не установлен в 0, может выполняться sweep. Кроме того, после отключения последнего пользователя сервер выполняет уборку "мусора" Обычно на это уходит 1-2 мин. но. если перед этим выполнялось много операций delete или update, процесс может затянуться.
Использование нестабильных серверов InterBase 5.1-5.5. Компания Borland официально признала наличие в этих серверах серьёзных ошибок и выкладывала на своём сайте для бесплатного скачивания покупателями серверов 5.1 - 5.5 стабильный upgrade 5.6 убранный только после выпуска сертифицированного InterBase 6.
Превышение ограничения на размер файла базы. Для большинства существующих на момент написания этих строк серверов Unix-платформы это 2 Гбайт, для Windows NT/2000 - 4 Гбайт, но рекомендовано ориентироваться также на 2 Гбайт. При приближении размера базы к граничному значению должен быть создан дополнительный файл.
Исчерпывание свободного дискового пространства во время работы с базой.
Для Borland InterBase-серверов версий меньше 6.0.1.6 превышение ограничения на количество генераторов, по сообщению Borland InterBase R&D, определяемое следующим образом (см. таблицу 4.9).
Табл 4.9. Критическое количество генераторов в InterBase ранних версий
| Версия | Размер страницы, байт | ||
| 1024 | 2К | 4К | |
| Pre-V6 | 248 | 504 | 1016 |
| V6 | 124 | 257 | 508 |
Табл 4.10. Критическое количество транзакций в серверах Borland InterBase
|
Размер страницы базы данных, байт |
Критическое число транзакций |
|
1024 |
131 596287 |
|
2048 |
265814016 |
|
4096 |
534 249 472 |
|
8192 |
1 071 120 384 |
ODS version
Версия On-Disk structure - структуры базы данных InterBase. Представляет собой два числа, разделенные точкой. "Целая" часть - это основная версия ODS, которая зависит от версии сервера, создавшего данную базу данных. Главная версия определяет основные возможности работы с базой данных, и ее значение присваивается при создании (восстановлении) базы данных.
"Дробная" часть (после точки) - это минорная версия ODS, которая может меняться (точнее, увеличиваться) в течение жизни базы данных в зависимости от того, под управлением какой версии сервера работают с этой базой данных.
Oldest active и Oldest snapshot
Параметр Oldest active - идентификатор старейшей активной транзакции. Обычно его значение близко к значению Next transaction. Параметр Oldest snapshot в документации по InterBase 6 не описывается. Однако Анн Харрисон любезно разъяснила смысл этого параметра. Дело в том, что только транзакции с уровнем изоляции SNAPSHOT вызывают появление мусорных версий записей (gaibage) в базе данных, и этот параметр показывает номер последней транзакции snapshot, которая влияет на процесс сборки мусора.
Oldest transaction
Параметр Oldest transaction показывает идентификатор старейшей заинтересованной транзакции в базе данных. Значение этого параметра часто сравнивается с Next transaction Разница этих значений является важным показателем "здоровья" базы данных и косвенно указывает на положение дел со сборкой "мусора" в базе данных. Подробно "Oldest transaction" рассмотрена в главе "Транзакции Параметры транзакций" (ч. 1).
Оптимизация работы InterBase
В этой главе мы рассмотрим, какое аппаратное обеспечение следует использовать для InterBase, а также выясним возможности оптимизации InterBase- сервера и его клонов, разберем параметры конфигурационных файлов InterBase и их назначение.
Организация пользователей в группы с помощью ролей
Чтобы уменьшить количество выдаваемых разрешений и объединить пользователей в группу по принципу наличия у них одинаковых прав, применяется механизм ролей. Порядок действия для использования ролей следующий:
Необходимо создать роль.
Выдать этой роли достаточные права.
Назначить конкретным пользователям эту роль.
При подсоединении к базе данных указать, помимо имени пользователя, ту роль, права которой будет иметь в течение времени данного соединения пользователь. То, что роль явно указывается при подсоединении, позволяет иметь для каждого пользователя набор ролей и менять их при каждом сеансе в зависимости от характера выполняемой работы.
Приведем пример использования ролей Для начала создадим роль с именем READER, которая будет иметь права для чтения данных:
CREATE ROLE READER;
Выдадим этой роли права на чтение таблицы Table_example:
GRANT Select ON Table_example TO READER;
Присвоим эту роль пользователю TESTUSER, чтобы он мог указать ее при подсоединении к базе данных (если этого не сделать, то возникнет ошибка авторизации):
GRANT READER TO testuser;
Теперь мы можем указать эту роль при подсоединении к базе данных. Все современные библиотеки доступа, описанные в данной книге, имеют специальную •опцию для использования роли пользователя в течение соединения. За подробностями обращайтесь к соответствующим главам. В общем виде, например при подсоединении через isql, указание роли выглядит так:
CONNECT 'server:Disk\Path\database.gdb' USER 'username'
PASSWORD 'password' ROLE ' rolename';
Для нашего примера и тестовой базы данных firstbase.gdb строка соединения по TCP/IP будет выглядеть следующим образом:
CONNECT 'localhost:C:\Database\firstbase.gdb' USER 'sysdba'
PASSWORD 'masterkey' ROLE 'READER';
Использование ролей, которое возможно в InterBase начиная с версии 5.х.. позволяет значительно упростить управление правами пользователей InterBase.
Ошибки проектирования базы данных
Необходимо также рассказать о некоторых ошибках, допускаемых разработчиками базы данных, которые могут привести к невозможности восстановления базы данных из резервной копии (файлы *.gbk, создаваемые программой gbak). Прежде всего это небрежное обращение с ограничениями целостности на уровне базы данных. Типичный пример - это ограничения NOT NULL. Предположим, что мы имеем таблицу, которая заполнена некоторым количеством записей. Теперь мы добавим к такой таблице с помощью команды ALTER TABLE еще один столбец, причем укажем, что он не может содержать неопределенных значений NULL, примерно так:
ALTER TABLE sometable ADD Fieldl INTEGER NOT NULL
И в данном случае не возникнет никакой ошибки, как этого можно было бы ожидать. Эта модификация метаданных выполнится, и мы не получим никаких сообщений об ошибках или предупреждений, что создает иллюзию нормальности данной ситуации. Однако если теперь мы произведем резервное копирование базы данных (backup) и попытаемся восстановить (restore) базу данных из этой резервной копии, то на этапе восстановления получим сообщение об ошибке (о том, что в столбец, имеющий ограничение NOT NULL, вставляются NULL) и процесс восстановления прервется. Эта резервная копия невосстановима. Если же восстановление было направлено в файл, имеющий то же имя, что и существующая база данных (т. е. при восстановлении перезаписывался существующий рабочий файл базы данных), то потеряем всю имеющуюся информацию. Это связано с тем, что ограничения NOT NULL реализуются с помощью системных триггеров, которые проверяют лишь вновь поступающие данные, т. е. "срабатывают" при вставке и модификации записей, а существующие данные обходят своим вниманием. При восстановлении же все данные из резервной копии вставляются в пустые, только что созданные таблицы; вот тут-то и выявляются недопустимые NULL в столбце с ограничением NOT NULL.
Некоторые программисты считают такое поведение InterBase ошибкой, но другое поведение просто не позволяет добавить поле с ограничением NOT NULL к таблице с данными. Вариант с требованием обязательного значения по умолчанию и заполнения им в момент создания публично обсуждался архитекторами Firebird, но не был принят из тех соображений, что программист, очевидно, намерен заполнить его в соответствии с каким-то алгоритмом, в общем случае довольно сложным и, возможно, итеративным. При этом не исключено, что он не будет иметь возможности отличить записи, пропущенные предыдущей итерацией, от незаполненных записей.
Похожий дефект данных может возникать в результате сбоев алгоритма сборки "мусора" из-за некорректного задания пути к базе (причина повреждения, указанная в п. 3) при соединении и при файловом доступе к файлам базы данных во время работы с ней сервера 4). При этом в некоторых таблицах могут появиться записи, целиком заполненные NULL. Выявить такие записи довольно сложно, поскольку они не соответствуют ограничениям контроля целостности и уникальности данных, наложенным на таблицы, и оператор Select их просто "не видит", хотя в резервную копию они попадают. В случае невозможности восстановления по этой причине следует обработать исходную базу программой gfix (см. ниже), найти и удалить такие записи, используя неиндексированные атрибутные поля в качестве условий поиска, после чего повторить попытку снятия резервной копии и восстановления из нее базы.
Подводя итог, можно сказать, что причин возникновения тех или иных поломок базы данных существует большое количество и всегда следует рассчитывать на худшее, а именно, что база данных по ч ой или иной причине повредится. Значит надо быть готовым ее восстановить и спасти ценную информацию. Далее мы рассмотрим профилактические процедуры, гарантирующие сохранность баз данных InterBase, а также способы починки поврежденных баз данных.
Основные "рычаги" управления производительностью
Сначала мы рассмотрим те параметры настройки InterBase, которые часто изменяют для настройки производительности InterBase. Рекомендации по улучшению производительности не только затрагивают те параметры, которые есть в конфигурационном файле ibconfig, но также рассматривают различные аспекты разработки программного обеспечения. Желающие разобраться во всех параметрах конфигурационного файла ibconfig могут обратиться к справочному материалу в приложении "Параметры конфигурационного файла InterBase".
В отличие от предыдущих версий,
В отличие от предыдущих версий, InterBase 6 5 имеет несколько другие права по умолчанию на системные таблицы. Пользователь SYSDBA, разумеется, имеет все права, однако все остальные могут только читать данные из системных таблиц. Это было сделано для того, чтобы избежать возможности прямой несанкционированной правки системных таблиц, что может привести к потере нужных метаданных. Разумеется, при использовании любых других версий InterBase вы можете достичь того же результата, применяя команду REVOKE ко всем системным таблицам. Также следует обратить внимание, что в InterBase 6.5 утилита gbak при восстановлении базы данных из резервной копии также восстанавливает заданные права на системные таблицы Gbak из предыдущих версий InteiBase восстанавливал права на все таблицы, кроме системных.
Особенности системы защиты данных в InterBase
Легкость и доступность информации, которые принесли с собой компьютерные технологии, имеют и свою обратную сторону - использование компьютеров резко обострило проблемы сохранности и конфиденциальности данных. Информация, которая хранится в базе данных, зачастую может стоить во много раз дороже иного бриллианта или золотого слитка.
Поэтому обеспечение безопасности хранимых данных является неотъемлемой частью любой современной СУБД, в том числе и InterBase.
InterBase предоставляет развитые средства для управления безопасностью в своих базах данных Но. прежде чем рассказать о конкретных способах защиты данных, необходимо прояснить ряд моментов в концепции безопасности InterBase, которые часто смущают пользователей, знакомых с другими СУБД.
Как и в большинстве других СУБД, в InterBase защита данных основывается на том, что существует концепция пользователей, которые получают те или иные права для работы с каждым объектом внутри базы данных. Реальные люди-пользователи получают в свое распоряжение имя пользователя InterBase и его пароль и применяют его для работы с базой данных
Под пользователем InterBase мы будем понимать регистрационную запись, состоящую из имени пользователя и идентифицирующего его пароля.
Администратор СУБД InterBase заводит необходимое число пользователей и назначает им нужные для их работы права, разрешая им доступ только к той информации, которая нужна для выполнения должностных обязанностей.
В этом InterBase как две капли воды похож практически на любую СУБД. Однако есть существенное отличие - данные о пользователях базы данных хранятся не в самой базе данных, а вне ее - в особой базе данных пользователей lSC4.gdb.
Дело в том, что реализация ограничений, налагаемых на объекты базы данных, осуществлена в InterBase на уровне сервера базы данных, а не самой базы данных Это означает, что внутри базы данных данные никак не шифруются и не защищаются. Все проверки прав доступа осуществляются сервером InterBase, который сравнивает права, выданные на объект базы данных, с правами, которые имеет конкретный пользователь, и в зависимости от результатов сравнения, разрешает или не разрешает доступ этого пользователя к запрашиваемому объекту
Следствием вынесения информации о пользователях и проверки прав доступа к базе данных на уровень сервера является то, что, физически скопировав базу данных на другой сервер, мы можем воспользоваться паролем администратора этого сервера и получить полный доступ к информации в базе данных, обойдя, таким образом, все ограничения на доступ к данным.
Причиной такого решения является, по-видимому, особый взгляд компании Borland на физическую безопасность файлов баз данных Считается, что защиту фата базы данных необходимо обеспечивать на ином уровне, чем уровень СУБД. Прежде всего на уровне ОС - путем запрета сетевого доступа к файлам базы данных и установки соответствующих прав доступа на каталоги и файлы баз данных (ниже мы подробно рассмотрим рекомендации по установке прав доступа на файлы базы данных). Затем следует ограничить доступ к компьютеру-серверу, на котором хранится база данных, чтобы предотвратить физический доступ злоумышленника к носителям, на которых хранятся файлы базы данных (а также их резервные копии).
Другими словами, InterBase обеспечивает управление безопасностью лишь в рамках своей компетенции, т. е. его система защиты информации предназначена исключительно для ограничения доступа к данным пользователей InterBase Заботиться о том, чтобы только этот способ доступа к базе данных стал единственным, - задача не InterBase, а опытного системного администратора и службы безопасности предприятия.
Размещение пользователей InterBase в отдельной базе данных позволяет во всех базах данных, обслуживаемых данным сервером, использовать единое пространство имен пользователей, что может упростить настройку и администрирование системы безопасности.
Особый процесс, или обратная миграция
Особый процесс выражать такой переход между версиями InterBase, когда обычным методом, через backup/restore, базу данных не удастся "понизить" до младшей версии: gbak от младшей версии откажется работать с базами данных, созданными с использованием старшей версии InterBase.
В целом обратная миграция является недокументированным действием, и потому особых гарантий целостности данных при таком переходе дать нельзя, однако известно достаточно много спешных примеров подобного переноса
Чтобы осуществить обратную миграцию базы данных, необходимо задействовать два компьютера с установленными на них серверами InterBase, один из которых имеет новую версию (источник), а другой - предыдущую (приемник). Последовательность действий такая:
На компьютере-приемнике запускаем инструмент командной строки gbak и даем ему указание создать backup базы данных, находящейся на компьютере- источнике. Например, если компьютер-источник называется source_nt, то команда будет выглядеть примерно так:
gbak -b -user SYSDBA -password <пароль> source_nt:<путь_к_базе
данных_источнику> <Путь к bасkup-приемнику>
При этом gbak подключится к серверу-источнику как клиент (здесь используется возможность обратной совместимости, когда клиент младшей версии может подсоединиться к серверу, имеющему старшую) и произведет чтение всех данных из базы данных-источника, пользуясь возможностями старшей версии сервера. Но backup лой базы данных будет создан с использованием старой версии InterBase-приемника, т. е. полученную резервную копию в дальнейшем можно будет восстановить в полноценную базу данных, соответствующую младшей версии. Естественно, при таком подходе могут быть "подводные камни" - в тех случаях, когда в базе данных используются те свойства новой версии, которые не поддерживаются в старой. При этом возможно несколько исходов процесса обратной миграции: gbak либо проигнорирует новые возможности и попытается закончить резервное копирование без них, либо попытается проинтерпретировать их в стиле своей версии и получить какие-то правдоподобные значения. Конечно, наличие новых свойств в базе данных, которую переводим на младшую версию InterBase, таит в себе ту опасность, что, произведя обратную миграцию, мы окажемся у "разбитого корыта" - с базой данных, наполненной некорректными значениями или вообще нечитабельной. К счастью, gbak достаточно жестко относится к неоднозначностям в процессе backup: практически всегда, когда он наталкивается на неизвестную ему особенность, выдается ошибка. Это предохраняет от возможных скрытых ошибок в интерпретации данных. Например, при наличие в базы данных от InterBase 6.x 64-разрядных генераторов при попытке перевода этой базы на InterBase 5.x возникнет ошибка, сигнализирующая о том, что в 5.x нет подобных генераторов. Их придется удалить перед обратной миграцией, а после восстановления базы данных вновь создать.
Вот вкратце мы и рассмотрели практически все возможные варианты миграции, приведенные в таблице 4.6. Остался открытым вопрос переводе базы данных InterBase 6.x с диалекта 1 на диалект 3. Мы вернемся к нему чуть позже, а пока рассмотрим поведение и вопросы совместимости клиентов и серверов InteiBase различных версий.
Отключение питания
При отключении питания на компьютере-сервере все процессы обработки данных прерываются в самых неожиданных и (согласно закону Мерфи) опасных местах. В результате информация в базе данных может исказиться или вовсе пропасть Самый простой случай, когда в результате отключения питания все неподтвержденные данные из пользовательских программ-клиентов пропали. После восстановления питания сервер просматривает данные, видит незавершенные транзакции не привязанные ни к одному из "живых" клиентов, и откатывает все изменения, проведенные в рамках этих "погибших" транзакций. Собственно, такое поведение является нормальным и изначально предполагаемым разработчиками InterBase. Однако отключение питания не всегда сопровождается лишь такими незначительными потерями. Если сервер в момент отключения питания производил расширение базы данных, то велик риск получить "потерянные" страницы в файле базы данных (orphan pages), т. е. такие страницы, которые физически распределены и зарегистрированы на страницах учета страниц (PIP), но запись данных на которые невозможна. Подробнее о потерянных страницах см. ниже главу "Структура базы данных InterBase". Бороться с потерянными страницам в файле-базы данных умеет только инструмент починки и модификации gfix, который мы подробнее рассмотрим ниже. Собственно, потерянные страницы приводят только к излишнему расходу дискового пространства и как таковые не служат причиной потери или порчи данных. Но потеря питания приводит и к более серьезным повреждениям.
Например, после отключения питания и повторного включения может оказаться, что пропало большое количество данных, в том числе и подтвержденных (после добавления или модификации которых была выполнена команда подтвердить транзакцию. - т. е. commit). Это происходит из-за того, что подтвержденные данные записываются не напрямую в файл базы данных на диске, а используют для этой цели файловый кеш ОС. То есть серверный процесс передал ОС команду на запись данных на диск. ОС "успокоила" сервер, что данные сохранены на диске. а на самом деле данные находятся в файловом кеше. ОС не торопится сбрасывать эти данные на диск, так как оценивает, что оперативной памяти еще много, и откладывает медленные операции записи на диск до тех пор, пока не закончится свободная оперативная память.
Page buffers
Размер кеша базы данных, исчисляемый в страницах. Определяет число страниц, которое может быть одновременно размещено в кеше. Размер кеша является важнейшим параметром, влияющим на производительность операций чтения ввода-вывода базы данных (см. ниже главу "Оптимизация работы InterBase"). Надо отметить, что установка размера кеша на уровне базы данных, отражаемая данным параметром, имеет значение только для InterBase SuperServer.
Page size
Размер страницы базы данных, исчисляется в байтах. Параметр, который устанавливает основополагающее свойство базы данных - размер ее страницы. Все файлы одной базы данных состоят из страниц одинакового размера, который устанавливается при создании базы данных и при восстановлении базы данных из резервной копии. Впрочем, восстановление можно считать частным
случаем создания базы данных. Множество важнейших параметров сервера зависят от размера страницы - например, кеш базы данных. Рекомендуют создавать базу данных с размером страниц не менее 4096 байт, а лучше 8192 или 16384 байта. Последнее, правда, доступно лишь в Firebird и Yffil (см. ниже главу "Структура базы данных InterBase").
Передача прав
Часто случается так, что во время разработки базы данных программист динамически добавляет необходимые права каким-либо пользователям, однако документировать вносимые изменения забывает. Для того чтобы выяснить права какого-либо пользователя, можно извлечь данные из системных таблиц InterBase. Для извлечения всех прав пользователя TESTUSER можно употребить следующий SQL-запрос
SELECT RDB$USER, RDB$GRANTOR, RDB$PRIVILEGE,
RDB$GRANT_OPTION, RDB$RELATION_NAME, RDB$FIELD_NAME, RDB$USER_TYPE, RDB$OBJECT_TYPE
FROM RDB$USER_PRIVILEGES
WHERE RDB$USER = 'TESTUSER'
В результате этого запроса получим таблицу, содержащую все права, выданные пользователю TESTUSER Применяя механизмы поиска и замены в любом текстовом редакторе, можно легко превратить возвращаемую таблицу в полноценные команды GRANT, получив, таким образом, скрипт, который можно будет использовать для "раздачи прав".
Чтобы назначить пользователю NEWUSER такие же права, как и у пользователя TESTUSER, причем сделать это от имени SYSDBA, можно применить следующий SQL-запрос:
INSERT INTO RDB$USER_PRIVILEGES (RDB$USER, RDB$GRANTOR,
RDB$PRIVILEGE, RDB$GRANT_OPTION, RDB$RELATION_NAME,
RDB$FIELD_NAME, RDB$USER_TYPE, RDB$OBJECT_TYPE)
SELECT 'NEWUSER', 'SYSDBA', RDB$PRIVILEGE, RDB$GRANT_OPTION,
RDB$RELATION_NAME, RDB$FIELD_NAME,
RDB$USER_TYPE, RDB$OBJECT_TYPE
FROM RDB$USER_PRIVILEGES UPR
WHERE UPR. RDB$USER = 'TESTUSER'
Разумеется, такой подход к манипулированию является недокументированным и может измениться и не работать в дальнейших версиях InterBase и его клонов, но иногда его использование может сэкономить массу времени на кропотливое создание SQL-скриптов со множеством GRANT.
Перевод базы данных InterBase 6.x на 3-й диалект
Итак, мы подходим к рассмотрению вопроса о переводе баз данных InterBase 6 1-го диалекта на диалект 3, использующий все возможности версии 6.x. Начнем рассматривать этот перевод с предположения, что в качестве исходного материала мы имеем базу данных InterBase 6.x диалекта 1 и клиентские приложения, использующие синтаксис 1-го диалекта.
Сейчас речь идет именно о переводе базы данных в 3-й диалект. Дело в том, что клиентские приложения при подключении к базе данных также указывают диалект. После рассмотрения перевода базы данных мы рассмотрим и те шаги, которые нужны для миграции приложения на 3-й диалект.
Итак, что же мешает нам перевести нашу базу данных в 3-й диалект? Существует 4 основных препятствия, которые надо преодолеть, чтобы успешно перейти на 3-й диалект, - это двойные кавычки, ключевые слова, новые типы данных DATE и большие целые числа.
Почему необходима миграция
Собственно, почему? Если вы любите эксперименты, то наверняка пробовали подключаться к базе данных от InterBase 5.x с помощью какого-нибудь клона 6.x и заметили, "старые" базы данных могут работать под управлением новых версий InterBase. Действительно, между версиями серверов существует совместимость "снизу вверх", когда старшая версия (например, 6.x) умеет работать с базами данных, созданных в предыдущей версии (например, 5.x), однако возможности такого взаимодействия ограничены. Например, нет совместимости при переносе базы данных между различными ОС и платформами - попробуйте скопировать файл базы данных с компьютера, на котором работает InterBase под Linux, на компьютер, где установлена Windows и соответствующая версия InterBase под Windows, а затем попытайтесь подключиться к этому файлу. База данных будет в большинстве случаев повреждена (не проводите таких экспериментов над рабочими базами данных!). Также не получится просто скопировать баз\ данных с системы на базе платформы Intel на систему SPARC и наоборот
Дело в том, что база данных, созданная с использованием определенной версии сервера InterBase, который выполняется под управлением какой-либо ОС, имеет в своей структуре привязки к версии InterBase -сервера и к ОС.
База данных имеет различные версии ODS (On-disk structure) в зависимости от того, с помощью какой версии InterBase она была создана. ODS определяет, какова внутренняя структура файлов базы данных InterBase (подробнее об ODS см. главу "Структура базы данных InterBase"). При переходе от одной версии сервера к другой ODS может меняться, при этом включаются дополнительные возможности, которые задействованы в новых версиях InterBase. Хотя новые версии InterBase ради совместимости позволяют работать с ODS от предыдущих версий, но при этом новые возможности будут недоступны.
Чтобы использовать возможности, предоставляемые новыми версиями InterBase, необходимо обязательно осуществить миграцию базы данных, созданной в предыдущей версии, к соответствующей ODS.
При переходе от одной ОС к другой возникает более очевидная ситуация: либо InterBase просто откажется работать с базой данных, пришедшей (читай - переписанной) с другой ОС, либо выдаст множество ошибок, связанных с несовместимостью представления данных в разных ОС. Дело в том, что в каждой ОС существует собственная реализация некоторых типов данных и при попытке работать с базой данных на другой платформе неверно интерпретируются значения, хранящиеся в базой данных. Миграция просто необходима при смене ОС, если вы желаете сохранить свою баз> данных в целости и сохранности.
Аначогичная ситуация складывается при переходе с одной аппаратной платформы на другую - например, при переходе Intel->Sparc. Миграция необходима для корректной модификации тех данных в базе данных, которые зависят от аппаратной платформы.
Получение статистики
Существует много способов получить статистику Почти все универсальные инструменты, перечисленные в приложении "Инструменты администратора и разработчика InterBase", позволяют получить статистику базы данных с помощью нескольких нажатий мыши, однако часто случается так, что нужных инструментов не оказывается под рукой; поэтому мы рассмотрим, как получить результат, пользуясь только стандартными средствами. К таковым относится утилита командной строки gstat, которая входит в стандартную поставку InterBase 6.x и его клонов и позволяет получить вес вышеперечисленные виды статистики. Правда, есть важное ограничение - gstat должна выполняться на том же компьютере, где находится сервер InterBase, т. е. удаленное получение статистики при помощи gstat невозможно.
Формат использования gstat следующий:
gstac [options] database
Здесь database - имя и путь к базе данных, из которой будет извлекаться статистика, a [optionsj - набор опций, которые определяют, какую информацию на- ю получить Опции утилиты gstat описаны в таблице 4.12:
Табл 4.12. Опции gstat
|
Опция |
Описание опции | ||
|
-all |
Опция выбирается по умолчанию - приводит к извлечению статистики по страницам данных и индексам | ||
|
-data |
Извлекает статистику по страницам данных всех пользовательских таблиц в базе данных | ||
|
-header |
Извлекает только статистику заголовочной страницы | ||
|
-index |
Извлекает статистику по индексам в базе данных | ||
|
-log |
Извлекает только статистику о страницах протокола | ||
|
-password] |
Пароль пользователя, который запускает gstat для получения статистики | ||
|
-system |
Извлекает статистику по системным таблицам и индексам | ||
|
-user name |
Пользователь InterBase, который запускает gstat для получения статистики Только владелец базы данных или системный администратор SYSDBA может запускать gstat для получения статистики | ||
|
-z |
Печатать версию gstat |
Помимо использования утилиты gstat, статистику всегда можно получить, применяя Sen ices API, который реализован во всех версиях InterBase 6.x и его клонов в варианте SuperServei, а также в клоне Yaffil Classic Server. Воспользоваться Services API можно как на низком уровне, так и посредством специализированных библиотек доступа к InterBase, таких, как FIBPlus и IBX. При использовании Services API нет ограничения на то, чтобы клиент, запрашивающий статистику, обязательно находился на компьютере-сервере.
В наших примерах мы будем использовать утилиту gstat, как наиболее надежный и стандартный способ получения статистики. Пример получения полной статистики базы данных выглядит следующим образом:
gstat -all -user SYSDBA -password masterkey
С:\Database\firstbase.gdb
При этом будет выведена как общая информация о базе данных, так и подробная информация о таблицах в базе данных. Надо сказать, что результатом выполнения этой команды даже для небольшой базы данных будет довольно обширный отчет. Давайте более подробно рассмотрим информацию, извлекаемую утилитой gstat.
Пользователи
Пользователь InterBase, как уже было сказано выше - это регистрационная запись, доступная во всех базах данных, обслуживаемых данным сервером. Пользователи InterBase, как правило, хранятся в служебной базе данных ISC4.gdb, но если и клиент, и сервер InterBase стоят на системе Linux/Unix, т. е. еще одна возможность. InterBase распознает пользователей и даже группы пользователей ОС Unix и поэтому можно рассматривать Unix-пользователей как обычных пользователей InterBase, несмотря на то, что они не занесены в служебную базу данных InterBase ISC4.gdb. Для осуществления такой возможности используется механизм "доверенных компьютеров" (trusted hosts). Пользователи Windows-клиентов (и тем более Windows-серверов InterBase) лишены такой возможности.
Среди всех пользователей главнейшим, несомненно, является пользователь SYSDBA - системный администратор сервера InterBase. Имя SYSDBA предопределено и не может меняться. По умолчанию этот пользователь обладает всеми правами над любым объектом базы данных. Поэтому SYSDBA является очень мощным пользователем и следует тщательно оберегать его пароль. Как вы знаете из предыдущих глав, по умолчанию пароль системного администратора - "masterkey" (на самом деле в InterBase используется всего 8 символов, и достаточно писать "masterkey"), однако желательно сменить этот пароль сразу после установки сервера и регулярно менять его впоследствии.
Чтобы создать нового пользователя, необходимо воспользоваться либо инструментом командной строки gsec, либо каким-либо графическим инструментом из списка, приведенного в приложении "Инструменты администратора и разработчика InterBase". С помощью SQL-команды создать или удалить пользователя InterBase нельзя - это следствие вынесения системы безопасности на уровень сервера.
Имя пользователя может иметь длину до 31 символа включительно, пароль - до 32 символов, однако из них для аутентификации используются только первые 8.
Для имен пользователей не важен регистр символов, но пароль является регистрочувивительным
Надо отметить, что только SYSDBA может создавать и изменять новых пользователей в InterBase. Для создания с помощью gsec нового пользователя с именем TESTUSER необходимо выполнить следующую команду:
gsec -user SYSDBA -password masterkey -add TESTUSER -pw test
Чтобы просмотреть с помощью gsec список пользователей InterBase, необходимо воспользоваться ключом -display:
С:\Firebird\bin>gsec -display
user name uid gid full name
SYSDBA О О
BUILDER О О
TESTUSER О О
Подробно ключи и использование инструмента командной строки gsec описаны в [4, гл. 5J. Мы не будем здесь повторять приведенный материал, так как основные команды для управления совершенно очевидны, однако вы всегда сможете познакомиться с ними поближе.
Обычно в системе на базе InterBase заводят столько пользователей, сколько людей обращается к приложению базы данных. Если же имеется несколько человек, выполняющих одну и ту же работу, то для упрощения системы прав применяют механизм ролей (ROLE).
Понятие об ODS
ODS - это аббревиатура для On-Disk Structure, т. е. структура данных баз данных InterBase на диске. ODS определяет, как организованы данные внутри файлов базы данных. Определение основных констант и структур данных для реализации On-Disk Structure находится в файле из комплекта исходных кодов ods.h.
ODS в процессе развития InterBase менялась, и, чтобы сервер при работе с конкретной базой данных точно знал, с чем он имеет дело, он выясняет номер версии ODS. Файл Ods.h представляет нам следующую картину версий On-Disk Structure:
ODS 5 поставлялась с версией InterBase 3.3 и более не поддерживается;
ODS 6 и ODS 7 никогда не выходили в свет;
ODS 8 поставляется с версией InterBase 4.0;
ODS 9 поставляется с версией InterBase 5.x и выше;
ODS 10 начала поставляться с InterBase 6.
Помимо основных (major) версий ODS существуют еще вспомогательные (minor) версии, которые зависят от конкретной версии сервера базы данных, создавшего их. Основные номера версии записываются в целой части числа, которое обозначает версию, а минорные - в дробной. Например, версия сервера 4.0 создает базы данных, которые имеют ODS 8.0, a InterBase 4.2 - 8.2. Переход между минорными версиями "снизу вверх" осуществляется автоматически. Например, достаточно открыть базу с ODS 8.0, созданную сервером 4.0, при помощи InterBase 4.2 - и ODS этой базы будет иметь версию 8.2. Переход между основными версиями базы данных осуществляется только через резервное копирование (backup) базы данных с применением старой версии сервера и восстановление из резервной копии (restore) с использованием новой версии сервера. Процесс перехода между версиями подробно рассмотрен в главе "Миграция" (ч. 4).
Важным моментом в реализации поддержки ODS для версий InterBase 4.x и 5.x является совместимость серверов InterBase 4.x и InterBase 5.x с версией, на единицу меньшей, чем реализация конкретного сервера. InterBase поддерживает несколько возможных ODS и, в зависимости от ее версии ODS, при присоединении к конкретной базе данных выбирает поддержку нужной реализации ODS. Механизм принятия решения о том, какую реализацию поддержки ODS выбрать в данном конкретном случае, называется Y-Valve (автор Стива Тентона). Проще говоря, базу с ODS 8.x ("родной" для InterBase 4.0), можно открыть в InterBase 5.x и работать с ней.
Совместимость версий ODS идет "сверху вниз", т. е. сервер с более высокой версией и все его инструменты сумеют работать с базой данных, созданной ранними версиями сервера, но никак не наоборот. Попытавшись открыть базу, созданную в 6-й версии InterBase, при помощи InterBase 5.x, вы получите ошибку "Unsupported On-disk structure: Found ODS 10, supported ODS 9".
Также следует заметить, что бета-версия InterBase 6.0 поддерживала только ODS 10. В то же время Firebird 1.0 уже позволяет открывать базы как с ODS 8.хх, так и с 9.хх. Следует обратить внимание, что Firebird позволял только открывать базы данных с ODS 8 и 9, потому что гарантировать что-то при таком способе работы ничего нельзя. Т. е., несмотря на совместимость между версиями ODS "сверху вниз", перенос базы данных между версиями сервера лучше производить документированным способом.
Особенно важна версия ODS в вопросах, связанных с резервным копированием и извлечением базы данных, а также с восстановлением испорченных баз данных. Инструменты резервного копирования gbak и восстановления gfix следят за версией ODS и просто не станут работать, если версия ODS-базы, которую они должны обслуживать, больше версии, реализованной в них. Это значит, что gbak от 4.x не сможет создать резервную копию базы данных, если она создана сервером 5.x, однако наоборот - пожалуйста.
Пошаговые инструкции для перехода на 3-й диалект
Исходные данные: предположим, что мы переводим базу данных, состоящую из одного файла, - base2migrate.gdb. База данных - источник имеет 1 диалект. Резервная копия базы данных-источника сделана.
Итак, начнем.
Необходимо получить метаданные, описывающие базу данных-источник в 1-м диалекте. Для этого выполняем команду вида isql base2migrate.gdb -x -user SYSDBA -password masterkey -о baseSource.ddl, которая извлечет метаданные и поместит их в файл baseSource.ddl. Эта команда выполнится успешно, если база данных-источник находится в том же каталоге, в котором находится и isql, в другом случае придется указать полный путь к базе данных.
Необходимо создать пустой файл с именем вроде makelt.sql, в который будут заноситься команды изменения метаданных базы данных, которые получим на основе анализа файла baseSource.ddl на предмет несоответствия содержащихся там метаданных требованиям диалекта 3. Команды изменения из файла makelt.sql подготовят базу данных-источник к переходу. Дальнейшие шаги до перехода будут посвящены наполнению файла.
Отыскиваем в файле baseSource.ddl все двойные кавычки и заменяем их на одинарные. Затем копируем все измененные выражения в файл makelt.sql. Например, если строка, ограниченная двойными кавычками, находится внутри триггера, то надо скопировать весь триггер с измененной строкой (и не за- о\дые предложение set term перед триггером!). Заметьте, что простым поиском/заменой кавычек здесь не обойтись, ведь двойные и одинарные кавычки могут быть и в середине, и в конце, и в начале строковых констант. Для замены следует воспользоваться следующими правилами, составленными на основе таблицы 2.1 в InterBase б Mignation Guide [3]:
Табл 4.8. Правила перевода строк с двойными кавычками
|
Двойные кавычки внутри строки | |||
|
Строка без кавычек как она есть |
In "peg" mode | ||
|
Строка, заключенная в двойные кавычки (допускается правилами IВ5.х и 1-го диалекта) |
"In ""peg"" mode" | ||
|
Строка, заключенная в одинарные кавычки согласно требованиям правил диалекта 3 |
'In "peg" mode' | ||
|
Одинарные кавычки внутри строки | |||
|
Строка без кавычек |
O'Reilly | ||
|
Строка, заключенная в двойные кавычки (допускается правилами IВ5.х и 1-го диалекта) |
"O'Reilly" | ||
|
Строка, заключенная в одинарные кавычки, согласно требованиям правил диалекта 3 |
'O"Reilly' | ||
После разрешения вопросов с двойными кавычками необходимо разобраться в типах для работы с датой и временем. Во время перехода на диалект 1 все "старые" столбцы типа DATE заменились на T1MESTAMP. Однако переменные типа DATE, которые могли быть в триггерах и процедурах, автоматически не заменились на TIMESTAMP. Поэтому надо произвести в файле baseSource ddl поиск всех вхождений переменных типа DATE и сменить их тип на TIMESTAMP. Все предложения (триггеры, представления, хранимые процедуры и т. д.), затронутые изменениями, следует перенести в файл makelt.sql. А затем надо повторить такой же поиск и произвести замену DATE на TIMESTAMP в файле makelt.sql, ведь в этот файл уже попали несколько предложений, модифицированных для того, чтобы соответствовать правилам 3-го диалекта для работы с двойными кавычками, и эти предложения тоже надо очистить от нежелательных переменных типа DATE.
Теперь следует заняться ключевыми словами, которые могли быть использованы в базе данных версий 5.x. Необходимо в файле makelt.sql найти все предложения, содержащие ключевые слова и изменить их на неключевые обозначения. Возможно, что изменение наименований столбцов повлечет за собой необходимость удалить и пересоздать зависимые от них объекты. Для получения списка зависящих от каждого меняющегося столбца объектов можно воспользоваться инструментами, указанными в приложении "Инструменты администратора и разработчика InterBase". Если существуют зависимые объекты, то их придется сначала удалить, а потом создать вновь, но уже с правильными ссылками на измененные объекты. То есть если у вас было поле, названное YEAR, и вы сменили его имя на YEAR1, то во всех процедурах, представлениях, триггерах необходимо заменить YEAR на YEAR1. Для этого придется удалить все эти объекты из базы данных, затем исправить имя столбца и после этого пересоздать все зависимые объекты.
Вообще говоря, избавление от ключевых слов является наиболее трудоемкой процедурой из-занеобходимости отследить и пересоздать, зависимые объекты. Лучше всего работу по удалению ключевых слов из базы данных выполнить отдельно, а не в рамках того набора изменений, который формируется в файле makelt.sql.
После разрешения вопроса с ключевыми словами в файле makelt. sql ту же самую процедуру необходимо проделать в файле baseSource.ddl и, как и раньше, скопировать все измененные предложения в файл makelt.sql.
Теперь необходимо превратить предложения, содержащиеся в файле makelt.sql, в команды DDL, которые приведут нашу базу данных в соответствие с правилами 3-го диалекта.
Для этого в файле makelt.sql надо заменить словосочетание CREATE TRIGGER на ALTER TRIIGER, CREATE DOMAIN - на ALTER DOMAIN. Затем перед каждой командой CREATE VIEW вставить DROP VIEW для создаваемого представления - сочетание DROP/CREATE используется из-за отсутствия для представлений команды ALTER. Проверьте, чтобы среди скопированных предложений не оказалось команд CREATE PROCEDURE, а были только ALTER PROCEDURE. Затем если в makelt.sql есть предложения ALTER TABLE, которые изменяют ограничения таблиц (CHECK), то модифицируйте предложения ALTER TABLE так, чтобы они сначала удаляли эти константы, а затем вновь создавали, но уже с одинарными кавычками. Вы можете заметить, что измененные из-за двойных кавычек предложения мог>т дублироваться в файле makelt.sql предложениями, имеющими переменные типа DATE, но это неопасно: повторное выполнение предложений по модификации не приведет к порче метаданных, хотя, возможно, приведет к возникновению ошибок вида "attempt to store duplicate value", которые сигнализируют о попытке повторного создания объекта.
В начало файла makelt.sql поместите команду CONNECT, которая обеспечит подключение к модифицируемой базе данных - что-то вроде:
CONNECT 'C:\Database\base2migr.gdb' USER 'SYSDBA' PASSWORD 'masterkey';
Запустите скрипт из файла makelt.sql с помощью isql или любого другого инструмента администрирования базы данных. Вполне возможно, что первый запуск этого файла приведет к появлению массы ошибок. Внимательно проанализируйте эти ошибки, внесите соответствующие изменения в makelt.sql и вновь запустите его на выполнение, только уже не на "использованной" базе данных. - извлеките из backup новую, нетронутую базу данных и проверяйте скрипт на ней.
Когда добьетесь удовлетворительного результата со скриптом в makelt.sql, необходимо явно установить 3-й диалект базы данных следующей командой:
gfix -sql_dialect 3 base2migr.gdb -user sysdba -password masterkey
Теперь вы получили базу данных 3-го диалекта. Конечно, ряд моментов остался нерассмотренным, поэтому в случае возникновения необходимости получить исчерпывающую информацию по переходу на 3-й диалект следует обратиться к [3, глава "Migration Guide"].
Повреждения жесткого диска
К такому же печальному результату могут привести повреждения жесткого диска (появление bad sectors) и нехватка дискового пространства в момент расширения базы данных. В последнем случае может произойти очень неприятная вещь: InterBase укажет на заголовочной странице, что файл базы данных теперь состоит из N страниц, в то время как реальное расширение файла до указанного размера аварийно прервется из-за нехватки дискового пространства. При этом скорее всего произойдет аварийное завершение сервера, затем он запустится снова и попытается подключиться к базе данных. Сравнит количество декларированных страниц в заголовке базы данных с реальным размером файла и откажется работать с таким файлом, выдав сообщение об ошибке "Unexpected end of file". Именно такой случай поломки базы данных мы подробно рассмотрим ниже.
Права
Права в InterBase - это разрешение какому-либо пользователю, хранимой процедуре или триггеру совершить какую-либо операцию над определенным объектом базы данных. Существуют несколько видов объектов, на которые можно устанавливать права для пользователей и ролей. Это таблицы и их поля, представления и хранимые процедуры.
Существуют следующие права, выдаваемые пользователям InterBase:
Для таблиц и их полей - права на выполнение операций SELECT, DELETE, INSERT, UPDATE и REFERENCES (это право дает пользователю возможность создавать ограничения внешнего ключа FOREIGN KEY на данную таблицу).
Для представлений (VIEW) и их полей - права на выполнение операций SELECT, DELETE, INSERT, UPDATE. Как вы уже знаете из главы "Представления" (ч. 1), данные представления не хранятся в базе данных, а извлекаются динамически по запросу, лежащему в основе представления. Поэтому права на изменение данных в представлении (DELETE, INSERT, UPDATE) фактически относятся либо к таблице, на которой основано представление, либо к триггерам, которые делают VIEW изменяемым.
Права на выполнение хранимых процедур - EXECUTE. Пользователь, желающий выполнять определенную хранимую процедуру, должен иметь на это право.
Помимо прав на объекты, которые выдаются пользователю InterBase, права на использование объектов могут иметь также те объекты, которые на них ссылаются. Например, если хранимая процедура производит вставки в какую-либо таблицу, то этой процедуре должны быть даны права на INSERT в этой таблице.
Вы могли также заметить, что часто создавали хранимые процедуры и триггеры, не заботясь о выдаче каких-либо прав, и все они прекрасно работали. Действительно, можно создать хранимую процедуру и она будет вставлять данные в таблицу, даже если она не имеет непосредственного разрешения на вставку - но только в том случае, если выполняющий ее пользователь InterBase имеет эти права! Другими словами, хранимая процедура применяет список прав выполняющего ее пользователя для своей работы.
Такой подход является чрезвычайно гибким и прозрачным. Например, мы можем вообще не заботиться о раздаче прав на хранимые процедуры и всю безопасность определять на уровне прав, выдаваемых пользователю. Это удобно в случае, если мы работаем в нашем приложении с таблицами базы данных напрямую: выполняем какие-либо вставки, изменения и удаления.
Однако также можно вынести всю логику работы с данными в хранимые процедуры, раздать им необходимые права на таблицы, а всем пользователям InterBase полностью запретить доступ к таблицам базы данных, чтобы исключить прямую правку данных, и разрешить только применение хранимых процедур. В этом случае все пользователи InterBase будут изолированы от непосредственных данных в таблицах базы данных и смогут работать с ними лишь посредством хранимых процедур, в которых легко организовать отслеживание изменений, и т. д.
Права для выполнения резервного копирования
Вопрос о правах, необходимых для резервного копирования базы данных - очень важный вопрос. Под "правами" имеются в виду самые различные привилегии, которые мы сейчас рассмотрим. Во-первых, это права на уровне InterBase. Только системный администратор или владелец базы может производить резервное копирование базы данных, т.е. "user name" всегда должно быть или SYSDBA, или именем пользователя-владельца. И пароль в опции password соответственно (по умолчанию для SYSDBA пароль задан строкой "masterkey") должен принадлежать данному пользователю.
Во-вторых, пользователь должен обладать правами на уровне ОС ддя осуществления процесса резервного копирования. В случае если компьютер-сервер, на котором функционирует InterBase, работает под управлением Windows NT/2000/XP, то пользователь, права которого серверный процесс InterBase, должен иметь привилегии для чтения и записи файла базы данных. Это совершенно необходимое требование, обычно оно выполняется, так как по умолчанию серверный процесс InterBase пользуется правами доступа системной учетной записи (пользователь "Система"), которая по умолчанию обладает правами доступа ко всему диску.
В-третьих, необходимо отрегулировать права доступа на уровне ОС для пользователей, обращающихся с клиентских компьютеров к InterBase на компьютере- сервере. Если соединение происходит по протоколу TCP/IP, то никаких привилегий для работы с базой данных пользователю, работающему на компьютере- клиенте, давать не надо. Более того, к InterBase-серверу под управлением NT/2000/XP может обращаться любой пользователь, в том числе и не имеющий никаких прав, потому что при соединении по TCP/IP не производится проверки привилегий, специфичных для Windows. Если соединение происходит по протоколу Named Pipes, то пользователь должен иметь права на модификацию каталога и файла базы данных.
Помните, что при соединении по TCP/IP строка соединения имеет вид server_name: <диск>\<путь_на_лиске_сервера_к_база данных>, а при соединении по протоколу Named Pipes -\\sеrver_name\<диск>\<путь_на_диске_сервера_к_база данных>.
Необходимо также обратить ваше внимание на вопрос, связанный с безопасностью совместно используемых ресурсов - так называемых shared folders. Вам не нужно давать никакие права на такие ресурсы при соединении по любому протоколу -для работы с InterBase они совершенно не нужны.
В случае если компьютер-сервер с InterBase работает под управлением Linux, то для выполнения gbak также необходимо, чтобы он работал под учетной записью, имеющей права на модификацию файла базы данных. Также необходимо, чтобы пользователь, запускающий gbak, имел право запускать libgds.so - динамическую библиотеку, которая используется gbak для обращения к InterBase.
Пример установочного скрипта
Разумеется, существует множество приложений, использующих InterBase и его клоны в качестве встроенной СУБД, поэтому можно найти примеры готовых установочных скриптов, которые реализуют все вышеописанные действия по корректной установке сервера и клиента InterBase.
Пример установочного скрипта, который создает полноценный установщик сервера Firebird 1.0, можно скачать по адресу http://clientes.netvisao.pt/luiforra/id/. Скрипт предназначен для использования в популярном бесплатном компиляторе установщиков InnoSetup (www.innosetup.com).
Прямая миграция
Итак, чтобы осуществить миграцию между теми версиями InterBase, на пересечении которых в таблице "Карта прямой миграции" стоит "Да", необходимо выполнить следующие действия.
Сделать резервную копию базы данных на системе-источнике. Для этого следует выполнить команду
gbak -b -user SYSDBA -password <пароль> <путь к базе данных>
<путь к backup>
При этом создастся резервная копия вашей базы данных (подробнее о резервном копировании см. в этой части главу "Резервное копирование базы данных и восстановление из резервной копии"). После этого необходимо проверить правильность этой резервной копии - попытаться восстановить ее на той же самой системе-источнике (но ни в коем случае не поверх базы данных источника!). Для этого выполняем команду:
gbak -с -user SYSDBA -password <пароль> <путь к backup>
<путь2 к базе данных>
Если контрольное восстановление прошло успешно, то сохраняем резервную копию базы данных в надежном месте (переустанавливаемый сервер таким местом обычно не является, скопируйте backup базы данных на другой компьютер или на какое-нибудь устройство резервного копирования) и приступаем к следующему этапу миграции, если нет. то смотрим главу "Починка базы данных" (см. ниже), чиним свою базу данных и вновь приступаем к процессу миграции с самого начала
Профилактика повреждений баз данных InterBase
Профилактические действия, которые следует производить для предотвращения поломок баз данных, - это постоянное создание резервных копий (подробно о резервном копировании см. главу "Резервное копирование и восстановление из резервной копии"). Это самый надежный рубеж обороны против повреждений базы данных. Только резервное копирование дает 100%-ную гарантию сохранности данных. Но, как описано выше, в результате резервного копирования может получиться и невосстановимая, т. е. бесполезная, копия, поэтому восстановление базы из копии никогда не должно выполняться путем записи поверх оригинала и резервное копирование должно следовать определенным правилам.
Во-первых, резервное копирование должно быть как можно более частым, во-вторых, оно должно быть последовательным, и, в-третьих, резервные копии нужно проверять на возможность восстановления.
Частое резервное копирование означает, что нужно достаточно часто делать резервную копию, например один раз в сутки. Чем меньше промежуток данных между резервным копированием базы данных, тем меньше данных потеряется в результате сбоя.
Последовательность резервного копирования означает, что резервные копии должны накапливаться и храниться как минимум неделю. Если есть возможность, то нужно записывать резервные копии на специальные устройства типа стримера, если нет - то хотя бы скопировать их на другой компьютер. История резервных копий позволит отследить скрытые повреждения и справиться с ошибкой, которая возникла давно, а проявилась, как всегда, неожиданно.
Необходимо проверять, можно ли восстановить без ошибок полученную резервную копию. Проверить это можно только одним способом - через тестовый процесс восстановления (restore). Надо сказать, что процесс восстановления занимает примерно в 3 раза больше времени, чем резервное копирование, и для больших баз проверку на восстановление ежедневно делать затруднительно, так как это может прервать работу пользователей на несколько часов, т. е. ночного перерыва может и не хватить. Конечно, организациям, имеющим базы данных такого большого объема лучше, не экономить "на спичках" и выделить отдельный компьютер для этих целей.
В том случае, если сервер должен функционировать при значительной нагрузке по 24 часа 7 дней в неделю, можно воспользоваться механизмом SHADOW для снятия "моментальных" снимков с базы данных и дальнейших операций по резервному копированию уже с моментальной копией. Подробно процесс резервного копирования и восстановления баз данных описан в главе "Резервное копирование и восстановление базы данных из резервной копии".
При создании резервной копии и затем при восстановлении базы данных из этой копии происходит пересоздание всех данных в базе данных Этот процесс backup/restore, или коротко - b/r) способствует исправлению большинства нефатальных ошибок в базе данных, связанных с повреждениями жесткого диска, выявляет проблемы с целостностью данных в базе, очищает базу данных от "мусора" (старых версий и фрагментов записей, незавершенных транзакций), значительно уменьшает размер базы данных. Можно сказать, что регулярный b/r - залог здоровья базы данных InterBase. Если база данных рабочая, то рекомендуется производить b/r еженедельно. Правда, есть свидетельства о базах данных InterBase, которые интенсивно используются по несколько лет без backup/restore. Тем не менее для собственного спокойствия все-таки желательно производить эту процедуру, тем более что ее легко можно автоматизировать.
Если по каким-то причинам невозможно часто производить процесс backup/restore (особенно restore), то можно воспользоваться инструментом для проверки и восстановления баз данных gfix, который позволяет провести проверку и восстановление многих ошибок без b/r.
Рабочие станции
Требования к компьютерам-рабочим станциям, на которых исполняются клиентские части приложений базы данных на базе InterBase, определяются в основном требованиями ОС. Клиентская часть приложения базы данных InterBase не требует большего, чем обычные офисные программы. Клиентская же часть самого InterBase весьма легковесна, не требует много ресурсов и состоит всего из трех файлов (см. ниже главу "Состав модулей InterBase"). Можно с уверенностью сказать, что большинству приложений баз данных InterBase будет более чем достаточно для выполнения компьютера офисного класса - например, Celeron с 256 Мбайт ОЗУ. Нижним пределом (для небольшого клиентского приложения) является компьютер класса Pentium-100 с 16 Мбайт ОЗУ.
Расширенная установка InterBase-сервера
Рассмотренный выше минимум файлов не включает в себя часть расширенных возможностей InterBase. Чтобы воспользоваться многоязыковой поддержкой, стандартными UDF-функциями или своей библиотекой функций, необходимо скопировать еще ряд файлов, список которых приведен в табл. 4.3.
Табл 4.3. Файлы для расширенной установки InterBase
|
Файл |
Описание |
Куда скопировать | |||
|
ib_ufil.dll |
Динамическая библиотека, содержащая необходимые для работы UDF-функции |
<lnterBase_root>\Bin | |||
|
gdsintl.dll |
Набор кодировок для поддержки национальных языков |
<lnterBase_root>\Bin | |||
|
ib_udf.dll |
Стандартная библиотека UDF-функций |
<lnterBase_root>\UDF |
Если в тиражируемом приложении используются какие-либо собственные UDF-библиотеки, помимо ib_udf.dll, то их всех также необходимо скопировать в каталог UDF в установочном каталоге InterBase.
Раздача прав
Права на объекты базы данных раздаются с помощью команды GRANT. Это очень многоликая команда, со множеством опций, поэтому мы не будем целиком цитировать документацию, а приведем лишь самые основные и часто используемые применения этой команды.
Давайте рассмотрим несколько простых примеров раздачи прав. Чтобы выдать пользователю TESTUSER права на выборку из таблицы Table_Example, применяется следующая команда:
GRANT Select ON Table_Example TO testuser;
Как видите, все очень просто и интуитивно понятно. Чтобы выдать права на чтение и запись данных, но не на изменение, используем следующую команду:
GRANT Select, Insert ON Table_Example TO testuser;
А чтобы выдать все возможные права, применяется ключевое слово ALL:
GRANT ALL ON Table_Example TO testuser;
Часто возникает необходимость выдать определенные права сразу нескольким пользователям. Для этого можно указать в команде GRANT не одного, а сразу нескольких пользователей (до 1500) через запятую следующим образом:
GRANT ALL ON Table_Example TO testuser, newuser;
Если же надо выдать определенные права сразу всем пользователям InterBase, то можно воспользоваться ключевым словом PUBLIC, которое эквивалентно перечислению всех пользователей через запятую:
GRANT Select, Insert ON Table_Example TO PUBLIC;
Помимо выдачи прав на всю таблицу (или представление - синтаксис здесь будет точно таким же), иногда возникает необходимость ограничить права пользователя несколькими определенными полями в таблице. Например, пользователь BOSS имеет право менять поле BIGMONEY, а все остальные пользователи могут только его просматривать. В этом случае можно воспользоваться механизмом ограничения выдачи прав на конкретные поля таблицы:
GRANT Select ON Table_example(BIGMONEY) TO PUBLIC;
GPANT ALL ON Table_example(BIGMONEY) TO BOSS;
Аналогичный синтаксис раздачи прав применяется и для хранимых процедур, только в первой части команды GRANT пишется GRANT EXECUTE ON PROCEDURE <имя_процедуры>, а далее как обычно. Например, для выдачи пользователю TESTUSER разрешения запускать хранимую процедуру SP_ADD надо написать следующее:
GRANT EXECUTE ON PROCEDURE SP_Add TO testuser;
Для тою чтобы некая процедура SP_MAIN могла вызывать процедуру SP_ADD без наличия таких прав у пользователя, вызывающего SP_MAIN, надо написать так:
GRANT EXECUTE ON PROCEDURE SP_Add TO SP_Main;
Однако раздача прав объектов на использование других объектов нужна только в том случае, если база данных проектируется с намерением скрыть исходные таблицы от пользователей. В противном случае гораздо проще будет раздавать права напрямую пользователям (ролям).
Размер страницы базы данных
Ha производительность операций чтения и записи сильно влияет размер страницы базы данных. Если страница мала (менее 4096 байт), то серверу приходится многократно обращаться к диску, чтобы прочитать некоторый кусок данных, т. к. все операции производятся постранично. Если страница имеет большой размер (8192 или даже 16384 байта), то нужно меньше "дергать" диск для чтения и записи данных. Помимо этих очевидных соображений, от размера страницы также зависит глубина индексов базы данных' чем страница больше. тем глубина меньше и тем быстрее происходит поиск с использованием индексов (подробнее см. главу "Индексы" (ч. 1)).
Для достижения оптимальной производительности рекомендуется устанавливать размер страницы базы данных не менее 4096 байт. Конечно, как всякое средство увеличение размера страницы имеет и побочный эффект - приводит к росту размера файлов базы данных.
Установить или изменить размер страницы базы данных можно только при ее создании или при восстановлении из резервной копии (см. главу этой части). "Резервное копирование и восстановление из резервной копии".
Интересно ознакомиться с общими рекомендации по оптимизации от известного разработчика Далтона Калфорда, которыми он поделился в одном из писем в конференцию mers com, посвященную вопросам использования InterBase. Они включают следующие пункты:
Разнесите файлы ОС, каталог временных файлов InterBase и файлы базы данных на разные каналы (и на разные диски, соответственно). Это означает, что ОС и программы (в том числе и InterBase) нужно разместить на одном диске временные файлы ОС и InterBase - на другом диске, а файлы базы данных поместить на надежном RAID.
Разнесите медленные и быстрые SCSI-устройства на разные каналы, т. к. многие SCSI-адаптеры работают на скорости самого медленного устройства. Поэтому следите за тем, чтобы CDROM, сканеры или ленточные накопители не были подключены к основному каналу, на котором расположены SCSI- диски с вашими базами данных.
Так как InterBase может использовать многофайловые базы данных, расположенные на разных дисках/контроллерах/RAIDax, то в случае использования нескольких RAID-контроллеров лучше всего расположить разные части базы данных на разных дисках, в результате чего каждый контроллер будет обслуживать свою порцию базы данных
InterBase создает временные файлы на диске во время выполнения любых запросов, которые могут дать в качестве результата неопределенное количество записей (а это практически все SQL-запросы на выборку данных). Кеш InterBase предназначен лишь для хранения страниц из базы данных, а не для кеширования временных файлов. Учитывая, что большинство ОС слабо оптимизированы для работы с временными файлами, для хранения временных файлов InterBase лучше всего создать диск в памяти (RAM-диск), а в файле конфигурации ibconfig с помощью параметров TMP_DIRECTORY установить первый каталог для хранения временных файлов на этот RAM-диск. Это должно заметно улучшить производительность запросов на выборку данных.
Не разрешайте совместное использование дисков, на которых находятся базы данных Чтение и запись данных из базы данных достаточно нагружают дисковую подсистему. Если разрешать использовать тот же диск как хранилище пользовательских файлов, то производительность может заметно ухудшиться.
Используйте для организации сети как можно меньше протоколов. Лучший выбор - это применять TCP/IP. Множество протоколов может пересекаться и создавать неприятные коллизии, которые могут значительно ухудшить пропускную способность сети.
Выделите специальный сервер для InterBase-сервера, т. е. не делайте этот компьютер одновременно своим Web-сервером, почтовым сервером и сервером приложений. Помимо загрузки компьютера, дополнительные приложения могут в результате своих ошибок повредить ОС, переполнить диск или еще каким-то образом осложнить вам жизнь.
Разрушаем легенду
Несколько лет назад по всему IT-миру прокатился слух, что внутрь кода InterBase встроен универсальный пользователь и пароль, позволяющий получить доступ к любой базе данных под управлением InterBase. Имя пользователя было politically, а пароль - corrected. Надо сказать, что такой слух имел под собой основания - в одной из промежуточных версий InterBase 5.x действительно была такая "дыра" в безопасности. Однако компания Borland практически мгновенно отреагировала и выпустила "заплатку" для ликвидации этой проблемы. С тех пор в InterBase нет подобных проблем - после того, как были обнародованы исходные коды 6-й версии, в этом может убедиться каждый желающий.
Хочется отметить, что в сочетании politically/corrected (политически корректный) кроется своеобразная ирония. Как известно, принципы "политической корректности" провозглашают отсутствие двойных стандартов. Всем нам известно множество примеров, когда IT-компании "первого эшелона" допускали появление в своих продуктах (в том числе и в СУБД) многочисленных "дыр", приводивших к многомиллионным потерям. Однако про эти проблемы никто не вспоминает, а про встроенного пользователя в InterBase, который, кстати говоря, имел весьма ограниченные права, никак не могут забыть. Впрочем, может, не вспоминают эти проблемы потому, что они активно вытесняются новыми. более "свежими" прорехами в безопасности, а про InterBase, кроме этого случая, вспоминать нечего.
Как бы то ни было, вы можете сами проверить уязвимость InterBase. Попробуйте подключиться к базе данных как politically/corrected и получить несанкционированный доступ к базе данных!
Регистрация TCP/IP-сервиса при клиентской установке
Обычно клиент и сервер InterBase, будучи на разных компьютерах, связываются по протоколу TCP/IP. Чтобы получить возможность общаться по TCP/IP, необходимо серверу InterBase поставить в соответствие порт, по котором} клиент будет общаться с сервером. Для этого надо в файл services добавить такую строку:
gds_db 3050/tcp # InterBase
и после строки добавить перевод строки. Если такая строка уже присутствует в файле services, то ничего добавлять не следует - две одинаковые строки нежелательны.
Добавление этой строки в services означает, что для сетевого общения клиентов и сервера InterBase на данном компьютере выделен порт 3050. Такая запись должна быть на сервере и на всех клиентских компьютерах.
Надо отметить, что в Firebird 1.0 и Yaffil 1.0 порт 3050 задан по умолчанию, можно ничего не прописывать в services. Единственное условие - система Windows, на которой устанавливается Firebird, должна поддерживать спецификацию winsock2. Это умеют делать все Windows, начиная с Windows 98, однако даже Windows 95 можно "научить", применив соответствующий пакет обновления.
Для всех предыдущих версий InterBase запись в services необходима для работы по TCP/IP.
Файл services в ОС Windows 9x находится в каталоге Windows, а в NT/2000/XP - в каталоге WINNT\System32\drivers\etc. Для его модификации в NT/2000/XP необходимо обладать правами администратора.
Как видите, установка клиента InterBase под Windows очень проста и не требует титанических усилий. Клиента InterBase легко включить в собственный инсталляционный пакет.
Регистрация ТСР/IР-сервиса
Регистрация TCP/IP-сервиса при серверной установке ничем не отличается от регистрации при клиентской установке InterBase. Необходимо отметить, что процесс установки InterBase на NT/2000/XP должен выполняться с использованием учетной записи администратора, которая имеет права на модификацию файла services!
Рекомендации по выбору архитектуры: Classic или SuperServer?
Прочитав предыдущий раздел, читатель может ощутить необходимость немедленно перейти на сервер InterBase с архитектурой Classic. Однако стоит побороть это иррациональное стремление и хорошенько все взвесить. Ведь нельзя сказать, что Classic (или SuperServer) - однозначно лучший выбор. У каждой архитектуры есть своя "весовая категория", в которой ее использование даст наилучшие результаты. Поэтому задача разработчика - правильно определить эту категорию.
Никакой разницы в структуре базы данных и в логике проектирования клиентских приложений при использовании различных вариантов архитектуры InterBase нет. При разработке можно спокойно воспользоваться SuperServer- сервером как наиболее экономичной версией InterBase. Это особенно важно, когда сервер стоит прямо на рабочей станции у разработчика.
Необходимость выбора той или иной архитектуры InterBase становится актуальной, когда разработка приложений базы данных близится к концу и готовая база данных и программное обеспечение, работающее с ней, готовятся к передаче заказчику.
Избежать больших проблем с выбором архитектуры позволяет нам гибкость InterBase. Выбирая любую из архитектур, можно быть уверенным, что этот выбор не является фатальным и его всегда можно изменить.
Итак, что выбрать? Для начала давайте условимся, что речь идет о действительно серьезных задачах, содержащих большое количество данных, для которых критична производительность. Ведь если речь идет о программе учета накладных, которой одновременно пользуется не более пяти человек, то выбор очевиден - это SuperServer. Это сэкономит ресурсы компьютера-сервера и даст отличную производительность. Можно сказать, что SuperServer - это выбор по умолчанию, т. е., если вы не знаете, что выбрать, выбирайте SuperServer, и скорее всего он удовлетворит потребностям 80% задач.
Но есть и такие 20 % задач, для которых критически важна масштабируемость при большом количестве обслуживаемых клиентов. Именно для них н\ж- но осознанно производить выбор между архитектурами Classic и SuperServer.
Первым критерием выбора является выполняемая задача. Ответьте для себя на следующий вопрос: каково максимальное число клиентов будет единовременно подсоединено к вашей базе данных? Помните, что это число не равно числу пользователей системы, поскольку обычно даже в пиковые моменты одновременно подсоединяются к базе данных около 70-80 % от общего числа пользователей. Затем выясните, запросы какого характера выполняются в вашей системе. Это сильно зависит от того, ближе ли разработанный вами продукт к системе OLTP (on-line transaction processing), которая рассчитана на обработку множества небольших одновременных операций по занесению в базу данных, или же он ближе к системе DSS (decision support system), где преобладают длительные запросы, затрагивающие большое количество данных. В первом случае важно обработать множество запросов за короткий промежуток времени, во втором - гибко распределить нагрузку, чтобы сервер хорошо отрабатывал "тяжелые" запросы, т. е. требуется не быстрота, а нагрузочная способность (быстро не надо: никто не требует быстроты от аналитических выборок и годовых отчетов).
Если у вас OLTP-подобная система, то добавляем плюс в пользу SuperServer, если DSS, то Classic. Также поступаем и с количеством активных пользователей: если это число более 50, то Classic становится однозначно оптимальнее - ведь скорее всего систему такого масштаба будет обслуживать высокопроизводительный многопроцессорный сервер.
Следующим критерием является оборудование. Если вы счастливый обладатель многопроцессорного сервера, то на этом муки выбора заканчиваются: однозначно следует выбрать Classic, вне зависимости от количества других плюсов и минусов. Classic в полной мере позволит ощутить преимущества нескольких процессоров.
Если процессор один, то надо продолжать выбирать. Сколько у вас оперативной памяти? Если больше 1 Гбайт, то ставим плюс Classic-архитектуре, если меньше - плюс SuperServer. Каков объем базы данных? Если он невелик, т. е. может 2-3 раза целиком поместиться в оперативной памяти компьютера- сервера, то следует поставить плюс SuperServer: его совместно используемый кеш позволит загрузить базу данных практически целиком в ОЗУ.
Теперь давайте подсчитаем плюсы. Большее количество у той или иной архитектуры следует рассматривать как возможный признак того, что она больше подойдет для вашей задачи. Но в любом случае (за исключением многопроцессорных систем, где однозначно выигрывает Classic) необходимо протестировать производительность обеих архитектур с вашей базой данных на конкретной конфигурации аппаратного обеспечения (тому, как настроить и оптимизировать ваш конкретный компьютер-сервер и функционирующий на нем InterBase, посвящена глава "Оптимизация работы InterBase" (ч. 4)). Никто не может заранее предсказать. какая именно архитектура станет наилучшим решением для вашей конкретной системы СУБД, но тот факт, что у вас есть выбор, представляет собой несомненное достоинство InterBase... для тех, кто сумеет воспользоваться этим выбором.
Резервное копирование базы данных и восстановление из резервной копии
Резервное копирование (backup) базы данных и восстановление из резервной копии (restore) - два важнейших и наиболее частых административных процесса, которые осуществляются разработчиками и администраторами InterBase.
Резервное копирование базы данных - практически единственный и самый надежный способ предохранить ваши данные от потери в результате поломки диска, сбоев электропитания, действий злоумышленников или ошибок программистов.
Помимо сохранения данных от возможных опасностей, в процессе резервного копирования создается независимый от платформы стабильный "снимок" базы данных, с помощью которого легко перенести данные на другую ОСили даже другую платформу. Также backup базы данных производит своего рода "освежение" данных в базе данных, производя сборку "мусора" во время процесса считывания данных. Полный цикл: резервное копирование и восстановление из резервной копии (часто эту последовательность действий называют backup/restore или сокращенно b/r) - является средством от излишнего "разбухания" базы данных, служит для корректировки статистической информации и является обязательным участником всех профилактических и "лечебных" процедур обслуживания базы данных. В процессе backup/restore сначала все данные из базы данных копируются в backup-копию базы данных - файл специального формата (не GDB), а затем на основе сохраненных данных база данных полностью пересоздается.
Можно сказать, что процессы backup и restore - лучшие друзья разработчика и администратора InterBase. Регулярное выполнение backup/restore поддерживает "здоровье" базы данных в прекрасном состоянии, предохраняя данные от порчи и возможных ошибок.
Помимо "лечебных" целей, процесс backup/restore дает возможность изменить многие ключевые характеристики базы данных - например, сменить размер страницы базы данных, установить для базы данных режим "только чтение" (readonly), разбить файл базы данных на несколько частей. Например, смена основных версий ODS (On-Disk Structure) и миграция от одной версии InterBase-сервера к другой происходят только при помощи процесса backup/restore.
Резервное копирование базы данных InterBase
Резервное копирование (backup) базы чанных - это процесс считывания всех данных из базы данных и сохранения их в виде одною или нескольких файлов на диске или устройстве резервного копирования. Во время backup происходит считывание самых последних версий записей в таблицах базы данных на момент запуска процесса резервного копирования Старые версии записей никогда не попадают в backup.
Backup - это не просто сохранение базы данных путем простого файлового копирования средствами ОС. Во время backup специальная программа-клиент подключается к базе данных в режиме чтения и считывает все системные и пользовательские данные в файл особого формата, который обычно имеет расширение gbk (groton backup, по всей видимости).
Для экономии дискового пространства часто бывает удобно упаковывать файл резервной копии с помощью архиватора (обычно ZIP), так как это позволяет сжать размер backup в 8-10 раз.
Памятуя о том, что backup базы данных InterBase - это обычное считывание информации из базы данных, выполняемое специальной программой в режиме клиентского доступа, перечислим следующие особенности резервного копирования:
Backup базы данных InterBase может осуществляться одновременно с работой обычных клиентских программ.
Backup базы данных InterBase содержит данные, которые находились в базе данных на момент начала подключения программы, осуществляющей резервное копирование. Все изменения, проводимые выполняющимися параллельно процессу резервного копирования клиентскими программами, в резервную копию не попадут.
Во время backup происходит считывание каждой записи из каждой таблицы в базе данных. Таким образом, происходит сборка "мусора" в базе данных (garbage collection): версии записей или их фрагменты, которые не являются актуальными, уничтожаются. Место из-под удаленных версий освобождается, и оставшиеся данные переупаковываются. Подробнее о версиях записей и сборке "мусора" смотрите главу "Транзакции. Параметры транзакций" (ч. 1).
В процессе резервного копирования во время посещения всех записей происходит пересчет статистики по индексам, что улучшает производительность операций, которые используют эти индексы.
Осуществить резервное копирование базы данных InterBase можно двумя основными способами - с помощью специальной утилиты gbak из комплекта поставки InterBase или воспользовавшись Services API (на тех версиях сервера, которые поддерживают это API). Помимо этих двух штатных способов, можно также написать собственную программу, которая будет производить backup/restore в каком-либо формате, однако этот трудоемкий способ мы рассматривать не будем, так как штатные средства удовлетворяют потребностям почти всех пользователей InterBase.
Резервное копирование многофайловых баз данных
Хотя база данных InterBase 6.x может иметь размер до 90 Тбайт, однако размер одного файла обычно ограничен размером 2 Гбайт (клоны InterBase 6 - Firebird и Yaffil, а также InterBase 6.5 на NT/2000/XP поддерживают файлы размером до 16 Гбайт). Поэтому необходимо коснуться вопроса о том, как осуществить резервное копирование базы данных InterBase, содержащей несколько файлов. Формат запуска УТИЛИТЫ gbak для резервного копирования многофайловой база данных следующий:
gbak [-B] [options] <база_данных-источник> <файл резервной копии1>
sizel[k|m|g] <файл резервной копии2> [ size2[k|m|g]
Как ви1но. формат команды аналогичен обычному однофайловому backup. Параметр <база_данных-источник> определяет путь к первому файлу базы данных. Информация об остальных файлах базы данных и путь к ним хранится в заголовке первого файла. Параметр <файл резервной копии 1> определяет имя первого файла резервной копии, <файл резервной копии2> - имя второго файла резервной копии и т. д. Так как файлы backup также подчиняются ограничению в 2 (или 4) Гбайт, то при большом размере базы данных необходимо создавать многофайловую резервную копию. Каждому файлу резервной копии поставлен в соответствие параметр "size", определяющий размер этого файла. По умолчанию размер файла указывается в байтах, однако суффикс, следующий сразу за размером, позволяет изменить единицы измерения - k (килобайты), m (мегабайты), g (гигабайты).
Для наглядности рассмотрим пример резервного копирования многофайловой базы данных в многофайловую резервную копию. Вот примерная команда для осуществления backup на сервере под управлением Windows:
gbak -b - user SYSDBA -password masterkey С: \database\verybigdb. gdb
D:\bacKups\dbbackl.gbk 650M D:\backups\dbback2.gbk 650M
D:\backups\dbback3.gbk 650M
В этом примере база данных, первый файл которой назван verybigdb.gdb, будет упакована в 3 backup-файла размером по 650 Мбайт - например, для записи на 3 компакт-диска (которые обычно имеют размер 650 Мбайт). Если резервная копия получится меньше, то последний файл соответственно уменьшится (а быть может, и вообще не создастся).
Для резервного копирования многофайловых баз данных удобно пользоваться возможностью запуска gbak как сервиса на сервере базы данных, чтобы ускорить процесс backup за счет использования мощностей компьютера-сервера и отсутствия обмена по сети. Рассмотрим пример команды резервного копирования для выполнения gbak в качестве сервиса (пример для компьютера-сервера server_nt под управлением Windows):
gbak -b -user SYSDBA -password -service server_nt:service_mgr C:\database\verybigdb.gdb
D:\backups\dbbackl.gbk 650M D:\backups\dbback2.gbk 650M
D:\backups\dbback3.gbk 650M
Остальные опции для резервного копирования многофайловых база данных аналогичны параметрам, описанным в таблице 4.4.
Если условия работы InterBase таковы,
Если условия работы InterBase таковы, что база данных имеет очень большой объем (порядка нескольких гигабайтов) и должна работать 7 дней в неделю и 24 часа в сутки (часто это называют режимом 24x7), например если InterBase обслуживает Web-сервер, который не должен простаивать, то существует особая методика получения резервной копии. Для этого используется механизм SHADOW- копий базы данных. В режиме использования SHADOW сервер осуществляет одновременную запись и чтение всех изменений из двух баз данных: основной и SHADOW-копии.
Когда нам необходимо сделать резервную копию, мы на 1-2 минуты останавливаем InterBase, переименовываем файл SHADOW-копии и снова запускаем сервер Затем производим резервное копирование файла SHADOW (на другом компьютере). Этот подход позволяет избежать выполнения резервного копирования рабочей базы и, таким образом, чрезмерной загрузки компьютера-сервера.
Надо отметить, что целесообразность данного подхода прямо зависит от размера базы данных. Если база данных имеет размер в 2-3 Гбайта, не надо использовать описанный механизм - обычный backup будет приемлемым решением.
Роли
Роли InterBase - это своего рода суррогатные пользователи. Роли служат для организации пользователей с одинаковыми правами в группы. Например, если у нас имеется группа пользователей, для которых нужен дост\п только на чтение, то мы создаем роль с именем READER, присваиваем этой роли все необходимые права и затем можем назначать эту роль со всеми принадлежащими ей правами какому-то конкретному пользователю.
Вы можете поинтересоваться, зачем нужно вводить промежуточный механизм ролей, когда права можно напрямую давать пользователям InterBase, соответствующим конкретным людям. Во-первых, люди приходят и уходят, а исполняемые ими роли остаются. Во-вторых, если давать права напрямую пользователям, а не посредством ролей, то при изменении прав у определенной группы пользователей придется модифицировать права у каждого пользователя. А при использовании роли достаточно изменить права только у роли, чтобы у всех принадлежащих ей пользователей изменились права. В-третьих, большое количество прав для разных пользователей на все объекты базы данных может значительно увеличить объем данных системной таблицы RDB$USER_PRIVILEGES. Это может сказаться на скорости выполнения всех запросов, поскольку для любого запроса InterBase проверяет наличие соответствующих прав у пользователя, который выполнил запрос.
Роли - это объекты уровня базы данных. Они видны только внутри той базы данных, в которой определены. Фактически роли представляют собой записи в системной таблице RDBSROLES. Чтобы создать роль с именем READER, необходимо выполнить следующий DDL-запрос (его можно выполнить в isql или в каком-либо графическом инструменте):
CREATE ROLE READER;
При использовании механизма ролей при соединении с базой данных надо указывать и имя пользователя, и его желаемую роль. Обычно роль указывается в параметрах соединения с базой данных.
Теперь мы вплотную подошли к третьему ключевому понятию системы безопасности InterBase - к правам. Именно права являются тем. что наполняет конкретным смыслом понятия "пользователь" и "роль".
Sequence number
Порядковый номер файла базы данных. Для базы данных, состоящей из одного файла, он всегда равен нулю. Второй файл в базе данных будет иметь номер 1 и т д. В документации ошибочно написано, что это номер заголовочной страницы, однако анализ исходных кодов InterBase и эксперименты показывают, что это не так.
Сервер для InterBase
Рассмотрим компоненты сервера согласно традиционным описаниям конфигурации компьютеров: платформа, процессор, материнская плата, ОЗУ, жесткие диски, сетевую плату
Платформа. Под платформой понимается архитектура процессора, например Intel. Большинство серверов в мире продается на платформе Intel. Это неплохой и достаточно экономичный выбор. Существует версия клона InterBase 6 - Firebird - под платформу SPARC Однако большинство заказчиков систем на базе InterBase вполне обойдутся серверами на базе платформы Intel, поэтому все дальнейшие рассуждения мы будем приводить, ориентируясь на Intel.
Процессор и материнская плата. Конечно, процессор важнейшая часть любой системы, когда дело касается интенсивных вычислений, однако рассматривать его в отрыве от материнской платы неразумно: даже самый лучший процессор, "посаженный" на низкопроизводительную материнскую плату, покажет довольно "средние" результаты. Сейчас на рынке конкурируют два сочетания "процессор и материнская плата" - от AMD и от Intel. Надо сказать, что по результатам тестов эти два конкурента практически сравнялись. Поэтому рекомендации будут лишь самого общего характера: процессор должен иметь большой внутренний кеш, а материнская плата - высокую частоту шины. Следует воздержаться от дешевых процессоров на базе Celeron и Duron, а также от материнских плат с "урезанными" частотами шин (133 МГц и менее). Надо сказать, что частота шины дает серверу весьма значительное преимущество. Так. например, сервер, оснащенный процессором Intel Xeon 866 МГц, но с материнской платой, у которой частота шины 66 МГц, значительно проигрывает в производительности "простому" Pentuim 3-866, но "посаженному" на материнскую плату с частотой 133 МГц. Поэтому при выборе материнской платы для сервера следует обратить внимание на платы с частотой шины 266 МГц (для AMD-процессоров) и 400 МГц (для Intel-процессоров). Разумеется, закон Мура еще никто не отменял, и к моменту выхода книги ситуация на рынке процессоров может ситьно измениться но рекомендации - "высокая частота шины у материнской платы и большой кеш у процессора" - останется прежними.
Два процессора и более. Несколько процессоров не дадут большого прироста производительности для InterBase, имеющего архитектуру SuperServer, но для архитектуры Classic позволят "почувствовать разницу" (подробнее о преимуществах и достоинствах различных вариантов InterBase см. ниже главу "Classic и SuperServer"). Поэтому если сервер выделен только под InterBase, а задача не требует использования Classic-архитектуры, то лучше сэкономить на многочисленных процессорах (и материнских платах для них) и выбрав однопроцессорный вариант.
ОЗУ. Оперативная память - весьма важный компонент серверной системы. Минимум ОЗУ, который позволит InterBase 6 работать, - это 32 Мбайт (возможно, и меньше; к сожалению, не нашлось компьютера с количеством ОЗУ 8 или 16 тМбайт, чтобы проверить). В наш век дешевых гигабайтов смешно говорить о таком небольшом количестве памяти, но InterBase действительно очень экономичен в использовании ОЗУ. Обычно количество ОЗУ рассчитывается следующим образом: необходимо взять среднее количество клиентов, одновременно использующих базу данных, выделить каждому по 10-15 Мбайт, затем прибавить 150 Мбайт. Например, если у вас 20 клиентов, то получим: 15*20+150 = 450 Мбайт. Нужно отметить, что величина в 10-15 Мбайт на клиента нужна в случае, если речь идет про архитектуру Classic, а клиенты весьма интенсивно работают с базой данных, например осуществляют аналитические выборки или что- то в этом роде. Вариант InterBase с архитектурой SuperServer значительно экономичнее расходует память - ему необходимо примерно на 30 - 40 % меньше ОЗУ
Если обратиться к реальной практике, то 50-60 клиентов системы АСТПП среднею класса (при размере базы данных около 1 Гбайт) неплохо обслуживаются InterBase SuperServer с 512 МБайт ОЗУ. Конкретные рекомендации таковы: для сервера, на котором ведется разработка, необходимо около 256 Мбайт ОЗУ, для рабочего сервера, обслуживающего задачу и среднего класса (т. е. 10 одновременно работающих активных пользователей), - 512 Мбайт и более. Количество ОЗУ также зависит от используемой ОС -для Linix обычно нужно меньшее количество ОЗУ для поддержания определенного уровня производительности, чем для Windows NT/2000.
Жесткие диски. Дисковая подсистема - один из наиболее важных компонентов сервера, который способен при неправильном его выборе чрезвычайно ухудшить производительность. Для InterBase-сервера неплохо использовать отказоустойчивые дисковые подсистемы на базе RAIDS-массивов, причем желательно иметь контроллер с кеш-памятью не менее 32 Мбайт. Но это достаточно дорогое решение, поэтому для систем, не предъявляющих особых требований к производительности, можно остановиться на более дешевых IDE-накопителях, поддерживающих различные UDMA-режимы доступа. Крайне нежелательно использовать программный RAID-массив, эмулирующий зеркальное отображение информации, - это верный способ замедлить сервер.
Сетевая плата. Сервер должен обеспечивать надежное сетевое соединение с десятками и сотнями пользователей. Нельзя сказать, что дорогие сетевые платы, рекламируемые производителями как "специальные серверные решения", будут работать заметно быстрее обычных сетевых плат, установленных на клиентах Сложно утверждать конкретно, в чем они надежнее обычных сетевых плат. В этой области рынка аппаратною обеспечения слишком много рекламного тумана, в котором спрятаны реальные преимущества серверных сетевых плат. Собственно, почти во всех случаях достаточно будет поставить на сервер, выделенный под InterBase, обыкновенную качественную сетевую плату - возможно, ту же, которая применяется на клиентах.
Сетевое оборудование
В настоящее время стандартом для корпоративных и офисных сетей является 100-Мбит Ethernet-сеть, основанная на витой паре (100Base-T). Она обеспечивает пропускную способность 3-10 Мбайт/с. 100-Мбит сеть достаточна для большинства клиент/серверных-приложений, в том числе и для приложений, использующих InterBase.
Обычно для организации сетевого общения InterBase и клиентов используется протокол TCP/IP, который является наиболее универсальным и масштабируемым сетевым протоколом. Практически все примеры в книге основываются на применении протокола TCP, хотя InterBase позволяет связываться и по протоколам Named Pipes и IPX.
Надо сказать, что неустойчиво работающая сеть, в которой часто теряются пакеты, является причиной возникновения ошибок InterBase 10054, загромождающих файл протокола InterBase.log. Поэтому, хотя вопросы настройки и обслуживания сети выходят за рамки данной книги, необходимо обратить особое внимание на обеспечение работы сети.
Shadow count
Число файлов Shadow, которые определены для данной базы данных. Как известно, файлы Shadow представляют собой зеркальные подобия основной базы данных. Ранее предназначенные для предохранения базы данных от неожиданной поломки жесткого диска, теперь они в основном используются в целях резервного копирования - для снятия мгновенных снимков базы данных (подробнее см. в этой части, в главе "Резервное копирование базы данных и восстановление из резервной копии").
Система безопасности InterBase
Разъяснив ряд "идеологических" особенностей защиты информации в InterBase, можем перейти к конкретному описанию системы безопасности этой СУБД и ее применению на практике. Начнем наше рассмотрение с основных понятий, которыми оперирует система безопасности.
Сохранение информации о пользователях при миграции
Далее, после получения корректной резервной копии вашей рабочей базы данных, необходимо установить новую версию InterBase. Процесс установки описан в главе "Установка InterBase" (ч 1), и в этой главе мы останавливаться на этом не будем. Но при установке новой версии в рамках миграции вне зависимости от того, куда устанавливается новая версия сервера InterBase - на новый компьютер пли на тот же, где стояла предыдущая версия, необходимо позаботиться о перенесении пользователей InterBase на новый сервер (конечно, если в вашей системе применяются еще какие-то вами созданные пользователи помимо устанавливаемого по умолчанию пользователя SYSDBA). Пользователи хранятся отдельно от вашей базы данных — для их хранения существует база данных ISC4.gdb, которая находится в том же каталоге, где установлен InterBase.
Помните, что, хотя пользователи хранятся в отдельной базе данных ISC4 gdb, вес разрешения и права для них хранятся в той же базе, где и объекты, на которые выдавались разрешения (т.е. в самой рабочей базе данных). Все эти права сохраняются при переходе на новую версию InieiBase (т.е. они не исчезают при backup/restore). Подробнее о пользователях и нравах см ниже главу "Безопасность в ImeiBase пользователи, роли и права"
При переустановке поверх старой версии установщик InterBase очень мудро не затирает существующие ISC4.gdb (а также ISC4.gbk), чтобы ненароком не с тереть информацию о пользователях Однако, несмотря на такую предусмотрительность, могут возникнуть проблемы связанные с тем что новый сервер может не суметь прочитать оставшеюся в наследство ISC4.gdb из-за различия в структурах баз данных новой и старой версии InterBase.
Чтобы избежать потерь информации и других проблем с базой данных пользователей ISC4.gdb при переустановке InterBase, надо сделать следующее:
до установки новой версии сделать backup ISC4.gdb с использованием старой версии InterBase;
в случае установки новой версии поверх старой переместить ISC4 gdb из установочного каталога InterBase, чтобы она не помешала установщику InterBase записать туда свою ISC4.gdb, которая создается по умолчанию при новой установке;
после установки новой версии InterBase надо восстановить базу данных пользователей из созданной резервной копии старой ISC4.gdb и заменить ею ту, которая была создана по умолчанию при установке новой версии.
Рассмофим теперь этот процесс подробнее. Для резервного копирования ISC4.gdb можно воспользоваться командой вроде этой:
gbak -b -user SYSDBA -password <пароль>
C:\IBServer\isc4.gdb С :\isc4.gbk
Для восстановления следует воспользоваться тем, что при установке новой версии всегда создается пользователь SYSDBA (с паролем по умолчанию masterkey) и мы можем восстановить backup старой ISC4.gdb:
gbak -с -user SYSDBA -password masterkey
C:\isc4.gbk С:\isc4.gdb
а затем заменить восстановленной копией ту ISC4.gdb, которая сформировалась по умолчанию в результате установки:
сору C:\isc4.gdb <путь к каталогу с новой версией IB>\isc4.gdb /у
Перед процедурой копирования восстановленной ISC4.gdb на положенное место желательно остановить сервер InterBase.
Состав модулей InterBase
Давайте подробнее рассмотрим, из каких файлов состоит сервер и клиент InterBase. Эта информация нужна для того, чтобы понимать, из каких ключевых модулей состоит сервер, и уверенно осуществлять администрирование сервера, например смену версий сервера.
В этой главе мы рассмотрим вариант InterBase с архитектурой SuperServer (SS) под Windows, а также Classic Server (CS) под Linux. Состав модулей, входящих в InterBase на других ОС, рассматривать здесь не будем, поскольку отличия будут незначительные.
Совместимость клиентов и серверов различных версий
Как известно, клиент-серверное приложение, использующее СУБД InterBase, обычно состоит из двух основных частей - клиентской и серверной. Клиентская часть, обычно состоящая из исполняемого модуля приложения базы данных (как правило, ехе-файла) и динамических библиотек, исполняется на клиентском компьютере. Серверная часть - собственно базы данных и серверные модули InterBase, обслуживающие клиентские запросы, - исполняется на компьютере- сервере (подробнее о составе модулей, образующих клиент и сервер СУБД InterBase, см. ниже главу "Состав модулей InterBase").
То, что в результате переустановки InterBase и миграции базы данных вы смените версию сервера InterBase на компьютере-сервере, не означает, автоматической замены клиентов на всех клиентских компьютерах. Обычно необходимо вручную заменить клиентскую часть InterBase на этих компьютерах. То есть обычно клиенты InterBase должны иметь ту же версию, что и сервер. Однако если вы не замените клиентские части, то можете обнаружить, что клиенты от младшей версии InterBase работают со старшей версией InterBase-сервера. Такая совместимость - вполне нормальная, документированная особенность, которая используется для облегчения процесса миграции. Возможность использования клиентов и серверов InterBase различных версий представлена в таблице 4.7.
Табл 4.7. Совместимость клиентов и серверов различных версий InterBase
|
Сервер от версии |
Клиент версии | ||||||
|
/диалект БД |
InterBase 4.x |
InterBase 5.x |
InterBase 6.x и клоны | ||||
|
InterBase 4 х |
Полная |
Полная |
Полная | ||||
|
InterBase 5 х |
С ограничениями |
" |
" | ||||
|
InterBase 6 х и его клоны /диалект 1 |
Неустойчивая |
С особыми свойствами |
" | ||||
|
InterBase 6.x и его клоны /диалект 3 |
" |
" |
" | ||||
В таблице 4.7 на пересечении версии клиента и версии сервера (для 6.x - с учетом диалекта базы данных) стоит описание их совместимости.
Как видно, совместимость клиентов и серверов InterBase имеет 4 основных разновидности - полную, с ограничениями, с особыми свойствами и неустойчивую.
Полная совместимость возможна в ситуации, когда клиент и сервер имеют одинаковые версии или когда версия клиента старше версии сервера. Полная совместимость означает, что клиент может реализовать всю функциональность, предлагаемую сервером.
Совместимость с ограничениями означает, что, хотя сервер и предлагает большую функциональность, чем может поддержать клиент, их взаимодействие все же вероятно - в рамках тех возможностей, которые поддерживает клиент.
Неустойчивая совместимость означает, что взаимодействие слишком "старого" клиента и сервера возможно, но в ряде случаев такое взаимодействие может привести к ошибкам сервера или клиента, а также к порче данных. Такое сочетание клиента и сервера использовать не рекомендуется.
Совместимость с особыми свойствами возникает, когда клиенты версии 5.x связываются с базами данных, работающими под управлением InterBase-сервера версии 6.x. Причем тот факт, имеет ли база данных диалект 1 или диалект 3, имеет большое значение.
Если клиент от версии 5.x соединяется с базой данных 6.x, имеющей диалект 1, то он получает возможность работать с этой базой так, как будто она находится под управлением InterBase-сервера 5.x. Это означает (помимо невозможности использовать новые свойства InterBase 6.x), что, если в переведенной из-под 5.x базе данных есть объекты, название которых совпадает с каким-либо новым ключевым словом InterBase 6.x, клиенты 5.x по-прежнему будут иметь возможность работать с этой базой данных, используя ключевые слова в качестве идентификаторов. Но только для доступа к уже существующим объектам. Создание новых объектов, использующих в качестве идентификаторов ключевые слова. невозможно ни в клиентах 5.x, ни в клиентах 6.x.
Вот список новых ключевых слов, появившихся в InterBase 6.x:
COLUMN, CURRENT_DATE, CURRENT_TIME, CURRENT_TIMESTAMP, DAY, EXTRACT, HOUR, MINUTE, MONTH, SECOND, TIME, TIMESTAMP, TYPE. WEEKDAY, YEAR, YEARDAY.
Клиенты InterBase 5.x, подсоединяющиеся к базе данных 6.x, которая имеет диалект 3, имеют следующие ограничения:
отсутствие доступа к полям, имеющие новые типы данных, определенные в 3-м диалекте InterBase 6.x;
отсутствие доступа к идентификаторам, заключенным в кавычки;
поля, имеющие тип DATE, рассматриваются клиентами 5.x как тип TIMESTAMP, т. к. в 4.x и 5.x тип "дата+время" назывался DATE.
Клиенты, применяющие для доступа к базе данных BDE версии ниже 5.3, не могут использовать объекты, имеющие новые типы данных, появившихся в 3-м диалекте InterBase 6.x.
Подводя итог разделу о совместимости клиентов и серверов, необходимо добавить, что, несмотря на возможность использовать "старых" клиентов, лучше всего использовать клиентов той же версии, которую имеют и серверы. Причем желательно, чтобы это соответствие было точным - вплоть до номеров билдов. То есть если вы используете в качестве сервера какой-нибудь клон InterBase. например Fuebnd 1 0, то желательно использовать и клиента именно от этой версии, а не от InterBase 6.0.1, например.
Совместное использование файлов
InterBase-сервер может быть встроен не только в ваше серверное программное обеспечение, поэтому основные файлы, входящие в состав его установки, надо зарегистрировать в Windows. Регистрация происходит точно так же, как описано выше в разделе "Совместное использование gds32.dll, InterBase.msg и mscvrt.dll", только помимо этих трех файлов надо зарегистрировать также файл ibserver.exe.
Совместное использование gds32.dll, InterBase.msg и mscvrt.dll
Представьте ситуацию, когда на одном компьютере оказались два приложения, использующие клиент InterBase. Первое приложение успешно инсталлировалось, установив вместе с собой InterBase-клиента. Второе приложение в процессе установки обнаружило, что клиент InterBase, удовлетворяющий его, уже существует, и ничего не стало устанавливать. Затем первое приложение было удалено с компьютера с помощью автоматического установщика. Правила хорошего тона Windows требуют, чтобы удаляющееся приложение убирало за собой ненужные dll и другие вспомогательные файлы. Однако gds32.dll и остальные файлы все еще используется другим приложением! Чтобы предотвратить удаление еще нужного клиента InterBase, необходимо указать установщику, что библиотеки gds32.dll, msvcrt.dll и файл InterBase.msg используются еще одним приложением. Для этой цели служит специальный счетчик, хранящийся в реестре Windows. Вне зависимости от того, устанавливало ли приложение при своей установке какие-либо файлы dll или удовлетворилось существующими, необходимо при установке увеличить этот счетчик на единицу, а при удалении программного обеспечения - уменьшить. Когда значение счетчика примет значение О, то это будет сигналом, что данную библиотеку можно удалить. Вот ветка реестра, где располагаются счетчики для совместно используемых динамических библиотек:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\
SharedDLLs
При установке клиента InterBase необходимо в этой ветке реестра искать ключ типа DWORD с именем C:\WlNDOWS\System32\gds32.dll, и если его не существует, то необходимо создать его (это означает, что установка производится в первый раз) и присвоить ему значение 1. Если такой ключ уже существует, то нужно увеличить его значение на единицу. Точно такую операцию надо проделать над ключами, содержащими ссылки на msvcrt.dll и InterBase.msg.
Спасение данных из поврежденной базы данных
Возможно, что все вышеприведенные действия не приведут к восстановлению базы данных. Это означает, что база серьезно повреждена и либо совсем не подлежит восстановлению как единое целое, либо для ее восстановления понадобится приложить значительное количество усилий Например, можно вручную осуществить модификацию системных метаданных, воспользоваться недокументированными функциями и т. д. Это очень тяжелая, длительная и неблагодарная работа с сомнительными шансами на успех, поэтому по возможности надо избегать ее и пользоваться другими способами. Если поврежденная база данных открывается и позволяет производить операции чтения и модификации хотя бы над частью данных, то нужно воспользоваться этой возможностью и спасать данные путем перекачки их в новую базу, а со старой базой распрощаться навсегда.
Итак, чтобы приступить к переносу данных из старой базы данных, надо сначала создать базу-приемник. Если база данных устоявшаяся (метаданные давно не менялись), то для создания базы данных-приемника можно воспользоваться какой-нибудь старой backup-копией, из которой можно извлечь метаданные (для этого лучше всего воспользоваться какой-нибудь утилитой администрирования). На основе этих метаданных необходимо создать базу данных-приемник и приступить к перекачиванию данных. В принципе главное - это вытащить данные из поврежденной базы данных, а размещение этих данные в новой базе является задачей менее трудоемкой и сложной, даже если придется восстанавливать структуру базы данных "по памяти".
При извлечении данных из таблиц следует пользоваться следующим алгоритмом действий:
Сначала нужно попытаться выполнить SELECT * FROM tableN. Если это прошло нормально, то вы можете сохранить полученные данные во внешнем источнике. Для этой цели хорошо подходит сохранение данных в скрипт (такую функцию предоставляют почти все графические утилиты администрирования), если только таблица не содержит BLOB-полей. Если в таблице есть BLOB-поля, то данные из них необходимо сохранять в другую базу данных с помощью программы-клиента, которая будет исполнять роль посредника. Возможно, вам придется написать эту тривиальную программу специально для целей восстановления данных.
Статистика базы данных InterBase
Из базы данных InterBase можно извлечь следующие виды статистики, различающиеся тем, откуда была получена информация:
Статистика заголовочной страницы (header page information). Это информация о глобальных свойствах всей базы данных, которая содержится на заголовочной странице каждой базы данных.
Статистика страницы протокола базы данных (database log page information). Это информация не используется в современных версиях InterBase 6.x и рассматриваться здесь не будет, хотя с помощью утилиты gstat можно получить представление о том, как выглядела эта статистическая информация.
Статистика страниц данных (data page information). Это информация о таблицах, содержащихся в базе данных, которая включает в себя номера страниц данных и страниц указателей для данной таблицы, степень заполнения страниц и другую важную информацию.
Статистика индексов (index information). Это информация об индексах в базе данных, включающая имя индекса, его глубину, среднюю длину ключей, процент заполнения страниц индексов и т. д.
Статистика системных таблиц (system relations information). Это информация о системных таблицах и индексах. Она аналогична статистике для обычных таблиц и индексов.
Мы подробно рассмотрим все эти виды статистики, но сначала остановимся на способе ее получения.
Статистика InterBase-сервера
Часто разработчики программ под InterBase желают получить информацию о поведении сервера во время выполнения запросов - использовании процессорного времени, загрузке памяти и т. д. Чтобы удовлетворить эти запросы, в InterBase и его клонах реализована функция InterBase API isc_database_info(), возвращающая необходимую информацию. Параметры этой функции перечислены в [4, гл. 8]. Очевидно, что писать каждый раз, когда потребовалась статистика, специальную программу с вызовами InterBase API неудобно, да и не нужно, потому как множество подобных высококачественных продуктов уже существует.
Одним из таких продуктов является MiTeC InterBase Performance Monitor (IBPM). Это свободно распространяемая программа, автором которой является Михаэль Матл (Michal Mutl). Этот монитор работает на всех ОС Windows, начиная с Windows 95. Эта программа отслеживает параметры InterBase-сервера, представленные в табл. 4.15.
Табл 4.15. Параметры производительности сервера
|
Параметра |
Описание параметра | ||
|
Memory and CPU usage |
Использование памяти и процессора | ||
|
Reads from memory buffer cache |
Число чтений из кеша в памяти с момента запуска InterBase-сервера | ||
|
Writes to memory buffer cache |
Число записей в кеш-память с момента запуска InterBase-сервера | ||
|
Reads from database |
Число чтений из базы данных с момента запуска текущего соединения | ||
|
Writes to database |
Число записей в базы данных с момента запуска текущего соединения | ||
|
Active users |
Число активных пользователей | ||
|
Server log |
Если сервер поддерживает Services API для статистики, то можно получить протокол работы сервера | ||
|
Allocated pages |
Число распределенных страниц в базе данных | ||
|
Number of buffers |
Размера кеша | ||
|
Removals of a version of a record |
Число удалений версий записей с момента текущего соединения | ||
|
Removals of fully mature records |
Число удалений записей с момента текущего соединения | ||
|
Removals of a record and all of its ancestors |
Число удалений записей и всех предков | ||
|
Reads done via index |
Количество чтений, осуществленных с помощью индекса (вычисляется для каждой таблицы с момента текущего соединения) | ||
|
Sequential table scans |
Количество последовательных проходов по таблицам | ||
|
Database updates |
Число обновлений в базе данных с момента текущего соединения | ||
|
Database inserts |
Число вставок в базу данных с момента текущего соединения | ||
|
Database deletes |
Число удалений в базе данных с момента текущего соединения | ||
|
Local SQL Monitor (for apps based on FIBPIus) |
Для приложений, написанных на FIBPIus, есть возможность отслеживать SQL-запросы, направляемые к базе данных |
Как видите, достаточно большое поле для изучения поведения InterBase- сервера MiTeC InterBase Performance Monitor не требует специальной установки - достаточно, чтобы на компьютере, где он запускается, был установлен клиент InterBase Удобный интерфейс поможет легко разобраться с использованием данной программы.
Помимо вышеперечисленных возможностей MiTeC IBРМ может также извлекать статистику базы данных, которую можно получать с помощью утилиты gstat.
Статистика по блокировкам
InterBase использует механизм блокировок, чтобы организовывать совместную работу многих пользователей с одной базой данных. Изучение статистики по блокировкам позволяет регулировать настройки механизма блокирования. Подробнее об этом написано в приложении "Параметры конфигурационного файла InterBase" Для получения такой статистики нужно использовать утилиту iblockpr (для Windows, а для Linux - gds_lock_print), которая предназначена специально для получения данных о блокировках. Обычно эта утилита располагается в подкаталоге BIN в основном каталоге InterBase.
Формат ее запуска и применяемые подробно изложены в [4, гл. 8], поэтому мы не будем здесь его приводить, тем более что область применения подобной статистики достаточно узка: ее анализ может производиться при тонкой на- стройке конфигурации сервера В 90% случаев изменять параметры механизма блокировок не требуется.
Статистика страниц индексов
Чтобы получить статистику по страницам индексов, необходимо либо указать при запуске gstat ключ -index, либо запустить с ключом -all. Статистика по одному индексу выглядит следующим образом:
CUSTOMER (33)
Index CONTACT_IDX (5)
Depth: 2, leaf buckets: 32, nodes: 20005
Average data length: 1.00,
total dup: 17584, max dup: 12096
Fill distribution:
0 - 19% = 0
20 - 39% = 0
40 - 59% = 22
60 - 79% = 4
80 - 99% = 6
Здесь CUSTOMER - имя таблицы, для которой создаются индексы. CONTACT_IDX - это имя индекса, а 5 - порядковый номер индекса для данной таблицы (нумерация начинается с нуля). Самым важным параметром в получаемой информации является глубина индекса - Depth. Она определяет, сколько веток в "дереве" индекса необходимо пройти, чтобы вычислить нужную запись (подробнее см. в главе "Индексы" (ч. 1)). Важно, что глубина индекса не была больше трех, так как в этом случае эффект от использования индекса невелик. Если она больше, то следует увеличить размер страницы данных в базе данных. Остальные параметры означают следующее: leaf buckets - число страниц на концах дерева ("листьев"); nodes - полное число узлов в индексе; Average data length - средняя длина ключей в индексе. Параметры total dup и max dup характеризуют число повторений записей в индексе. Таблица Fill distribution аналогична по своему назначению такой же таблице, входящей в состав информации о с i раницах данных.
Статистика базы данных дает возможность точнее диагностировать проблемы, возникающие в процессе эксплуатации, позволяет произвести тонкую настройку производительности и является неотъемлемой частью профилактических процедур, производимых над базой данных.
Статистика в InterBase
Статистика - одно из изобретений человечества, которое позволяет количественно оценить динамику развития каких-либо процессов и принимать важные решения на основе цифр, а не только интуиции. InterBase предоставляет большое количество статистических данных, многие из которых могут быть использованы для принятия решений, способствующих оптимизации работы сервера. В этой главе будут рассмотрены виды статистической информации InterBase и способы ее получения и интерпретации.
Статистика в InterBase бывает двух видов - статистика базы данных и статистика сервера. Сначала мы рассмотрим статистику базы данных.
SuperServer
Архитектура SuperServer реализует принцип "все в одном", т. е. существует один-единственный серверный процесс, который обслуживает всех клиентов. Экп процесс никто не выбывает, он выполняется где-то в недрах ОС, ожидая запросов (на Unix-системах SuperServer реализован в виде демона, а в Windows NT /2000 - в виде службы Windows NT).
Все действия, выполняемые отдельными процессами в Classic-архитектуре, в в SuperServer выполняются отдельными потоками (threads) в рамках единого серверного процесса. Существует поток, который занимается разрешением конфликтов, другой поток обслуживает запросы на соединение, множество других потоков играют роль отдельных серверных процессов рахитектуры Classic по обслуживанию клиентов.
Из-за того что все клиенты находятся в адресном пространстве одного процесса (но в разных потоках), значительно упрощается и ускоряется разрешение конфликтов. Вместо механизмов межпроцессного взаимодействия используется более быстрый межпотоковый обмен. Исчезают издержки на запуск множества процессов, а ведь каждый процесс забирает у ОС довольно значительную часть ресурсов
Для обработки пользовательских запросов в SuperServer применяется единый кеш. позволяющий свести к минимуму бесполезный расход памяти. Например, если клиеш открыл соединение и дальше не проявляет активности, то ему будет выделен минимапьно необходимый для поддержания соединения размер ОЗУ.
Помимо вышеперечисленных достоинств, в SuperServer реализован интерфейс Services API, который позволяет управлять сервером через клиентское соединение Таким образом, архитектура SuperServer способна обслужить больше клиентов, чем Classic, используя при этом меньше ресурсов.
Сущность процесса миграции
Миграция - это перенос баз данных между различными версиями InterBase, а также платформами и ОС. Миграция заключается в том, что в системе- источнике (где система - это уникальное сочетание версии InterBase-сервера, ОС и аппаратной платформы, например InterBase 5.6 +Windows NT+Intel) данные из базы данных "складываются" в некоторый универсальный формат, из которого затем они разворачиваются в базу данных в системе-приемнике с учетом ее особенностей. Универсальный формат должен "пониматься" всеми модификациями InterBase, конечно, с ограничениями на переносимость между старыми и новыми версиями.
Этим универсапьным промежуточным хранилищем для данных является резервная копия базы данных (backup), созданная в виде transportable backup (подробнее о процессе резервного копирования и восстановления см. в этой части главу "Резервное копирование и восстановление из резервной копии").
В самом простом случае миграция заключается в том, чтобы создать backup на системе-источнике (где система - это сочетание InterBase+OC-t-платформа) и восстановить эту резервную копию на системе-приемнике. Такой способ применим в случае перехода с предыдущей версии InterBase на новую (например, с 5.x на 6.x). Примером более сложного случая миграции является смена диалекта базы данных с 1-го на 3-й, где необходимо либо применять инструмент модификации базы данных gfix, либо полностью пересоздавать базу данных.
Sweep interval
Параметр устанавливает интервал между старейшей активной и следующей транзакциями (ОГГ и Next), после которого начинается сборка "мусора". Более подробно об этом можно прочитать в главах "Оптимизация работы InterBase" (ч. 4) и "Транзакции. Параметры транзакций" (ч. 1).
Помимо рассмотренных параметров, информация в заголовочном файле содержит информацию о вторичных файлах базы данных - имя, размер и расположение.
Теперь можно перейти к рассмотрению других видов статистической информации, получаемых из базы данных InterBase.
Если посмотреть статистику по базе данных (как это сделать - см. в этой части главу "Статистика в InterBase"), то можно обнаружить в данных о заголовочной странице параметр Sweep interval. Этот параметр устанавливает разницу между старейшей интересующейся транзакцией (ОГГ) и следующей транзакцией (Next), при которой следует запускать процесс сборки "мусора". Подробнее о транзакциях и сборке "мусора" вы можете прочитать в главе, посвященной транзакциям (ч. 1), а с точки зрения производительности Sweep Interval интересует нас, поскольку при сборке "м>сора" работа обычных клиентов, работающих с базой данных, может замедлиться. Особенно это актуально для серверов, работающих в круглосуточном режиме Чтобы избежать проблем с производительностью, связанных с периодической сборкой "мусора", устанавливают Sweep Interval равным нулю, что означает запрет автоматической сборки "мусора". В этом случае процесс сборки "мусора" осуществляют вручную - например, с помощью резервного копирования. Дело в том, что процесс резервного копирования базы данных обычно сопровождается сборкой "мусора" (если не установлен флаг -garbage_collect). Полной заменой sweep процесс backup нельзя назвать, гак как во время sweeping происходит обновление статуса транзакций Поэтому если и отказываться от sweep, то необходимо заменить его не просто резервным копированием, а регулярным циклом backup/restore.
Чтобы установить sweep interval, используют инструмент gfix. Например, чтобы установить sweep interval в 0 и запретить автоматическую сборку "мусора", надо выполнить следующею команду:
gfix -h 0 -user SYSDBA -password <пароль> С:\database\myDatabase.gdb
Типы данных для работы с датой и временем
В версиях 4.x и 5.x и 1-м диалекте 6.x присутствует только один тип данных - DATE, который позволяет хранить информацию о дате и времени суток. В 3-м диалекте существует 3 типа для работы с датой и временем - это тип TMESTAMP, хранящий информацию о дате и времени (т. е он аналогичен типу DATE в 1-м диалекте и в 5.x), тип DATE, хранящий информацию только о дате, и тип TIME, хранящий информацию только о времени. Довольно запутанно, не так ли? Функции "старого доброго" DATE теперь берет на себя TIMESTAMP, a DATE, изменив свое назначение, означает теперь только дату.
Как же происходит замена типов данных? Объявления столбцов типа DATE автоматически меняют свой тип на TIMESTAMP уже при переходе на диалект 1 InterBase 6x, а вот с переменными типа DATE, использующимися (может быть) в триггерах и процедурах, ситуация сложнее. Они не меняют свой тип автоматически, и необходимо будет сменить их тип ("старый" DATE) на TIMESTAMP перед сменой диалекта 1 на 3.
Типы страниц и их использование
Давайie подробнее рассмотрим каждый тип страниц и ознакомимся с их назначением и информацией, которая на ни\ содержится Начнем по порядку - ч. самой первой сфаницы
Любая работа с базой данных начинается с чтения страницы заголовка базы данных (или заголовочной страницы) Страница заголовка базы данных всегда иде! первой в первом файле базы данных Соответственно она изображена первой и на рис 4 Ч (если представить, что рисунок представляет протяженность фай ia базы данных с 1ева направо сверху вниз)
Заголовочная страница содержит информацию о базе данных в целом. На рис 4 4 изображена страница данных так, как это показывает нам IBSurgeon
Получить представление о содержании заголовочной страницы также можно, получив статистику по базе данных Для этого можно воспользоваться утилитой командной строки qstat или каким-нибудь более удобным инструментом для администрирования InteiBase из списка в приложении "Инструменты администратора и разработчика InterBase" Подробнее процесс получения статистики для базы данных и описание данных заголовочной страницы содержатся в главе "Статистика в InterBase" (ч 4)
Здесь стоит лишь отметить, что заголовочная страница содержит такую важную информацию, как размер страницы, номер версии ODS (On-Disk Structure) (см о ней ниже], конфольная сумма базы данных (для On-Disk Structuie 9 хх и старше она обычно равна 12345), дата создания базы данных, а также информацию о транзакциях и множество других сведений. Например, Implementation ID хранит информацию о том. под какой ОС эта база данных была создана
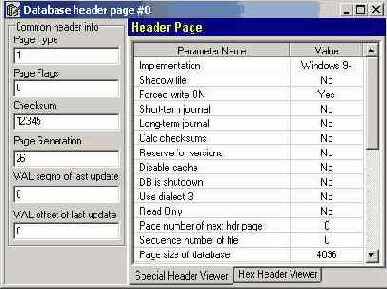
Рис 4.4. Страница заголовка базы данных (header page)
При подключении к базе сервер InterBase считывает первые 1024 байта информации от начала файла и определяет по считанным значениям, действительно ли файл, указанный в строке соединения, является базой данных InterBase. Затем сервер с заголовочной страницы считывает номер версии ODS (On-Disk Structure) и размер страницы в этой базе данных и, если версия ODS совместима с реализацией сервера, производит перечитывание всей заголовочной страницы, пользуясь уже корректным размером страницы, полученным из первых 1024 байт После этого с заголовочной страницы считываются остальные важные параметры базы данных - режим чтения-записи, диалект базы данных и т.д.
На заголовочной странице находится ссылка на первую из страниц указателей (Pointer page), на которой содержащие ссылки на страницы данных, содержат метаданные: таблицу RDBSPages (см. ниже в разделе "Логическая структура базы данных InterBase"). На рис. 4.3 эта ссылка проиллюстрирована стрелкой с надписью Number of the 1st pointer page in database, т. е. "номер первой страницы указателей в базе данных". Сервер читает номер первой страницы указателей с заголовочной страницы и переходит к ней. Фактически он просто отсчитывает "размер страницы умножить на номер страницы" байт.
Страница указателей состоит из упорядоченного массива номеров страниц данных, составляющих определенную таблицу (таблица понимается в смысле SQL-объекта, описываемого логической структурой базы данных). Вот как интерпретирует страницу указателей IBSurgeon (рис. 4.5).
Рис 4.5. Страница указателей базы данных InterBase (pointer page)
Страница содержит список страниц данных (data page vector), которые составляют определенную таблицу в базе данных. Список представляет собой массив указателей, соответствующих номерам страниц данных в файле.
Сервер считывает 4-байтовый номер страницы данных и переходит к нужной странице данных. Перейдя на первую страницу данных, составляющих RDBSPages, сервер начинает построение внутреннего представления базы данных, которое в дальнейшем используется сервером для всех операций с базой данных.
В RDBSPages содержатся ссылки не только на страницы данных, хранящие информацию о базе данных, но и на все остальные страницы, играющие роль в обеспечении работы базы данных
Мы часто упоминаем эту таблицу, что, строго говоря, относится к логической структуре базы данных. Тем не менее все очень взаимосвязано, поэтому нельзя описывать одно, не ссылаясь на другое.
Важным типом страниц являются страницы, учитывающие транзакции (TIP. '1 гапьаиюп inventor)' page) Они, как и все страницы, состоят из заголовка и основной части, представляющей собой массив из 2-битовых последовательностей. Эти последовательности описывают состояние транзакций в базе данных (подробности о транзакциях см. в главе "Транзакции. Параметры транзакций" (ч. 1)).
Табл 4.23. Возможные состояния транзакции в Transaction inventory page
|
Значение последовательности на странице учета транзакций |
Смысл |
|
0 |
Транзакция не запускалась, активна или потеряна без commit или rollback |
|
1 |
Транзакция завершилась Commit |
|
2 |
Транзакция завершилась rollback |
|
3 |
Limbo-транзакция (для 2РС) |
Заголовочная страница базы данных, страницы указателей и страницы учета транзакций относятся к служебным ("housekeeping") типам страниц, которые используются только сервером Информация, содержащаяся в них, никогда не попадает к пользователям InterBase К служебному тип) страниц также относятся страницы учета страниц (обычно они упоминаются как Page Inventoiy Page (PIP) или Space Inventoiy pages (SIP)) Эти страницы расположены начиная со второй, т е первая PIP саедует прямо за заголовочной страницей, и появляются в базе данных через фиксированные промежутки страниц других типов Размер этих промежутков т е через какое количество страниц других типов появляется Р1Р, зависит от размера страницы, установленного для данной базы данных Page Inventoiy Pages не учитываются на страницах указателей (Pomtei page) и не указаны в RDB$Pages Целостность этих страниц критична дтя здоровья всей базы гак как содерлуимое PIP описывает состояние всех остальных страниц в базе данных Каждая страница базы данных может иметь 3 состояния нераспреде iennoe (not allocated),распределенное (allocated with space),распреде- генное и започненное (allocated and full) Когда появляется необходимость в до- потнитетьном пространстве дтя новых данных, сервер проверяет PIP на предмет на 1ИЧИЯ ntpauipt. je ]ишы\ страниц 1 с ж нахоцикя такая страница сервер из меняет ее состояние на распределенное Если нераспределенных страниц нет, то база данных расширяется - к ней дописывается новая страница данных
Изображение страницы данных в IBSurgeon и содержащихся на ней данных приведено на рис 4.6
Рис 4.6. Страница v ют i страниц (PIP)
Как только страница распределена, InterBase записывает ее состояние на SIP, а затем пишет саму страницу После этого необходимо присоединить вновь образованную страницу к какому-нибудь множеству страниц, например к страницам данных для какой-то таблицы Дтя этого надо записать ссылку на эту свежую страницу на последней странице этого множества страниц- например на последнюю страницу данных какой-то таблицы
Если сервер прервал свою работу сразу после записи на SIP. но не дойдя до записи ссылки на страницы, которая ссылается на только что распределенную, то эта тотько что распределенная страница становится "потерянной" (orphan) Потерянная страница физически создана зарезервирована на SIP но ссылок сдругих страниц на нее нет, а значит сервер не сможет найти ее и записать на нее данные Потерянная страница изображена красным квадратиком на рис 4 3 Потерянные страницы чаще всего возникают в результате неожиданного выключения питания > сервера и 'аечатся специальным инструментом для починки баз данных gfix (смотри раздет "Починка базы данных")
Прежде чем перейти к рассмотрению страниц данных следует упомянуть о важных типах страниц страницах генераторов и страницах индексов Страницы генераторов представляют собой массив 4-байтовых чисел, которые показывают состояние генераторов Фактически генератор - это обыкновенный счетчик
На рис 4.7 показана страница генераторов Обратите внимание, что хотя IBSuigeon и показывает имена генераторов это не значит что эти имена хранятся на страницах генераторов, - это сдетано дтя удобства пользователя, исследующего базу данных На самом деле имена генераторов хранятся в системной таблице RDBSGeneiators
Рис 4.7. Страница генераторов (gen-ids)
Как видите в данном примере в базе данных содержали только системные генераторы, начинающиеся с префикса RDBS (О назначении и использовании генераторов при разработке приложений баз данных InterBase рассказано в главе Таблицы Первичные ключи и генераторы (ч 1)) Страницы генераторов учитываются наряду с другими страницами в таблице RDBSPages
Каждой таблице, вне зависимости от того, имеет ли она индексы или нет, соответствует по крайней мере одна страница вершины индекса (index root page). Эта страница содержит указатели на страницы индексов для соответствующей таблицы. Можно сказать, что index root page играет для страниц индексов такую же роль, какую играет страница указателей для страниц данных. Поэтому IBSurgeon показывает ее сходным образом.
Изображение страницы вершины индекса приведено на рис. 4.8.
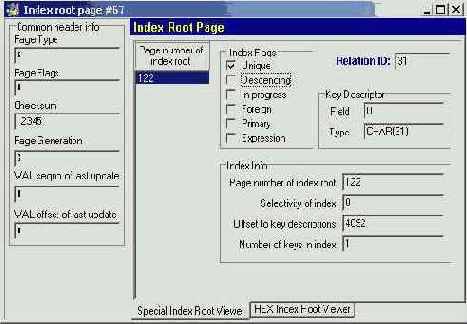
Рис 4.8. Страница вершины индексов (index root page)
Страница вершины индексов содержит список страниц, на которых собственно хранятся сами значения индексов, а также системную информацию об индексах - о селективности индексов и различных флагах. Подробнее про индексы, о их роли и значениях в базах данных рассказано в главе "Индексы" (ч. 1.).
Непосредственно значения индексов содержат индексные страницы (index pages). Пример такой страницы изображен на рис. 4.9.
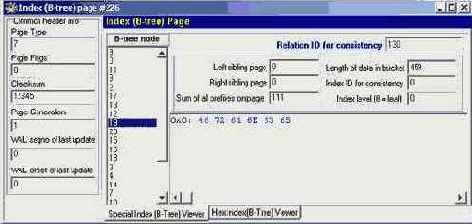
Рис 4.9. Страница индексов (index B-tree page)
Страница индексов хранит упакованные значения проиндексированных данных. Используется достаточно сложный механизм индексации, особенно при построении составных индексов (включающих в себя несколько полей).
Пользовательскую информацию в основном хранят страницы данных (data pages) и страницы, содержащие BLOB-значения (Blob pages). Страницы данных содержат записи в пользовательских таблицах базы данных, фрагменты записей, старые версии записей, различия между версиями, BLOB-поля (если они помещаются на странице) и т. д. Что касается Blob-полей, то они связаны с записями на страницах данных и содержат данные большого размера, не помещающиеся на странице данных. Ссылочный тип хранения BLOB-значений позволяет хранить очень большие данные.
Изображение страницы данных в IBSurgeon приведено на рис. 4.10:
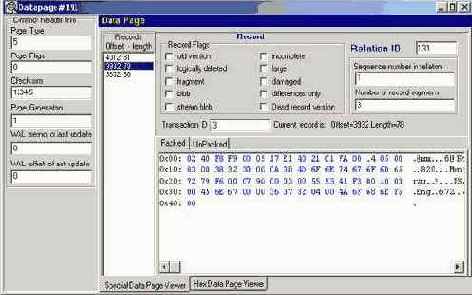
Рис 4.10. Страница данных (data page)
Заголовок страницы данных содержит тип страницы (Page Type), идентификатор таблицы (RelationID), информацию о которой содержит страница, а также номер следующей страницы с данными в этой таблице.
Записи хранятся на страницах данных с конца страницы и по мере заполнения размещаются ближе к началу страницы.
В этом легко убедиться, взглянув на список записей на странице (row indexes), содержащий два значения - сдвиг записи (Offset) на странице и ее длину (length). Как видите, в начале списка располагаются записи, находящиеся на самом конце страницы - например, первая запись имеет сдвиг 8156 байт, а длину 34 байта, следовательно, заканчивается она 8156+34=8192 байтом - на самом краю сфаницы (в данном случае размер страницы - 8192 байта, т. е. размер с фаницы - 8 192 байта).
Когда страница заполнена (сверху - данными, снизу - индексами записей), сервер начинает записывать новые записи и версии старых записей на новые страницы.
Исходя из описанного механизма заполнения страниц, можно легко сказать, почему специалисты по InterBase так настойчиво рекомендуют использовать страницы данных большого размера (4096 байт как минимум, а лучше 8192 байта). Если мы создадим таблицу, одна запись которой будет иметь значительный размер (например, 10 полей VARCHAR(255)), то они будут занимать, будучи заполненными, более 2550 байт. Т. е. одна такая запись не поместится на странице малого размера (1024 или 2048 байт). Очевидно, что необходимость загрузить несколько страниц с диска, чтобы прочитать единственную запись, не ускорит работу с вашей базой данных. Таким образом, настоятельно рекомендуется переопределять размер страницы данных при создании или восстановлении базы данных, потому что по умолчанию устанавливается размер 1024 байта.
Кратко рассмотрев основные типы страниц данных в InterBase и их назначение, перейдем теперь на более высокий структурный уровень.
Установка InterBase на платформе Windows
Один из установщиков InterBase, который предоставляет удобный графический интерфейс и поможет самому неискушенному пользователю справиться с процессом инсталляции, описан в главе "Установка InterBase" в самом начале этой книги Однако сейчас нас интересует то, что происходит за кулисами удобных установщиков какие фай ты и куда копируются, какие ключи в реестре изменяются и добавляются, какие условия проверяются в процессе установки.
Важный вопрос, который обязательно возникнет в процессе чтения главы, откуда брать файлы для создания собственного установщика? Их можно взять и из стандартной установки InterBase, которая была проведена установщиком, а можно загрузить прямо с "родных" сайтов InterBase или Firebird.
Установка InterBase-сервера на Windows
Собственный установщик тиражируемого приложения может установить сервер InterBase так же легко, как и клиента. Давайте рассмотрим необходимые для этого действия.
В процессе установки InterBase-сервера так же, как и при установке клиента, необходимо выбрать установочный каталог <InterBase_root>.
Далее, чтобы установить InterBase-сервер под Windows, необходимо действовать по следующему алгоритму:
Проверить, запущен ли InterBase-сервер на компьютере. Для этого необходимо вызвать функцию Windows API FindWindow и поискать процесс с именем "ibserver" или "ibremote". Если такой процесс найден, то необходимо прервать установку и сообщить пользователю, что он должен остановить любые версии InterBase, находящиеся на этом компьютере, прежде чем начинать инсталляцию.
Скопировать файлы сервера в предназначенные для них каталоги.
Зарегистрировать файлы для совместного использования.
Зарегистрировать сервис TCP/IP
Запустить InterBase-сервер.
Установка клиента под Windows
Давайте рассмотрим, что происходит при установке клиента под Windows. Каким бы скрытым ни был процесс инсталляции сервера, некоторые исходные данные задать все равно придется, явно запросив их у пользователя или установив какие-то по умолчанию значения.
Во время процесса установки InterBase-клиента нужно указать каталог, куда будет устанавливаться InterBase, - назовем его <InterBase_root>. Установка клиента включает следующие шаги:
Копирование файлов, входящих в состав клиента.
Регистрация файлов для совместного использования.
Создание реестровых ключей.
Регистрация сервиса TCP/IP.
Владелец базы данных
Резервное копирование базы данных может быть выполнено либо владельцем базы данных (owner), либо системным администратором (SYSDBA). Но восстановление базы данных может быть выполнено любым пользователем (исключая ситуацию, когда нужно восстановить базу данных поверх существующего файла, - это может осуществить только системный администратор SYSDBA или владелец). Восстановленная база данных принадлежит пользователю, который осуществил процесс восстановления т. е., он становится владельцем (owner) базы данных. Таким образом, процесс backup/restore является средством смены владельца базы данных.
Восстановление "безнадежных" баз данных. InterBase Surgeon
В общем, восстановление базы данных может быть очень хлопотным и тяжелым делом, поэтому никогда не бывает лишним сделать резервную копию базы данных, чтобы не заниматься восстановлением поврежденных данных. Тем не менее, даже если это и случилось, не стоит отчаиваться - выход можно найти даже в самых, казалось бы, безнадежных ситуациях, и сейчас мы рассмотрим два таких случая.
Первый случай представляет собой классическую проблему - это невосстанавливающаяся резервная копия из-за наличия NULL-значений в столбце с ограничениями NOT NULL, которую пустили на восстановление прямо поверх рабочего файла. Рабочий файл затерся, процесс восстановления (restore) прервался из-за ошибки, и мы получили в результате необдуманных действий большой кусок бесполезных данных вместо резервной копии, который лежит на диске и, кажется, не поддается восстановлению. Но выход все же был найден. В той реальной ситуации, в которой мы нашли данное решение, программист сумел вспомнить, на какую именно таблицу и на какой столбец было наложено злополучное ограничение NOT NULL. Файл резервной копии был загружен в шестнадцатеричный редактор, и там путем поиска было найдено сочетание байтов, соответствующее определению этого столбца. После многочисленных экспериментов выяснилось, что ограничение NOT NULL добавляет единичку "где-то рядом" с именем столбца. Прямой правкой в НЕХ-редакторе эта единичка была исправлена на 0, и резервная копия была восстановлена. Программист отделался легким испугом и навсегда запомнил, как правильно организовывать процесс резервного копирования и восстановления из резервной копии.
Следующий сличай казался совершенно безнадежным, однако выход все же был найден.
Ситуация сложилась катастрофическая. База данных "сломалась" на этапе расширения из-за нехватки дискового пространства. InterBase записал на странице учета страниц число страниц, превышающее ее реальный размер. Более того, на страницах учета страниц, похоже, также образовались повреждения. В результате база данных вообще не открывалась ни средствами администрирования, ни утилитой gbak, а при попытке подключиться к базе данных появлялась ошибка "Unexpected end of file". При запуске утилиты gfix происходили весьма странные вещи, программа попросту входила в бесконечный цикл. Сервер в момент работы gfix с огромной скоростью (около 100 Кбайт/с) писал ошибки в лог (файл interbase.log). В результате файл лога очень быстро заполнял все свободное дисковое пространство, и пришлось даже написать программу, которая по таймеру уничтожала неимоверно распухающий лог. Этот процесс продолжался довольно долго - gfix работал более 16 ч без каких-либо видимых результатов.
Лог наполнялся ошибками вида "Page XXXX doubly allocated". В исходных кодах InterBase (в файле val.c) есть скупое описание этой ошибки. Оно гласит, что данная ошибка возникает в случае, когда одна и та же страница данных используется дважды. Очевидно, что эта ошибка, как и зацикливание, являлась следствием разрх тения критически важных страниц в базе данных В результате после нескольких дней безуспешных экспериментов попытки восстановить данные стандартными (документированными) способами были оставлены Поэтому пришлось перейти к низкоуровневому анализу данных, хранящихся в поврежденной базе данных, точнее, в том неупорядоченном массиве данных, который oт нее остался.
Автором идеи о том, как извлечь информацию из подобных "безнадежных" баз данных является Александр Козельский, начальник отдела информационных технологий компании East View Publications Inc. (www.eastview.com).
Метод восстановления, полученный в результате исследований, основывался на том факте, что база данных имеет страничную организацию, а данные из каждой таблицы сгруппированы по страницам данных. Каждая страница данных содержит идентификатор таблицы, для которой она хранит данные.
Особенно было важно восстановить данные из нескольких критичных таблиц. Существовали данные из таких же таблиц, полученные из старой резервной копии, которая отлично работала и могла служить образцом.
База данных-образец была загружена в редактор шестнадцатеричных кодов, затем был произведен поиск образцов тех данных, которые нас интересовали. Шестнадцатеричное представление этих данных было скопировано в буфер, а затем в редактор загрузили остатки поврежденной базы данных. В поврежденной базе данных была найдена последовательность байтов, соответствующая образцу, и была проанализирована страница, на которой нашлась эта последовательность. Сначала было определено начало страницы, что оказалось несложно, поскольку размер файла базы данных кратен размеру страницы данных. Найти начало страницы также оказалось возможным, для этого пришлось поделить номер текущего байта на размер страницы - 8192 байта, а затем округлить результат до целых (в результате получился номер текущей страницы) и умножить полученное число на размер страницы. Таким образом, был найден номер байта, соответствующий началу текущей страницы. Проанализировав заголовок, определили тип страницы (для страниц с данными тип равен пяти - см. файл ods.h из комплекта исходных кодов InterBase, а также ниже главу "Структура базы данных InterBase"), а также идентификатор нужной таблицы.
Дальше была написана программа, которая "просматривала" всю базу данных, собирала все страницы для нужной нам таблицы в единый кусок и сбрасывала его в файл.
Получив таким образом "выжимку" только тех данных, которые были нужны в первую очередь, приступили к анализу содержимого отобранных страниц. InterBase активно использует сжатие данных для экономии места. Например, строку типа VARCHAR, содержащую строку "ABC", он хранит в виде последовательности таких значений: длины строки (2 байта, в нашем случае это 00 03), затем самих символов, а потом контрольной суммы. Пришлось написать анализатор строк, а также других типов данных, который преобразовывал специализированное шестнадцатеричное представление данных в "нормальный" вид.
Применив такой метод "рукопашного" разбора содержимого базы данных, удалось извлечь около 80% информации из нескольких критически важных таблиц.
Позже на основе полученного опыта Олегом Кульковым и Алексеем Ковязи- ным, одним из авторов этой книги, была разработана утилита IBSurgeon (т. е. InterBase Хирург), которая осуществляет прямой доступ к базе данных, минуя ядро InterBase-сервера, и позволяет напрямую читать и корректным образом интерпретировать данные внутри базы данных InterBase.
Используя InterBase Surgeon, удается распознать причины повреждения и восстановить до 90 %, казалось бы безнадежных баз данных, которые не открываются с помощью InterBase и не "лечатся" стандартными методами.
Скачать эту программу можно с сайта поддержки данной книги www.InterBaseworld.com, а также с официального сайта программы www.ibsurgeon.com.
Восстановление из резервной копии
Восстановление из резервной копии (restore) - это процесс создания базы данных на основе информации, извлекаемой из файла резервной копии.
В сущности, restore представляет собой создание пустой базы данных с заданными параметрами (размером страницы, режимом записи и т. д.). Затем в эту базу данных добавляются метаданные - таблицы, различные ограничения и проверки, триггеры, хранимые процедуры и т. д. Созданная база данных наполняется данными из файла резервной копии, после чего создаются необходимые индексы.
Пересоздание базы данных позволяет улучшить скорость работы, а также уменьшить размер базы данных за счет избавления от старых версий записей (ведь в backup включаются только актуальные версии записей) и переупаковки данных. Пересоздание индексов также улучшает скорость доступа к информации в базе данных. Обычно рекомендуется проводить полный цикл backup/restore не реже чем раз в месяц, чтобы избежать излишнего "разбухания" базы данных от накопленных версий.
Трудно переоценить возможность полного пересоздания базы данных (можно даже сказать - возрождения) на основе "мгновенного снимка" информации из базы данных. Только во время восстановления можно сменить основную версию ODS, перейти на другую платформу или ОС. Также restore является обязательным участником процесса преобразования однофайловой базы данных в многофайловую.
Восстановление из резервной копии на системе-приемнике
Итак, мы установили новую версию InterBase и перенесли на нее информацию о наших пользователях (т. е. восстановили базу данных ISC4.gdb). Теперь мы готовы восстановить резервную копию рабочей базы данных (созданную на старой системе) в новой версии InterBase. Для этого можно воспользоваться командой, похожей на эту:
gbak -с -user SYSDBA -password <пароль> <путь к backup>
<путь2 к базе данных>
Как видите, эта команда аналогична той, которую мы применяли для контрольного восстановления резервной копии. База данных восстановится на новой системе, причем если вы сменили версию сервера (например, с 5.x на 6.x), то во время восстановления базы данных будет создана уже с новой версией ODS, т. е. прямая миграция "назад", на предыдущую версию, будет невозможна.
При восстановлении вы можете изменить владельца базы данных, т. е. можно восстановить база данных от имени какого-либо другого пользователя, а не от SYSDBA. Это бывает полезным в целях повышения безопасности работы с базой данных.
Аналогичный процесс миграции применяется и в случае смены аппаратной платформы и/или ОС - будь то переход на другую платформу (Intel->Sparc) или просто замена оборудования или ОС
Прямая миграция по вышеописанному алгоритму - наиболее простой и частый вид миграции баз данных InterBase. Однако, как вы можете видеть, в таблице 4 6 существуют также миграции, обозначенные как "Особый процесс". Сейчас мы подробно рассмотрим его
Восстановление из резервных копий многофайловых баз данных
Из-за ограничения на размер одного файла базы данных в 2 (иногда 4) Гбайт, базы данных большего размера размещаются в нескольких файлах (так же как и резервные копии). Для восстановления многофайловой базы данных из многофайлового backup следует воспользоваться командой
gbak {-C|-R} [options] <файл_резервной_копии1>
<файл_резервной_копии2> [<файл_резервной_копииЗ ...]
<файл создаваемой базы данных1> <размер базы данных1>
<файл создаваемой базы данных2> <размер базы данных2>
[<файл создаваемой базы данных3> <размер базы данных3> ..]
Здесь <файл_резервной_копии N> - это N-й файл резервной копии. Восстановление будет производиться начиная с <файл_резервной_копии1>, затем будет обработан <файл_резервной_копии2>. База данных будет содержать несколько файлов начиная с <файл создаваемой БД1>, затем <файл создаваемой БД2> и т. д. После имени файла базы данных идет размер этого файла. Обратите внимание, что размер файлов исчисляется в страницах! Поэтому необходимо следить за тем, чтобы размер файла не вышел за обозначенные пределы в 2(4) Гбайт. Минимальный размер восстанавливаемого файла базы данных составляет 200 страниц. Также следует помнить о том, что не надо указывать размер последнего файла, - он увеличивается автоматически, чтобы вместить все данные из backup.
Как и в случае с резервным копированием больших многофайловых баз данных для ускорения процесса восстановления лучше всего воспользоваться запуском gbak в режиме сервиса.
Восстановление поврежденной базы данных
Предположим, что наша база данных содержит ошибки и нам необходимо, во-первых, проверить наличие этих ошибок, во-вторых, попытаться исправить эти ошибки. Порядок действий при этом рекомендуется соблюдать следующий.
Останавливаем сервер InterBase, если он еще работает, и делаем копию файла или файлов базы данных. Все действия по восстановлению следует производить только над копией базы данных, так как выбранная стратегия может привести к неудаче и придется начать процедуру восстановления снова - с начального состояния базы данных.
После создания копии произведем полную проверку базы данных (с проверкой фрагментов записей), для чего необходимо выполнить следующую команду:
gfix -v -full corruptbase.gdb - user SYSDBA -password
<ваш_пароль>
В данном случае corruptbase.gdb - это копия поврежденной базы данных. Команда проверит базу данных на предмет повреждения любых структур и выведет список неразрешенных проблем. Если обнаружатся такие ошибки, то нам придется пометить поврежденные данные для удаления и подготовиться к процессу backup/restore, используя следующую команду:
gfix -mend corruptbase. gdb-user SYSDBA-password <ваш_пароль>
После выполнения этой команды следует проверить, остались ли ошибки в базе данных, для чего необходимо вновь запустить gfix с опциями -v -full, а после того, как он отработает, произвести резервное копирование базы данных:
gdak -b -v -ig user SYSDBA -password <ваш_пароль> corruptbase.gdb corruptbase.gbk
Эта команда произведет резервное копирование базы данных (об этом говори: опция -b при этом будут выводиться подробные сведения о ходе backup (опция -v), причем ошибки, связанные с контрольными суммами, будут игнорироваться (опция -ig). Подробнее об опциях инструмента командной строки gbak можно посмотреть в главе "Резервное копирование и извлечение базы данных из резервной копии" этой части.
В случае ошибок с backup следует запустить его в другой конфигурации:
gbak -b -v -ig -g user SYSDBA -password <ваш_пароль>
corruptbase.gdb corruptbase.gbk
где опция - g запретит сборку мусора во время резервного копирования. Часто это помогает решить проблему с backup. Но бывает, что и такого сочетания опций недостаточно для успешного завершения процесса backup. Тогда следует добавить в команду резервного копирования опции -inactive и -one_at_a_time, которые де- активируют индексы в создаваемой из backup-копии базы данных и производят подтверждение (commit) данных для каждой таблицы соответственно.
Также бывает возможным сделать резервную копию базы данных, если перед этим предварительно перевести базу данных в режим "только чтени" (read-only). Такой режим препятствует записи любых изменений а базу данных и иногда помогает осуществить backup поврежденной базы данных. Для перевода базы данных в режим "только чтение" следует воспользоваться следующей командой:
gfix -m read_only -user SYSDBA -password masterkey Disk:\Path\file.gdb
После этого необходимо вновь попытаться сделать backup базы данных с приведенными выше параметрами.
Восстановление с использованием инструмента gbak
Так же как и резервное копирование, восстановление можно осуществить двумя способами - с помощью утилиты gbak и с помощью Services API (если версия InterBase-сервера имеет это API). Наиболее универсальным способом, который мы и рассмотрим, является использование gbak.
Формат команды восстановления база данных следующий:
gbak {-C|-R} [options] <файл_резервной_копии_источник> <файл
создаваемой базы данных>
При восстановлении с помощью gbak необходимо указать либо параметр —С, либо параметр -R, чтобы производить именно restore (по умолчанию gbak будет пытаться произвести backup). Параметр -С означает, что будет создан новый файл базы данных, но если его имя совпадет с уже существующим, то процесс будет
остановлен с ошибкой, сигнализирующей о том, что файл с именем <файл создаваемой базы данных> уже существует. Параметр —R также приводит к созданию базы данных, но в случае совпадения имен без дополнительных вопросов перезапишет существующий файл базы данных.
Опции options, применяющиеся для того, чтобы повлиять на процесс восстановления, описаны в таблице 4.5.
Табл 4.5. Опции gbak при восстановлении из резервной копии
|
Опция |
Описание | ||
|
-c[reate_database] |
Восстанавливает базу данных из резервной копии | ||
|
-buffers] |
Устанавливает размер буфера базы данных | ||
|
-i[nactive] |
Делает индексы неактивными после восстановления | ||
|
-k[ill] |
Не создает shadow-копий, которые были определены для базы данных ранее | ||
|
-mo[de] [read_write | read_only} |
Устанавливает режим записи для восстанавливаемой базы данных. Возможны значения read_write ("чтение и запись" - режим по умолчанию) и read_only ("только для чтения") | ||
|
-n[o_validity] |
Удаляет ограничения ссылочной целостности из восстанавливаемой базы данных, что позволяет восстанавливать те данные, которые не удовлетворяют этим ограничениям | ||
|
-o[ne_at_a_time] |
Восстанавливает одну таблицу зараз - это бывает полезным для частичного восстановления базы данных, которая содержит поврежденные данные | ||
|
-p[age_slze] n |
Устанавливает размер страницы восстанавливаемой базы данных в n байт. Доступны значения 1024, 2048, 4196 или 8192; По умолчанию размер страницы - 1024 байта | ||
|
-pas[sword] text |
Пароль пользователя, подключающегося к базе данных для восстановление из резервной копии | ||
|
-r[eplace_database] |
Восстанавливать базу данных в новый файл, а если такой файл уже существует, то перезаписать поверх | ||
|
-se[rvice] servicename • |
Восстановить базу данных на том же компьютере, где находится база данных-оригинал. Для этого вызывается Service Manager на компьютере-сервере, причем формат вызова отличается для различных сетевых протоколов: TCP/IP hostname:service_mgr; SPX hostname@service_mgr; Named pipes \\hostname\service_mgr; Local service_mgr | ||
|
-u[ser] name |
Имя пользователя, который подключается к базе данных для восстановлениям | ||
|
-use_[all_space] |
Восстанавливает базу данных со 100 %-ным заполнением каждой страницы данных, вместо 80 %-ного заполненния по умолчанию | ||
|
-v[erbose] |
Включить показ подробного протокола действий gbak во время restore | ||
|
-y [file | suppress_output] |
Направлять сообщения в файл (файла с таким именем не должно существовать) или подавить вывод сообщений | ||
|
-z |
Показать версию gbak и версию ядра InterBase-сервера |
Коротко рассмотрим некоторые важные ключи процесса восстановления. Во- первых, ключ -p[age_size] n, который устанавливает размер страницы создаваемой базы данных. Выполнить восстановление с этой опцией - это единственный способ изменить размер страницы базы данных.
Во-вторых, сочетание ключей -use_[all_space] и -mo[de] read_only позволяет создать базу данных только для чтения, с максимальным заполнением страниц данных. Это полезно при создании баз данных-справочников, распространяемых на компакт-дисках.
В-третьих, ключи -i[nactive] (деактивация индексов) и -n[o_validity] (удаление ограничений ссылочной целостности) часто применяются при восстановлении поврежденных баз данных (см. ниже главу "Починка базы данных" (ч. 4)).
Выбор аппаратного обеспечения для InterBase
Аппаратное обеспечение ("железо"-на компьютерном жаргоне) - это компьютер-сервер и его компоненты, сетевое оборудование, а также рабочие станции, на которых будут выполняться клиентские программы, использующие InterBase. Более всего внимания мы уделим компьютеру-серверу, но также дадим несколько рекомендаций относительно остальных компонентов.
Конечно, разные задачи требуют различного аппаратного обеспечения Поэтому здесь мы будем рассматривать преимущества и недостатки аппаратного обеспечения исходя, из того, что выбор СУБД для задачи уже позади, т. е. твердо выбран InterBase. Это позволит нам избежать замечаний вроде: "При таких объемах данных вам лучше еще раз подумать об Oracle".
Разумеется, выбор аппаратного оборудования нельзя рассматривать как оптимизационный процесс, который целиком относится только к InteiBase, однако часто бывает так, что для внедрения какой-либо задачи покупается новое оборудование. Поэтому аппаратное обеспечение нельзя обойти вниманием. Будем считать, что подбор подходящего оборудования также относится к оптимизации производительности InterBase.
Зачем изучать физическую структуру базы данных?
Говоря о физической структуре базы данных InterBase, обычно подразумевают то что представляют собой данные с точки зрения низкоуровневой организации данных - вплоть до уровня байтов. Многие программисты, работающие на языках высокого уровня, пренебрегают изучением физической структуры. Однако знание основных принципов организации информации внутри базы данных дает ключ к действительно эффективному проектированию приложений баз данных. Поэтом} в этой главе мы проведем экскурс во "внутренности" устройства базы данных InterBase и разберемся в том, как она устроена.
Итак, для чего предназначена система управления базами данных? Очевидно, для хранения и управления данными. Это звучит банально, но об этом стоит задуматься. Пользователь некоторым образом помещает данные в СУБД, которая эти данные каким-то образом переводит в понятные ей внутренние форматы. Вы можете представлять себе "нолики и единички", если слова "внутренний формат данных" вызывают какие-то трудности с ассоциациями. СУБД хранит эти данные и по первому требованию должна извлечь их из своего формата, преобразовать в удобочитаемый вид и предоставить пользователю.
Предметом рассмотрения этой главы будет то, как именно СУБД хранит свои данные, в каком виде, как они opi авизованы на диске. Мы попробуем прояснить, как из битов и байтов, лежащих на диске, получается ценная информация, помещаемая в базу данных пользователями.
restore дает возможность обновить вашу
Процесс backup/ restore дает возможность обновить вашу базу данных, очистить ее от "пепла" старых версий и пересоздать индексы. Чтобы уберечь данные от потери, необходимо регулярное резервное копирование, а для нормального функционирования базы данных надо периодически производить полное пересоздание базы данных с помощью восстановления ее из резервной копии.
Главное, что следует вынести из этой главы, - это то, что миграция процесс сложный и нелинейный, поэтому нельзя браться за нее без тщательного продумывания и, конечно же, без резервного копирования.
Статистику InterBase-сервера и базы данных необходимо проанализировать на этапе тестирования приложения баз данных, чтобы выявить возможные "узкие места" в производительности, а также во время профилактических процедур по обслуживанию базы данных после возникновения сбоев или каких-либо проблем.
Необходимо уделять особое внимание оптимизации производительности приложений баз данных InterBase, так как правильно выбранные настройки позволяют улучшать производительность без чрезмерных затрат средств на покупку аппаратного обеспечения и эксплуатировать приложения баз данных с максимальной эффективностью.
В данной главе были рассмотрены две версии InterBase: Super под Windows и Classic под Linux, чтобы читатель получил представление о том, какой совокупностью файлов представлен InterBase. Состав файлов для InterBase обеих версий был рассмотрен на примере клона InterBase 6 - Firebird 1.0.
В этой главе впервые были рассмотрены вопросы реализации хранения и обработки данных внутри базы данных InterBase. К сожалению, даже провести краткий обзор данной темы не удается, не прибегая к большому числу терминов и к большому количеству неточных аналогий. При более подробном изложении физической и логической структуры базы данных в любом случае пришлось бы обращаться к исходным кодам InterBase, но это потребовало бы уже совершенно отдельной книги.
Тем не менее мы считаем, что каждому программисту было бы полезно ознакомиться с "начинкой" того продукта, который он ежедневно использует. Возможно, кто-то из читателей пойдет дальше - попробует разобраться в исходном коде InterBase/Firebird и примкнет к команде разработчиков Firebird или Yaffil, внеся туда множество новых интересных идей.
Запуск InterBase-сервера
InterBase-сервер, функционирующий под управлением NT/2000/XP, может выполняться в двух режимах - в виде службы (service) и в виде приложения. На Windows 9x InterBase может использоваться только в режиме приложения. Давайте рассмотрим, как настроить и запустить наш сервер после установки. Чтобы запустить InterBase в режиме приложения, необходимо выполнить команду "ibserver.exe -а". Чтобы установить InterBase в качестве сервиса на NT/2000/XP, следует воспользоваться утилитой instsvc.exe, которая зарегистрирует InterBase- сервер в качестве службы. Как известно, служба может либо запускаться автоматически при запуске Windows, либо запускаться вручную. Для запуска сервиса в автоматическом режиме необходимо выполнить команду
instsvc install "<InterBase_root>" -auto
Если InterBase устанавливается на систему Windows 2000/XP, то никаких дополнительных действий можно не предпринимать - эти системы сумеют самостоятельно перезапустить сервис, если он аварийно завершится. Другое дело - Windows NT4.0. Для перезапуска InterBase-сервера после возникновения сбоев необходимо воспользоваться специальной службой-хранителем - InterBase Guardian. В этом случае необходимо в процессе инсталляции скопировать файл ibguard.exe и установить его в качестве сервиса. В связи с тем, что поддержка NT4.0 в 2002 году прекращена, рассматривать установку этого сервиса здесь мы не будем, лишь порекомендуем InterBase 5.5 Embedded Installation Guide.
